
Hai Nama saya Askhat Nuryev, saya seorang insinyur otomatisasi terkemuka di DINS.
Saya telah bekerja di Dino Systems selama 7 tahun terakhir. Selama waktu ini, saya harus berurusan dengan berbagai tugas: dari menulis tes fungsional otomatis hingga menguji kinerja dan ketersediaan tinggi. Lambat laun, saya menjadi lebih terlibat dalam mengatur pengujian dan mengoptimalkan proses secara umum.
Dalam artikel ini saya akan memberi tahu:
- Bagaimana jika bug sudah bocor ke produksi?
- Bagaimana cara bersaing untuk kualitas sistem, jika Anda tidak dapat menghitung kesalahan dengan tangan Anda dan tidak merevisi mata Anda?
- Apa jebakan dalam penanganan kesalahan otomatis?
- Bonus apa yang bisa saya dapatkan dari menganalisis statistik kueri?
DINS adalah pusat pengembangan RingCentral, pemimpin pasar di antara penyedia cloud Unified Communications. Ringentral menyediakan segalanya untuk komunikasi bisnis mulai dari telepon klasik, SMS, rapat hingga fungsionalitas pusat kontak dan produk untuk kerja tim yang kompleks (ala Slack). Solusi cloud ini terletak di pusat data sendiri, dan klien hanya perlu berlangganan ke situs.
Sistem, dalam pengembangan yang kami ikuti, melayani 2 juta pengguna aktif dan memproses lebih dari 275 juta permintaan per hari. Tim yang saya kerjakan sedang mengembangkan API.
Sistem ini memiliki API yang agak rumit. Dengannya, Anda dapat mengirim SMS, melakukan panggilan, mengumpulkan konferensi video, mengatur akun, dan bahkan mengirim faks (halo, 2019). Dalam bentuk yang disederhanakan, skema interaksi layanan terlihat seperti ini. Saya tidak bercanda.

Jelaslah bahwa sistem yang begitu kompleks dan sangat sarat menciptakan sejumlah besar kesalahan. Misalnya, setahun yang lalu kami menerima puluhan ribu kesalahan per minggu. Ini adalah seperseribu persen relatif terhadap jumlah total permintaan, tetapi masih banyak kesalahan yang berantakan. Kami menangkap mereka berkat layanan dukungan yang dikembangkan, namun, kesalahan ini memengaruhi pengguna. Selain itu, sistem ini terus berkembang, jumlah pelanggan terus bertambah. Dan jumlah kesalahan juga.
Pertama, kami mencoba menyelesaikan masalah dengan cara klasik.
Kami mengumpulkan, meminta log dari produksi, mengoreksi sesuatu, melupakan sesuatu, membuat dasbor di Kibana dan Sumologic. Tapi secara keseluruhan itu tidak membantu. Bugnya bocor, pengguna mengeluh. Menjadi jelas bahwa ada sesuatu yang salah.
Otomasi
Tentu saja, kami mulai memahami dan melihat bahwa 90% dari waktu yang dihabiskan untuk memperbaiki kesalahan dihabiskan untuk mengumpulkan informasi tentangnya. Inilah tepatnya:
- Dapatkan informasi yang hilang dari departemen lain.
- Periksa log server.
- Selidiki perilaku sistem kami.
- Memahami apakah perilaku sistem ini atau itu salah.
Dan hanya 10% sisanya yang kami habiskan langsung untuk pengembangan.
Kami pikir - tetapi bagaimana jika kami membuat sistem yang dengan sendirinya menemukan kesalahan, menempatkan mereka prioritas dan menunjukkan semua data yang diperlukan untuk memperbaikinya?
Saya harus mengatakan bahwa gagasan tentang layanan semacam itu menimbulkan beberapa kekhawatiran.
Seseorang berkata: "Jika kita menemukan semua bug sendiri, lalu mengapa kita membutuhkan QA?"
Yang lain mengatakan sebaliknya: "Anda akan tenggelam dalam tumpukan bug ini!".
Singkatnya, ada baiknya membuat layanan jika hanya untuk memahami mana yang benar.
spoiler(kedua kelompok skeptis salah)
Solusi siap pakai
Pertama-tama, kami memutuskan untuk melihat sistem mana yang sudah ada di pasaran. Ternyata ada banyak dari mereka. Anda dapat menyorot Raygun, Sentry, Airbrake, ada layanan lain.
