Sedikit lebih dari setahun telah berlalu sejak MIT mengumumkan rilis bahasa tujuan umum kinerja tinggi Julia . Sejak itu, bahasa tersebut telah mendapatkan popularitas: digunakan di lebih dari 1.500 universitas (di beberapa itu diajarkan sebagai bahasa pengantar pertama), dan bidang-bidang penutup aplikasi dari diagnosa medis dan perencanaan misi luar angkasa untuk masalah-masalah mendesak seperti mengoptimalkan lalu lintas bus sekolah .
Salah satu bidang kegiatan utama dari banyak proyek, tidak sulit untuk ditebak, adalah pembelajaran mesin, di mana Julia memiliki banyak alat yang kuat , dan proyek yang agak menarik baru-baru ini telah diterbitkan - Sistem Pemrograman Probabilitas Umum “GEN” .
Hari ini kita akan memperhatikan, seperti namanya, paket Flux , yang menyediakan semua kekuatan jaringan saraf. Kami akan mencoba beralih dari mengolah dan meneliti set gambar ke jaringan saraf terlatih untuk mendapatkan klasifikasi penuh!
Instalasi
Unduh kit distribusi dari situs resmi dan instal Julia interpreter ( REPL ) di komputer Anda.
Agar manajer paket berfungsi dengan benar, pengguna Windows 7 / Windows Server 2012 juga harus menginstal:
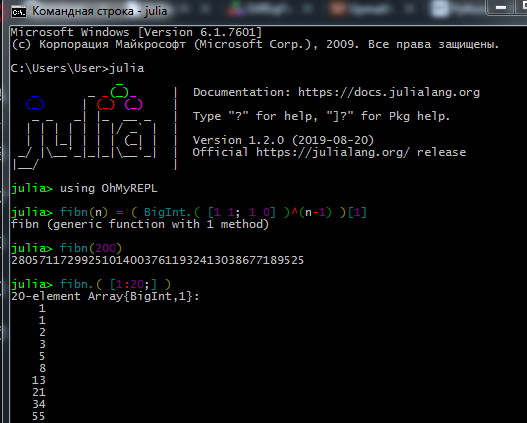
Proses bekerja di REPL terlihat seperti ini:
Ahli data sejati dan ahli mesin lebih menyukai Jupyter . Di sini Anda dapat melihat tentang instalasi, serta menemukan pelajaran interaktif untuk belajar mandiri dengan tugas dalam bahasa Rusia (tautan ke tutorial asli dan panduan ke bahasa di sana).
Di sini Anda dapat melihat cara bekerja dengan Notebook Jupyter.
Jika masalah instalasi- Koneksi tidak dapat dibuat - periksa hak akses Anda (apakah Anda memiliki pembatasan penulisan ke folder di C: \, login sebagai admin atau mulai Julia dalam mode administrator), jika menggunakan proxy, pastikan bahwa itu dikonfigurasi tidak hanya untuk browser
- Beberapa paket tidak suka alfabet Cyrillic di jalur file, jadi karena nama pengguna dalam bahasa Rusia saya punya banyak masalah
- Jika paket Berinteraksi tidak menampilkan hasil, Anda mungkin telah menginstal WebIO secara tidak benar, yang dapat diperbaiki
- Agar beberapa paket berfungsi dengan benar di Windows, jalur ke Julia dan Jupyter harus dimasukkan dalam variabel lingkungan.
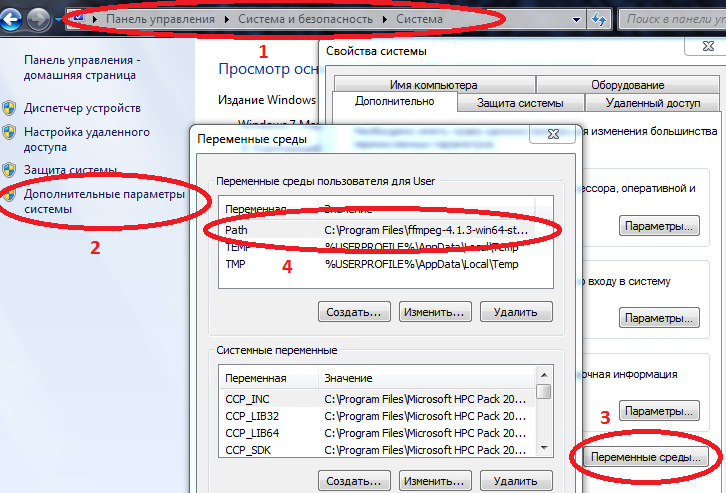
Properti Komputer / Sistem / Parameter sistem lanjutan / Variabel lingkungan / Path (Buat jika tidak) dan tambahkan path ke julia.exe di sana
Contoh C: \ Users \ User \ AppData \ Local \ Julia-1.2.0 \ bin
jika Path sudah memiliki nilai, maka pisahkan dengan titik koma.
