
Halo, Khabrovchans! Kami terus memperkenalkan Anda dengan sistem hyperconverged Rusia AERODISK vAIR. Artikel ini akan fokus pada arsitektur sistem ini. Pada artikel terakhir, kami mem-parsing sistem file ARDFS kami, dan dalam artikel ini kami akan membahas semua komponen perangkat lunak utama yang membentuk vAIR dan tugas-tugas mereka.
Kami mulai deskripsi arsitektur dari bawah ke atas - dari penyimpanan ke manajemen.
Sistem File Driver ARDFS + Raft Cluster
Dasar dari vAIR adalah sistem file terdistribusi ARDFS, yang menggabungkan disk lokal dari semua node cluster menjadi satu kumpulan logis, berdasarkan disk virtual dengan satu atau satu skema toleransi kesalahan (faktor Replikasi atau Penghapusan pengkodean) dibentuk dari blok virtual 4MB. Penjelasan lebih rinci tentang pekerjaan ARDFS diberikan dalam artikel sebelumnya.
Raft Cluster Driver adalah layanan ARDFS internal yang memecahkan masalah penyimpanan metadata sistem file yang terdistribusi dan andal.
Metadata ARDFS secara konvensional dibagi menjadi dua kelas.
- pemberitahuan - informasi tentang operasi dengan objek penyimpanan dan informasi tentang objek itu sendiri;
- informasi layanan - mengatur kunci dan informasi konfigurasi untuk node penyimpanan.
Layanan RCD digunakan untuk mendistribusikan data ini. Secara otomatis menetapkan sebuah node dengan peran seorang pemimpin yang tugasnya adalah untuk mendapatkan dan menyebarkan metadata di seluruh node. Seorang pemimpin adalah satu-satunya sumber sejati informasi ini. Selain itu, pemimpin mengatur detak jantung, mis. memeriksa ketersediaan semua node penyimpanan (ini tidak ada hubungannya dengan ketersediaan mesin virtual, RCD hanyalah layanan untuk penyimpanan).
Jika karena alasan apa pun pemimpin telah menjadi tidak tersedia untuk salah satu node biasa selama lebih dari satu detik, simpul biasa ini menyelenggarakan pemilihan ulang pemimpin, meminta ketersediaan pemimpin dari node biasa lainnya. Jika ada kuorum, pemimpin dipilih kembali. Setelah mantan pemimpin "bangun", ia secara otomatis menjadi simpul biasa, karena pemimpin baru mengirimnya tim yang tepat.
Logika RCD itu sendiri bukanlah hal baru. Banyak solusi pihak ketiga dan komersial dan gratis juga dipandu oleh logika ini, tetapi solusi ini tidak cocok untuk kami (seperti FS open-source yang ada), karena mereka cukup berat, dan sangat sulit untuk mengoptimalkannya untuk tugas-tugas sederhana kami, jadi kami hanya menulis sendiri Layanan RCD.
Mungkin terlihat bahwa pemimpin adalah "leher sempit" yang dapat memperlambat kerja dalam kelompok besar dengan ratusan node, tetapi ini tidak demikian. Proses yang dijelaskan terjadi hampir secara instan dan “berbobot” sangat sedikit sejak kami menulisnya sendiri dan hanya menyertakan fungsi yang paling diperlukan. Selain itu, ini terjadi sepenuhnya secara otomatis, hanya menyisakan pesan dalam log.
MasterIO - Layanan Manajemen I / O Multithreaded
Setelah kumpulan ARDFS dengan disk virtual diatur, itu dapat digunakan untuk I / O. Pada titik ini, muncul pertanyaan khusus untuk sistem hyperconverged, yaitu: berapa banyak sumber daya sistem (CPU / RAM) yang dapat kita sumbangkan untuk IO?
Dalam sistem penyimpanan klasik, pertanyaan ini tidak terlalu akut, karena tugas penyimpanan hanya untuk menyimpan data (dan sebagian besar sumber daya penyimpanan sistem dapat dengan aman diberikan di bawah IO), dan tugas hyperconvergence, selain penyimpanan, juga mencakup pelaksanaan mesin virtual. Oleh karena itu, GCS membutuhkan penggunaan sumber daya CPU dan RAM terutama untuk mesin virtual. Nah, bagaimana dengan I / O?
