
Dalam
artikel sebelumnya, kami memeriksa pengelompokan RabbitMQ untuk toleransi kesalahan dan ketersediaan tinggi. Sekarang mari kita menggali lebih dalam ke Apache Kafka.
Di sini, unit replikasi adalah partisi. Setiap topik memiliki satu atau lebih bagian. Setiap bagian memiliki pemimpin dengan atau tanpa pengikut. Saat membuat topik, jumlah partisi dan tingkat replikasi ditunjukkan. Nilai yang biasa adalah 3, yang berarti tiga komentar: satu pemimpin dan dua pengikut.
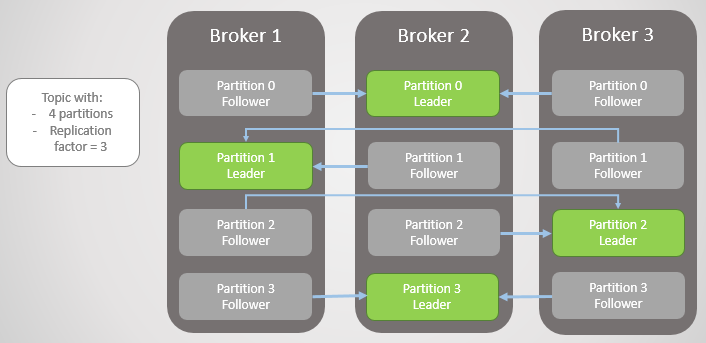 Fig. 1. Empat bagian didistribusikan di antara tiga broker
Fig. 1. Empat bagian didistribusikan di antara tiga brokerSemua permintaan baca dan tulis pergi ke pemimpin. Pengikut secara berkala mengirim permintaan kepada pemimpin untuk menerima pesan terbaru. Konsumen tidak pernah beralih ke pengikut, yang terakhir hanya ada untuk redundansi dan toleransi kesalahan.

Bagian gagal
Ketika broker jatuh, pemimpin beberapa bagian sering gagal. Di masing-masing dari mereka, pengikut dari simpul lain menjadi pemimpin. Sebenarnya, ini tidak selalu terjadi, karena faktor sinkronisasi juga mempengaruhi: apakah ada pengikut yang disinkronkan, dan jika tidak, apakah transisi ke replika yang tidak disinkronkan diperbolehkan. Tetapi untuk sekarang, jangan menyulitkannya.
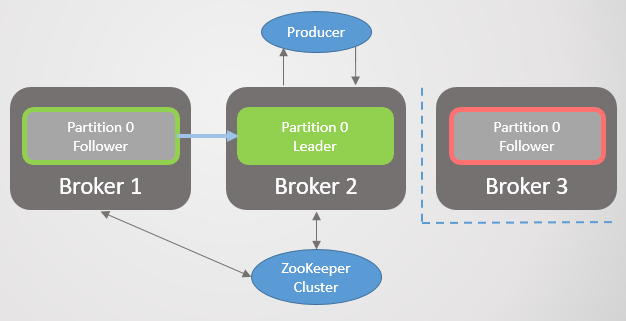
Broker 3 meninggalkan jaringan - dan untuk bagian 2 pemimpin baru pada broker 2 dipilih.
 Fig. 2. Broker 3 meninggal dan pengikutnya di broker 2 terpilih sebagai pemimpin baru pada bagian 2
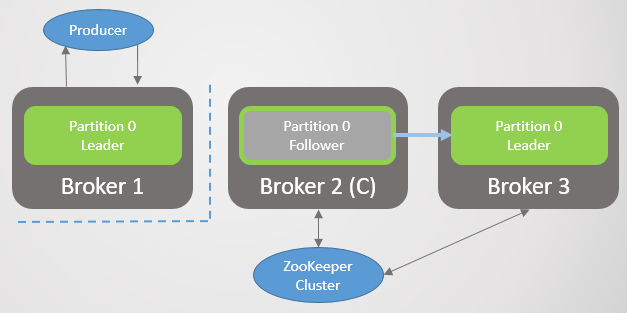
Fig. 2. Broker 3 meninggal dan pengikutnya di broker 2 terpilih sebagai pemimpin baru pada bagian 2Kemudian broker 1 pergi dan bagian 1 juga kehilangan pemimpinnya, yang perannya menjadi broker 2.
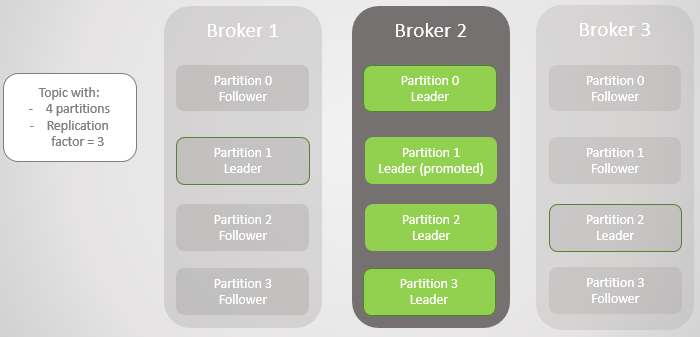 Fig. 3. Hanya ada satu broker yang tersisa. Semua pemimpin berada pada broker redundansi nol yang sama.
Fig. 3. Hanya ada satu broker yang tersisa. Semua pemimpin berada pada broker redundansi nol yang sama.Ketika broker 1 kembali ke jaringan, ia menambahkan empat pengikut, memberikan redundansi pada setiap bagian. Tetapi semua pemimpin masih tetap pada broker 2.