Sekarang jika Anda mengarahkan julia ke konsol perintah ( cmd ), juru bahasa akan mulai.
Setelah menginstal semua yang Anda butuhkan, Anda dapat melanjutkan untuk mengunduh paket yang Anda butuhkan hari ini. Masukkan perintah di REPL atau Jupyter
Kode using Pkg pkgs = ["Plots", "TextParse", "CSV", "DataFrames", "ImageMagick", "Images", "Interact", "Flux"] for p in pkgs Pkg.add(p) end for p in pkgs Pkg.build(p) end
Setelah mempelajari dasar-dasar bahasa (bekerja dengan array, membuat fungsi, mengunduh paket, merencanakan grafik), Anda dapat melanjutkan ke materi selanjutnya.
Pemuatan dan pemrosesan data
Mengumpulkan dan mengatur data adalah seni tersendiri. Mengenai Julia, jaringan ini memiliki banyak materi yang sudah ketinggalan zaman, tetapi pertama-tama Anda dapat mencoba tutorial di atas , dan untuk studi yang lebih menyeluruh, baca buku Data Science dengan Julia (dalam domain publik)
Dan hari ini, mungkin, kami akan bekerja dengan data yang sudah disiapkan: set data dari sejumlah besar foto buah-buahan dari berbagai sudut - yang menginginkan buah segar?


Sebenarnya ini tugasnya - kami akan mengajarkan jaringan saraf untuk membedakan apel dari pisang!
Pertama-tama, unggah beberapa gambar uji:
using Images fnames = [ "data/10_100.jpg", "data/107_100.jpg", "data/yellow_apple_2.jpg", "data/8_100.jpg", "data/104_100.jpg", "data/3_100.jpg" ]

Bagaimana perbedaan benda-benda dalam gambar? Pertama, dengan bentuk, kedua oleh warna, dan kemudian oleh tekstur dan atribut lainnya. Analisis gambar adalah topik yang menarik dalam dirinya sendiri, dan klasifikasi dapat dibuat tidak hanya oleh neuron, tetapi juga, katakanlah, oleh wavelet . Kami akan mulai dengan warna tanda yang paling sederhana.
Seperti yang Anda ketahui, gambar disimpan dalam memori komputer dalam bentuk array, dalam kasus kami ini adalah matriks, masing-masing sel yang berisi tiga angka, menunjukkan jumlah warna merah, hijau dan biru di setiap piksel gambar. Mari kita lihat jumlah rata-rata setiap warna dalam gambar ini:
using Statistics: mean M1 = [ mean(float.(c.(img))) for c = [red,green,blue], img = fruits ] 3×6 Array{Float32,2}: 0.570278 0.652852 0.977111 0.835252 0.903998 0.842564 0.338118 0.468729 0.950773 0.806882 0.880692 0.755442 0.322406 0.379424 0.835212 0.707626 0.799643 0.761916
Kami dengan hati-hati melihat baris pertama - apakah itu tidak mengganggu Anda? Sebuah apel kuning dan pisang lebih merah dari apel varietas Breburn! Bagaimana bisa ?! Ayo, buat tambang asam, mungkin anak sekolah membaca tutorial ini, atau siswa yang lebih muda dari Ballet and Tractor Institute. Oleh karena itu, kami akan mencoba untuk menghindari kelalaian. Faktanya adalah bahwa latar belakang setiap gambar adalah putih, dan dalam notasi RGB itu diwakili oleh nilai-nilai (1,1,1). Dan karena ada 6 latar belakang lebih dalam 3 gambar dasbor, ditambah pewarnaan pisang dan apel kuning juga mengandung warna merah, ternyata dua gambar pertama hilang dalam warna merah. Untuk lebih jelasnya, kami membagi gambar menjadi warna-warna dasar:
function tweaking(img) R = colorview( RGB, red.(img),zeroarray,zeroarray ) G = colorview( RGB, zeroarray,green.(img),zeroarray ) B = colorview( RGB, zeroarray,zeroarray, blue.(img) ) [R; G; B] end tweaking( hcat(fruits...) )

Pernahkah Anda mendengar kata samar "dasar?" Jadi, kita dapat mengatakan bahwa gambar-gambar ini diletakkan dalam basis RGB . Semakin gelap - semakin sedikit warna tertentu, dan seperti yang kami harapkan, latar belakang dengan kekayaannya membuat perhitungan rata-rata menjadi bising. Hapus itu.
