Hai, nama saya Eugene. Saya bekerja di infrastruktur pencarian Yandex.Market. Saya ingin memberi tahu komunitas Habr tentang dapur internal Pasar - tetapi ada sesuatu untuk diceritakan. Pertama-tama, bagaimana Pencarian Pasar, proses dan arsitektur bekerja. Bagaimana kita menghadapi situasi darurat: apa yang terjadi jika satu server lumpuh? Dan jika ada 100 server seperti itu?
Anda juga akan belajar bagaimana kami menerapkan fungsionalitas baru pada sekelompok server segera. Dan bagaimana menguji layanan kompleks langsung dalam produksi, tanpa memberi pengguna ketidaknyamanan. Secara umum, cara pencarian Pasar bekerja, sehingga semua orang baik-baik saja.
Sedikit tentang kita: masalah apa yang kita pecahkan
Saat Anda memasukkan teks, mencari produk dengan parameter atau membandingkan harga di toko yang berbeda, semua permintaan tiba di layanan pencarian. Pencarian adalah layanan terbesar di Pasar.
Kami memproses semua permintaan pencarian: dari market.yandex.ru, beru.ru, layanan Supercheck, Yandex.Advisor, dan aplikasi seluler. Kami juga menyertakan penawaran barang dalam hasil pencarian di yandex.ru.
Dengan layanan pencarian, maksud saya tidak hanya mencari secara langsung, tetapi juga database dengan semua penawaran di Pasar. Skalanya adalah ini: lebih dari satu miliar permintaan pencarian diproses per hari. Dan semuanya harus bekerja dengan cepat, tanpa gangguan dan selalu menghasilkan hasil yang diinginkan.
Apa itu: Arsitektur pasar
Jelaskan secara singkat arsitektur Pasar saat ini. Secara konvensional, dapat dijelaskan oleh skema di bawah ini:
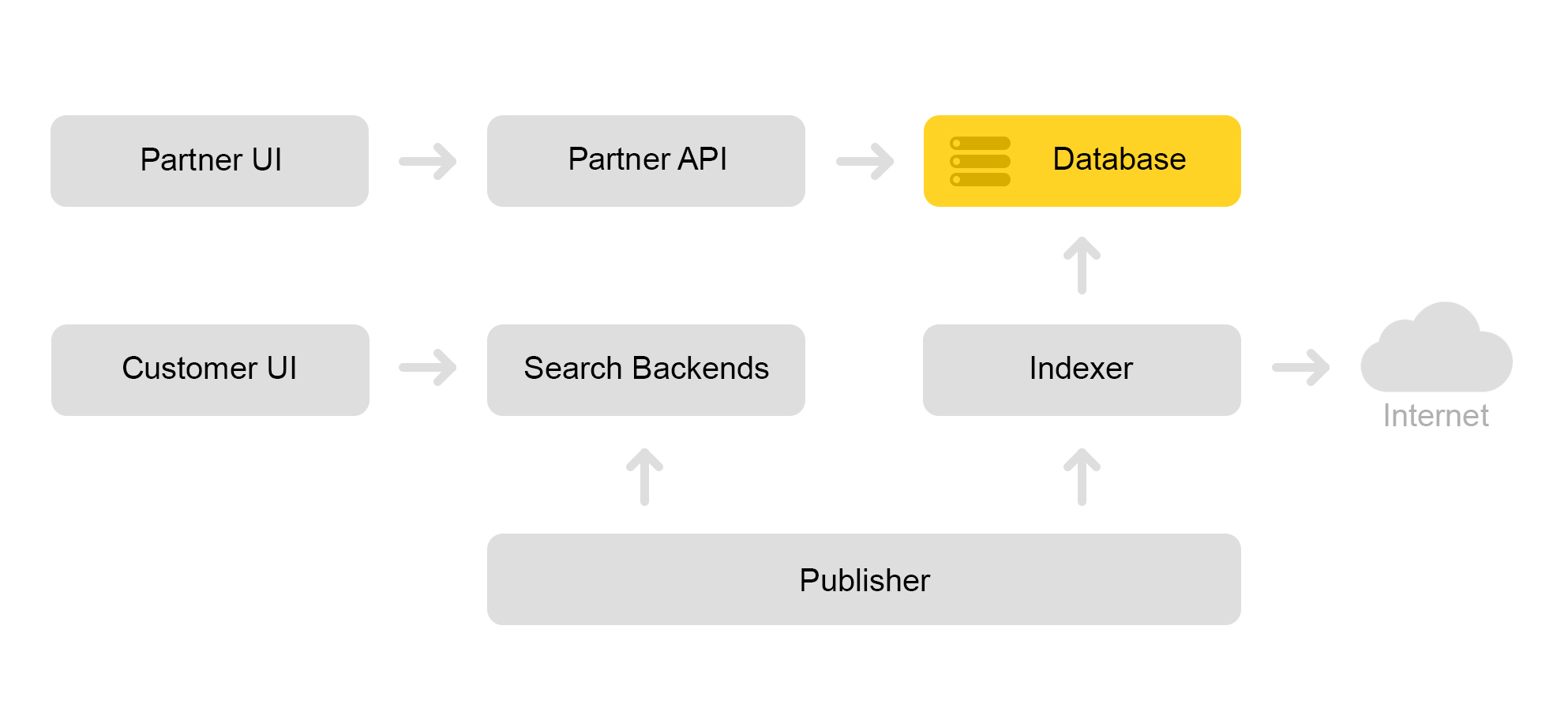
Katakanlah toko mitra datang kepada kita. Dia bilang aku ingin menjual mainan: kucing jahat ini dengan alat penyapu. Dan kucing jahat tanpa tweeter. Dan hanya seekor kucing. Maka toko perlu menyiapkan penawaran yang dicari Pasar. Toko membentuk xml khusus dengan penawaran dan mengkomunikasikan jalur ke xml ini melalui antarmuka mitra. Kemudian pengindeks secara berkala mengunduh xml ini, memeriksa kesalahan dan menyimpan semua informasi dalam database besar.
Ada banyak xml yang disimpan. Indeks pencarian dibuat dari database ini. Indeks disimpan dalam format internal. Setelah membuat indeks, layanan Tata Letak mengunggahnya ke mesin pencari.
Akibatnya, kucing jahat dengan pencabik muncul di database, dan indeks kucing muncul di server.
Saya akan berbicara tentang bagaimana kita mencari kucing di bagian tentang arsitektur pencarian.
