Ada banyak cara untuk menguji API dan antarmuka. Sehubungan dengan pembukaan akses luas ke Acronis Cyber Platform, kami terpaksa mencari cara untuk menguji layanan “untuk daya tahan” dari berbagai posisi. Dalam posting ini, arsitek perangkat lunak utama Acronis Dmitry Salomatin berbicara tentang bagaimana kami memilih kerangka kerja untuk pengujian, kesulitan apa yang kami temui, dan perbaikan apa yang harus kami lakukan sendiri.

Saya harus segera mengatakan bahwa kami di Acronis sangat berhati-hati dalam menguji API. Faktanya adalah produk kami sendiri mengakses layanan melalui API yang sama yang digunakan untuk menghubungkan sistem eksternal. Oleh karena itu, pengujian kinerja setiap antarmuka diperlukan. Kami menguji operasi API dan secara terpisah memverifikasi operasi UI. Hasil pengujian akan memungkinkan Anda untuk mengevaluasi apakah API itu sendiri berfungsi dengan baik, serta antarmuka pengguna. Konfirmasikan pengembangan yang berhasil atau rumuskan tugas untuk pengembangan lebih lanjut.
Tetapi tes berbeda. Terkadang suatu layanan tidak langsung menunjukkan degradasi. Bahkan jika kami menjalankan layanan yang mirip dengan produk yang sudah dirilis dalam rilis, untuk verifikasi Anda dapat memuatnya dengan data yang sama yang digunakan "dalam prod". Dalam hal ini, Anda dapat melihat regresi, tetapi sama sekali tidak mungkin untuk menilai perspektif. Anda tidak tahu apa yang akan terjadi jika jumlah data meningkat tajam atau frekuensi permintaan meningkat.
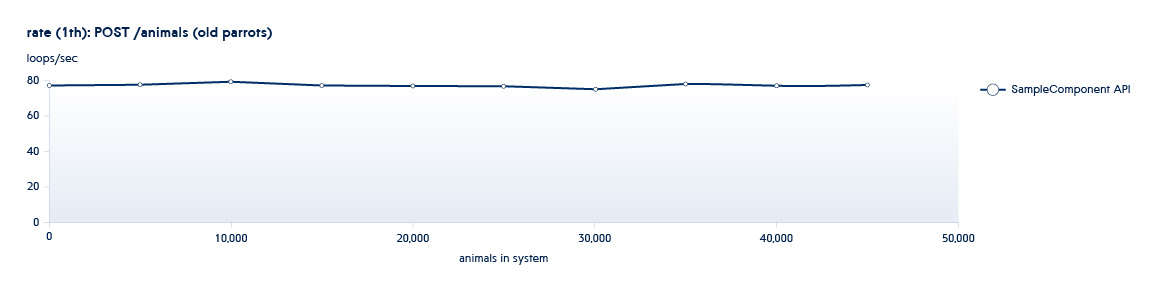
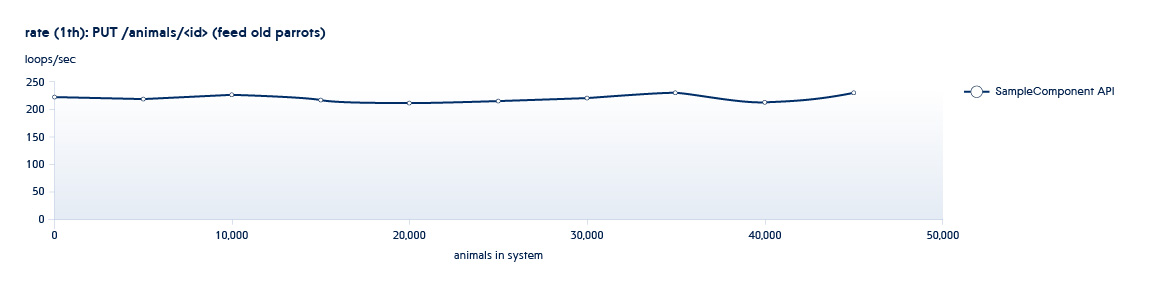
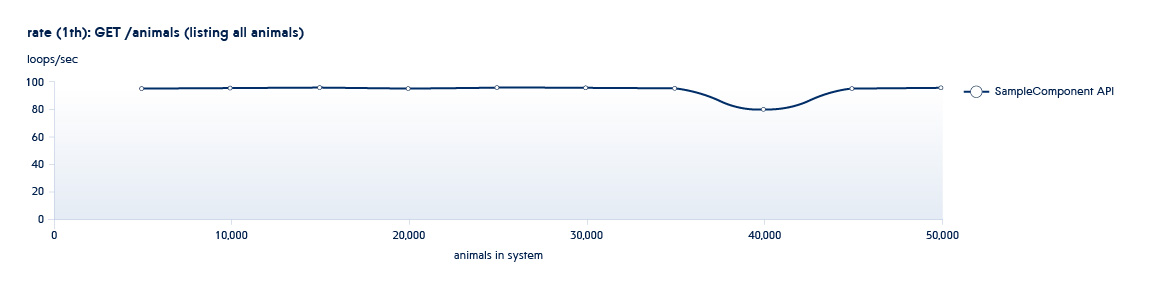
Di bawah ini adalah grafik yang menunjukkan bagaimana jumlah API yang diproses oleh backend per detik berubah dengan pertumbuhan data dalam sistem

Misalkan layanan yang kami uji adalah dalam keadaan khas dari awal jadwal ini. Dalam hal ini, bahkan dengan pertumbuhan sistem yang kecil, kecepatan API ini akan menurun tajam.
