Hari ini kami ingin berbicara tentang konsep Insight-Driven dan bagaimana menerapkannya menggunakan DataOps dan ModelOps. Pendekatan Insight-Driven adalah topik komprehensif yang kami bicarakan secara terperinci di perpustakaan kami yang baru-baru ini berisi materi yang berguna tentang manajemen data (tautannya akan di bawah). Dalam habratopica hari ini, kita akan berkonsentrasi pada tahapan kunci dari siklus hidup model pembelajaran mesin, seperti Ini adalah salah satu topik utama dalam konsep tersebut.

Apa inti dari pendekatan Insight-Driven
Banyak ahli telah berbicara tentang pentingnya
Data-Driven untuk waktu yang lama, yang tentu saja benar secara umum, karena pendekatan ini melibatkan pengambilan keputusan manajemen yang lebih efisien dengan menganalisis data, dan bukan hanya intuisi dan pengalaman kepemimpinan pribadi. Analis Forrester
mencatat bahwa perusahaan yang mengandalkan analisis data dalam aktivitasnya tumbuh rata-rata 30% lebih cepat daripada pesaing.
Tetapi kita semua memahami bahwa perusahaan bergerak maju bukan dari ketersediaan data seperti itu, tetapi dari kemampuan untuk bekerja dengan mereka - yaitu, untuk menemukan wawasan yang dapat dimonetisasi, dan untuk itu layak mengumpulkan, memproses, dan menganalisis data. Oleh karena itu, kita berbicara secara khusus tentang pendekatan Insight-Driven, sebagai versi yang lebih canggih dari Data-Driven.
Paling sering, ketika datang untuk bekerja dengan data, kebanyakan spesialis terutama berarti informasi terstruktur dalam perusahaan, namun, belum lama ini kita berbicara tentang mengapa sebagian besar bisnis tidak menggunakan sekitar 80% dari data yang berpotensi tersedia. Insight-Driven hanya menciptakan dasar untuk melengkapi gambar dengan informasi eksternal yang tidak terstruktur, serta hasil interpretasi data untuk mencari dependensi tersirat di antara mereka.
Tautan yang dijanjikan ke pustaka materi yang lengkap tentang manajemen data , di mana ada video yang disebutkan tentang data yang tidak digunakan.
DevOps + DataOps + ModelOps