Arsitektur Pencarian Pasar
Kita hidup di dunia layanan-mikro: setiap permintaan masuk ke
market.yandex.ru menyebabkan banyak
subkueri , dan lusinan layanan berpartisipasi dalam pemrosesan mereka. Diagram hanya menunjukkan beberapa:
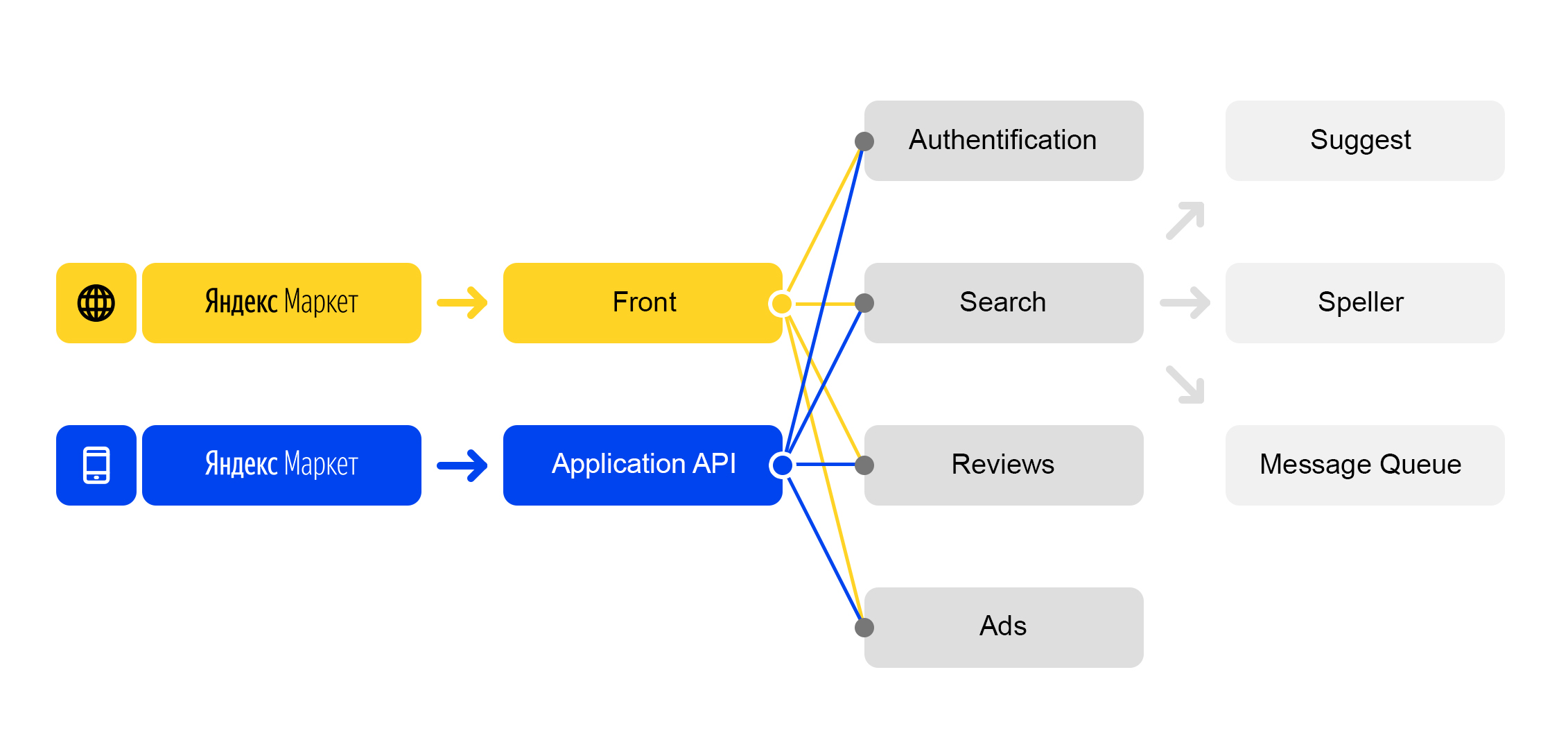 Skema pemrosesan permintaan yang disederhanakan
Skema pemrosesan permintaan yang disederhanakanSetiap layanan memiliki hal yang luar biasa - penyeimbangnya sendiri dengan nama yang unik:
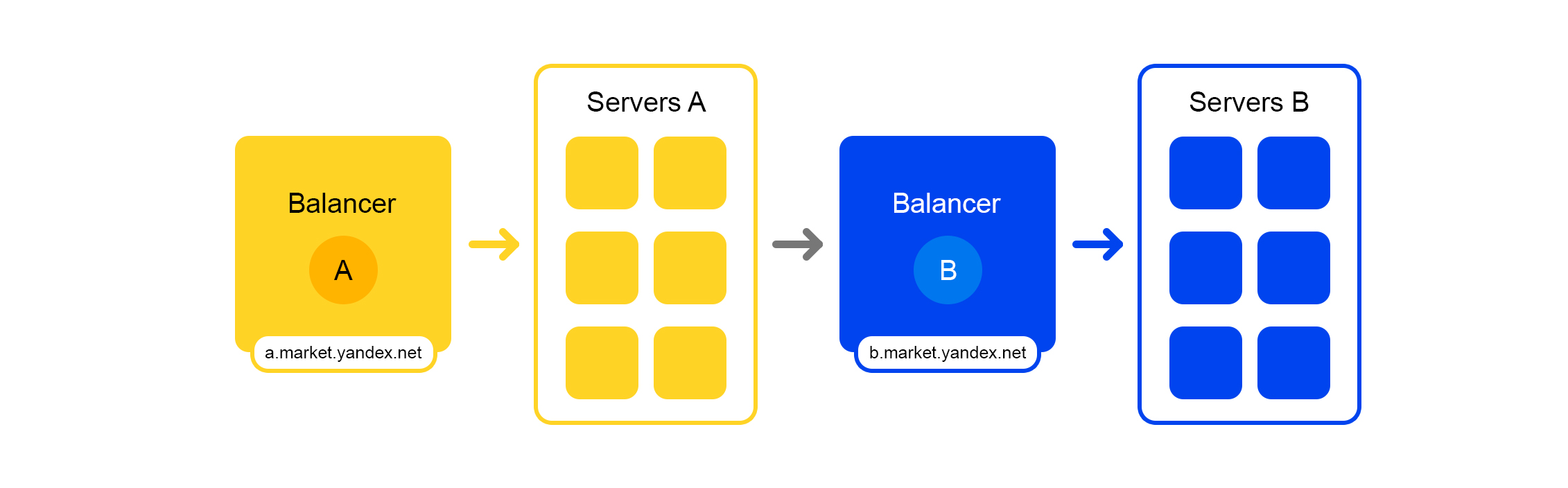
Penyeimbang memberi kami fleksibilitas besar dalam mengelola layanan: misalnya, Anda dapat mematikan server, yang sering diperlukan untuk pembaruan. Penyeimbang melihat bahwa server tidak tersedia dan secara otomatis mengalihkan permintaan ke server lain atau pusat data. Ketika Anda menambah atau menghapus server, beban secara otomatis didistribusikan kembali antara server.
Nama unik penyeimbang tidak bergantung pada pusat data. Ketika layanan A membuat permintaan ke B, maka secara default, penyeimbang B mengalihkan permintaan ke pusat data saat ini. Jika layanan tidak tersedia atau tidak ada di pusat data saat ini, permintaan dialihkan ke pusat data lainnya.
FQDN tunggal untuk semua pusat data memungkinkan layanan A untuk secara umum melepaskan diri dari lokasi. Permintaannya untuk layanan B akan selalu diproses. Pengecualian adalah kasus ketika layanan di semua pusat data.
Tapi tidak semuanya begitu cerah dengan penyeimbang ini: kami memiliki komponen perantara tambahan. Penyeimbang mungkin tidak stabil, dan masalah ini diselesaikan oleh server yang berlebihan. Ada juga penundaan tambahan antara layanan A dan B. Namun dalam praktiknya, itu kurang dari 1 ms dan untuk sebagian besar layanan ini tidak kritis.
Memerangi yang tak terduga: menyeimbangkan dan layanan pencarian tangguh
Bayangkan bahwa keruntuhan terjadi: Anda perlu menemukan kucing dengan alat penyapu, tetapi server macet. Atau 100 server. Bagaimana cara keluar? Akankah kami benar-benar meninggalkan pengguna tanpa kucing?
Situasinya mengerikan, tetapi kami siap untuk itu. Aku akan memberitahumu dalam rangka.
