Halo semuanya! Nama saya Vlad dan saya bekerja sebagai ilmuwan data dalam tim teknologi bicara Tinkoff yang digunakan dalam asisten suara kami Oleg.
Dalam artikel ini, saya ingin memberikan gambaran singkat tentang teknologi sintesis pidato yang digunakan dalam industri dan berbagi pengalaman tim kami dalam membangun mesin sintesis kami sendiri.

Sintesis ucapan
Sintesis ucapan adalah penciptaan suara berdasarkan teks. Masalah ini hari ini diselesaikan dengan dua pendekatan:
- Pemilihan unit [1], atau pendekatan gabungan. Ini didasarkan pada menempelkan fragmen dari audio yang direkam. Sejak akhir 90-an, telah lama dianggap sebagai standar de facto untuk mengembangkan mesin sintesis bicara. Misalnya, suara yang terdengar dengan metode pemilihan unit dapat ditemukan di Siri [2].
- Sintesis ucapan parametrik [3], intinya adalah membangun model probabilistik yang memprediksi sifat akustik dari sinyal audio untuk teks yang diberikan.
Pidato model pemilihan unit berkualitas tinggi, variabilitas rendah dan membutuhkan sejumlah besar data untuk pelatihan. Pada saat yang sama, untuk model pelatihan parametrik, jumlah data yang jauh lebih kecil diperlukan, mereka menghasilkan intonasi yang lebih beragam, tetapi sampai saat ini mereka mengalami kualitas suara yang agak buruk secara keseluruhan dibandingkan dengan pendekatan pemilihan unit.
Namun, dengan perkembangan teknologi pembelajaran yang mendalam, model sintesis parametrik telah mencapai pertumbuhan yang signifikan dalam semua metrik kualitas dan mampu menciptakan ucapan yang secara praktis tidak dapat dibedakan dari ucapan manusia.
Metrik kualitas
Sebelum berbicara tentang model sintesis ucapan mana yang lebih baik, Anda perlu menentukan metrik kualitas yang digunakan algoritme.
Karena teks yang sama dapat dibaca dalam jumlah cara yang tak terbatas, apriori cara yang tepat untuk mengucapkan frasa tertentu tidak ada. Oleh karena itu, seringkali metrik untuk kualitas sintesis ucapan bersifat subyektif dan tergantung pada persepsi pendengar.
Metrik standar adalah MOS (skor pendapat rata-rata), penilaian rata-rata dari kealamian bicara, yang diberikan oleh penilai untuk audio yang disintesis pada skala 1 sampai 5. Satu berarti suara yang benar-benar tidak masuk akal, dan lima berarti suara yang tidak dapat dibedakan dari manusia. Rekaman orang sungguhan biasanya mendapatkan sekitar 4,5, dan nilai lebih dari 4 dianggap cukup tinggi.
Cara kerja sintesis ucapan
Langkah pertama untuk membangun sistem sintesis pidato adalah mengumpulkan data untuk pelatihan. Biasanya ini adalah rekaman audio berkualitas tinggi di mana penyiar membaca frasa yang dipilih secara khusus. Ukuran perkiraan dataset yang diperlukan untuk model pemilihan unit pelatihan adalah 10-20 jam bicara murni [2], sedangkan untuk metode parametrik jaringan saraf, batas atas adalah sekitar 25 jam [4, 5].
Kami membahas kedua teknologi sintesis.
