
Jaringan saraf dalam visi komputer sedang aktif berkembang, banyak tugas yang masih jauh dari penyelesaian. Untuk menjadi tren di bidang Anda, cukup ikuti influencer di Twitter dan baca artikel yang relevan di arXiv.org. Tetapi kami memiliki kesempatan untuk pergi ke Konferensi Internasional tentang Visi Komputer (ICCV) 2019. Tahun ini diadakan di Korea Selatan. Sekarang kami ingin berbagi dengan para pembaca Habr yang kami lihat dan pelajari.
Ada banyak dari kami dari Yandex: pengembang kendaraan tak berawak, peneliti, dan mereka yang terlibat dalam tugas CV dalam layanan tiba. Tapi sekarang kami ingin memperkenalkan sudut pandang yang sedikit subyektif dari tim kami - laboratorium kecerdasan mesin (Yandex MILAB). Orang lain mungkin melihat konferensi dari sudut pandang mereka.
Apa yang dilakukan laboratoriumKami melakukan proyek eksperimental terkait dengan pembuatan gambar dan musik untuk tujuan hiburan. Kami terutama tertarik pada jaringan saraf yang memungkinkan Anda mengubah konten dari pengguna (untuk foto tugas ini disebut manipulasi gambar).
Contoh hasil pekerjaan kami dari konferensi YaC 2019.
Ada banyak konferensi ilmiah, tetapi konferensi puncak yang disebut A * menonjol dari mereka, di mana artikel tentang teknologi yang paling menarik dan penting biasanya diterbitkan. Tidak ada daftar konferensi A * yang pasti, berikut adalah contoh dan tidak lengkap: NeurIPS (sebelumnya NIPS), ICML, SIGIR, WWW, WSDM, KDD, ACL, CVPR, ICCV, ECCV. Tiga yang terakhir mengkhususkan diri dalam topik CV.
Sekilas tentang ICCV: poster, tutorial, lokakarya, stan
1075 makalah diterima di konferensi, pesertanya 7.500. 103 orang datang dari Rusia, ada artikel dari karyawan Yandex, Skoltech, Samsung AI Center Moscow dan Samara University. Tahun ini, tidak banyak peneliti top mengunjungi ICCV, tetapi di sini, misalnya, Alexey (Alyosha) Efros, yang selalu mengumpulkan banyak orang:

Di semua konferensi semacam itu, artikel disajikan dalam bentuk poster (
lebih banyak tentang formatnya), dan yang terbaik juga disajikan dalam bentuk laporan singkat.
Ini bagian dari pekerjaan Rusia Pada tutorial Anda dapat membenamkan diri dalam beberapa bidang studi, itu menyerupai ceramah di universitas. Itu dibaca oleh satu orang, biasanya tanpa membicarakan karya tertentu. Contoh tutorial keren (
Michael Brown, Memahami Warna dan Pipa Pemrosesan Gambar Dalam Kamera untuk Computer Vision ):

Sebaliknya, dalam lokakarya, mereka berbicara tentang artikel. Biasanya ini adalah pekerjaan dalam beberapa topik sempit, cerita dari para pemimpin laboratorium tentang semua pekerjaan siswa terbaru, atau artikel yang tidak diterima di konferensi utama.
Perusahaan sponsor datang ke ICCV dengan stan. Tahun ini, Google, Facebook, Amazon dan banyak perusahaan internasional lainnya tiba, serta sejumlah besar startup - Korea dan Cina. Ada banyak startup yang berspesialisasi dalam markup data. Ada pertunjukan di tribun, Anda dapat mengambil barang dagangan dan mengajukan pertanyaan. Perusahaan sponsor memiliki pihak untuk berburu. Mereka berhasil melanjutkan jika meyakinkan perekrut bahwa Anda tertarik dan bahwa Anda berpotensi diwawancarai. Jika Anda menerbitkan artikel (atau, lebih lanjut, berbicara dengannya), memulai atau mengakhiri PhD - ini merupakan nilai tambah, tetapi kadang-kadang Anda dapat menyetujui suatu pendirian, mengajukan pertanyaan menarik kepada para insinyur perusahaan.
Tren
Konferensi ini memungkinkan Anda untuk melirik seluruh area CV. Dengan jumlah poster dari topik tertentu, Anda dapat mengevaluasi seberapa panas topik tersebut. Beberapa kesimpulan meminta kata kunci:

Nol-tembakan, satu-tembakan, beberapa-tembakan, diawasi sendiri dan semi-diawasi: pendekatan baru untuk masalah yang telah lama dipelajari
Orang-orang belajar menggunakan data dengan lebih efisien. Misalnya, dalam
FUNIT, Anda dapat membuat ekspresi wajah binatang yang tidak ada dalam set pelatihan (menerapkan beberapa gambar referensi dalam aplikasi). Gagasan Deep Image Prior telah dikembangkan, dan sekarang jaringan
GAN dapat dilatih dalam satu gambar - kita akan membicarakannya nanti
dalam sorotan . Anda dapat menggunakan pengawasan sendiri untuk pra-pelatihan (menyelesaikan masalah yang memungkinkan untuk mensintesis data yang selaras, misalnya, untuk memprediksi sudut rotasi gambar) atau untuk belajar pada saat yang sama dari data yang ditandai dan tidak berlabel. Dalam pengertian ini, mahkota penciptaan dapat dianggap sebagai artikel
S4L: Pembelajaran yang Semi-Supervised dengan Supervisi . Tetapi pra-pelatihan di ImageNet
tidak selalu membantu.

