Decoding dari laporan "Implementasi khas pemantauan" oleh Nikolay Sivko.
Nama saya Nikolai Sivko. Saya juga melakukan pemantauan. Okmeter adalah 5 pemantauan yang saya lakukan. Saya memutuskan bahwa saya akan menyelamatkan semua orang dari neraka pengawasan dan kami akan menyelamatkan seseorang dari penderitaan ini. Saya selalu berusaha untuk tidak mengiklankan okmeter dalam presentasi saya. Secara alami, gambar akan berasal dari sana. Tetapi ide dari apa yang ingin saya sampaikan adalah bahwa kami melakukan pemantauan pendekatan yang sedikit berbeda dari yang biasanya dilakukan semua orang. Kami banyak berbicara tentang ini. Ketika kami mencoba meyakinkan setiap orang dalam hal ini, pada akhirnya ia menjadi yakin. Saya ingin berbicara tentang pendekatan kami secara tepat sehingga jika Anda melakukan pemantauan sendiri, sehingga Anda menghindari menyapu kami.

Singkatnya tentang Okmeter. Kami melakukan hal yang sama seperti Anda, tetapi ada semua jenis keripik. Keripik:
- merinci;
- sejumlah besar pemicu pra-konfigurasi yang didasarkan pada masalah pelanggan kami;
- Konfigurasi otomatis

Pelanggan tipikal mendatangi kami. Dia memiliki dua tugas:
1) untuk memahami bahwa semuanya rusak karena pemantauan, ketika tidak ada sama sekali.
2) cepat memperbaikinya.
Dia datang untuk memantau jawaban dari apa yang terjadi padanya.
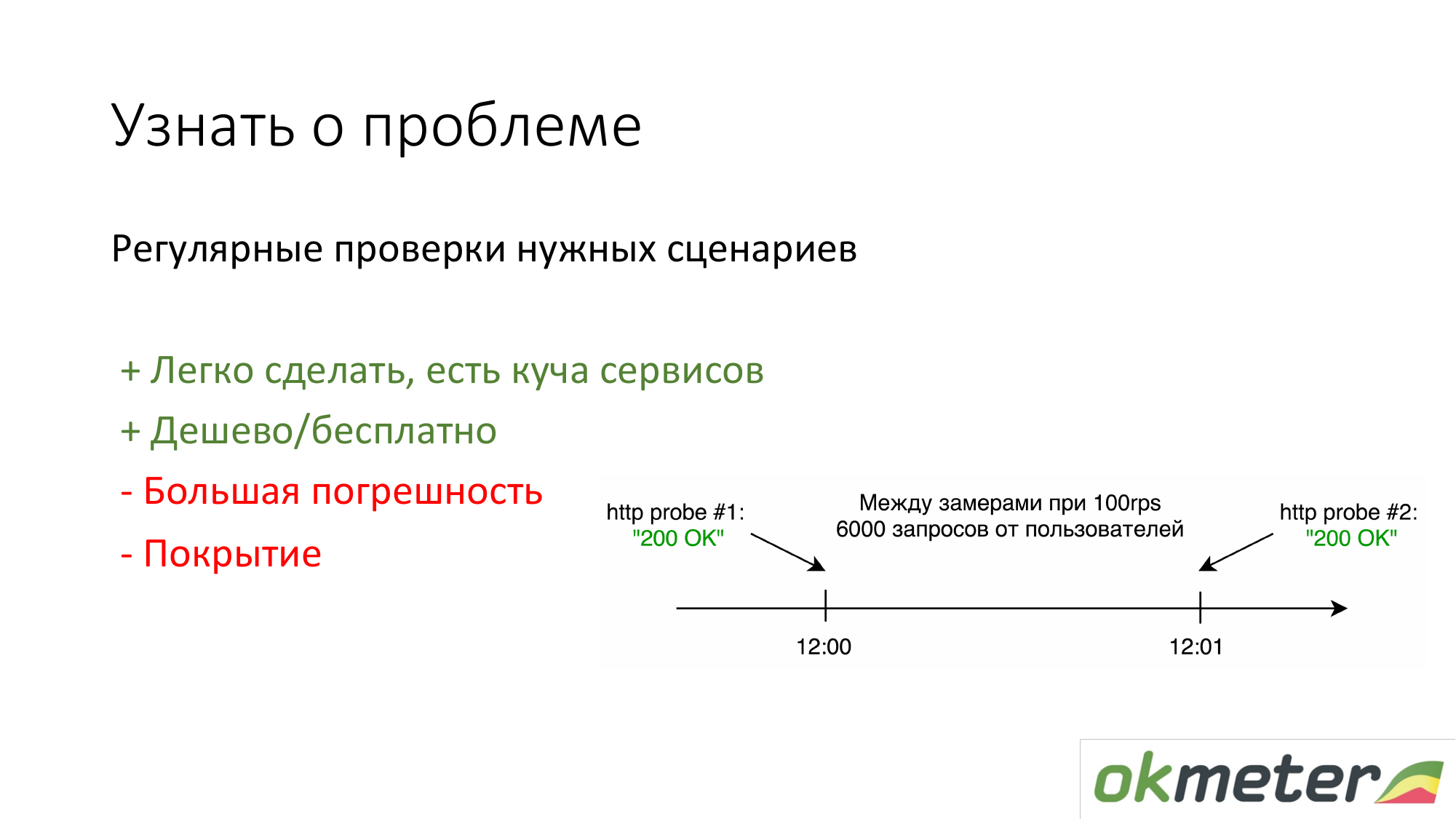
Hal pertama yang dilakukan orang yang tidak melakukan apa pun adalah memasang https://www.pingdom.com/ dan layanan lainnya untuk verifikasi. Keuntungan dari solusi ini adalah dapat dilakukan dalam 5 menit. Anda tidak akan lagi belajar tentang masalah dari panggilan pelanggan. Ada masalah dengan akurasi sehingga mereka melewatkan masalah. Tetapi untuk situs sederhana, ini sudah cukup.

Hal kedua yang kami anjurkan adalah menghitung dengan log sesuai dengan statistik pengguna nyata. Itu adalah berapa banyak pengguna tertentu mendapat kesalahan 5xx. Berapa waktu respons oleh pengguna. Ada kerugian, tetapi secara umum, hal seperti itu berhasil.

Tentang nginx: kami membuatnya sehingga setiap klien yang datang segera menempatkan agen di frontend dan semuanya diambil secara otomatis olehnya, itu mulai parsing, kesalahan mulai muncul, dan sebagainya. Dia hampir tidak memiliki apa pun untuk dikonfigurasikan.

Tetapi kebanyakan klien tidak memiliki pengatur waktu dalam log nginx standar. Ini 90 persen pelanggan tidak ingin tahu waktu respons situs mereka. Kita dihadapkan dengan ini sepanjang waktu. Perlu untuk memperluas log nginx. Kemudian di luar kotak kita secara otomatis mulai menunjukkan histogram di luar kotak. Ini mungkin merupakan aspek penting dari fakta bahwa waktu harus diukur.

Apa yang kita tarik dari sana? Dalam praktiknya, kami mengambil metrik dalam dimensi seperti itu. Ini bukan metrik datar. Metrik disebut index.request.rate - jumlah kueri per detik. Itu dirinci oleh:
- host tempat Anda menghapus log;
- log dari mana data ini diambil;
- http dengan metode;
- status http;
- status cache.
Ini BUKAN setiap URL spesifik dengan semua argumen. Kami tidak ingin menghapus 100.000 metrik dari log.

Kami ingin mengambil 1.000 metrik. Karena itu, kami mencoba untuk menormalkan URL, jika memungkinkan. Ambil URL teratas. Dan untuk URL yang bermakna, kami menampilkan grafik batang terpisah, secara terpisah 5xx.

Berikut adalah contoh bagaimana metrik sederhana ini berubah menjadi grafik yang dapat digunakan. Ini adalah DSL kami di atas. Saya mencoba DSL ini untuk menjelaskan perkiraan logika. Kami mengambil semua permintaan nginx per detik dan meletakkannya di semua mesin yang kami miliki. Dapatkan pengetahuan tentang bagaimana kami menyeimbangkannya, seberapa banyak kami memiliki RPS total (permintaan per detik, permintaan per detik).

Di sisi lain, kita dapat memfilter metrik ini dan hanya menampilkan 4xx. Pada grafik 4xx, mereka dapat ditata sesuai dengan status yang nyata. Saya ingatkan Anda bahwa ini adalah metrik yang sama.

