Redash baru-baru ini mulai berubah dari satu sistem eksekusi tugas ke yang lain. Yakni, mereka memulai transisi dari Celery ke RQ. Pada tahap pertama, hanya tugas-tugas yang tidak melakukan permintaan secara langsung yang ditransfer ke platform baru. Di antara tugas-tugas ini adalah mengirim email, mencari tahu permintaan mana yang harus diperbarui, merekam acara pengguna, dan tugas pendukung lainnya.

Setelah menyebarkan semua ini, diketahui bahwa pekerja RQ membutuhkan lebih banyak sumber daya komputasi untuk menyelesaikan volume tugas yang sama dengan yang digunakan Selery untuk menyelesaikannya.
Bahan, terjemahan yang kami terbitkan hari ini, didedikasikan untuk kisah bagaimana Redash menemukan penyebab masalah dan mengatasinya.
Beberapa kata tentang perbedaan antara Seledri dan RQ
Seledri dan RQ memiliki konsep pekerja proses. Baik di sana maupun di sana untuk organisasi pelaksanaan paralel tugas menggunakan penciptaan garpu. Ketika pekerja Seledri dimulai, beberapa proses garpu dibuat, masing-masing secara mandiri memproses tugas. Dalam kasus RQ, turunan pekerja hanya mengandung satu subproses (dikenal sebagai "pekerja keras"), yang melakukan satu tugas, dan kemudian dihancurkan. Ketika pekerja mengunduh tugas berikutnya dari antrian, ia menciptakan "pekerja keras" baru.
Saat bekerja dengan RQ, Anda dapat mencapai tingkat paralelisme yang sama seperti ketika bekerja dengan Celery, hanya dengan menjalankan lebih banyak proses pekerja. Namun, ada satu perbedaan halus antara Seledri dan RQ. Di Seledri, seorang pekerja membuat banyak instance dari subproses pada saat startup, dan kemudian menggunakannya berulang kali untuk menyelesaikan banyak tugas. Dan dalam kasus RQ, untuk setiap pekerjaan Anda perlu membuat garpu baru. Kedua pendekatan memiliki pro dan kontra, tetapi di sini kita tidak akan membicarakan hal ini.
Pengukuran kinerja
Sebelum saya mulai membuat profil, saya memutuskan untuk mengukur kinerja sistem dengan mencari tahu berapa lama wadah pekerja perlu memproses 1000 pekerjaan. Saya memutuskan untuk fokus pada tugas
record_event , karena ini adalah operasi ringan yang umum. Untuk mengukur kinerja, saya menggunakan perintah
time . Ini memerlukan beberapa perubahan pada kode proyek:
- Untuk mengukur kinerja melakukan 1000 tugas, saya memutuskan untuk menggunakan mode batch RQ, di mana, setelah memproses tugas, proses keluar.
- Saya ingin menghindari mempengaruhi pengukuran saya dengan tugas-tugas lain yang mungkin telah dijadwalkan untuk waktu saya mengukur kinerja sistem. Jadi saya memindahkan
record_event ke antrian terpisah yang disebut benchmark , menggantikan @job('default') dengan @job('benchmark') . Ini dilakukan tepat sebelum record_event dalam tasks/general.py .
Sekarang dimungkinkan untuk memulai pengukuran. Sebagai permulaan, saya ingin tahu berapa lama untuk memulai dan menghentikan pekerja tanpa beban. Waktu ini bisa dikurangkan dari hasil akhir yang didapat nanti.
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m14.728s user 0m6.810s sys 0m2.750s
Butuh 14,7 detik untuk menginisialisasi pekerja di komputer saya. Saya ingat itu.
Lalu saya menempatkan 1000
record_event uji dalam antrian
benchmark :
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]"
Setelah itu, saya memulai sistem dengan cara yang sama seperti yang saya lakukan sebelumnya, dan menemukan berapa lama untuk memproses 1000 pekerjaan.