Tapi tidak satu pun dari mereka yang cocok untuk kita, dan inilah alasannya:
- Beberapa layanan mengharuskan kami melakukan perubahan terlalu besar pada infrastruktur yang ada, termasuk perubahan di server. Airbrake.io harus memperbaiki puluhan, ratusan komponen sistem.
- Yang lain mengumpulkan data tentang kesalahan kita sendiri dan mengirimkannya ke suatu tempat di samping. Kebijakan keamanan kami tidak mengizinkan ini - data pengguna dan kesalahan harus tetap bersama kami.
- Yah, mereka juga cukup mahal.
Kami melakukan kami
Menjadi jelas bahwa kami harus membuat layanan kami, terutama karena kami telah membangun infrastruktur yang sangat baik untuk itu:
- Semua layanan sudah menulis log ke repositori tunggal - Elastis. Dalam log, pengidentifikasi seragam permintaan melalui semua layanan dilemparkan.
- Statistik kinerja juga dicatat di Hadoop. Kami bekerja dengan log menggunakan Impala dan Metabase.
Dari semua kesalahan server (
sesuai dengan klasifikasi kode status HTTP ), 500 kode adalah yang paling menjanjikan dalam hal analisis kesalahan. Menanggapi kesalahan 502, 503 dan 504, dalam beberapa kasus Anda hanya dapat mengulangi permintaan setelah beberapa waktu tanpa menunjukkan jawaban kepada pengguna. Dan menurut rekomendasi RC Platform API, pengguna harus menghubungi dukungan jika mereka menerima kode status 500 sebagai jawaban atas panggilan.
Versi pertama dari sistem mengumpulkan log eksekusi kueri, semua jejak stack yang muncul, data pengguna dan memasukkan bug ke dalam pelacak, dalam kasus kami adalah JIRA.
Tepat setelah pengujian berjalan, kami perhatikan bahwa sistem menciptakan sejumlah besar kesalahan duplikat. Namun, di antara duplikat ini, banyak memiliki jejak tumpukan yang hampir sama.
Itu perlu untuk mengubah metode untuk mengidentifikasi kesalahan yang sama. Dari menganalisis data statistik murni, lanjutkan ke menemukan akar penyebab kesalahan. Stack traces mencirikan masalah dengan baik, tetapi mereka agak sulit untuk dibandingkan satu sama lain - nomor baris berubah dari versi ke versi, data pengguna dan kebisingan lainnya masuk ke dalamnya. Selain itu, mereka tidak selalu masuk ke log - untuk beberapa permintaan yang dibatalkan, mereka tidak ada.
Dalam bentuk paling murni, jejak tumpukan tidak nyaman digunakan untuk melacak kesalahan.
Itu perlu untuk memilih pola, templat jejak tumpukan, dan menghapusnya dari informasi yang sering berubah. Setelah serangkaian percobaan, kami memutuskan untuk menggunakan ekspresi reguler untuk menghapus data.
Sebagai hasilnya, kami merilis versi baru, di dalamnya kesalahan diidentifikasi oleh templat unik ini, jika jejak tumpukan tersedia. Dan jika mereka tidak tersedia, maka dengan cara lama, dengan metode http dan grup API.
Dan setelah itu praktis tidak ada duplikat. Namun, banyak kesalahan unik ditemukan.
Langkah selanjutnya adalah memahami bagaimana memprioritaskan kesalahan, yang mana yang perlu diperbaiki lebih awal. Kami diprioritaskan oleh:
- Frekuensi kesalahan.
- Jumlah pengguna yang dia khawatirkan.
