Pengembang dari University of Edinburgh memperkenalkan algoritma baru untuk menciptakan gerakan karakter realistis dalam game. Dilatih pada lintasan Gerak Tangkap, jaringan saraf mencoba untuk menyalin gerakan orang sungguhan, tetapi pada saat yang sama menyesuaikannya dengan karakter permainan video.
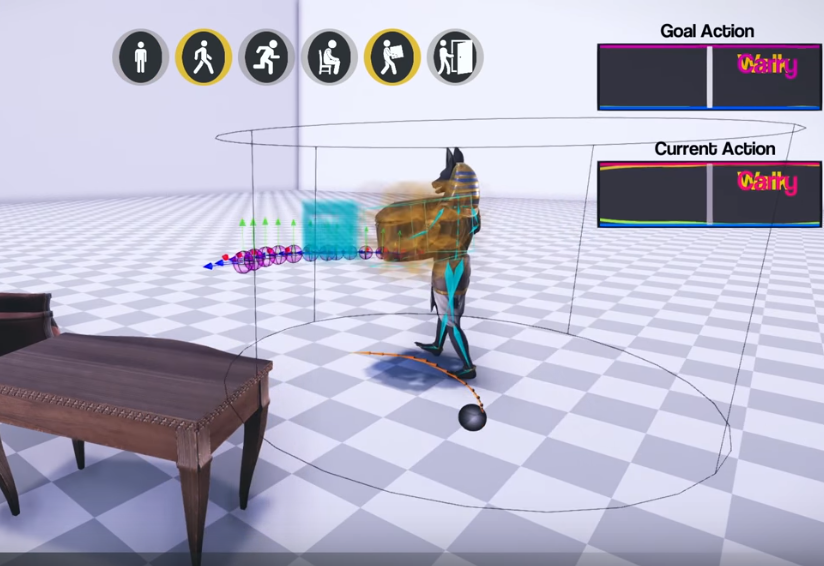
Satu jaringan saraf mampu mengelola beberapa aksi dalam game sekaligus. Membuka pintu, memindahkan barang, menggunakan furnitur. Pada saat yang sama, ia secara dinamis mengubah posisi kaki dan lengan sehingga karakter dapat secara realistis memegang laci dengan ukuran berbeda, duduk di kursi dengan ukuran berbeda, dan juga merangkak ke lorong-lorong dengan ketinggian yang berbeda.
Biasanya, di bawah kendali karakter dalam game menggunakan AI, itu berarti kontrol penuh atas upaya di anggota badan, berdasarkan beberapa jenis mesin fisik yang meniru hukum fisika. Ini adalah domain dari pembelajaran mesin yang disebut Reinforcement Learning. Sayangnya, dengan cara ini, gerakan realistis belum
dapat dicapai.
Di sisi lain, Anda dapat mencoba melatih jaringan saraf untuk mensimulasikan gerakan orang nyata yang ditangkap menggunakan Motion Capture. Dengan cara ini, sekitar setahun yang lalu, kemajuan signifikan dibuat dalam animasi realistis karakter 3d.


Ada beberapa karya ilmiah berturut-turut tentang topik ini, tetapi deskripsi paling lengkap dapat ditemukan di
Menuju karya
Virtual Stuntman di jaringan saraf DeepMimic (
https://www.youtube.com/watch?v=vppFvq2quQ0 ).
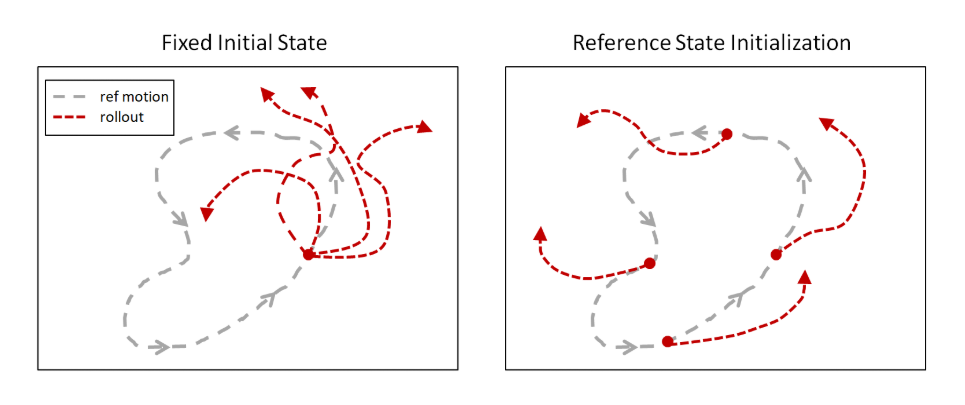
Gagasan utamanya adalah untuk mensimulasikan gerakan manusia selama pelatihan untuk memulai episode, bukan dari awal lagu Motion Capture, seperti yang mereka lakukan sebelumnya, tetapi dari titik acak di sepanjang jalur. Algoritma Learning Reinforcement Learning yang ada mengeksplorasi lingkungan dari titik awal, sehingga paling sering mereka tidak mencapai akhir lintasan. Tetapi jika setiap episode dimulai di sepanjang trek, maka kemungkinan meningkat bahwa jaringan saraf akan belajar mengulangi seluruh lintasan.
Kemudian, ide ini diambil di daerah yang sama sekali berbeda. Sebagai contoh, dengan mengajar orang untuk memainkan jaringan saraf melalui permainan, dan juga memulai episode bukan dari awal, tetapi dari titik acak (khususnya dalam kasus ini, dari akhir, dan secara bertahap pindah ke awal), OpenAI mengajarkan jaringan saraf
untuk memainkan Revenge Montezuma . Yang tidak menghasilkan algoritma Penguatan Belajar biasa sebelumnya.
Tanpa trik ini, upaya untuk melatih jaringan saraf untuk menyalin gerakan kompleks berakhir dengan kegagalan karena jaringan saraf menemukan jalan yang lebih pendek. Meskipun tidak memberikan hadiah sebesar itu untuk seluruh lintasan, tapi masih ada semacam hadiah. Sebagai contoh, alih-alih melakukan jungkir balik, jaringan saraf hanya sedikit memantul dan jatuh di punggungnya.

