Topologi pusat data dan perangkat modern di dalamnya tidak lagi memungkinkan kita untuk menjadi puas secara eksklusif dengan
pemantauan papan tulis . Seiring waktu, saya membutuhkan alat yang akan menunjukkan kinerja perangkat tertentu, berdasarkan situasi nyata dengan transfer lalu lintas (dataplane) di mana saja di
jaringan Clos . Beberapa minggu yang lalu di konferensi
Next Hop , insinyur jaringan Yandex Alexander Klimenko berbagi pengalamannya dalam memecahkan masalah ini.
- Saya bekerja di departemen operasi dan pengembangan jaringan Yandex, dan kadang-kadang mereka memaksa saya untuk memecahkan beberapa masalah, bukannya menggambar awan yang indah di selebaran atau menciptakan masa depan yang cerah. Orang-orang datang dan mengatakan bahwa sesuatu tidak bekerja untuk mereka. Jika masalah ini dipantau, jika teknisi kami melihat bahwa itu tidak berhasil, maka akan lebih mudah bagi saya sendiri. Jadi setengah jam ini akan dikhususkan untuk pemantauan.

Cepat atau lambat, semua orang datang ke ide pemantauan. Artinya, pada awalnya Anda dapat mengumpulkan banding dari pengguna sendiri, mereka akan mengetuk Anda dan mengatakan bahwa ada sesuatu yang tidak berfungsi untuk mereka. Tetapi jelas bahwa sistem seperti itu tidak memiliki skala yang baik. Jika Anda memiliki lebih dari satu switch, jika Anda memiliki jaringan yang cukup besar, maka dengan opsi pemantauan ini Anda tidak bisa melangkah jauh.
Dan cepat atau lambat semua sampai pada kesimpulan bahwa perlu untuk mengumpulkan beberapa data dari peralatan. Ini adalah langkah pertama. Ini bisa berupa log, berbagai data pada SNMP, tetes, Anda dapat membangun topologi sesuai dengan LLDP, dll. Ada minus yang jelas - perangkat itu sendiri memberikan semua informasi ini kepada Anda. Mungkin tidak mengatakan apa pun, menipu Anda, dll.
Tahap logis dalam pengembangan pemantauan Anda adalah pemantauan pada host. Kita dapat mengatakan bahwa ada cabang kecil. Jika Anda beruntung - atau tidak beruntung - memiliki jaringan pada satu vendor, maka vendor tersebut dapat menawarkan kepada Anda beberapa opsi pemantauan Anda sendiri. Tapi tahun lalu di Next Hop, Dima Ershov
mengatakan bahwa pabrik kami dibuat dari dua vendor dasar dan kami tidak mampu membeli barang mewah seperti itu. Atau kita bisa, tetapi hanya sebagian.
Akhirnya, opsi terakhir, yang semua orang capai dengan perkembangan jaringan. Ini memantau host akhir. Yandex memiliki pemantauan seperti itu. Ini disebut Netmon.

Di bagian bawah slide
ada tautan dengan presentasi terperinci tentang cara kerja Netmon. Saya akan kirim secara harfiah dalam satu slide. Jika ada yang mau, silakan baca ceramah dari konferensi Netmon lain.
Netmon adalah agen yang diinstal pada hampir setiap host di jaringan. Tugas tiba di agen: untuk mengirim beberapa paket ke beberapa node jaringan. Mereka bisa sangat berbeda: UDP, TCP, ICMP. Bisa seperti cat yang berbeda, yaitu, DSCP, dan tujuan. Port sumber dan tujuan juga bisa berbeda.
Data ini dikumpulkan, diunggah ke penyimpanan terpisah, dan kami mendapatkan potongan di sini seperti yang ada di kanan pada gambar. Sepotong bisa lebih teragregasi atau kurang teragregasi, tergantung pada apa yang ingin kita lihat. Misalnya, di sini, sejauh yang saya lihat, kami memiliki sebagian dari semua konektivitas pusat data, yaitu, di antara semua pusat data kami. Kita dapat masuk lebih dalam ke dalam kotak - lihat konektivitas antara POD atau di dalam pembangunan satu pusat data; bahkan lebih dalam - di dalam POD di antara rak-rak; dan bahkan lebih dalam - bahkan di dalam rak.

Apa yang mungkin salah di sini? Penyimpangan kecil bagi mereka yang tidak menonton Hop Berikutnya tahun lalu.
Kami menggunakan 400 gigabit per ToR, dan pada saat pertama implementasi pabrik ini kami hanya memasukkan 200, karena ada tugas yang lebih penting. Tidak peduli mengapa Mereka menyalakan 200, layanan datang dan berkata: mengapa 200? Kami ingin 400! Mulai menyalakannya. Dan kebetulan bahwa bagian kedua dari pabrik, yang kami sertakan, memiliki semacam pernikahan dalam memori kartu. Akibatnya, kami menghidupkan pabrik dan melihat gambar ini:

Netmon ini, kotak merah, terbakar. Kami memahami bahwa semuanya hilang. Kami memegang kepala kami, seperti Homer, dan mencoba mendorong sesuatu dengan panik. Dan apa yang harus ditekan, apa yang harus dimatikan, kita tidak mengerti. Yaitu, Netmon menunjukkan kepada kita adanya masalah, tetapi tidak menunjukkan di mana, sebenarnya, masalahnya terletak pada jaringan.

Kita sampai pada tugas yang harus kita selesaikan. Apa yang perlu dilakukan? Tentukan dengan perangkat yang ada di jaringan ada masalah dan keluarkan dari layanan - baik secara otomatis, atau dengan kekuatan, misalnya, insinyur yang sedang bertugas.
Selain itu, kondisi awal sedemikian sehingga kami memiliki topologi yang cukup teratur, yaitu, tidak ada hubungan aneh antara putaran tingkat kedua atau antara tori. Kami memiliki sebagian besar lalu lintas - TCP, ada tempat sentral, kami telah diberitahu tentang hal itu, dan server lebih atau kurang dikelola secara terpusat. Kita bisa datang ke tempat sentral ini dan menyatakan secara wajar: kawan, kami ingin melakukannya, silakan lakukan.
Opsi apa yang telah kita pertimbangkan?

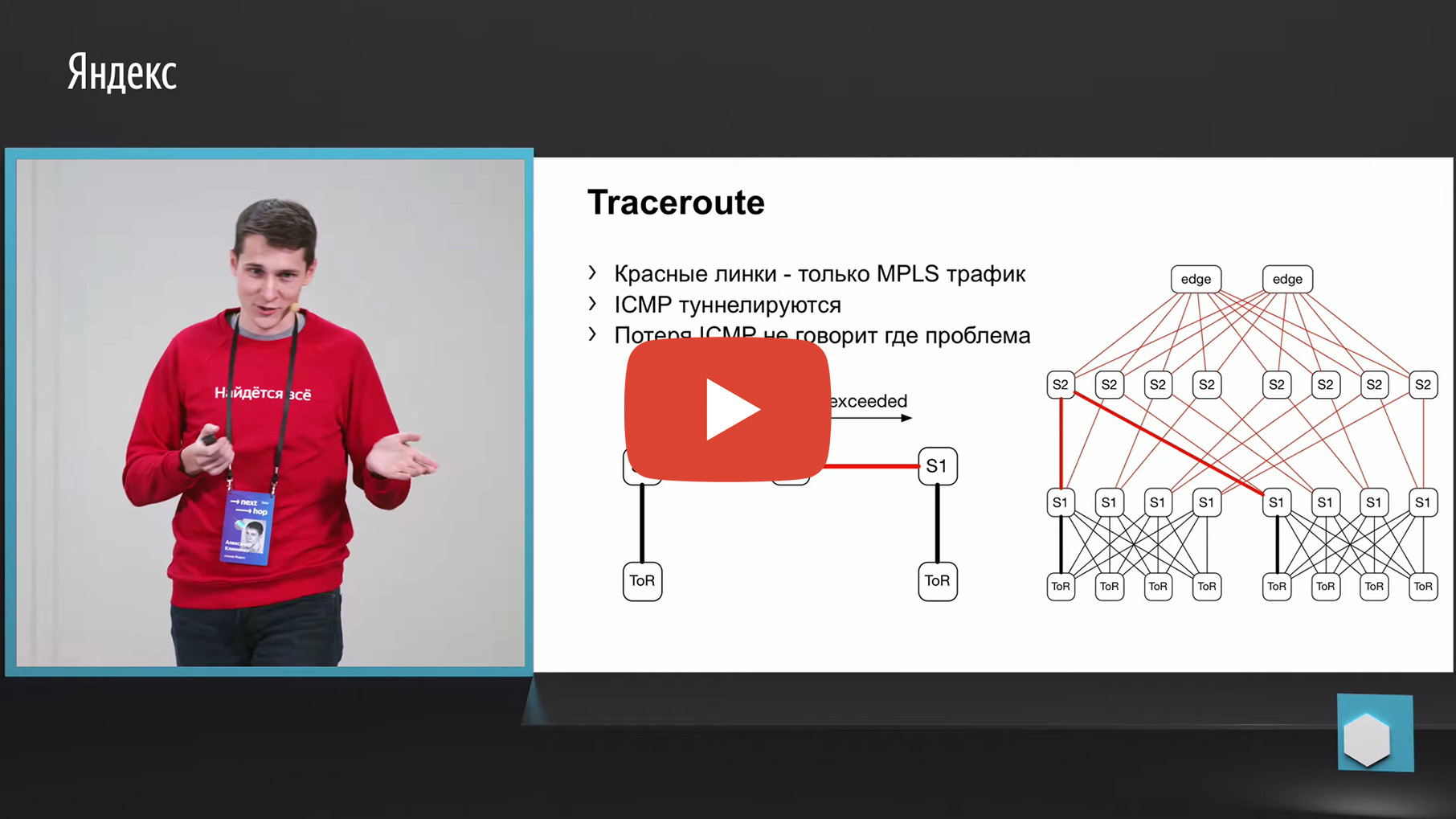
Hal pertama yang terlintas dalam pikiran adalah menelusuri. Mengapa Karena Netmon yang sama membongkar sumber dan tujuan yang gagal memasangkan ke kolektor terpisah. Oleh karena itu, kita dapat mengambil 5-tuple ini, melihatnya dan membuat jejak dengan parameter yang sama. Dan untuk mengumpulkan data tentang tautan mana atau melalui perangkat mana jejak terbanyak dilewati.