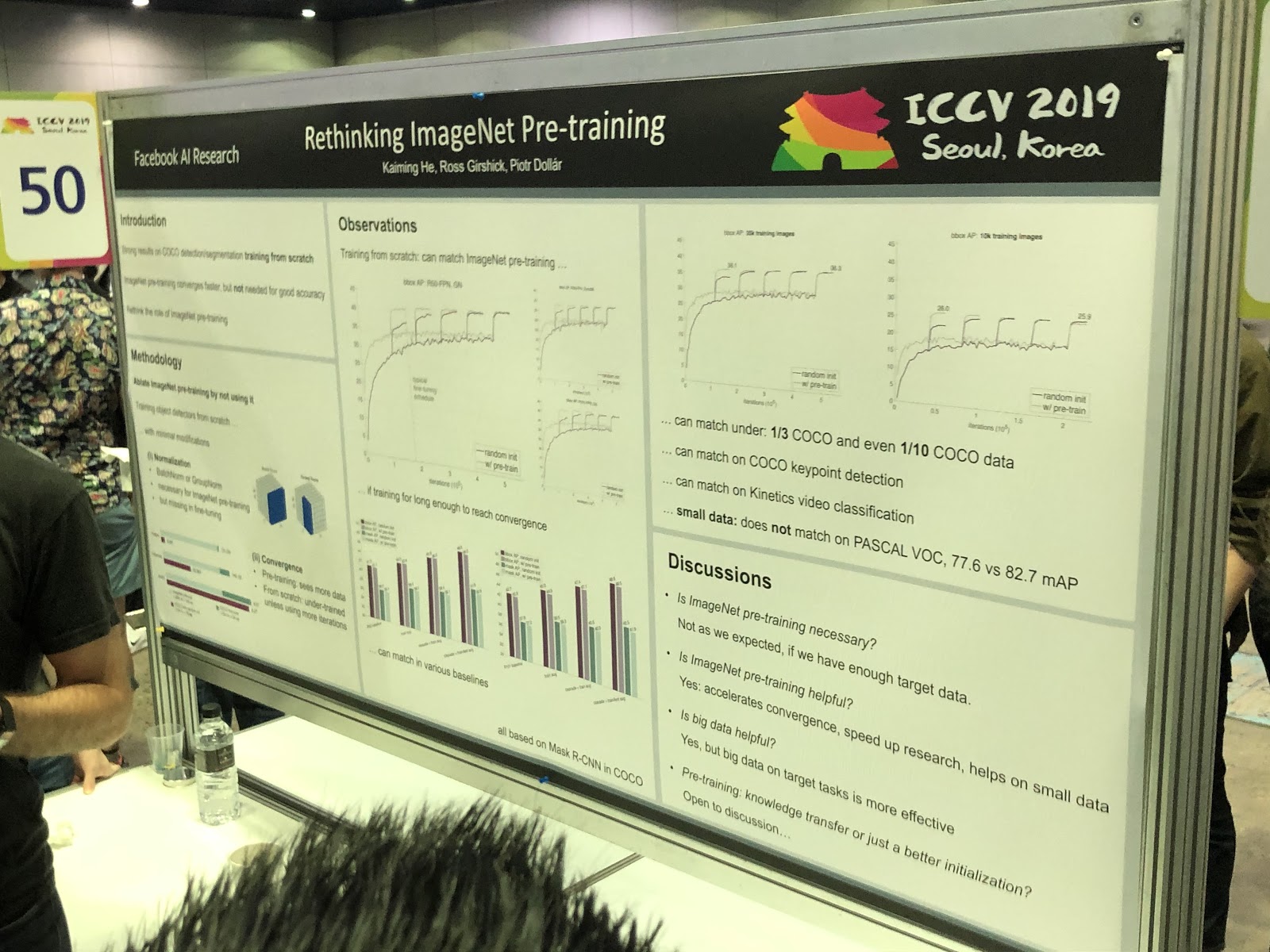
3D dan 360 °
Tugas, sebagian besar diselesaikan untuk foto (segmentasi, deteksi), memerlukan penelitian tambahan untuk model 3D dan video panorama. Kami melihat banyak artikel tentang konversi RGB dan
RGB-D ke 3D. Beberapa tugas, seperti menentukan pose seseorang (estimasi pose), diselesaikan lebih alami jika kita beralih ke model tiga dimensi. Namun sejauh ini tidak ada konsensus tentang bagaimana tepatnya mewakili model 3D - dalam bentuk kotak, awan titik,
voxel atau
SDF . Berikut ini pilihan lain:
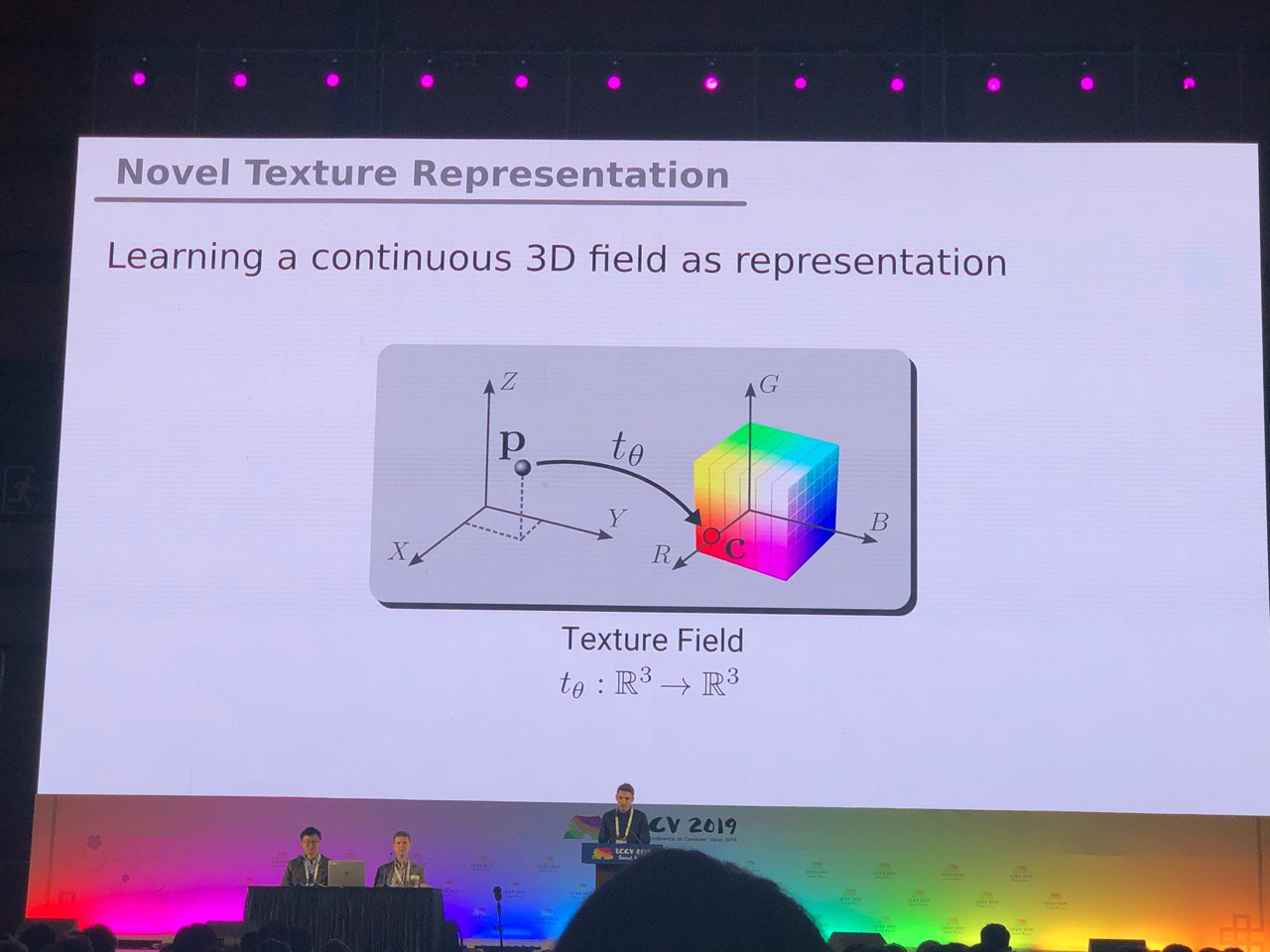
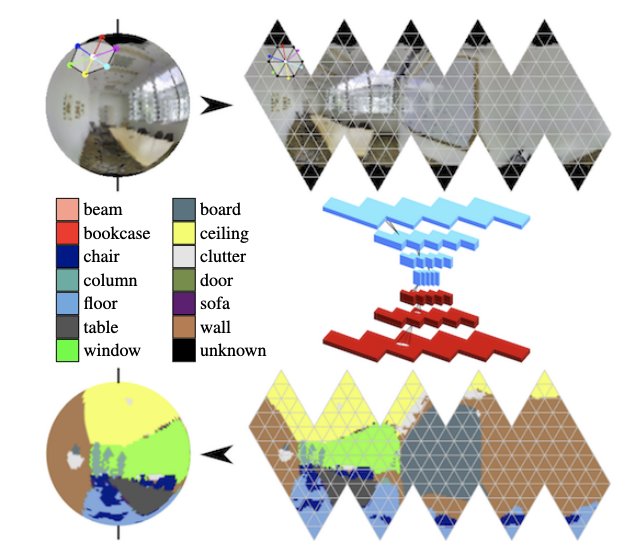
Dalam panorama, konvolusi pada bola secara aktif berkembang (lihat
Segmentasi Semantic yang sadar Orientasi pada Icosahedron Spheres ) dan pencarian objek-objek kunci dalam sebuah bingkai.
Definisi postur dan prediksi pergerakan manusia
Untuk menentukan pose dalam 2D, sudah ada kesuksesan - sekarang fokus telah bergeser ke arah bekerja dengan banyak kamera dan dalam 3D. Misalnya, Anda dapat menentukan kerangka melalui dinding, melacak perubahan pada sinyal Wi-Fi saat melewati tubuh manusia.
Banyak pekerjaan telah dilakukan di bidang deteksi keypoint tangan. Kumpulan data baru muncul, termasuk yang didasarkan pada video dengan dialog dua orang - sekarang Anda dapat memprediksi gerakan tangan dengan audio atau teks percakapan! Kemajuan yang sama telah dibuat dalam tugas penilaian tatapan.