Berdasarkan statistik yang dikumpulkan, kami mulai menerbitkan laporan mingguan. Mereka terlihat seperti ini:
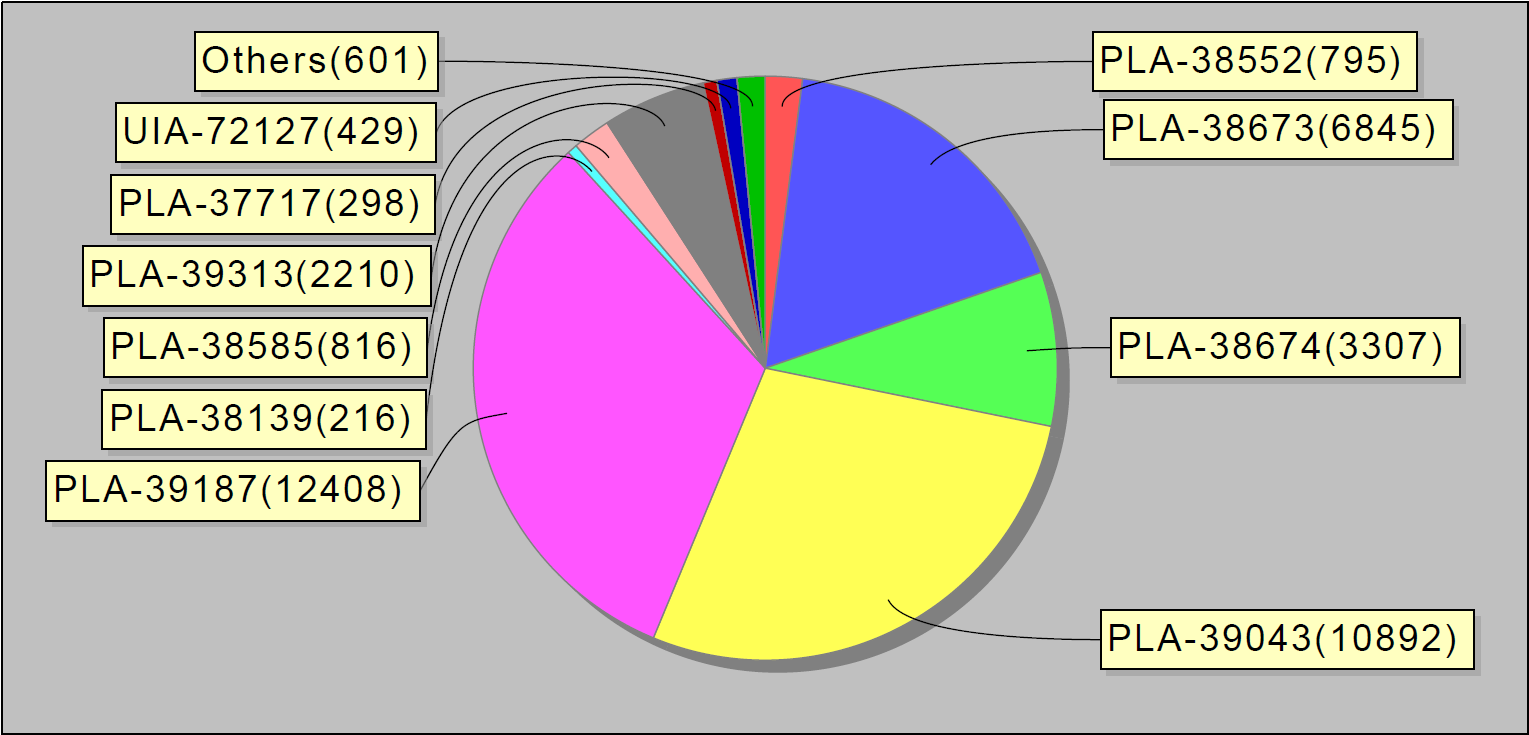
Atau, misalnya, 10 kesalahan teratas per minggu. Menariknya, 10 bug di jira ini menyumbang 90% dari kesalahan layanan:
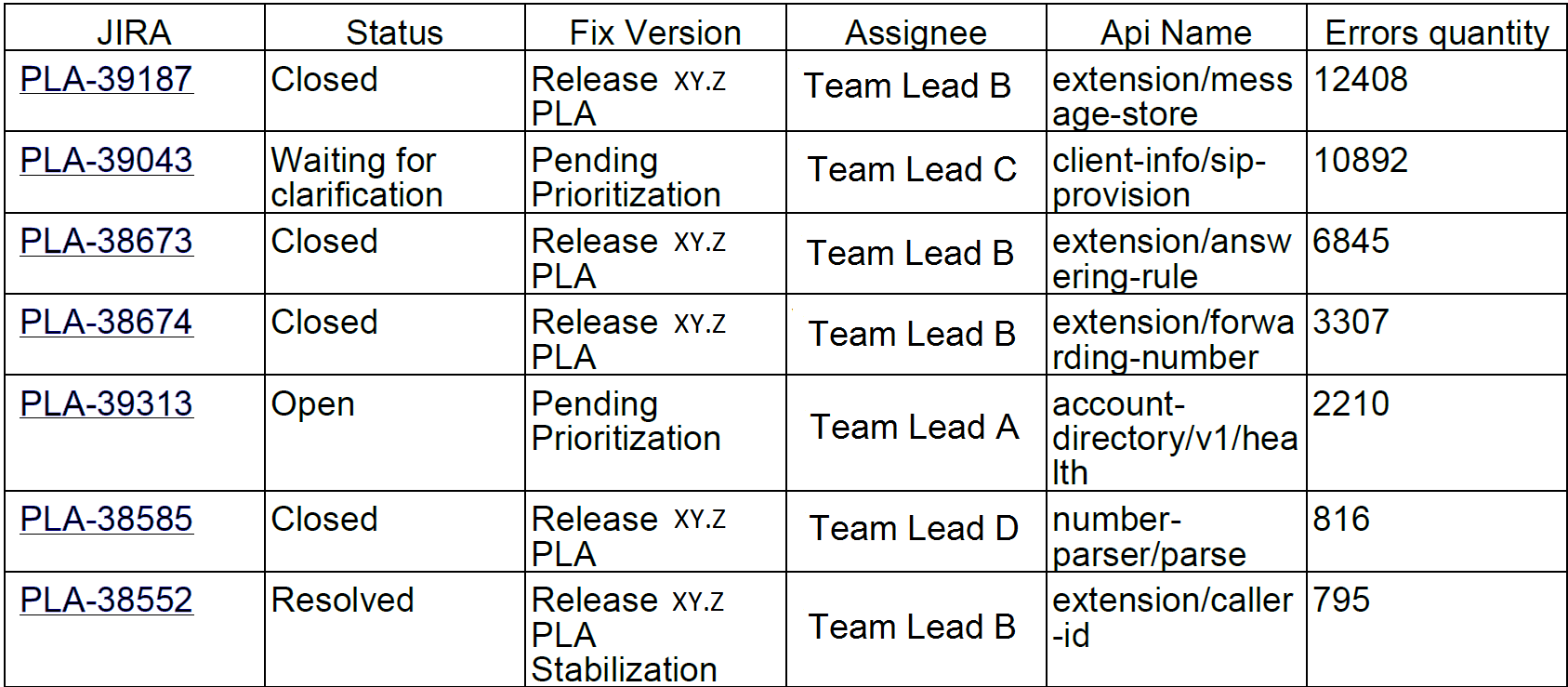
Kami mengirim laporan tersebut kepada pengembang dan pemimpin tim.
Beberapa bulan setelah kami meluncurkan sistem, jumlah masalah menjadi berkurang. Bahkan MVP kecil kami (produk yang layak minimal) membantu memperbaiki kesalahan.
Masalah
Mungkin kita akan berhenti di sini, jika bukan karena satu kecelakaan.
Suatu ketika saya mulai bekerja dan memperhatikan bahwa sistem memusatkan bug seperti kue panas: satu per satu. Setelah penyelidikan singkat, menjadi jelas bahwa lusinan kesalahan ini berasal dari satu layanan. Untuk mencari tahu ada apa, saya pergi ke ruang obrolan tim penempatan. Ada orang-orang di dalamnya yang terlibat dalam memasang versi layanan baru pada produksi dan memastikan bahwa mereka bekerja seperti yang diharapkan.
Saya bertanya: "Teman-teman, apa yang terjadi dengan layanan ini?"