 Fig. 4. Pemimpin tetap di broker 2
Fig. 4. Pemimpin tetap di broker 2Ketika broker 3 naik, kami kembali ke tiga replika per bagian. Tetapi semua pemimpin masih di broker 2.
 Fig. 5. Penempatan pemimpin yang tidak seimbang setelah pemulihan broker 1 dan 3
Fig. 5. Penempatan pemimpin yang tidak seimbang setelah pemulihan broker 1 dan 3Kafka memiliki alat untuk menyeimbangkan pemimpin yang lebih baik daripada RabbitMQ. Di sana Anda harus menggunakan plug-in atau skrip pihak ketiga yang mengubah kebijakan untuk memigrasi node utama dengan mengurangi redundansi selama migrasi. Selain itu, untuk antrian besar harus memasang dengan tidak dapat diaksesnya selama sinkronisasi.
Kafka memiliki konsep "isyarat pilihan" untuk peran kepemimpinan. Ketika bagian topik dibuat, Kafka mencoba untuk mendistribusikan pemimpin secara merata di seluruh simpul dan menandai pemimpin pertama ini sebagai yang disukai. Seiring waktu, karena server reboot, kegagalan, dan kegagalan konektivitas, pemimpin mungkin berakhir pada node lain, seperti dalam kasus ekstrim yang dijelaskan di atas.
Untuk memperbaikinya, Kafka menawarkan dua opsi:
- Opsi auto.leader.rebalance.enable = true memungkinkan node controller untuk secara otomatis menugaskan kembali pemimpin ke replika yang disukai dan dengan demikian mengembalikan distribusi yang seragam.
- Administrator dapat menjalankan skrip kafka-preferred-replica-election.sh untuk ditugaskan kembali secara manual.
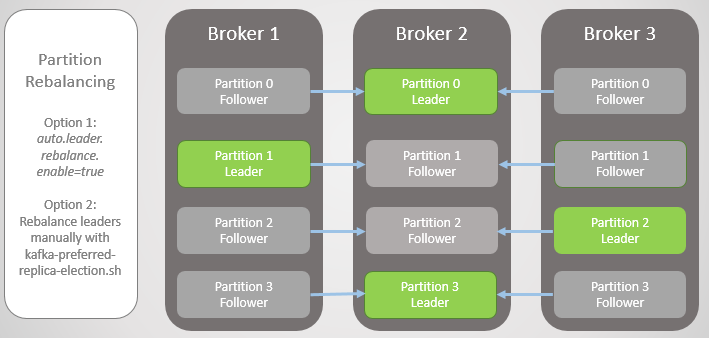 Fig. 6. Replika setelah penyeimbangan ulang
Fig. 6. Replika setelah penyeimbangan ulangItu adalah versi kegagalan yang disederhanakan, tetapi kenyataannya lebih kompleks, meskipun tidak ada yang terlalu rumit di sini. Semuanya bermuara pada replika yang disinkronkan (In-Sync Replicas, ISR).
Replika Tersinkronisasi (ISR)
ISR adalah sekumpulan replika partisi yang dianggap “disinkronkan” (in-sync). Ada seorang pemimpin, tetapi mungkin tidak ada pengikut. Seorang pengikut dianggap tersinkronisasi jika ia membuat salinan yang tepat dari semua pesan pemimpin sebelum berakhirnya interval
replica.lag.time.max.ms .
Pengikut dihapus dari set ISR jika:
- tidak mengajukan permintaan pengambilan sampel untuk interval replica.lag.time.max.ms (dianggap mati)
- tidak punya waktu untuk memperbarui untuk replica.lag.time.max.ms interval (dianggap lambat)
Pengikut melakukan pengambilan permintaan dalam interval
replica.fetch.wait.max.ms , yang secara default adalah 500 ms.
Untuk menjelaskan dengan jelas tujuan ISR, Anda perlu melihat konfirmasi dari produsen (produsen) dan beberapa skenario kegagalan. Produsen dapat memilih kapan broker mengirim konfirmasi:
- acks = 0, konfirmasi tidak terkirim
- acks = 1, konfirmasi dikirim setelah pemimpin menulis pesan ke log lokalnya
- acks = all, konfirmasi dikirim setelah semua replika di ISR telah menulis pesan ke log lokal
Dalam terminologi Kafka, jika ISR telah menyimpan pesan, itu "berkomitmen". Acks = all adalah opsi paling aman, tetapi juga penundaan tambahan. Mari kita lihat dua contoh kegagalan dan bagaimana opsi 'acks' berbeda berinteraksi dengan konsep ISR.
Acks = 1 dan ISR
Dalam contoh ini, kita akan melihat bahwa jika pemimpin tidak menunggu setiap pesan dari semua pengikut disimpan, maka jika pemimpin gagal, data dapat hilang. Pergi ke pengikut yang tidak disinkronkan dapat diaktifkan atau dinonaktifkan dengan menetapkan
unclean.leader.election.enable .
Dalam contoh ini, pabrikan diatur ke acks = 1. Bagian ini didistribusikan di ketiga broker. Broker 3 di belakang, disinkronkan dengan pemimpin delapan detik yang lalu dan sekarang di belakang oleh 7456 pesan. Broker 1 hanya satu detik di belakang. Produser kami mengirim pesan dan dengan cepat menerima ack kembali, tanpa biaya overhead untuk pengikut yang lambat atau mati yang tidak diharapkan oleh pemimpin.
