
Hai, Habr. Baru-baru ini ada kompetisi dari Tinkoff dan McKinsey. Kompetisi ini diadakan dalam dua tahap: yang pertama - kualifikasi, dalam format kaggle, yaitu kirim prediksi - dapatkan penilaian kualitas prediksi; pemenangnya adalah orang dengan skor terbaik. Yang kedua adalah penukaran hackathon di Moskow, yang menjadi tuan rumah 20 tim teratas dari tahap pertama. Pada artikel ini saya akan berbicara tentang tahap kualifikasi, di mana saya berhasil mengambil tempat pertama dan memenangkan MacBook. Tim di papan peringkat disebut "anak-anak Lesha."
Kompetisi diadakan dari 19 September hingga 12 Oktober. Saya mulai menyelesaikan tepat seminggu sebelum akhir dan memutuskan hampir penuh waktu.
Deskripsi singkat dari kompetisi:
Di musim panas, cerita muncul di aplikasi perbankan Tinkoff (seperti di Instagram). Dalam cerita, Anda dapat bereaksi seperti, tidak suka, melewatkan atau melihat sampai akhir. Tugasnya adalah untuk memprediksi reaksi pengguna terhadap cerita.
Kompetisi ini kebanyakan bersifat tabular, tetapi cerita-cerita itu sendiri memiliki teks dan gambar.
Rencana cerita

Metrik
Perkiraan reaksi dapat mengambil nilai dari -1 hingga 1 inklusif - semakin dekat dengan 1, semakin tinggi kemungkinan mendapatkan sejenisnya. Dan dengan nilai -1, lebih baik untuk menghapus cerita ini dari mata pengguna.
Untuk memeriksa keakuratan solusi, rumus digunakan, dinormalisasi ke hasil maksimum yang mungkin:
\ begin {array} {l} {\ text {weight (event)} = \ left \ {\ begin {array} {ll} {- 10} & {\ text {dislike}} \\ {-0.1} & {\ text {skip}} \\ {0,1} & {\ text {view}} \\ {0,5} & {\ text {like}} \ end {array} \ kanan.} \\ [15pt] {\ text {Metric} \ kiri (y _ {\ text {pred}} \ kanan) = \ sum_ {i = 1} ^ {n} \ kiri (\ text {weight} \ kiri (\ text {event} _ {i} \ kanan) \ cdot y _ {\ text {pred,} i} \ kanan)} \ end {array}
Data apa yang ada di sana:
- Informasi Pengguna Dasar
- Transaksi Pengguna
- Informasi tentang cerita (json dari mana Anda dapat membangunnya)
- Sejarah reaksi pengguna terhadap cerita.
Selanjutnya, saya akan berbicara secara rinci tentang setiap bagian data, bagaimana saya memprosesnya dan fitur apa (selanjutnya disebut sebagai fitur) yang saya ekstrak.

apa yang aslinya:
- ID pengguna
- produk bank anonim yang dibuka pengguna (OPN), menggunakan (UTL) atau ditutup (CLS)
- jenis kelamin, usia binarized, status perkawinan, entri pertama ke dalam aplikasi
- job_title - apa yang orang tulis tentang diri mereka sendiri
- job_position_cd - judul pekerjaan seseorang, sebagai salah satu dari 22 kategori
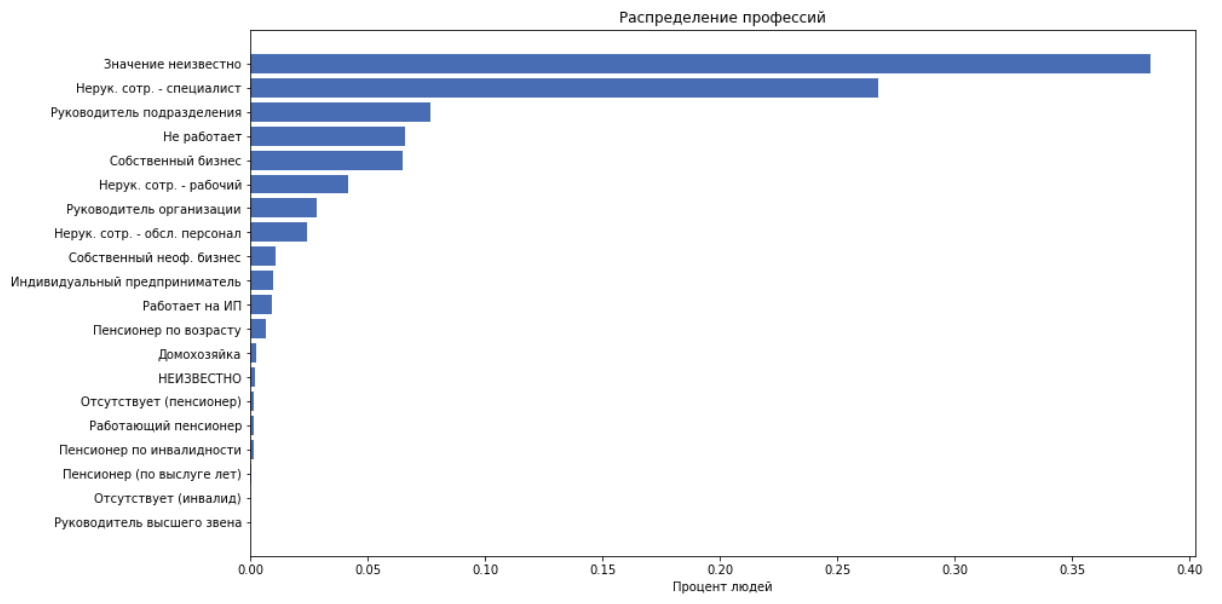