Dan mereka menjawab: "Satu jam yang lalu kami menginstal versi baru di sana."
Langkah demi langkah, kami mengidentifikasi masalah dan menemukan solusi sementara, dengan kata lain, me-restart server.
Menjadi jelas bahwa sistem "keliru" diperlukan tidak hanya oleh pengembang dan insinyur yang bertanggung jawab atas kualitas. Para insinyur yang bertanggung jawab untuk keadaan server pada produksi, serta orang-orang yang menginstal versi baru di server, juga tertarik. Layanan yang kami kembangkan akan menunjukkan kesalahan apa yang terjadi dalam produksi selama perubahan sistem, seperti menginstal server, menerapkan konfigurasi baru, dan sebagainya.
Dan kami memutuskan untuk melakukan iterasi pengembangan lain.
Dalam proses penanganan kesalahan, kami menambahkan catatan statistik pemutaran masalah ke database dan dasbor di Grafana. Ini adalah bagaimana distribusi grafis kesalahan per hari di seluruh sistem terlihat seperti:

Dan begitu - kesalahan dalam layanan individual.

Kami juga mengacaukan pemicu dengan eskalasi ke tim teknik yang bertanggung jawab - jika ada banyak kesalahan. Kami juga mengatur pengumpulan data sekali setiap 30 menit (bukan sekali sehari, seperti sebelumnya).