 Fig. 7. ISR dengan tiga replika
Fig. 7. ISR dengan tiga replikaBroker 2 gagal, dan pabrikan menerima kesalahan koneksi. Setelah transisi kepemimpinan ke broker 1, kami kehilangan 123 pesan. Pengikut di broker 1 adalah bagian dari ISR, tetapi tidak sepenuhnya melakukan sinkronisasi dengan pemimpin ketika dia jatuh.
 Fig. 8. Setelah gagal, pesan hilang
Fig. 8. Setelah gagal, pesan hilangDalam konfigurasi
bootstrap.servers , pabrikan mencantumkan beberapa pialang, dan ia dapat menanyakan pialang lain yang menjadi pemimpin baru bagian tersebut. Dia kemudian membangun koneksi dengan broker 1 dan terus mengirim pesan.
 Fig. 9. Mengirim pesan dilanjutkan setelah istirahat singkat
Fig. 9. Mengirim pesan dilanjutkan setelah istirahat singkatBroker 3 tertinggal lebih jauh. Itu membuat mengambil permintaan, tetapi tidak dapat menyinkronkan. Ini mungkin karena koneksi jaringan yang lambat antara broker, masalah penyimpanan, dll. Itu dihapus dari ISR. Sekarang ISR terdiri dari satu replika - pemimpin! Pabrikan terus mengirim pesan dan menerima konfirmasi.
 Fig. 10. Pengikut pada broker 3 dihapus dari ISR
Fig. 10. Pengikut pada broker 3 dihapus dari ISRPialang 1 jatuh, dan peran pemimpin beralih ke pialang 3 dengan hilangnya 15286 pesan! Pabrikan menerima pesan kesalahan koneksi. Pergi ke pemimpin di luar ISR hanya dimungkinkan karena pengaturan
unclean.leader.election.enable = true . Jika disetel ke
false , maka transisi tidak akan terjadi, dan semua permintaan baca dan tulis akan ditolak. Dalam hal ini, kami sedang menunggu kembalinya broker 1 dengan data yang tidak tersentuh dalam replika, yang akan kembali memimpin.
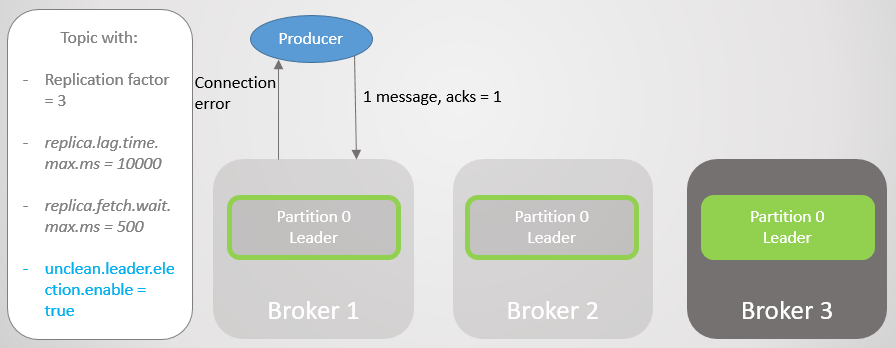 Fig. 11. Broker 1 tetes. Jika kegagalan terjadi, sejumlah besar pesan hilang
Fig. 11. Broker 1 tetes. Jika kegagalan terjadi, sejumlah besar pesan hilangPabrikan menjalin hubungan dengan broker terakhir dan melihat bahwa ia sekarang adalah pemimpin bagian. Dia mulai mengirim pesan ke broker 3.
 Fig. 12. Setelah istirahat singkat, pesan dikirim lagi ke bagian 0
Fig. 12. Setelah istirahat singkat, pesan dikirim lagi ke bagian 0Kami melihat bahwa selain gangguan singkat untuk membuat koneksi baru dan mencari pemimpin baru, pabrikan terus-menerus mengirim pesan. Konfigurasi ini menyediakan aksesibilitas melalui konsistensi (keamanan data). Kafka kehilangan ribuan pesan, tetapi terus menerima entri baru.
Acks = all dan ISR
Mari kita ulangi skenario ini lagi, tetapi dengan
acks = all . Menunda broker 3 rata-rata empat detik. Pabrikan mengirim pesan dengan
acks = all , dan sekarang tidak menerima respons cepat. Pemimpin menunggu hingga semua pesan di ISR menyimpan pesan.
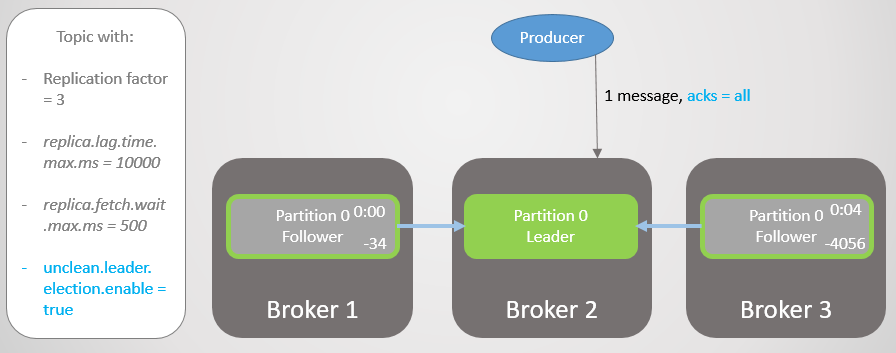 Fig. 13. ISR dengan tiga replika. Salah satunya lambat, menyebabkan penundaan dalam perekaman
Fig. 13. ISR dengan tiga replika. Salah satunya lambat, menyebabkan penundaan dalam perekamanSetelah empat detik penundaan tambahan, broker 2 mengirimkan ack. Semua replika sekarang sepenuhnya diperbarui.