Namun sayangnya, MPLS digunakan di pabrik kami (sekarang kami bergerak berlawanan arah dengan MPLS, tetapi kami juga perlu memantau pabrik-pabrik lama, tetapi jangan membuangnya, sebenarnya). Kami memiliki MPLS di pabrik, dan masalah dengan MPLS dan tracing adalah bahwa ia perlu untuk tunnel TTL melebihi pesan ICMP, yang mendasari tracing. Setelah kehilangan pesan seperti itu dari masuk ke jalan keluar, kita bisa kehilangan pengawasan. Artinya, kita tidak akan mengerti melalui titik mana pesan ini dilewati. Ini tidak cocok untuk kami pemantauan.
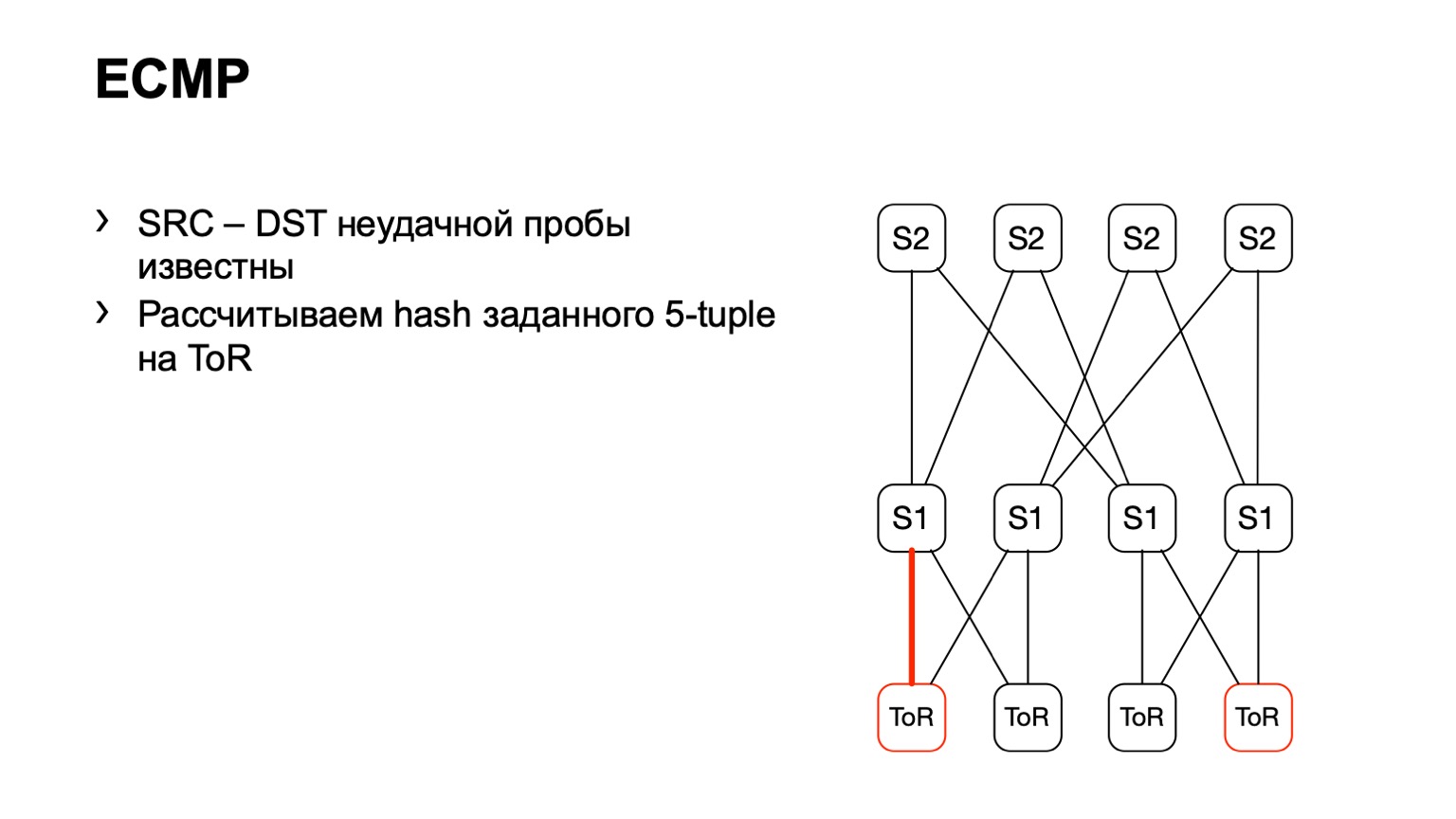
Ada opsi kedua terkait dengan ECMP. Kami mengambil pasangan sumber dan tujuan yang sama, sebagai tambahan sumber-port tujuan-port. Kita sampai pada sepotong besi, melalui API atau melalui CLI kita memberi makan sepotong besi ini ke sepotong besi, dan kita mendapatkan antarmuka output. Banyak perangkat mendukung output semacam ini.
Kami datang ke ToR, melihat bahwa ToR telah memilih tautan kiri atau kanan. Dalam hal ini, tautan kiri mengarah ke S1 kiri.