Pada grafik, Anda dapat menampilkan 4xx dengan URL. Ini adalah metrik yang sama.

Kami juga memotret histogram dari log. Histogram adalah metrik response_time.histrogram, yang sebenarnya adalah RPS dengan parameter level tambahan. Ini hanya batas waktu untuk menerima permintaan.
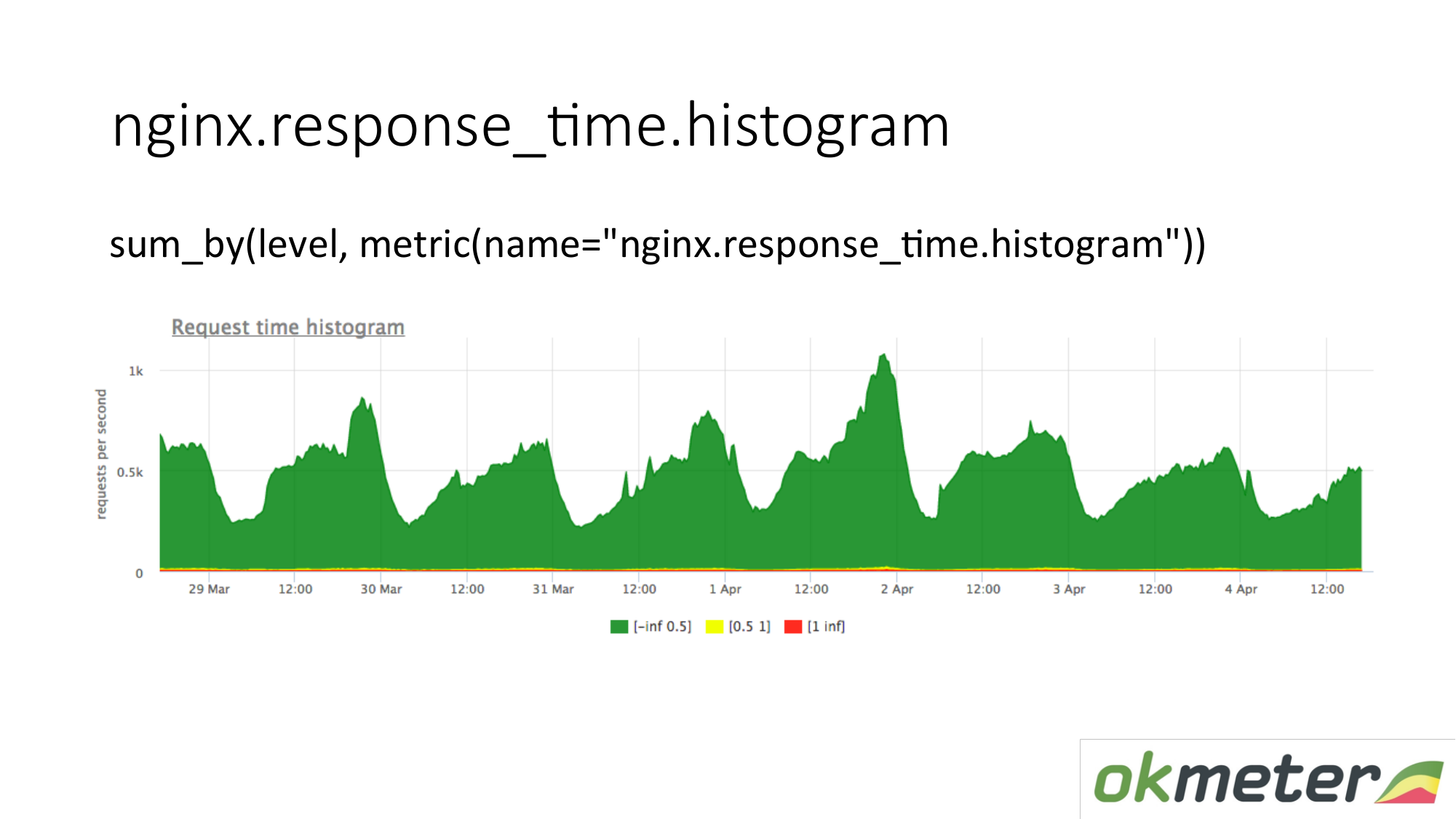
Kami menarik permintaan: merangkum seluruh histogram dan mengurutkannya ke dalam level:
- Permintaan lambat
- permintaan cepat;
- permintaan rata-rata;
Kami memiliki gambar yang telah disimpulkan oleh server. Metriknya sama. Makna fisiknya bisa dimengerti. Tapi kami memanfaatkannya dengan cara yang sangat berbeda.
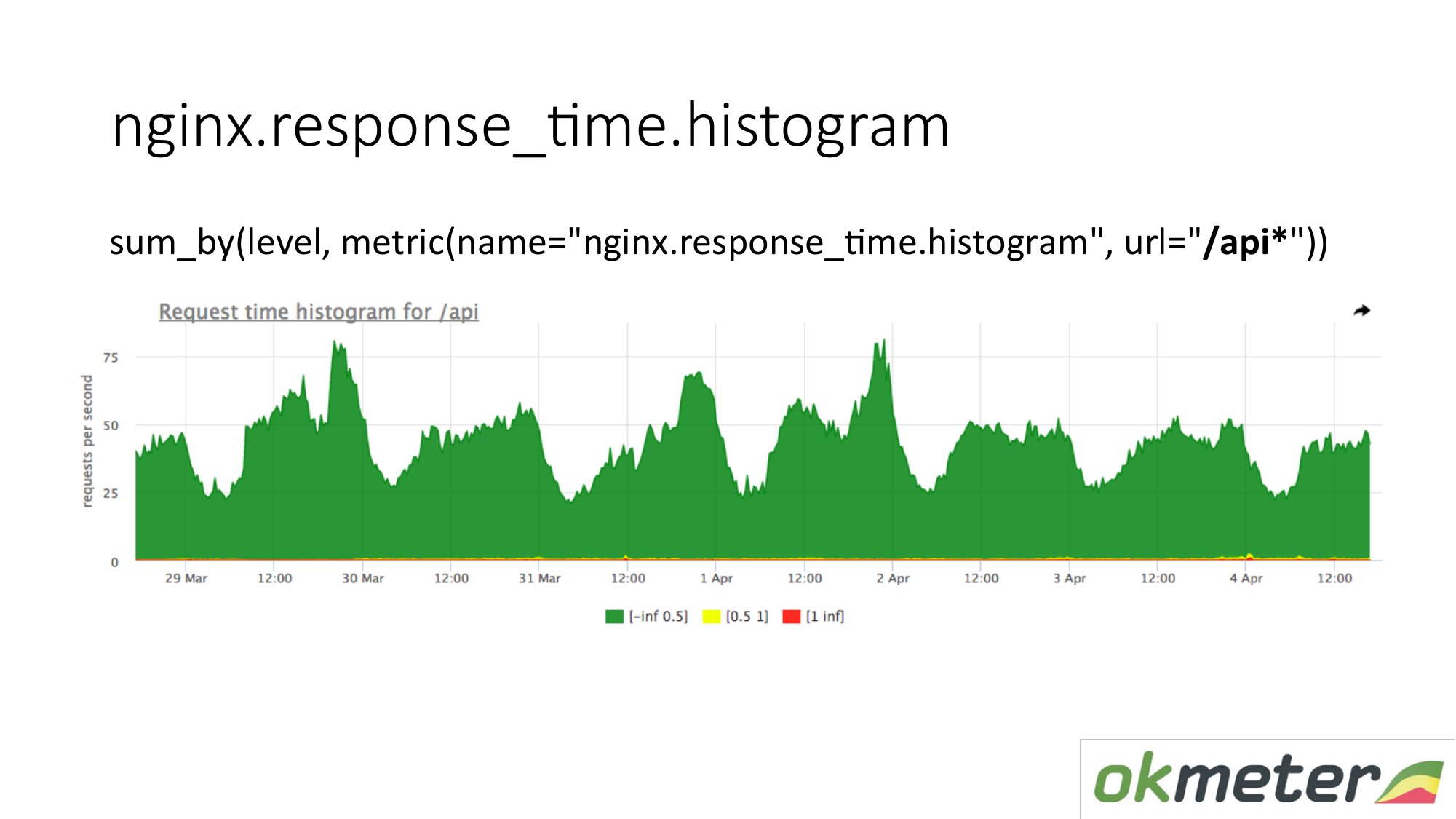
Pada bagan, Anda dapat menampilkan histogram hanya dengan URL dimulai dengan "/ api". Jadi kita melihat histogram secara terpisah. Kami melihat seberapa banyak saat ini. Kami melihat berapa banyak RPS yang ada di URL "/ api". Metrik yang sama, tetapi aplikasi yang berbeda.

