TL DR: JSONB dapat sangat menyederhanakan pengembangan skema basis data tanpa mengorbankan kinerja kueri.
Pendahuluan
Mari kita berikan contoh klasik, mungkin, dari salah satu kasus penggunaan tertua dari basis data relasional (database): kita memiliki entitas, dan perlu untuk mempertahankan properti (atribut) tertentu dari entitas ini. Tetapi tidak semua instance memiliki set properti yang sama, di samping itu, di masa depan, kemungkinan penambahan lebih banyak properti.
Cara termudah untuk menyelesaikan masalah ini adalah dengan membuat kolom di tabel database untuk setiap nilai properti, dan cukup mengisi yang diperlukan untuk instance entitas tertentu. Hebat! Masalahnya teratasi ... sampai meja Anda berisi jutaan catatan dan Anda tidak perlu menambahkan catatan baru.
Pertimbangkan pola EAV (
Entity-Attribute-Value ), ini cukup umum. Satu tabel berisi entitas (catatan), tabel lain berisi nama properti (atribut), dan tabel ketiga mengaitkan entitas dengan atributnya dan berisi nilai atribut ini untuk entitas saat ini. Ini memberi Anda kesempatan untuk memiliki set properti yang berbeda untuk objek yang berbeda, serta menambahkan properti dengan cepat, tanpa mengubah struktur database.
Meskipun demikian, saya tidak akan menulis catatan ini jika tidak ada kekurangan dalam pendekatan menggunakan EVA. Jadi, misalnya, untuk mendapatkan satu atau lebih entitas yang masing-masing memiliki 1 atribut, diperlukan 2 join'a (bergabung) dalam permintaan: yang pertama adalah penyatuan dengan tabel atribut, yang kedua adalah penyatuan dengan tabel nilai. Jika suatu entitas memiliki 2 atribut, maka 4 gabungan sudah diperlukan! Selain itu, semua atribut biasanya disimpan sebagai string, yang mengarah ke tipe casting untuk hasil dan klausa WHERE. Jika Anda menulis banyak permintaan, maka ini agak boros dalam hal penggunaan sumber daya.
Terlepas dari kekurangan yang jelas ini, EAV telah lama digunakan untuk memecahkan masalah semacam ini. Ini adalah kelemahan yang tak terhindarkan, dan tidak ada alternatif yang lebih baik.
Tapi kemudian "teknologi" baru muncul di PostgreSQL ...
Dimulai dengan PostgreSQL 9.4, tipe data JSONB telah ditambahkan untuk menyimpan data JSON biner. Meskipun menyimpan JSON dalam format ini biasanya membutuhkan sedikit lebih banyak ruang dan waktu daripada JSON teks biasa, operasi dengannya jauh lebih cepat. JSONB juga mendukung pengindeksan, yang membuat pencarian mereka lebih cepat.
Tipe data JSONB memungkinkan kita untuk mengganti pola EAV yang besar dengan menambahkan hanya satu kolom JSONB ke tabel entitas kita, yang sangat menyederhanakan desain basis data. Tetapi banyak yang berpendapat bahwa ini harus dibarengi dengan penurunan produktivitas ... Itu sebabnya saya muncul di artikel ini.
Uji pengaturan basis data
Untuk perbandingan ini, saya membuat database pada instalasi baru PostgreSQL 9.5 berdasarkan $ 80 membangun
DigitalOcean Ubuntu 14.04. Setelah mengatur beberapa parameter di postgresql.conf, saya menjalankan skrip
ini menggunakan psql. Tabel berikut dibuat untuk mewakili data sebagai EAV:
CREATE TABLE entity ( id SERIAL PRIMARY KEY, name TEXT, description TEXT ); CREATE TABLE entity_attribute ( id SERIAL PRIMARY KEY, name TEXT ); CREATE TABLE entity_attribute_value ( id SERIAL PRIMARY KEY, entity_id INT REFERENCES entity(id), entity_attribute_id INT REFERENCES entity_attribute(id), value TEXT );
Di bawah ini adalah tabel di mana data yang sama akan disimpan, tetapi dengan atribut di kolom tipe JSONB -
properties .
CREATE TABLE entity_jsonb ( id SERIAL PRIMARY KEY, name TEXT, description TEXT, properties JSONB );
Terlihat jauh lebih mudah, bukan? Kemudian, 10 juta catatan ditambahkan ke tabel entitas (
entitas &
entity_jsonb ), dan karenanya, data tabel yang sama diisi menggunakan pola EAV dan pendekatan dengan kolom
JSONB -
entity_jsonb.properties . Jadi, kami menerima beberapa tipe data yang berbeda di antara seluruh rangkaian properti. Data sampel:
{ id: 1 name: "Entity1" description: "Test entity no. 1" properties: { color: "red" lenght: 120 width: 3.1882420 hassomething: true country: "Belgium" } }
Jadi, sekarang kita memiliki data yang sama, untuk dua opsi. Mari kita mulai membandingkan implementasi di tempat kerja!