Untuk mengatasi masalah ini, vAIR menggunakan layanan manajemen I / O: MasterIO. Tugas layanan ini sederhana - “Ambil semuanya dan bagikan” dijamin untuk mengambil jumlah sumber daya sistem n untuk input dan output dan, mulai dari mereka, mulai jumlah n input / output stream.
Awalnya, kami ingin menyediakan mekanisme "sangat cerdas" untuk mengalokasikan sumber daya untuk IO. Misalnya, jika tidak ada beban pada penyimpanan, maka sumber daya sistem dapat digunakan untuk mesin virtual, dan jika beban muncul, sumber daya ini “dengan lembut” dihilangkan dari mesin virtual dalam batas yang telah ditentukan sebelumnya. Namun upaya ini berakhir dengan kegagalan parsial. Pengujian menunjukkan bahwa jika beban ditingkatkan secara bertahap, maka semuanya OK, sumber daya (ditandai untuk kemungkinan penghapusan) secara bertahap ditarik dari VM demi I / O. Tetapi ledakan tajam dari penyimpanan menyebabkan tidak terlalu lunaknya penarikan sumber daya dari mesin virtual, dan sebagai hasilnya, antrian menumpuk pada prosesor dan, sebagai akibatnya, dan serigala lapar dan domba mati dan virtualka hang, dan tidak ada IOPS.
Mungkin di masa depan kami akan kembali ke masalah ini, tetapi untuk saat ini kami telah menerapkan penerbitan sumber daya untuk IO dengan cara kakek tua yang baik.
Berdasarkan data ukuran, administrator melakukan pra-alokasi nomor inti CPU dan RAM untuk layanan MasterIO. Sumber daya ini dialokasikan secara monopoli, yaitu mereka tidak dapat digunakan dengan cara apa pun untuk kebutuhan VM sampai admin mengizinkannya. Sumber daya dialokasikan secara merata, mis. jumlah sumber daya sistem yang sama diambil dari setiap node cluster. Pertama-tama, sumber daya prosesor menarik bagi MasterIO (RAM kurang penting), terutama jika kita menggunakan Erasure coding.
Jika kesalahan terjadi dengan ukuran, dan kami memberikan terlalu banyak sumber daya untuk MasterIO, maka situasinya mudah diselesaikan dengan menghapus sumber daya ini kembali ke kumpulan sumber daya VM. Jika sumber daya diam, maka mereka akan segera kembali ke sumber daya VM, tetapi jika sumber daya ini dibuang, Anda harus menunggu beberapa saat agar MasterIO melepaskannya dengan lembut.
Situasi sebaliknya lebih rumit. Jika kita perlu meningkatkan jumlah core untuk MasterIO, dan mereka sibuk dengan virtual, maka kita harus "bernegosiasi" dengan virtual, yaitu, memilihnya dengan pegangan, karena dalam mode otomatis dalam situasi semburan muatan yang tajam, operasi ini penuh dengan pembekuan VM dan perilaku berubah-ubah lainnya.
Oleh karena itu, banyak perhatian perlu diberikan untuk mengukur kinerja sistem hyperconverged IO (tidak hanya milik kita). Beberapa saat kemudian di salah satu artikel kami berjanji untuk mempertimbangkan masalah ini secara lebih rinci.
Hypervisor
Hypervisor Aist bertanggung jawab untuk menjalankan mesin virtual di vAIR. Hypervisor ini didasarkan pada hypervisor KVM yang telah teruji waktu. Pada prinsipnya, cukup banyak yang telah ditulis tentang karya KVM, jadi tidak ada kebutuhan khusus untuk melukisnya, cukup tunjukkan bahwa semua fungsi standar KVM disimpan di Bangau dan berfungsi dengan baik.