Anda juga dapat menyoroti sekelompok besar karya yang berkaitan dengan prediksi gerakan manusia (misalnya,
Prediksi Gerakan Manusia melalui Spatio-Temporal Inpainting atau
Prediksi Terstruktur Membantu Pemodelan Gerakan Manusia 3D ). Tugas ini penting dan, berdasarkan percakapan dengan penulis, tugas ini paling sering digunakan untuk menganalisis perilaku pejalan kaki dalam mengemudi mandiri.
Memanipulasi orang dalam foto dan video, ruang pas virtual
Tren utama adalah untuk mengubah gambar wajah dalam hal parameter yang ditafsirkan. Gagasan:
deepfake pada satu gambar, perubahan ekspresi dengan rendering wajah (
PuppetGAN ), perubahan feedforward parameter (misalnya,
usia ). Transfer gaya dipindahkan dari judul topik ke penerapan pekerjaan. Lain cerita - kamar pas virtual, mereka bekerja hampir selalu buruk,
berikut adalah contoh demo.


Pembuatan Sketsa / Grafik
Pengembangan gagasan "Biarkan grid menghasilkan sesuatu berdasarkan pengalaman sebelumnya" telah menjadi berbeda: "Mari kita tunjukkan grid mana pilihan yang menarik minat kita."
SC-FEGAN memungkinkan Anda untuk melakukan inpaint dipandu: pengguna dapat menggambar bagian wajah di area gambar yang dihapus dan mendapatkan gambar yang dipulihkan tergantung pada rendering.

Dalam salah satu dari 25 artikel Adobe untuk ICCV, dua GAN digabungkan: satu menggambar sketsa untuk pengguna, yang lain menghasilkan gambar realistis foto dari sketsa (
halaman proyek ).

Sebelumnya pada generasi gambar grafik tidak diperlukan, tetapi sekarang mereka telah dibuat wadah pengetahuan tentang pemandangan. Penghargaan ICCV Best Paper Honorable Mention juga diberikan kepada artikel yang
Menentukan Atribut dan Hubungan Objek dalam Generasi Adegan Interaktif . Secara umum, Anda dapat menggunakannya dengan berbagai cara: menghasilkan grafik dari gambar, atau gambar dan teks dari grafik.
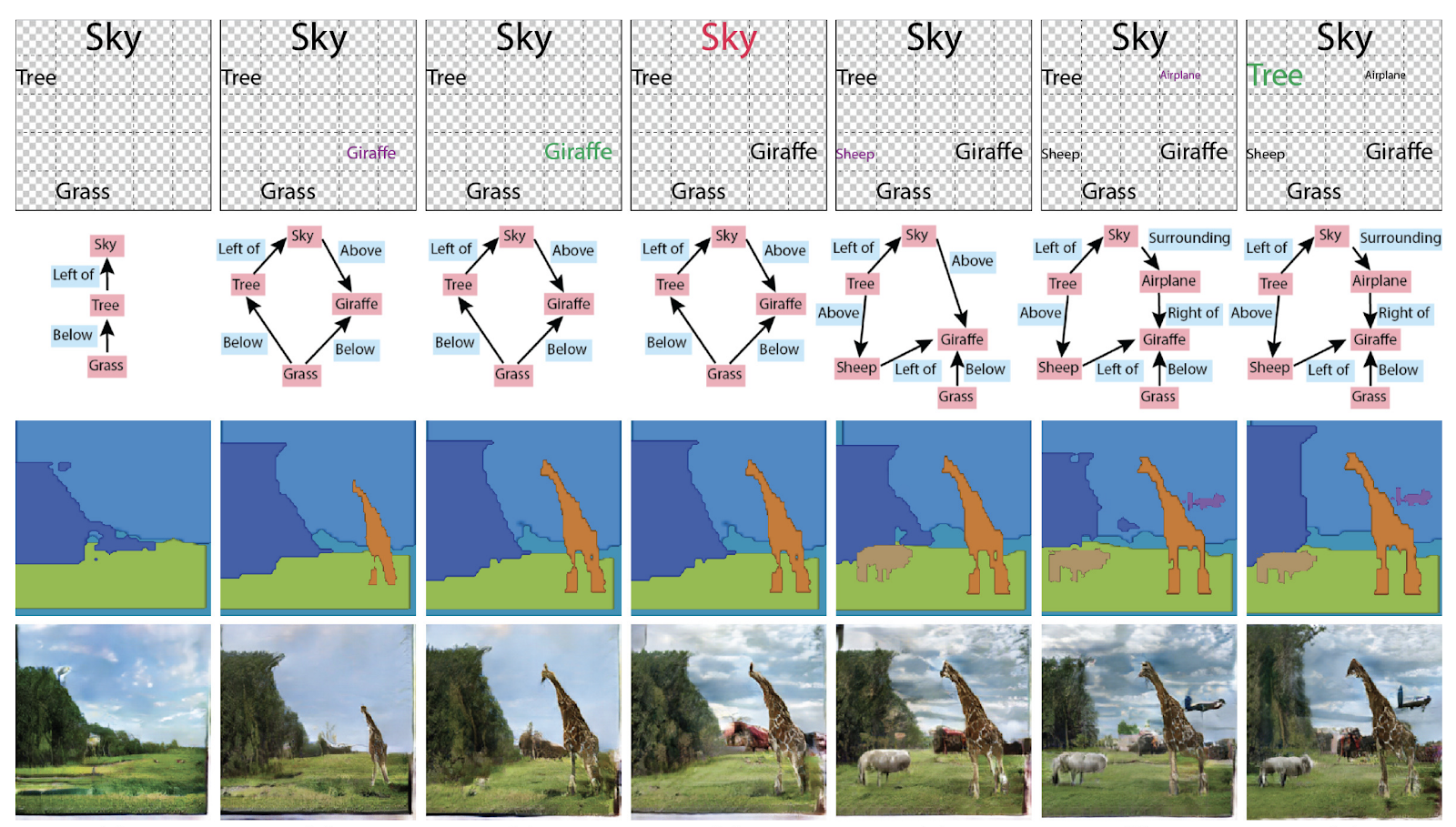
Identifikasi ulang orang dan mesin, dengan menghitung jumlah orang banyak (!)
Banyak artikel yang ditujukan untuk melacak orang dan
mengidentifikasi orang dan mesin. Tapi yang mengejutkan kami adalah banyak artikel tentang menghitung orang di tengah orang banyak, dan semuanya dari Tiongkok.
Tetapi Facebook, sebaliknya, menganonimkan foto tersebut. Selain itu, ia melakukannya dengan cara yang menarik: ia mengajarkan jaringan saraf untuk menghasilkan wajah tanpa detail unik - serupa, tetapi tidak begitu banyak sehingga terdeteksi dengan benar oleh sistem pengenalan wajah.