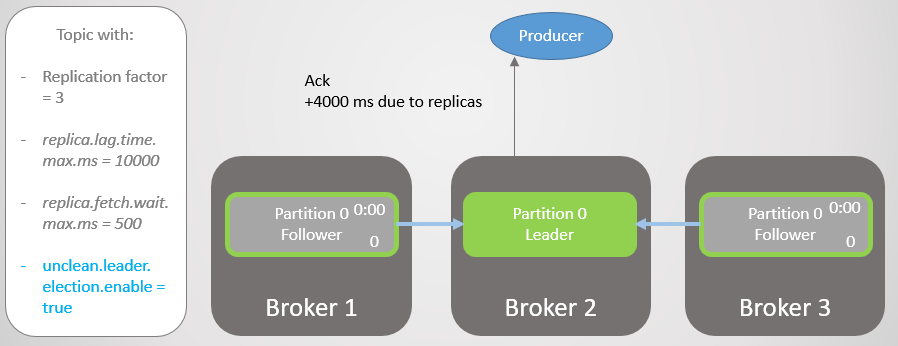 Fig. 14. Semua replika menyimpan pesan dan ack dikirim
Fig. 14. Semua replika menyimpan pesan dan ack dikirimBroker 3 sekarang bahkan lebih jauh di belakang dan sedang dihapus dari ISR. Penundaan berkurang secara signifikan karena tidak ada replika lambat yang tersisa di ISR. Broker 2 sekarang menunggu hanya untuk broker 1, dan ia memiliki jeda rata-rata 500 ms.
 Fig. 15. Replika pada broker 3 dihapus dari ISR
Fig. 15. Replika pada broker 3 dihapus dari ISRKemudian broker 2 jatuh, dan kepemimpinan berpindah ke broker 1 tanpa kehilangan pesan.
 Fig. 16. Pialang 2 jatuh
Fig. 16. Pialang 2 jatuhPabrikan menemukan pemimpin baru dan mulai mengiriminya pesan. Penundaan masih berkurang, karena sekarang ISR terdiri dari satu replika! Oleh karena itu, opsi
acks = all tidak menambahkan redundansi.
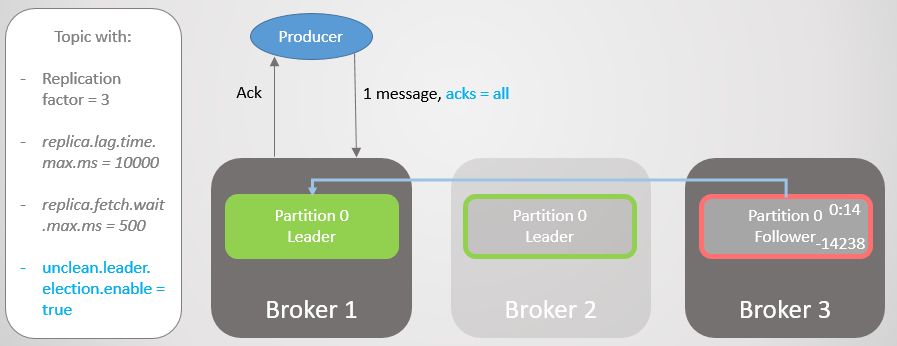 Fig. 17. Replika pada broker 1 memimpin tanpa kehilangan pesan
Fig. 17. Replika pada broker 1 memimpin tanpa kehilangan pesanKemudian broker 1 jatuh, dan kepemimpinan beralih ke broker 3 dengan hilangnya 14.238 pesan!
 Fig. 18. Pialang 1 meninggal, dan transisi kepemimpinan dengan pengaturan yang tidak bersih menyebabkan hilangnya data yang luas
Fig. 18. Pialang 1 meninggal, dan transisi kepemimpinan dengan pengaturan yang tidak bersih menyebabkan hilangnya data yang luasKami tidak dapat mengatur opsi
unclean.leader.election.enable menjadi
true . Secara default, ini
salah . Pengaturan
acks = all dengan
unclean.leader.election.enable = true menyediakan aksesibilitas dengan beberapa keamanan data tambahan. Tapi, seperti yang Anda lihat, kita masih bisa kehilangan pesan.
Tetapi bagaimana jika kita ingin meningkatkan keamanan data? Anda dapat mengatur
unclean.leader.election.enable = false , tetapi ini tidak selalu melindungi kami dari kehilangan data. Jika pemimpin jatuh dan mengambil data bersamanya, maka pesannya masih hilang, ditambah aksesibilitasnya hilang sampai administrator memulihkan situasi.
Lebih baik untuk menjamin redundansi semua pesan, dan sebaliknya menolak untuk merekam. Kemudian, setidaknya dari sudut pandang broker, kehilangan data hanya mungkin terjadi dengan dua kegagalan simultan atau lebih.