Beberapa kata tentang timing di nginx. Ada request_time, yang mencakup waktu dari awal permintaan hingga transfer byte terakhir ke soket ke klien. Dan ada upstream_response_time. Mereka perlu diukur keduanya. Jika kami hanya menghapus request_time, maka di sana Anda akan melihat penundaan karena masalah konektivitas klien dengan server Anda, Anda akan melihat penundaan di sana jika kami memiliki permintaan batas c dikonfigurasi dan klien dalam kamar mandi. Anda tidak akan mengerti apakah Anda perlu memperbaiki server atau menelepon hoster. Karenanya, kami menghapus keduanya dan kira-kira jelas apa yang terjadi.

Dengan tugas memahami apakah situs tersebut berfungsi atau tidak, saya percaya bahwa kami memiliki lebih atau kurang mengatasinya. Ada kesalahan. Ada ketidakakuratan. Prinsip-prinsip umum adalah sebagai berikut.
Sekarang tentang pemantauan arsitektur multi-tier. Karena bahkan toko online paling sederhana memiliki paling tidak sebuah frontend, diikuti oleh bitrix dan base. Ini sudah banyak tautan. Poin umumnya adalah Anda perlu memotret beberapa indikator dari setiap level. Artinya, pengguna berpikir tentang frontend. Frontend sedang memikirkan backend. Backend berpikir tentang backend tetangga. Dan mereka semua berpikir tentang markas. Jadi, demi lapisan, oleh ketergantungan, kita pergi. Kami mencakup semuanya dengan semacam metrik. Kami mendapatkan sesuatu di pintu keluar.

Kenapa tidak dibatasi satu lapisan saja? Biasanya, antara lapisan adalah jaringan. Jaringan besar di bawah beban adalah zat yang sangat tidak stabil. Karena itu, semuanya terjadi di sana. Plus, pengukuran-pengukuran yang Anda buat pada lapisan mana yang bisa diletakkan. Jika Anda melakukan pengukuran pada layer "A" dan layer "B", dan jika mereka berinteraksi satu sama lain melalui jaringan, maka Anda dapat membandingkan bacaannya, temukan beberapa anomali dan inkonsistensi.