Infrastruktur pencarian terletak di beberapa pusat data:
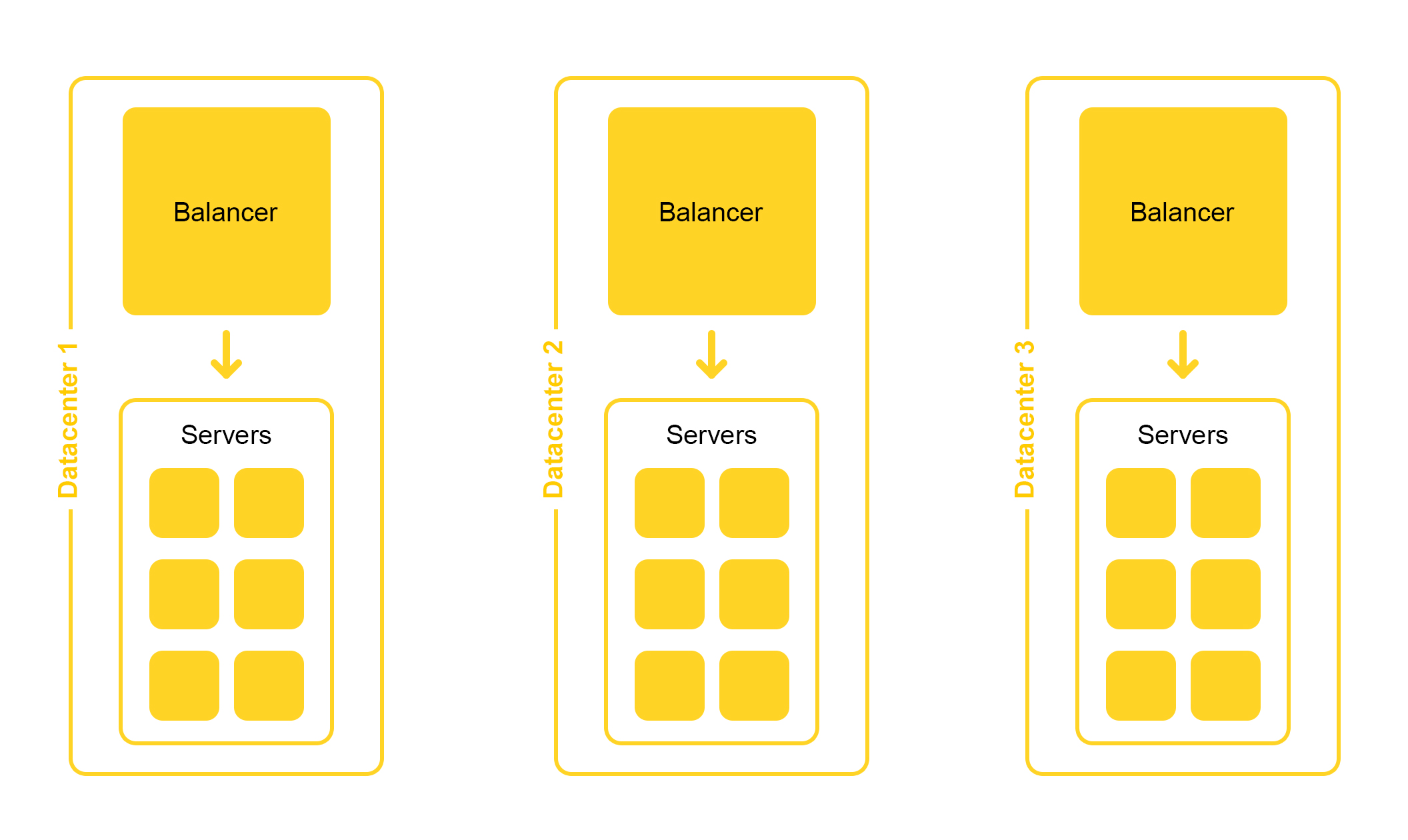
Saat mendesain, kami meletakkan kemungkinan menonaktifkan satu pusat data. Hidup ini penuh kejutan - misalnya, sebuah ekskavator dapat memotong kabel bawah tanah (ya, memang seperti itu). Kapasitas di pusat data yang tersisa harus cukup untuk menahan beban puncak.
Pertimbangkan pusat data tunggal. Di setiap pusat data, skema penyeimbang yang sama:
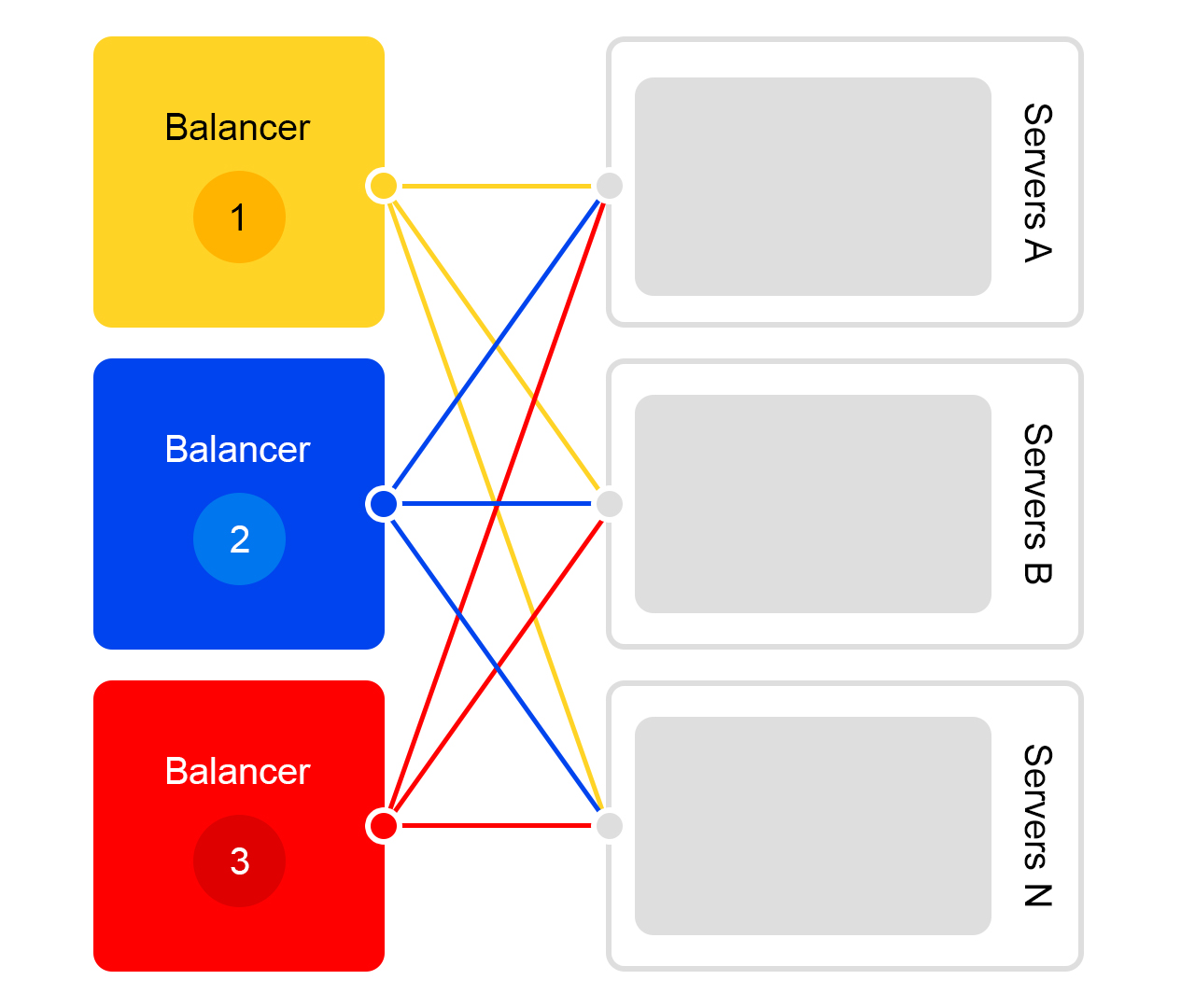
Satu penyeimbang setidaknya tiga server fisik. Redundansi tersebut dibuat untuk keandalan. Balancers bekerja pada HAProx.
Kami memilih HAProx karena kinerjanya yang tinggi, persyaratan sumber daya yang kecil, dan fungsionalitas yang luas. Di dalam setiap server, perangkat lunak pencarian kami berfungsi.
Probabilitas kegagalan satu server kecil. Tetapi jika Anda memiliki banyak server, kemungkinan setidaknya satu jatuh akan meningkat.
Inilah yang terjadi pada kenyataannya: server mengalami crash. Karena itu, Anda harus terus memantau status semua server. Jika server berhenti merespons, maka server terputus secara otomatis dari lalu lintas. Untuk ini, HAProxy memiliki pemeriksaan kesehatan bawaan. Ia pergi ke semua server dengan permintaan HTTP "/ ping" satu detik sekali.
Fitur lain dari HAProxy: agent-check memungkinkan Anda memuat semua server secara merata. Untuk melakukan ini, HAProxy terhubung ke semua server, dan mereka mengembalikan beratnya tergantung pada beban saat ini dari 1 hingga 100. Berat dihitung berdasarkan jumlah permintaan dalam antrian pemrosesan dan beban pada prosesor.
Sekarang tentang mencari kucing. Pertanyaan tentang formulir
/ pencarian? Teks = angry + cat tiba untuk
mencari . Agar pencarian cepat, seluruh indeks kucing harus ditempatkan dalam RAM. Bahkan membaca dari SSD tidak cukup cepat.
Sekali waktu, basis penawaran kecil, dan ada cukup RAM untuk satu server untuk itu. Ketika basis data proposal bertambah, semuanya tidak lagi sesuai dengan RAM ini, dan data dibagi menjadi dua bagian: pecahan 1 dan pecahan 2.