Untuk mengecualikan situasi seperti itu, kami meningkatkan jumlah data beberapa kali, menambah jumlah utas paralel untuk memahami bagaimana layanan akan berperilaku jika beban meningkat secara dramatis.
Namun ada satu lagi nuansa. Jika pekerjaan layanan "akrab" berubah sesuai dengan pertumbuhan jumlah data, perkembangannya, munculnya fungsi baru, dengan layanan baru situasinya bahkan lebih rumit. Ketika suatu layanan baru secara konseptual muncul dalam suatu produk, ia perlu dipertimbangkan dari berbagai sudut pandang. Untuk situasi ini, Anda perlu menyiapkan set data khusus, melakukan pengujian beban, menyarankan kemungkinan kasus penggunaan.
Fitur pengujian kinerja di Acronis
Biasanya, proses pengujian kami berlangsung dalam "pola spiral." Salah satu fase pengujian melibatkan penggunaan API untuk meningkatkan jumlah entitas (ukuran), dan yang kedua melakukan operasi baru pada set data yang ada (penggunaan). Semua tes dijalankan dalam jumlah utas berbeda. Misalnya, kami memiliki layanan Hewan, dan memiliki API berikut:
POST /animals PUT /animals/<id> GET /animals?filter=criteria
1 dan 2 adalah API yang disebut dalam tes ukuran - mereka meningkatkan jumlah entitas baru dalam sistem.
3 adalah API yang disebut dalam fase penggunaan. API ini memiliki banyak opsi penyaringan. Dengan demikian, akan ada lebih dari satu tes
Dengan demikian, dengan menjalankan tes ukuran dan penggunaan berulang, kami mendapatkan gambaran tentang perubahan kinerja sistem dengan pertumbuhannya

Kerangka kerja yang dibutuhkan ...
Untuk melakukan pengujian skala besar terhadap sejumlah besar layanan baru dan yang diperbarui, kami membutuhkan kerangka kerja fleksibel yang memungkinkan kami menjalankan skrip yang berbeda. Dan hal utama adalah untuk benar-benar menguji API, dan tidak hanya membuat beban pada layanan dengan operasi berulang.
Pengujian kinerja dapat dilakukan baik pada beban sintetis maupun menggunakan pola beban yang dicatat dari produksi. Kedua pendekatan memiliki pro dan kontra mereka. Metode dengan beban nyata dapat lebih dikarakteristikkan sebagai pengujian tegangan - kami mendapatkan gambaran nyata tentang kinerja sistem dalam beban seperti itu, tetapi kami tidak memiliki kemampuan untuk dengan mudah mengidentifikasi area masalah, mengukur throughput komponen secara individual, kami tidak mendapatkan angka pasti yang memuat komponen individual yang dapat bertahan. Dalam hal pendekatan sintetis, kami mendapatkan angka pastinya, kami memiliki fleksibilitas besar, dan kami dapat dengan mudah memperbaiki area yang bermasalah, dan dengan menjalankan beberapa skrip uji secara paralel, kami dapat mereproduksi beban stres. Kerugian utama dari pendekatan kedua adalah biaya tenaga kerja yang tinggi untuk menulis skrip tes, serta meningkatnya risiko kehilangan beberapa skrip penting. Karena itu, kami memutuskan untuk menempuh jalan yang lebih sulit.
Jadi, pilihan kerangka kerja ditentukan oleh tugas. Dan tugas kita adalah:
- Menemukan kemacetan API
- Periksa ketahanan terhadap beban tinggi
- Untuk mengevaluasi efektivitas layanan dengan pertumbuhan volume data
- Identifikasi kesalahan kumulatif yang terjadi seiring waktu
Ada begitu banyak kerangka kerja Kinerja di pasar yang dapat memecat sejumlah besar permintaan yang identik. Banyak dari mereka tidak mengizinkan perubahan apa pun secara internal (misalnya, Apache Benchmark) atau dengan kemampuan terbatas untuk menggambarkan skrip (misalnya, JMeter).