Tetapi dengan pendekatan ini, jaringan saraf tanpa masalah mempelajari lintasan hampir semua kompleksitas.

Masalah utama DeepMimic, yang mencegah langsung menerapkannya ke video game, adalah bahwa tidak mungkin untuk melatih jaringan saraf untuk melakukan beberapa animasi yang berbeda sekaligus. Itu perlu untuk melatih jaringan saraf yang terpisah untuk setiap animasi. Para penulis mencoba menggabungkan mereka dengan cara yang berbeda, tetapi lebih dari 3-4 animasi tidak dapat digabungkan.
Dalam karya baru, masalah ini juga tidak sepenuhnya diselesaikan, tetapi banyak kemajuan telah dibuat menuju transisi yang lancar antara berbagai animasi.
Perlu dicatat bahwa masalah ini mempengaruhi semua jaringan saraf animasi yang ada saat ini. Sebagai contoh,
jaringan saraf ini , yang juga terlatih dalam peniruan Motion Capture, mampu secara jujur mengendalikan sejumlah besar otot (326!) Dari karakter humanoid pada mesin fisik. Beradaptasi dengan bobot berbeda dari bobot terangkat dan berbagai cedera sendi. Tetapi pada saat yang sama, untuk setiap animasi, diperlukan jaringan saraf terlatih yang terpisah.
Harus dipahami bahwa tujuan dari jaringan saraf semacam itu bukan hanya untuk mengulang animasi manusia. Dan ulangi di mesin fisika. Pada saat yang sama, algoritma Reinforcement Learning menjadikan pelatihan ini andal dan tahan terhadap gangguan. Kemudian jaringan saraf seperti itu dapat ditransfer ke robot fisik yang berbeda dalam geometri atau massa dari seseorang, tetapi masih akan terus secara realistis mengulangi gerakan orang (mulai dari awal, seperti yang telah disebutkan, efek ini belum tercapai). Atau, seperti dalam pekerjaan di atas, Anda dapat menjelajahi bagaimana seseorang dengan cedera kaki akan bergerak untuk mengembangkan prostesis yang lebih nyaman.
Bahkan dalam DeepMimic pertama ada awal dari adaptasi semacam itu. Itu mungkin untuk memindahkan bola merah, dan karakter melemparkan bola ke arahnya setiap kali. Mengarahkan dan mengukur gaya lempar untuk mengenai target dengan tepat. Meskipun ia dilatih di satu-satunya lagu Motion Capture, yang tidak memberikan kesempatan seperti itu.

Oleh karena itu, ini dapat dianggap sebagai pelatihan AI lengkap, dan meniru gerakan manusia hanya memungkinkan Anda untuk mempercepat pembelajaran dan membuat gerakan secara visual lebih menarik, akrab bagi kami (meskipun dari sudut pandang jaringan saraf mereka mungkin bukan yang paling optimal pada saat yang sama).
Pekerjaan baru telah melangkah lebih jauh ke arah ini.
Tidak ada mesin fisik, itu murni sistem animasi untuk video game. Tetapi penekanannya adalah pada peralihan yang realistis antara banyak animasi. Dan untuk berinteraksi dengan item game: memindahkan barang, menggunakan furnitur, membuka pintu.

Arsitektur jaringan saraf terdiri dari dua bagian. Satu (jaringan Gating), berdasarkan keadaan saat ini dan tujuan saat ini, memilih animasi mana yang akan digunakan, dan yang lainnya (Jaringan prediksi gerak) memprediksi frame animasi berikutnya.