Perlindungan Serangan Adversarial
Dengan perkembangan aplikasi penglihatan komputer di dunia nyata (pada kendaraan tak berawak, dalam pengenalan wajah), pertanyaan tentang keandalan sistem semacam itu lebih sering muncul. Untuk memanfaatkan CV sepenuhnya, Anda harus yakin bahwa sistem tersebut tahan terhadap serangan musuh - karena itu tidak ada artikel yang lebih sedikit tentang perlindungan terhadap mereka daripada tentang serangan itu sendiri. Banyak pekerjaan adalah tentang menjelaskan prediksi jaringan (peta arti-penting) dan mengukur kepercayaan diri pada hasilnya.
Tugas Gabungan
Dalam sebagian besar tugas dengan satu target, kemungkinan peningkatan kualitas hampir habis, salah satu area baru dari pertumbuhan kualitas lebih lanjut adalah untuk mengajarkan jaringan saraf untuk memecahkan beberapa masalah serupa pada saat yang bersamaan. Contoh:
- prediksi aksi + prediksi aliran optik,
- presentasi video + representasi bahasa (
VideoBERT ),
-
resolusi super + HDR .
Dan ada artikel tentang segmentasi, menentukan postur dan identifikasi ulang hewan!

Sorotan
Hampir semua artikel diketahui sebelumnya, teksnya tersedia di arXiv.org. Oleh karena itu, presentasi karya-karya seperti Everybody Dance Now, FUNIT, Image2StyleGAN agak aneh - ini adalah karya yang sangat berguna, tetapi tidak baru sama sekali. Tampaknya proses klasik publikasi ilmiah gagal di sini - sains berkembang terlalu cepat.
Sangat sulit untuk menentukan karya terbaik - ada banyak dari mereka, subjeknya berbeda. Beberapa artikel telah menerima
penghargaan dan referensi .
Kami ingin menyoroti karya yang menarik dalam hal manipulasi gambar, karena ini adalah topik kami. Mereka ternyata cukup segar dan menarik bagi kita (kita tidak berpura-pura objektif).
SinGAN (penghargaan kertas terbaik) dan InGAN
SinGAN:
halaman proyek ,
arXiv ,
kode .
InGAN:
halaman proyek ,
arXiv ,
kode .
Pengembangan gagasan Deep Image Prior oleh Dmitry Ulyanov, Andrea Vedaldi dan Victor Lempitsky. Alih-alih melatih GAN pada dataset, jaringan belajar dari potongan-potongan gambar yang sama untuk mengingat statistik di dalamnya. Jaringan terlatih memungkinkan Anda untuk mengedit dan menghidupkan foto (SinGAN) atau menghasilkan gambar baru dari berbagai ukuran dari tekstur gambar asli, sambil mempertahankan struktur lokal (InGAN).
SinGAN:

InGAN:

Melihat Apa yang Tidak Dapat Dihasilkan oleh GAN
Halaman proyek .
Jaringan saraf penghasil gambar sering menerima vektor noise acak sebagai input. Dalam jaringan yang terlatih, banyak vektor input membentuk ruang, gerakan kecil yang menyebabkan perubahan kecil pada gambar. Dengan menggunakan pengoptimalan, Anda dapat memecahkan masalah terbalik: menemukan vektor input yang cocok untuk gambar dari dunia nyata. Penulis menunjukkan bahwa hampir tidak mungkin untuk menemukan gambar yang benar-benar cocok di jaringan saraf hampir tidak pernah. Beberapa objek dalam gambar tidak dihasilkan (tampaknya, karena variabilitas objek-objek ini).
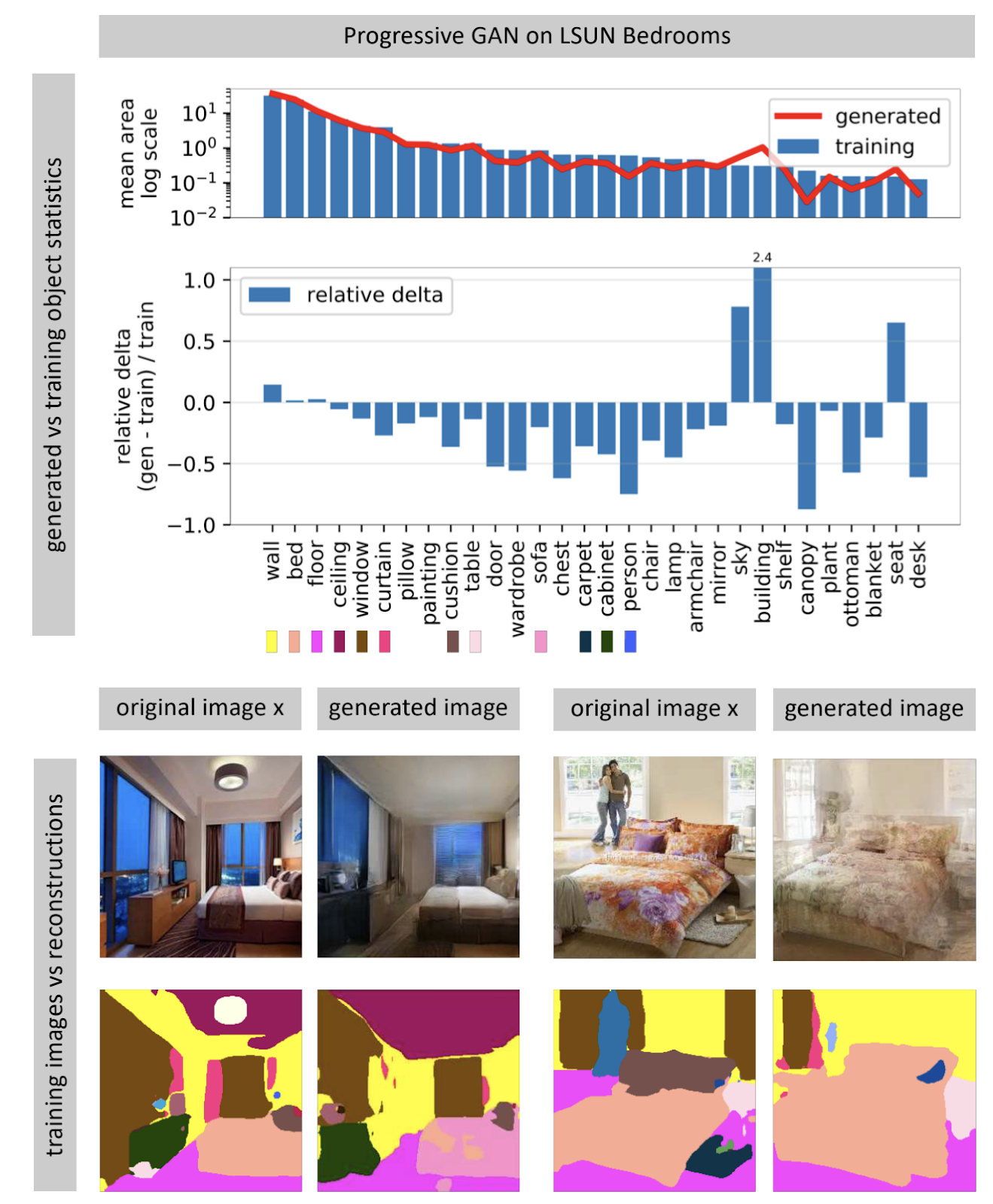
Penulis berhipotesis bahwa GAN tidak mencakup seluruh ruang gambar, tetapi hanya beberapa bagian yang diisi dengan lubang, seperti keju. Ketika kami mencoba menemukan foto dari dunia nyata di dalamnya, kami akan selalu gagal, karena GAN masih menghasilkan foto yang tidak terlalu nyata. Anda dapat mengatasi perbedaan antara gambar nyata dan yang dihasilkan hanya dengan mengubah berat jaringan, yaitu melatih ulang untuk foto tertentu.

Ketika jaringan dilatih ulang untuk foto tertentu, Anda dapat mencoba melakukan berbagai manipulasi dengan gambar ini. Pada contoh di bawah ini, jendela ditambahkan ke foto, dan jaringan juga menghasilkan refleksi pada perangkat dapur. Ini berarti bahwa jaringan setelah pelatihan ulang untuk fotografi tidak kehilangan kemampuan untuk melihat hubungan antara objek pemandangan.