Pemilihan unit
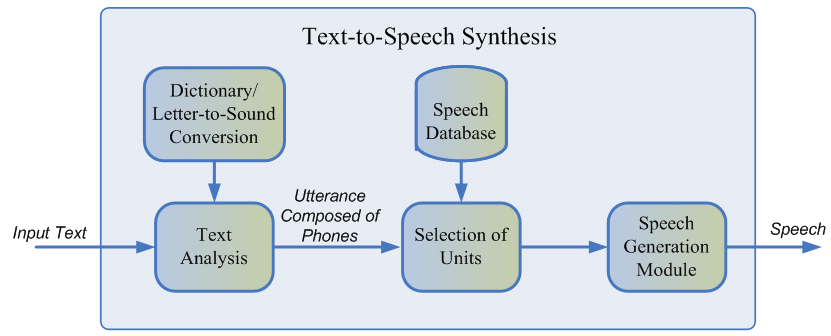
Biasanya, ucapan pembicara yang direkam tidak dapat mencakup semua kasus yang memungkinkan di mana sintesis akan digunakan. Oleh karena itu, inti dari metode ini adalah untuk membagi seluruh basis audio menjadi fragmen kecil yang disebut unit, yang kemudian direkatkan menggunakan minimal pasca pemrosesan. Unit biasanya merupakan unit bahasa akustik minimal, seperti setengah telepon atau dipon [2].
Seluruh proses pembuatan terdiri dari dua tahap: frontend NLP, yang bertanggung jawab untuk mengekstraksi representasi linguistik teks, dan backend, yang menghitung fungsi unit penalti untuk fitur linguistik yang diberikan. Frontend NLP meliputi:
- Tugas menormalkan teks adalah menerjemahkan semua karakter non-huruf (angka, tanda persen, mata uang, dan sebagainya) ke dalam representasi verbal mereka. Misalnya, "5%" harus dikonversi menjadi "lima persen".
- Mengekstraksi fitur-fitur linguistik dari teks yang dinormalisasi: representasi fonem, stres, bagian-bagian pembicaraan dan sebagainya.
Biasanya, frontend NLP diimplementasikan menggunakan aturan yang ditentukan secara manual untuk bahasa tertentu, tetapi baru-baru ini ada peningkatan bias terhadap penggunaan model pembelajaran mesin [7].
Denda yang diestimasi oleh subsistem backend adalah jumlah dari biaya target, atau korespondensi dari representasi akustik unit untuk fonem tertentu, dan biaya gabungan, yaitu, kesesuaian menghubungkan dua unit tetangga. Untuk mengevaluasi fungsi-fungsi halus, seseorang dapat menggunakan aturan atau model akustik sintesis parametrik yang sudah terlatih [2]. Pemilihan urutan unit paling optimal dari sudut pandang hukuman yang ditentukan di atas terjadi menggunakan algoritma Viterbi [1].
Nilai perkiraan model pemilihan unit MOS untuk bahasa Inggris: 3.7-4.1 [2, 4, 5].
Keuntungan dari pendekatan pemilihan unit:
- Suara alami.
- Generasi kecepatan tinggi.
- Ukuran model yang kecil - ini memungkinkan Anda untuk menggunakan sintesis secara langsung di perangkat seluler Anda.
Kekurangan:
- Pidato yang disintesis adalah monoton, tidak mengandung emosi.
- Artefak perekatan karakteristik.
- Dibutuhkan basis pelatihan yang cukup besar dari data audio untuk mencakup semua jenis konteks.
- Pada prinsipnya, itu tidak dapat menghasilkan suara yang tidak ditemukan dalam set pelatihan.
Sintesis pidato parametrik
Pendekatan parametrik didasarkan pada gagasan membangun model probabilistik yang memperkirakan distribusi fitur akustik teks yang diberikan.
Proses pembuatan pidato dalam sintesis parametrik dapat dibagi menjadi empat tahap:
- Frontend NLP adalah tahap yang sama dari preprocessing data seperti dalam pendekatan pemilihan unit, yang hasilnya adalah sejumlah besar fitur linguistik peka konteks.
- Model durasi memprediksi durasi fonem.
- Model akustik yang mengembalikan distribusi fitur akustik di atas yang linguistik. Fitur akustik termasuk nilai frekuensi fundamental, representasi spektral sinyal, dan sebagainya.
- Seorang vocoder menerjemahkan fitur akustik menjadi gelombang suara.