Tentang backend. Kami ingin memahami cara memonitor backend. Apa yang harus dilakukan untuk memahami dengan cepat apa yang terjadi. Saya mengingatkan Anda bahwa kami telah beralih ke tugas meminimalkan waktu henti. Dan tentang backend, kami menyarankan pemahaman secara standar:
- Berapa banyak sumber daya ini dimakan?
- Apakah kita terbentur dalam batasan apa pun?
- Apa yang terjadi dengan runtime? Misalnya, platform runtime JVM, runtime Golang, dan runtime lainnya.
- Ketika kita sudah membahas semua ini, menarik bagi kita untuk lebih dekat dengan kode kita. Kita dapat menggunakan intrumetri otomatis (statsd, * -metric), yang akan menunjukkan kepada kita semua ini. Atau instruksikan diri Anda dengan mengatur penghitung waktu, penghitung, dll.
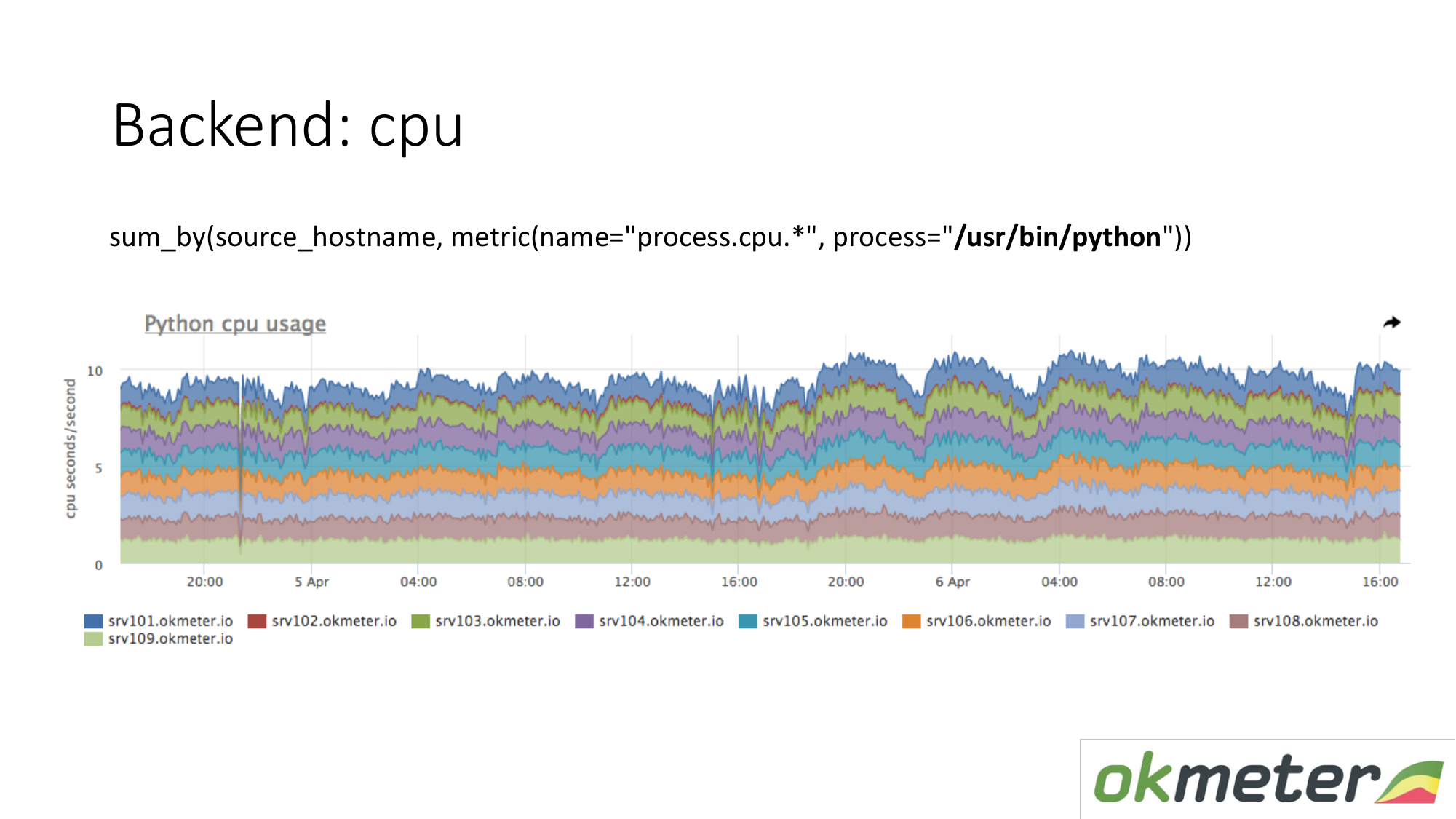
Tentang sumber daya. Agen standar kami menghapus konsumsi sumber daya oleh semua proses. Oleh karena itu, untuk backend, kita tidak perlu secara terpisah mengambil data. Kami mengambil dan melihat berapa banyak CPU mengkonsumsi proses, misalnya Python di server bertopeng. Kami menunjukkan semua server di gugus pada grafik yang sama, karena kami ingin memahami jika kami memiliki ketidakseimbangan dan jika ada sesuatu yang meledak pada mesin yang sama. Kami melihat total konsumsi dari kemarin hingga hari ini.
Hal yang sama berlaku untuk memori. Ketika kita menggambar seperti ini. Kami memilih Python RSS (RSS adalah ukuran halaman memori yang dialokasikan untuk proses oleh sistem operasi dan saat ini terletak di RAM). Jumlahkan oleh tuan rumah. Kami tidak melihat ke mana pun ingatan mengalir. Di mana-mana memori didistribusikan secara merata. Pada prinsipnya, kami menerima jawaban untuk pertanyaan kami.
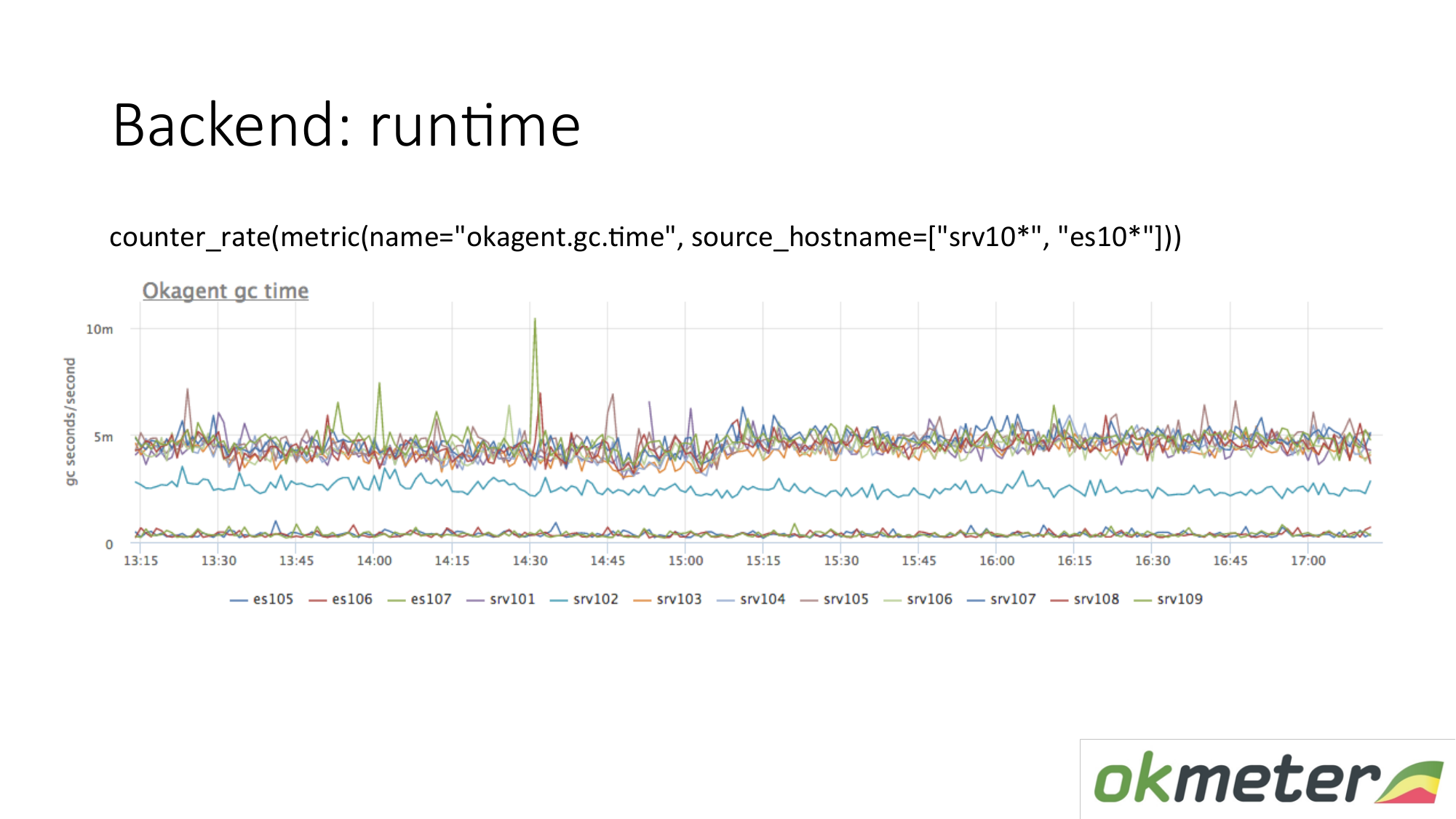
Contoh runtime. Agen kami ditulis dalam Golang. Agen Golang mengirimkan sendiri metrik runtime-nya. Ini khususnya jumlah detik yang dihabiskan oleh pengumpul sampah Golang untuk pengumpulan sampah per detik. Kami melihat di sini bahwa beberapa server memiliki metrik yang berbeda dari server lain. Kami melihat anomali. Kami mencoba menjelaskan ini.
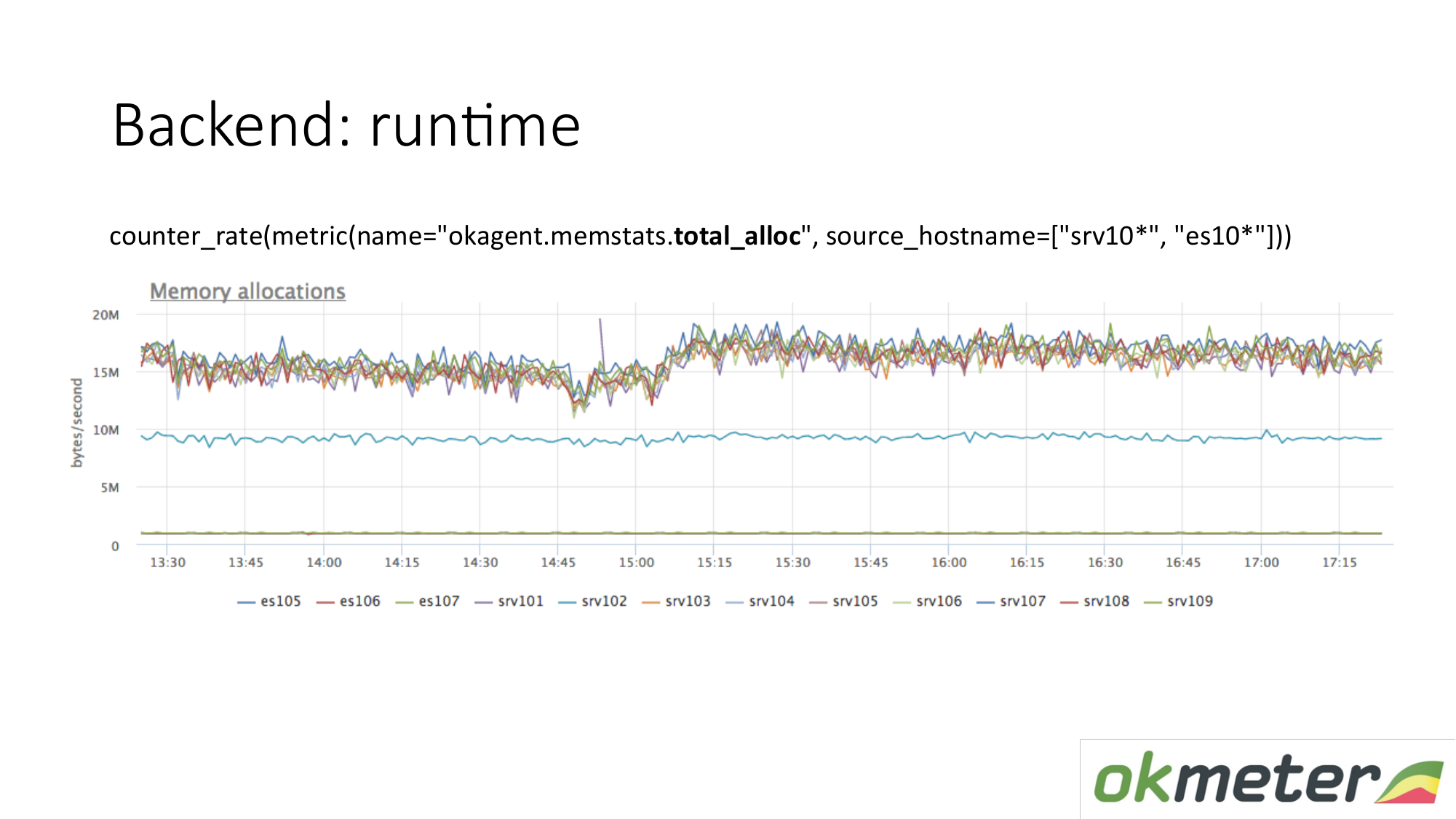
Ada lagi metrik runtime. Berapa banyak memori yang dialokasikan per unit waktu. Kami melihat bahwa agen dengan tipe yang ada di atas mengalokasikan lebih banyak memori daripada agen yang lebih rendah. Di bawah ini adalah agen dengan Pengumpul Sampah yang kurang agresif. Ini logis. Semakin banyak memori yang melewati Anda, dialokasikan, dibebaskan, semakin besar beban Kolektor Sampah. Selanjutnya, menurut metrik internal kami, kami memahami mengapa kami ingin begitu banyak memori pada mesin-mesin itu dan lebih sedikit pada mesin-mesin ini.
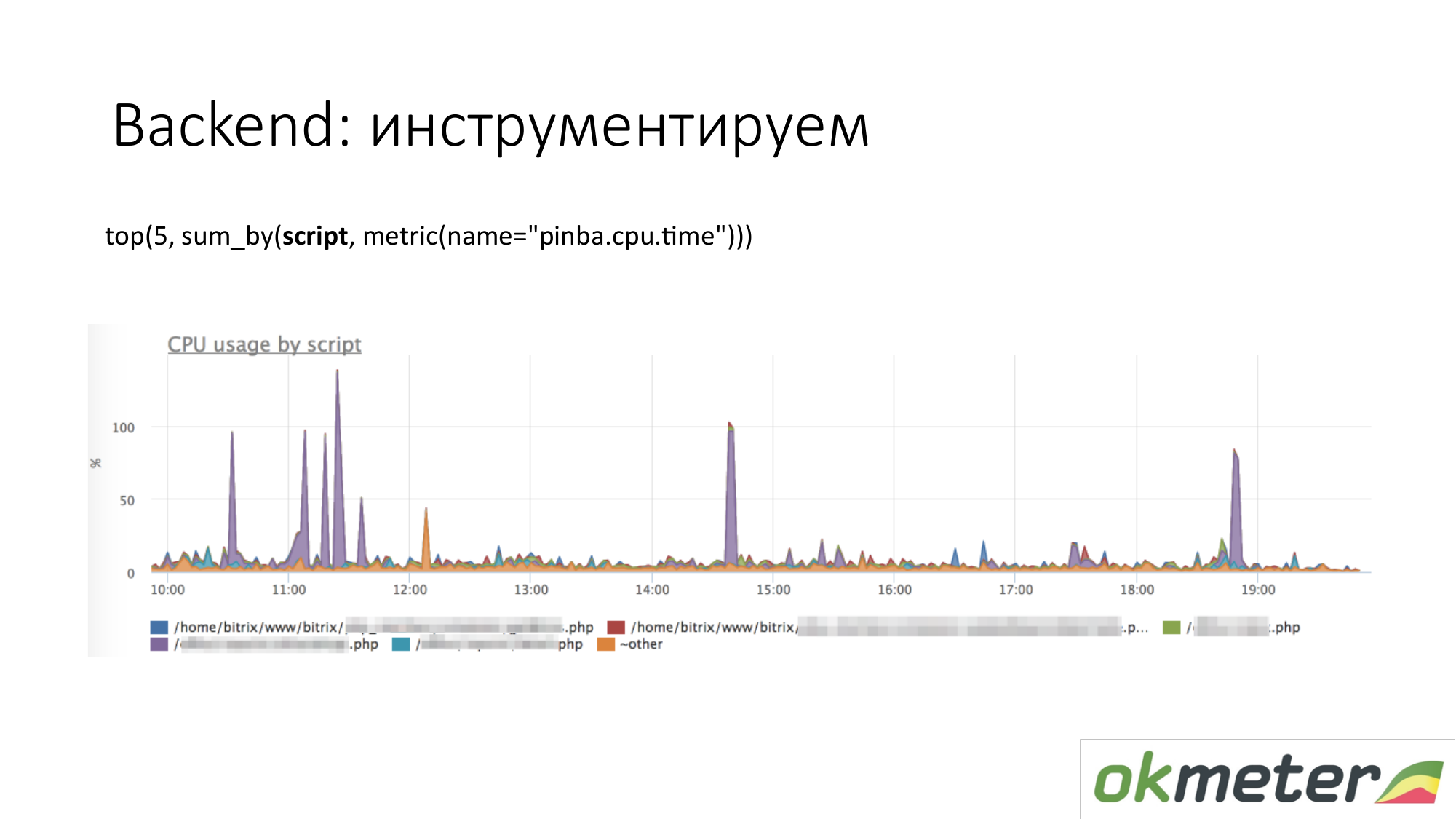
Ketika kita berbicara tentang instrumentasi, segala macam alat seperti http://pinba.org/ untuk php datang. Pinba adalah ekstensi untuk php dari Badoo, yang Anda pasang dan sambungkan ke php. Ini memungkinkan Anda untuk segera menghapus dan mengirim protobuf melalui UDP. Mereka memiliki server pinba. Tapi kami membuat server Pinba tertanam di agen. PHP mengirimkan kepada dirinya sendiri berapa banyak menghabiskan CPU dan memori untuk skrip tersebut, berapa banyak lalu lintas yang diberikan oleh skrip tersebut, dan sebagainya. Berikut ini adalah contoh dengan Pinba. Kami menampilkan 5 skrip teratas tentang konsumsi CPU. Kami melihat outlier violet yang merupakan titik tercoreng dari PHP. Kami akan memperbaiki titik lebur PHP atau untuk memahami mengapa itu memakan CPU. Kami telah mempersempit ruang lingkup masalah sehingga kami memahami langkah-langkah berikut. Kami pergi untuk melihat kode dan memperbaikinya.