Oleh karena itu, di sini kami akan menjelaskan perbedaan utama dari KVM standar, yang kami implementasikan di Bangau. Bangau adalah bagian dari sistem (pra-instal hypervisor) dan dikendalikan dari konsol umum vAIR melalui Web-GUI (versi Rusia dan Inggris) dan SSH (jelas, hanya bahasa Inggris).
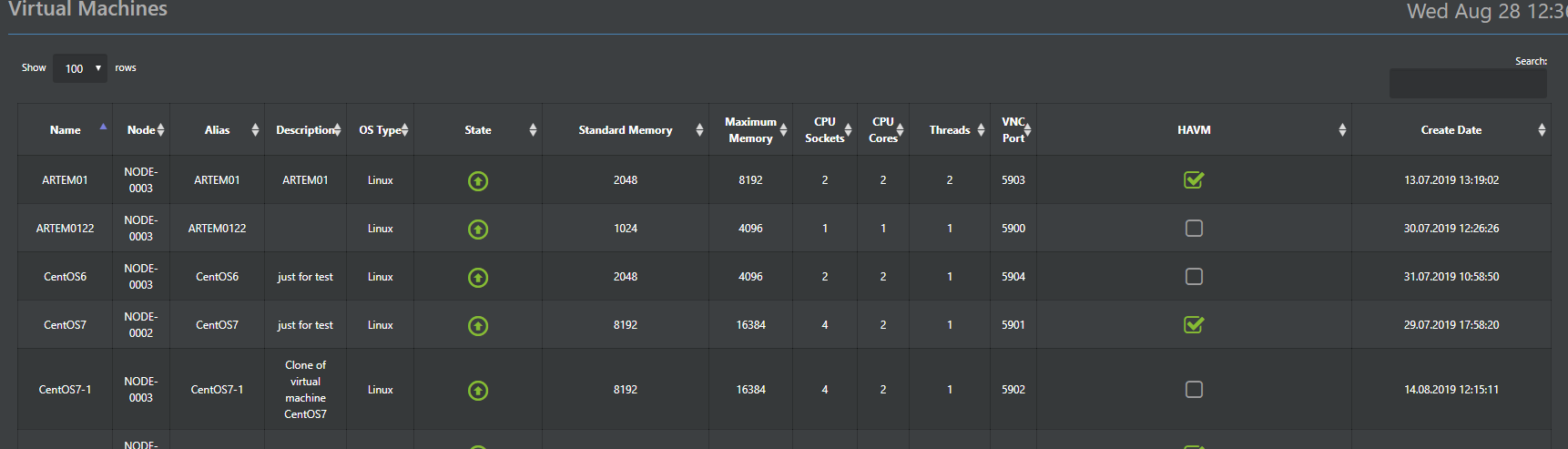
Selain itu, konfigurasi hypervisor disimpan dalam database ConfigDB yang didistribusikan (kira-kira nanti), yang juga merupakan satu titik kontrol. Yaitu, Anda dapat terhubung ke sembarang simpul di kluster dan mengelola semua tanpa perlu server manajemen yang terpisah.
Tambahan penting untuk fungsionalitas KVM standar adalah modul HA yang kami kembangkan. Ini adalah implementasi paling sederhana dari sekelompok mesin virtual ketersediaan tinggi, yang memungkinkan Anda untuk secara otomatis me-restart mesin virtual pada node cluster lain jika terjadi kegagalan simpul.
Fitur lain yang bermanfaat adalah penyebaran massal mesin virtual (relevan untuk lingkungan VDI), yang akan mengotomatiskan penyebaran mesin virtual dengan distribusi otomatis antar node tergantung pada bebannya.
Distribusi VM antar node adalah dasar untuk penyeimbangan beban otomatis (ala DRS). Fungsi ini belum tersedia dalam rilis saat ini, tetapi kami sedang aktif mengatasinya dan pasti akan muncul di salah satu pembaruan berikutnya.
VMware ESXi hypervisor secara opsional didukung, saat ini diimplementasikan menggunakan protokol iSCSI, dan dukungan NFS juga direncanakan di masa depan.