Untuk durasi pelatihan dan model akustik, model Markov tersembunyi [3], jaringan saraf dalam, atau varietas berulangnya [6] dapat digunakan. Seorang vocoder tradisional adalah algoritma yang didasarkan pada model sumber-filter [3], yang mengasumsikan bahwa ucapan adalah hasil dari penerapan filter derau linear ke sinyal asli.
Kualitas bicara keseluruhan dari metode parametrik klasik cukup rendah karena sejumlah besar asumsi independen tentang struktur proses pembuatan suara.
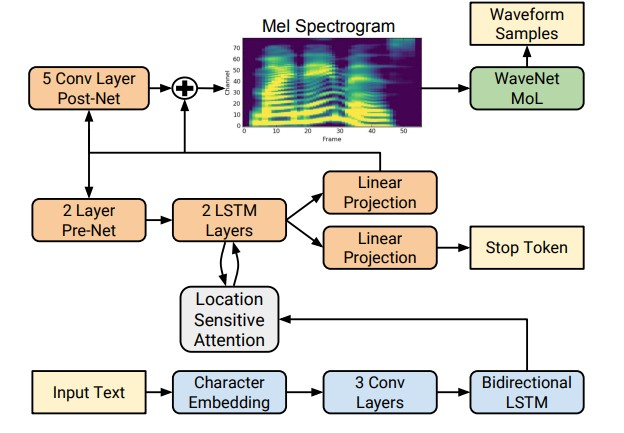
Namun, dengan munculnya teknologi pembelajaran yang mendalam, menjadi mungkin untuk melatih model ujung ke ujung yang secara langsung memprediksi tanda akustik melalui surat. Misalnya, jaringan saraf Tacotron [4] dan Tacotron 2 [5] memasukkan urutan huruf dan mengembalikan spektrogram kapur menggunakan algoritma seq2seq [8]. Dengan demikian, langkah 1-3 dari pendekatan klasik digantikan oleh jaringan saraf tunggal. Diagram di bawah ini menunjukkan arsitektur jaringan Tacotron 2, yang mencapai kualitas suara yang cukup tinggi.
Faktor lain dari peningkatan yang signifikan dalam kualitas pidato yang disintesis adalah penggunaan neural network vocoders alih-alih algoritma pemrosesan sinyal digital.
Vokoder pertama seperti itu adalah jaringan saraf WaveNet [9], yang secara berurutan, langkah demi langkah, meramalkan amplitudo gelombang suara.
Karena penggunaan sejumlah besar lapisan convolutional dengan celah untuk menangkap lebih banyak konteks dan melompati koneksi dalam arsitektur jaringan, dimungkinkan untuk mencapai peningkatan sekitar 10% dalam MOS dibandingkan dengan model pemilihan unit. Diagram di bawah ini menunjukkan arsitektur jaringan WaveNet.

Kerugian utama WaveNet adalah kecepatan rendah yang terkait dengan rangkaian pengambilan sampel sinyal serial. Masalah ini dapat diselesaikan dengan menggunakan optimasi teknik untuk arsitektur besi tertentu, atau dengan mengganti skema pengambilan sampel dengan yang lebih cepat.
Kedua pendekatan telah berhasil diimplementasikan di industri. Yang pertama adalah di Tinkoff.ru, dan sebagai bagian dari pendekatan kedua, Google memperkenalkan jaringan Parallel WaveNet [10] pada tahun 2017, yang pencapaiannya digunakan di Asisten Google.
Nilai perkiraan MOS untuk metode jaringan saraf: 4.4-4.5 [5, 11], yaitu, ucapan yang disintesis secara praktis tidak berbeda dari ucapan manusia.
Keuntungan sintesis parametrik:
- Suara alami dan halus saat menggunakan pendekatan ujung ke ujung.
- Variasi intonasi yang lebih besar.
- Gunakan lebih sedikit data daripada model pemilihan unit.