Hal yang sama berlaku untuk lalu lintas. Kami melihat 5 skrip lalu lintas teratas. Jika ini penting bagi kami, maka kami pergi dan mengerti.

Ini adalah bagan tentang alat internal kami. Ketika kami mengatur timer melalui statsd dan mengukur metrik. Kami membuatnya sehingga jumlah total waktu yang dihabiskan dalam CPU atau untuk mengantisipasi beberapa sumber daya disusun sesuai dengan handler yang kami proses saat ini, dan menurut tahapan penting dari kode Anda: menunggu cassander, menunggu elasticsearch. Bagan menunjukkan 5 tahapan teratas untuk penangan / metric / query. Pada grafik, Anda dapat menampilkan 5 penangan teratas untuk konsumsi CPU, jadi apa yang terjadi di dalamnya. Sudah jelas apa yang harus diperbaiki.
Tentang backend Anda bisa masuk lebih dalam. Ada hal-hal yang dilakukan penelusuran. Artinya, Anda dapat melihat permintaan pengguna khusus ini dengan cookie begitu-dan-begitu dan IP begitu-dan-begitu menghasilkan begitu banyak permintaan ke database, mereka menunggu begitu lama. Kami tidak dapat melacak. Kami tidak melacak. Kami masih percaya bahwa kami tidak melakukan aplikasi dan pemantauan kinerja.