sebagai fitur kami menggunakan semua hal di atas kecuali job_title, karena kami menganggap bahwa job_position_cd biasanya menggambarkan posisi seseorang.
Transaksi

apa yang aslinya:
- ID pengguna
- hari, bulan transaksi
- jumlah transaksi (binari dengan penambahan 250)
- merchant_id - id bank internal kasir. Selanjutnya tidak digunakan.
- merchant_mcc
MCC - Kode kategori pedagang. Ini adalah kode layanan standar yang disediakan oleh penerima. Informasi ini terbuka, ini transkripnya . Kode-kode ini dapat dengan mudah dibagi menjadi beberapa kategori, misalnya: hiburan, hotel, dll.
Untuk setiap customer_id, kami membandingkan fitur berikut:
- menghitung jumlah pengeluaran, rata-rata cek, standar deviasi
- jumlah transaksi
- Kami membagi kode mcc ke dalam 20 kategori, menghitung berapa banyak orang yang menghabiskan uang untuk kategori ini. Dapatkan 20 fitur
- kami akan mendapatkan 20 fitur lainnya dengan membagi biaya dalam kategori dengan jumlah biaya. Yaitu dapatkan persentase uang yang dihabiskan untuk kategori tersebut.
Cerita
Secara total, kami memiliki 959 cerita.
apa yang aslinya:
json terlihat seperti ini:

Ini adalah pohon elemen, di mana setiap elemen dijelaskan dengan kunci: ['guid', 'type', 'description', 'properties', 'content']. 'Konten' berisi daftar anak-anak. Ceritanya terdiri dari beberapa halaman. Latar belakang, teks, gambar dilemparkan ke halaman. Kami tidak memiliki konstruktor cerita, dan menggambar semua ini agak sulit dan bukan fakta, yang akan sangat membantu di masa depan.
Reguler mencabut semua teks dan ukuran font yang sesuai. Kami mengekstrak fitur berikut:
- jumlah halaman, tautan, elemen total
- ukuran font teks rata-rata
- jumlah elemen teks
- "volume teks" adalah heuristik untuk secara hati-hati mempertimbangkan panjang teks tergantung pada ukuran font.
Kode Hitungan Volumedef get_text_amount(all_text, font_sizes): assert len(all_text) == len(font_sizes) lengths = np.array(list(map(len, all_text))) sizes = (np.array(font_sizes) / 100)**2 return (lengths * sizes).sum()
- Sekarang mari kita ambil keseluruhan teks, menggunakan dostoevsky kita mendefinisikan semantik teks: ['netral', 'negatif', 'lewati', 'ucapan', 'positif']. Dan tambahkan ini sebagai 5 fitur
Reaksi

apa yang aslinya:
- id dan riwayat pengguna
- waktu
- reaksi
Kami memproses waktu dan menambahkan fitur sebagai fitur:
- hari dalam seminggu
- jam, menit
Selanjutnya, sekelompok fitur akan ditambahkan berdasarkan data pada reaksi, tetapi untuk sekarang, kita akan bertarung dengan gudang fitur untuk membuat garis dasar.