Kekurangan:
- Kecepatan rendah dibandingkan dengan pemilihan unit.
- Kompleksitas komputasi yang hebat.
Cara Kerja Sintesis Bicara Tinkoff
Sebagai berikut dari ulasan, metode sintesis ucapan parametrik berdasarkan jaringan saraf saat ini secara signifikan unggul dalam kualitas dari pendekatan pemilihan unit dan jauh lebih mudah untuk dikembangkan. Karena itu, untuk membangun mesin sintesis kami sendiri, kami menggunakannya.
Untuk model pelatihan, sekitar 25 jam pidato murni seorang pembicara profesional digunakan. Membaca teks dipilih secara khusus sehingga sebagian besar mencakup fonetik pidato sehari-hari. Selain itu, untuk menambah variasi pada sintesis intonasi, kami meminta penyiar untuk membaca teks dengan ekspresi tergantung pada konteksnya.
Arsitektur solusi kami secara konseptual terlihat seperti ini:
- Frontend NLP, yang mencakup normalisasi teks jaringan saraf dan model untuk menempatkan jeda dan tekanan.
- Tacotron 2 menerima surat sebagai masukan.
- WaveNet Autoregressive, bekerja secara real time pada CPU.
Berkat arsitektur ini, mesin kami menghasilkan pidato ekspresif berkualitas tinggi secara real time, tidak memerlukan membangun kamus fonem, dan memungkinkan untuk mengontrol tekanan dalam kata-kata individual. Contoh audio yang disintesis dapat didengar dengan mengklik tautan .
Referensi:
[1] AJ Hunt, AW Black. Seleksi unit dalam sistem sintesis pidato concatenative menggunakan database pidato besar, ICASSP, 1996.
[2] T. Capes, P. Coles, A. Conkie, L. Golipour, A. Hadjitarkhani, Q. Hu, N. Huddleston, M. Hunt, J. Li, M. Neeracher, K. Prahallad, T. Raitio , R. Rasipuram, G. Townsend, B. Williamson, D. Winarsky, Z. Wu, H. Zhang. Unit Pembelajaran Terpandu Dalam-Pembelajaran Siri Sistem Pemilihan Text-to-Speech System, Interspeech, 2017.
[3] H. Zen, K. Tokuda, AW Black. Sintesis pidato parametrik statistik, Komunikasi Bicara, Vol. 51, tidak. 11, hlm. 1039-1064, 2009.
[4] Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Chen Zhifeng, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark, Rif A. Saurous . Tacotron: Menuju Sintesis Bicara End-to-End.
[5] Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Wang Yuxuan, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu. Sintesis TTS Alami dengan Mengkondisikan WaveNet pada Prediksi Mel Spectrogram.
[6] Heiga Zen, Andrew Senior, Mike Schuster. Sintesis pidato parametrik statistik menggunakan jaringan saraf dalam.
[7] Hao Zhang, Richard Sproat, Axel H. Ng, Felix Stahlberg, Peng Xiaochang, Kyle Gorman, Brian Roark. Model Saraf Normalisasi Teks untuk Aplikasi Bicara.
[8] Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Sequence to Sequence Learning dengan Neural Networks.
[9] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu. WaveNet: Model Generatif untuk Audio Mentah.
[10] Aaron van den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, George van den Driessche, Edward Lockhart, Luis C. Cobo, Florian Stimberg, Norman Casagrande, Dominik Grewe, Seb Noury, Sander Dieleman , Erich Elsen, Nal Kalchbrenner, Heiga Zen, Alex Graves, Helen King, Tom Walters, Dan Belov, Demis Hassabis. Parallel WaveNet: Sintesis Pidato High-Fidelity Cepat.
[11] Wei Ping Kainan Peng Jitong Chen. ClariNet: Generasi Gelombang Paralel dalam Teks-ke-Akhir dari ujung ke ujung.
[12] Dario Rethage, Jordi Pons, Xavier Serra. A Wavenet for Speech Denoising.