function remove_background(img) mtrx = copy( channelview(img) ) for i = 1:size(mtrx, 2), j = 1:size(mtrx, 3) if reduce(&, mtrx[:,i,j] .> [0.8, 0.8, 0.8])

M3 = [ mean(float.(c.(img))) for c = [red,green,blue], img = greyfruits ] 3×6 Array{Float32,2}: 0.451008 0.532696 0.578967 0.527727 0.52849 0.500276 0.218805 0.348609 0.552679 0.499192 0.505136 0.412946 0.203528 0.260142 0.439354 0.400631 0.424784 0.419291
Perbedaan area yang ditempati oleh masing-masing objek masih mempengaruhi, tetapi secara umum, dapat disimpulkan bahwa pisang adalah apel yang lebih hijau ( dan biru ). Ini akan menjadi kriteria evaluasi, yaitu - tanda. Sekarang mari kita lihat gambar-gambar lainnya:
pth = "C:\\Users\\User\\Desktop\\Banana"
Untuk setiap gambar, kami menetralkan kontribusi latar belakang, kami menemukan jumlah rata-rata setiap warna, secara bersamaan mengingat ukuran gambar ...
dataz = [] for fname in fnames img_i = load("$pth\\$fname") gbimg = remove_background(img_i) colorz = [ mean(c.(gbimg)) for c = [red,green,blue] ] inform = [size(gbimg, 1) size(gbimg, 2) colorz' ] push!(dataz, inform) end dataz
... dan kemudian Anda dapat mengatur data kami dalam struktur yang nyaman untuk bekerja - bingkai data:
using DataFrames, CSV banans = DataFrame( vcat(dataz...), [:height, :width, :red, :green, :blue] ) CSV.write("data/bananas.csv", banans)
apples = CSV.read("data/Apple_Braeburn.csv")
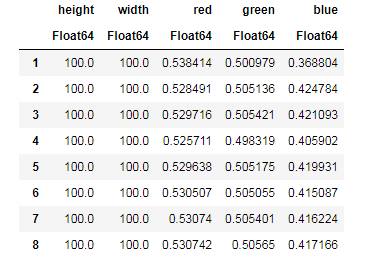
Desc = describe(apples, :all)
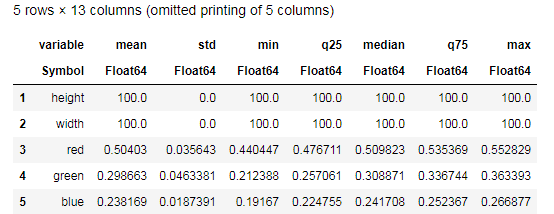
Cobalah untuk memahami data yang disediakan oleh fungsi describe() dan bandingkan dengan tabel serupa untuk pisang. Nah, analisis data seperti apa yang bisa tanpa grafik?