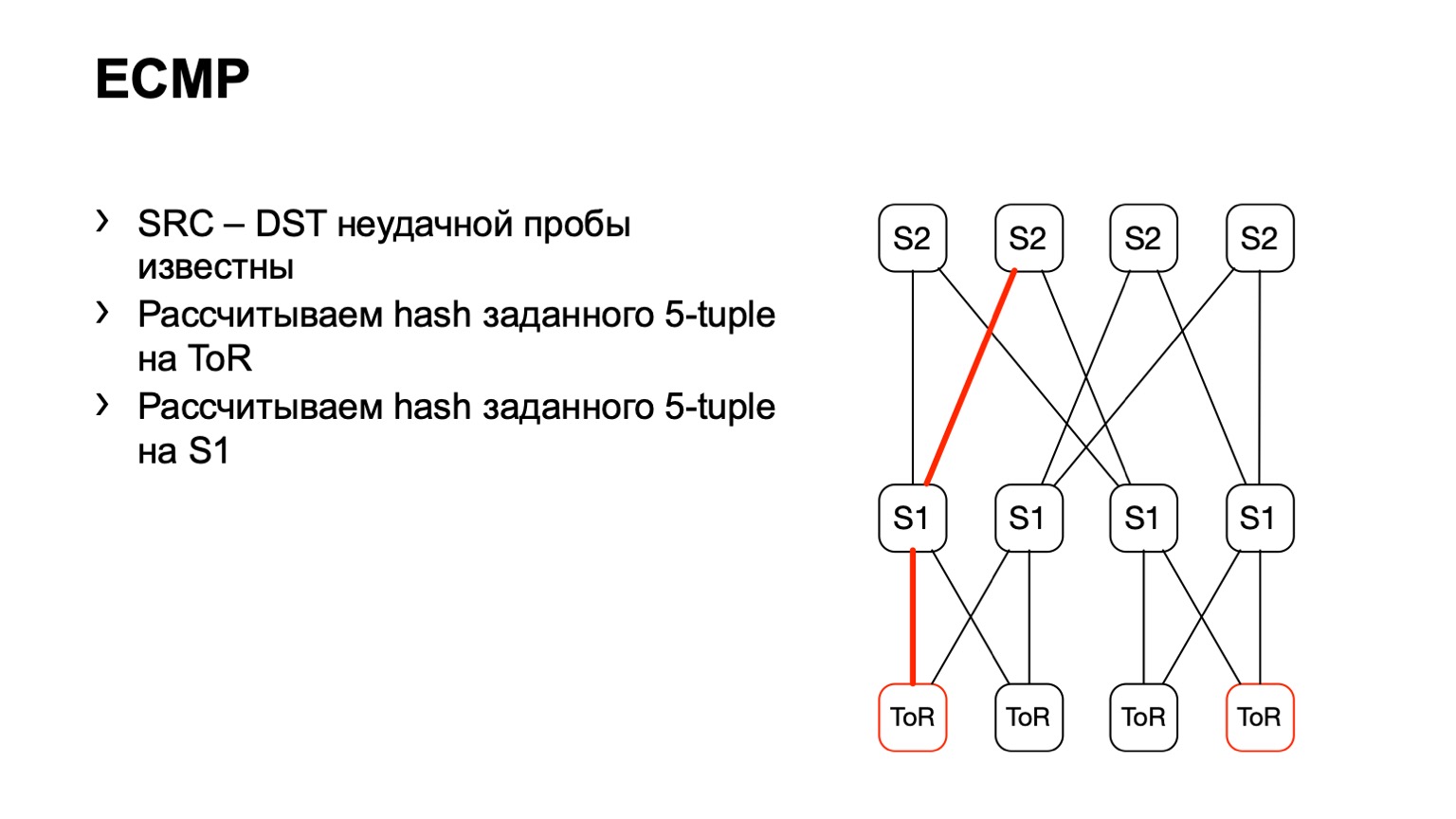
Kami datang ke S1 ini, tampak, S2 kanan, dan dengan cara ini jalur siap terbentuk.
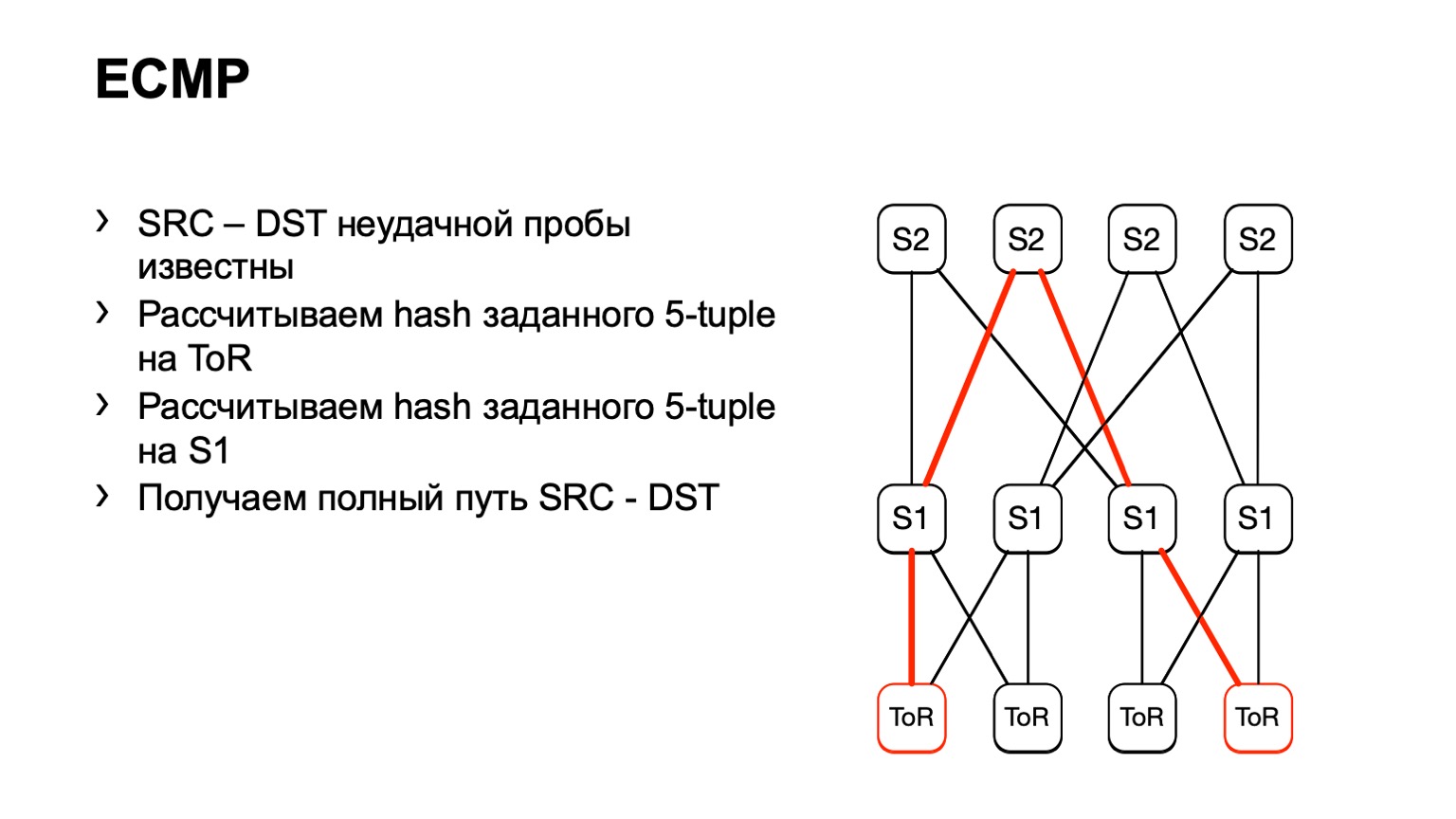
Ada beberapa kekurangannya. Pertama, tidak semua perangkat biasanya dapat menerima data input yang kami berikan ini. Hal ini disebabkan oleh fakta bahwa kami memiliki IPv6 dan MPLS, serta fakta bahwa beberapa vendor tidak menerapkannya. Kekurangan kedua dari solusi ini: kita bergantung pada apa yang akan diceritakan oleh sepotong besi itu pada kita, alih-alih melihat apa yang terjadi pada tuan rumah. Dan akhirnya, minus ketiga - selama Anda pergi dan melihat apa yang terjadi di sana, sesuatu sudah dapat berubah di jaringan dan data Anda tidak akan relevan.

Kemudian kami menemukan presentasi menarik yang dibuat oleh Facebook. Kami menyukai gagasan yang diusulkan Facebook, kami memutuskan untuk mencoba melakukan hal serupa.
Apa ide utamanya? Gunakan program eBPF pada host untuk mewarnai pengiriman ulang TCP dan kemudian menghitung jumlah paket tersebut. Sayangnya, kami tidak dapat melakukannya seperti di Facebook, kami harus menciptakan sepeda kami sendiri. Saya akan mencoba memberi tahu Anda tentang jalan rasa sakit dan penderitaan yang telah kami lalui.