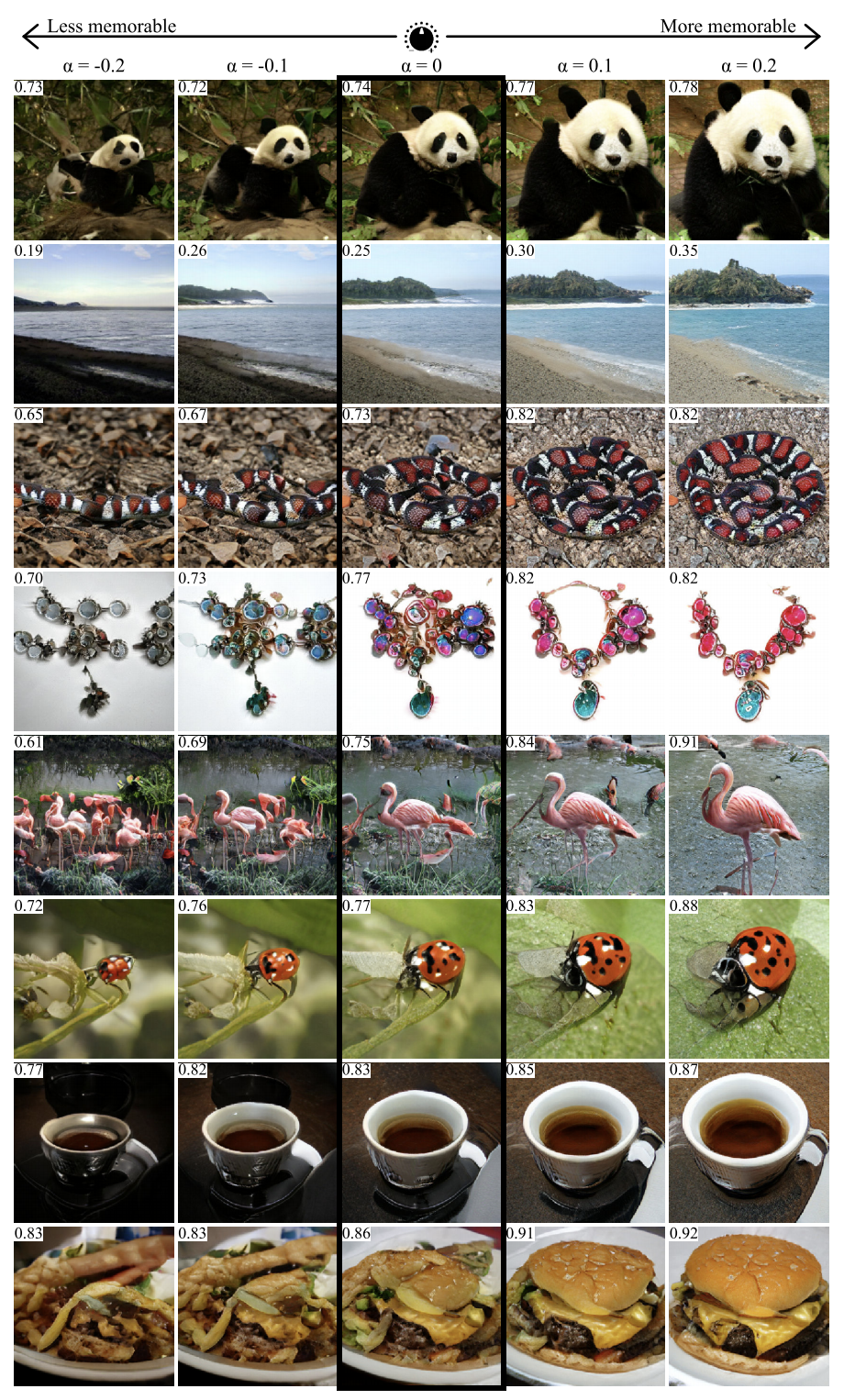
GANalyze: Menuju Definisi Visual dari Properti Gambar Kognitif
Halaman Proyek ,
arXiv .
Dengan menggunakan pendekatan dari karya ini, Anda dapat memvisualisasikan dan menganalisis apa yang telah dipelajari jaringan saraf. Para penulis mengusulkan pelatihan GAN untuk membuat gambar yang jaringannya akan menghasilkan prediksi yang diberikan. Beberapa jaringan digunakan sebagai contoh dalam artikel tersebut, termasuk MemNet, yang memprediksi kemampuan mengingat foto. Ternyata untuk daya ingat yang lebih baik, objek dalam foto harus:
- lebih dekat ke pusat
- memiliki bentuk bulat atau persegi dan struktur sederhana,
- berlatar belakang seragam,
- mengandung mata ekspresif (setidaknya untuk foto anjing),
- lebih cerah, lebih kaya, dalam beberapa kasus - lebih merah.
Liquid Warping GAN: Kerangka Terpadu untuk Imitasi Gerakan Manusia, Transfer Penampilan dan Sintesis Tampilan Novel
Halaman proyek ,
arXiv ,
kode .
Saluran pipa untuk menghasilkan foto orang dari satu foto. Para penulis menunjukkan contoh sukses mentransfer perpindahan satu orang ke orang lain, mentransfer pakaian antara orang-orang dan menghasilkan perspektif baru seseorang - semua dari satu foto. Tidak seperti karya sebelumnya, di sini, untuk membuat kondisi, bukan titik kunci dalam 2D (pose) yang digunakan, tetapi jala 3D tubuh (pose + bentuk). Para penulis juga menemukan cara untuk mentransfer informasi dari gambar asli ke yang dihasilkan (Liquid Warping Block). Hasilnya terlihat baik, tetapi resolusi gambar yang dihasilkan hanya 256x256. Sebagai perbandingan, vid2vid, yang muncul setahun yang lalu, mampu menghasilkan resolusi 2048x1024, tetapi membutuhkan sebanyak 10 menit perekaman video sebagai dataset.

FSGAN: Subjek Swapping dan Peragaan Wajah Agnostik Subjek
Halaman Proyek ,
arXiv .
Pada awalnya tampaknya tidak ada yang aneh: deepfake dengan kualitas yang kurang lebih normal. Namun pencapaian utama dari karya ini adalah penggantian wajah dalam satu gambar. Tidak seperti karya-karya sebelumnya, pelatihan diperlukan pada berbagai foto orang tertentu. Pipa ternyata rumit (pemeragaan dan segmentasi, melihat interpolasi, inpainting, blending) dan dengan banyak peretasan teknis, tetapi hasilnya sepadan.

