Logging adalah bagian penting dari aplikasi apa pun. Setiap sistem logging melewati tiga langkah evolusi utama. Yang pertama adalah output ke konsol, yang kedua adalah log ke file dan tampilan kerangka kerja untuk logging terstruktur, dan yang ketiga didistribusikan logging atau mengumpulkan log dari berbagai layanan di satu pusat.
Jika logging dikelola dengan baik, ini memungkinkan Anda untuk memahami apa, kapan dan bagaimana kesalahannya, dan untuk menyampaikan informasi yang diperlukan kepada orang-orang yang harus memperbaiki kesalahan ini. Untuk sistem di mana 100 ribu pesan dikirim setiap detik di 10 pusat data di 190 negara, dan 350 insinyur menyebarkan sesuatu setiap hari, sistem logging sangat penting.
 Ivan Letenko
Ivan Letenko adalah pemimpin tim dan pengembang di Infobip. Untuk memecahkan masalah pemrosesan terpusat dan penelusuran log dalam arsitektur layanan mikro di bawah beban yang begitu besar, perusahaan mencoba berbagai kombinasi tumpukan ELK, Graylog, Neo4j, dan MongoDB. Akibatnya, setelah banyak menyapu, mereka menulis layanan log mereka di Elasticsearch, dan PostgreSQL diambil sebagai database untuk informasi tambahan.
Di bawah kucing secara rinci, dengan contoh dan grafik: arsitektur dan evolusi sistem, garu, penebangan dan penelusuran, metrik dan pemantauan, praktik bekerja dengan kelompok Elasticsearch dan mengelolanya dengan sumber daya terbatas.
Untuk memperkenalkan Anda pada konteksnya, saya akan memberi tahu Anda sedikit tentang perusahaan tersebut. Kami membantu klien-organisasi mengirimkan pesan kepada klien mereka: pesan dari layanan taksi, SMS dari bank tentang pembatalan, atau kata sandi satu kali saat memasuki VC.
350 juta pesan melewati kami setiap hari untuk klien di 190 negara. Masing-masing dari mereka kami terima, proses, tagihan, rute, adaptasi, kirim ke operator, dan sebaliknya, proses pengiriman laporan dan hasilkan analitik.
Agar semua ini berfungsi dalam volume seperti itu, kami memiliki:
- 36 pusat data di seluruh dunia;
- 5000+ mesin virtual
- 350+ insinyur;
- 730+ layanan microser yang berbeda.
Ini adalah sistem yang kompleks, dan tidak seorang guru pun yang dapat memahami skala penuh seorang diri. Salah satu tujuan utama perusahaan kami adalah kecepatan tinggi pengiriman fitur baru dan rilis untuk bisnis. Dalam hal ini, semuanya harus bekerja dan tidak jatuh. Kami sedang mengerjakan ini: 40.000 penempatan pada 2017, 80.000 pada 2018, 300 penempatan per hari.
Kami memiliki 350 insinyur - ternyata
setiap insinyur menyebarkan sesuatu setiap hari . Hanya beberapa tahun yang lalu, hanya satu orang di perusahaan yang memiliki produktivitas seperti itu - Kreshimir, insinyur utama kami. Tapi kami memastikan bahwa setiap insinyur merasa percaya diri seperti Kresimir ketika dia menekan tombol Deploy atau menjalankan skrip.
Apa yang dibutuhkan untuk ini? Pertama-tama,
kepercayaan diri bahwa kita memahami apa yang terjadi dalam sistem dan dalam keadaan apa itu. Keyakinan diberikan oleh kemampuan untuk mengajukan pertanyaan kepada sistem dan mencari tahu penyebab masalah selama insiden dan selama pengembangan kode.
Untuk mencapai kepercayaan ini, kami berinvestasi dalam
observability . Secara tradisional, istilah ini menggabungkan tiga komponen:
Kami akan membicarakan ini. Pertama-tama, mari kita lihat solusi kami untuk login, tetapi kami juga akan menyentuh metrik dan jejak.
Evolusi
Hampir semua aplikasi atau sistem logging, termasuk kita, melewati beberapa tahap evolusi.
Langkah pertama adalah
output ke konsol .
Kedua - kita mulai
menulis log ke file ,
kerangka kerja muncul untuk output terstruktur ke file. Kami biasanya menggunakan Logback karena kami tinggal di JVM. Pada tahap ini, log masuk terstruktur ke file muncul, memahami bahwa log yang berbeda harus memiliki tingkat, peringatan, kesalahan yang berbeda.
Segera
setelah ada beberapa contoh layanan kami atau layanan yang berbeda, tugas
akses terpusat ke log untuk pengembang dan dukungan muncul. Kami beralih ke logging terdistribusi - kami menggabungkan berbagai layanan menjadi layanan logging tunggal.
Logging terdistribusi
Opsi yang paling terkenal adalah tumpukan ELK: Elasticsearch, Logstash dan Kibana, tetapi kami memilih
Graylog . Ini memiliki antarmuka yang keren yang diarahkan untuk logging. Alarm keluar dari kotak sudah dalam versi gratis, yang tidak ada di Kibana, misalnya. Bagi kami, ini adalah pilihan yang sangat baik dalam hal log, dan di bawah tenda adalah Elasticsearch yang sama.
 Di Graylog, Anda bisa membuat lansiran, bagan seperti Kibana, dan bahkan mencatat metrik.
Di Graylog, Anda bisa membuat lansiran, bagan seperti Kibana, dan bahkan mencatat metrik.Masalahnya
Perusahaan kami berkembang, dan pada titik tertentu menjadi jelas bahwa ada sesuatu yang salah dengan Graylog.
Beban berlebih . Ada masalah kinerja. Banyak pengembang mulai menggunakan fitur-fitur keren Graylog: mereka membangun metrik dan dasbor yang melakukan agregasi data. Bukan pilihan terbaik untuk membangun analitik yang rumit pada gugus Elasticsearch, yang berada di bawah beban perekaman yang berat.
Tabrakan Ada banyak tim, tidak ada skema tunggal. Secara tradisional, ketika satu ID pertama kali memukul Graylog sebagai panjang, pemetaan secara otomatis terjadi. Jika tim lain memutuskan bahwa harus ada UUID yang ditulis sebagai string - ini akan merusak sistem.
Keputusan pertama
Log aplikasi dan log komunikasi yang terpisah . Log yang berbeda memiliki skenario dan metode aplikasi yang berbeda. Ada, misalnya, log aplikasi yang timnya berbeda memiliki persyaratan berbeda untuk parameter yang berbeda: berdasarkan waktu penyimpanan dalam sistem, oleh kecepatan pencarian.
Oleh karena itu, hal pertama yang kami lakukan adalah memisahkan log aplikasi dan log komunikasi. Tipe kedua adalah log penting yang menyimpan informasi tentang interaksi platform kami dengan dunia luar dan tentang interaksi di dalam platform. Kami akan berbicara lebih banyak tentang ini.
Mengganti sebagian besar log dengan metrik . Di perusahaan kami, pilihan standar adalah Prometheus dan Grafana. Beberapa tim menggunakan solusi lain. Tetapi penting bahwa kami menyingkirkan sejumlah besar dasbor dengan agregasi di dalam Graylog, mentransfer semuanya ke Prometheus dan Grafana. Ini sangat meringankan beban di server.
Mari kita lihat skenario untuk menerapkan log, metrik, dan jejak.
Log
Dimensi tinggi, debugging, dan penelitian . Apa itu log yang baik?
Log adalah peristiwa yang kita catat.
Mereka dapat memiliki dimensi besar: Anda dapat mencatat ID Permintaan, ID Pengguna, atribut permintaan dan data lainnya, yang dimensinya tidak terbatas. Mereka juga baik untuk debugging dan penelitian, untuk mengajukan pertanyaan sistem tentang apa yang terjadi dan mencari sebab dan akibat.
Metrik
Dimensi, agregasi, pemantauan, dan peringatan yang rendah . Di bawah kap semua sistem pengumpulan metrik adalah basis data deret waktu. Database ini melakukan pekerjaan agregasi yang sangat baik, sehingga metrik cocok untuk agregasi, pemantauan, dan peringatan bangunan.
Metrik sangat sensitif terhadap dimensi data.