Penyederhanaan desain
Sebelumnya dikatakan bahwa desain database sangat disederhanakan: satu tabel, karena penggunaan kolom JSONB untuk properti, alih-alih menggunakan tiga tabel untuk EAV. Tetapi bagaimana ini tercermin dalam permintaan? Memperbarui satu properti suatu entitas adalah sebagai berikut:
Seperti yang Anda lihat, permintaan terakhir tidak terlihat lebih mudah. Untuk memperbarui nilai properti di objek JSONB, kita harus menggunakan fungsi
jsonb_set () , dan harus meneruskan nilai baru kita sebagai objek JSONB. Namun, kami tidak perlu mengetahui identitas sebelumnya. Melihat contoh EAV, kita perlu mengetahui entitas_id dan entitas_attribute_id untuk memperbarui. Jika Anda ingin memperbarui properti di kolom JSONB berdasarkan nama objek, maka ini semua dilakukan dalam satu baris sederhana.
Sekarang mari kita pilih entitas yang baru saja kita perbarui, sesuai dengan kondisi warna barunya:
Saya pikir kita bisa sepakat bahwa yang kedua lebih pendek (tanpa bergabung!), Dan karena itu lebih mudah dibaca. Inilah kemenangan JSONB! Kami menggunakan operator JSON - >> untuk mendapatkan warna sebagai nilai teks dari objek JSONB. Ada juga cara kedua untuk mencapai hasil yang sama dalam model JSONB menggunakan operator @>:
Ini sedikit lebih rumit: kami memeriksa untuk melihat apakah objek JSON di kolom properti berisi objek di sebelah kanan operator @>. Kurang terbaca, lebih produktif (lihat di bawah).
Sederhanakan penggunaan JSONB bahkan lebih ketika Anda perlu memilih beberapa properti sekaligus. Di sinilah pendekatan JSONB benar-benar cocok: kita cukup memilih properti sebagai kolom tambahan di set hasil kami tanpa perlu bergabung:
Dengan EAV, Anda akan membutuhkan 2 gabungan untuk setiap properti yang ingin Anda minta. Menurut pendapat saya, pertanyaan di atas menunjukkan penyederhanaan besar dalam desain basis data. Lihat lebih banyak contoh cara menulis permintaan JSONB, juga di pos
ini .
Sekarang saatnya berbicara tentang kinerja.
Performa
Untuk membandingkan kinerja, saya menggunakan
EXPLAIN ANALYZE dalam kueri, untuk menghitung runtime. Setiap permintaan dieksekusi setidaknya tiga kali karena pertama kali perencana kueri membutuhkan waktu lebih lama. Pada awalnya, saya menjalankan kueri tanpa indeks. Jelas, ini menjadi keuntungan JSONB, karena gabungan yang diperlukan untuk EAV tidak dapat menggunakan indeks (bidang kunci asing tidak diindeks). Setelah itu, saya membuat indeks untuk 2 kolom kunci asing di tabel nilai EAV, serta indeks
GIN untuk kolom JSONB.
Pembaruan data menunjukkan hasil berikut dalam waktu (dalam ms). Perhatikan bahwa skalanya adalah logaritmik:

Kami melihat bahwa JSONB jauh (> 50.000-x) lebih cepat daripada EAV jika Anda tidak menggunakan indeks, karena alasan yang ditunjukkan di atas. Ketika kami mengindeks kolom dengan kunci utama, perbedaannya hampir menghilang, tetapi JSONB masih 1,3 kali lebih cepat dari EAV. Harap perhatikan bahwa indeks di kolom JSONB tidak berpengaruh di sini, karena kami tidak menggunakan kolom properti dalam kriteria evaluasi.