Semua ini dilatih pada satu set lagu Motion Capture menggunakan simulasi Penguatan Pembelajaran.
Tetapi pencapaian utama dari pekerjaan ini berbeda. Dalam cara para pengembang mengajarkan jaringan saraf untuk bekerja dengan benda-benda dengan ukuran yang berbeda dan masuk ke dalam bagian dengan lebar atau ketinggian yang berbeda. Sehingga posisi lengan dan kaki terlihat realistis dan sesuai dengan ukuran objek yang dengannya karakter berinteraksi dalam permainan.
Rahasianya sederhana: pembesaran!
Pertama, dari trek Motion Capture, mereka menentukan titik kontak tangan dengan sandaran tangan kursi. Kemudian mereka mengganti model kursi dengan yang lebih luas, dan menghitung ulang lintasan Gerak Tangkapan sehingga tangan menyentuh sandaran tangan pada titik yang sama, tetapi pada kursi yang lebih luas. Dan mereka memaksa jaringan saraf untuk mensimulasikan lintasan baru yang dihasilkan oleh Motion Capture ini. Demikian pula dengan dimensi kotak, ketinggian lorong, dll.
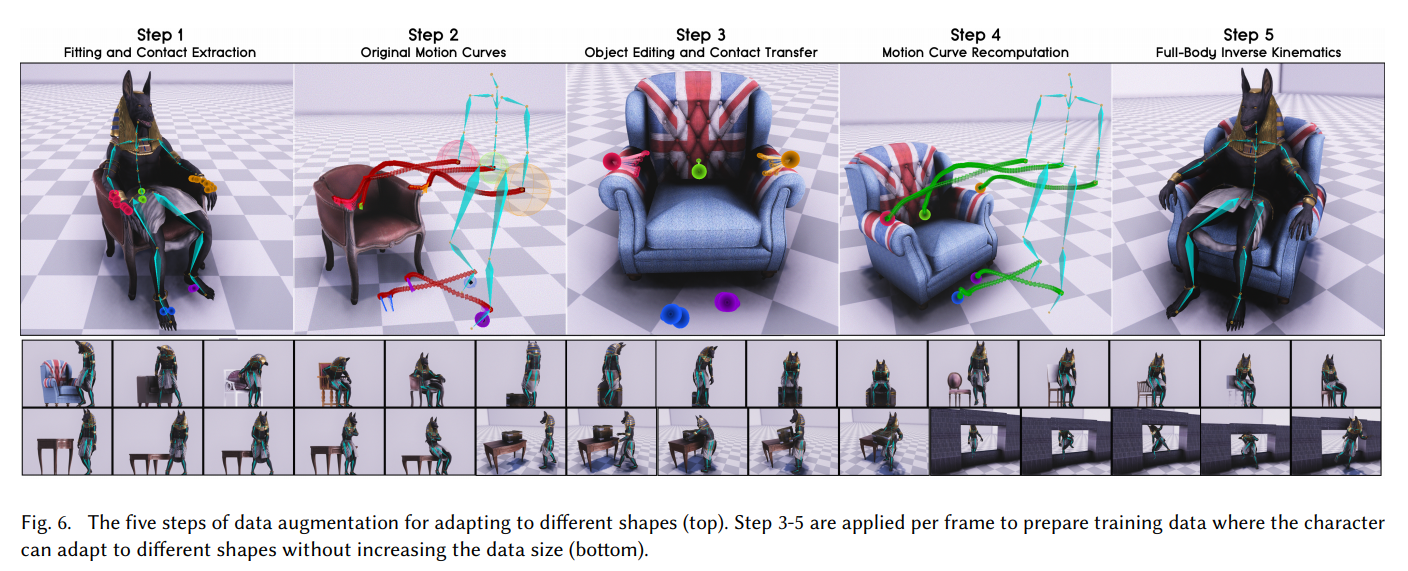
Mengulangi ini berkali-kali dengan berbagai model 3d dari lingkungan yang dengannya pemain akan berinteraksi, jaringan saraf telah belajar untuk secara realistis menangani objek dari berbagai ukuran.

Untuk berinteraksi dengan lingkungan dalam game itu sendiri, itu juga perlu untuk menguapkan benda-benda di sekitarnya sehingga itu berfungsi sebagai sensor pada input dari jaringan saraf.

Hasilnya adalah animasi yang sangat bagus untuk karakter permainan. Dengan transisi yang mulus antara tindakan dan dengan kemampuan untuk berinteraksi secara realistis dengan objek dari berbagai ukuran.
Saya sangat merekomendasikan menonton video jika ada yang belum melakukannya. Ini menjelaskan dengan sangat rinci bagaimana mereka mencapai ini.
Pendekatan ini dapat digunakan untuk animasi, termasuk hewan berkaki empat, mendapatkan kualitas dan realisme pergerakan hewan dan monster yang tak tertandingi:
Referensi
VideoHalaman proyek dengan sumberFile PDF dengan deskripsi terperinci tentang pekerjaan:
SIGGRAPH_Asia_2019 / Paper.pdf