Hai Hari ini saya akan memberi tahu pembaca Habr tentang bagaimana kami menciptakan teknologi pengenalan teks yang bekerja dalam 45 bahasa dan dapat diakses oleh pengguna Yandex.Cloud, tugas apa yang kami tetapkan, dan bagaimana kami menyelesaikannya. Ini akan berguna jika Anda mengerjakan proyek serupa atau ingin mengetahui bagaimana hal itu terjadi sehingga hari ini Anda hanya perlu memotret tanda toko Turki sehingga Alice menerjemahkannya ke dalam bahasa Rusia.

Teknologi optical character recognition (OCR) telah berkembang di dunia selama beberapa dekade. Kami di Yandex mulai mengembangkan teknologi OCR kami sendiri untuk meningkatkan layanan kami dan memberi pengguna lebih banyak opsi. Gambar adalah bagian besar dari Internet, dan tanpa kemampuan untuk memahaminya, pencarian di internet tidak akan lengkap.
Solusi analisis gambar menjadi semakin populer. Hal ini disebabkan oleh proliferasi jaringan saraf tiruan dan perangkat dengan sensor berkualitas tinggi. Jelas bahwa pertama-tama kita berbicara tentang smartphone, tetapi tidak hanya tentang mereka.
Kompleksitas tugas di bidang pengenalan teks terus berkembang - semuanya dimulai dengan pengakuan dokumen yang dipindai. Kemudian
pengenalan Born-Digital-gambar dengan teks dari Internet ditambahkan. Kemudian, dengan semakin populernya kamera ponsel, pengakuan akan hasil jepretan kamera yang bagus (
teks adegan terfokus ). Dan semakin jauh, semakin rumit parameternya: teks bisa kabur (
Incidental scene text ),
ditulis dengan sembarang tikungan atau spiral, dari berbagai kategori - dari
foto kwitansi hingga
rak toko dan papan nama.
Kemana kita pergi
Pengenalan teks adalah kelas yang terpisah dari tugas visi komputer. Seperti banyak algoritma visi komputer, sebelum popularitas jaringan saraf, sebagian besar didasarkan pada fitur manual dan heuristik. Namun, baru-baru ini, dengan transisi ke pendekatan jaringan saraf, kualitas teknologi telah tumbuh secara signifikan. Lihatlah contoh di foto. Bagaimana ini terjadi, saya akan ceritakan lebih lanjut.
Bandingkan hasil pengakuan hari ini dengan hasil di awal 2018:
Kesulitan apa yang kita hadapi pada awalnya?
Pada awal perjalanan kami, kami membuat teknologi pengenalan untuk Rusia dan Inggris, dan kasing utama adalah halaman teks dan gambar yang difoto dari Internet. Tetapi dalam perjalanan, kami menyadari bahwa ini tidak cukup: teks pada gambar ditemukan dalam bahasa apa pun, pada permukaan apa pun, dan gambar-gambar itu kadang-kadang ternyata memiliki kualitas yang sangat berbeda. Ini berarti bahwa pengenalan harus bekerja dalam situasi apa pun dan pada semua jenis data yang masuk.
Dan di sini kita dihadapkan pada sejumlah kesulitan. Berikut ini beberapa di antaranya:
- Detail Untuk orang yang terbiasa mendapatkan informasi dari teks, teks dalam gambar adalah paragraf, garis, kata-kata dan huruf, tetapi untuk jaringan saraf semuanya terlihat berbeda. Karena sifat teks yang kompleks, jaringan dipaksa untuk melihat gambar secara keseluruhan (misalnya, jika orang bergandengan tangan dan membuat prasasti), dan detail terkecil (dalam bahasa Vietnam, simbol serupa dan ừ mengubah arti kata). Tantangan terpisah adalah mengenali teks sewenang-wenang dan font yang tidak standar.