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 1m57.332s user 1m11.320s sys 0m27.540s
Mengurangkan 14,7 detik dari apa yang terjadi, saya menemukan bahwa 4 pekerja memproses 1000 tugas dalam 102 detik. Sekarang mari kita coba mencari tahu mengapa demikian. Untuk melakukan ini, kami, sementara para pekerja sibuk, akan meneliti mereka menggunakan
py-spy .
Pembuatan profil
Kami menambahkan 1.000 tugas lagi ke antrian (ini harus dilakukan karena fakta bahwa selama pengukuran sebelumnya semua tugas diproses), jalankan pekerja dan memata-matai mereka.
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]" $ docker-compose exec worker bash -c 'nohup ./manage.py rq workers 4 benchmark & sleep 15 && pip install py-spy && rq info -u "redis://redis:6379/0" | grep busy | awk "{print $3}" | grep -o -P "\s\d+" | head -n 1 | xargs py-spy record -d 10 --subprocesses -o profile.svg -p' $ open -a "Google Chrome" profile.svg
Saya tahu bahwa tim sebelumnya sangat panjang. Idealnya, untuk meningkatkan keterbacaannya, ada baiknya memecahnya menjadi beberapa bagian terpisah, membaginya di tempat-tempat di mana urutan karakter
&& ditemukan. Tetapi perintah harus dieksekusi secara berurutan di dalam sesi
docker-compose exec worker bash , jadi semuanya tampak seperti itu. Berikut adalah deskripsi tentang apa yang dilakukan perintah ini:
- Meluncurkan 4 pekerja batch di latar belakang.
- Itu menunggu 15 detik (kira-kira sangat dibutuhkan untuk menyelesaikan unduhan mereka).
- Menginstal
py-spy . - Jalankan
rq-info dan temukan PID salah satu pekerja. - Merekam informasi tentang pekerjaan pekerja dengan PID yang diterima sebelumnya selama 10 detik dan menyimpan data dalam file
profile.svg
Hasilnya, “jadwal berapi-api” berikut diperoleh.
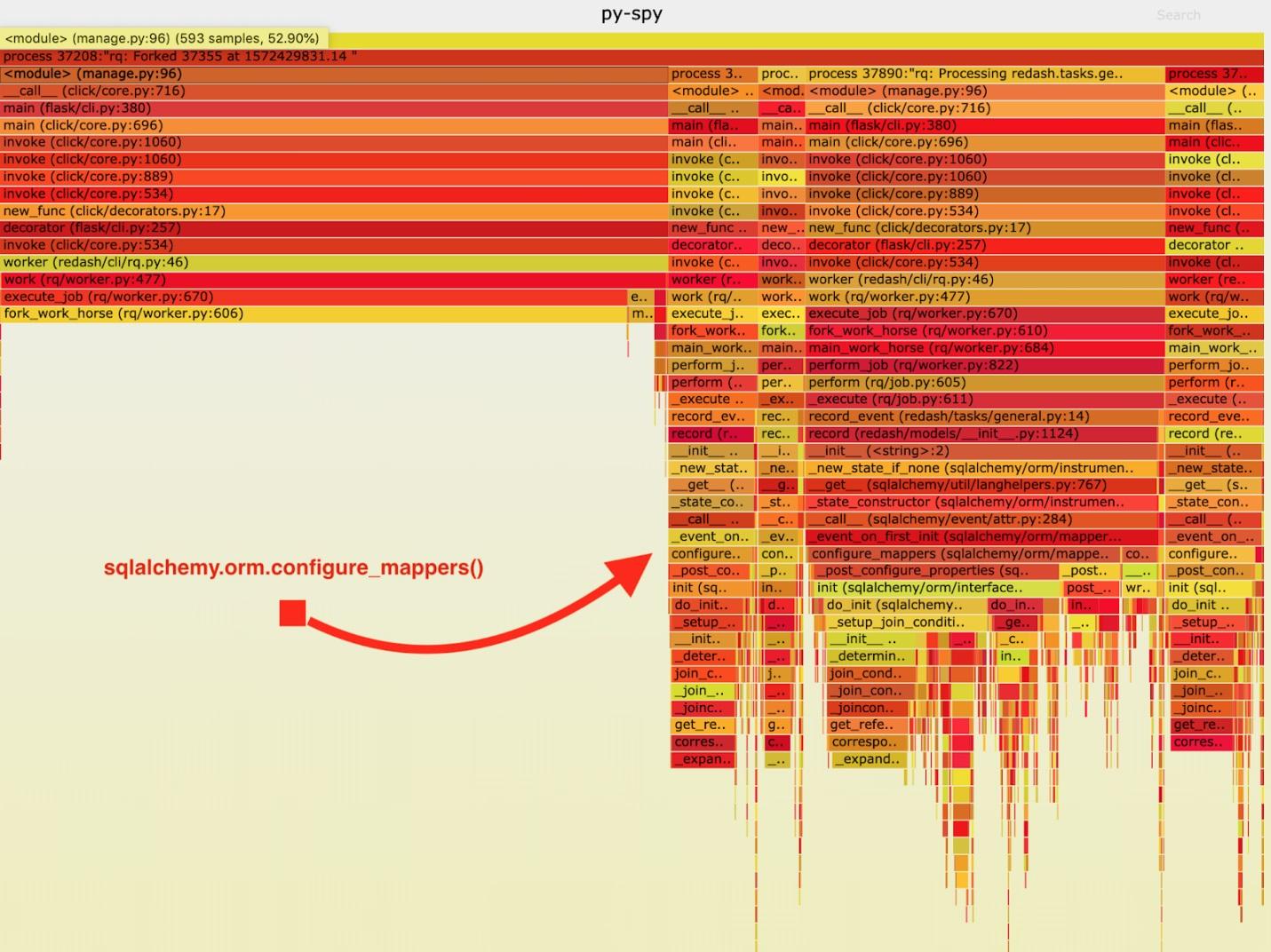 Visualisasi data yang dikumpulkan oleh py-spy
Visualisasi data yang dikumpulkan oleh py-spySetelah menganalisis data ini, saya perhatikan bahwa tugas