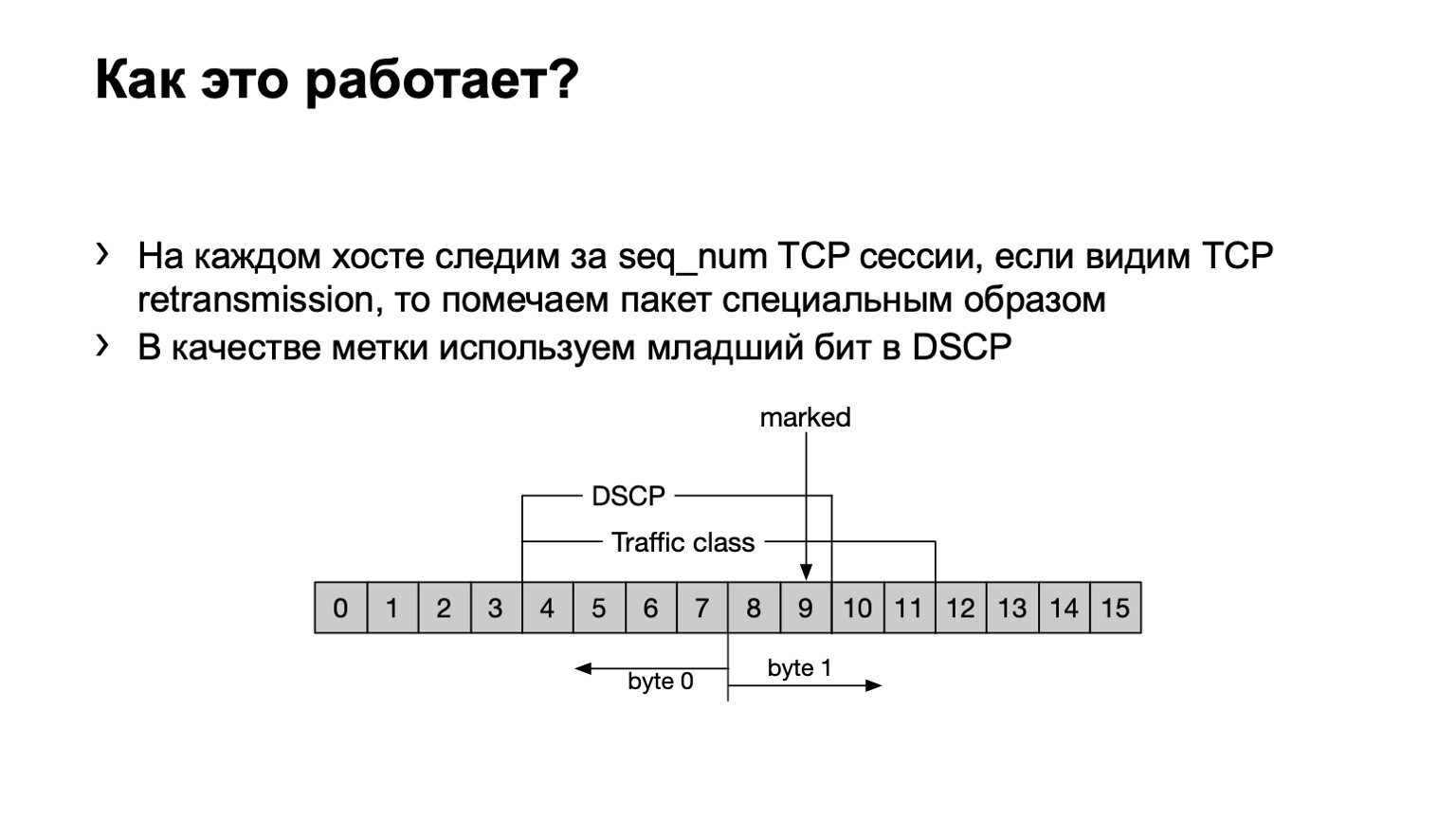
Apa yang telah kita lakukan Untuk jaga-jaga, saya akan menunjukkan bahwa pengiriman ulang TCP adalah pesan TCP yang diulang beberapa kali karena faktanya bahwa kwitansi mereka tidak dikonfirmasi. Kami memiliki program eBPF yang diinstal pada host dan melihat apakah pesan TCP ini mengirim ulang atau tidak mengirimkan kembali. Itu klise - dengan nomor urut. Jika nomor urut yang sama ditransmisikan dalam sesi TCP, maka ini adalah pengiriman ulang.
Apa yang kita lakukan dengan paket seperti itu? Kami mengatur bit terakhir di bidang DSCP ke satu untuk menghitung lebih lanjut semuanya.
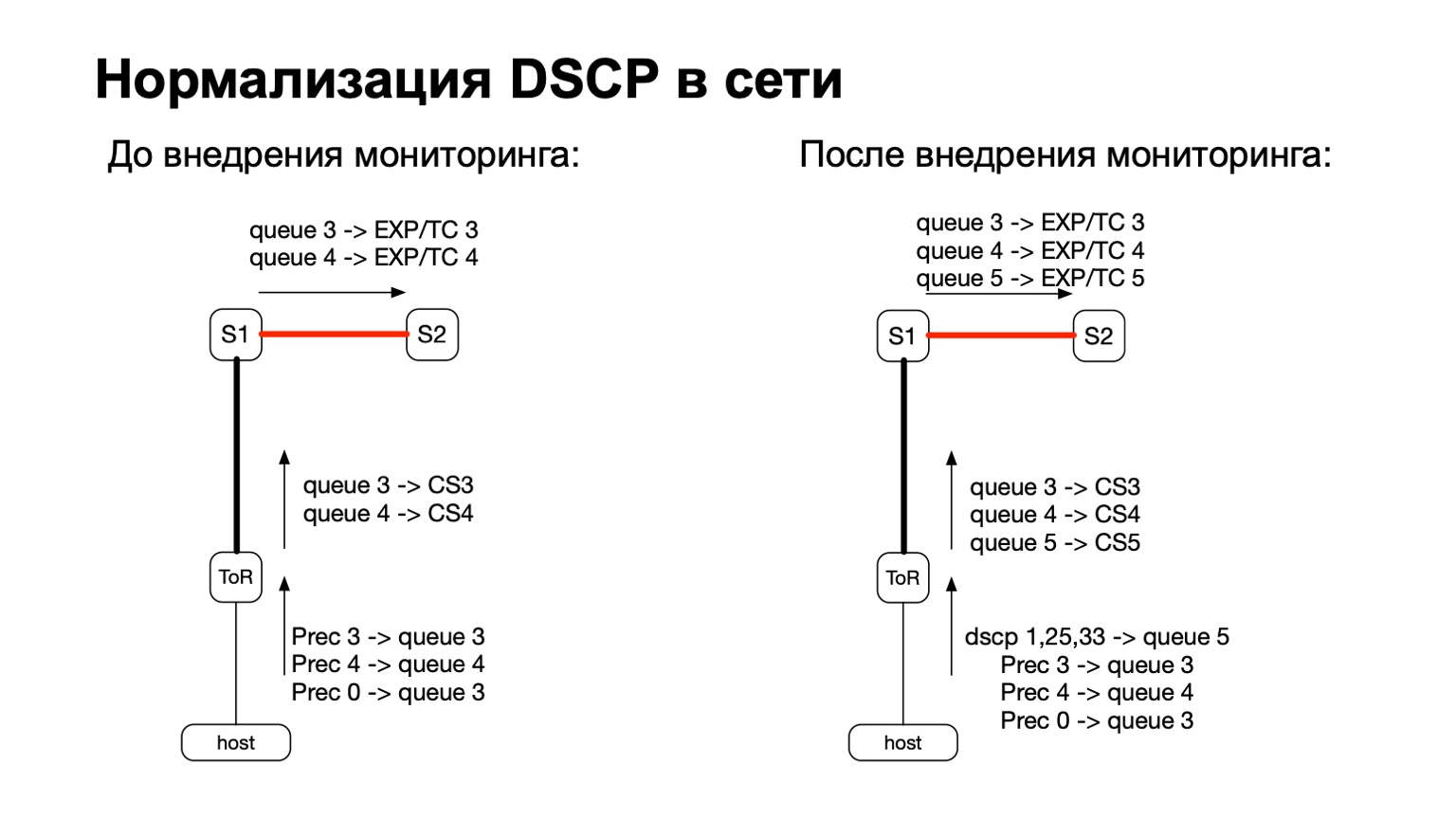
Secara umum, entah bagaimana DSCP terkait dengan QoS, bukan? Dan dengan QoS, sejarah di jaringan kami cukup rumit dan lama. Kami memiliki kebijakan tertentu yang dipantau pada sakelar ToR. Untuk kebijakan ini, kami hanya menambahkan kebutuhan untuk menghitung lebih banyak dan paket berwarna ini.
Jadi, untuk paket berwarna (baca: untuk paket transmisi ulang TCP dari host), kami cukup menambahkan antrian QoS lainnya. Ini cukup mudah dilakukan, karena kami masih memiliki saluran bebas. Plus, ini nyaman, karena pada tahap transisi antara IPv6 dan MPLS di pabrik, yaitu, pada tahap ketika paket terbang S1 dan pergi ke bagian MPLS kami di pabrik, akan lebih mudah untuk mengambil dan mengecat EXP / TC di header paket MPLS untuk setiap antrian spesifik .