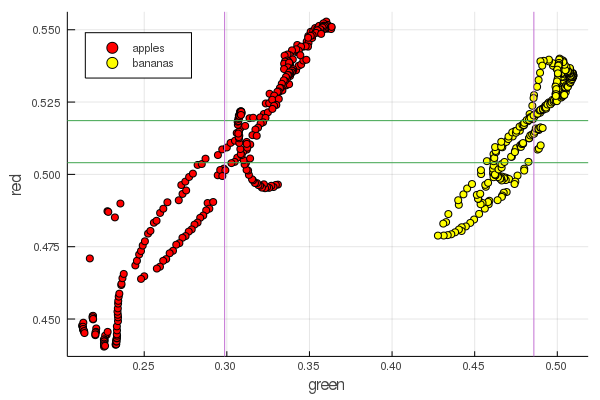
function plot2features(clr) x_apples = apples[:, :green] x_banans = banans[:, :green] y_apples = apples[:, clr] y_banans = banans[:, clr] scatter(x_apples, y_apples, lab = "apples", colour = :red) scatter!(x_banans, y_banans, lab = "bananas", legend = :topleft, colour = :yellow) hline!([mean(y_apples), mean(y_banans) ], lab = "" ) vline!([mean(x_apples), mean(x_banans) ], lab = "" ) xaxis!("green") yaxis!("$clr") end plot2features(:red)
plot2features(:blue)
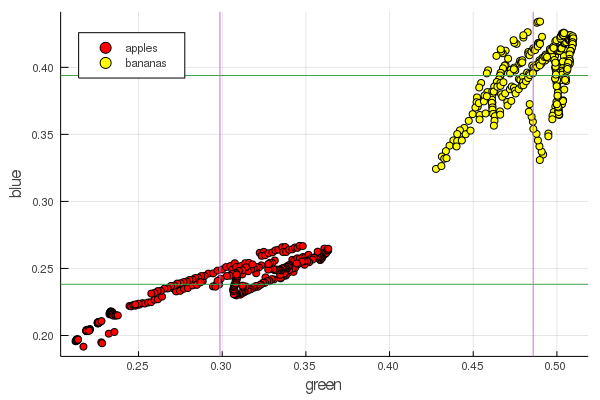
Mid-pisang merah nilainya sangat dekat dengan mid-apple. Tetapi pada bagan kedua, isolasi buah segera lebih jelas ditelusuri oleh dua karakteristik warna sekaligus. Pemisahan dapat ditingkatkan dengan renormalisasi yang benar, misalnya, nilai hijau kami berubah dari 0,2 menjadi 0,55, dan jika Anda melakukan konversi
x′i= fracxi− min(x) max(x)− min(x)
maka kita mendapatkan data yang dihitung ulang dengan [0,1], yang akan meningkatkan kesenjangan di antara ini tumpukan kelompok poin.
Perceptron
Tugas klasifikasi terdiri dalam mendefinisikan model dan memilih parameter yang berbagai data akan secara unik menerima penilaian milik mereka ke kelas tertentu. Sederhananya, kita perlu memperkenalkan fungsi tertentu dan mengatur parameternya sehingga memisahkan apel kita dari pisang.
Model yang paling terkenal dan populer untuk tujuan ini adalah neuron buatan McCulloch-Pitts, yang dikembangkan pada awal 1940-an. Selanjutnya, Frank Rosenblatt mengusulkan jaringan saraf yang terlatih - perceptron. Tidak sulit untuk menemukan penjelasan komprehensif tentang jaringan saraf, termasuk pada sumber daya ini (misalnya jaringan saraf untuk pemula , penggunaan jaringan saraf dalam pengenalan gambar , jaringan saraf, prinsip-prinsip dasar operasi, keragaman dan topologi )
Memilih sigmoid sebagai fungsi aktivasi dan mengatur output dari objek rahasia (buah-buahan) sesuai dengan outputnya
sigma(x;w,b):= frac11+ exp(−wx+b)
x= mathrmdata
sigma(x;w,b) approx0 menyiratkan mathrmapple
sigma(x;w,b) approx1 menyiratkan mathrmpisang
pilih parameter tersebut W dan b sehingga nilai output dari sigmoid untuk data yang diterima sesuai dengan notasi di atas
using Interact sigmo(x,w,b) = 1 / (1 + exp(-w*x+b)) r_apples, g_apples, b_apples = apples[:, :red], apples[:, :green], apples[:, :blue] r_banans, g_banans, b_banans = banans[:, :red], banans[:, :green], banans[:, :blue]; @manipulate for w in 10:1:60, b in -5:1:25 plot(x->sigmo(x,w,b), 0, 1, label="Model", legend = :topleft, lw=3) scatter!(g_apples[1:5], zeros(10), label="Apple", colour = :red) scatter!(g_banans[1:5], ones(10), label="Banana", colour = :yellow) end
foon(x) = sigmo(x,60,24) plot(foon, 0, 1, label="Model", legend = :topleft, lw=3) scatter!(foon, g_apples, label="Apple", colour = :red) scatter!(foon, g_banans, label="Banana", colour = :yellow) xaxis!("green")
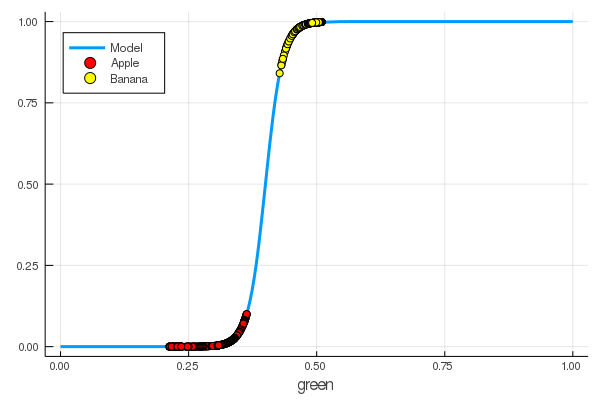
Kami secara manual mengajarkan neuron untuk membedakan apel dari pisang dengan jumlah hijau!