Sakelar virtual
Untuk implementasi perangkat lunak switch, komponen terpisah disediakan - Fraktal. Seperti pada komponen kami yang lain, kami beralih dari yang sederhana ke yang rumit, sehingga dalam versi pertama peralihan sederhana diterapkan, sementara perutean dan firewall diberikan ke perangkat pihak ketiga. Prinsip operasi adalah standar. Antarmuka fisik server terhubung oleh jembatan ke objek Fraktal - sekelompok port. Sekelompok port, pada gilirannya, dengan mesin virtual yang diinginkan dalam klaster. Organisasi VLAN didukung, dan di salah satu rilis selanjutnya, dukungan VxLAN akan ditambahkan. Semua sakelar yang dibuat didistribusikan secara default, mis. didistribusikan di semua node cluster, sehingga mesin virtual mana yang beralih untuk terhubung ke VM tidak bergantung pada node lokasi, ini adalah masalah keputusan administrator saja.
Pemantauan dan statistik
Komponen yang bertanggung jawab untuk pemantauan dan statistik (judul pekerjaan Monica), pada kenyataannya, adalah klon yang dirancang ulang dari sistem penyimpanan ENGINE. Pada suatu waktu, ia merekomendasikan dirinya dengan baik dan kami memutuskan untuk menggunakannya dengan vAIR dengan penyetelan yang mudah. Seperti semua komponen lainnya, Monica dieksekusi dan disimpan di semua node cluster secara bersamaan.
Tanggung jawab Monica yang sulit dapat diuraikan sebagai berikut:
Pengumpulan data:
- dari sensor perangkat keras (apa yang dapat memberi zat besi pada IPMI);
- dari objek logis vAIR (ARDFS, Bangau, Fraktal, MasterIO, dan objek lainnya).
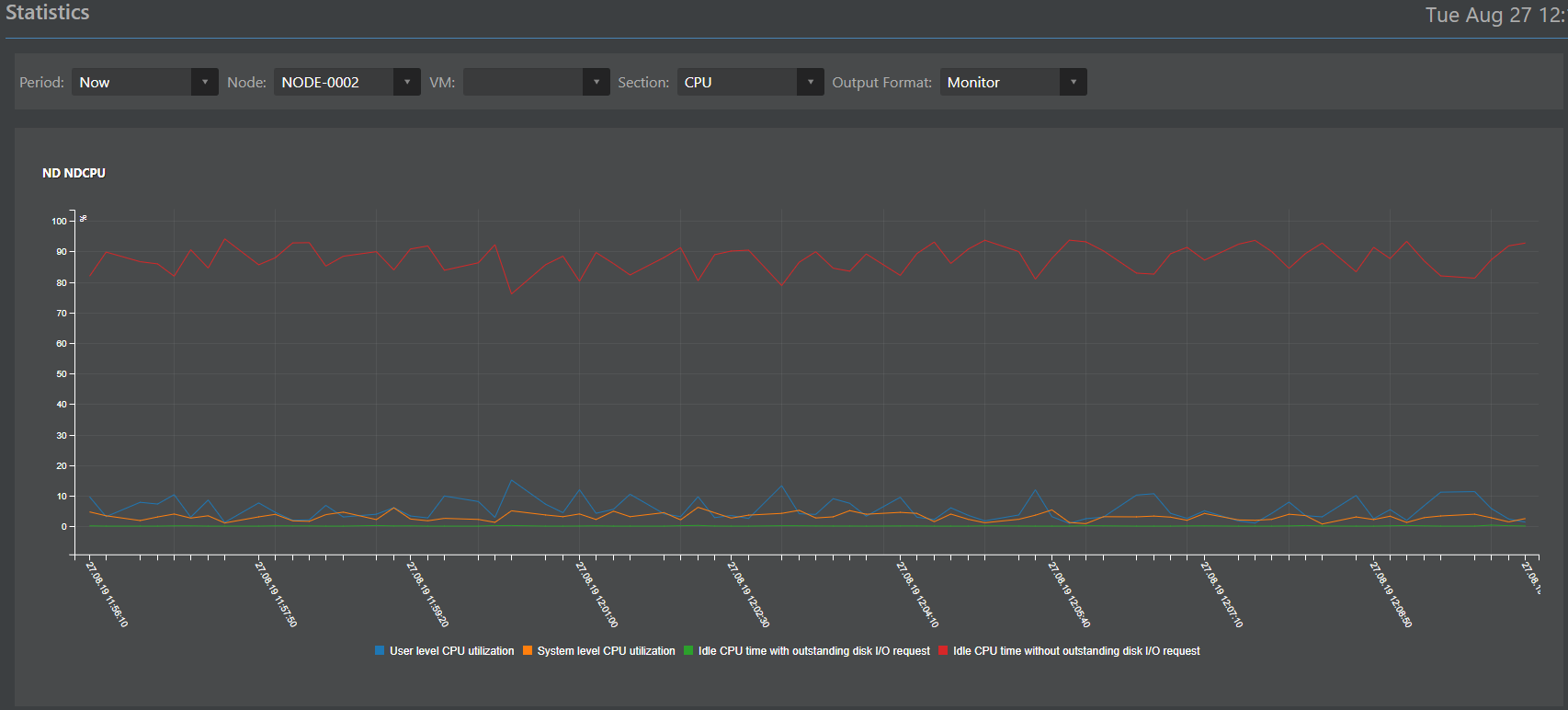
Mengumpulkan data dalam database terdistribusi;
Interpretasi data dalam bentuk:
Interaksi eksternal dengan sistem pihak ketiga melalui protokol SMTP (mengirim peringatan email) dan SNMP (interaksi dengan sistem pemantauan pihak ketiga).
Basis Konfigurasi Terdistribusi
Dalam paragraf sebelumnya, disebutkan bahwa banyak data disimpan di semua node cluster pada saat yang sama. Untuk mengatur metode penyimpanan ini, disediakan database ConfigDB terdistribusi khusus. Seperti namanya, database menyimpan konfigurasi semua objek cluster: hypervisor, mesin virtual, modul HA, switch, sistem file (jangan bingung dengan database metadata FS, ini adalah database lain), serta statistik. Data ini disimpan secara sinkron pada semua node dan konsistensi data ini merupakan prasyarat untuk operasi stabil vAIR.
Poin penting: meskipun fungsi ConfigDB sangat penting untuk operasi vAIR, kegagalannya, meskipun akan menghentikan cluster, tidak mempengaruhi konsistensi data yang disimpan di ARDFS, yang menurut kami merupakan nilai tambah untuk keandalan solusi secara keseluruhan.
ConfigDB juga merupakan satu titik manajemen, sehingga Anda dapat pergi ke sembarang cluster dari alamat IP dan sepenuhnya mengelola semua node dari cluster, yang cukup nyaman.
Selain itu, untuk mengakses sistem eksternal, ConfigDB menyediakan Restful API di mana Anda dapat mengkonfigurasi integrasi dengan sistem pihak ketiga. Sebagai contoh, kami baru-baru ini membuat integrasi pilot dengan beberapa solusi Rusia di bidang VDI dan keamanan informasi. Ketika proyek selesai, kami akan dengan senang hati menulis rincian teknis di sini.
Seluruh gambar
Akibatnya, kami memiliki dua versi arsitektur sistem.
Dalam kasus pertama - utama - perangkat lunak Avisor hypervisor dan Fractal switch KVM kami digunakan.