- Multilingualisme . Semakin banyak bahasa yang kami tambahkan, semakin banyak kami dihadapkan dengan kekhususannya: dalam bahasa Cyrillic dan Latin terdiri dari huruf-huruf yang terpisah, dalam bahasa Arab keduanya ditulis bersama, dalam bahasa Jepang tidak ada kata yang berbeda yang dibedakan. Beberapa bahasa menggunakan ejaan dari kiri ke kanan, beberapa dari kanan ke kiri. Beberapa kata ditulis secara horizontal, beberapa secara vertikal. Alat universal harus memperhitungkan semua fitur ini.
- Struktur teks . Untuk mengenali gambar tertentu, seperti cek atau dokumen yang kompleks, struktur yang memperhitungkan tata letak paragraf, tabel, dan elemen lainnya sangat penting.
- Performa . Teknologi ini digunakan pada berbagai perangkat, termasuk offline, jadi kami harus memperhitungkan persyaratan kinerja yang ketat.
Pemilihan Model Deteksi
Langkah pertama untuk mengenali teks adalah menentukan posisinya (deteksi).
Deteksi teks dapat dianggap sebagai tugas pengenalan objek, di mana
karakter individu,
kata atau
garis dapat bertindak sebagai objek.
Penting bagi kami bahwa model selanjutnya diskalakan ke bahasa lain (sekarang kami mendukung 45 bahasa).
Banyak artikel penelitian tentang deteksi teks menggunakan model yang memprediksi posisi
kata -
kata individual. Tetapi dalam kasus
model universal, pendekatan ini memiliki beberapa keterbatasan - misalnya, konsep kata untuk bahasa Cina pada dasarnya berbeda dari konsep kata, misalnya, dalam bahasa Inggris. Kata-kata individual dalam bahasa Cina tidak dipisahkan oleh spasi. Di Thailand, hanya satu kalimat yang dibuang dengan spasi.
Berikut adalah contoh teks yang sama dalam bahasa Rusia, Cina, dan Thailand:
. .
今天天气很好 这是一个美丽的一天散步。
สภาพอากาศสมบูรณ์แบบในวันนี้ มันเป็นวันที่สวยงามสำหรับเดินเล่นกันหน่อยแล้วBaris , pada gilirannya, sangat bervariasi dalam hal rasio aspek. Karena itu, kemungkinan model pendeteksian umum seperti itu (misalnya, berbasis SSD atau RCNN) untuk prediksi saluran terbatas, karena model ini didasarkan pada daerah kandidat / kotak jangkar dengan banyak rasio aspek yang telah ditentukan. Selain itu, garis dapat memiliki bentuk sewenang-wenang, misalnya, melengkung, oleh karena itu untuk deskripsi kualitatif garis itu tidak cukup eksklusif untuk menggambarkan segi empat, bahkan dengan sudut rotasi.
Terlepas dari kenyataan bahwa posisi masing-masing
karakter bersifat lokal dan dideskripsikan, kelemahan mereka adalah bahwa diperlukan langkah pasca-pemrosesan yang terpisah - Anda perlu memilih heuristik untuk menempelkan karakter ke dalam kata dan garis.
Oleh karena itu, kami menggunakan
model SegLink sebagai dasar untuk deteksi, ide utamanya adalah untuk menguraikan baris / kata menjadi dua entitas lokal: segmen dan hubungan di antara mereka.
Arsitektur detektor
Arsitektur model didasarkan pada SSD, yang memprediksi posisi objek pada beberapa skala fitur. Hanya selain memprediksi koordinat "segmen" individu juga diprediksi "koneksi" antara segmen yang berdekatan, yaitu, apakah dua segmen milik garis yang sama. "Koneksi" diprediksi baik untuk segmen tetangga pada skala tanda yang sama, dan untuk segmen yang terletak di daerah yang berdekatan pada skala tetangga (segmen dari skala tanda yang berbeda mungkin sedikit berbeda dalam ukuran dan termasuk dalam garis yang sama).