Tapi itu selalu terjadi: solusi apa pun, bahkan solusi yang baik, menimbulkan masalah lain.
Penyeimbang masih pergi ke server mana pun. Tetapi pada mesin di mana permintaan itu datang, hanya ada setengah indeks. Sisanya ada di server lain. Oleh karena itu, server harus pergi ke beberapa mesin tetangga. Setelah menerima data dari kedua server, hasilnya digabungkan dan direorganisasi.
Karena penyeimbang mendistribusikan permintaan secara merata, semua server terlibat dalam mengatur ulang, dan tidak hanya memberikan data.
Masalah terjadi jika server tetangga tidak tersedia. Solusinya adalah menetapkan beberapa server dengan prioritas berbeda sebagai server "tetangga". Pertama, permintaan dikirim ke server di rak saat ini. Jika tidak ada respons yang diterima, permintaan dikirim ke semua server di pusat data ini. Dan yang tak kalah pentingnya, permintaan tersebut dikirim ke pusat data lainnya.
Ketika jumlah proposal meningkat, data dibagi menjadi empat bagian. Tapi ini bukan batasnya.
Sekarang konfigurasi delapan pecahan digunakan. Selain itu, untuk lebih menghemat memori, indeks dibagi menjadi bagian pencarian (dimana pencarian berlangsung) dan bagian potongan (yang tidak terlibat dalam pencarian).
Satu server berisi informasi hanya pada satu shard. Oleh karena itu, untuk melakukan pencarian pada indeks lengkap, Anda perlu mencari di delapan server yang berisi pecahan yang berbeda.
Server dikelompokkan dalam kelompok. Setiap klaster berisi delapan mesin pencari dan satu cuplikan.
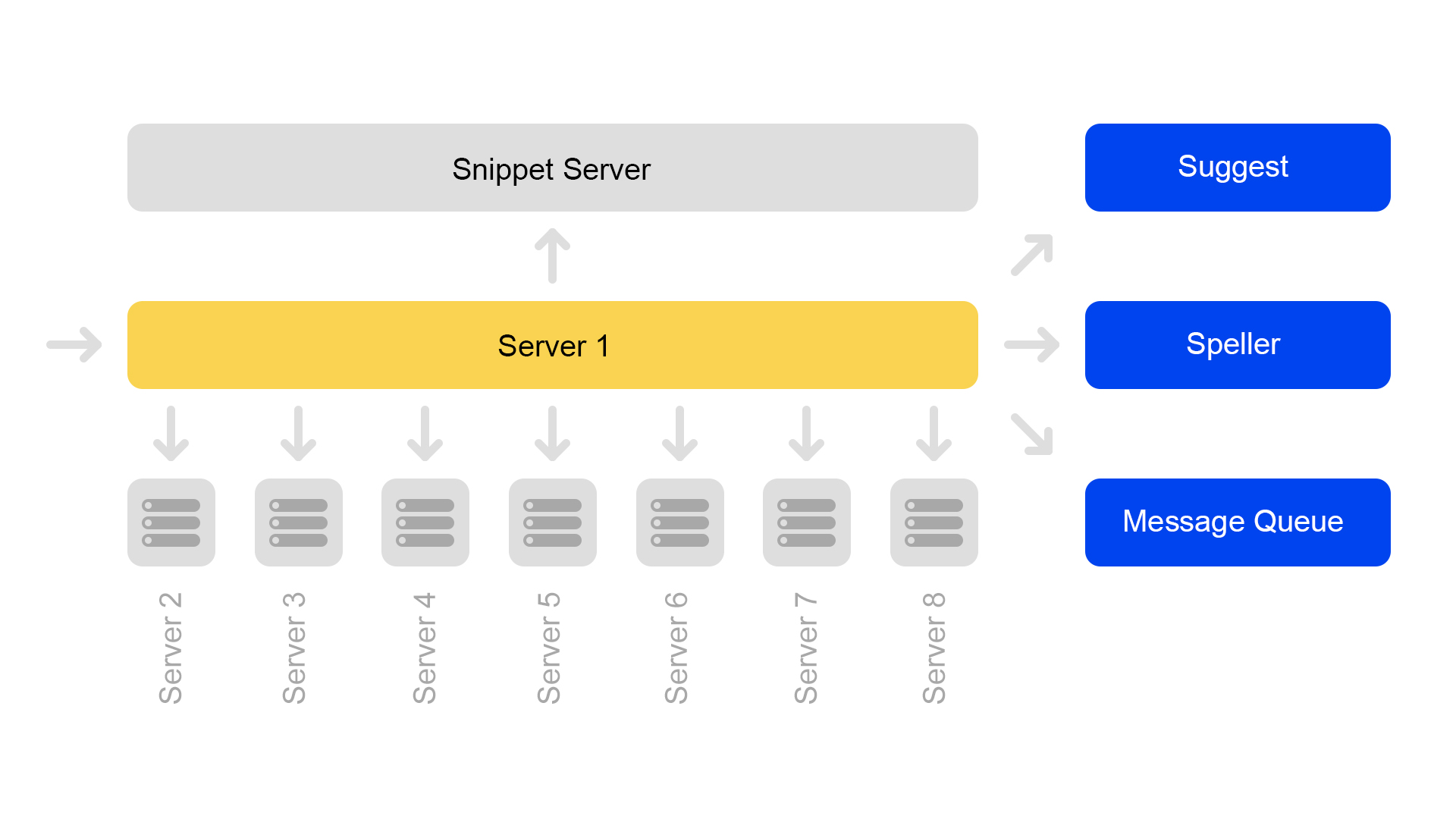
Database kunci-nilai dengan data statis sedang berjalan di server snippet. Mereka diperlukan untuk mengeluarkan dokumen, misalnya, deskripsi kucing dengan alat pencicit. Data secara khusus diambil pada server yang terpisah sehingga tidak memuat memori mesin pencari.
Karena ID dokumen unik hanya dalam kerangka satu indeks, sebuah situasi dapat muncul bahwa tidak ada dokumen dalam snippet. Baik atau bahwa pada satu ID akan ada konten lain. Oleh karena itu, agar pencarian bekerja dan pencarian terjadi, suatu kebutuhan telah muncul untuk konsistensi seluruh cluster. Saya akan berbicara tentang bagaimana kita memantau konsistensi sedikit kemudian.
Pencarian itu sendiri diatur sebagai berikut: permintaan pencarian dapat datang ke salah satu dari delapan server. Katakanlah dia datang ke server 1. Server ini memproses semua argumen dan mengerti apa dan bagaimana mencari. Tergantung pada permintaan yang masuk, server dapat membuat permintaan tambahan ke layanan eksternal untuk informasi yang diperlukan. Satu permintaan dapat diikuti hingga sepuluh permintaan ke layanan eksternal.
Setelah mengumpulkan informasi yang diperlukan, pencarian dimulai pada database penawaran. Untuk melakukan ini, subqueries dibuat untuk semua delapan server di cluster.
Setelah menerima jawaban, hasilnya digabungkan. Pada akhirnya, untuk menghasilkan masalah, Anda mungkin perlu beberapa subquery lagi ke server snippet.
Permintaan pencarian dalam cluster adalah:
/ shard1? Teks = angry + cat . Selain itu, subqueries dari form:
/ status secara konstan dibuat antara semua server di dalam cluster sekali per detik.
Permintaan
/ status mendeteksi situasi ketika server tidak tersedia.
Ini juga mengontrol bahwa di semua server versi mesin pencari dan versi indeks adalah sama, jika tidak akan ada data yang tidak konsisten di dalam cluster.
Terlepas dari kenyataan bahwa satu server cuplikan memproses permintaan dari delapan mesin pencari, prosesornya dimuat dengan sangat ringan. Karenanya, sekarang kami mentransfer data cuplikan ke layanan terpisah.
