Dataset yang digunakan selanjutnya diambil dari kompetisi kaggle yang telah berlalu
dari sini .
Pada tab Data, Anda dapat membaca deskripsi semua bidang.
Semua kode sumber dalam format laptop di
sini .
Kami memuat data, periksa bahwa kami umumnya memiliki:
import numpy as np import pandas as pd dataset = pd.read_csv('../input/ghouls-goblins-and-ghosts-boo/train.csv')
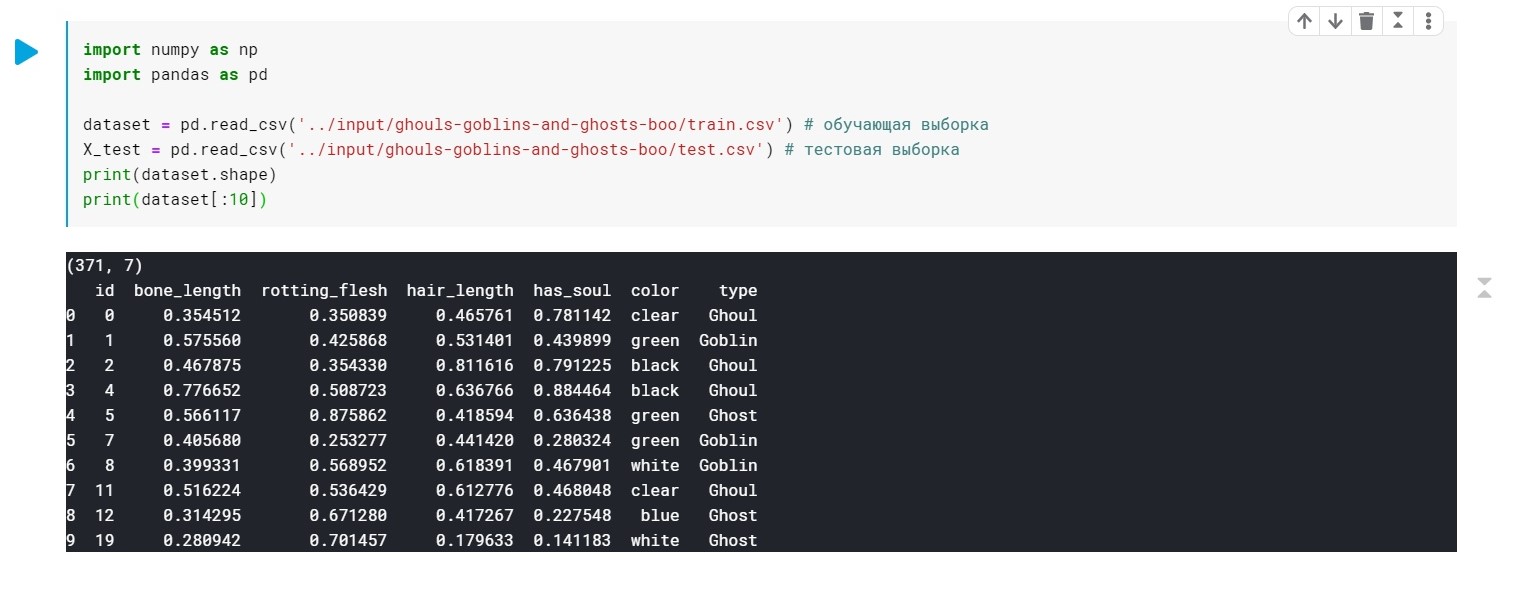
Nilai-nilai bidang tipe (Ghoul, Ghost, Goblin) hanya diganti dengan 0, 1 dan 2.
Warna - juga perlu diproses terlebih dahulu (kita hanya perlu nilai numerik untuk membangun model). Kami akan menggunakan LabelEncoder dan OneHotEncoder untuk ini.
Lebih detail .
from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X_1 = LabelEncoder() X_train[:, 4] = labelencoder_X_1.fit_transform(X_train[:, 4]) labelencoder_X_2 = LabelEncoder() X_test[:, 4] = labelencoder_X_2.fit_transform(X_test[:, 4]) labelencoder_Y_2 = LabelEncoder() Y_train = labelencoder_Y_2.fit_transform(Y_train) one_hot_encoder = OneHotEncoder(categorical_features = [4]) X_train = one_hot_encoder.fit_transform(X_train).toarray() X_test = one_hot_encoder.fit_transform(X_test).toarray()
Nah, pada titik ini data kami sudah siap. Masih melatih model kami.