Untuk setiap skala, setiap sel fitur dikaitkan dengan "segmen" yang sesuai. Untuk setiap segmen s
(x, y, l) pada titik (x, y) pada skala l, berikut ini dilatih:
- p
s apakah segmen yang diberikan adalah teks;
- x
s , y
s , w
s , h
s , θ
s - offset koordinat basis dan sudut kemiringan segmen;
- 8 skor untuk kehadiran "koneksi" dengan segmen yang berdekatan dengan skala ke-l (
Ls , s ' , s' dari {s
(x ', y', l) } / s
(x, y, l) , di mana x –1 ≤ x '≤ x + 1, y - 1 ≤ y' ≤ y + 1);
- 4 skor untuk kehadiran "koneksi" dengan segmen yang berdekatan dengan skala l-1 (L
c s, s ' , s' dari {s
(x ', y', l-1) }, di mana 2x ≤ x '≤ 2x + 1 , 2y ≤ y '≤ 2y + 1) (yang benar karena fakta bahwa dimensi fitur pada skala tetangga berbeda persis 2 kali).
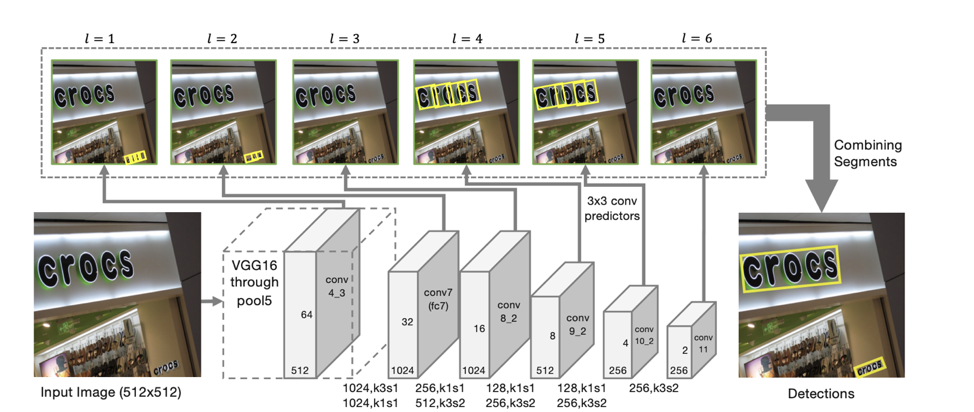
Menurut prediksi seperti itu, jika kita mengambil sebagai simpul semua segmen yang probabilitas bahwa mereka adalah teks lebih besar dari ambang α, dan sebagai ujung semua ikatan yang probabilitasnya lebih besar dari ambang β, maka segmen membentuk komponen yang terhubung, masing-masing menggambarkan garis teks .
Model yang dihasilkan memiliki
kemampuan generalisasi yang tinggi : bahkan dilatih dalam pendekatan pertama pada data Rusia dan Inggris, secara kualitatif ditemukan teks Cina dan Arab.
Sepuluh skrip
Jika untuk pendeteksian kami dapat membuat model yang bekerja langsung untuk semua bahasa, maka untuk pengenalan garis-garis yang ditemukan model seperti itu jauh lebih sulit diperoleh. Karena itu, kami memutuskan untuk menggunakan
model terpisah untuk setiap skrip (Sirilik, Latin, Arab, Ibrani, Yunani, Armenia, Georgia, Korea, Thailand). Model umum yang terpisah digunakan untuk Cina dan Jepang karena persimpangan besar dalam hieroglif.
Model yang umum untuk seluruh skrip berbeda dari model terpisah untuk setiap bahasa kurang dari 1 p.p. kualitas. Pada saat yang sama, pembuatan dan implementasi satu model lebih sederhana daripada, misalnya, 25 model (jumlah bahasa Latin yang didukung oleh model kami). Tetapi karena seringnya bahasa Inggris di semua bahasa, semua model kami dapat memprediksi, selain skrip utama, karakter Latin.
Untuk memahami model mana yang harus digunakan untuk pengakuan, pertama-tama kita menentukan apakah baris yang diterima milik salah satu dari 10 skrip yang tersedia untuk pengakuan.
