Setiap hari web global diisi ulang dengan artikel tentang algoritma pembelajaran mesin yang paling populer untuk memecahkan berbagai masalah. Selain itu, dasar dari artikel-artikel ini, sedikit berubah bentuk di satu tempat atau yang lain, mengembara dari satu peneliti data ke yang lain. Selain itu, semua pekerjaan ini disatukan oleh satu dalil yang diterima secara umum, tak terbantahkan: penerapan satu atau lain algoritma pembelajaran mesin tergantung pada ukuran dan sifat data yang tersedia dan tugas yang dihadapi.
Selain itu, peneliti data yang bersikeras, berbagi pengalaman mereka, menekankan:
"Pilihan metode penilaian sebagian harus bergantung pada data Anda dan pada apa, menurut Anda, model harus baik" ("Ilmu Data: informasi orang dalam untuk pemula. Termasuk bahasa R, oleh Cathy O'Neill, Rachel Shutt) .
Dengan kata lain, seorang ahli statistik / data seharusnya tidak hanya memiliki pengalaman di bidang subjek, tetapi juga beragam pengetahuan:
"Seorang peneliti data adalah orang yang memiliki pengetahuan di bidang-bidang berikut: matematika, statistik, teknik komputer, pembelajaran mesin, visualisasi, sarana pertukaran data ... ” (dari buku yang sama). Hanya dengan memuat pengetahuan secara menyeluruh dari area-area di atas ke dalam kepala, seseorang dapat mendekati pembelajaran mesin dan menemukan solusi untuk masalah-masalah yang ditunjukkan.
Bagi saya, permulaan ini sangat cocok untuk beberapa buku reguler satu setengah kilogram tentang Ilmu Pengetahuan Data, atau artikel cerita horor ilmiah dengan formula, simbol, dan coretan berlantai dua yang “tidak berharga” yang memiliki dampak menyedihkan dan menyedihkan pada pemula di bidang pembelajaran mesin dan hanya secara kebetulan. tertarik pada arah ini pembaca yang tidak berpengalaman, tidak terbebani dengan "pengetahuan yang diperlukan." Selain itu, angka bulat 10 artikel yang sama tentang 10 algoritma pembelajaran mesin paling populer (
misalnya ) hanya memperkuat efek yang dikenakan.
Di habr, mereka juga membedakan diri mereka sendiri :
"Jawaban untuk pertanyaan:" Algoritma pembelajaran mesin seperti apa yang harus saya gunakan? "Selalu terdengar seperti ini:" Tergantung pada keadaan ". Pilihan algoritma tergantung pada volume, kualitas dan sifat data. Itu tergantung pada bagaimana Anda mengatur hasilnya. Itu tergantung pada bagaimana instruksi untuk komputer yang mengimplementasikannya dibuat dari algoritma, dan juga pada berapa banyak waktu yang Anda miliki. Bahkan analis data yang paling berpengalaman tidak akan memberi tahu Anda algoritma mana yang lebih baik sampai mereka mencobanya. "Tidak diragukan lagi, semua pengetahuan ini, serta ketekunan dan minat diperlukan dan berguna dalam mencapai hasil yang baik tidak hanya di jalan untuk memahami pembelajaran mesin, tetapi juga di banyak bidang lainnya. Selain itu, mereka akan memfasilitasi pemahaman bahwa algoritma pembelajaran mesin (selanjutnya disebut sebagai algoritma) jauh dari selusin; tetapi ini baru kemudian, dengan studi independen.
Tujuan saya adalah memperkenalkan pembaca pada algoritma yang paling banyak digunakan dari sudut pandang praktis dan dapat diakses. (Fakta bahwa saya bukan seorang programmer dan, apalagi, bukan seorang ahli matematika (suci-suci-suci!) Harus menggarisbawahi minat dalam narasi. Pendidikan teknik ditambah pengalaman dalam "pertumbuhan subjek" 10 tahun (hanya semacam angka ajaib) ) - seperti yang mereka katakan, dan semua barang-barang saya, semua barang bawaan saya untuk belajar mesin, terima kasih untuk pengalaman yang diperoleh dalam industri minyak, ide-ide untuk menggunakan jaringan saraf tiruan dan algoritma pembelajaran mesin ditemukan segera (baca - perlu ada set data.) Yang tersisa hanyalah berurusan Scarlet - belajar memelintir-memelintir data untuk mengirimkannya dengan benar ke input "program" dan yang, pada kenyataannya, algoritma untuk memilih. Dan kemudian dalam lingkaran setan. Saya perhatikan bahwa jalan saya berduri dan menyenangkan - "peluru bersiul di atas kepala" (dari m / f "The Adventures of Funtik"), - tapi masih saya berhasil membuat catatan, dan jika minat ditunjukkan, maka di masa depan saya akan mempublikasikan pesan lain.)
Jadi, saya mengusulkan mendekati "permesinan" di sisi lain: mengapa tidak memberi makan set data Anda yang ada (dalam contoh Anda akan memuat set data yang dapat dengan mudah dilatih) ke banyak algoritma sekaligus, dan menurut hasil memutuskan mana yang harus memperhatikan lebih dekat ke studi cermat berikutnya dan pemilihan parameter optimal yang meningkatkan hasil. Selain itu, nilai utama dari metode yang dibahas di atas adalah bahwa hasilnya akan menjawab pertanyaan tentang nilai set data Anda:
"mulailah dengan memecahkan masalah dan pastikan Anda memiliki sesuatu untuk dioptimalkan" (juga dari beberapa lalu statistik yang terus-menerus berbunyi, "hormatilah" padanya, saran yang bagus!).
Bagaimana ini dibuat?
Diketahui bahwa sebagian besar masalah diselesaikan dengan bantuan algoritma berkaitan dengan masalah klasifikasi (klasifikasi) dan analisis regresi (analisis prediktif).