Untuk metrik, dimensi data tidak boleh melebihi seribu. Jika kami menambahkan beberapa ID Permintaan, yang ukuran nilainya tidak terbatas, maka kami akan segera menghadapi masalah serius. Kami sudah menginjak penggaruk ini.
Korelasi dan penelusuran
Log harus dikorelasikan.
Log terstruktur tidak cukup bagi kami untuk dengan mudah mencari berdasarkan data. Harus ada bidang dengan nilai-nilai tertentu: ID Permintaan, ID Pengguna, data lain dari layanan dari mana log itu berasal.
Solusi tradisional adalah dengan menetapkan ID unik untuk transaksi (log) di pintu masuk ke sistem. Kemudian ID ini (konteks) diteruskan melalui seluruh sistem melalui rantai panggilan dalam suatu layanan atau antar layanan.
 Korelasi dan penelusuran.
Korelasi dan penelusuran.Ada istilah yang sudah mapan. Jejak dibagi menjadi bentang dan menunjukkan tumpukan panggilan dari satu layanan relatif ke yang lain, satu metode relatif ke yang lain relatif terhadap timeline. Anda dapat dengan jelas melacak jalur pesan, semua timing.
Pertama kami menggunakan Zipkin. Sudah pada tahun 2015, kami memiliki Bukti Konsep (proyek percontohan) dari solusi ini.
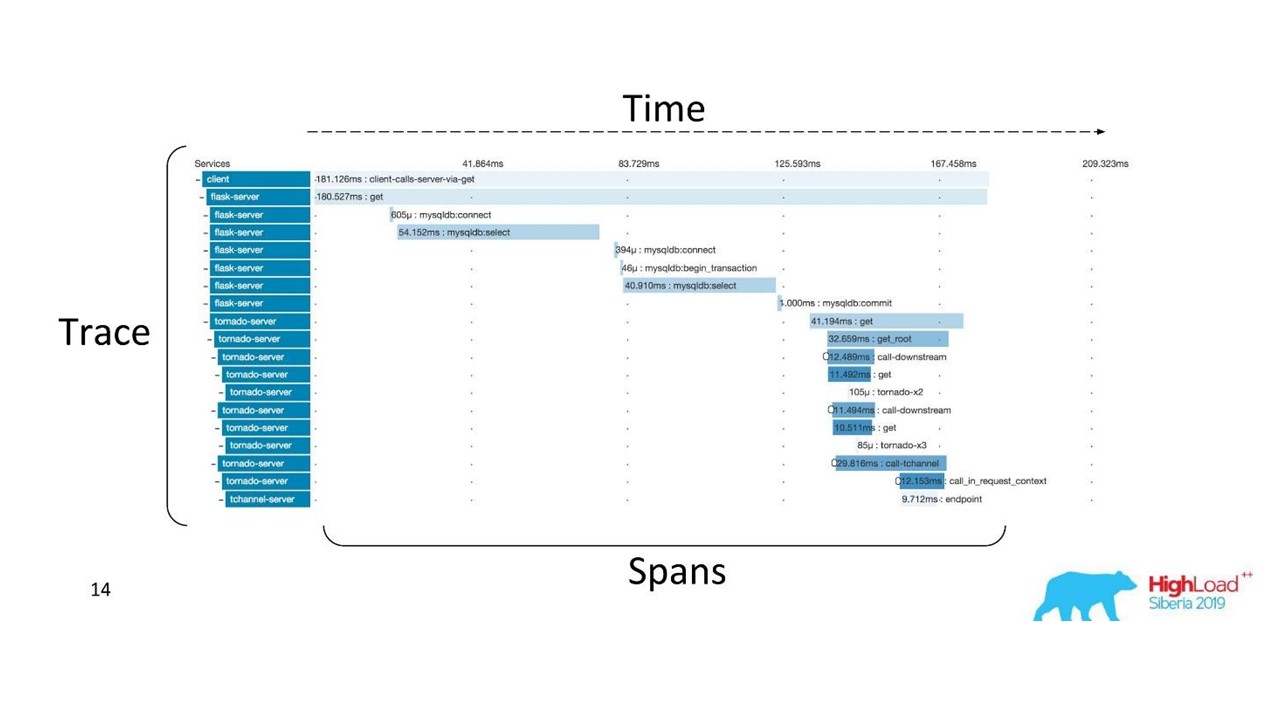 Jejak terdistribusi
Jejak terdistribusiUntuk mendapatkan gambar seperti itu,
kode harus diinstrumentasi . Jika Anda sudah bekerja dengan basis kode yang ada, Anda harus menjalaninya - itu membutuhkan perubahan.
Untuk mendapatkan gambaran lengkap dan mendapatkan manfaat dari jejak, Anda perlu
memasukkan semua layanan dalam rantai , dan bukan hanya satu layanan yang sedang Anda kerjakan.
Ini adalah alat yang ampuh, tetapi membutuhkan biaya administrasi dan perangkat keras yang signifikan, jadi kami beralih dari Zipkin ke solusi lain, yang disediakan oleh "sebagai layanan".
Laporan Pengiriman
Log harus dikorelasikan. Jejak juga harus dikorelasikan. Kami membutuhkan ID tunggal - konteks umum yang dapat diteruskan ke seluruh rantai panggilan. Tetapi seringkali ini tidak mungkin -
korelasi terjadi di dalam sistem sebagai akibat dari operasinya . Ketika kita memulai satu atau lebih transaksi, kita masih tidak tahu bahwa mereka adalah bagian dari keseluruhan besar.
Perhatikan contoh pertama.
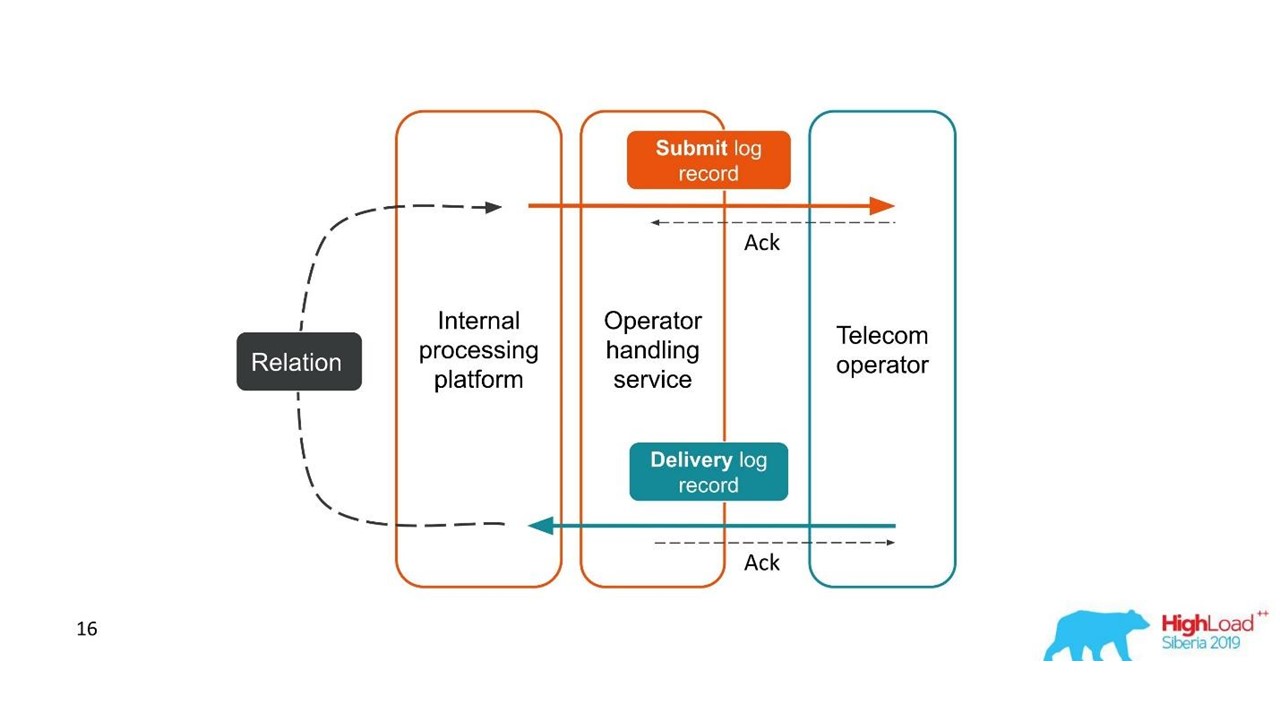 Laporan pengiriman.