Perlu dicatat secara terpisah bahwa tidak selalu mungkin untuk secara unik menentukan skripnya. Misalnya, angka atau karakter Latin tunggal terkandung dalam banyak skrip, sehingga salah satu kelas output dari model adalah skrip "tidak terdefinisi".
Definisi skrip
Untuk mendefinisikan skrip, kami membuat classifier terpisah. Tugas mendefinisikan naskah jauh lebih sederhana daripada tugas pengakuan, dan jaringan saraf mudah dilatih ulang pada data sintetik. Oleh karena itu, dalam percobaan kami, peningkatan yang signifikan dalam kualitas model diberikan oleh
pra-pelatihan tentang masalah pengenalan string . Untuk melakukan ini, kami pertama-tama melatih jaringan untuk masalah pengenalan untuk semua bahasa yang tersedia. Setelah itu, tulang punggung yang dihasilkan digunakan untuk menginisialisasi model ke tugas klasifikasi skrip.
Sementara sebuah skrip pada baris individual sering kali sangat berisik, gambar secara keseluruhan paling sering berisi teks dalam satu bahasa, baik di samping diselingi utama dengan bahasa Inggris (atau dalam kasus pengguna Rusia kami). Oleh karena itu, untuk
meningkatkan stabilitas, kami mengumpulkan prediksi garis dari gambar untuk mendapatkan prediksi skrip gambar yang lebih stabil. Baris dengan kelas prediksi "tidak terbatas" tidak diperhitungkan dalam agregasi.
Pengenalan garis
Langkah selanjutnya, ketika kita telah menentukan posisi setiap baris dan skripnya, kita perlu
mengenali urutan karakter dari skrip yang
diberikan yang ditampilkan di atasnya, yaitu dari urutan piksel untuk memprediksi urutan karakter. Setelah banyak percobaan, kami sampai pada model berdasarkan perhatian Sequence2 berikut:

Menggunakan CNN + BiLSTM dalam encoder memungkinkan Anda untuk mendapatkan tanda yang menangkap konteks lokal dan global. Untuk teks, ini penting - seringkali ditulis dalam satu font (membedakan huruf serupa dengan informasi font jauh lebih mudah). Dan untuk membedakan dua huruf yang ditulis dengan spasi dari yang berurutan, statistik global juga diperlukan untuk saluran tersebut.
Pengamatan yang menarik : dalam model yang dihasilkan, output topeng perhatian untuk simbol tertentu dapat digunakan untuk memprediksi posisinya dalam gambar.
Ini mengilhami kami untuk mencoba
"memfokuskan" perhatian model dengan jelas . Gagasan semacam itu juga ditemukan dalam artikel - misalnya, dalam artikel
Perhatian Fokus: Menuju Pengakuan Teks yang Akurat dalam Gambar Alam .
Karena mekanisme perhatian memberikan distribusi probabilitas di atas ruang fitur, jika kita mengambil sebagai tambahan kerugian jumlah output perhatian di dalam topeng yang sesuai dengan huruf yang diprediksi pada langkah ini, kita mendapatkan bagian dari "perhatian" yang berfokus langsung padanya.
Dengan memperkenalkan loss -log (∑
i, j∈M t α
i, j ), di mana
Mt adalah topeng dari huruf tth, α adalah output dari perhatian, kami akan mendorong "perhatian" untuk fokus pada simbol yang diberikan dan dengan demikian membantu jaringan saraf belajar lebih baik.
Untuk contoh pelatihan yang lokasi karakter individu tidak diketahui atau tidak akurat (tidak semua data pelatihan memiliki tanda di tingkat karakter individu, bukan kata-kata), istilah ini tidak diperhitungkan dalam kerugian akhir.
Fitur bagus lainnya: arsitektur ini memungkinkan Anda untuk memprediksi
pengenalan garis
kanan-ke-kiri tanpa perubahan tambahan (yang penting, misalnya, untuk bahasa seperti Arab, Ibrani). Model itu sendiri mulai mengeluarkan pengakuan dari kanan ke kiri.