Klasifikasi berarti diferensiasi yang mantap dari unit pengamatan (contoh) dari suatu set data ke kategori tertentu (kelas) berdasarkan hasil pelatihan.
Analisis regresi adalah seperangkat metode statistik dan proses untuk menilai hubungan antara variabel [
Statistik: Buku Teks / Ed. prof. M.R. Efimova. - M.: INFRA-M, 2002 ]. Tujuan dari analisis regresi adalah untuk mengevaluasi nilai variabel output kontinu dari nilai-nilai variabel input [
tautan ].
Kami mengabaikan fakta bahwa analisis regresi memiliki dua metode berbeda - pemodelan prediktif dan peramalan. Kami hanya mencatat bahwa jika ada deret waktu (data deret waktu), kemudian menggunakan model regresi berdasarkan tren eksplisit, tunduk pada stasioneritas (keteguhan), peramalan dapat dilakukan. Jika kondisi untuk pembentukan tingkat perubahan deret waktu, yaitu, proses non-stasioner tidak diamati, maka terserah pemodelan prediktif. Khusus ditujukan pada penguasaan lengkap ML, saya mengusulkan untuk membaca artikel ini dalam bahasa Inggris:
tautan . Jika diskusi muncul tentang ini, saya akan senang untuk mengambil bagian di dalamnya.
Karena deret waktu tidak akan digunakan dalam contoh di artikel ini, istilah
peramalan mengacu pada
analisis prediktif .
Untuk mengatasi masalah klasifikasi dan peramalan, seluruh jajaran algoritma cocok, beberapa di antaranya akan kita bahas nanti. Untuk kenyamanan, teks selanjutnya akan dibagi menjadi dua bagian: pertama kita mempertimbangkan algoritma klasifikasi yang paling umum, yang kedua kita curahkan untuk algoritma analisis regresi. Untuk setiap bagian, set "mainan" data dimuat dari
perpustakaan scikit-learn (v0.21.3):
dataset digit (klasifikasi) dan
dataset harga rumah boston (regresi) akan disajikan, serta tautan ke setiap algoritma perpustakaan scikit-learn library untuk pemeriksaan diri dan, mungkin, belajar.
Semua contoh kode dieksekusi di konsol
IDE Spyder 3.3.3 pada Python 3.7.3.
Masalah klasifikasi
Pertama, kami mengimpor modul dan fungsi yang diperlukan yang akan kami gunakan untuk menyelesaikan masalah klasifikasi data:
Unduh dataset 'digit' langsung dari
modul 'sklearn.datasets' :
IDE Spyder menyediakan alat yang mudah digunakan "Variable Manager", yang berguna setiap saat belajar mesin pembelajaran (setidaknya untuk saya), seperti
"trik" lainnya :
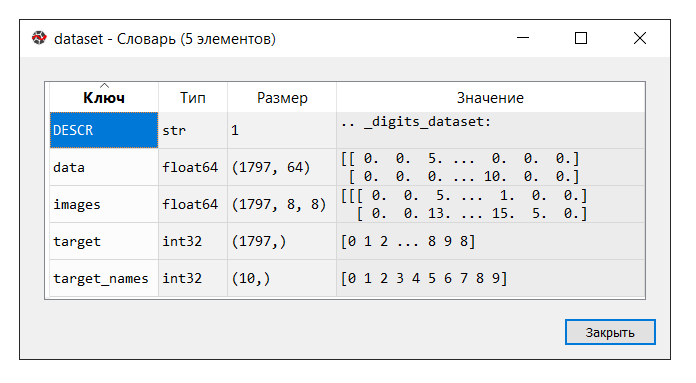
Jalankan kodenya. Di konsol "manajer variabel", klik pada variabel
dataset . Kamus berikut ditampilkan:
Deskripsi dataset adalah sebagai berikut:
Dalam contoh ini, kami tidak memerlukan kunci 'gambar', jadi kami menetapkan variabel 'data' ke variabel
X , yang merupakan array NumPy multidimensi dengan sekumpulan atribut, dengan ukuran 1797 baris dengan 64 kolom, dan variabel
Y untuk 'target', array NumPy multidimensi dengan penanda untuk masing-masing tali.
Selanjutnya, kita membagi set data ke dalam bagian pelatihan dan pengujian, mengonfigurasi parameter untuk mengevaluasi algoritma (validasi silang digunakan [
satu ,
dua ]), mendefinisikan metrik 'akurasi' dalam parameter 'scoring' [
tautan ]. Akurasi adalah proporsi objek yang diklasifikasikan dengan benar relatif terhadap jumlah total objek. Semakin dekat hasilnya ke 1, semakin baik [
tautan ]. Selain itu, dalam salah satu buku ditemukan bahwa hasil dari 0,95 (atau 95%) dan lebih tinggi dianggap sangat baik.
Biarkan variabel
X_train dan
Y_train digunakan untuk tujuan pelatihan,
X_test dan
Y_test untuk pengembangan nilai perkiraan. Dalam kasus ini, variabel
Y_test tidak terlibat dalam penghitungan perkiraan: menggunakan metode 'skor', yang sama untuk setiap algoritme yang disajikan di bawah ini, kami akan menghitung jawaban yang benar menggunakan metrik 'akurasi'. Ini akan memungkinkan kita untuk menilai bagaimana algoritma mengatasi tugas tersebut. Saya tidak berdebat, bagi kami, sangat manusiawi tidak mendorong mobil dengan jawaban yang benar, tetapi bagaimana lagi memeriksa kinerjanya?
Di bawah ini adalah daftar algoritme yang kami beri makan kumpulan data. Berdasarkan hasil perhitungan, kami akan menyimpulkan algoritma mana (yang mana dari algoritma) yang menunjukkan efisiensi terbesar. Metode ini dapat juga disebut
"uji blitz dari algoritma pembelajaran mesin" (selanjutnya - tes blitz).