Acks = all, min.insync.replicas, dan ISR
Dengan
konfigurasi topik
min.insync.replicas, kami meningkatkan keamanan data. Mari kita kembali ke bagian terakhir dari skenario terakhir, tetapi kali ini dengan
min.insync.replicas = 2 .
Jadi, broker 2 memiliki pemimpin replika, dan pengikut broker 3 dihapus dari ISR.
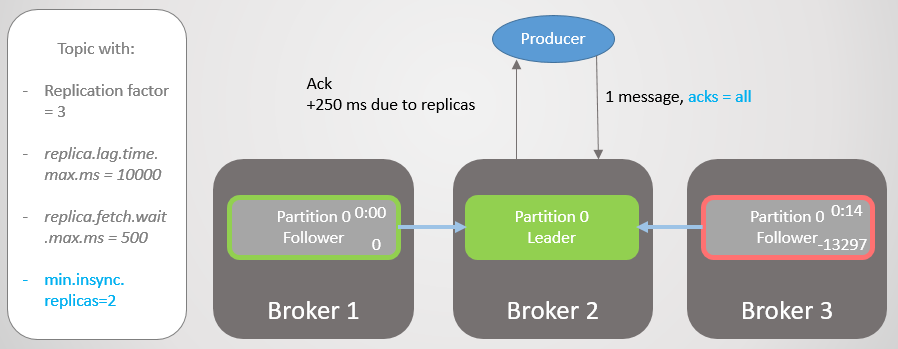 Fig. 19. ISR dari dua replika
Fig. 19. ISR dari dua replikaBroker 2 jatuh, dan kepemimpinan berpindah ke broker 1 tanpa kehilangan pesan. Tetapi sekarang ISR hanya terdiri dari satu replika. Ini tidak sesuai dengan jumlah minimum untuk menerima catatan, dan karena itu broker menanggapi upaya untuk merekam dengan kesalahan
NotEnoughReplicas .
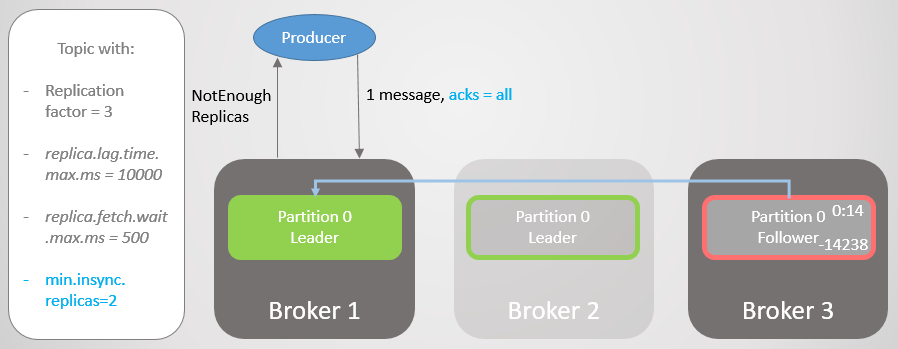 Fig. 20. Jumlah ISR adalah satu lebih rendah dari yang ditentukan dalam min.insync.replicas
Fig. 20. Jumlah ISR adalah satu lebih rendah dari yang ditentukan dalam min.insync.replicasKonfigurasi ini mengorbankan ketersediaan untuk konsistensi. Sebelum mengkonfirmasi suatu pesan, kami menjamin bahwa pesan itu direkam pada setidaknya dua replika. Ini memberi produsen lebih percaya diri. Di sini, kehilangan pesan hanya dimungkinkan jika dua replika secara bersamaan gagal dalam interval pendek, sampai pesan direplikasi ke pengikut tambahan, yang tidak mungkin. Tetapi jika Anda seorang superparanoid, maka Anda dapat mengatur rasio replikasi menjadi 5, dan
min.insync.replicas menjadi 3. Kemudian tiga broker sekaligus harus jatuh pada waktu yang sama untuk kehilangan catatan! Tentu saja, untuk keandalan seperti itu Anda akan membayar penundaan tambahan.
Ketika aksesibilitas diperlukan untuk keamanan data
Seperti
halnya RabbitMQ , terkadang aksesibilitas diperlukan untuk keamanan data. Anda perlu memikirkan ini:
- Bisakah penerbit hanya mengembalikan kesalahan, dan layanan yang lebih tinggi atau pengguna mencoba lagi nanti?
- Bisakah penerbit menyimpan pesan secara lokal atau dalam database untuk mencoba lagi nanti?
Jika jawabannya tidak, maka mengoptimalkan aksesibilitas akan meningkatkan keamanan data. Anda akan kehilangan lebih sedikit data jika Anda memilih ketersediaan alih-alih membuang rekaman. Dengan demikian, semuanya bermuara pada menemukan keseimbangan, dan keputusan tergantung pada situasi spesifik.
Arti ISR
Suite ISR memungkinkan Anda untuk memilih keseimbangan optimal antara keamanan data dan latensi. Misalnya, untuk memastikan bahwa sebagian besar replika dapat diakses jika terjadi kegagalan, meminimalkan dampak mati atau lambat dalam hal penundaan.
Kami sendiri memilih nilai
replica.lag.time.max.ms sesuai dengan kebutuhan kami. Intinya, parameter ini berarti penundaan apa yang siap kami terima dengan
acks = all . Nilai default adalah sepuluh detik. Jika ini terlalu lama untuk Anda, Anda bisa menguranginya. Maka frekuensi perubahan dalam ISR akan meningkat, karena pengikut akan lebih sering dihapus dan ditambahkan.