Tentang database. Hal yang sama. Database adalah proses yang sama. Dia mengkonsumsi sumber daya. Jika pangkalan sangat sensitif terhadap latensi, maka ada fitur yang sedikit berbeda. Kami menyarankan untuk memeriksa bahwa tidak ada sumber daya yang lebih sedikit, tidak ada degradasi dalam sumber daya. Sangat ideal untuk memahami bahwa jika basis mulai mengkonsumsi lebih banyak daripada yang dikonsumsi, maka pahami apa yang sebenarnya telah berubah dalam kode Anda.
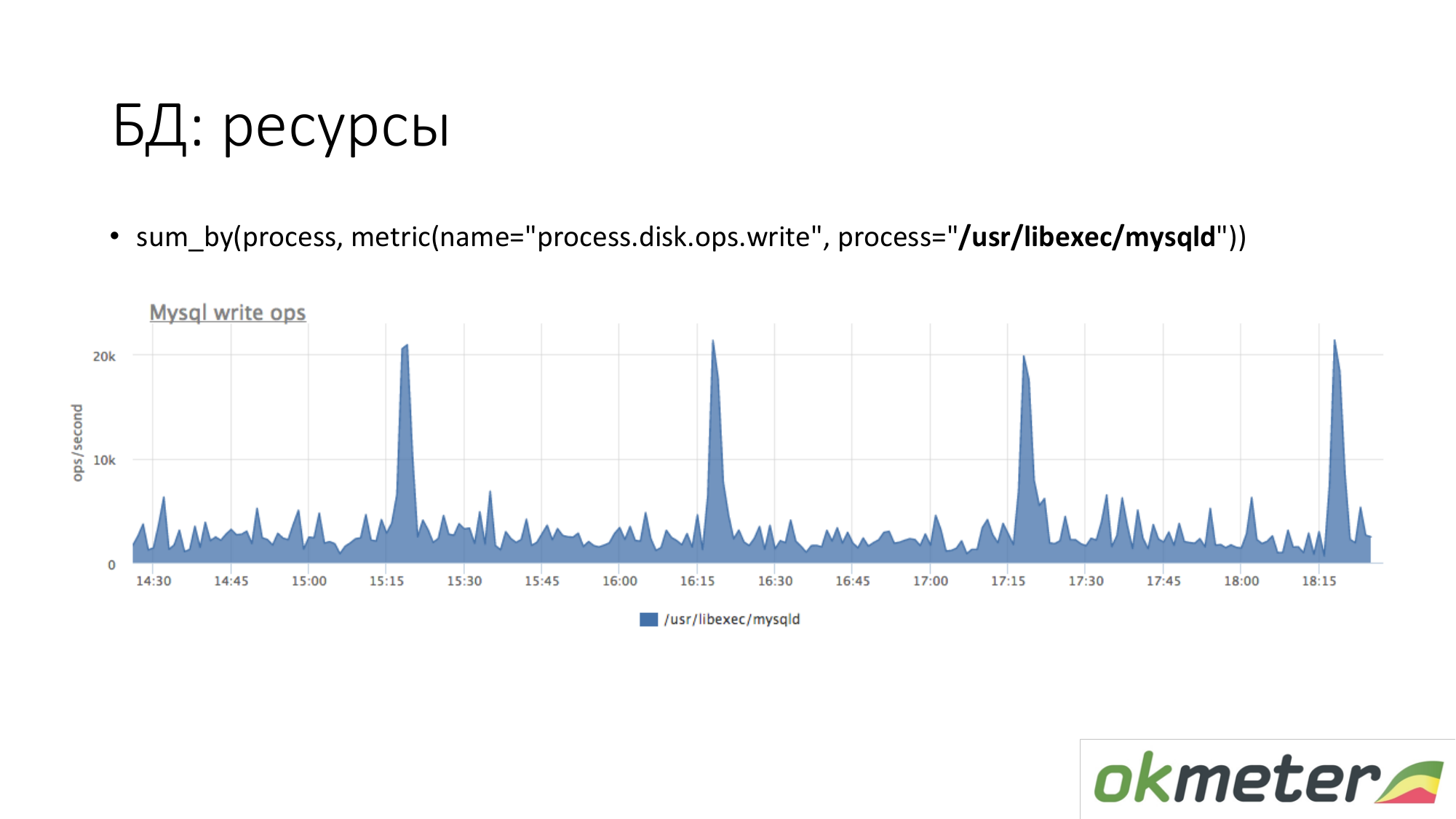
Tentang sumber daya. Dengan cara yang sama, kita melihat seberapa banyak proses MySQL dihasilkan pada disk kita. Kita melihat bahwa rata-rata ada begitu banyak, tetapi beberapa puncak terjadi. Misalnya, banyak sisipan masuk dan mulai menulis ke disk pada pukul 15.15, 16.15, 17.15.
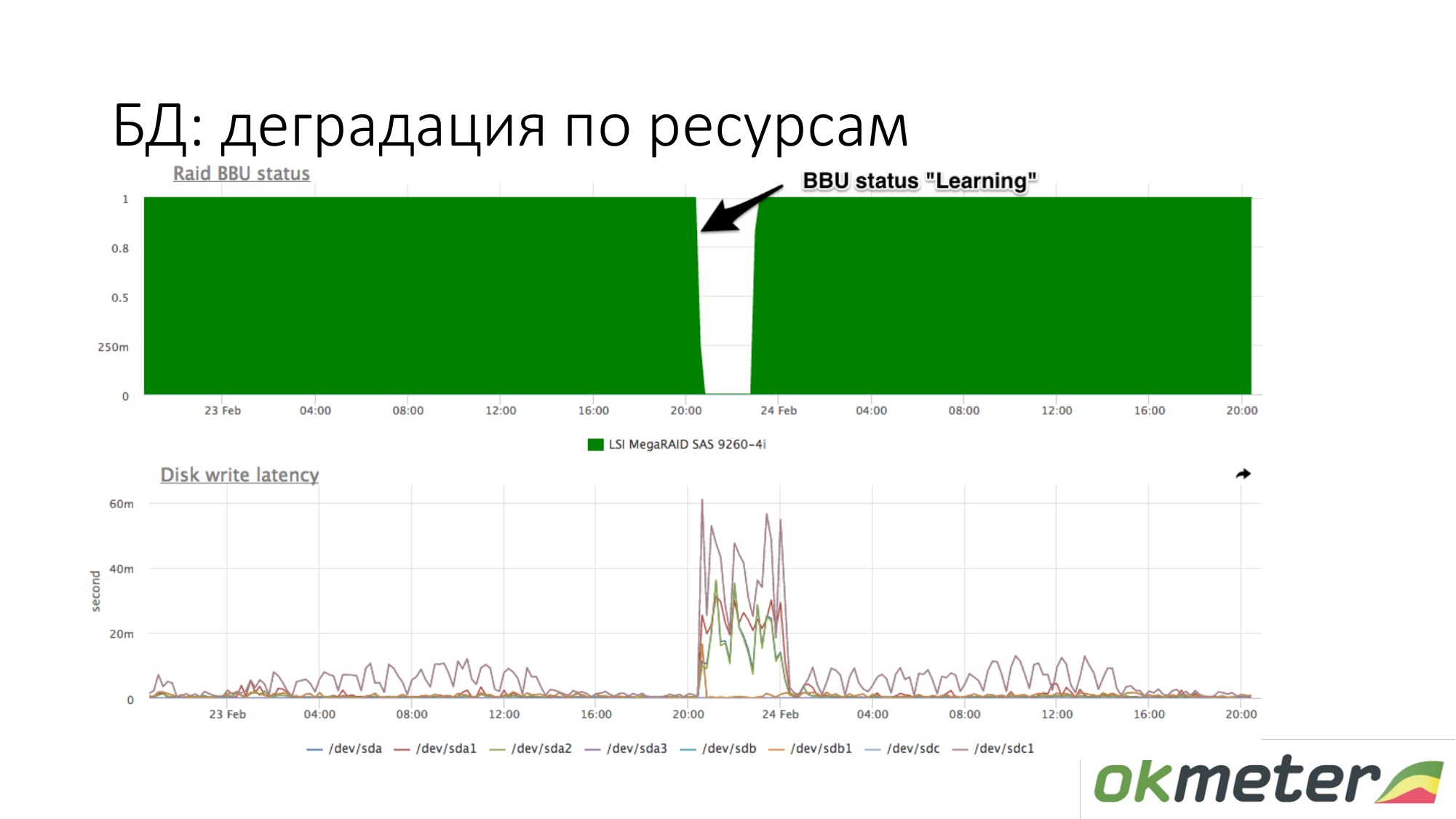
Tentang degradasi sumber daya. Misalnya, baterai RAID telah masuk ke mode pemeliharaan. Dia berhenti menjadi pengontrol seperti baterai hidup. Pada titik ini, cache tulis terputus, laten disk tulis meningkat. Pada titik ini, jika basis data mulai tumpul sambil menunggu disk, dan Anda tahu secara kasar bahwa Anda memiliki latensi berbeda untuk menulis ke disk, kemudian periksa baterai dalam RAID.