Untuk kenyamanan, informasi akan disingkat di sebelah setiap algoritma. Perlu dicatat bahwa pengaturan masing-masing algoritma diterima secara default (default), dengan pengecualian beberapa titik, untuk memberikan kondisi yang sama.
Algoritma Linier:
- Regresi Logistik * /
Regresi Logistik ('LR')
* Kata "regresi" dapat membingungkan. Tetapi jangan lupa bahwa "Regresi Logistik" adalah algoritma klasifikasi-
Analisis Diskriminan Linier ('LDA')
Algoritma Nonlinier:
- Metode k-tetangga terdekat (klasifikasi) /
K-Neighbors Classifier ('KNN')
-
Decision Tree Classifier ('CART')
-
Klasifikasi Naif Bayes ('NB')
- Metode
Klasifikasi Vektor Dukungan Linier (Klasifikasi) /
Klasifikasi Vektor Dukungan Linier ('LSVC')
- Metode
Vektor Dukungan (Klasifikasi) /
Klasifikasi V-Dukungan V ('SVC')
Algoritma Jaringan Saraf Tiruan:
-
Multilayer Perceptron /
Multilayer Perceptrons ('MLP')
Algoritma Ensemble:
- Bagging (klasifikasi) /
Bagging Classifier ('BG') (Bagging = Bootstrap aggregating)
-
Klasifikasi Hutan Acak ('RF')
-
Pengklasifikasi Pohon Ekstra ('ET')
- AdaBoost (klasifikasi) /
AdaBoost Classifier ('AB') (AdaBoost = Adaptive Boosting)
- Gradient boosting (klasifikasi) /
Gradient Boosting Classifier ('GB')
Dengan demikian, daftar 'model' berisi model-model berikut:
models = [] models.append(('LR', LogisticRegression())) models.append(('LDA', LinearDiscriminantAnalysis())) models.append(('KNN', KNeighborsClassifier())) models.append(('CART', DecisionTreeClassifier())) models.append(('NB', GaussianNB())) models.append(('LSVC', LinearSVC())) models.append(('SVC', SVC())) models.append(('MLP', MLPClassifier())) models.append(('BG', BaggingClassifier(n_estimators=n_estimators))) models.append(('RF', RandomForestClassifier(n_estimators=n_estimators))) models.append(('ET', ExtraTreesClassifier(n_estimators=n_estimators))) models.append(('AB', AdaBoostClassifier(n_estimators=n_estimators, algorithm='SAMME'))) models.append(('GB', GradientBoostingClassifier(n_estimators=n_estimators)))
Seperti yang telah disebutkan, efektivitas setiap algoritma dievaluasi menggunakan cross-validation. Akibatnya, sebuah pesan ditampilkan (msg - singkatan dari pesan) yang berisi informasi berikut: nama model dalam bentuk singkatan, skor rata-rata 10 kali lipat validasi silang pada data pelatihan (metrik 'akurasi'), standar deviasi ditampilkan dalam tanda kurung , serta nilai metrik 'akurasi' pada data uji.
Setelah menjalankan kode, kami mendapatkan hasil berikut:
LR: train = 0.957 (0.014) / test = 0.948 LDA: train = 0.951 (0.014) / test = 0.946 KNN: train = 0.985 (0.013) / test = 0.981 CART: train = 0.843 (0.033) / test = 0.830 NB: train = 0.819 (0.048) / test = 0.806 LSVC: train = 0.942 (0.017) / test = 0.928 SVC: train = 0.343 (0.079) / test = 0.342 MLP: train = 0.972 (0.012) / test = 0.961 BG: train = 0.952 (0.021) / test = 0.941 RF: train = 0.968 (0.017) / test = 0.965 ET: train = 0.980 (0.010) / test = 0.975 AB: train = 0.827 (0.049) / test = 0.823 GB: train = 0.964 (0.013) / test = 0.968
Bagan rentang (
"kotak dengan kumis" ) (diagram kotak atau plot dan kumis, plot kotak):
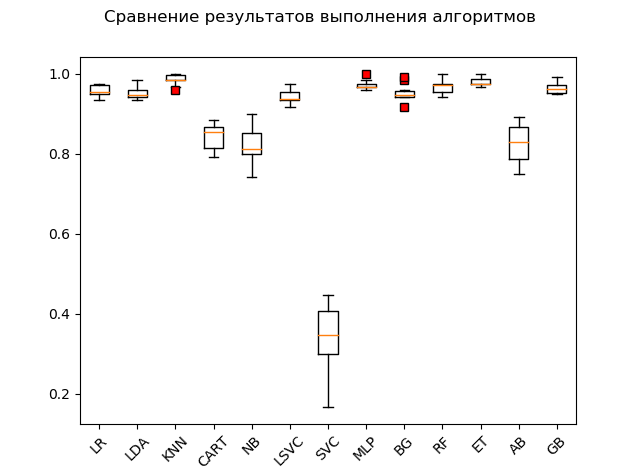
Sebagai hasil dari tes blitz pada data mentah, dapat dilihat bahwa yang paling efektif pada data uji adalah algoritma 'KNN' (k-tetangga terdekat), 'ET' (pohon ekstra), 'GB' (gradien "meningkatkan"), 'RF' (hutan acak) dan 'MLP' (multilayer perceptron):
KNN: train = 0.985 (0.013) / test = 0.981 ET: train = 0.980 (0.010) / test = 0.975 GB: train = 0.964 (0.013) / test = 0.968 RF: train = 0.968 (0.017) / test = 0.965 MLP: train = 0.972 (0.012) / test = 0.961 LR: train = 0.957 (0.014) / test = 0.948 LDA: train = 0.951 (0.014) / test = 0.946 BG: train = 0.952 (0.021) / test = 0.941 LSVC: train = 0.942 (0.017) / test = 0.928 CART: train = 0.843 (0.033) / test = 0.830 AB: train = 0.827 (0.049) / test = 0.823 NB: train = 0.819 (0.048) / test = 0.806 SVC: train = 0.343 (0.079) / test = 0.342
Namun, banyak algoritma sangat pilih-pilih tentang data yang disajikan. Oleh karena itu, salah satu langkah yang diperlukan adalah persiapan data awal yang disebut (praproses data [
tautan ])
Namun, itu terjadi bahwa algoritma menunjukkan hasil terbaik tanpa pemrosesan awal. Karenanya rekomendasi berikut: sertakan dalam blitz test beberapa transformasi dari kumpulan data asli dan, setelah melakukan perhitungan, bandingkan hasilnya untuk menangkap esensi masalah secara keseluruhan.