RabbitMQ hanyalah kumpulan cermin yang perlu direplikasi. Mirror lambat memperkenalkan penundaan tambahan, dan respons dari mirror mati dapat diharapkan sebelum berakhirnya paket yang memeriksa ketersediaan setiap node (net tick). ISR adalah cara yang menarik untuk menghindari masalah ini dengan latensi yang meningkat. Tetapi kita berisiko kehilangan redundansi, karena ISR hanya dapat direduksi menjadi seorang pemimpin. Untuk menghindari risiko ini, gunakan pengaturan
min.insync.replicas .
Jaminan Konektivitas Pelanggan
Dalam pengaturan
bootstrap.servers dari pabrikan dan konsumen, Anda dapat menentukan beberapa broker untuk menghubungkan klien. Idenya adalah bahwa ketika Anda memutuskan satu node, ada beberapa node cadangan yang dengannya klien dapat membuka koneksi. Ini tidak harus pemimpin bagian, tetapi hanya batu loncatan untuk bootstrap. Klien dapat bertanya pada mereka di simpul mana pemimpin bagian baca / tulis berada.
Di RabbitMQ, klien dapat terhubung ke host mana pun, dan routing internal mengirimkan permintaan jika diperlukan. Ini artinya Anda dapat memasang penyeimbang beban di depan RabbitMQ. Kafka mengharuskan klien untuk terhubung ke host yang menampung pemimpin dari partisi yang sesuai. Dalam situasi ini, penyeimbang beban tidak memberikan. Daftar
bootstrap.servers sangat penting sehingga klien dapat mengakses node yang benar dan menemukannya setelah crash.
Arsitektur Konsensus Kafka
Sejauh ini, kami belum mempertimbangkan bagaimana cluster mengetahui tentang jatuhnya broker dan bagaimana pemimpin baru dipilih. Untuk memahami bagaimana Kafka bekerja dengan partisi jaringan, Anda harus terlebih dahulu memahami arsitektur konsensus.
Setiap cluster Kafka digunakan dengan cluster Zookeeper - ini adalah layanan konsensus terdistribusi yang memungkinkan sistem untuk mencapai konsensus di beberapa negara tertentu dengan prioritas konsistensi daripada ketersediaan. Persetujuan operasi baca dan tulis membutuhkan persetujuan dari sebagian besar node Zookeeper.
Zookeeper menyimpan status kluster:
- Daftar topik, bagian, konfigurasi, replika pemimpin saat ini, replika pilihan.
- Anggota cluster. Setiap broker masuk ke dalam cluster Zookeeper. Jika dia tidak menerima ping untuk jangka waktu tertentu, maka Zookeeper menulis broker tidak dapat diakses.
- Pilihan node primer dan sekunder untuk controller.
Node controller adalah salah satu broker Kafka yang bertanggung jawab untuk memilih pemimpin replika. Zookeeper mengirimkan pemberitahuan kepada pengontrol tentang perubahan keanggotaan dan perubahan topik, dan pengontrol harus bertindak sesuai dengan perubahan ini.
Misalnya, ambil topik baru dengan sepuluh bagian dan koefisien replikasi 3. Pengontrol harus memilih pemimpin dari setiap bagian, mencoba untuk mendistribusikan pemimpin secara optimal di antara broker.
Untuk setiap bagian, pengontrol:
- memperbarui informasi dalam Zookeeper tentang ISR dan pemimpinnya;
- mengirimkan perintah LeaderAndISRCommand kepada setiap broker yang memposting replika bagian ini, memberi tahu broker tentang ISR dan pemimpinnya.
Ketika broker dengan seorang pemimpin jatuh, Zookeeper mengirimkan pemberitahuan ke controller, dan dia memilih pemimpin baru. Sekali lagi, controller pertama memperbarui Zookeeper, dan kemudian mengirimkan perintah ke masing-masing broker, memberi tahu mereka tentang perubahan dalam kepemimpinan.
Setiap pemimpin bertanggung jawab untuk merekrut ISR.
Pengaturan replica.lag.time.max.ms menentukan siapa yang akan pergi ke sana. Ketika ISR berubah, pemimpin memberikan informasi baru kepada Zookeeper.
Zookeeper selalu mendapat informasi tentang perubahan apa pun, sehingga jika terjadi kegagalan, manajemen lancar pindah ke pemimpin baru.
 Fig. 21. Konsensus Kafka
Fig. 21. Konsensus KafkaProtokol replikasi
Memahami detail replikasi membantu Anda lebih memahami potensi skenario kehilangan data.
Permintaan Sampel, Log End Offset (LEO) dan Highwater Mark (HW)
Kami telah mempertimbangkan bahwa pengikut secara berkala mengirim permintaan pengambilan kepada pemimpin. Interval default adalah 500 ms. Ini berbeda dari RabbitMQ di bahwa di RabbitMQ, replikasi dimulai bukan oleh cermin antrian, tetapi oleh penyihir. Master mendorong perubahan ke mirror.
Pemimpin dan semua pengikut mempertahankan label Log End Offset (LEO) dan Highwater (HW). Tanda LEO menyimpan offset pesan terakhir di replika lokal, dan HW menyimpan offset komitmen terakhir. Ingat bahwa untuk status komit, pesan harus disimpan di semua replika ISR. Ini berarti bahwa LEO biasanya sedikit di depan HW.