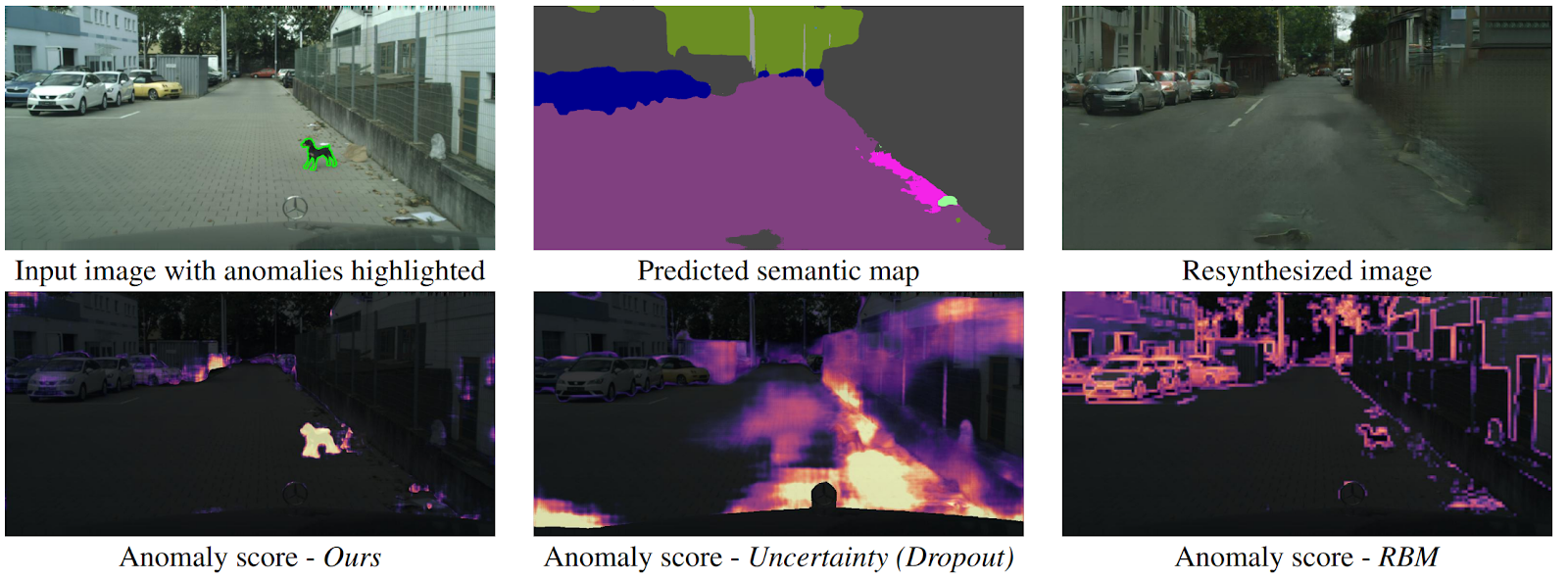
Mendeteksi Yang Tidak Terduga melalui Image Resintesis
arXiv .
Bagaimana sebuah drone dapat memahami bahwa suatu objek tiba-tiba muncul di depannya yang tidak jatuh ke kelas segmentasi semantik apa pun? Ada beberapa metode, tetapi penulis menawarkan algoritma baru dan intuitif yang bekerja lebih baik dari pendahulunya. Segmentasi semantik diprediksi dari input gambar jalan. Ini dimasukkan ke dalam GAN (pix2pixHD), yang mencoba mengembalikan gambar asli hanya dari peta semantik. Anomali yang tidak termasuk dalam salah satu segmen akan berbeda secara signifikan dalam sumber dan gambar yang dihasilkan. Kemudian tiga gambar (awal, segmentasi dan direkonstruksi) dikirimkan ke jaringan lain, yang memprediksi anomali. Dataset untuk ini dihasilkan dari dataset Cityscapes yang terkenal, tanpa sengaja mengubah kelas pada segmentasi semantik. Menariknya, dalam pengaturan ini, seekor anjing berdiri di tengah jalan, tetapi tersegmentasi dengan benar (yang berarti ada kelas untuk itu), bukan anomali, karena sistem dapat mengenalinya.
Kesimpulan
Sebelum konferensi, penting untuk mengetahui minat ilmiah Anda, pidato apa yang ingin saya sampaikan, dengan siapa harus berbicara. Maka semuanya akan jauh lebih produktif.
ICCV terutama berjejaring. Anda mengerti bahwa ada lembaga top dan ilmuwan top, Anda mulai memahami ini, untuk mengenal orang. Dan Anda dapat membaca artikel di arXiv - dan omong-omong, sangat keren bahwa Anda tidak dapat pergi ke mana pun untuk mendapatkan pengetahuan.
Selain itu, pada konferensi tersebut Anda dapat menyelami topik yang tidak terlalu dekat dengan Anda, lihat tren. Nah, tulis daftar artikel untuk dibaca. Jika Anda seorang pelajar, ini adalah kesempatan bagi Anda untuk berkenalan dengan ilmuwan potensial, jika Anda berasal dari industri, lalu dengan majikan baru, dan jika perusahaan, maka tunjukkan diri Anda.
Berlangganan
@loss_function_porn ! Ini adalah proyek pribadi: kami bersama-sama dengan
karfly . Semua pekerjaan yang kami sukai selama konferensi, kami diposting di sini:
@loss_function_live .