Praktek Insight-Driven didasarkan pada DevOps, DataOps, dan ModelOps. Mari kita bicara tentang mengapa kombinasi dari praktik-praktik khusus ini dapat memastikan implementasi penuh dari pendekatan ini.
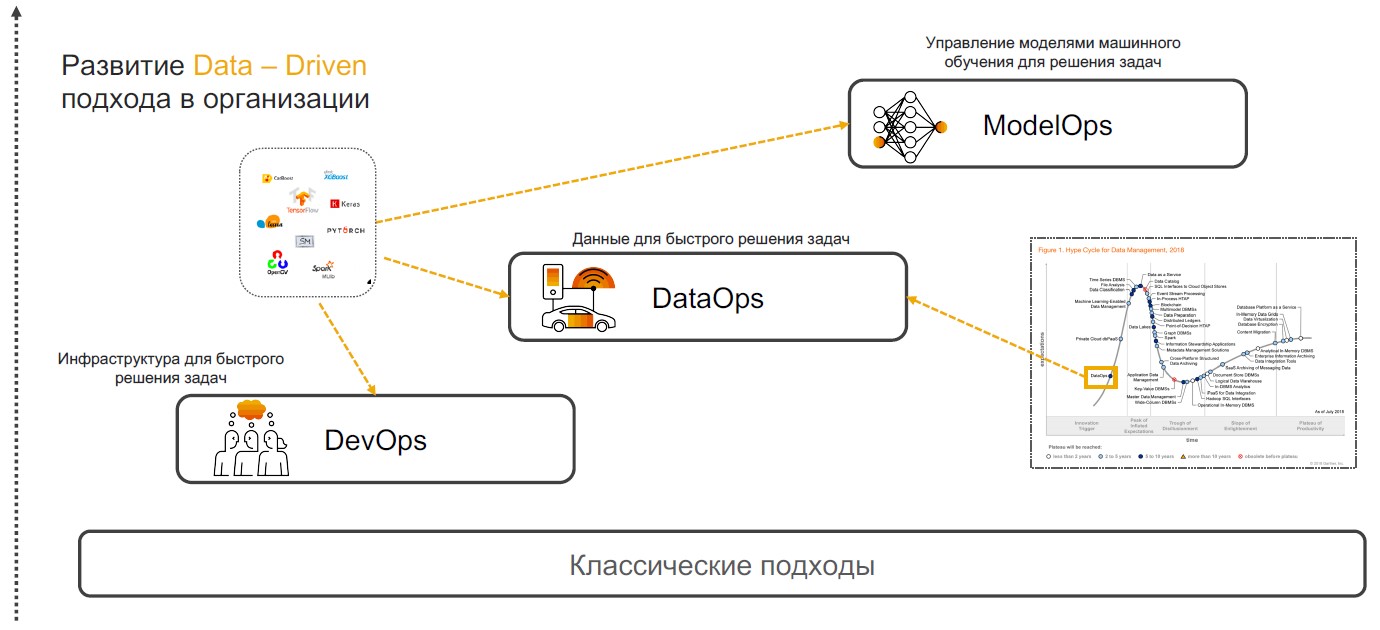 DevOps + DataOps
DevOps + DataOps . DevOps melibatkan pengurangan waktu rilis produk, pembaruannya, dan meminimalkan biaya dukungan lebih lanjut melalui penggunaan alat untuk kontrol versi, integrasi berkelanjutan, pengujian dan pemantauan, manajemen rilis. Jika kami menambahkan pemahaman praktik tentang data apa yang ada di dalam perusahaan, bagaimana mengelola format dan strukturnya, tag, kualitas trek, transformasi, agregasi dan memiliki kemampuan untuk menganalisis dan memvisualisasikan dengan cepat, maka kami mendapatkan
DataOps . Fokus dari pendekatan ini adalah implementasi skenario menggunakan model pembelajaran mesin yang memberikan dukungan keputusan, pencarian wawasan dan peramalan.
ModelOps . Segera setelah perusahaan mulai secara aktif menggunakan model pembelajaran mesin, menjadi perlu untuk mengelolanya, memantau metrik kualitas, melatih ulang, membandingkan, memperbarui dan versi. ModOps adalah seperangkat praktik dan pendekatan yang menyederhanakan manajemen siklus hidup model tersebut. Ini digunakan oleh perusahaan yang menangani sejumlah besar model di berbagai bidang bisnis, misalnya, layanan streaming.
Menerapkan pendekatan Insight-Driven di sebuah perusahaan bukanlah tugas sepele. Tetapi bagi mereka yang masih ingin mulai bekerja dengannya, kami akan memberi tahu Anda cara melakukan ini.
Pencarian dan persiapan data
Implementasi praktik Insight-Driven dimulai dengan pencarian dan persiapan data. Kemudian mereka dianalisis dan digunakan untuk membangun model MOs, tetapi kasus-kasus sebelumnya ditentukan di mana algoritma cerdas dapat berguna.
Definisi tugas . Pada tahap ini, perusahaan menetapkan tujuan bisnis, misalnya, meningkatkan laba di pasar. Selanjutnya, metrik bisnis ditentukan untuk mencapainya, seperti peningkatan jumlah pelanggan baru, ukuran cek rata-rata dan persentase konversi. Jadi ada skenario di mana sudah dimungkinkan untuk mencari data yang relevan.