Pendekatan terbaik yang digunakan oleh seluruh top adalah sebagai berikut: kami mengurangi masalah ke klasifikasi multikelas, yaitu memprediksi probabilitas setiap reaksi. Kami mempertimbangkan ekspektasi penilaian untuk cerita ini :
Binarize :
- jawaban kami untuk objek tersebut yang dapat mengambil nilai
Model
Dari awal hingga akhir, saya menggunakan CatBoost. Ini disebabkan oleh kenyataan bahwa di luar kotak, CatBoost membuat statistik yang berguna untuk fitur-fitur kategorikal. Dan statistik pada pengguna - seberapa besar ia cenderung pada reaksi apa, dan statistik pada sejarah - bagaimana mereka paling sering tidak bereaksi, adalah fitur yang paling kuat dalam tugas ini.
Bagaimana CatBoost bekerja dengan fitur-fitur kategoris dijelaskan dengan baik dalam dokumentasi .
TLDR:
- menghasilkan beberapa permutasi data
- berjalan secara berurutan dan membangun rata-rata target encoding (mte) pada objek-objek yang sudah dilihatnya
secara singkat tentang mte dalam contoh kitakami mengambil nilai tanda, misalnya, salah satu customer_id, kami mempertimbangkan persentase kasus ketika pelanggan ini bereaksi seperti, tidak suka, dilewati atau dilihat. Kami mendapat 4 angka. Kami mengganti customer_id dengan 4 angka ini dan menggunakannya sebagai tanda. Kami melakukan ini untuk setiap customer_id.
Hasil saat ini
Dengan fitur saat ini, dengan catbust yang tidak dioptimalkan, di papan peringkat publik pada waktu itu saya menempati posisi ke-11 dengan hasil 0,31209
Fitur pembunuh
Pada titik tertentu, sebuah hipotesis muncul bahwa aplikasi tersebut dapat menampilkan cerita lebih sering atau kurang tergantung pada bagaimana pengguna bereaksi terhadapnya sebelumnya. Mari kita tambahkan fitur yang akan mengatakan:
- berapa kali pengguna melihat riwayat yang sesuai di masa lalu / masa depan, selama bulan / hari / jam / total
- waktu sejak melihat terakhir dari cerita yang sama
- waktu setelah itu pengguna lain kali melihat cerita yang sama
- sebenarnya, pengguna memuat beberapa cerita sekaligus dalam satu detik, biasanya sekitar 5-7. Sebut kumpulan cerita ini sebagai kelompok . Saya menambahkan sejumlah cerita dalam grup ini sebagai fitur, yang memberi peningkatan besar dalam kualitas.
Tentu saja, fitur-fitur ini tidak dapat digunakan dalam produksi, karena mereka tidak akan klise pada saat penerapan model, tetapi dalam persaingan cara apa pun baik.
Jadi, dikatakan - dilakukan. Mendapat 0,35657 di papan peringkat.
Optimasi model
Saya memeriksa parameter menggunakan optimasi Bayesian
Yang menarik, kita dapat menyebutkan parameter max_ctr_complexity, yang bertanggung jawab atas jumlah maksimum fitur kategorikal yang dapat digabungkan. Contoh di bawah spoiler.
Kutipan dari dokumentasiAsumsikan bahwa objek dalam set latihan termasuk dua fitur kategorikal: genre musik ("rock", "indie") dan gaya musik ("dance", "classic"). Fitur-fitur ini dapat terjadi dalam kombinasi yang berbeda. CatBoost dapat membuat fitur baru yang merupakan kombinasi dari yang terdaftar ("dance rock", "rock klasik", "dance indie", atau "indie classic").
Pengamatan menarik
CatBoost dapat dilatih tentang GPU, ini mempercepat pembelajaran secara signifikan, tetapi juga memperkenalkan banyak batasan, terutama mengenai fitur-fitur kategorikal. Dalam tugas ini, pelatihan pada GPU memberikan hasil yang jauh lebih buruk daripada pada CPU.