Proses sistem kami mulai terlihat seperti ini:
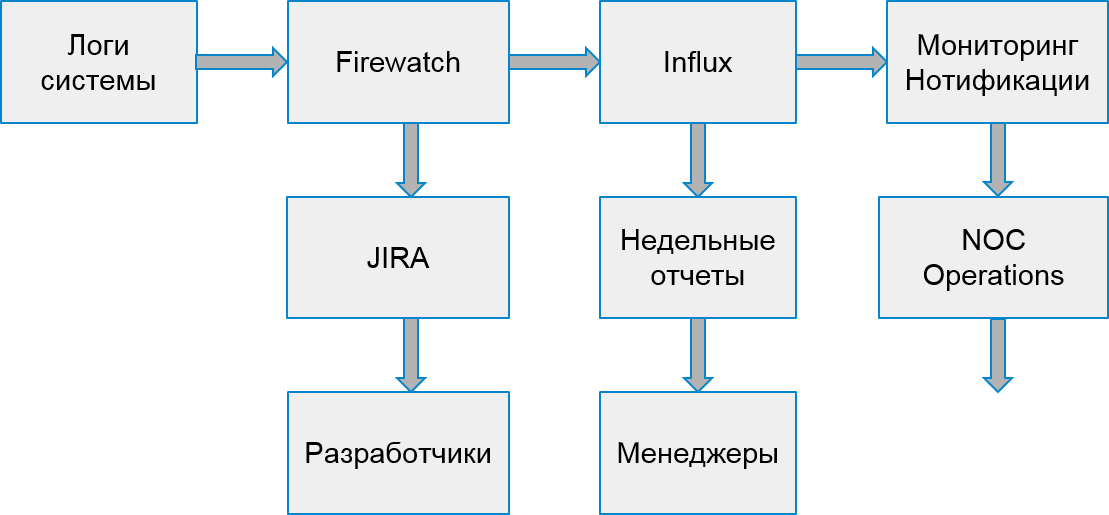
Kesalahan Pelanggan
Namun, pengguna tidak hanya menderita dari kesalahan server. Itu juga terjadi bahwa kesalahan terjadi karena penerapan aplikasi klien.
Untuk menangani kesalahan klien, kami memutuskan untuk membangun proses pencarian dan analisis lainnya. Untuk melakukan ini, kami memilih 2 jenis kesalahan yang memengaruhi perusahaan: kesalahan otorisasi dan kesalahan pelambatan.
Throttling adalah cara untuk melindungi sistem dari kelebihan beban. Jika aplikasi atau pengguna melebihi kuota permintaan mereka, sistem mengembalikan kode kesalahan 429 dan header Coba Lagi, nilai header menunjukkan waktu setelah permintaan harus diulang untuk eksekusi yang berhasil.
Aplikasi dapat tetap dibatasi tanpa batas waktu jika mereka berhenti mengirim permintaan baru. Pengguna akhir tidak dapat membedakan kesalahan ini dari yang lain. Akibatnya, ini menyebabkan keluhan ke layanan dukungan.
Untungnya, infrastruktur dan sistem statistik memungkinkan untuk melacak bahkan kesalahan klien. Kami dapat melakukan ini karena pengembang aplikasi yang menggunakan API kami harus melakukan pra-registrasi dan menerima kunci unik mereka. Setiap permintaan dari klien harus berisi token otorisasi, jika tidak, klien akan menerima kesalahan. Dengan menggunakan token ini, kami menghitung aplikasi.
Ini adalah bagaimana pemantauan kesalahan pelambatan terlihat. Puncak kesalahan sesuai dengan hari kerja, dan pada akhir pekan - sebaliknya, tidak ada kesalahan:

Dengan cara yang sama seperti dalam kasus kesalahan internal, berdasarkan statistik dari Hadoop, kami menemukan aplikasi yang mencurigakan. Pertama, terkait dengan jumlah permintaan yang berhasil ke jumlah permintaan yang dilengkapi dengan kode 429. Jika kami menerima lebih dari setengah permintaan tersebut, kami berpikir bahwa aplikasi tersebut tidak berfungsi dengan benar.
Kemudian kami mulai menganalisis perilaku aplikasi individual dengan pengguna tertentu. Di antara aplikasi yang mencurigakan, kami menemukan perangkat spesifik tempat aplikasi itu berjalan dan menyaksikan seberapa sering ia mengeksekusi permintaan setelah menerima kesalahan pelambatan pertama. Jika frekuensi permintaan tidak berkurang, aplikasi tidak menangani kesalahan seperti yang diharapkan.