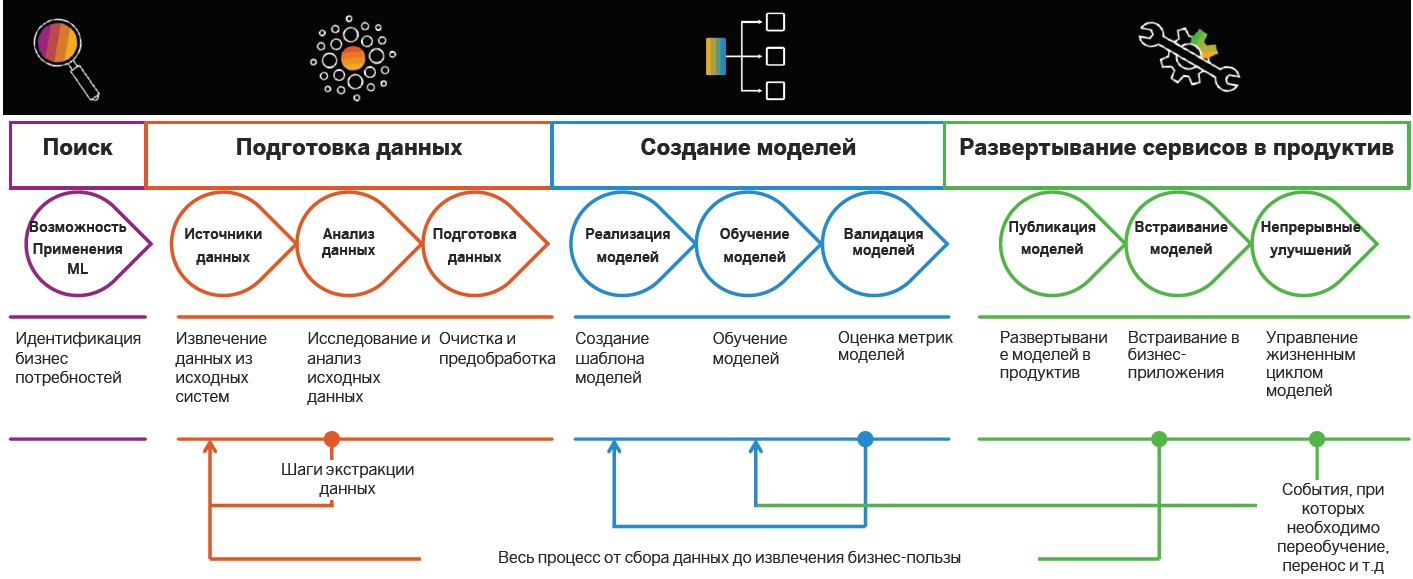 Sumber dan analisis data
Sumber dan analisis data . Ketika tujuan dan arahan untuk pengambilan data ditentukan, sekarang saatnya untuk menganalisis sumber. Ini dan tahap selanjutnya dari pengembangan skenario cerdas yang berhubungan dengan persiapan
mengambil 70-80% dari anggaran perusahaan dalam implementasi. Faktanya adalah bahwa kualitas set data mempengaruhi keakuratan model pembelajaran mesin yang dirancang. Tetapi informasi yang diperlukan sering "tersebar" di berbagai sistem - dapat terletak pada basis data relasional, seperti MS SQL, Oracle, PostgreSQL, pada platform Hadoop dan banyak sumber lainnya. Dan pada tahap ini, Anda perlu memahami di mana data yang relevan dan bagaimana cara mengumpulkannya.
Seringkali, analis membongkar dan memproses semuanya secara manual, yang sangat memperlambat proses dan meningkatkan risiko kesalahan. Kami di SAP menawarkan pelanggan kami untuk menerapkan sistem-meta yang terhubung ke sumber yang tepat dan mengumpulkan data berdasarkan permintaan.