Laporan pengiriman.- Klien mengirim permintaan untuk pesan, dan platform internal kami memprosesnya.
- Layanan, yang terlibat dalam interaksi dengan operator, mengirim pesan ini ke operator - entri muncul di sistem log.
- Kemudian, operator mengirimi kami laporan pengiriman.
- Layanan pemrosesan tidak mengetahui pesan yang terkait dengan laporan pengiriman ini. Hubungan ini dibuat kemudian di platform kami.
Dua transaksi terkait adalah bagian dari satu transaksi keseluruhan. Informasi ini sangat penting untuk insinyur pendukung dan pengembang integrasi. Tapi ini benar-benar mustahil untuk dilihat berdasarkan satu jejak atau ID tunggal.
Kasus kedua serupa - klien mengirimi kami pesan dalam satu bundel besar, kemudian kami membongkar mereka, mereka juga kembali dalam batch. Jumlah paket bahkan dapat bervariasi, tetapi kemudian semuanya digabungkan.
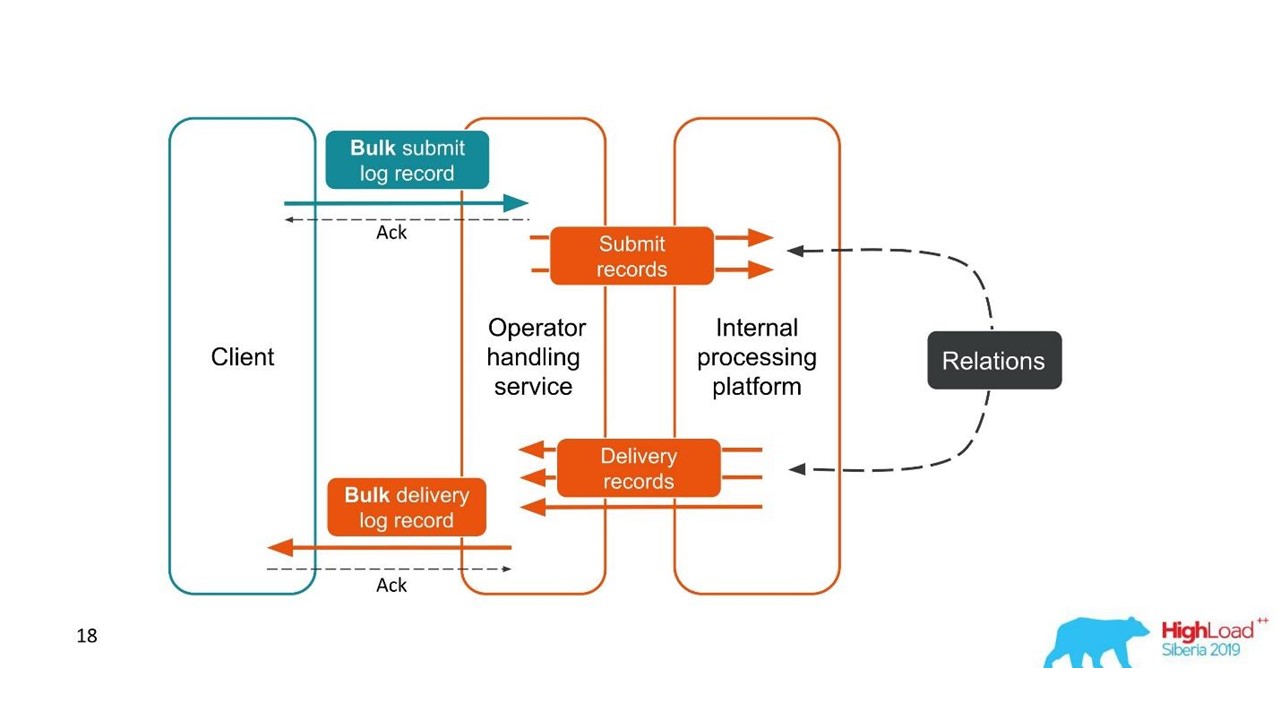
Dari sudut pandang klien, ia mengirim pesan dan menerima tanggapan. Tetapi kami mendapat beberapa transaksi independen yang perlu digabungkan. Ternyata hubungan satu-ke-banyak, dan dengan laporan pengiriman - satu ke satu. Ini pada dasarnya adalah grafik.
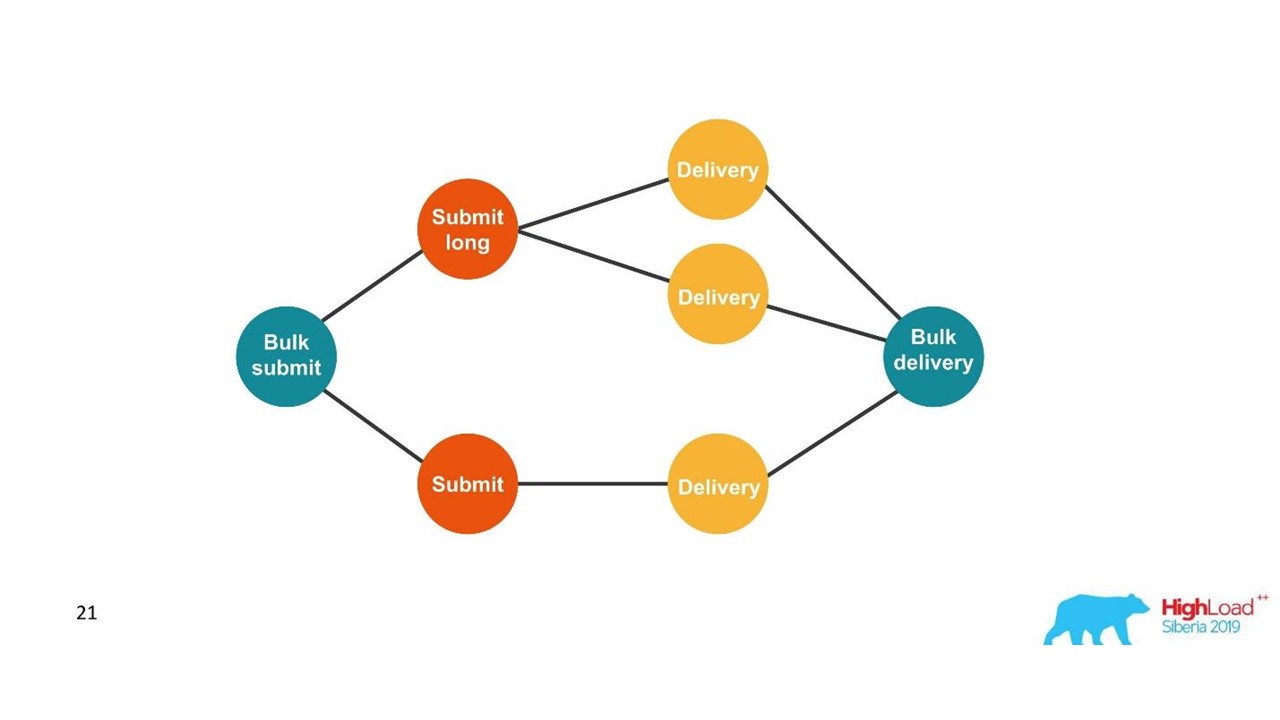 Kami sedang membangun grafik.
Kami sedang membangun grafik.Setelah kita melihat grafik, maka pilihan yang memadai adalah basis data grafik, misalnya, Neo4j. Pilihannya jelas karena Neo4j memberikan T-shirt keren dan buku gratis di konferensi.
Neo4j
Kami menerapkan Bukti Konsep: host 16-inti yang dapat memproses grafik 100 juta node dan 150 juta tautan. Grafik hanya menempati 15 GB disk - maka cocok untuk kami.