Kami biasanya menggunakan skrip yang lebih kompleks dalam pengujian. Seringkali, panggilan API harus dilakukan secara berurutan - satu demi satu, atau untuk mengubah parameter permintaan sesuai dengan beberapa jenis logika. Contoh paling sederhana ketika kami ingin menguji API REST dari formulir
PUT /endpoint/resource/<id>
Dalam hal ini, Anda perlu mengetahui terlebih dahulu <id> sumber daya yang ingin kami ubah untuk mengukur waktu eksekusi kueri net.
Oleh karena itu, kita memerlukan kemampuan untuk membuat skrip untuk menjalankan kueri pengujian yang kompleks.
Lebih cepat
Karena produk Acronis dirancang untuk memuat tinggi, kami menguji API dalam puluhan ribu permintaan per detik. Ternyata tidak semua kerangka kerja dapat memungkinkan ini dilakukan. Sebagai contoh, Python tidak selalu dan tidak selalu mungkin digunakan untuk pengujian, karena karena kekhasan bahasa kemampuan untuk membuat beban multi-threaded besar terbatas
Masalah lain adalah penggunaan sumber daya. Sebagai contoh, kami pertama kali melihat kerangka kerja Locust, yang dapat dijalankan dari beberapa perangkat keras sekaligus dan mendapatkan kinerja yang baik. Tetapi pada saat yang sama, banyak sumber daya dihabiskan untuk pekerjaan sistem pengujian, dan ternyata mahal untuk dioperasikan.
Sebagai hasilnya, kami memilih kerangka kerja K6, yang memungkinkan kami untuk menggambarkan skrip dalam Javascript lengkap, dan memberikan kinerja di atas rata-rata. Kerangka kerja ini ditulis dalam Go, dan dengan cepat mendapatkan popularitas. Misalnya, di Github, proyek ini telah menerima hampir 5,5 ribu bintang! K6 secara aktif berkembang, dan masyarakat telah mengusulkan hampir 3 ribu komitmen, dan proyek ini memiliki 50 kontributor yang telah membuat 36 cabang kode. Tentu saja, K6 masih jauh dari ideal, tetapi secara bertahap kerangka kerja menjadi lebih baik, dan Anda dapat membaca tentang perbandingannya dengan Jmeter di
sini .
Kesulitan dan solusinya
Mengingat "kemudaan" K6, bahkan setelah pilihan kerangka yang seimbang, kami menghadapi sejumlah masalah. Sebagai contoh, sebelum menguji API seperti / titik akhir /, Anda harus terlebih dahulu menemukan titik akhir ini entah bagaimana. Kami tidak dapat menggunakan nilai yang sama, karena karena caching hasilnya akan salah.
Anda bisa mendapatkan data yang Anda butuhkan dengan berbagai cara:
- Anda dapat meminta mereka melalui API
- Anda dapat menggunakan akses langsung ke database
Metode kedua bekerja lebih cepat, dan ketika menggunakan DB relasional sering ternyata jauh lebih nyaman, karena memungkinkan Anda untuk menghemat waktu yang signifikan selama tes yang panjang. Satu-satunya "tetapi" adalah bahwa Anda dapat menggunakannya hanya jika kode layanan dan tes ditulis oleh orang yang sama. Karena untuk bekerja melalui database, tes harus selalu mutakhir. Namun, dalam kasus K6, kerangka kerja tidak memiliki mekanisme akses ke database. Karena itu, saya harus menulis modul yang sesuai sendiri.
Masalah lain muncul ketika menguji API non-idempoten. Dalam hal ini, penting bahwa mereka dipanggil hanya sekali dengan parameter yang sama (misalnya, DELETE API). Dalam pengujian kami, kami menyiapkan data pengujian terlebih dahulu, pada tahap pengaturan, saat sistem disiapkan dan disiapkan. Dan selama pengujian, pengukuran dilakukan dari panggilan API murni, karena waktu dan sumber daya untuk menyiapkan data tidak lagi diperlukan. Namun, ini menimbulkan masalah pendistribusian data yang telah disiapkan sebelumnya melalui aliran utama yang tidak disinkronkan. Masalah ini berhasil diselesaikan dengan menulis antrian data internal. Tapi ini adalah topik besar, yang akan kita bahas di posting selanjutnya.
Kerangka Siap
Singkatnya, saya ingin mencatat bahwa tidak mudah untuk menemukan kerangka kerja yang sepenuhnya siap pakai, dan saya masih harus menyelesaikan beberapa hal dengan tangan saya. Namun demikian, hari ini kami memiliki alat yang cocok untuk kami, yang, dengan mempertimbangkan peningkatan, memungkinkan kami untuk melakukan tes yang kompleks, membuat simulasi beban tinggi untuk menjamin fungsionalitas API dan GUI dalam kondisi yang berbeda.
Dalam posting berikutnya, saya akan berbicara tentang bagaimana kami memecahkan masalah pengujian layanan yang mendukung koneksi simultan dari ratusan ribu koneksi menggunakan sumber daya minimal.