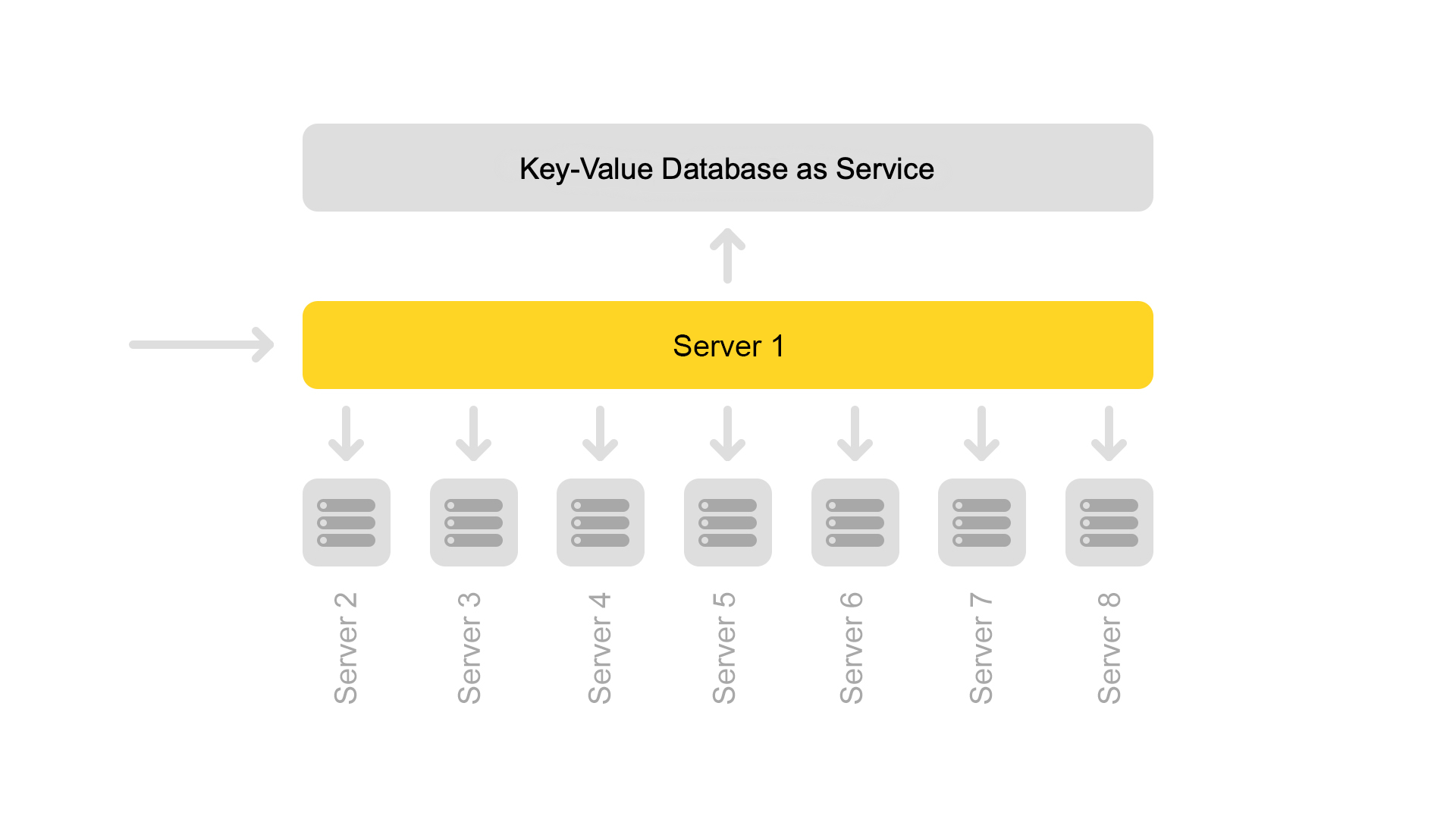
Untuk mentransfer data, kami memperkenalkan kunci universal untuk dokumen. Sekarang situasinya tidak mungkin ketika satu kunci mengembalikan konten dari dokumen lain.
Namun transisi ke arsitektur lain belum lengkap. Sekarang kami ingin menyingkirkan server cuplikan khusus. Dan kemudian umumnya menjauh dari struktur cluster. Ini akan memungkinkan kami untuk terus skala dengan mudah. Bonus tambahan adalah penghematan zat besi yang signifikan.
Dan sekarang untuk kisah-kisah menakutkan dengan akhir yang bahagia. Pertimbangkan beberapa kasus tidak tersedianya server.
Mengerikan terjadi: satu server tidak tersedia
Katakanlah satu server tidak tersedia. Kemudian server lain di cluster dapat terus merespons, tetapi hasil pencarian tidak akan lengkap.
Melalui pemeriksaan status, server tetangga memahami bahwa ada yang tidak tersedia. Oleh karena itu, untuk menjaga kelengkapan, semua server di kluster mulai menanggapi permintaan
/ ping ke penyeimbang bahwa mereka juga tidak tersedia. Ternyata semua server di cluster meninggal (yang tidak terjadi). Ini adalah kelemahan utama dari skema cluster kami - oleh karena itu, kami ingin menjauh darinya.
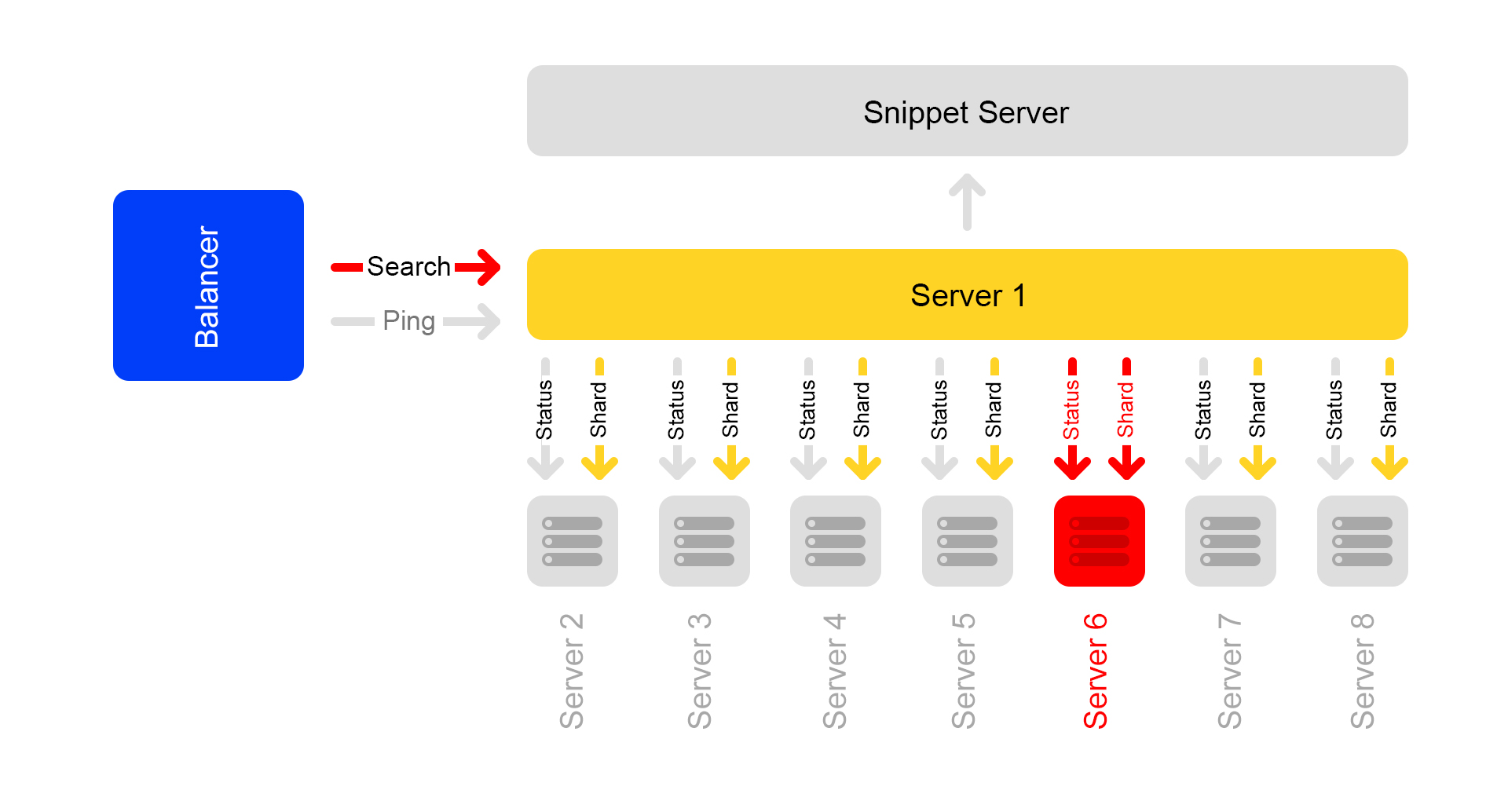
Permintaan yang diakhiri dengan kesalahan, penyeimbang bertanya lagi di server lain.