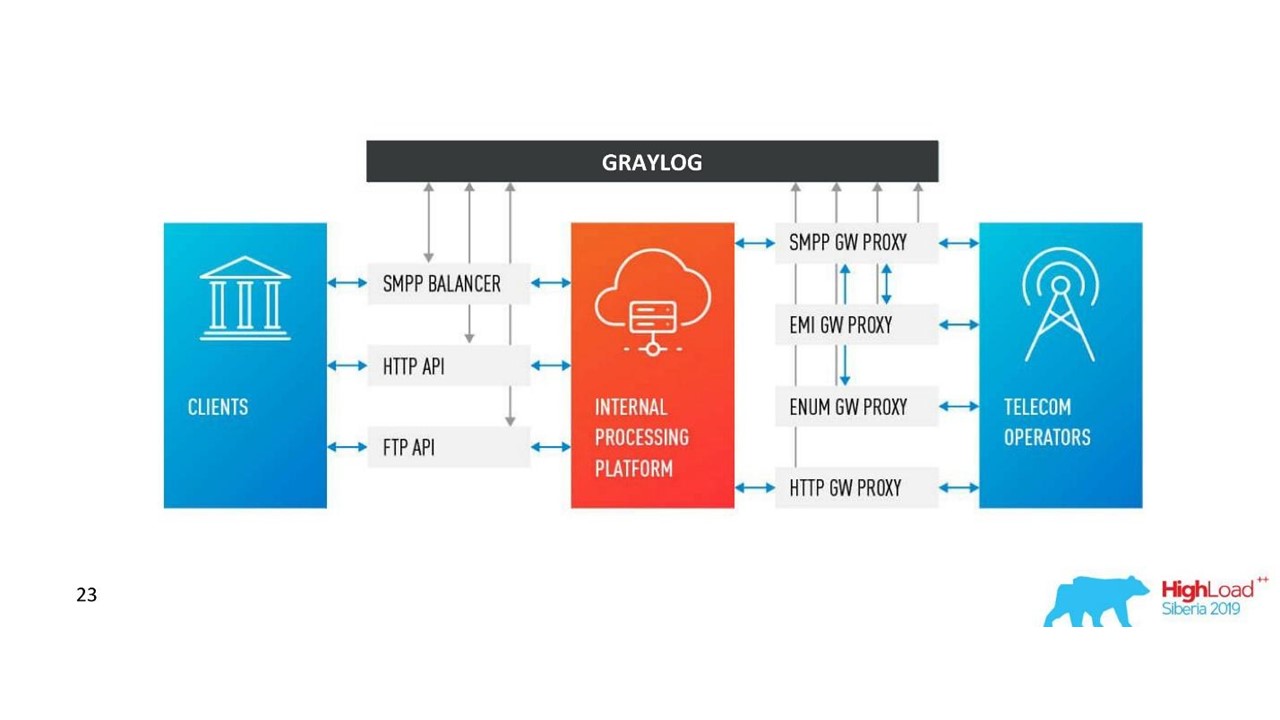 Keputusan kami. Arsitektur log.
Keputusan kami. Arsitektur log.Selain Neo4j, kami sekarang memiliki antarmuka sederhana untuk melihat log terkait. Dengan dia, para insinyur melihat seluruh gambar.
Tapi cukup cepat, kami menjadi kecewa dengan database ini.
Masalah dengan Neo4j
Rotasi data . Kami memiliki volume yang kuat dan data harus diputar. Tetapi ketika sebuah node dihapus dari Neo4j, data pada disk tidak dihapus. Saya harus membangun solusi yang kompleks dan sepenuhnya membangun kembali grafik.
Performa . Semua basis data grafik hanya baca. Saat merekam, kinerjanya terasa kurang. Kasus kami benar-benar kebalikannya: kami banyak menulis dan relatif jarang membaca - ini adalah unit permintaan per detik atau bahkan per menit.
Ketersediaan tinggi dan analisis kluster untuk biaya . Pada skala kami, ini berarti biaya yang layak.
Karena itu, kami pergi ke arah lain.
Solusi dengan PostgreSQL
Kami memutuskan bahwa karena kami jarang membaca, grafik dapat dibangun dengan cepat saat membaca. Jadi kita di database relasional PostgreSQL menyimpan daftar kedekatan ID kita dalam bentuk plat sederhana dengan dua kolom dan indeks pada keduanya. Ketika permintaan datang, kami memotong grafik konektivitas menggunakan algoritma DFS yang sudah dikenal (kedalaman traversal), dan mendapatkan semua ID terkait. Tapi ini perlu.
Rotasi data juga mudah dipecahkan. Untuk setiap hari kami memulai piring baru dan setelah beberapa hari ketika saatnya tiba, kami menghapusnya dan merilis data. Solusi sederhana.
Kami sekarang memiliki 850 juta koneksi di PostgreSQL, mereka menempati 100 GB disk. Kami menulis di sana dengan kecepatan 30 ribu per detik, dan untuk ini dalam database hanya ada dua VM dengan 2 CPU dan 6 GB RAM. Seperti yang diperlukan, PostgreSQL dapat menulis rindu dengan cepat.
Masih ada mesin kecil untuk layanan itu sendiri, yang memutar dan mengontrol.
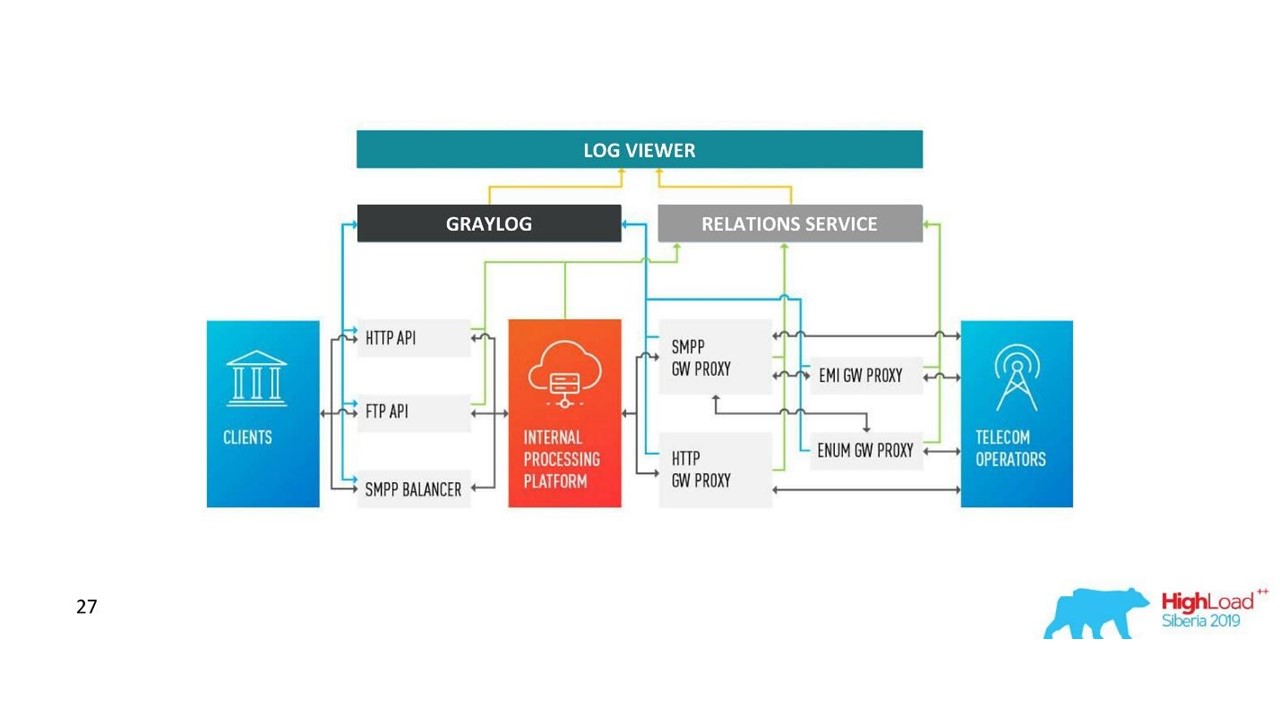 Bagaimana arsitektur kita berubah.
Bagaimana arsitektur kita berubah.Tantangan dengan Graylog
Perusahaan tumbuh, pusat data baru muncul, beban meningkat secara nyata, bahkan dengan solusi dengan log komunikasi. Kami berpikir bahwa Graylog tidak lagi sempurna.
Skema dan sentralisasi terpadu . Saya ingin memiliki alat manajemen satu cluster di 10 pusat data. Juga, muncul pertanyaan tentang skema pemetaan data terpadu sehingga tidak ada tabrakan.