record_event menghabiskan waktu lama dalam menjalankannya di
sqlalchemy.orm.configure_mappers . Ini terjadi selama setiap tugas. Dari dokumentasi saya mengetahui bahwa pada saat itu menarik minat saya, hubungan semua pembuat peta yang dibuat sebelumnya diinisialisasi.
Hal-hal semacam itu sama sekali tidak diperlukan untuk terjadi pada setiap garpu. Kami dapat menginisialisasi hubungan sekali dalam pekerja induk dan menghindari mengulangi tugas ini di "workhorses".
Akibatnya, saya menambahkan panggilan ke
sqlalchemy.org.configure_mappers() ke kode sebelum memulai "pekerja keras" dan melakukan pengukuran lagi.
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)] $ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m39.348s user 0m15.190s sys 0m10.330s
Jika Anda mengurangi 14,7 detik dari hasil ini, ternyata kami telah meningkatkan waktu yang diperlukan untuk 4 pekerja untuk memproses 1000 tugas dari 102 detik menjadi 24,6 detik. Ini adalah peningkatan kinerja empat kali lipat! Berkat perbaikan ini, kami dapat melipatgandakan sumber daya produksi RQ dan mempertahankan bandwidth sistem yang sama.
Ringkasan
Dari semua ini, saya membuat kesimpulan berikut: perlu diingat bahwa aplikasi berperilaku berbeda jika itu adalah satu-satunya proses, dan jika itu datang ke garpu. Jika selama setiap tugas itu perlu untuk menyelesaikan beberapa tugas resmi yang sulit, maka lebih baik untuk menyelesaikannya terlebih dahulu, setelah melakukan ini sekali sebelum garpu selesai. Hal-hal seperti itu tidak terdeteksi selama pengujian dan pengembangan, oleh karena itu, setelah merasa bahwa ada sesuatu yang salah dengan proyek, mengukur kecepatannya dan mencapai akhir sambil mencari penyebab masalah dengan kinerjanya.
Pembaca yang budiman! Apakah Anda mengalami masalah kinerja dalam proyek Python yang dapat Anda selesaikan dengan menganalisis sistem kerja dengan cermat?