Selain itu, penyeimbang berhenti mengirim lalu lintas pengguna ke server yang mati, tetapi terus memeriksa statusnya.
Ketika server menjadi tersedia, ia mulai merespons
/ ping . Segera setelah respons normal terhadap ping dari server mati mulai berdatangan, penyeimbang mulai mengirimkan lalu lintas pengguna ke sana. Cluster dipulihkan, tepuk tangan.
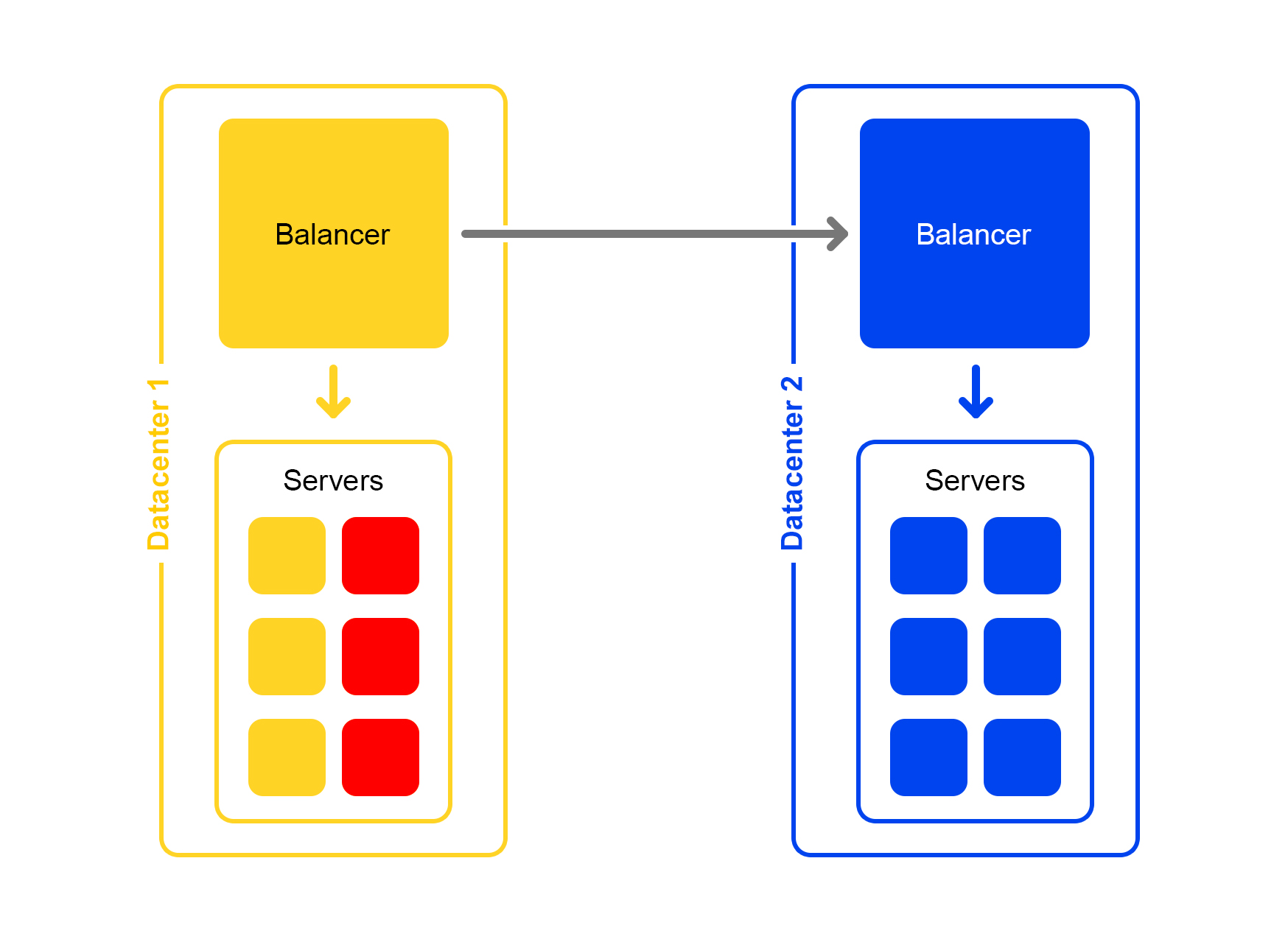
Lebih buruk lagi: banyak server tidak tersedia
Sebagian besar server di pusat data terputus. Apa yang harus dilakukan, ke mana harus lari? Penyeimbang datang untuk menyelamatkan lagi. Setiap penyeimbang secara konstan menyimpan dalam memori jumlah server saat ini. Dia selalu mempertimbangkan jumlah maksimum lalu lintas yang dapat ditangani oleh pusat data saat ini.
Ketika banyak server di pusat data jatuh, penyeimbang memahami bahwa pusat data ini tidak dapat memproses semua lalu lintas.
Kemudian kelebihan lalu lintas mulai didistribusikan secara acak ke pusat data lainnya. Semuanya berfungsi, semua orang senang.
Bagaimana kami melakukannya: rilis rilis
Sekarang tentang bagaimana kami mempublikasikan perubahan yang dilakukan pada layanan. Di sini kami mengambil jalur proses perampingan: meluncurkan rilis baru hampir sepenuhnya otomatis.
Ketika sejumlah perubahan diakumulasi dalam proyek, rilis baru secara otomatis dibuat dan perakitannya diluncurkan.
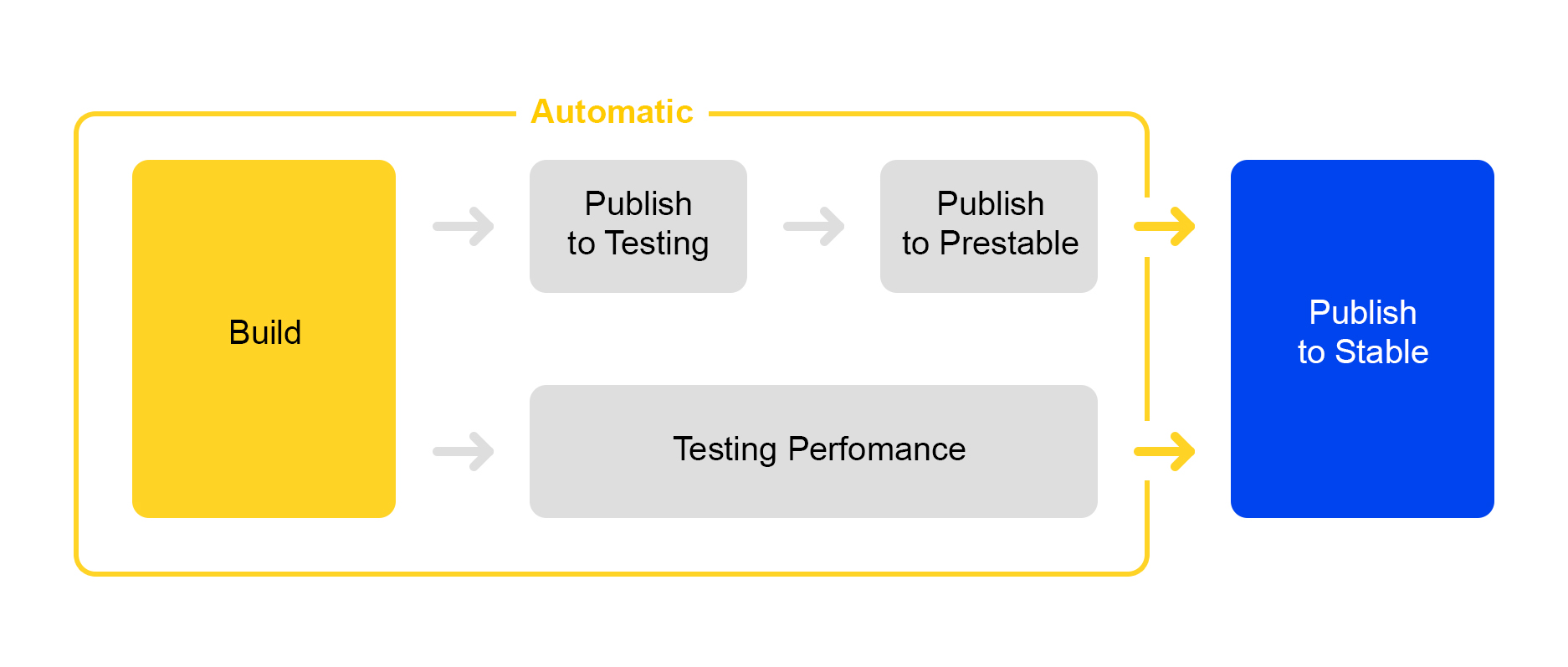
Kemudian layanan diluncurkan untuk pengujian, di mana stabilitas diperiksa.