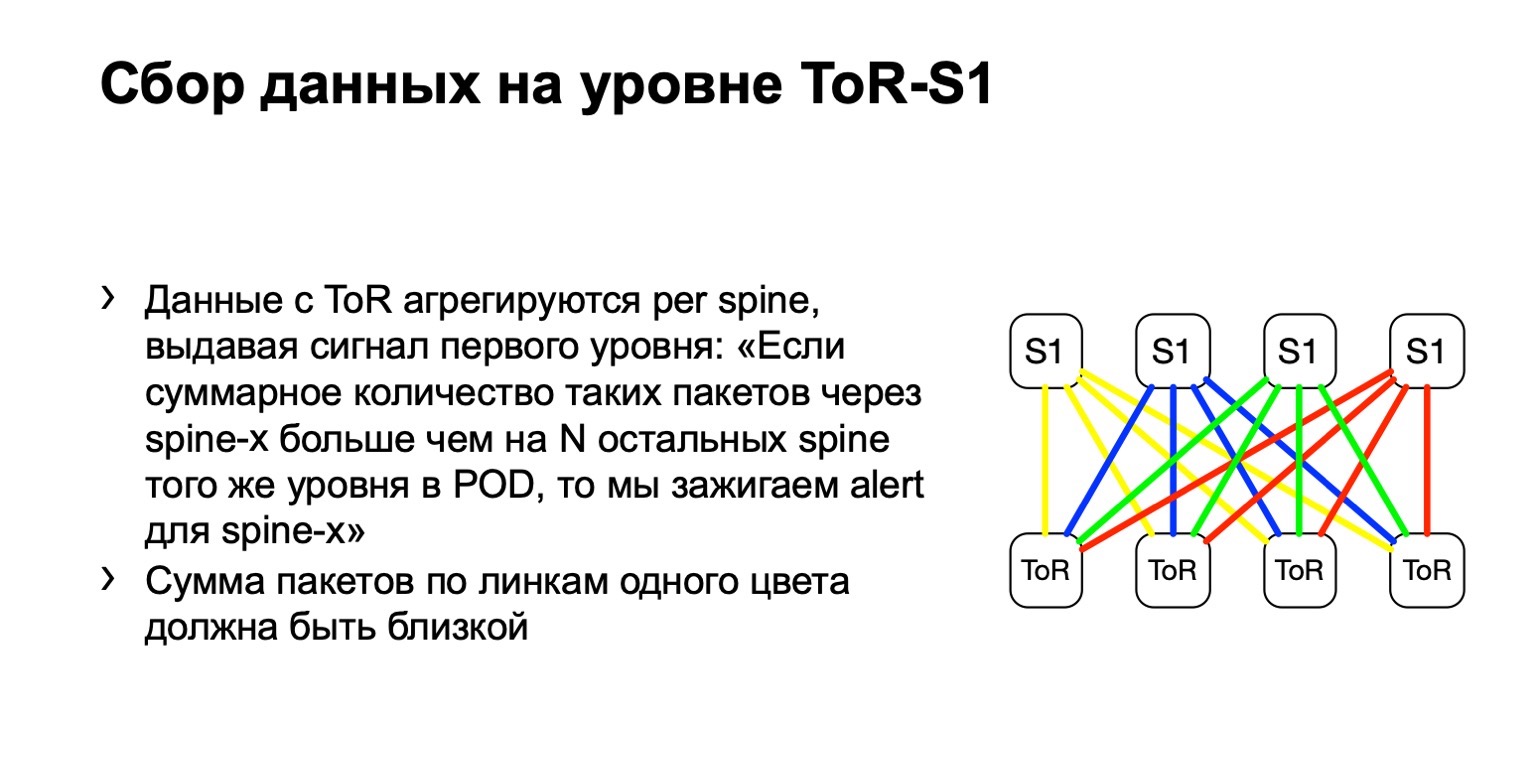
Apa yang kita lakukan dengan data ini? Kami mengumpulkannya dengan filter ACL standar, kelas lalu lintas. Artinya, ini bekerja, pada prinsipnya, pada vendor mana pun. Kami dapat mengumpulkan dan menghitung jumlah paket tersebut di mana-mana.
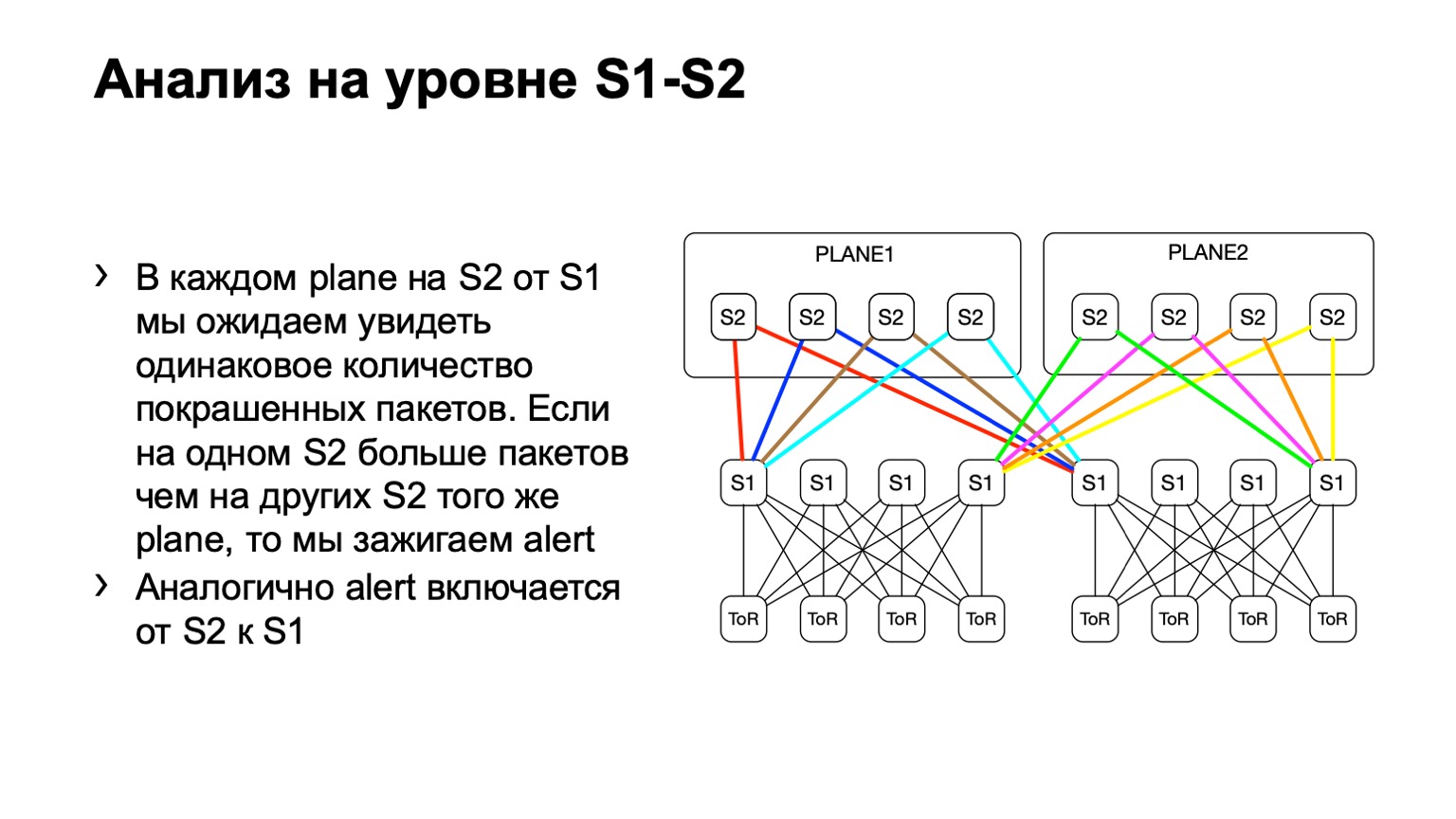
Selanjutnya, kita melihat distribusi paket yang tidak merata pada POD. Di dalamnya, misalnya, empat tulang belakang, seperti pada gambar. Jika jumlah paket pada tautan kuning, biru, hijau dan merah sama, maka kami percaya bahwa semuanya lebih atau kurang baik. Jika pada suatu saat kita melihat peningkatan, katakanlah, di tulang belakang paling kanan tingkat pertama, kita memahami bahwa perangkat ini menarik pengiriman ulang, ada yang salah dengan itu. Kemudian kami mencoba menonaktifkannya, atau setidaknya menyewanya. Setidaknya ketika kita melihat masalah di Netmon, kita akan tahu perangkat apa yang mungkin muncul.