API Kami menggunakan antarmuka kami sendiri untuk menampilkan koneksi antara log dan standar Graylog API tidak selalu nyaman digunakan, misalnya, ketika Anda perlu menampilkan data dari pusat data yang berbeda, mengurutkan dan menandai dengan benar. Karena itu, kami ingin dapat mengubah API sesuka kami.
Kinerja, sulit menilai kerugian . Lalu lintas kami adalah 3 TB log per hari, yang layak. Oleh karena itu, Graylog tidak selalu bekerja secara stabil, perlu masuk ke bagian dalamnya untuk memahami penyebab kegagalan. Ternyata kami tidak lagi menggunakannya sebagai alat - kami harus melakukan sesuatu.
Memproses penundaan (antrian) . Kami tidak menyukai penerapan standar antrian di Graylog.
Kebutuhan untuk mendukung MongoDB . Graylog menyeret MongoDB, perlu untuk mengelola sistem ini juga.
Kami menyadari bahwa pada tahap ini kami menginginkan solusi kami sendiri. Mungkin ada lebih sedikit fitur keren untuk peringatan yang belum pernah digunakan, untuk dasbor, tetapi fitur mereka sendiri lebih baik.
Keputusan kami
Kami telah mengembangkan layanan Log kami sendiri.
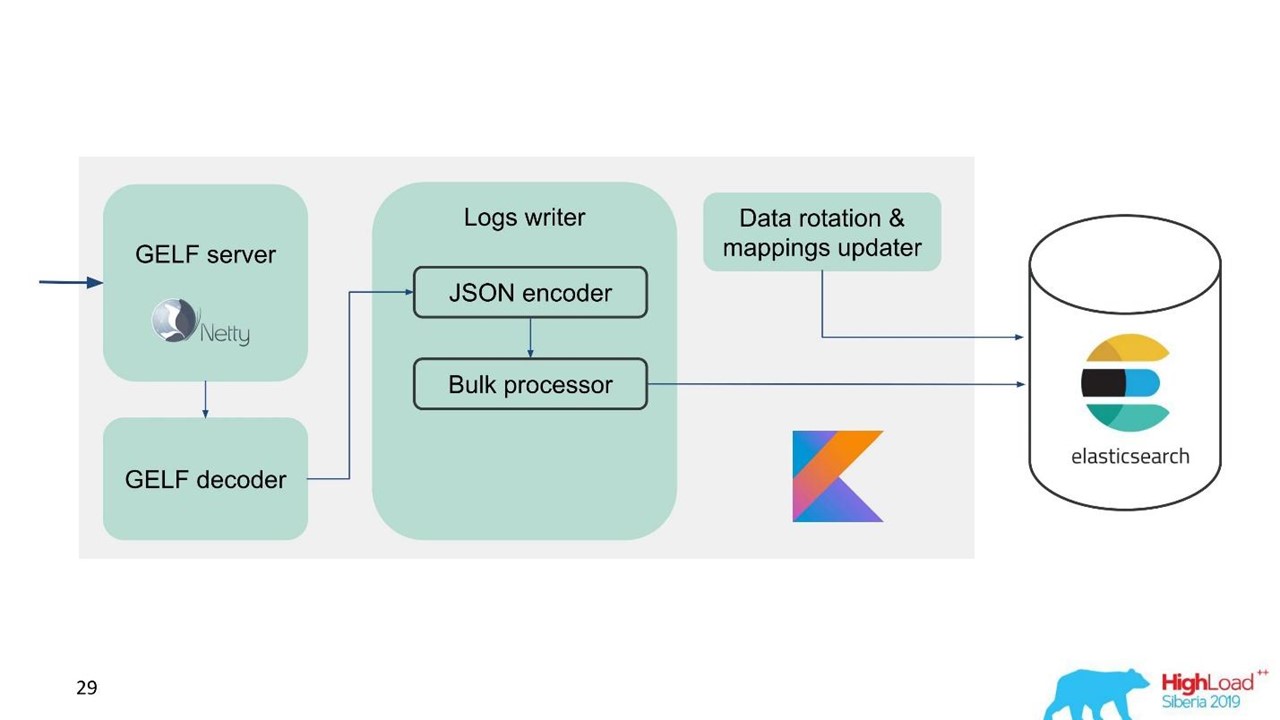 Layanan log.
Layanan log.Pada saat itu, kami sudah memiliki keahlian dalam melayani dan mempertahankan kelompok Elasticsearch yang besar, jadi kami mengambil Elasticsearch sebagai basis. Tumpukan standar di perusahaan adalah JVM, tetapi untuk backend kami juga menggunakan Kotlin terkenal, jadi kami mengambil bahasa ini untuk layanan.
Pertanyaan pertama adalah bagaimana merotasi data dan apa yang harus dilakukan dengan pemetaan. Kami menggunakan pemetaan tetap. Dalam Elasticsearch, lebih baik memiliki indeks dengan ukuran yang sama. Tetapi dengan indeks seperti itu, kita perlu memetakan data, terutama untuk beberapa pusat data, sistem terdistribusi, dan status terdistribusi. Ada ide untuk mempercepat ZooKeeper, tetapi ini lagi-lagi merupakan komplikasi dari pemeliharaan dan kode.
Oleh karena itu, kami memutuskan hanya - menulis tepat waktu.
Satu indeks selama satu jam, di pusat data lain 2 indeks selama satu jam, di indeks ketiga selama 3 jam, tetapi semua dalam waktu. Indeks diperoleh dalam ukuran yang berbeda, karena pada malam hari lalu lintas kurang dari siang hari, tetapi secara umum berfungsi. Pengalaman menunjukkan bahwa tidak ada komplikasi yang diperlukan.
Untuk memudahkan migrasi dan diberi sejumlah besar data, kami memilih protokol GELF, sebuah protokol Graylog sederhana berbasis TCP. Jadi kami mendapat server GELF untuk Netty dan dekoder GELF.
Kemudian JSON dikodekan untuk menulis ke Elasticsearch. Kami menggunakan Java API resmi dari Elasticsearch dan menulis dalam Massal.
Untuk kecepatan perekaman tinggi Anda perlu menulis Bulk'ami.
Ini adalah optimasi penting. API menyediakan prosesor Massal yang secara otomatis mengakumulasi permintaan dan kemudian mengirimkannya untuk direkam dalam satu bundel atau dari waktu ke waktu.
Masalah dengan Prosesor Massal
Segalanya tampak baik-baik saja. Tetapi kami mulai dan menyadari bahwa kami bersandar pada prosesor Massal - itu tidak terduga. Kami tidak dapat mencapai nilai-nilai yang kami andalkan - masalahnya datang entah dari mana.
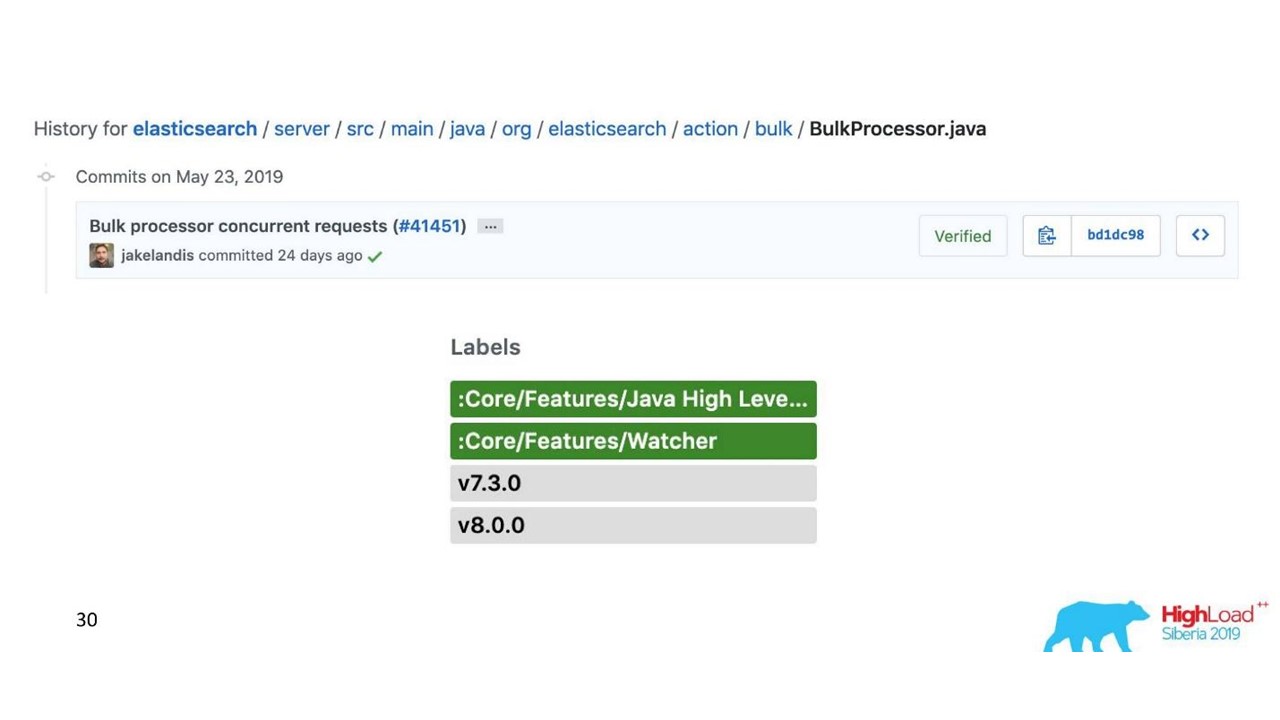
Dalam implementasi standar, prosesor Massal adalah single-threaded, sinkron, terlepas dari kenyataan bahwa ada pengaturan paralelisme. Itu masalahnya.