Secara alami, keinginan untuk mengotomatiskan proses ini. Kami memperkenalkan fungsi kerugian
L(w,b)=(0−σ(x1,w,b))2+(1−σ(x2,w,b))2
Sekarang proses pembelajaran akan terdiri dari meminimalkan fungsi ini:
Kode apples_mean_green = mean(g_apples) banans_mean_green = mean(g_banans) L(w, b) = (0 - sigmo(apples_mean_green,w,b))^2 + (1 - sigmo(banans_mean_green,w,b))^2 w_range = 10:0.5:30 b_range = 0:0.5:20 L_values = [L(w,b) for b in b_range, w in w_range] @manipulate for w in w_range, b in b_range p1 = surface(w_range, b_range, L_values, xlabel="b", ylabel="w", cam=(80,40), cbar=false, leg=false) scatter!(p1, [w], [b], [L(w,b)+1e-2], markersize=5, color = :blue) p2 = plot(x->sigmo(x,w,b), 0, 1, label="Model", legend = :topleft, lw=3) scatter!(p2, [apples_mean_green], [0.0], label="Apple", markersize=10) scatter!(p2, [banans_mean_green], [1.0], label="Banana", markersize=10, xlim=(0,1), ylim=(0,1)) plot(p1, p2, layout=(2,1)) end
Sebelumnya kami mempelajari paket untuk Julia yang memungkinkan pemecahan masalah optimasi dengan berbagai metode. Untungnya, hal-hal penting sudah ada di lingkungan Flux!
Fluks
using Flux
Pertama, kami menyajikan data untuk pelatihan dalam bentuk yang dapat dicerna:
Y = [zeros(length(g_apples)); ones(length(g_banans)) ] |> permutedims X = [g_apples; g_banans] |> permutedims;
Urutan berikutnya:
- Kami membuat dataset pelatihan dengan menggabungkan data input dengan jawaban yang benar mengenai klasifikasi data ini
- Kami mengatur parameter W dan b dengan matriks nilai acak (ada satu tanda pada input dan satu pada output, sehingga ukuran matriks 1 x 1 )
- Sebagai model, kami menetapkan layer padat - perceptron dengan fungsi aktivasi sigmoidal
- Kami mengatur fungsi kerugian - jumlah perbedaan kuadrat (Anda masih dapat menggunakan
Flux.crossentropy() lebih populer Flux.crossentropy() ) - Sebagai metode optimasi, kami memilih gradient descent . Dibutuhkan parameter - kecepatan keturunan
- Kami menetapkan fungsi evaluasi yang akan membulatkan nilai-nilai output model dan membandingkannya dengan jawaban yang benar.
- Dan cetak parameter dari model kami yang tidak terlatih
dataz = [(X, Y)] W = param(rand(1)) b = param(rand(1)) model = Dense(W, b, σ) loss(x, y) = mse(model(x), y) opt = Descent(0.1) accuracy(x, y) = mean( round.(model(x)) .== y ) params(model) Params([[0.3372841444115968] (tracked), [0.8430399003786011] (tracked)])
Mari kita lihat apa output dari fungsi kerugian untuk data kita.