Ketika seorang pemimpin menerima pesan, ia menyimpannya secara lokal. Pengikut membuat permintaan pengambilan, melewati LEO-nya. Pemimpin kemudian mengirim paket pesan yang dimulai dengan LEO ini, dan juga mentransmisikan HW saat ini. Ketika pemimpin menerima informasi bahwa semua replika telah menyimpan pesan pada offset yang diberikan, ia memindahkan tanda HW. Hanya pemimpin yang bisa memindahkan HW, sehingga semua pengikut akan tahu nilai saat ini dalam tanggapan terhadap permintaan mereka. Ini berarti bahwa pengikut dapat tertinggal di belakang pemimpin dalam pelaporan dan pengetahuan tentang HW. Konsumen hanya menerima pesan hingga HW saat ini.
Perhatikan bahwa "bertahan" berarti ditulis ke memori, bukan ke disk. Untuk kinerja, Kafka menyinkronkan ke disk pada interval yang ditentukan. RabbitMQ juga memiliki interval seperti itu, tetapi akan mengirimkan konfirmasi kepada penerbit hanya setelah master dan semua mirror menulis pesan ke disk. Pengembang Kafka untuk alasan kinerja memutuskan untuk mengirim ack segera setelah pesan tersebut ditulis ke memori. Kafka bergantung pada kenyataan bahwa redundansi mengkompensasi risiko penyimpanan jangka pendek dari pesan yang dikonfirmasi hanya dalam memori.
Kegagalan Pemimpin
Ketika seorang pemimpin jatuh, Zookeeper memberitahu controller, dan dia memilih replika pemimpin baru. Pemimpin baru menetapkan tanda HW baru sesuai dengan LEO-nya. Kemudian pengikut menerima informasi tentang pemimpin baru. Bergantung pada versi Kafka, pengikut akan memilih satu dari dua skenario:
- Memotong log lokal ke HW yang terkenal dan mengirim pesan ke pemimpin baru setelah tanda ini.
- , HW , . , .
:
- , ISR, Zookeeper, . ISR, «», . , . Kafka , . , , HW . , acks=all .
- . , . , , , , , .
c
, : HW ( ). , RabbitMQ . . , « ». . .
Kafka — , , RabbitMQ, . . Kafka — , . . Kafka HW ( ) , . , , , LEO.
ISR . , , , ISR. .
Kafka , RabbitMQ, , . Kafka , .
:
- 1. , Zookeeper.
- 2. , Zookeeper.
- 3. , Zookeeper.
- 4. , Zookeeper.
- 5. Kafka, Zookeeper.
- 6. Kafka, Zookeeper.
- 7. Kafka Kafka.
- 8. Kafka Zookeeper.
.
1. , Zookeeper
 . 22. 1. ISR
. 22. 1. ISR3 1 2, Zookeeper. 3 .
replica.lag.time.max.ms ISR . , ISR, . Zookeeper , .
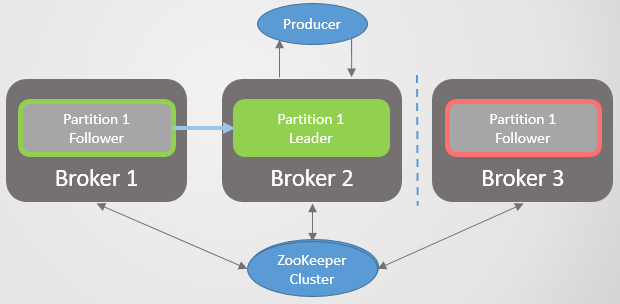 . 23. 1. ISR, replica.lag.time.max.ms
. 23. 1. ISR, replica.lag.time.max.ms(split-brain) , RabbitMQ. .
2. , Zookeeper
 . 24. 2.
. 24. 2., Zookeeper. , ISR , , . , . , . Zookeeper , .
 . 25. 2. ISR
. 25. 2. ISR3. , Zookeeper
Zookeeper, . ISR. Zookeeper , , .
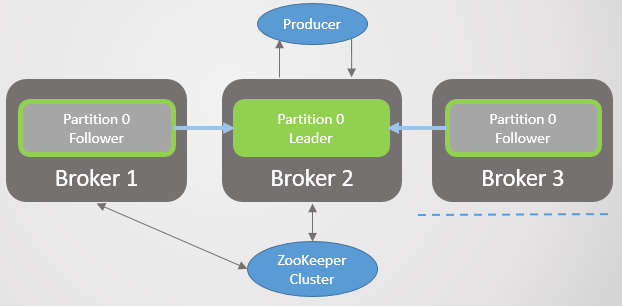 . 26. 3.
. 26. 3.4. , Zookeeper
 . 27. 4.
. 27. 4.Zookeeper, .
 . 28. 4. Zookeeper
. 28. 4. ZookeeperZookeeper . . ,
acks=1 . , ISR . Zookeeper, , .
acks=all , ISR , . ISR, - .
. , , , HW, , . . , . , , .
 . 29. 4. 1
. 29. 4. 15. Kafka, Zookeeper
Kafka, Zookeeper. ISR, , .
 . 30. 5. ISR
. 30. 5. ISR6. Kafka, Zookeeper
 . 31. 6.
. 31. 6., Zookeeper.
acks=1 .
 . 32. 6. Kafka Zookeeperreplica.lag.time.max.ms
. 32. 6. Kafka Zookeeperreplica.lag.time.max.ms , ISR , , Zookeeper, .
, Zookeeper , .