Jadi, Anda dapat membuat katalog semua tabel, kumpulan eksternal dengan data tidak terstruktur, dan sumber lainnya - tetapkan tag (termasuk yang hierarkis) dan kumpulkan informasi yang relevan dengan cepat. Secara kondisional, jika informasi tentang klien terletak di database yang berbeda, maka cukup untuk menunjukkan entitas ini. Lain kali Anda membutuhkan "set data klien", Anda akan memilih showcase yang sudah jadi.
Setelah sumber data diidentifikasi, Anda dapat beralih
ke pelacakan dan profil kualitas data . Operasi ini diperlukan untuk memahami jumlah kesenjangan, nilai unik, dan memverifikasi kualitas data secara keseluruhan. Untuk semua ini, Anda dapat membuat dasbor dengan aturan dan melacak perubahan apa pun.
Transformasi data . Langkah selanjutnya adalah pekerjaan langsung dengan data yang harus menyelesaikan tugas. Untuk melakukan ini, data dihapus: diperiksa, dideduplikasi, diisi kesenjangan. Proses ini dapat disederhanakan dengan pemrograman berbasis aliran. Dalam hal ini, kami berhadapan dengan urutan operasi - saluran pipa. Keluarannya dapat dikirim ke antarmuka grafis atau sistem lain untuk pekerjaan selanjutnya. Di sini, penangan data dirakit sebagai konstruktor (dan tergantung pada skenario). Ini bisa berupa pemrosesan berkala atau streaming, atau layanan REST.

Konsep pemrograman berbasis aliran cocok untuk menyelesaikan berbagai tugas: mulai dari memperkirakan penjualan dan mengevaluasi kualitas layanan hingga menemukan alasan churn pelanggan. Ada dua alat untuk mencari dan menyiapkan data dalam SAP. Yang pertama adalah
SAP Data Intelligence untuk analis data. Tidak seperti platform serupa, solusi ini bekerja dengan data terdistribusi dan tidak memerlukan sentralisasi - solusi ini menyediakan lingkungan terpadu untuk implementasi, publikasi, integrasi, penskalaan, dan dukungan model. Alat kedua adalah
SAP Agile Data Preparation , layanan persiapan data kecil yang ditargetkan untuk analis dan pengguna bisnis. Ini memiliki antarmuka sederhana yang membantu mengumpulkan kumpulan data, memfilter, memproses, dan memetakan informasi. Ini dapat dipublikasikan dalam showcase untuk mentransfer BI Swalayan - sistem swalayan untuk membuat skenario analitik (mereka tidak memerlukan pengetahuan mendalam di bidang ilmu data).
Pembuatan model
Setelah persiapan, giliran untuk membuat model pembelajaran mesin. Berikut ini dibedakan: penelitian, prototipe dan produktivitas. Tahap terakhir mencakup implementasi jaringan pipa untuk pelatihan dan penerapan model.
Penelitian dan pembuatan prototipe . Saat ini, ada banyak kerangka kerja tematik dan perpustakaan yang tersedia. Para pemimpin dalam frekuensi penggunaan adalah TensorFlow dan PyTorch, yang popularitasnya selama setahun terakhir telah
tumbuh sebesar 243%. Platform SAP memungkinkan Anda untuk menggunakan kerangka kerja ini dan dapat secara fleksibel dilengkapi oleh perpustakaan seperti CatBoost dari Yandex, LightGBM dari Microsoft, scikit-learn dan panda. Anda masih dapat menggunakan
HANA DataFrame di pustaka hanaml. API ini meniru panda, dan HANA memungkinkan Anda untuk memproses sejumlah besar data menggunakan "komputasi malas."
Untuk model prototyping, kami menawarkan Jupyter Lab. Ini adalah alat open source untuk para profesional data-sains. Kami membangunnya ke dalam ekosistem SAP, sambil memperluas fungsionalitas. Jupyter Lab bekerja di platform Data Intelligence dan karena perpustakaan sapdi bawaan, ia dapat terhubung ke sumber data apa pun yang terhubung pada langkah sebelumnya, memantau eksperimen, dan metrik kualitas untuk analisis lebih lanjut.