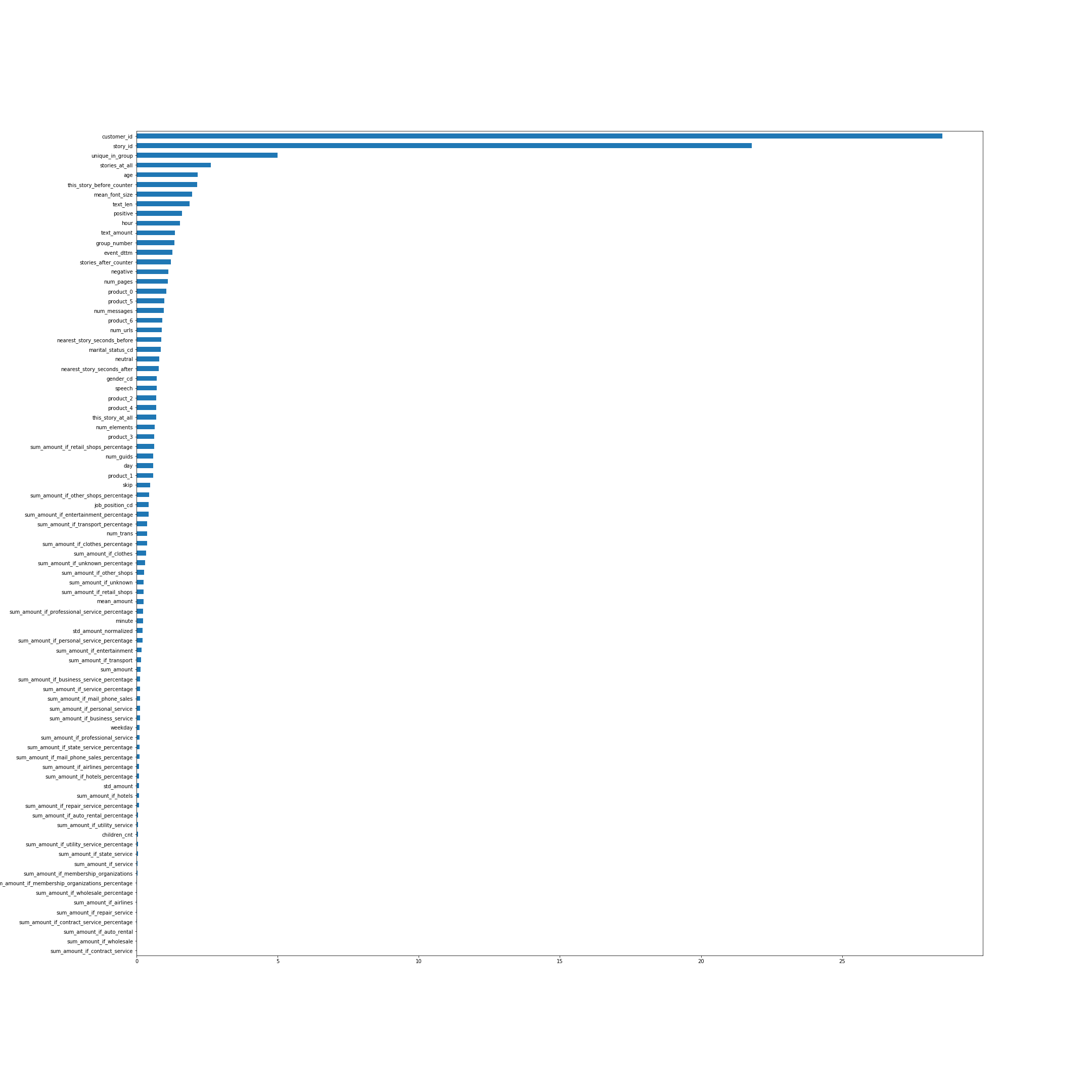
Pentingnya fitur menurut CatBoost. Dalam banyak hal, nama-nama fitur berbicara sendiri, tetapi beberapa, bukan yang paling jelas dari atas, saya akan menjelaskan:
- unique_in_group - jumlah cerita dalam grup. (Di dalam grup mereka selalu unik, tepat pada saat fitur itu dibuat saya tidak tahu itu)
- stories_at_all - jumlah cerita yang dilihat seseorang di masa depan dan di masa lalu.
- this_story_before_counter - berapa kali orang telah menonton cerita ini sebelumnya.
- text_amount - heuristik dengan volume teks.
- group_number - nomor seri grup.
- terdekat_story_seconds_before / after - pada dasarnya inilah saatnya sampai kelompok berikutnya ditampilkan.
Gambar bisa diklik.
Mari kita lihat distribusi reaksi dari waktu ke waktu:

Yaitu pada titik tertentu, distribusi reaksi sangat bervariasi.
Selanjutnya, saya ingin mendapatkan konfirmasi bahwa distribusi pada tes sama dengan pada akhir sampel pelatihan. Mari kita kirim semua sebagai prediksi, kami mendapatkan hasilnya 0,00237. Kami memperkirakan semua yang ada di bagian terakhir kereta - kami mendapat sekitar 0,009, di bagian pertama - sekitar -0,22. Jadi distribusi pada tes kemungkinan besar sama seperti pada akhir kereta dan jelas tidak terlihat seperti bagian utama. Hal ini menimbulkan hipotesis bahwa jika distribusi diperbaiki dalam prediksi kami, hasil di papan peringkat akan sangat meningkat, karena distribusi di kereta dan di tes berbeda.