Kami mencari-cari dan ternyata ini adalah bug yang diketahui, tetapi tidak diselesaikan. Kami mengubah prosesor Massal sedikit - membuat kunci eksplisit melalui ReentrantLock. Hanya pada bulan Mei, perubahan serupa dilakukan pada repositori resmi Elasticsearch dan hanya akan tersedia dari versi 7.3. Yang sekarang adalah 7.1, dan kami menggunakan versi 6.3.
Jika Anda juga bekerja dengan prosesor Massal dan ingin meng-overclock entri di Elasticsearch - lihat
perubahan ini
di GitHub dan port kembali ke versi Anda. Perubahan hanya memengaruhi prosesor Massal. Tidak akan ada kesulitan jika Anda perlu port ke versi di bawah ini.
Semuanya baik-baik saja, prosesor Massal telah pergi, kecepatan telah dipercepat.
Kinerja penulisan Elasticsearch tidak stabil dari waktu ke waktu, karena berbagai operasi berlangsung di sana: penggabungan indeks, flush. Juga, kinerja melambat untuk sementara waktu selama pemeliharaan, ketika bagian dari node dikeluarkan dari cluster, misalnya.
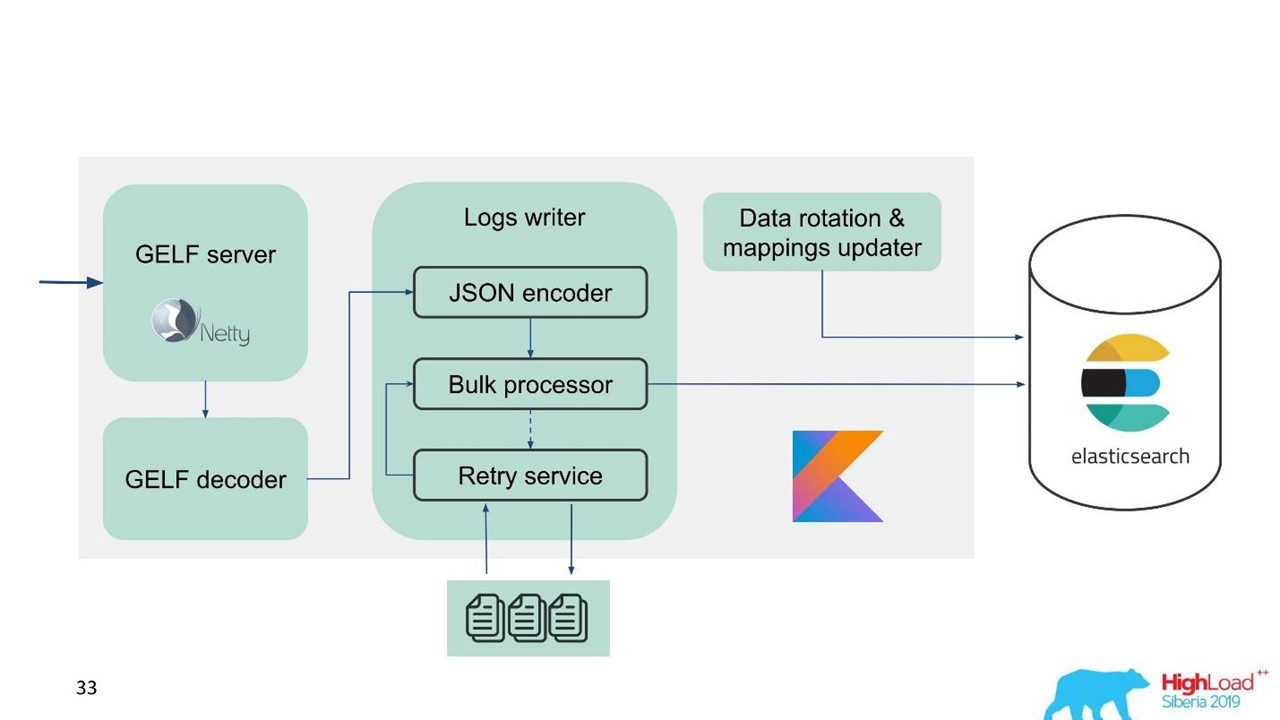
Dalam hal ini, kami menyadari bahwa kami perlu mengimplementasikan tidak hanya buffer dalam memori, tetapi juga antrian. Kami memutuskan bahwa kami hanya akan mengirim pesan yang ditolak ke antrian - hanya yang tidak dapat ditulis oleh prosesor Massal ke Elasticsearch.
Coba lagi fallback
Ini adalah implementasi sederhana.
- Kami menyimpan pesan yang ditolak dalam file -
RejectedExecutionHandler .
- Kirim ulang pada interval yang ditentukan dalam pelaksana terpisah.
- Namun, kami tidak menunda lalu lintas baru.
Untuk insinyur dan pengembang dukungan, lalu lintas baru dalam sistem terasa lebih penting daripada lalu lintas yang karena beberapa alasan tertunda selama lonjakan atau perlambatan Elasticsearch. Dia bertahan, tetapi dia akan datang nanti - bukan masalah besar. Lalu lintas baru diprioritaskan.
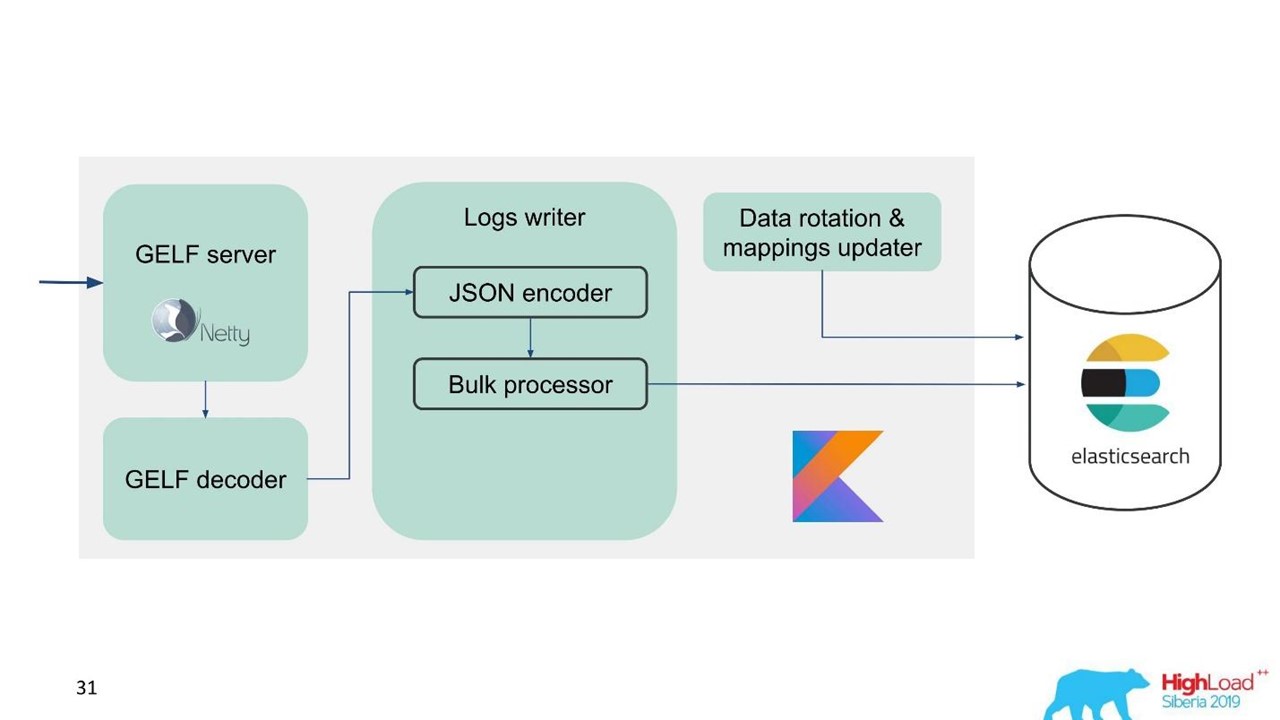
 Skema kami mulai terlihat seperti ini.