Pada saat yang sama, pengujian kinerja otomatis diluncurkan. Dia terlibat dalam layanan khusus. Saya tidak akan membicarakannya sekarang - deskripsinya layak untuk artikel terpisah.
Jika publikasi dalam pengujian berhasil, publikasi rilis dalam prestable secara otomatis dimulai. Prestable adalah gugus khusus tempat lalu lintas pengguna normal diarahkan. Jika itu mengembalikan kesalahan, penyeimbang melakukan permintaan ulang dalam produksi.
Dalam prestable, waktu respons diukur dan dibandingkan dengan rilis sebelumnya dalam produksi. Jika semuanya baik-baik saja, maka orang tersebut menghubungkan: memeriksa grafik dan hasil pengujian beban dan kemudian mulai meluncurkan ke produksi.
Semua yang terbaik untuk pengguna: pengujian A / B
Tidak selalu jelas apakah perubahan dalam layanan akan membawa manfaat nyata. Untuk mengukur manfaat perubahan, orang-orang datang dengan pengujian A / B. Saya akan berbicara sedikit tentang cara kerjanya di pencarian Yandex.Market.
Semuanya dimulai dengan penambahan parameter CGI baru yang mencakup fungsionalitas baru. Biarkan parameter kami menjadi:
market_new_functionality = 1 . Kemudian, dalam kode, aktifkan fungsi ini dengan tanda:
If (cgi.experiments.market_new_functionality) {
Fungsionalitas baru diluncurkan dalam produksi.
Ada layanan khusus untuk mengotomatisasi pengujian A / B, yang
dijelaskan secara rinci di
sini . Eksperimen dibuat dalam layanan. Pangsa lalu lintas ditetapkan, misalnya, 15%. Minat ditetapkan bukan untuk permintaan, tetapi untuk pengguna. Waktu percobaan, misalnya, seminggu, juga ditunjukkan.
Beberapa percobaan dapat dimulai secara bersamaan. Di pengaturan, Anda dapat menentukan apakah persimpangan dengan eksperimen lain dimungkinkan.
Akibatnya, layanan ini secara otomatis menambahkan argumen
market_new_functionality = 1 hingga 15% pengguna. Dia juga secara otomatis menghitung metrik yang dipilih. Setelah percobaan, analis melihat hasilnya dan menarik kesimpulan. Berdasarkan temuan, keputusan dibuat untuk memulai dalam produksi atau penyempurnaan.
Tangan gesit pasar: pengujian produksi
Sering terjadi bahwa perlu untuk memeriksa operasi fungsi baru dalam produksi, tetapi tidak ada kepastian bagaimana itu akan berperilaku dalam kondisi "pertempuran" di bawah beban berat.
Ada solusinya: flag dalam parameter CGI dapat digunakan tidak hanya untuk pengujian A / B, tetapi juga untuk menguji fungsionalitas baru.
Kami membuat alat yang memungkinkan Anda untuk langsung mengubah konfigurasi pada ribuan server tanpa membuat layanan berisiko. Ini disebut "Stop Crane." Ide aslinya adalah kemampuan untuk dengan cepat mematikan beberapa fungsi tanpa tata letak. Kemudian alat diperluas dan menjadi lebih kompleks.
Skema layanan disajikan di bawah ini:
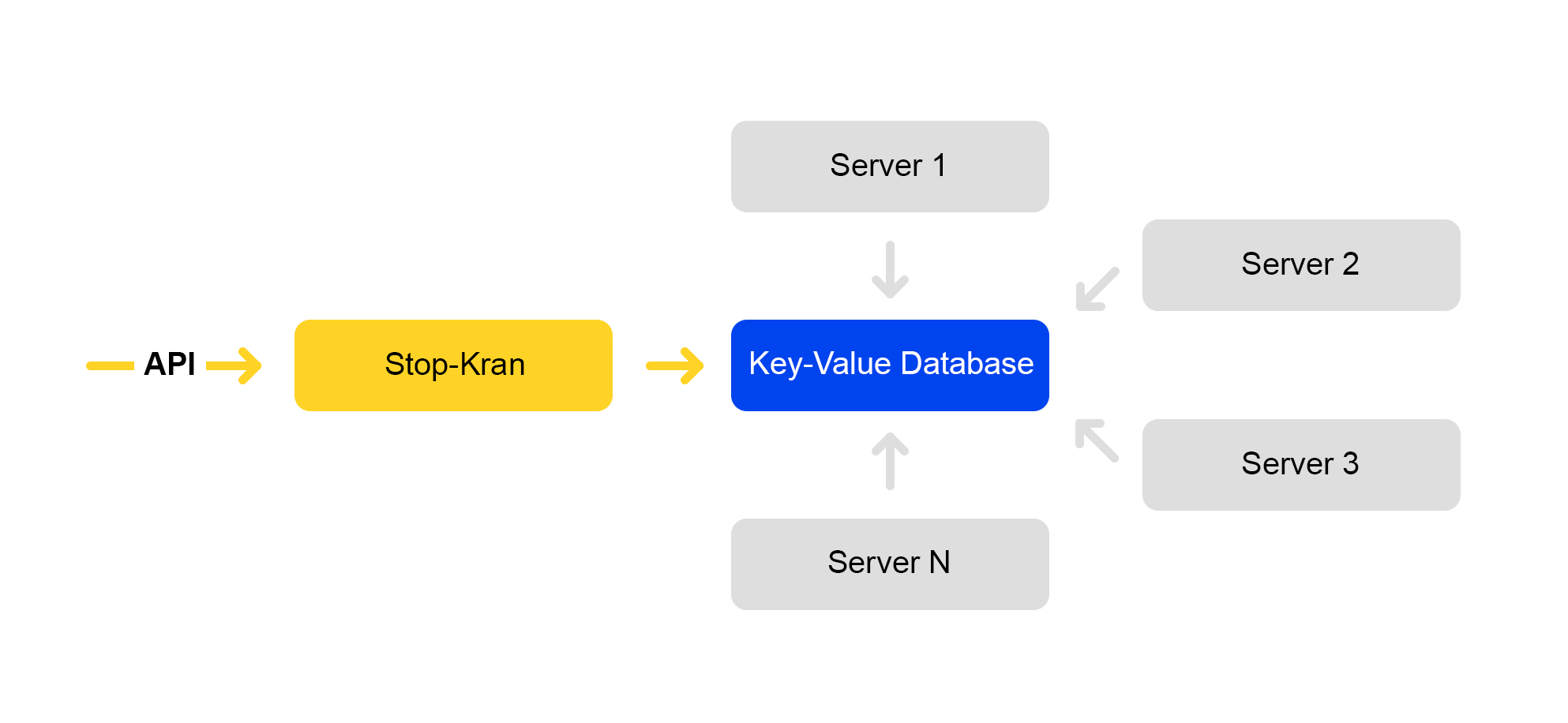
API menetapkan nilai bendera. Layanan manajemen menyimpan nilai-nilai ini dalam database. Semua server pergi ke database sekali setiap sepuluh detik, memompa nilai-nilai bendera dan menerapkan nilai-nilai ini untuk setiap permintaan.