Sumberdaya Sesuai Permintaan. Tidak sesederhana itu di sini. Tergantung pada pangkalan. Pangkalan tersebut harus dapat memberi tahu tentang dirinya sendiri: permintaan apa yang dihabiskan sumber daya, dll. Pemimpin dalam hal ini adalah PostgreSQL. Dia memiliki pg_stat_statements. Anda dapat memahami jenis permintaan apa yang Anda miliki menggunakan banyak CPU, baca dan tulis disk, dan lalu lintas.
Di MySQL, sejujurnya, semuanya jauh lebih buruk. Ini memiliki performance_schema. Entah bagaimana itu bekerja dari versi 5.7. Tidak seperti tampilan tunggal di PostgreSQL, performance_schema adalah tabel tampilan sistem 27 atau 23 di MySQL. Terkadang, jika Anda membuat kueri di tabel yang salah (pada tampilan yang salah), Anda bisa menghambur-hamburkan MySQL.
Redis memiliki statistik tim. Anda melihat bahwa perintah tertentu menggunakan banyak CPU, dll.
Cassandra memiliki waktu untuk menanyakan tabel tertentu. Tetapi karena cassandra dirancang sehingga satu jenis kueri dibuat ke tabel, ini sudah cukup untuk pemantauan.
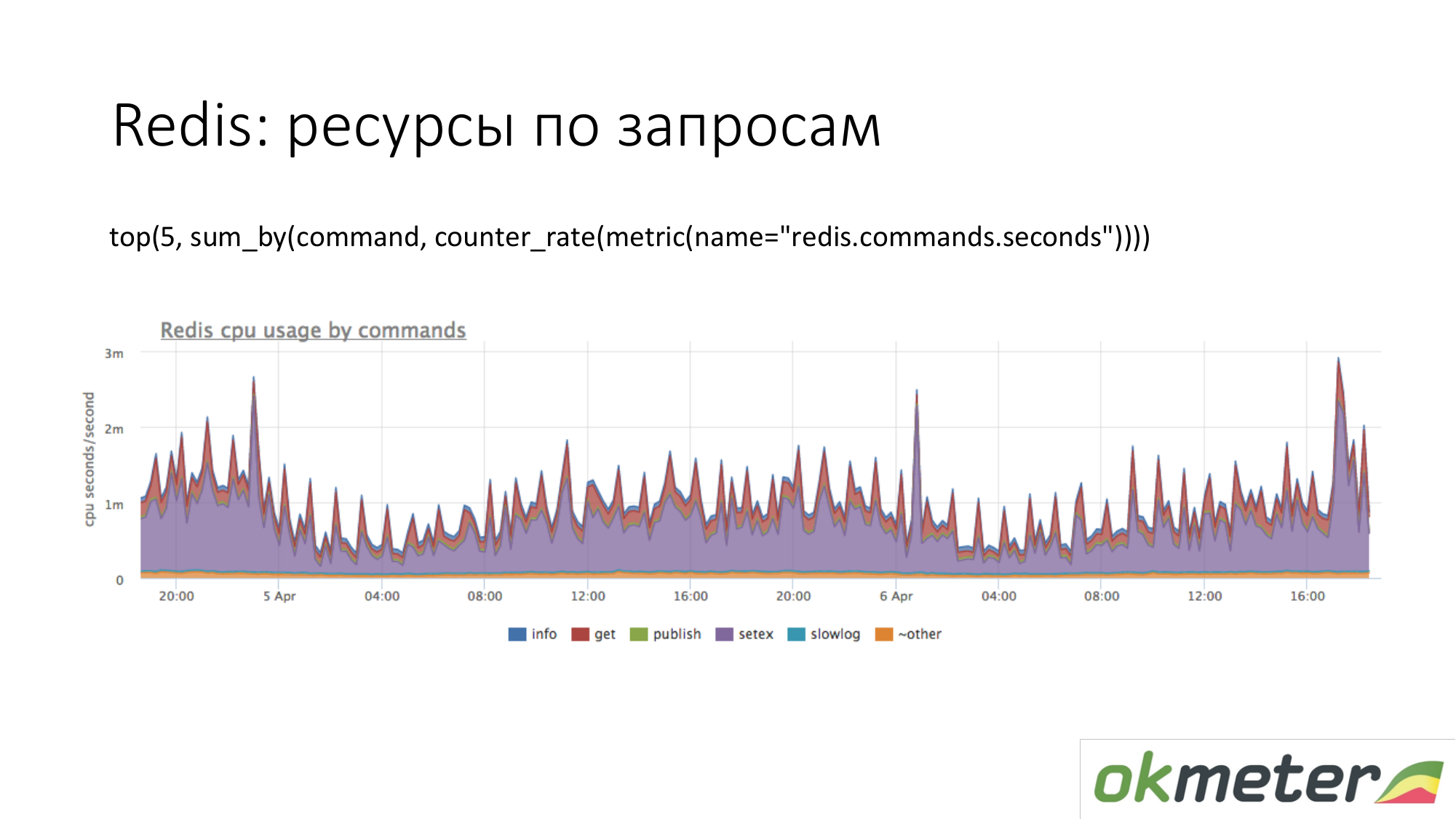
Ini Redis. Kami melihat bahwa ungu menggunakan banyak CPU. Violet adalah setex. Setex - catatan kunci dengan instalasi TTL. Jika ini penting bagi kami, mari kita hadapi itu. Jika ini tidak penting bagi kami, kami hanya tahu kemana semua sumber daya pergi.
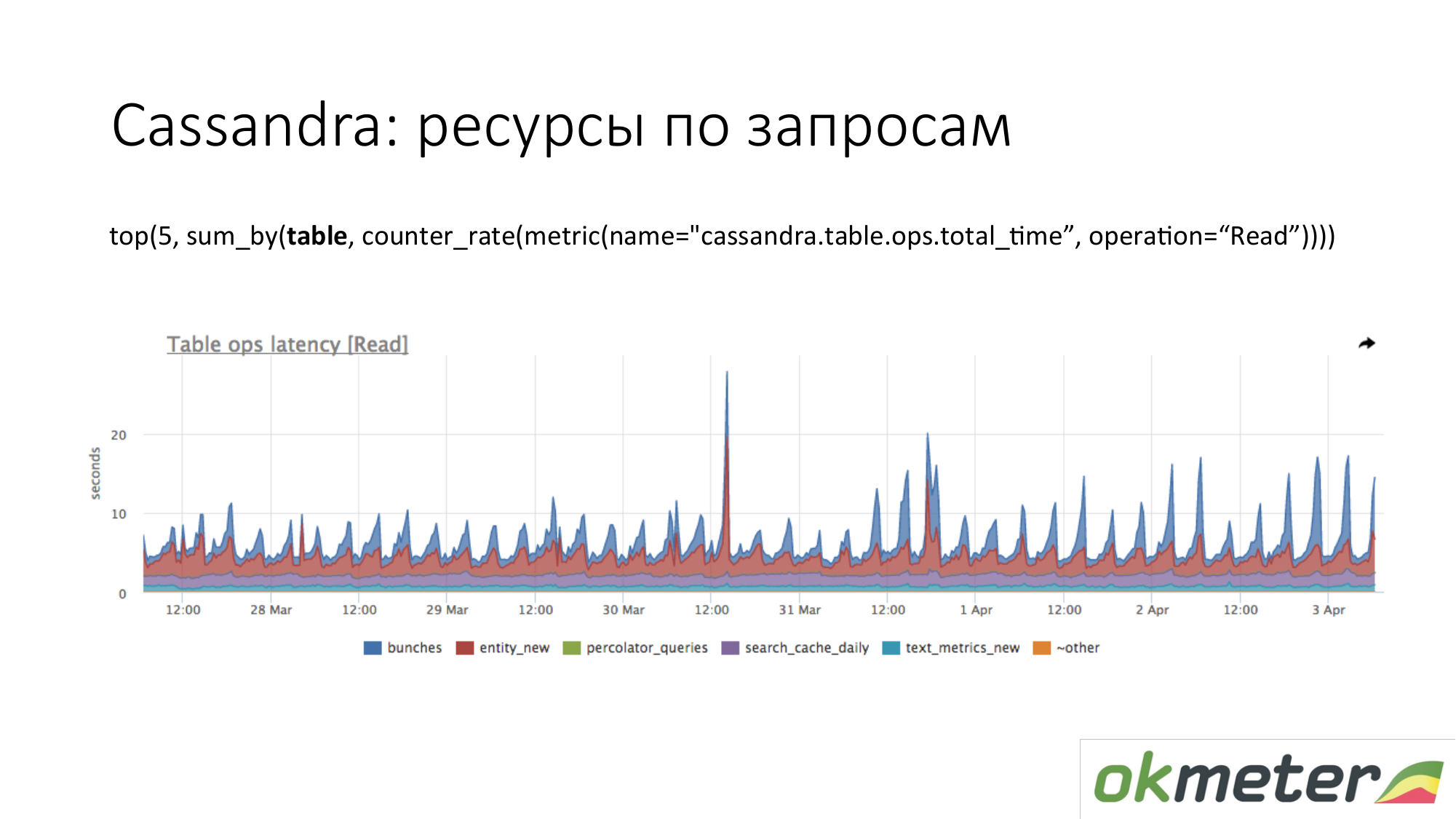
Cassandra. Kami melihat 5 tabel teratas untuk permintaan baca dengan total waktu tanggapan. Kami melihat gelombang ini. Ini adalah kueri ke tabel, dan kami secara kasar memahami bahwa kueri ke tabel ini menghasilkan satu potong kode. Cassandra bukan database SQL yang dapat digunakan untuk membuat kueri yang berbeda pada tabel. Cassandra menjadi semakin celaka.

Beberapa kata tentang alur kerja berfungsi dengan insiden. Seperti yang saya lihat.
Tentang waspada. Pandangan kami tentang alur kerja kejadian berbeda dari apa yang secara umum diterima.

Sangat kritis. Kami memberi tahu Anda melalui SMS dan semua saluran komunikasi real-time.
Severy Info adalah bola lampu yang dapat membantu Anda dengan sesuatu ketika bekerja dengan insiden. Info tidak diberitahukan di mana pun. Info hanya hang dan memberitahu Anda bahwa ada sesuatu yang terjadi.
Severy Warning adalah sesuatu yang bisa diberitahukan, mungkin juga tidak.