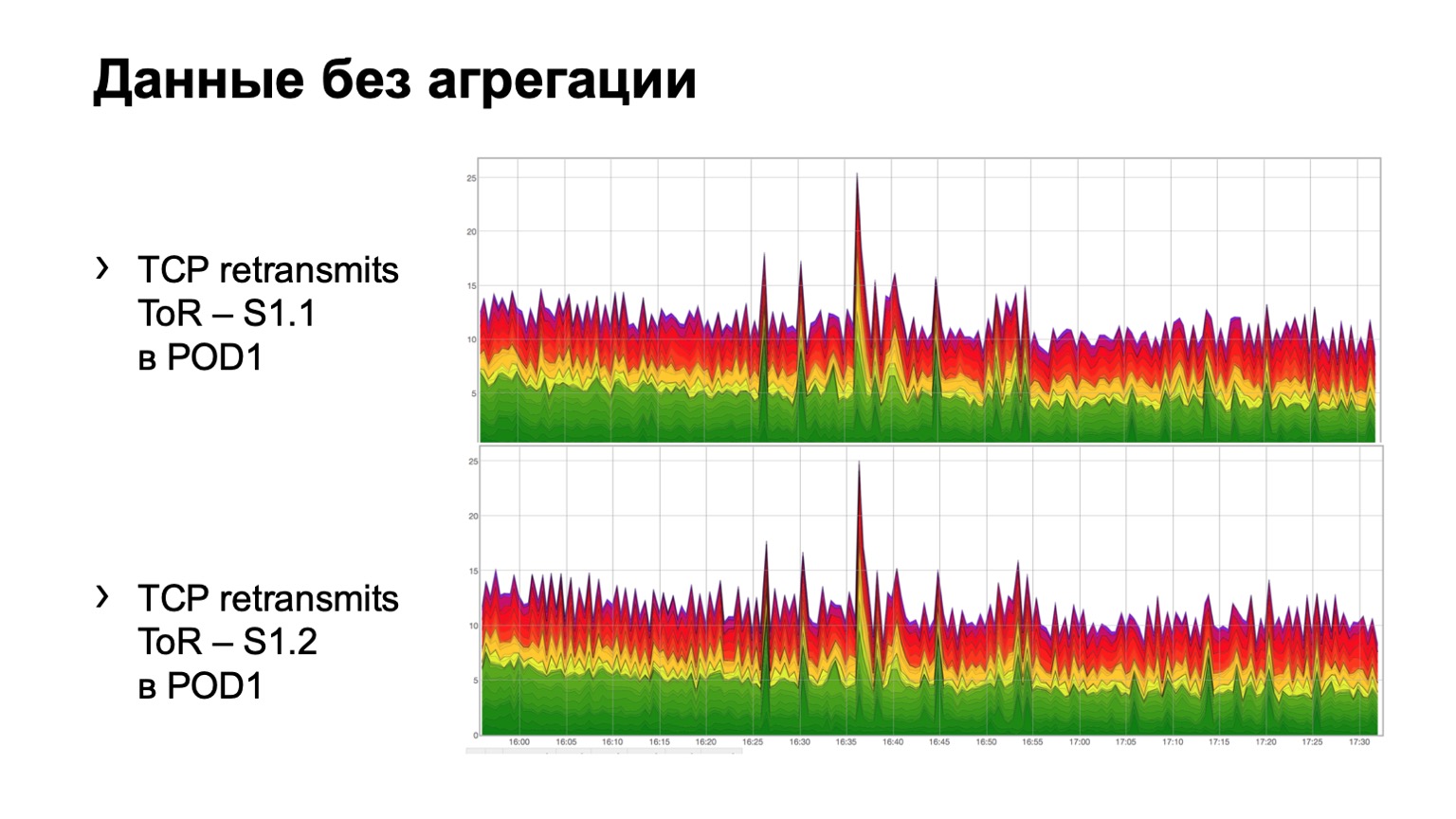
Bagaimana tampilannya pada data mentah sederhana? Berikut ini dua grafik. Faktanya, ini adalah grafik transmisi ulang dengan ToR menuju spine level pertama. Dalam contoh, dua tulang belakang di modul. Grafik atas adalah agregasi tulang belakang pertama, grafik bawah adalah tulang belakang kedua. Menyaksikan ini dalam formulir ini sangat tidak nyaman, jadi kami telah menambahkan agregasi informasi ini.
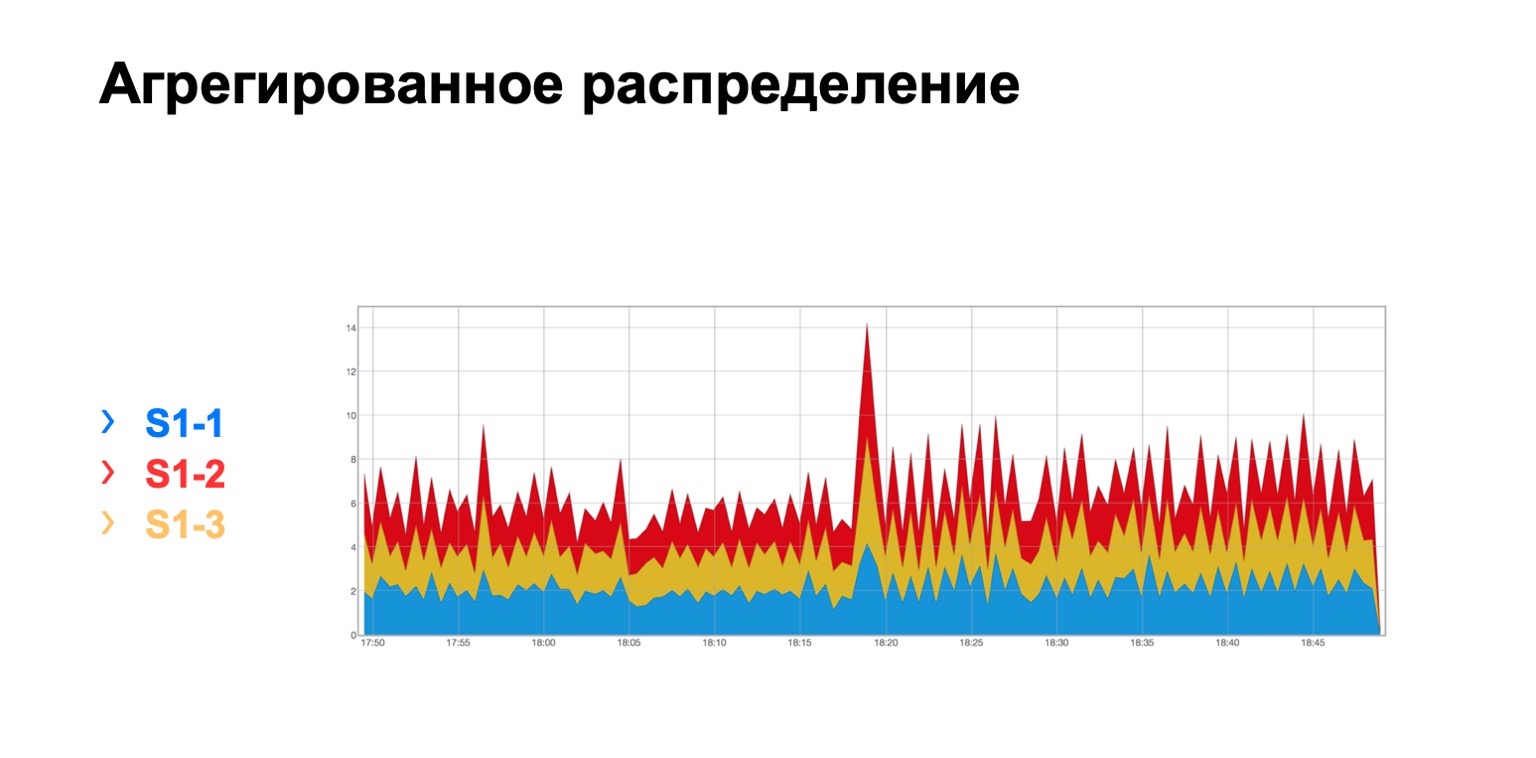
Ini terlihat seperti ini. Ada modul di mana tiga duri, untuk beberapa alasan, tidak peduli yang mana, dan kita lihat di sini distribusi total pengiriman ulang ke tiga duri. Pada prinsipnya seragam.
Untuk tulang belakang tingkat kedua, kita mungkin memiliki berbagai penyimpangan, sebut saja itu. Topologi masih tetap teratur, tetapi tergantung pada pusat data, kami mungkin atau mungkin tidak menggunakan arsitektur seperti piring. Intinya di sini persis sama. Pada satu tingkat, kita harus memiliki distribusi paket berwarna yang kira-kira sama.