Model cepat dan lambat
Dalam prosesnya, kami mengalami masalah:
untuk font "tinggi" , yaitu font yang memanjang secara vertikal, modelnya bekerja dengan buruk. Ini disebabkan oleh fakta bahwa dimensi tanda pada level perhatian 8 kali lebih kecil dari dimensi gambar asli karena langkah dan tarikan arsitektur bagian konvolusional jaringan. Dan lokasi beberapa karakter tetangga di gambar sumber dapat sesuai dengan lokasi vektor fitur yang sama, yang dapat menyebabkan kesalahan dalam contoh-contoh tersebut. Penggunaan arsitektur dengan penyempitan dimensi fitur yang lebih kecil menyebabkan peningkatan kualitas, tetapi juga peningkatan waktu pemrosesan.
Untuk mengatasi masalah ini dan
menghindari bertambahnya waktu pemrosesan , kami melakukan penyempurnaan berikut pada model:
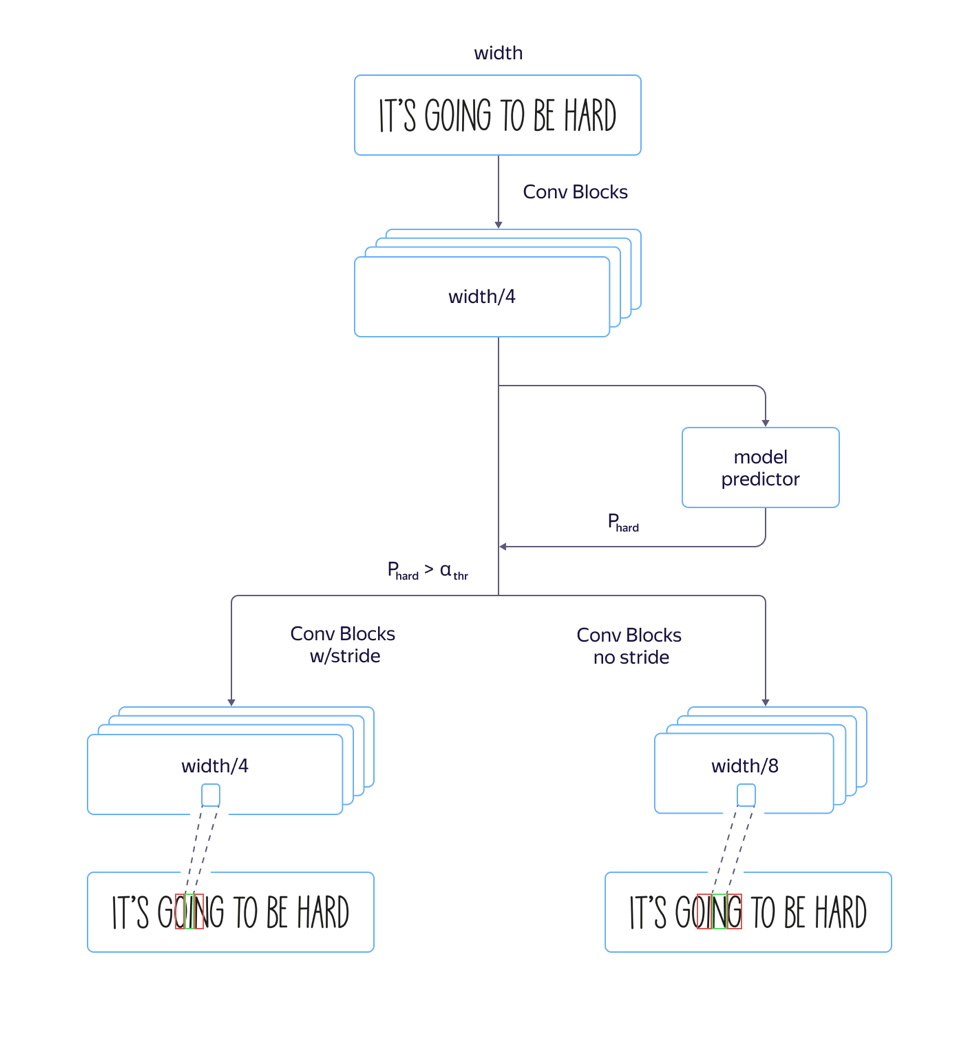
Kami melatih kedua model cepat dengan banyak langkah dan lambat dengan kurang. Pada layer di mana parameter model mulai berbeda, kami menambahkan output jaringan terpisah yang memperkirakan model mana yang akan memiliki kesalahan pengenalan yang lebih sedikit. Kehilangan total model terdiri dari L
kecil + L
besar +
kualitas L. Jadi, pada lapisan menengah, model belajar untuk menentukan "kompleksitas" dari contoh ini. Selanjutnya, pada tahap aplikasi, bagian umum dan prediksi "kompleksitas" dari contoh dipertimbangkan untuk semua lini, dan tergantung pada outputnya, baik model cepat atau lambat digunakan di masa depan sesuai dengan nilai ambang batas. Ini memungkinkan kami untuk mendapatkan kualitas yang hampir tidak berbeda dari kualitas model lama, sementara kecepatannya hanya meningkat 5% persen daripada perkiraan 30%.