Metode persiapan data pendahuluan yang paling umum digunakan adalah:
-
standardisasi;
-
penskalaan (rentang default adalah [0, 1]);
-
normalisasiOperasi ini dengan evaluasi selanjutnya dapat diotomatisasi dan diletakkan pada conveyor menggunakan alat
Pipeline .
Cuplikan kode dengan standarisasi data sumber adalah sebagai berikut:
Perhatikan penambahan '_SS' (kependekan dari StandardScaler) ke daftar nama. Hal ini dilakukan agar tidak menumpuk hasil, serta untuk melihatnya dengan mudah menggunakan "manajer variabel" setelah konversi dilakukan.
Menjalankan cuplikan kode menghasilkan hasil berikut:
SS_LR: train = 0.958 (0.015) / test = 0.949 SS_LDA: train = 0.951 (0.014) / test = 0.946 SS_KNN: train = 0.968 (0.023) / test = 0.970 SS_CART: train = 0.853 (0.036) / test = 0.835 SS_NB: train = 0.756 (0.046) / test = 0.751 SS_LSVC: train = 0.945 (0.018) / test = 0.941 SS_SVC: train = 0.976 (0.015) / test = 0.990 SS_MLP: train = 0.976 (0.012) / test = 0.973 SS_BG: train = 0.947 (0.018) / test = 0.948 SS_RF: train = 0.973 (0.016) / test = 0.970 SS_ET: train = 0.980 (0.012) / test = 0.975 SS_AB: train = 0.827 (0.049) / test = 0.823 SS_GB: train = 0.964 (0.013) / test = 0.968
Kotak Kumis (StandardScaler):
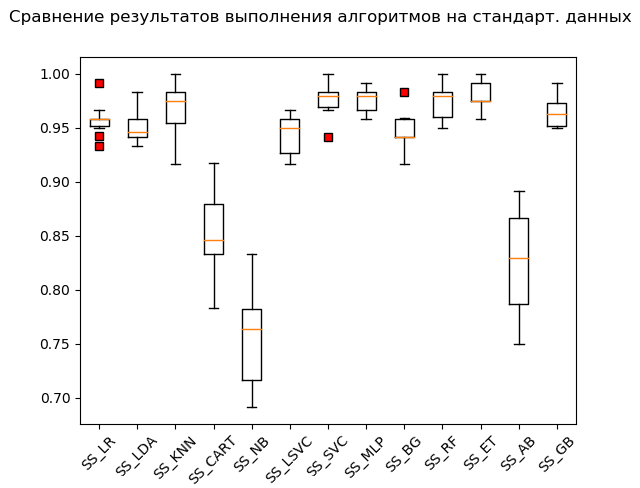
Menurut hasil perhitungan pada data standar, algoritma berikut menjadi pemimpin:
SS_SVC: train = 0.976 (0.015) / test = 0.990 SS_ET: train = 0.980 (0.012) / test = 0.975 SS_MLP: train = 0.976 (0.012) / test = 0.973 SS_KNN: train = 0.968 (0.023) / test = 0.970 SS_RF: train = 0.973 (0.016) / test = 0.970 SS_GB: train = 0.964 (0.013) / test = 0.968 SS_LR: train = 0.958 (0.015) / test = 0.949 SS_BG: train = 0.947 (0.018) / test = 0.948 SS_LDA: train = 0.951 (0.014) / test = 0.946 SS_LSVC: train = 0.945 (0.018) / test = 0.941 SS_CART: train = 0.853 (0.036) / test = 0.835 SS_AB: train = 0.827 (0.049) / test = 0.823 SS_NB: train = 0.756 (0.046) / test = 0.751
Seperti yang mereka katakan, dari kain menjadi kekayaan: metode vektor dukungan ('SVC'), dimasukkan oleh data terstandarisasi, melakukan sisanya, menunjukkan hasil yang sangat baik. Selama pemeriksaan "manual", membandingkan nilai-nilai variabel
Y_test dan
predictions_SS [6] , algoritma tidak hanya mengunyah beberapa nilai.
Selanjutnya, kode yang sama dijalankan untuk fungsi MinMaxScaler (scaling) dan Normalizer (normalisasi). Saya tidak akan memberikan kode lengkap dalam artikel. Anda dapat mengunduhnya dari repositori saya di
tautan GitHub :.