Skema kami mulai terlihat seperti ini.Sekarang mari kita bicara tentang bagaimana kita mempersiapkan Elasticsearch, parameter apa yang kita gunakan dan bagaimana kita mengaturnya.
Konfigurasi Pencarian Elastics
Masalah yang kita hadapi adalah kebutuhan untuk meng-overclock Elasticsearch dan mengoptimalkannya untuk menulis, karena jumlah bacaan terasa lebih kecil.
Kami menggunakan beberapa parameter.
"ignore_malformed": true -
buang bidang dengan tipe yang salah, dan bukan seluruh dokumen . Kami masih ingin menyimpan data, bahkan jika karena alasan tertentu pemetaan yang salah telah bocor di sana. Opsi ini tidak sepenuhnya terkait dengan kinerja.
Untuk zat besi, Elasticsearch memiliki nuansa. Ketika kami mulai meminta kelompok besar, kami diberitahu bahwa RAID-array dari SSD-drive untuk volume Anda sangat mahal. Tetapi array tidak diperlukan karena toleransi kesalahan dan partisi sudah dibangun ke dalam Elasticsearch. Bahkan di situs resminya ada rekomendasi untuk mengonsumsi zat besi lebih murah daripada yang lebih murah dan bagus. Ini berlaku untuk cakram dan jumlah inti prosesor, karena seluruh Elasticsearch sejajar dengan sangat baik.
"index.merge.scheduler.max_thread_count": 1 -
direkomendasikan untuk HDD .
Jika Anda tidak mendapatkan SSD, tetapi HDD biasa, maka atur parameter ini menjadi satu. Indeks ditulis dalam bentuk potongan, kemudian bagian ini dibekukan. Ini menghemat sedikit disk, tetapi, di atas segalanya, mempercepat pencarian. Juga, ketika Anda berhenti menulis ke indeks, Anda bisa melakukan
force merge . Ketika beban pada kluster kurang, secara otomatis membeku.
"index.unassigned.node_left.delayed_timeout": "5m" -
keterlambatan penyebaran ketika sebuah node hilang . Ini adalah waktu setelah Elasticsearch akan mulai menerapkan indeks dan data jika sebuah simpul di-boot ulang, disebarkan, atau ditarik untuk pemeliharaan. Tetapi jika Anda memiliki banyak beban pada disk dan jaringan, maka penyebaran adalah operasi yang sulit. Agar tidak membebani mereka, batas waktu ini lebih baik untuk mengontrol dan memahami penundaan yang dibutuhkan.
"index.refresh_interval": -1 -
jangan perbarui indeks jika tidak ada permintaan pencarian . Kemudian indeks akan diperbarui ketika permintaan pencarian muncul. Indeks ini dapat diatur dalam detik dan menit.
"index.translogDurability": "async" - seberapa sering menjalankan fsync: dengan setiap permintaan atau berdasarkan waktu. Memberikan keuntungan kinerja untuk drive yang lambat.
Kami juga memiliki cara yang menarik untuk menggunakannya. Dukungan dan pengembang ingin dapat pencarian teks lengkap dan menggunakan regexp'ov di seluruh isi pesan. Tetapi dalam Elasticsearch ini tidak mungkin - ia hanya dapat mencari berdasarkan token yang sudah ada dalam sistemnya. RegExp dan wildcard dapat digunakan, tetapi token tidak dapat mulai dengan beberapa RegExp. Karena itu, kami menambahkan
word_delimiter ke filter:
"tokenizer": "standard" "filter" : [ "word_delimiter" ]
Secara otomatis membagi kata menjadi token:
- “Wi-Fi” → “Wi”, “Fi”;
- “PowerShot” → “Power”, “Shot”;
- "SD500" → "SD", "500".
Dengan cara yang sama nama kelas ditulis, berbagai informasi debugging. Dengan itu, kami menutup beberapa masalah dengan pencarian teks lengkap. Saya menyarankan Anda untuk menambahkan pengaturan seperti itu ketika bekerja dengan login.
Tentang kluster
Jumlah pecahan harus sama dengan jumlah data node untuk load balancing . Jumlah minimum replika adalah 1, maka setiap node akan memiliki satu beling utama dan satu replika. Tetapi jika Anda memiliki data berharga, misalnya, transaksi keuangan, lebih baik 2 atau lebih.
Ukuran beling adalah dari beberapa GB hingga beberapa puluh GB . Jumlah pecahan pada sebuah simpul tidak lebih dari 20 per 1 GB pinggul Elasticsearch, tentu saja. Selanjutnya Elasticsearch melambat - kami juga menyerangnya. Di pusat data tersebut di mana ada sedikit lalu lintas, data tidak berputar dalam volume, ribuan indeks muncul dan sistem macet.
Gunakan allocation awareness , misalnya, dengan nama hypervisor jika ada layanan. Membantu menyebarkan indeks dan pecahan di berbagai hypervisor sehingga tidak tumpang tindih saat hypervisor keluar.
Buat indeks sebelumnya . Latihan yang bagus, terutama saat menulis tepat waktu. Indeks langsung panas, siap dan tidak ada penundaan.
Batasi jumlah pecahan satu indeks per node .
"index.routing.allocation.total_shards_per_node": 4 adalah jumlah maksimum pecahan satu indeks per node. Dalam kasus ideal, ada 2 dari mereka, kami menempatkan 4 berjaga-jaga, jika kami masih memiliki mobil lebih sedikit.
Apa masalahnya di sini? Kami menggunakan
allocation awareness - Elasticsearch tahu bagaimana cara menyebarkan indeks secara tepat di seluruh hypervisor. Tetapi kami menemukan bahwa setelah node dimatikan untuk waktu yang lama, dan kemudian kembali ke cluster, Elasticsearch melihat bahwa secara formal ada lebih sedikit indeks di dalamnya dan mereka dipulihkan. Sampai data disinkronkan, secara formal ada beberapa indeks pada node. Jika perlu, alokasikan indeks baru, Elasticsearch mencoba memalu mesin ini sepadat mungkin dengan indeks baru. Jadi sebuah node mendapatkan beban tidak hanya dari fakta bahwa data direplikasi padanya, tetapi juga dengan lalu lintas baru, indeks dan data baru yang jatuh pada node ini. Kontrol dan batasi.
Rekomendasi Pemeliharaan Elasticsearch
Mereka yang bekerja dengan Elasticsearch memahami rekomendasi ini.
Selama pemeliharaan terjadwal, terapkan rekomendasi untuk meningkatkan rolling: menonaktifkan alokasi shard, flush disinkronkan.
Nonaktifkan alokasi shard . Nonaktifkan alokasi shard replika, biarkan kemampuan hanya mengalokasikan primer. Ini secara nyata membantu Elasticsearch - ini tidak akan mengalokasikan kembali data yang tidak Anda butuhkan. Misalnya, Anda tahu bahwa dalam setengah jam simpul akan naik - mengapa mentransfer semua pecahan dari satu simpul ke simpul lainnya? Tidak ada yang mengerikan akan terjadi jika Anda hidup dengan kluster kuning selama setengah jam, ketika hanya pecahan utama yang tersedia.