Contoh kritis.
Situs tidak berfungsi sama sekali. Misalnya, 5xx 100% atau waktu respons meningkat dan pengguna mulai pergi.
Kesalahan logika bisnis. Apa yang kritis. Penting untuk mengukur uang per detik. Uang per detik adalah sumber data yang bagus untuk Critical. Misalnya jumlah pesanan, promosi iklan dan lainnya.

Alur kerja dengan Critical sedemikian sehingga insiden ini tidak dapat ditunda. Anda tidak dapat mengklik OK dan pulang. Jika Critical datang kepada Anda dan Anda naik kereta bawah tanah, maka Anda harus keluar dari kereta bawah tanah, pergi keluar, mengambil bangku dan mulai memperbaiki. Kalau tidak, itu tidak kritis. Dari pertimbangan ini, kami membangun keparahan yang tersisa untuk atribut residual.

Peringatan. Contoh peringatan.
- Ruang disk habis.
- Layanan internal berfungsi untuk waktu yang lama, tetapi jika Anda tidak memiliki Kritis, berarti Anda tetap bersyarat.
- Banyak kesalahan pada antarmuka jaringan.
- Yang paling kontroversial adalah server tidak tersedia. Bahkan, jika Anda memiliki lebih dari satu server dan server tidak tersedia, ini adalah Peringatan. Jika Anda tidak memiliki 1 backend dari 100, maka itu bodoh untuk bangun dari SMS dan Anda akan mendapatkan admin gugup.
Semua Severy lainnya dirancang untuk membantu Anda menangani Critical.

Peringatan. Kami menganjurkan pendekatan ini untuk bekerja dengan Peringatan. Lebih disukai Peringatan tutup pada siang hari. Sebagian besar pelanggan kami telah menonaktifkan Pemberitahuan peringatan. Dengan demikian, mereka tidak memiliki apa yang disebut pemantauan kebutaan. Ini berarti melipat surat dalam surat tanpa membaca direktori terpisah. Klien telah menonaktifkan peringatan peringatan.
(Seperti yang saya pahami, pemantauan murni adalah peringatan dan pemicu yang tidak perlu ditambahkan ke pengecualian - perhatikan oleh penulis pos)
Jika Anda menggunakan teknik pemantauan murni, jika Anda memiliki 5 Peringatan baru, maka Anda dapat memperbaikinya dalam mode senyap. Mereka tidak punya waktu untuk memperbaikinya hari ini, mereka menunda sampai besok, jika tidak kritis. Jika Peringatan menyala dan padam sendiri, maka ini harus diputar dalam pemantauan sehingga sekali lagi Anda tidak repot. Maka Anda akan lebih toleran terhadap mereka dan, dengan demikian, hidup akan meningkat.

Contoh info. Dapat diperdebatkan bahwa banyak Kritis memiliki pemanfaatan CPU yang tinggi. Bahkan, jika tidak ada yang mempengaruhi, maka Anda dapat mengabaikan notifikasi ini.

Peringatan (mungkin saya melihat Info - catatan oleh penulis posting) ini adalah lampu yang menyala ketika Anda datang untuk memperbaiki Critical. Anda melihat dua tanda Peringatan berdampingan (mungkin ada tautan Info - catatan oleh penulis posting). Mereka dapat membantu Anda dalam menyelesaikan insiden dengan Critical. Mengapa tidak jelas tentang tingginya penggunaan CPU secara terpisah dalam SMS atau surat.
Info tidak berguna juga buruk. Jika Anda mengkonfigurasinya sebagai pengecualian, maka Anda akan sangat menyukai Info.

Prinsip umum untuk desain peringatan. Peringatan harus menunjukkan alasannya. Ini sempurna. Tetapi ini sulit dicapai. Di sini kami bekerja penuh waktu untuk tugas itu dan ternyata ada beberapa keberhasilan.
Semua orang berbicara tentang perlunya kecanduan, sihir otomatis. Bahkan, jika Anda tidak menerima pemberitahuan untuk sesuatu yang tidak Anda minati, maka tidak akan ada terlalu banyak. Dalam praktik saya, statistik menunjukkan bahwa seseorang akan melihat saat kejadian kritis dengan mata mereka sekitar seratus umbi secara diagonal. Dia akan menemukan yang tepat di sana dan tidak akan berpikir bahwa ketergantungan telah menyembunyikan bola lampu yang akan membantu saya sekarang. Dalam praktiknya, ini berhasil. Yang perlu Anda lakukan adalah membersihkan peringatan yang tidak perlu.

(Di sini video dilewati - catatan oleh penulis pos)

Akan bagus untuk mengklasifikasikan downtime ini sehingga Anda dapat bekerja dengannya nanti. Misalnya, buat kesimpulan organisasi. Anda perlu memahami mengapa Anda berbohong. Kami mengusulkan untuk mengklasifikasikan / membagi ke dalam kelas-kelas berikut:
- buatan manusia
- pengaturan hoster
- datang bot
Jika Anda mengklasifikasikannya, maka semua orang akan senang.

SMS telah tiba. Apa yang kita lakukan Pertama kita jalankan untuk memperbaiki semuanya. Sejauh ini, tidak ada yang penting bagi kami, kecuali downtime berakhir. Karena kita termotivasi untuk tidak berbohong. Kemudian, ketika insiden ditutup, itu harus ditutup ke sistem pemantauan. Kami percaya bahwa insiden tersebut harus diperiksa dengan pemantauan. Jika pemantauan Anda tidak dikonfigurasi, cukup untuk memastikan bahwa masalahnya selesai. Ini harus diputar. Setelah kejadian ditutup, sebenarnya tidak ditutup. Dia menunggu saat Anda sampai ke dasar alasannya. Pemimpin mana pun, pada kenyataannya, pertama-tama perlu memastikan bahwa masalahnya tidak terulang kembali. Agar masalah tidak terulang, Anda harus sampai ke dasar alasannya. Setelah kami sampai di dasar alasan, kami memiliki data untuk mengklasifikasikannya. Kami menganalisis alasannya. Kemudian, ketika kita sampai pada dasar alasannya, kita perlu melakukannya di masa depan agar kejadian itu tidak terulang:
- dibutuhkan dua orang seperempat untuk menulis logika ini dan itu ke backend.
- perlu menempatkan lebih banyak replika.
Penting untuk memastikan bahwa kejadian yang sama tidak terjadi. Ketika Anda bekerja dalam alur kerja seperti itu melalui N iterasi, kebahagiaan menanti Anda, waktu yang baik.
Mengapa kami mengklasifikasikannya? Kami dapat mengambil statistik untuk kuartal ini dan memahami apa yang paling memberi Anda waktu henti. Kemudian kerjakan ke arah ini. Anda dapat bekerja di semua bidang tidak akan sangat efektif, terutama jika Anda memiliki sedikit sumber daya di sana.

Kami menghitung di sana kami berbaring begitu lama, misalnya 90% karena hoster. Kami menagih kami mengubah hoster ini. Jika orang mengacaukan kami, kami mengirim mereka ke kursus. , - — . . , . , .

. :
, , . , , .

: , . : , , . False Positive ( ), , . ?
: . 10- frontend , . 9 frontend nginx, 10- , warning alert . . , . . .
: . , , load avarage 4 , - load avarage 20 .
: load avarage. 100 . CPU usage Hadoop . . . . , , . PostgreSQL autovacuum, worker autovacuum . 99 . Warning . Critical . Critical 10 5 , Critical.
Pertanyaan: Pada titik apa dan bagaimana ambang ditentukan? Siapa yang melakukan ini?
Jawab: Anda datang kepada kami dan berkata: kami ingin bertanya beberapa Kritis dari proyek kami. Jika Anda menempatkan 10 5xx per detik sekarang, maka berapa banyak pemberitahuan yang akan Anda terima seminggu yang lalu.
Pertanyaan: Apa beban dari pemantauan yang baik ini?
Jawab: Rata-rata, umumnya tidak terlihat. Tetapi jika Anda mem-parsing 50.000 RPS itu akan dari 1% hingga 10% dari satu CPU. Karena kami hanya memantau, kami mengoptimalkan agen kami. Kami mengukur kinerja agen. Jika Anda tidak memiliki sumber daya untuk dipantau di server, maka Anda melakukan sesuatu yang salah. Harus selalu ada sumber daya untuk dipantau. Jika tidak, maka Anda akan sama buta dengan sentuhan untuk mengelola proyek Anda.