loss(X, Y)
Dan periksa hasil fungsi evaluasi
accuracy(X, Y) 0.5
Hasilnya cukup alami - output didistribusikan cukup seragam dan setengah dari data diklasifikasikan dengan benar:
Kode modeldataz(x) = x |> model |> data |> permutedims
modelX = modeldataz(X) modelapples = modeldataz(g_apples') modelbanans = modeldataz(g_banans') plot(modelX, legend = false) hline!([0.5]) p1 = yaxis!((0,1)) curv = [-1:0.01:1;]' |> modeldataz plot( [-1:0.01:1;], curv, label="Model", legend = :topleft, lw=3) scatter!(g_apples, modelapples, label="Apple", colour = :red) scatter!(g_banans, modelbanans, label="Banana",colour = :yellow) hline!([0.5], lab = "", legend = :topleft) p2 = xaxis!("green") plot(p1, p2)
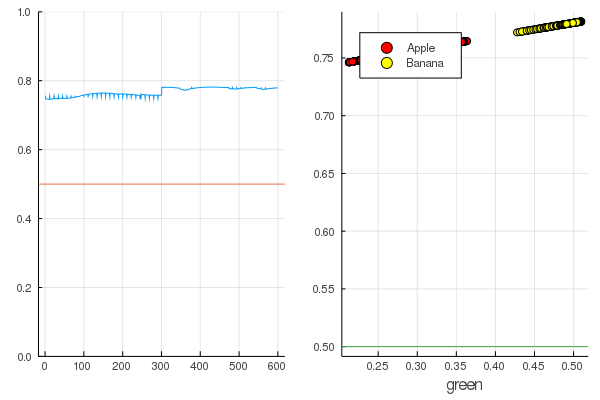
Mari kita mulai: ini sangat sederhana. Anda hanya perlu berteriak di jaringan saraf: "Kereta!", Sambil menunjukkan apa yang harus dilatih dan apa yang harus dikurangi, dan dia akan menyelesaikan satu sesi pelatihan. Karena itu, kami akan memaksanya untuk menyapih semuanya sebagaimana mestinya, tetapi hanya tanpa fanatisme, sehingga tidak ada pelatihan ulang
for i in 1:7000 train!(loss, params(model), dataz, opt) end model.W, model.b ([9.578663260720564] (tracked), [-3.7540362587506464] (tracked))
Kerugian menjadi jauh lebih sedikit:
loss(X, Y) 0.09152783090457564 (tracked)
Peringkat lebih baik:
accuracy(X, Y) 1.0
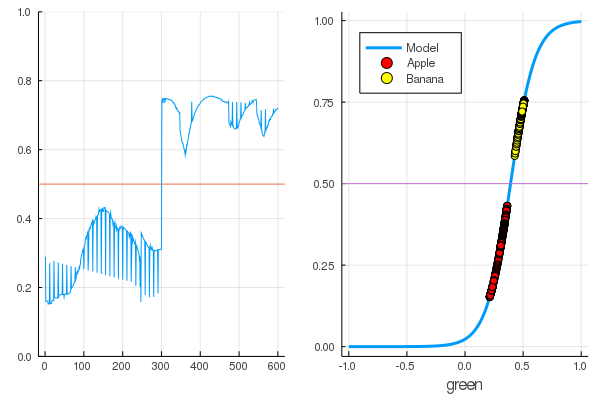
Data dibagi, dan pelatihan lebih lanjut akan membuat fungsi model lebih vertikal. Periksa model terlatih pada set buah pertama:
function classifier(img) gbimg = remove_background(img) greenmean = mean(float.(green.(gbimg))) answ = data( model( [ greenmean ]' ) )[1] fr = answ > 0.5 ? "Banana" : "Apple" "$fr $(round(200abs(0.5-answ)))%" end hcat(fruits...)
classifier.(fruits) 6-element Array{String,1}: "Apple 68.0%" "Apple 20.0%" "Banana 65.0%" "Banana 47.0%" "Banana 49.0%" "Banana 10.0%"
Sebuah apel kuning yang ditanam secara khusus, tentu saja, tidak dikenali dengan benar, dan pisang merah hampir tidak masuk kategori. Tetapi neuron hanya mendapat satu angka dari gambar - jumlah rata-rata hijau. Anda dapat menambahkan tanda lain, misalnya, jumlah biru, yang akan membuat model sedikit lebih mudah beradaptasi.