Sebagian dari aplikasi dikembangkan di perusahaan kami. Oleh karena itu, kami dapat segera menemukan insinyur yang bertanggung jawab dan memperbaiki kesalahan dengan cepat. Dan kami memutuskan untuk mengirim kesalahan yang tersisa ke tim yang menghubungi pengembang eksternal dan membantu mereka memperbaiki aplikasi mereka.
Untuk setiap aplikasi tersebut, kami:
- Kami membuat tugas di JIRA.
- Kami mencatat statistik dalam Influx.
- Kami sedang mempersiapkan pemicu untuk intervensi bedah jika terjadi peningkatan tajam dalam jumlah kesalahan.
Sistem untuk bekerja dengan kesalahan klien terlihat seperti ini:
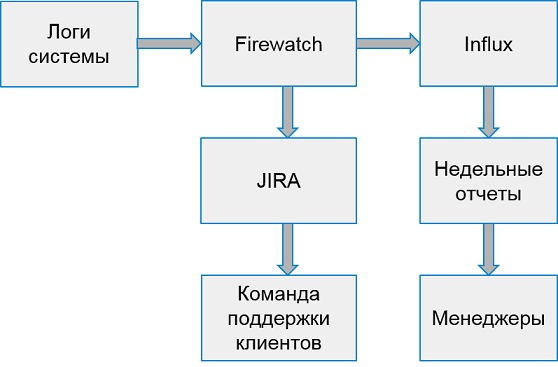
Sekali seminggu kami mengumpulkan laporan dari 10 aplikasi terburuk teratas dengan jumlah kesalahan.
Jangan ditangkap, tapi peringatkan
Jadi, kami belajar cara menemukan kesalahan dalam sistem produksi, belajar cara bekerja dengan kesalahan server dan kesalahan klien. Segalanya tampak baik-baik saja, tapi ...
Namun faktanya, kami terlambat merespons - bug sudah memengaruhi pengguna!
Mengapa tidak mencoba mencari kesalahan lebih awal?
Tentu saja, akan sangat menyenangkan untuk menemukan semuanya di lingkungan pengujian. Tetapi lingkungan pengujian adalah ruang white noise. Mereka sedang dalam pengembangan aktif, setiap hari beberapa versi server yang berbeda bekerja. Menangkap kesalahan secara terpusat pada mereka terlalu dini. Ada terlalu banyak kesalahan di dalamnya, terlalu sering semuanya berubah.
Namun, perusahaan memiliki lingkungan khusus di mana semua rakitan stabil terintegrasi untuk memeriksa kinerja, regresi manual terpusat dan pengujian ketersediaan tinggi. Sebagai aturan, lingkungan seperti itu masih belum cukup stabil. Namun, ada tim yang tertarik untuk memecahkan masalah dengan lingkungan ini.
Tetapi ada satu kendala lagi - Hadoop tidak mengumpulkan data dari lingkungan ini! Kami tidak dapat menggunakan metode yang sama untuk mendeteksi kesalahan, kami perlu mencari sumber data yang berbeda.
Setelah pencarian singkat, kami memutuskan untuk memproses streaming statistik, membaca data dari antrian di mana layanan kami menulis untuk ditransfer ke Hadoop. Itu sudah cukup untuk mengakumulasi kesalahan unik dan memprosesnya dalam batch, misalnya, setiap 30 menit sekali. Sangat mudah untuk membuat sistem antrian yang mengirimkan data - yang tersisa hanyalah memperbaiki kwitansi dan pemrosesan.
Kami mulai mengamati bagaimana kesalahan yang ditemukan berperilaku setelah deteksi. Ternyata sebagian besar kesalahan yang ditemukan dan tidak diperbaiki muncul nanti dalam produksi. Jadi, kami menemukannya dengan benar.
Jadi, kami membangun prototipe sistem, institusi, dan kesalahan pelacakan. Sudah dalam bentuk saat ini, memungkinkan Anda untuk meningkatkan kualitas sistem, pemberitahuan dan memperbaiki kesalahan sebelum pengguna mengetahuinya. Jika sebelumnya kami memproses puluhan ribu permintaan yang salah per minggu, sekarang hanya 2-3 ribu. Dan kami memperbaikinya lebih cepat.
Apa selanjutnya
Tentu saja, kami tidak akan berhenti di situ dan akan terus meningkatkan sistem pencarian dan pelacakan kesalahan. Kami memiliki rencana:
- Analisis lebih banyak kesalahan API.
- Integrasi dengan tes fungsional.
- Fitur tambahan untuk menyelidiki insiden di sistem kami.
Tetapi lebih banyak tentang hal itu lain kali.