Siram disinkronkan . Dalam hal ini, simpul akan melakukan sinkronisasi jauh lebih cepat ketika kembali ke cluster.
Dengan beban besar pada penulisan ke indeks atau pemulihan, Anda dapat mengurangi jumlah replika.
Jika Anda mengunduh sejumlah besar data, misalnya, beban puncak, Anda dapat mematikan pecahan dan kemudian memberikan perintah kepada Elasticsearch untuk membuatnya ketika bebannya sudah kurang.
Berikut adalah beberapa perintah yang ingin saya gunakan:
GET _cat/thread_pool?v - memungkinkan Anda untuk melihat thread_pool pada setiap node: apa yang sedang panas sekarang, apa antrian penulisan dan baca.
GET _cat/recovery/?active_only=true - indeks mana yang digunakan di mana, di mana pemulihan terjadi.
GET _cluster/allocation/explain - dalam bentuk manusia yang mudah mengapa dan indeks atau replika mana yang tidak dialokasikan.
Untuk pemantauan kami menggunakan Grafana.
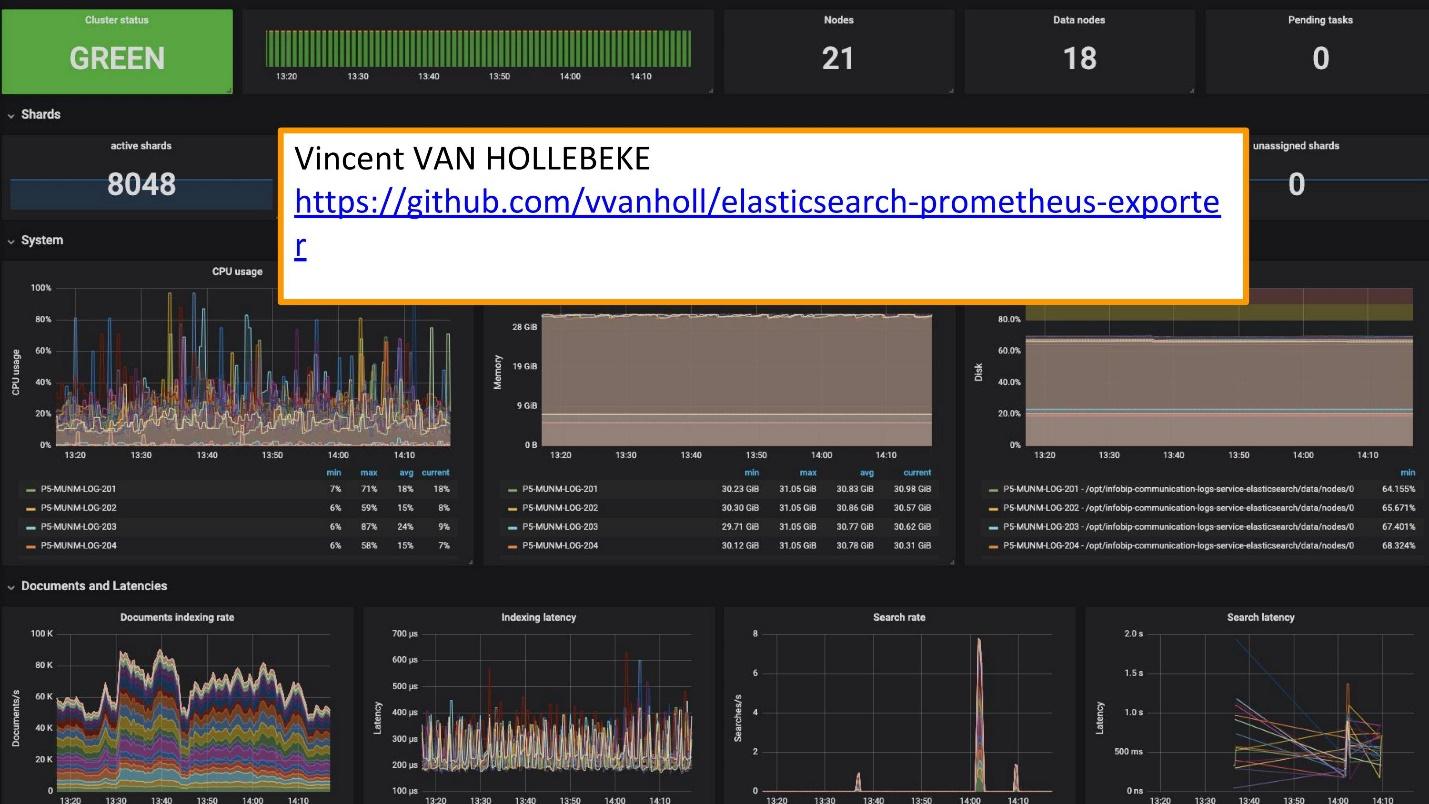
Ada
pengekspor yang sangat baik dan Teamplay Grafana dari
Vincent van Hollebeke , yang memungkinkan Anda untuk melihat secara visual status cluster dan semua parameter utamanya. Kami menambahkannya ke gambar Docker kami dan semua metrik saat digunakan dari kotak kami.
Kesimpulan Penebangan
Log harus:
- terpusat - titik masuk tunggal untuk pengembang;
- tersedia - kemampuan untuk mencari dengan cepat;
- terstruktur - untuk ekstraksi informasi berharga yang cepat dan mudah;
- berkorelasi - tidak hanya di antara mereka sendiri, tetapi juga dengan metrik dan sistem lain yang Anda gunakan.
Kontes
Melodifestivalen Swedia baru-baru ini diadakan. Ini adalah pilihan perwakilan dari Swedia untuk Eurovision. Sebelum kompetisi, layanan dukungan kami menghubungi kami: “Sekarang di Swedia akan ada beban besar. Lalu lintas sangat sensitif dan kami ingin menghubungkan beberapa data. Anda memiliki data di log yang hilang di dasbor Grafana. Kami memiliki metrik yang dapat diambil dari Prometheus, tetapi kami membutuhkan data tentang permintaan ID tertentu. "
Mereka menambahkan Elasticsearch sebagai sumber Grafana dan dapat menghubungkan data ini, menutup masalah dan mendapatkan hasil yang baik dengan cukup cepat.
Memanfaatkan solusi Anda sendiri jauh lebih mudah.
Sekarang, alih-alih 10 cluster Graylog yang berfungsi untuk solusi ini, kami memiliki beberapa layanan. Ini adalah 10 pusat data, tetapi kami bahkan tidak memiliki tim khusus dan orang-orang yang melayani mereka. Ada beberapa orang yang mengerjakannya dan mengubah sesuatu sesuai kebutuhan. Tim kecil ini terintegrasi dengan sempurna ke dalam infrastruktur kami - penggunaan dan servis lebih mudah dan lebih murah.
Pisahkan kasing dan gunakan alat yang sesuai.
Ini adalah alat terpisah untuk mencatat, melacak dan memantau. Tidak ada "instrumen emas" yang akan memenuhi semua kebutuhan Anda.
Untuk memahami alat mana yang diperlukan, apa yang harus dipantau, di mana menggunakan log, persyaratan apa untuk log, Anda harus beralih ke
SLI / SLO - Indikator Tingkat Layanan / Sasaran Tingkat Layanan. Anda perlu tahu apa yang penting bagi pelanggan dan bisnis Anda, indikator apa yang mereka lihat.
Seminggu kemudian, SKOLKOVO akan menyelenggarakan HighLoad ++ 2019 . Pada malam 7 November, Ivan Letenko akan memberi tahu Anda bagaimana ia hidup bersama Redis, dan secara total ada 150 laporan dalam program tentang berbagai topik.
Jika Anda mengalami masalah saat mengunjungi HighLoad ++ 2019 secara langsung, kami memiliki kabar baik. Tahun ini konferensi akan diadakan di tiga kota sekaligus - di Moskow, Novosibirsk dan St. Petersburg. Pada saat bersamaan. Bagaimana nantinya dan bagaimana menuju ke sana - cari tahu di halaman promo terpisah acara.