Ingatlah untuk menggantung sebentar dan menertawakan diri Anda di 'hanya untuk tujuan pendidikan'! :)
Akibatnya, setelah melalui seluruh kode, kami mendapatkan hasil berikut:
LR: train = 0.957 (0.014) / test = 0.948 LDA: train = 0.951 (0.014) / test = 0.946 KNN: train = 0.985 (0.013) / test = 0.981 CART: train = 0.843 (0.033) / test = 0.830 NB: train = 0.819 (0.048) / test = 0.806 LSVC: train = 0.942 (0.017) / test = 0.928 SVC: train = 0.343 (0.079) / test = 0.342 MLP: train = 0.972 (0.012) / test = 0.961 BG: train = 0.952 (0.021) / test = 0.941 RF: train = 0.968 (0.017) / test = 0.965 ET: train = 0.980 (0.010) / test = 0.975 AB: train = 0.827 (0.049) / test = 0.823 GB: train = 0.964 (0.013) / test = 0.968 SS_LR: train = 0.958 (0.015) / test = 0.949 SS_LDA: train = 0.951 (0.014) / test = 0.946 SS_KNN: train = 0.968 (0.023) / test = 0.970 SS_CART: train = 0.853 (0.036) / test = 0.835 SS_NB: train = 0.756 (0.046) / test = 0.751 SS_LSVC: train = 0.945 (0.018) / test = 0.941 SS_SVC: train = 0.976 (0.015) / test = 0.990 SS_MLP: train = 0.976 (0.012) / test = 0.973 SS_BG: train = 0.947 (0.018) / test = 0.948 SS_RF: train = 0.973 (0.016) / test = 0.970 SS_ET: train = 0.980 (0.012) / test = 0.975 SS_AB: train = 0.827 (0.049) / test = 0.823 SS_GB: train = 0.964 (0.013) / test = 0.968 MMS_LR: train = 0.961 (0.013) / test = 0.953 MMS_LDA: train = 0.951 (0.014) / test = 0.946 MMS_KNN: train = 0.985 (0.013) / test = 0.981 MMS_CART: train = 0.850 (0.027) / test = 0.840 MMS_NB: train = 0.796 (0.045) / test = 0.786 MMS_LSVC: train = 0.964 (0.012) / test = 0.958 MMS_SVC: train = 0.963 (0.016) / test = 0.956 MMS_MLP: train = 0.972 (0.011) / test = 0.963 MMS_BG: train = 0.948 (0.024) / test = 0.946 MMS_RF: train = 0.973 (0.014) / test = 0.968 MMS_ET: train = 0.983 (0.010) / test = 0.981 MMS_AB: train = 0.827 (0.049) / test = 0.823 MMS_GB: train = 0.963 (0.013) / test = 0.968 N_LR: train = 0.938 (0.020) / test = 0.919 N_LDA: train = 0.952 (0.013) / test = 0.949 N_KNN: train = 0.981 (0.012) / test = 0.985 N_CART: train = 0.834 (0.028) / test = 0.825 N_NB: train = 0.825 (0.043) / test = 0.805 N_LSVC: train = 0.960 (0.014) / test = 0.953 N_SVC: train = 0.551 (0.053) / test = 0.586 N_MLP: train = 0.963 (0.018) / test = 0.946 N_BG: train = 0.949 (0.016) / test = 0.938 N_RF: train = 0.973 (0.015) / test = 0.970 N_ET: train = 0.982 (0.012) / test = 0.980 N_AB: train = 0.825 (0.040) / test = 0.820 N_GB: train = 0.953 (0.022) / test = 0.956
Hasil 'Top 5':
SS_SVC: train = 0.976 (0.015) / test = 0.990 N_KNN: train = 0.981 (0.012) / test = 0.985 KNN: train = 0.985 (0.013) / test = 0.981 MMS_KNN: train = 0.985 (0.013) / test = 0.981 MMS_ET: train = 0.983 (0.010) / test = 0.981
Dengan demikian, menurut hasil tes blitz dari algoritma pembelajaran mesin untuk memecahkan masalah klasifikasi dataset 'digit', algoritma pembelajaran mesin yang paling cocok adalah: metode k-tetangga terdekat ('KNN'), metode vektor dukungan ('SVC') dan ekstra-pohon ('ET'). Algoritma ini harus lebih diperhatikan untuk pengembangan lebih lanjut dari hasil yang bertujuan untuk meningkatkan efisiensi perhitungan. Semuanya, seperti kata mereka, bisa dipecahkan.
Dan pada nada terangkat ini, lanjutkan dengan lancar ke bagian ke-2.
Peramalan masalah
Kami bergerak dengan ibu jari:
Jalankan kode dan urus kamus. Deskripsi dan kunci adalah sebagai berikut:


Kami menetapkan kunci 'data' ke variabel
X , yang merupakan array NumPy multidimensi dengan seperangkat atribut, dimensi 506 baris dengan 13 kolom, dan variabel
Y - 'target', array NumPy multidimensi dengan spidol untuk setiap baris.
Kami membagi set data menjadi bagian pelatihan dan pengujian, mengonfigurasikan parameter untuk mengevaluasi algoritma. Dalam parameter 'penilaian' kami menetapkan salah satu
metrik 'r2' tradisional untuk analisis regresi:
R2 - koefisien determinasi - ini adalah proporsi varians dari variabel dependen, dijelaskan oleh model yang dimaksud (
tautan ).
“Koefisien determinasi untuk model dengan konstanta mengambil nilai dari 0 hingga 1. Semakin dekat koefisien ke 1, semakin kuat ketergantungannya. Saat mengevaluasi model regresi, ini ditafsirkan sebagai pencocokan model dengan data. Untuk model yang dapat diterima, diasumsikan bahwa koefisien determinasi setidaknya harus setidaknya 50% (dalam hal ini, koefisien korelasi berganda melebihi 70% modulo). Model dengan koefisien determinasi di atas 80% dapat dianggap cukup baik (koefisien korelasi melebihi 90%). Kesetaraan koefisien determinasi terhadap persatuan berarti bahwa variabel yang dijelaskan persis dijelaskan oleh model yang sedang dipertimbangkan ” (ibid.).