Prediksi Ambang Batas
Pada langkah terakhir untuk mendapatkan prediksi akhir, tambahkan thrashhold:
Dalam model terakhir, saya memiliki sekitar 66% unit, jika dibiakkan dengan trashhold sama dengan 0. Ternyata memang, penurunan jumlah +1 memberi peningkatan kuat dalam kualitas. Hanya 3 premis terakhir yang dievaluasi, jadi saya mengirim prediksi model terbaik dengan trashhold yang berbeda sehingga persentase plus satu adalah sekitar 62, 58 dan 54.
Hasilnya, di papan peringkat publik, hasil terbaik saya adalah 0,37970 .
Hasil Kompetisi
tentang leaderboard publik / pribadiSeperti kebiasaan dalam kompetisi pembelajaran mesin, ketika Anda mengirim prediksi ke sistem, hasilnya hanya dievaluasi untuk bagian dari seluruh sampel uji. Biasanya sekitar 30%. Hasil untuk bagian ini tercermin dalam leaderboard publik. Untuk sisa tes, hasil akhir dievaluasi, yang ditampilkan setelah akhir kompetisi di papan peringkat pribadi.
Pada akhir kompetisi di papan publik, situasinya adalah sebagai berikut:
- 0,382 - HereCould BeYourAdvertising
- 0,379 - Anak-anak Lesha
- 0,372 - Tukang Kebun
- 0,35 - malas & akulov
Pada papan peringkat pribadi, yang menurutnya hasil akhir dipertimbangkan, saya beruntung dan orang-orang karena alasan tertentu turun dari tempat keempat ke posisi keempat. Ini posisi terakhir.
- 0,45807 anak-anak Lesha
- 0.45264 Tukang Kebun
- 0.44136 Zhuk
- 0.43704 HereCould BeYour Advertising
- 0,43474 malas & akulov
Apa yang tidak berhasil
- Saya mencoba menerjemahkan semua teks dari cerita menjadi vektor menggunakan fasttext, lalu mengelompokkan vektor dan menggunakan nomor cluster sebagai fitur kategorikal. Fitur ini berada di peringkat 3 teratas (setelah story_id dan customer_id) dalam fitur penting CatBoost, tetapi karena beberapa alasan fitur ini stabil dan secara signifikan memperburuk hasil validasi.
- Berkat cluster, orang bisa menemukan cerita yang terkait dengan Piala Dunia dan hanya ada di set pelatihan.
Namun, mengeluarkan benda seperti itu dari dataset tidak meningkatkan hasilnya. - secara default, CatBoost menghasilkan permutasi objek secara acak dan mempertimbangkan tanda-tanda untuk fitur kategorikal berdasarkan pada mereka. Tetapi kita dapat mengatakan kepada Katbust bahwa kita memiliki waktu dalam data - has_time = True. Kemudian akan berurutan, tanpa mencampur dataset. Dalam masalah ini, meskipun kita memiliki waktu, hasilnya dengan has_time lebih buruk.
Dalam kasus umum, jika ada waktu, tetapi tidak boleh diperhitungkan saat membuat Pengkodean Target Sasaran, maka model akan menggunakan informasi tentang jawaban yang benar dari masa depan dan dapat melatihnya. Dalam masalah ini, tampaknya, ini tidak memiliki banyak efek dan lebih penting untuk membahas beberapa kali dalam permutasi yang berbeda. - Ada ide untuk memberi bobot lebih pada benda-benda di ujung kereta, mis. untuk memperhitungkan lebih banyak objek dengan distribusi reaksi yang benar. Tetapi baik pada validasi dan pada leaderboard publik ini memberikan hasil yang lebih buruk.
- Anda dapat memperhitungkan reaksi berbeda dengan bobot berbeda selama pelatihan. Meskipun ini tidak membaik untuk saya, itu membantu beberapa tim.
Kesimpulan
Kompetisi ini ternyata menarik, karena menyatukan banyak komponen, seperti data tabular, teks, dan gambar. Ada banyak ruang untuk penelitian, banyak yang masih bisa dicoba. Secara umum, saya tidak harus bosan.
Terima kasih kepada penyelenggara kontes!
Semua kode diposting di github .