 . 33. 6.
. 33. 6., . 60 . .
 . 34. 6.
. 34. 6., . , Zookeeper , . HW .
 . 35. 6.
. 35. 6.,
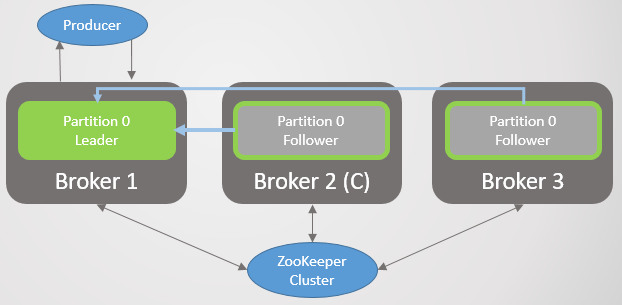
acks=1 min.insync.replicas 1. , , , , — , . ,
acks=1 .
, , ISR . - . , ,
acks=all , ISR . . —
min.insync.replicas = 2 .
7. Kafka Kafka
, Kafka . , 6. .
8. Kafka Zookeeper
Zookeeper Kafka. , Zookeeper, . , , , Kafka.
, , , . , , , .
- Zookeeper,
acks=1 . Zookeeper .
acks=all .
min.insync.replicas , , 6.
, Kafka:
- , acks=1
- (unclean) , ISR, acks=all
- Zookeeper, acks=1
- , ISR . , acks=all . , min.insync.replicas=1 .
- . , . .
, , . —
acks=all min.insync.replicas 1.
RabbitMQ Kafka
. RabbitMQ . , . RabbitMQ. , . . , ( ) .
Kafka . . . , . , , . , - , . , .
RabbitMQ Kafka . , RabbitMQ . :
- fsync setiap beberapa ratus milidetik
- Mirror dapat dideteksi hanya setelah masa pak paket yang memeriksa ketersediaan setiap node (centang net). Jika cermin melambat atau jatuh, ini menambah penundaan.
Kafka bergantung pada kenyataan bahwa jika pesan disimpan di beberapa node, Anda dapat mengkonfirmasi pesan segera setelah mereka ada di memori. Karena itu, ada risiko kehilangan pesan dalam jenis apa pun (bahkan
acks = all ,
min.insync.replies = 2 ) jika terjadi kegagalan secara bersamaan.
Secara keseluruhan, Kafka menunjukkan kinerja yang lebih baik dan pada awalnya dirancang untuk cluster. Jumlah pengikut dapat ditingkatkan menjadi 11, jika perlu untuk keandalan. Faktor replikasi 5 dan jumlah minimum replika dalam keadaan tersinkronisasi
min.insync.replicas = 3 akan membuat kehilangan pesan peristiwa yang sangat jarang. Jika infrastruktur Anda mampu memberikan tingkat replikasi dan tingkat redundansi seperti itu, maka Anda dapat memilih opsi ini.
Pengelompokan RabbitMQ baik untuk antrian kecil. Tetapi bahkan antrian kecil dapat tumbuh dengan cepat dengan lalu lintas tinggi. Setelah antrian menjadi besar, Anda harus membuat pilihan sulit antara ketersediaan dan keandalan. Pengelompokan RabbitMQ paling cocok untuk situasi non-tipikal di mana keuntungan dari fleksibilitas RabbitMQ lebih besar daripada kerugian dari pengelompokan itu.
Salah satu penangkal kerentanan besar antrian RabbitMQ adalah memecahnya menjadi banyak yang lebih kecil. Jika Anda tidak memerlukan pemesanan penuh seluruh antrian, tetapi hanya pesan yang relevan (misalnya, pesan dari klien tertentu), atau tidak sama sekali, maka opsi ini dapat diterima: lihat proyek
Rebalanser saya untuk memisahkan antrian (proyek masih pada tahap awal).
Akhirnya, jangan lupa tentang sejumlah bug dalam mekanisme clustering dan replikasi dari RabbitMQ dan Kafka. Seiring waktu, sistem menjadi lebih matang dan stabil, tetapi tidak ada satu pesan pun yang akan 100% terlindungi dari kehilangan! Selain itu, kecelakaan skala besar terjadi di pusat data!
Jika saya melewatkan sesuatu, membuat kesalahan atau Anda tidak setuju dengan tesis ini, jangan ragu untuk menulis komentar atau hubungi saya.
Orang sering bertanya kepada saya: "Apa yang harus dipilih, Kafka atau RabbitMQ?", "Platform mana yang lebih baik?". Yang benar adalah bahwa itu benar-benar tergantung pada situasi Anda, pengalaman saat ini, dll. Saya tidak berani mengungkapkan pendapat saya, karena akan terlalu banyak penyederhanaan untuk merekomendasikan satu platform untuk semua kasus penggunaan dan batasan yang mungkin. Saya menulis serangkaian artikel ini sehingga Anda dapat membentuk pendapat Anda sendiri.
Saya ingin mengatakan bahwa kedua sistem adalah pemimpin di bidang ini. Mungkin saya sedikit bias, karena dari pengalaman proyek saya, saya lebih cenderung menghargai hal-hal seperti pemesanan pesan yang terjamin dan keandalan.
Saya melihat teknologi lain yang tidak memiliki keandalan ini dan pemesanan yang terjamin, kemudian lihat RabbitMQ dan Kafka - dan saya mengerti nilai luar biasa dari kedua sistem ini.