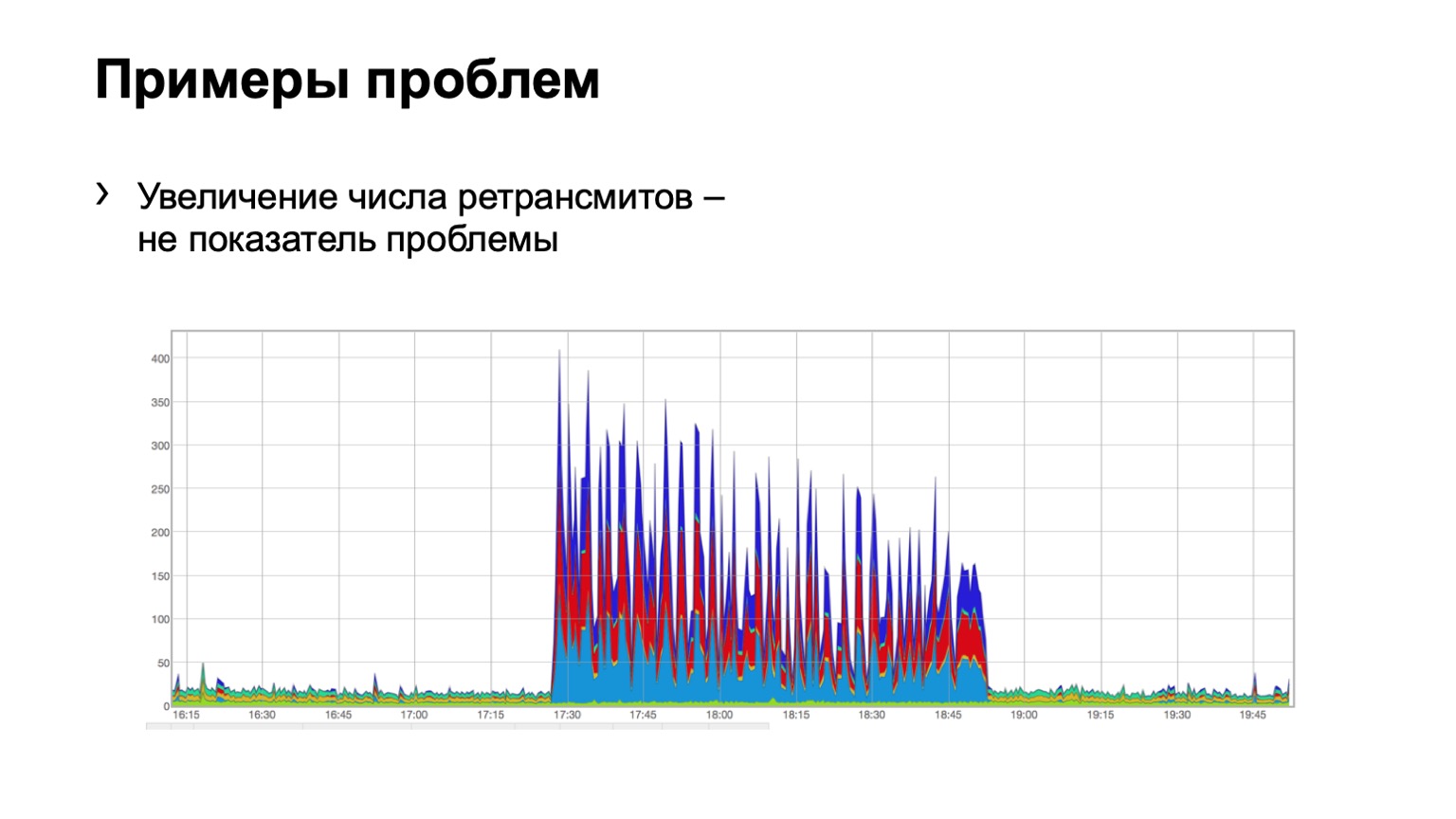
Mari kita lihat beberapa contoh. Adakah yang melihat masalah pada bagan seperti itu? Ada masalah di sini, tetapi tidak ada di sana secara bersamaan. Ya, ini masalah Schrödinger. Kenapa dia ada di sana dan tidak? Karena kami melihat peningkatan dalam jumlah pengiriman ulang, secara langsung jelas bahwa sesuatu terjadi pada kami. Tetapi pada saat yang sama, kita melihat bahwa pertumbuhan ini cukup seragam. Yaitu, tiga tulang belakang biru, merah, biru, bahkan distribusi di atasnya. Apa artinya ini? Bahwa ada semacam masalah dalam jaringan, tetapi tidak terkait dengan tingkat agregasi data ini. Dia ada di tempat lain.
Mungkin seseorang menutup port pada firewall, memutus beberapa cluster, yaitu, sesuatu terjadi. Tapi kami sama sekali tidak tertarik pada apa yang ada di sana dan mengapa. Artinya, kami bahkan tidak mempertimbangkan masalah seperti itu.
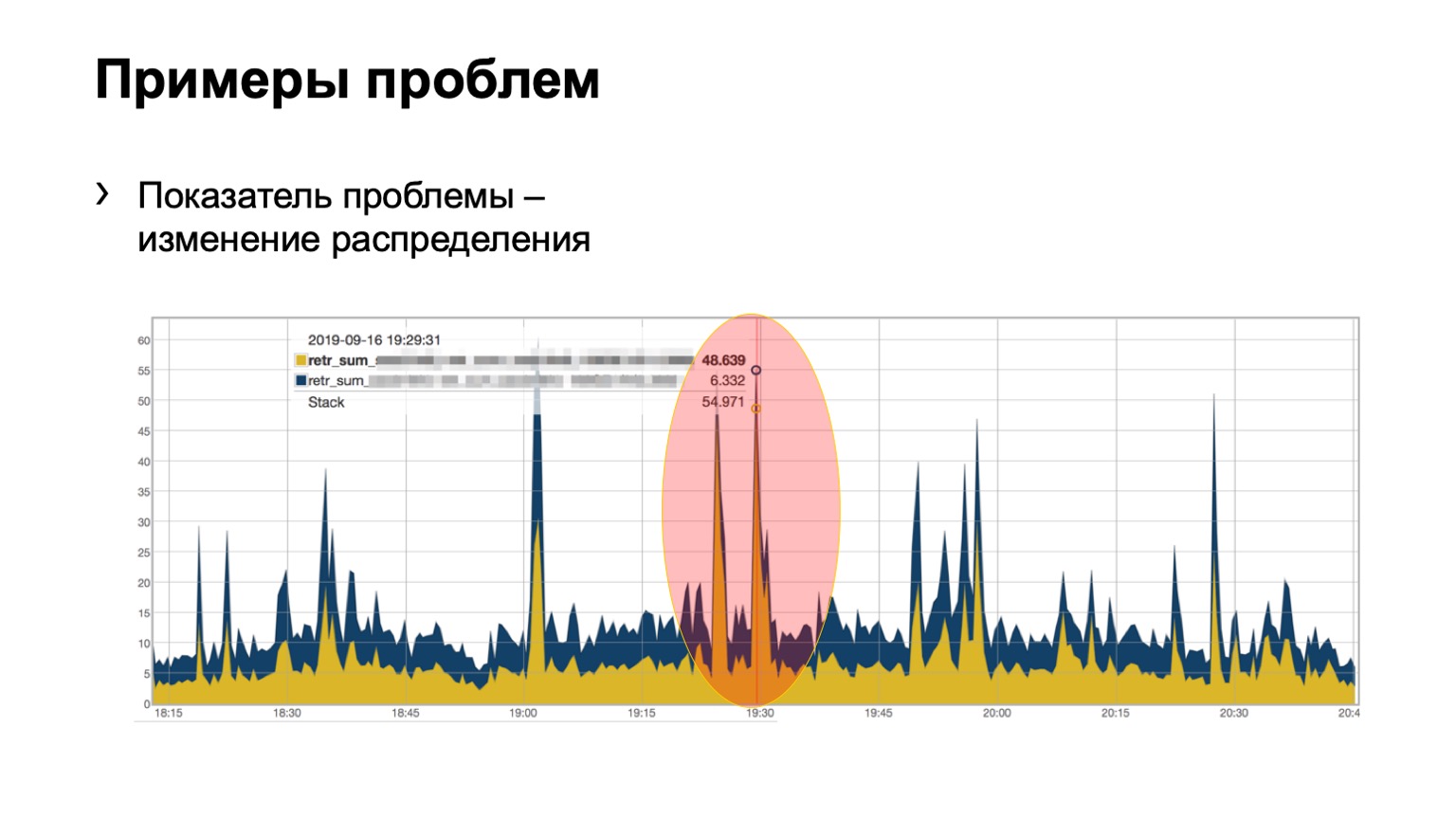
Dan di sini, mungkin, tidak begitu jelas, tetapi masalahnya terlihat. Dua duri dalam modul, 46 paket yang dicat terbang pada satu, dan sedikit pada yang kedua. Kami memahami bahwa kami memiliki masalah dengan beberapa jenis tulang belakang di jaringan, kami harus melakukan sesuatu.