Untuk mengatasi masalah perkiraan, kami menggunakan algoritme berikut:
Algoritma Linier:
-
Regresi Linier ('LR')
- Regresi punggungan (regresi punggungan) /
Regresi Punggung ('R')
- Regresi Lasso (dari Bahasa Inggris LASSO - Penyusutan dan Penyeleksi Pilihan Mutlak Mutlak) /
Regresi Lasso ('L')
-
Metode regresi Elastis Net Regresi ('ELN')
-
Metode Least Angle Regression (LARS) ('LARS')
- Regresi ridge Bayesian / Regresi ridge
Bayesian ('BR')
Algoritma Nonlinier:
-
metode k-tetangga terdekat regressor ('KNR')
-
Decision Tree Regressor ('DTR')
-
Mesin Vektor Dukungan Linier (regresi) /
Mesin Vektor Dukungan Linier - Regresi / ('LSVR')
- Metode
Vektor Pendukung (Regresi) /
Regresi Vektor Dukungan Epsilon ('SVR')
Algoritma Ensemble:
- AdaBoost (regresi) /
AdaBoost Regressor ('ABR') (AdaBoost = Adaptive Boosting)
- Bagging (regresi) /
Bagging Regressor ('BR') (Bagging = Bootstrap aggregating)
-
Regulator Pohon Ekstra ('ETR')
-
Peningkatan Gradien (regresi) /
Regulator Peningkatan Gradien ('GBR')
-
Klasifikasi Hutan Acak (regresi) /
Klasifikasi Hutan Acak ('RFR')
Dengan demikian, daftar 'model' berisi model-model berikut:
models = [] models.append(('LR', LinearRegression())) models.append(('R', Ridge())) models.append(('L', Lasso())) models.append(('ELN', ElasticNet())) models.append(('LARS', Lars())) models.append(('BR', BayesianRidge(n_iter=n_iter))) models.append(('KNR', KNeighborsRegressor())) models.append(('DTR', DecisionTreeRegressor())) models.append(('LSVR', LinearSVR())) models.append(('SVR', SVR())) models.append(('ABR', AdaBoostRegressor(n_estimators=n_estimators))) models.append(('BR', BaggingRegressor(n_estimators=n_estimators))) models.append(('ETR', ExtraTreesRegressor(n_estimators=n_estimators))) models.append(('GBR', GradientBoostingRegressor(n_estimators=n_estimators))) models.append(('RFR', RandomForestRegressor(n_estimators=n_estimators)))
Seperti halnya klasifikasi, mengevaluasi efektivitas setiap algoritma dilakukan dengan menggunakan cross-validation. Pesan yang ditampilkan berisi informasi berikut: nama model dalam bentuk singkatan, skor rata-rata 10-kali lipat validasi silang pada data pelatihan (metrik 'r2'), standar deviasi dan koefisien determinasi r2 pada data uji ditampilkan dalam tanda kurung.
Setelah menjalankan kode, kami mendapatkan hasil berikut:
LR: train = 0.746 (0.068) / test = 0.579 R: train = 0.744 (0.067) / test = 0.570 L: train = 0.689 (0.070) / test = 0.641 ELN: train = 0.677 (0.074) / test = 0.662 LARS: train = 0.744 (0.069) / test = 0.579 BR: train = 0.739 (0.069) / test = 0.571 KNR: train = 0.434 (0.288) / test = 0.538 DTR: train = 0.671 (0.145) / test = 0.637 LSVR: train = 0.550 (0.144) / test = 0.459 SVR: train = -0.012 (0.048) / test = -0.003 ABR: train = 0.810 (0.078) / test = 0.763 BR: train = 0.854 (0.064) / test = 0.805 ETR: train = 0.889 (0.047) / test = 0.836 GBR: train = 0.878 (0.042) / test = 0.863 RFR: train = 0.852 (0.068) / test = 0.819
Bagan rentang:
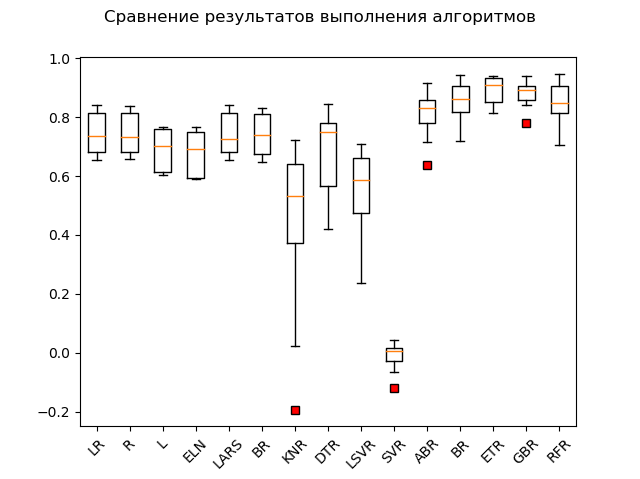
Para pemimpin yang jelas adalah metode ensemble 'GBR' (gradien 'meningkatkan'), 'ETR' (pohon ekstra), 'RFR' (hutan acak) dan 'BR' ('mengantongi'):
GBR: train = 0.878 (0.042) / test = 0.863 ETR: train = 0.889 (0.047) / test = 0.836 RFR: train = 0.852 (0.068) / test = 0.819 BR: train = 0.854 (0.064) / test = 0.805 ABR: train = 0.810 (0.078) / test = 0.763 ELN: train = 0.677 (0.074) / test = 0.662 L: train = 0.689 (0.070) / test = 0.641 DTR: train = 0.671 (0.145) / test = 0.637 LR: train = 0.746 (0.068) / test = 0.579 LARS: train = 0.744 (0.069) / test = 0.579 BR: train = 0.739 (0.069) / test = 0.571 R: train = 0.744 (0.067) / test = 0.570 KNR: train = 0.434 (0.288) / test = 0.538 LSVR: train = 0.550 (0.144) / test = 0.459 SVR: train = -0.012 (0.048) / test = -0.003
Satu jenis "adabust", "loshara", tertinggal.