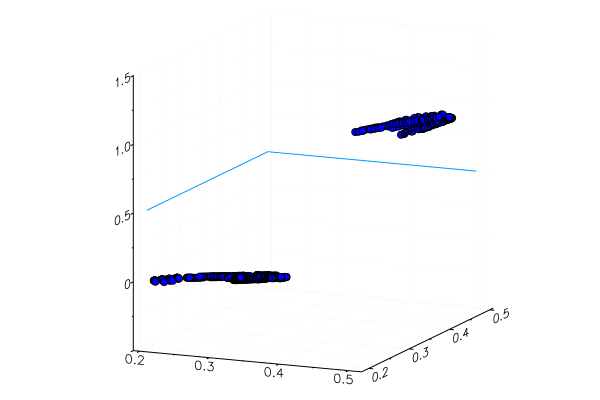
Atau Anda dapat menggunakan bukan representasi RGB, tetapi HSV (rona, saturasi, nilai), di mana rona saluran akan berisi informasi tentang warna gambar.
Seluruh kegemaran dari jaringan saraf adalah bahwa mereka sendiri dapat membedakan fitur yang kadang-kadang tidak terlalu jelas (korelasi warna, distribusi, garis besar dan kurva ...), tetapi Anda dapat membantu mereka dengan bantuan heuristik dan teknik khusus, yang mengubah bekerja dengan jaringan saraf menjadi seni asli.

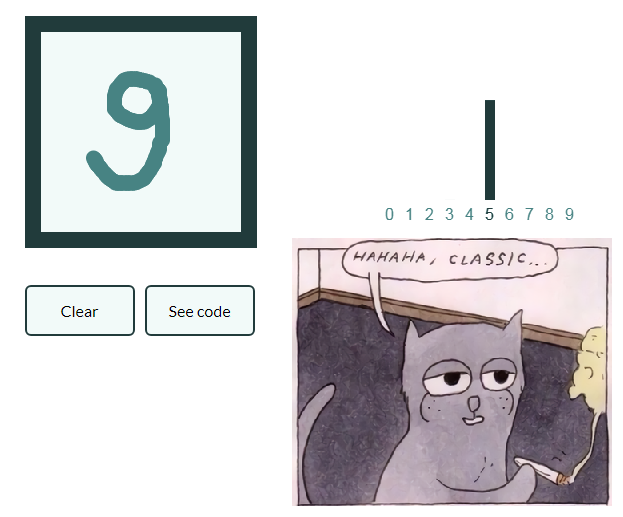
Sehingga kepemimpinan tidak tumbuh terlalu banyak dan melakukan serangkaian artikel terlalu malas Mari kita juga memberikan contoh klasifikasi gambar dengan angka tulisan tangan, dan pembaca yang tertarik akan menggeneralisasi pengetahuan yang diperoleh ke dalam gambar dengan buah-buahan dan membuat jaringan sarafnya sendiri, yang mampu, katakanlah, menandai objek dalam kehidupan yang masih hidup!
Mnist
using Images using Flux, Flux.Data.MNIST, Statistics using Flux: onehotbatch, onecold, crossentropy, throttle using Base.Iterators: repeated
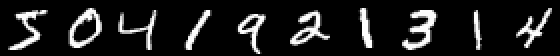
Contohnya menarik karena sudah ada sepuluh pintu keluar. Vektor One-hot yang disebut berguna di sini.
labels = MNIST.labels()
10×60000 Flux.OneHotMatrix{Array{Flux.OneHotVector,1}}: 0 1 0 0 0 0 0 0 0 0 0 0 0 … 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 … 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0
Kami mendefinisikan rantai neuron sebagai model, cross-entropy akan menjadi fungsi yang hilang, dan Adam sebagai metode optimisasi:
m = Chain( Dense(28^2, 32, relu), Dense(32, 10), softmax) loss(x, y) = crossentropy(m(x), y) accuracy(x, y) = mean(onecold(m(x)) .== onecold(y)) dataset = repeated((X, Y), 20) evalcb = () -> @show(loss(X, Y)) opt = ADAM()
Berlatihlah dalam mode hemat, tetapi mencetak kerugian setiap 10 detik:
for i = 1:10 Flux.train!(loss, params(m), dataset, opt, cb = throttle(evalcb, 10)) end
accuracy(X, Y) 0.64545
Dan periksa data yang tidak digunakan dalam pelatihan
Jaringan saraf pada Julia sederhana dan sangat menarik! Bahkan jika tidak perlu mencari koneksi antara bidang aktivitas Anda dan pembelajaran mesin, Anda setidaknya harus merasakan keingintahuan ini, yang diteriakkan dari semua sudut, dan tidak akan ada kekurangan alat!
Semua panas CPU moderat!