Data Pelatihan
Tahap penting dalam menciptakan model berkualitas tinggi adalah persiapan sampel pelatihan yang besar dan beragam. Sifat "sintetik" dari teks memungkinkan untuk menghasilkan sejumlah besar contoh dan mendapatkan hasil yang layak pada data nyata.
Setelah pendekatan pertama untuk menghasilkan data sintetis, kami dengan hati-hati melihat hasil model yang diperoleh dan menemukan bahwa model tersebut tidak mengenali huruf tunggal 'I' dengan baik karena bias dalam teks yang digunakan untuk membuat set pelatihan. Oleh karena itu, kami jelas menghasilkan
serangkaian contoh "bermasalah" , dan ketika kami menambahkannya ke data awal model, kualitasnya meningkat secara signifikan. Kami mengulangi proses ini berkali-kali, menambahkan irisan yang semakin kompleks, di mana kami ingin meningkatkan kualitas pengakuan.
Poin penting adalah bahwa
data yang dihasilkan
harus beragam dan mirip dengan yang asli . Dan jika Anda ingin model bekerja pada foto teks pada lembaran kertas, dan seluruh dataset sintetis berisi teks yang ditulis di atas lanskap, maka ini mungkin tidak berfungsi.
Langkah penting lainnya adalah menggunakan untuk melatih contoh-contoh di mana pengakuan saat ini salah. Jika ada sejumlah besar gambar yang tidak ada markup, Anda dapat mengambil output dari sistem pengenalan saat ini di mana dia tidak yakin, dan hanya menandai mereka, sehingga mengurangi biaya markup.
Untuk contoh kompleks, kami meminta pengguna layanan Yandex.Tolok untuk memotret dan mengirimi kami
gambar grup "kompleks" tertentu - misalnya, foto paket barang:


Kualitas pekerjaan pada data "kompleks"
Kami ingin memberi pengguna kami kesempatan untuk bekerja dengan foto-foto dengan kompleksitas apa pun, karena mungkin perlu mengenali atau menerjemahkan teks tidak hanya pada halaman buku atau dokumen yang dipindai, tetapi juga pada tanda jalan, pengumuman atau kemasan produk. Oleh karena itu, sambil mempertahankan kualitas kerja yang tinggi pada aliran buku dan dokumen (kami akan mencurahkan cerita terpisah untuk topik ini), kami memberikan perhatian khusus pada "set gambar yang kompleks".
Dengan cara yang dijelaskan di atas, kami telah menyusun serangkaian gambar yang berisi teks di alam liar, yang mungkin berguna bagi pengguna kami: foto-foto papan nama, pengumuman, piring, sampul buku, teks pada peralatan rumah tangga, pakaian dan benda. Pada kumpulan data ini (tautannya di bawah), kami mengevaluasi kualitas algoritma kami.