Pertama, terapkan
Adagrad :
Intinya, ini adalah modifikasi dari penurunan gradien stokastik, tentang yang saya tulis terakhir kali:
habr.com/en/post/472300Metode ini memperhitungkan sejarah semua gradien masa lalu untuk setiap parameter individu (ide penskalaan). Ini memungkinkan Anda mengurangi ukuran langkah pembelajaran untuk parameter yang memiliki gradien besar:
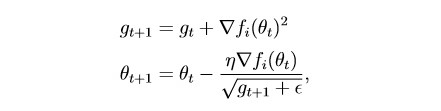
g adalah parameter penskalaan (g0 = 0)
θ - parameter (berat)
epsilon adalah konstanta kecil yang diperkenalkan untuk mencegah pembagian dengan nol
Bagilah dataset menjadi 2 bagian:
Sampel pelatihan (kereta) dan validasi (val):
from sklearn.model_selection import train_test_split x_train, x_val, y_train, y_val = train_test_split(X_train, Y_train, test_size = 0.2)
Sedikit persiapan untuk pelatihan model:
import torch import numpy as np device = 'cuda' if torch.cuda.is_available() else 'cpu' def make_train_step(model, loss_fn, optimizer): def train_step(x, y): model.train() yhat = model(x) loss = loss_fn(yhat, y) loss.backward() optimizer.step() optimizer.zero_grad() return loss.item() return train_step
Model pelatihan mandiri:
from torch import optim, nn model = torch.nn.Sequential( nn.Linear(10, 270), nn.ReLU(), nn.Linear(270, 3)) lr = 0.01 n_epochs = 500 loss_fn = torch.nn.CrossEntropyLoss() optimizer = optim.Adagrad(model.parameters(), lr=lr) train_step = make_train_step(model, loss_fn, optimizer) from sklearn.utils import shuffle for epoch in range(n_epochs): x_train, y_train = shuffle(x_train, y_train)
Peringkat Model:
Di sini, selain lapisan, kami hanya memiliki 2 parameter yang dapat dikonfigurasi (untuk saat ini):
tingkat belajar dan n_epochs (jumlah era).
Bergantung pada bagaimana kami menggabungkan dua parameter ini, 3 situasi dapat muncul:
1 - semuanya baik-baik saja, mis. model menunjukkan kehilangan yang rendah pada sampel pelatihan dan akurasi yang tinggi pada yang validasi.
2 - kurang fit - kerugian besar pada sampel pelatihan dan akurasi rendah pada yang validasi.
3 - overfitting - kerugian rendah pada sampel pelatihan, tetapi akurasi rendah pada yang validasi.
Dengan yang pertama, semuanya jelas :)
Dengan yang kedua, tampaknya juga - untuk bereksperimen dengan tingkat pembelajaran dan n_epochs.
Dan apa yang harus dilakukan dengan yang ketiga? Jawabannya sederhana - regularisasi!
Sebelumnya, kami memiliki fungsi kehilangan bentuk:
L = MSE (Y, y) tanpa persyaratan tambahan
Inti dari regularisasi adalah bahwa, menambahkan istilah pada fungsi objektif, "baik" gradien jika terlalu besar. Dengan kata lain, kami memberlakukan batasan pada fungsi tujuan kami.
Ada banyak metode regularisasi. Lebih lanjut tentang L1 dan L2 - regularisasi:
craftappmobile.com/l1-vs-l2-regularisasi/#_L1_L2Metode Adagrad mengimplementasikan regularisasi L2, mari kita terapkan!
Pertama, untuk kejelasan, kami melihat indikator model tanpa regularisasi:
lr = 0,01, n_epochs = 500:
kerugian = 0,44 ...
Akurasi: 0,71
lr = 0,01, n_epochs = 1000:
kerugian = 0,41 ...
Akurasi: 0,75
lr = 0,01, n_epochs = 2000:
kerugian = 0,39 ...
Akurasi: 0,75
lr = 0,01, n_epochs = 3000:
kerugian = 0,367 ...
Akurasi: 0,76
lr = 0,01, n_epochs = 4000:
kerugian = 0,355 ...
Akurasi: 0,72
lr = 0,01, n_epochs = 10000:
kerugian = 0,285 ...