Di Stop Crane, Anda dapat menetapkan dua jenis nilai:
1) Ekspresi bersyarat. Terapkan ketika salah satu nilai dieksekusi. Sebagai contoh:
{ "condition":"IS_DC1", "value":"3", }, { "condition": "CLUSTER==2 and IS_BERU", "value": "4!" }
Nilai "3" akan diterapkan ketika permintaan diproses di lokasi DC1. Dan nilainya adalah "4" ketika permintaan diproses pada cluster kedua untuk situs beru.ru.
2) Nilai tanpa syarat. Mereka digunakan secara default jika tidak ada kondisi yang terpenuhi. Sebagai contoh:
nilai, nilai!Jika nilai berakhir dengan tanda seru, itu diberikan prioritas yang lebih tinggi.
Pengurai parameter CGI mem-parsing URL. Kemudian terapkan nilai dari stop tap.
Nilai dengan prioritas berikut berlaku:
- Prioritas lebih tinggi dari stop tap (tanda seru).
- Nilai dari kueri.
- Nilai default adalah dari stop tap.
- Nilai default dalam kode.
Ada banyak flag yang ditunjukkan dalam nilai kondisional - mereka cukup untuk semua skenario yang kita ketahui:
- Pusat data.
- Lingkungan: produksi, pengujian, bayangan.
- Tempat: pasar, beru.
- Nomor cluster.
Dengan alat ini, Anda dapat mengaktifkan fungsionalitas baru pada sekelompok server (misalnya, hanya dalam satu pusat data) dan memeriksa pengoperasian fungsi ini tanpa banyak risiko pada seluruh layanan. Bahkan jika Anda secara serius membuat kesalahan di suatu tempat, semuanya mulai turun dan seluruh pusat data turun, penyeimbang akan mengarahkan permintaan ke pusat data lainnya. Pengguna akhir tidak akan melihat apa pun.
Jika Anda melihat masalah, Anda dapat segera mengembalikan nilai bendera sebelumnya, dan perubahan akan dibatalkan.
Layanan ini memiliki kekurangan: pengembang sangat menyukainya dan sering mencoba untuk mendorong semua perubahan ke dalam Stop Crane. Kami berusaha memerangi penyalahgunaan.
Pendekatan Stop Crane berfungsi dengan baik ketika Anda sudah memiliki kode stabil, siap untuk diluncurkan dalam produksi. Pada saat yang sama, Anda masih memiliki keraguan, dan Anda ingin memeriksa kode dalam kondisi "pertempuran".
Namun, stopcock tidak cocok untuk pengujian selama pengembangan. Untuk pengembang, ada cluster terpisah yang disebut "shadow cluster".
Pengujian Terselubung: Shadow Cluster
Permintaan dari salah satu kelompok digandakan ke kelompok bayangan. Tetapi penyeimbang benar-benar mengabaikan tanggapan dari gugus ini. Skema karyanya disajikan di bawah ini.
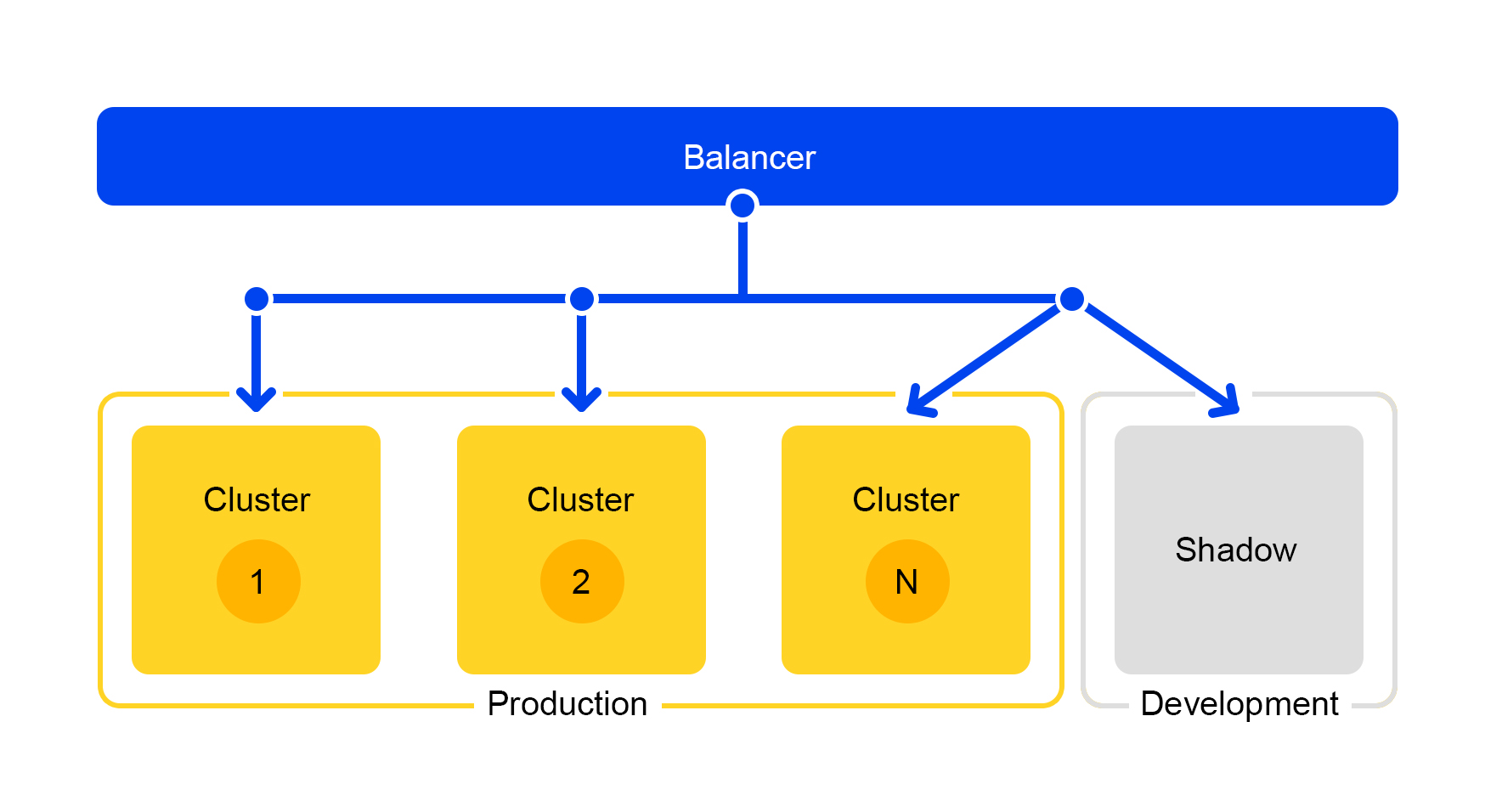
Kami mendapatkan kelompok uji yang dalam kondisi "pertempuran" nyata. Lalu lintas pengguna normal terbang di sana. Perangkat keras di kedua cluster adalah sama, sehingga Anda dapat membandingkan kinerja dan kesalahan.
Dan karena penyeimbang sepenuhnya mengabaikan jawaban, pengguna akhir tidak akan melihat respons dari kelompok bayangan. Karena itu, tidak menakutkan untuk melakukan kesalahan.
Kesimpulan
Jadi, bagaimana kami membangun pencarian Pasar?
Agar semuanya berjalan lancar, kami memisahkan fungsionalitas menjadi layanan terpisah. Jadi, Anda hanya dapat menskala komponen-komponen yang kami butuhkan dan membuat komponen lebih sederhana. Sangat mudah untuk memberikan komponen terpisah kepada tim lain dan berbagi tanggung jawab untuk mengerjakannya. Dan penghematan yang signifikan dalam zat besi dengan pendekatan ini merupakan nilai tambah yang jelas.
Shadow cluster juga membantu kami: Anda dapat mengembangkan layanan, mengujinya dalam proses dan pada saat yang sama tidak mengganggu pengguna.
Baik dan periksa produksi, tentu saja. Perlu mengubah konfigurasi pada seribu server? Mudah, gunakan stop crane. Jadi, Anda dapat segera meluncurkan solusi kompleks yang sudah jadi dan mengembalikan ke versi stabil jika muncul masalah.
Saya harap saya bisa menunjukkan bagaimana kita membuat Pasar cepat dan stabil dengan basis penawaran yang terus berkembang. Bagaimana mengatasi masalah server, menangani sejumlah besar permintaan, meningkatkan fleksibilitas layanan dan melakukan ini tanpa mengganggu proses kerja.