Mungkin ketiga pemimpin itu menyisir standardisasi dan normalisasi. Mari kita cari tahu dengan mengeksekusi sisa kode.
Hasilnya adalah sebagai berikut:
SS_LR: train = 0.746 (0.068) / test = 0.579 SS_R: train = 0.746 (0.068) / test = 0.578 SS_L: train = 0.678 (0.054) / test = 0.510 SS_ELN: train = 0.665 (0.060) / test = 0.513 SS_LARS: train = 0.744 (0.069) / test = 0.579 SS_BR: train = 0.746 (0.066) / test = 0.576 SS_KNR: train = 0.763 (0.098) / test = 0.739 SS_DTR: train = 0.610 (0.242) / test = 0.629 SS_LSVR: train = 0.727 (0.091) / test = 0.482 SS_SVR: train = 0.653 (0.126) / test = 0.610 SS_ABR: train = 0.811 (0.076) / test = 0.819 SS_BR: train = 0.853 (0.074) / test = 0.813 SS_ETR: train = 0.887 (0.048) / test = 0.846 SS_GBR: train = 0.878 (0.038) / test = 0.860 SS_RFR: train = 0.851 (0.071) / test = 0.818 N_LR: train = 0.751 (0.099) / test = 0.576 N_R: train = 0.287 (0.126) / test = 0.271 N_L: train = -0.030 (0.032) / test = -0.000 N_ELN: train = -0.007 (0.030) / test = 0.023 N_LARS: train = 0.751 (0.099) / test = 0.576 N_BR: train = 0.744 (0.100) / test = 0.589 N_KNR: train = 0.485 (0.192) / test = 0.504 N_DTR: train = 0.729 (0.080) / test = 0.765 N_LSVR: train = 0.182 (0.108) / test = 0.136 N_SVR: train = 0.086 (0.076) / test = 0.084 N_ABR: train = 0.795 (0.053) / test = 0.752 N_BR: train = 0.854 (0.054) / test = 0.827 N_ETR: train = 0.877 (0.048) / test = 0.850 N_GBR: train = 0.852 (0.063) / test = 0.872 N_RFR: train = 0.852 (0.051) / test = 0.801
Seperti yang Anda lihat, metode ensemble masih di depan semua orang.'Top 5' berisi hasil berikut: N_GBR: train = 0.852 (0.063) / test = 0.872 GBR: train = 0.878 (0.042) / test = 0.863 SS_GBR: train = 0.878 (0.038) / test = 0.860 N_ETR: train = 0.877 (0.048) / test = 0.850 SS_ETR: train = 0.887 (0.048) / test = 0.846
:
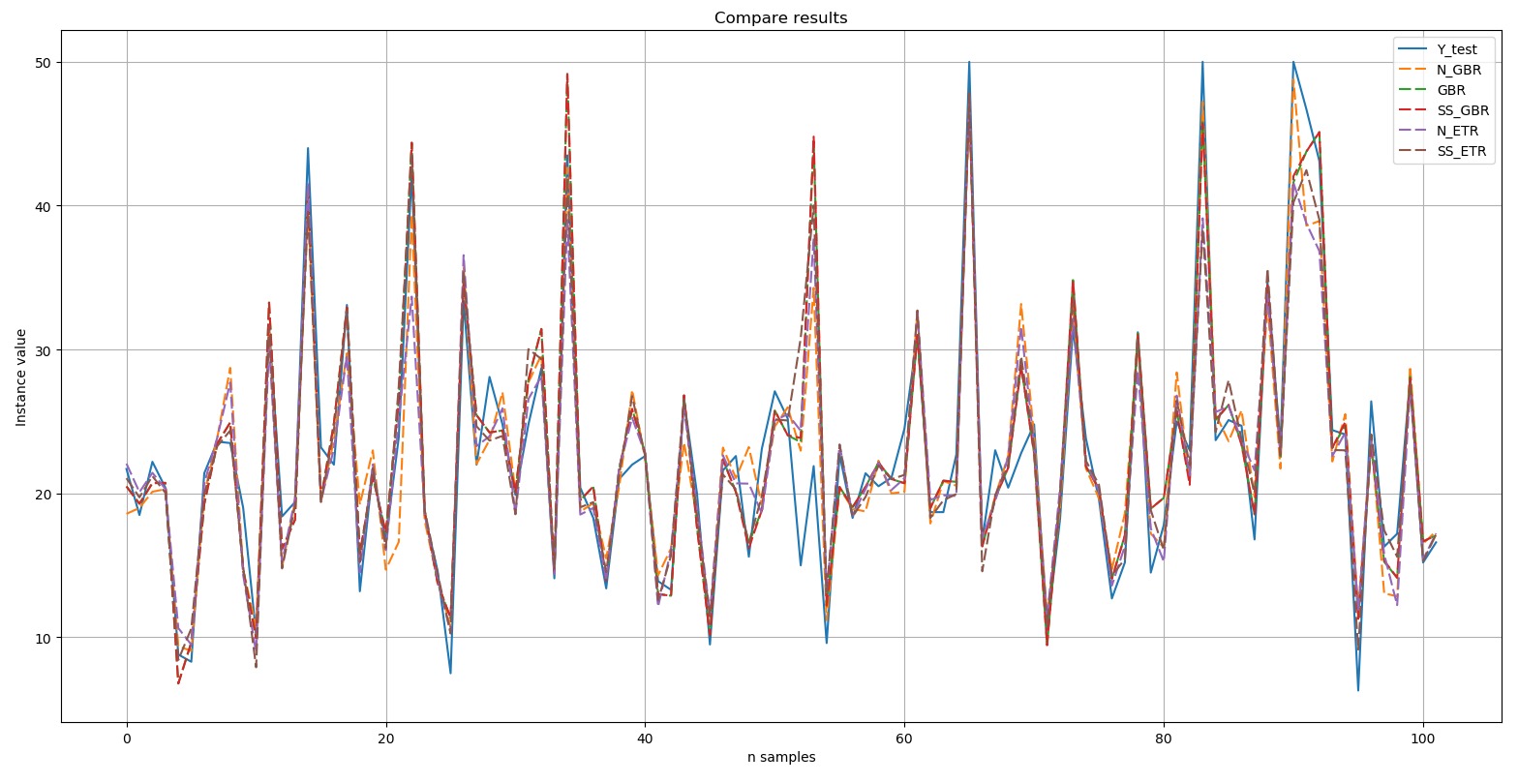 Y-test
Y-test – . , , (dashed). , , .