Untuk memilih data berdasarkan nilai properti, kami memperoleh hasil berikut (skala normal):
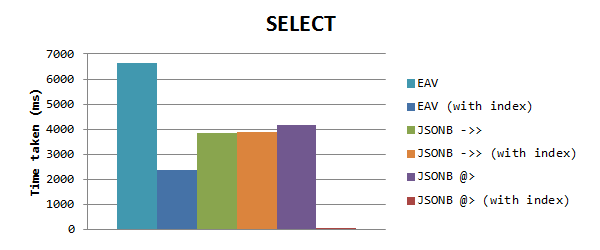
Anda mungkin memperhatikan bahwa JSONB lebih cepat lagi dari EAV tanpa indeks, tetapi ketika EAV dengan indeks, JSONB masih bekerja lebih cepat daripada JSONB. Tapi kemudian saya melihat bahwa waktu untuk permintaan JSONB sama, ini mendorong saya pada kenyataan bahwa indeks GIN tidak berfungsi. Rupanya, ketika Anda menggunakan indeks GIN untuk kolom dengan properti yang diisi, itu hanya bertindak ketika menggunakan operator inklusi @>. Saya menggunakan ini dalam tes baru, yang berdampak besar pada waktu: hanya 0,153 ms! Ini 15.000 kali lebih cepat dari EAV, dan 25.000 kali lebih cepat dari operator - >>.
Saya pikir itu cukup cepat!
Ukuran tabel DB
Mari kita bandingkan ukuran tabel untuk kedua pendekatan. Dalam psql, kita bisa menampilkan ukuran semua tabel dan indeks menggunakan perintah
\ dti +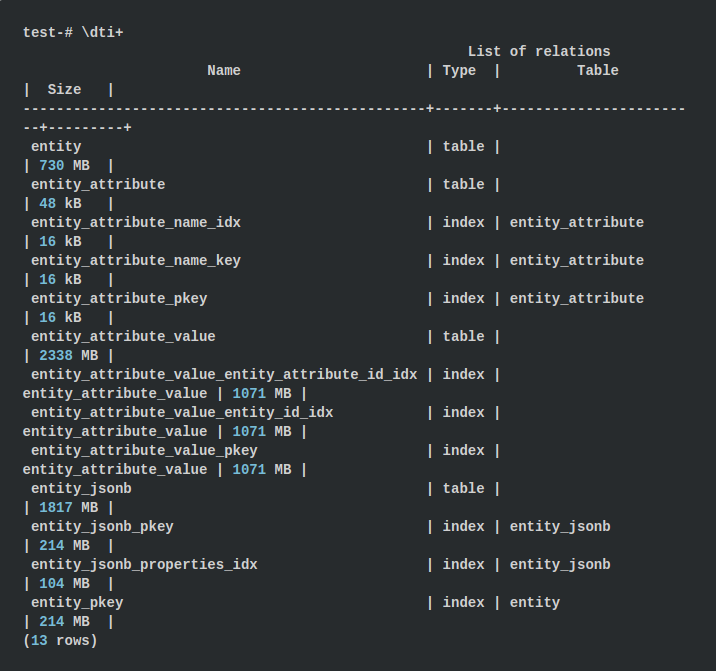
Untuk pendekatan EAV, ukuran tabel sekitar 3068 MB, dan indeks hingga 3427 MB, yang secara total menghasilkan 6,43 GB. Menggunakan pendekatan JSONB, 1817 MB untuk tabel dan 318 MB untuk indeks yang digunakan, yaitu 2,08 GB. Ternyata 3 kali lebih sedikit! Fakta ini sedikit mengejutkan saya karena kami menyimpan nama properti di setiap objek JSONB.
Namun demikian, angka-angkanya berbicara sendiri: di EAV kami menyimpan 2 kunci asing integer untuk nilai atribut, sebagai hasilnya kami mendapatkan 8 byte data tambahan. Selain itu, dalam EAV, semua nilai properti disimpan sebagai teks, sementara JSONB akan menggunakan nilai numerik dan logis secara internal jika memungkinkan, sehingga mengurangi volume.
Ringkasan
Secara umum, saya berpikir bahwa menyimpan properti entitas dalam format JSONB dapat sangat menyederhanakan desain dan pemeliharaan database Anda. Jika Anda menjalankan banyak kueri, maka semua yang disimpan dalam tabel yang sama dengan entitas sebenarnya akan bekerja lebih efisien. Dan fakta bahwa ini menyederhanakan interaksi antara data sudah plus, tetapi database yang dihasilkan adalah 3 kali lebih kecil volumenya.
Juga, menurut tes, kita dapat menyimpulkan bahwa kehilangan kinerja sangat kecil. Dalam beberapa kasus, JSONB bahkan bekerja lebih cepat daripada EAV, yang membuatnya lebih baik. Namun, tolok ukur ini, tentu saja, tidak mencakup semua aspek (misalnya, entitas dengan jumlah properti yang sangat besar, peningkatan signifikan dalam jumlah properti dari data yang ada, ...), oleh karena itu, jika Anda memiliki saran tentang cara memperbaikinya, silakan Jangan ragu untuk meninggalkan komentar!