Sebagai metrik untuk perbandingan, kami menggunakan metrik standar akurasi dan kelengkapan pengenalan kata dalam dataset, serta ukuran-F. Kata yang dikenali dianggap benar ditemukan jika koordinatnya sesuai dengan koordinat kata yang ditandai (IoU> 0,3) dan pengakuannya bertepatan dengan tanda yang ditandai persis dengan case. Angka pada dataset yang dihasilkan:
Kumpulan data, metrik, dan skrip untuk mereproduksi hasil tersedia di
sini .
Pembaruan. Teman, membandingkan teknologi kami dengan solusi serupa dari Abbyy menyebabkan banyak kontroversi. Kami menghormati pendapat komunitas dan rekan-rekan industri. Tetapi pada saat yang sama kami yakin dengan hasil kami, jadi kami memutuskan dengan cara ini: kami akan menghapus hasil produk lain dari perbandingan, mendiskusikan metodologi pengujian dengan mereka lagi dan kembali ke hasil di mana kami mencapai kesepakatan umum.
Langkah selanjutnya
Di persimpangan langkah-langkah individual, seperti deteksi dan pengakuan, masalah selalu muncul: perubahan sekecil apa pun dalam model deteksi memerlukan kebutuhan untuk mengubah model pengakuan, jadi kami secara aktif bereksperimen dengan menciptakan solusi ujung ke ujung.
Selain cara yang telah dijelaskan untuk meningkatkan teknologi, kami akan mengembangkan arah untuk menganalisis struktur dokumen, yang secara fundamental penting ketika mengekstraksi informasi dan diminati oleh pengguna.
Kesimpulan
Pengguna sudah terbiasa dengan teknologi yang nyaman dan tanpa ragu menyalakan kamera, arahkan ke tanda toko, menu di restoran atau halaman dalam buku dalam bahasa asing dan cepat menerima terjemahan. Kami mengenali teks dalam 45 bahasa dengan akurasi yang telah terbukti, dan peluang hanya akan berkembang. Seperangkat alat di dalam Yandex.Cloud memungkinkan siapa saja yang ingin menggunakan praktik terbaik yang telah dilakukan Yandex sendiri sejak lama.
Hari ini Anda bisa mengambil teknologi yang sudah jadi, mengintegrasikannya ke dalam aplikasi Anda sendiri dan menggunakannya untuk menciptakan produk baru dan mengotomatiskan proses Anda sendiri. Dokumentasi untuk OCR kami tersedia di
sini .
Apa yang harus dibaca:
- D. Karatzas, SR Mestre, J. Mas, F. Nourbakhsh, dan PP Roy, “ICDAR 2011 kompetisi membaca yang kuat-tantangan 1: membaca teks dalam gambar digital-lahir (web dan email),” dalam Analisis dan Pengakuan Dokumen (ICDAR ), Konferensi Internasional 2011 tentang. IEEE, 2011, hlm. 1485-1490.
- Karatzas D. et al. Kompetisi ICDAR 2015 tentang Bacaan Kuat // 2015 Konferensi Internasional ke-13 tentang Analisis dan Pengakuan Dokumen (ICDAR). - IEEE, 2015 .-- S. 1156-1160.
- Chee-Kheng Chng et. al. ICDAR2019 Tantangan Membaca Kuat pada Teks Berbentuk Sewenang-wenang (RRC-ArT) [ arxiv: 1909.07145v1 ]
- ICDAR 2019 Tantangan Membaca Kuat pada Tanda Terima yang Dipindai OCR dan Ekstraksi Informasi rrc.cvc.uab.es/?ch=13
- ShopSign: Dataset Teks Adegan Beragam dari Tanda Toko Cina di Street Views [ arxiv: 1903.10412 ]
- Baoguang Shi, Xiang Bai, Serge Belongie Mendeteksi Teks Berorientasi dalam Gambar Alam dengan Menautkan Segmen [ arxiv: 1703.06520 ].
- Zhanzhan Cheng, Fan Bai, Yunlu Xu, Gang Zheng, Pu Shiliang, Shuigeng Zhou Memfokuskan Perhatian: Menuju Pengakuan Teks Akurat dalam Gambar Alam [ arxiv: 1709.02054 ].