, Top 5:
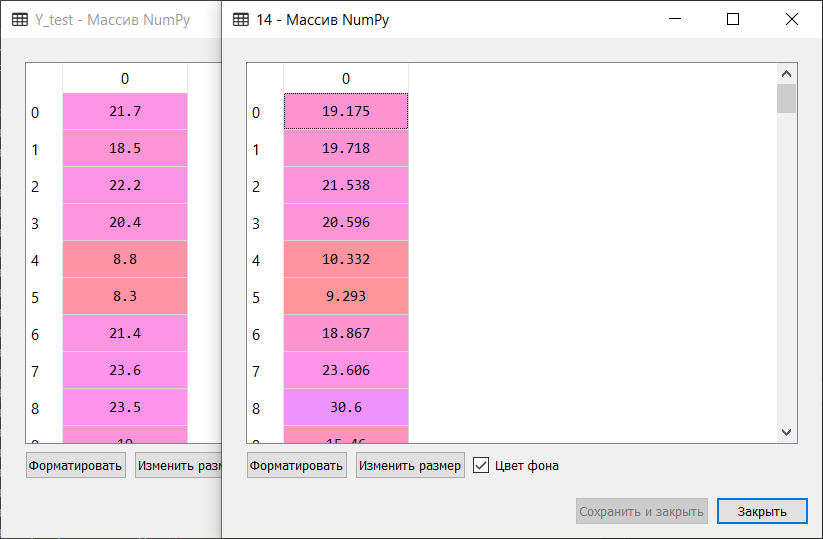
, - 'boston house-price' «» ('GBR') - ('ETR'). .
Kata penutup
- (). , 'digits', 10 , 'boston house-price', «» «» .
, , GitHub. :
.
— -. , : . :)
. , , , . , «- », , , , ( ):), ; , ; , «». :)
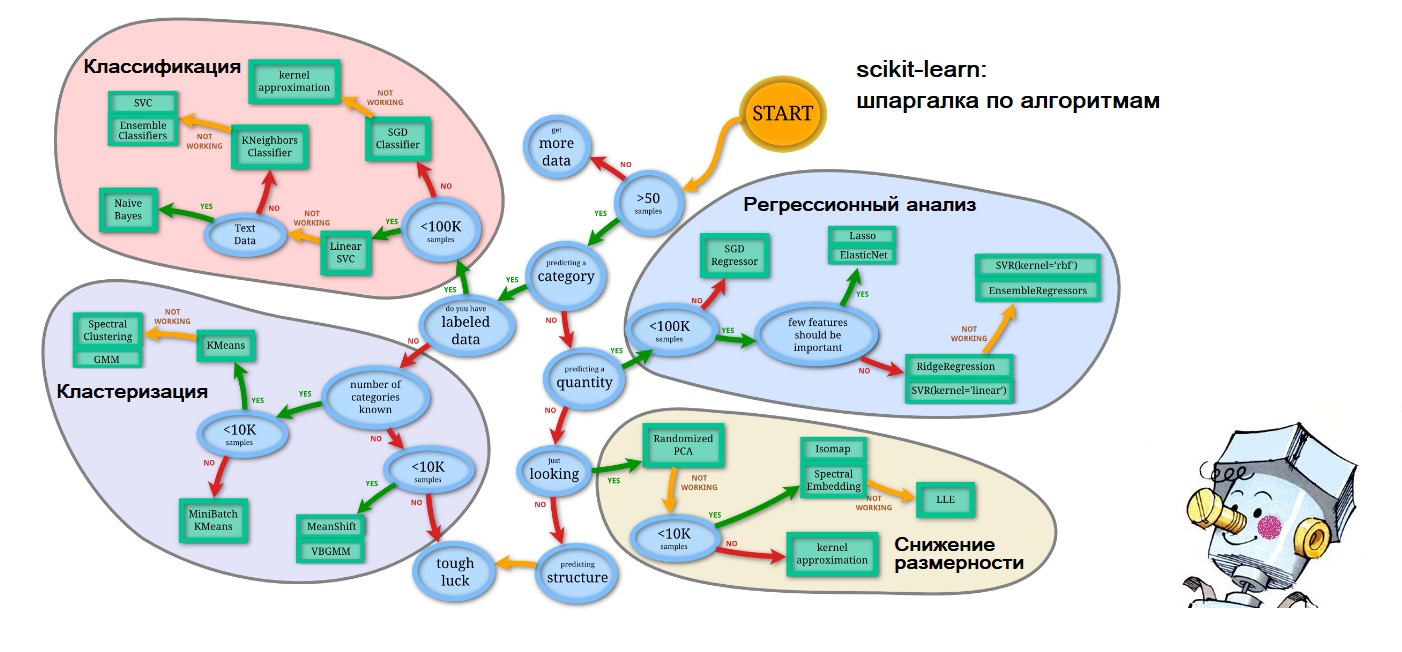
PS , , - : scikit-learn.org (
'Choosing the right estimator' ):
. – .