Secara terpisah, harus dicatat bahwa notebook, dataset, pelatihan dan
pipa inferensi , serta layanan untuk menyebarkan model harus konsisten. Untuk menggabungkan semua objek ini, gunakan skrip ML (objek berversi).
Pelatihan model . Ada dua opsi untuk bekerja dengan skrip ML. Ada model yang tidak perlu dilatih sama sekali. Misalnya, dalam SAP Data Intelligence kami menawarkan sistem pengenalan wajah, terjemahan otomatis, OCR (pengenalan karakter optik) dan lainnya. Mereka semua bekerja di luar kotak. Di sisi lain, ada model-model yang perlu dilatih dan produktif. Pelatihan ini dapat terjadi baik di kluster Kecerdasan Data itu sendiri maupun pada sumber daya komputasi eksternal yang terhubung hanya selama durasi perhitungan.
"Di bawah tenda" di SAP Data Intelligence adalah platform Kubernetes, sehingga semua operator terikat pada wadah buruh pelabuhan. Untuk bekerja dengan model, cukup untuk menggambarkan file buruh pelabuhan dan melampirkan tag untuk itu untuk perpustakaan dan versi yang digunakan.
Cara lain untuk membuat model adalah dengan AutoML. Ini adalah sistem MO otomatis. Alat semacam itu dikembangkan oleh
H2O ,
Microsoft ,
Google, dll. Mereka bekerja
ke arah ini
di MIT . Tetapi insinyur universitas tidak fokus pada penanaman dan produktivitas. SAP juga memiliki sistem AutoML yang berfokus pada hasil yang cepat. Dia bekerja di HANA dan memiliki akses langsung ke data - mereka tidak perlu dipindahkan atau dimodifikasi di mana pun. Sekarang kami sedang mengembangkan solusi yang berfokus pada kualitas model - kami akan mengumumkan rilis nanti.
Manajemen siklus hidup . Kondisi berubah, informasi menjadi usang, sehingga keakuratan model MO menurun dari waktu ke waktu. Dengan demikian, setelah mengumpulkan data baru, kami dapat melatih ulang model dan memperbaiki hasilnya. Misalnya, satu produsen minuman besar
menggunakan informasi preferensi konsumen di 200 negara yang berbeda untuk melatih kembali sistem pintar. Perusahaan memperhitungkan selera orang, jumlah gula, kandungan kalori minuman, dan bahkan produk yang ditawarkan merek pesaing di pasar sasaran. Model MO secara otomatis menentukan mana dari ratusan produk yang akan diterima perusahaan terbaik di wilayah tertentu.
 Menggunakan Kembali Komponen Berbasis Agen di SAP Data Hub
Menggunakan Kembali Komponen Berbasis Agen di SAP Data HubTetapi versi dan memperbarui model juga perlu dilakukan ketika algoritma baru dan pembaruan komponen perangkat keras dirilis. Implementasinya dapat meningkatkan akurasi dan kualitas model yang digunakan dalam pekerjaan.
Insight-Didorong untuk Pertumbuhan Bisnis
Pendekatan untuk mengelola tahap siklus hidup model pembelajaran mesin yang dijelaskan di atas, pada kenyataannya, merupakan kerangka kerja universal yang memungkinkan perusahaan untuk menjadi Insight-Driven dan menggunakan pekerjaan dengan data sebagai pendorong utama untuk pertumbuhan bisnis. Organisasi yang mewujudkan konsep ini lebih tahu, tumbuh lebih cepat, dan, menurut kami, bekerja jauh lebih menarik dalam teknologi canggih ini!
Pelajari lebih lanjut tentang membangun konsep Insight-Driven di
perpustakaan kami
tentang materi manajemen data yang bermanfaat , tempat kami mengumpulkan video, brosur bermanfaat, dan akses uji coba ke sistem SAP.