Skenario 1. Benar
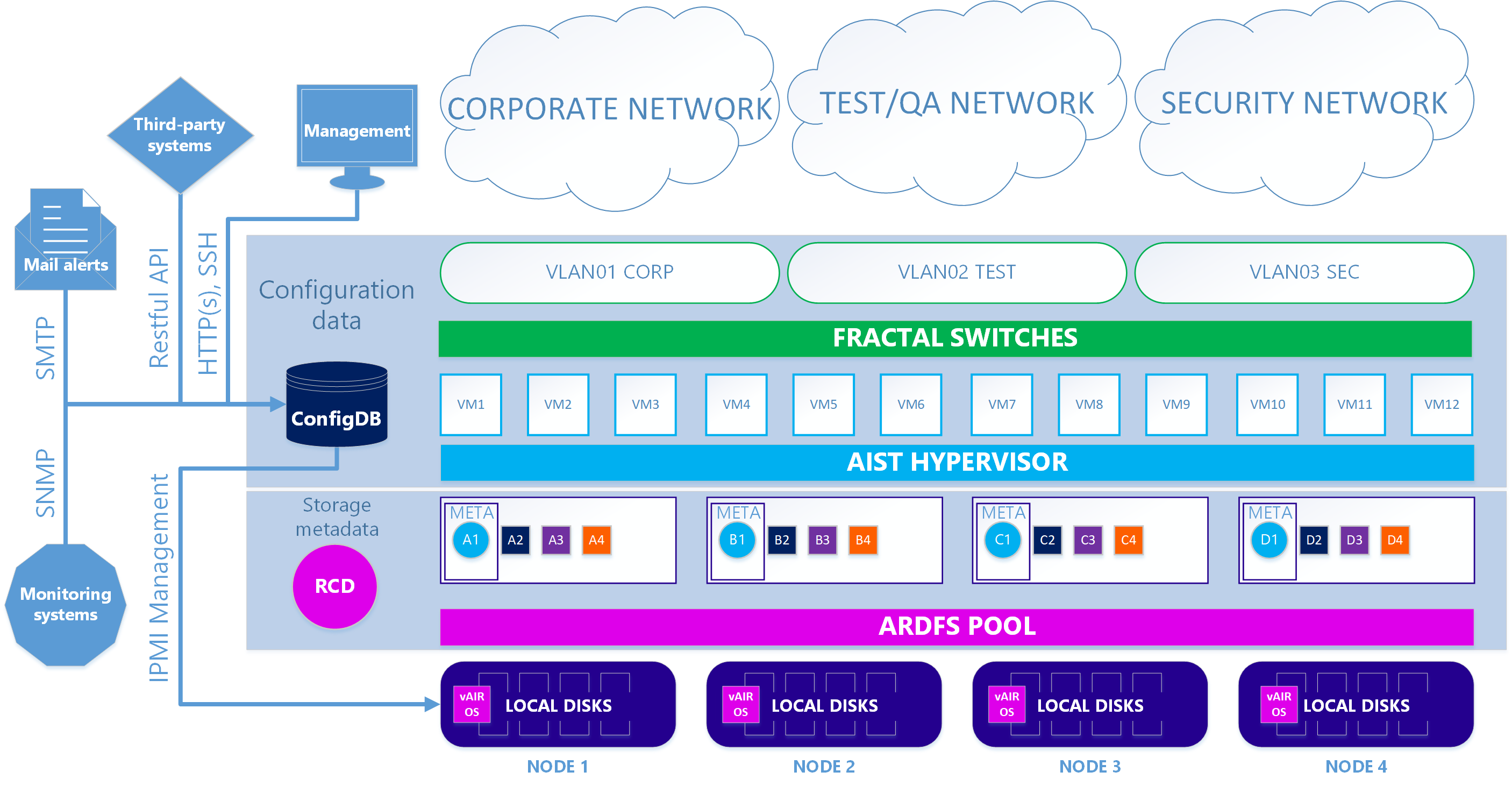
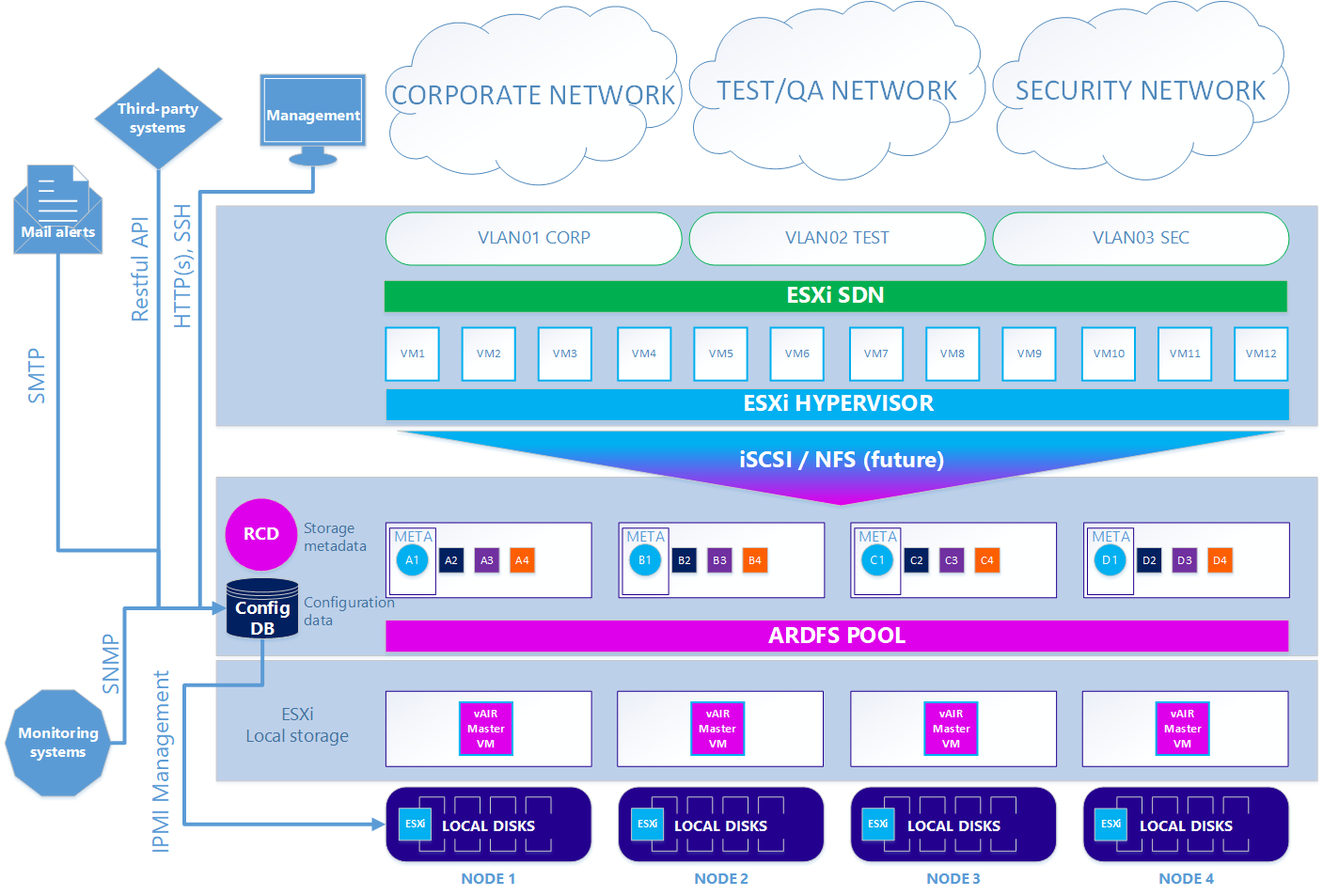
Pada opsi kedua - opsional - ketika Anda ingin menggunakan hypervisor ESXi, skema ini agak rumit. Untuk menggunakan ESXi, itu harus diinstal dengan cara standar pada drive lokal cluster. Selanjutnya, pada setiap node ESXi, mesin virtual vAIR MasterVM diinstal, yang berisi distribusi vAIR khusus untuk dijalankan sebagai mesin virtual VMware.
ESXi memberikan semua disk lokal gratis dengan meneruskan ke MasterVM. Di dalam MasterVM, disk ini sudah diformat secara standar di ARDFS dan dikirim ke luar (atau lebih tepatnya, kembali ke ESXi) menggunakan protokol iSCSI (dan di masa depan juga akan ada NFS) melalui antarmuka khusus di ESXi. Dengan demikian, mesin virtual dan jaringan perangkat lunak dalam hal ini disediakan oleh ESXi.
Skenario 2. ESXi
Jadi, kami telah membongkar semua komponen utama arsitektur vAIR dan tugas-tugas mereka. Pada artikel selanjutnya kita akan berbicara tentang fungsionalitas dan rencana yang sudah diterapkan untuk waktu dekat.
Kami menunggu komentar dan saran.