Mengapa saya pertama kali berbicara tentang jalan rasa sakit dan penderitaan? Karena ada banyak masalah dengan solusi seperti itu. Masalah utamanya adalah, tentu saja, masalah pemantauan apa pun, ini salah positif. Positif palsu cukup banyak. Terutama karena kami menggunakan DSCP dan umumnya terkait dengan QoS.

Kami menemukan bahwa paket orang lain terbang di cat kami dan mengingatkan kami untuk pemantauan kami. Yaitu, kami pikir ini adalah pengiriman ulang, dan orang lain menaruh paket mereka di sana dan, secara umum, merusak gambar untuk kami. Secara alami, kami mulai mengerti, menemukan banyak tempat di mana kami pikir itu bekerja, tetapi sebenarnya tidak bekerja seperti yang kami pikirkan. Misalnya, lalu lintas yang memasuki jaringan tampaknya harus dicat ulang, lalu lintas dengan kelas CS6 dan CS7 di asrama tidak boleh masuk ke jaringan kami. Tetapi di beberapa tempat ada, katakanlah, kekurangan, dan kami berhasil mengobatinya.
Beberapa produsen menyajikan kejutan dalam bentuk bahwa Anda menghitung penghitung dalam arah keluar dari paket-paket tersebut, dan chip bekerja sedemikian rupa sehingga, pada kenyataannya, untuk memproses daftar akses keluar, ia membungkus lalu lintas dengan sendirinya lagi, menggigit setengah dari bandwidth chip . Itu 900 gigabit per chip, itu menjadi setengah lebih banyak.
Dan kami membuat beberapa peningkatan karena fakta bahwa pengaturan pada tuan rumah dapat berbeda. Artinya, beberapa host dapat mengirim transmisi ulang lebih sering, beberapa host dapat lebih jarang, beberapa dua, sekitar lima, dan semua ini mengingatkan pemantauan kami, semua ini adalah false positive.
Pertama, kami meninggalkan ide mengecat setiap pengiriman ulang TCP. Kami menyadari bahwa, pada prinsipnya, kami tidak perlu setiap transmisi ulang untuk memahami di mana masalahnya. Kami mulai hanya melukis ulang SYN. SYN adalah paket pertama dalam sesi ini, ini cukup bagi kami untuk menerima sinyal. Kami melukis SYN-ACL juga.
Semua sama, itu memberi beberapa positif palsu. Kami melangkah lebih jauh. Kami mulai hanya melukis ulang TCP-SYN pertama dalam sesi ini. Artinya, sebenarnya ada beberapa dari mereka yang dikirim, masing-masing kami lukis, - hanya satu yang mulai dicat. Jadi kita telah sampai pada apa yang kita miliki sekarang.
Secara total, ada Netmon, ada agen di host yang mewarnai pengiriman ulang SYN pertama dalam sesi, dan kami menghitung pengiriman ulang ini di setiap perangkat, di hampir setiap tautan di jaringan kami.

Tetapi untuk melihat dengan mata Anda pada gambar yang saya tunjukkan tidak begitu nyaman. Artinya, Anda tidak bisa menjualnya kepada petugas jaga, karena di setiap bagian Anda harus mengevaluasi semuanya dengan mata Anda. Dan kami sampai pada fakta bahwa saya ingin memiliki peringatan. Saya ingin lampu menyala: perangkat ini dan itu adalah masalah; perangkat lain adalah masalah.
Mari kita ingat beberapa statistik matematika. Idenya dengan waspada adalah bahwa setiap perangkat pada dasarnya adalah keranjang. Kami memiliki probabilitas keberhasilan dan probabilitas kegagalan untuk empat perangkat. Probabilitas pengiriman ulang masuk ke keranjang, yaitu sukses, adalah ¼. Ternyata distribusi binomial.
Apa kesulitan membuat peringatan di sini? Fakta bahwa kita tidak dapat membuat ambang batas menjadi statis, kita tidak dapat mengatakan: jika sepuluh transmisi ulang tiba pada satu perangkat dan sembilan pada perangkat lainnya, maka tidak ada masalah. Dan jika sepuluh dan lima, maka ada masalah. Karena jika kita skala ke seribu PPS, maka data seperti itu tidak lagi relevan. 1000 PPS dan 800 PPS antara perangkat yang berbeda jelas merupakan masalah.
Kami tidak dapat menetapkan ambang statis dalam PPS atau byte, kami tidak dapat mengaturnya sebagai persentase - masalah yang sama dengan mereka. Oleh karena itu, kita memerlukan solusi yang membuat ambang ini lebih atau kurang dinamis, tergantung pada jumlah paket.
Dan pesona dari distribusi binomial adalah bahwa pada peningkatan PPS cenderung normal, dan untuk distribusi normal kita sudah dapat menghitung ekspektasi, varians, dan menghitung interval kepercayaan, yang kita lakukan. Interval kepercayaan untuk kami adalah 3NPQ, yaitu tergantung pada jumlah paket melalui perangkat. Sebagai hasilnya, kami memiliki ambang pergeseran dinamis.
Ini adalah bagaimana sinyal kami terlihat dalam gambar. Jika beberapa perangkat tersingkir dari distribusi, maka kami mengibarkan bendera padanya - ada yang salah dengan itu.

Di mana kita ingin mengembangkan lebih lanjut, apa yang ingin kita tingkatkan di sini, selain, tentu saja, perang melawan false positive? Pertama-tama, kita akan tertarik untuk melihat apa yang ada di sana pada saat masalah terjadi? Untuk melakukan ini, kami memiliki opsi seperti itu di agen - Debug. Kita dapat mengunggah persis apa yang dikirim ulang, yaitu paket 5-tuple, misalnya, ke kolektor terpisah, dan kemudian melihatnya. Tapi ini memberi beban pada host, jadi kita kadang-kadang dilarang melakukannya. Kami ingin mempercepat ERSPAN dan membongkar paket-paket seperti itu ke kolektor dari perangkat keras itu sendiri, karena tidak ada yang melarang kami untuk melakukan ini pada perangkat keras.
Dima Afanasyev
mengatakan bagaimana kami akan mengembangkan pabrik kami, dan salah satu poinnya adalah transisi dari pabrik MPLS ke IPv6 saja. Apa yang ini berikan pada kita? MPLS memiliki tiga bit untuk penandaan QoS. Di IPv6, setidaknya enam. Hanya tiga bit yang benar-benar digunakan di jaringan kami saat ini. Artinya, kita masih memiliki tiga bit lagi di mana kita dapat memasukkan, pada kenyataannya, informasi apa pun dari tuan rumah.
Sebagai contoh, sekarang kita hanya melukis ulang SYN-retransmit pertama dalam sesi ini. Dan kita bisa mewarnai bit kedua, misalnya, jika paketnya masuk ke jaringan eksternal. Dan kita dapat mengirim ulang, yaitu menyoroti sinyal lain, yang kemudian akan kita pertimbangkan secara terpisah.
Selain itu, transisi ke desain dengan tepi pod, ketika kami melakukan DCI di beberapa tempat tertentu, mengancam kami dengan fakta bahwa di tempat ini kami dapat lebih mengontrol domain difserv kami. Yaitu, mengecat ulang dan melakukan sesuatu dengan cat untuk memotong false positive.
Akibatnya, melakukan semua hal di atas ternyata agak menyakitkan, tetapi menarik. Tidak ada yang perlu dikhawatirkan. Kami, pada kenyataannya, telah mengembangkan solusi yang dapat digunakan semua orang. Ini diuji pada hampir setiap vendor, ini berfungsi, tidak sulit. Dan itu benar-benar menunjukkan perangkat mana di jaringan yang ada masalah. Karena itu, pesan saya adalah - jangan takut untuk melakukan hal yang sama, dan biarkan pemantauan Anda tetap hijau. Terima kasih sudah mendengarkan.