Akurasi: 0,69
Di sini Anda dapat melihat bahwa pada era 4k + - modelnya sudah overfit. Sekarang mari kita coba untuk menghindari ini:
Untuk melakukan ini, tambahkan parameter weight_decay untuk metode optimasi kami:
optimizer = optim.Adagrad(model.parameters(), lr=lr, weight_decay = 0.001)
Dengan lr = 0,01, m_epochs = 10000:
kerugian = 0,367 ...
Akurasi: 0,73
Pada 4000 era:
kerugian = 0,389 ...
Akurasi: 0,75
Ternyata jauh lebih baik, tetapi kami hanya menambahkan 1 parameter di optimizer :)
Sekarang pertimbangkan SGDm (ini adalah penurunan gradien stokastik dengan ekstensi kecil - heuristik, jika Anda suka).
Intinya adalah bahwa
SGD memperbarui parameter dengan cukup kuat setelah setiap iterasi. Adalah logis untuk "menghaluskan" gradien menggunakan gradien dari iterasi sebelumnya (ide inersia):
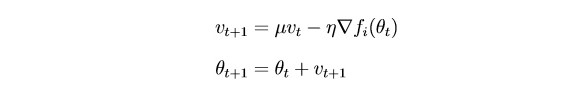
θ - parameter (berat)
μ - hiperparameter inersia
SGD tanpa parameter momentum:
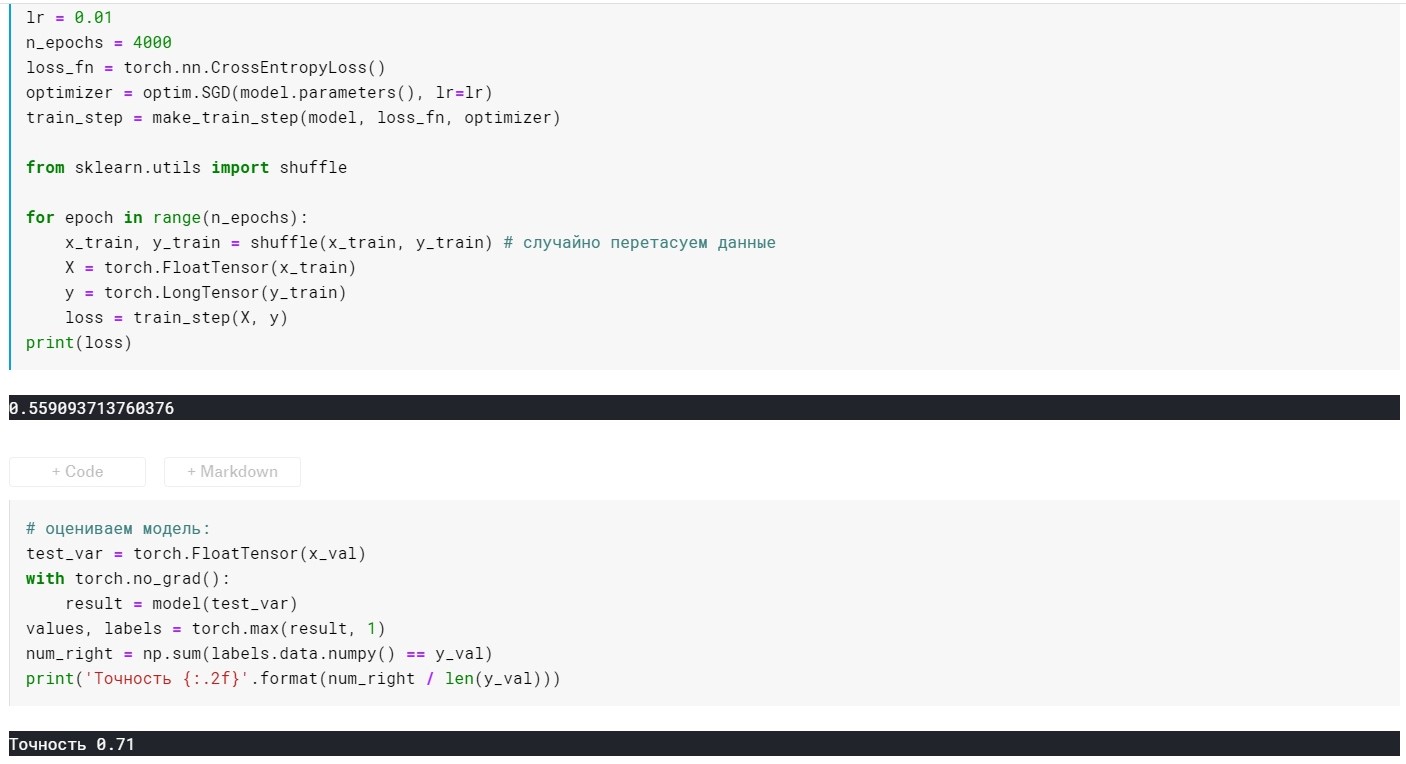
SGD dengan parameter momentum:
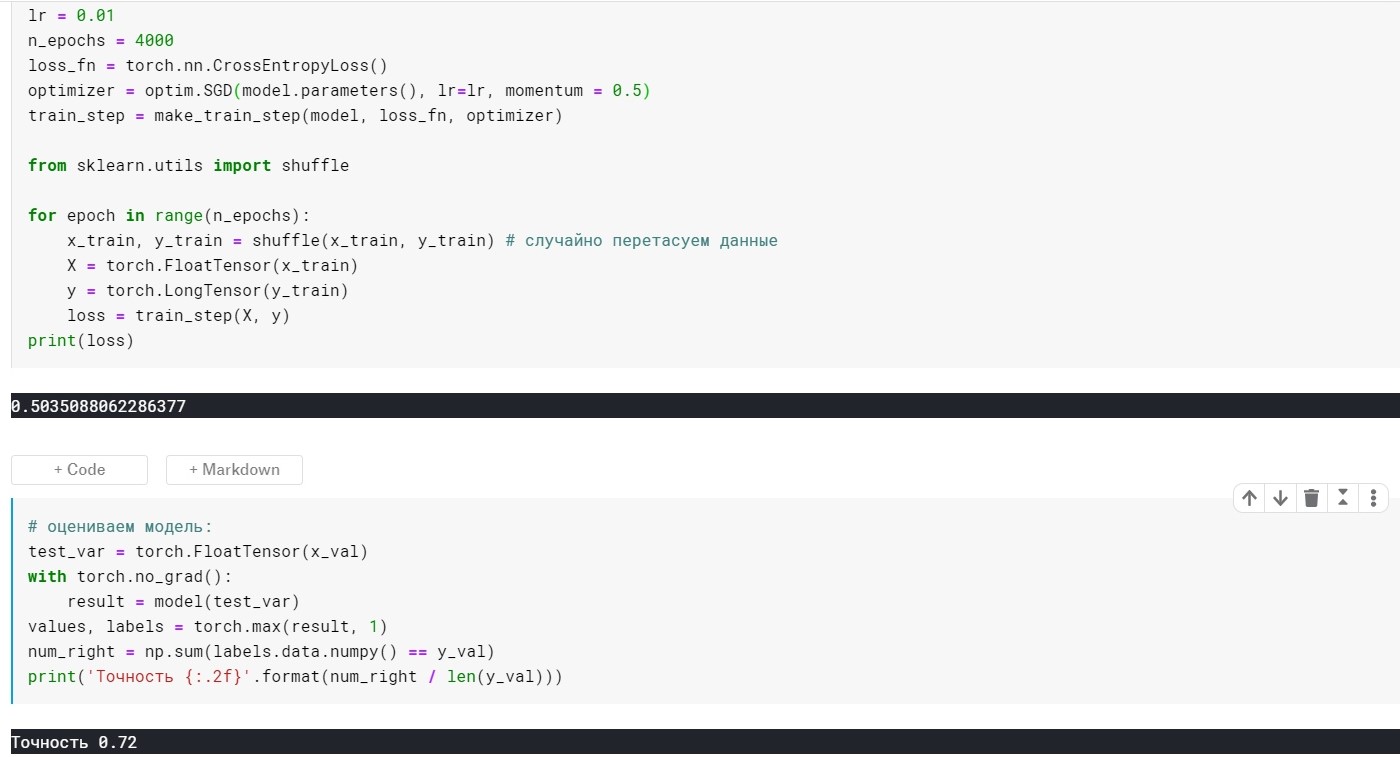
Ternyata tidak jauh lebih baik, tetapi intinya di sini adalah bahwa ada metode yang segera menggunakan gagasan penskalaan dan inersia. Misalnya, Adam atau Adadelta, yang sekarang menunjukkan hasil yang baik. Nah, untuk memahami metode ini, saya pikir perlu untuk memahami beberapa ide dasar yang digunakan dalam metode yang lebih sederhana.
Terima kasih atas perhatian Anda!