Selamat siang dan hormat saya, para pembaca Habr!
Latar belakang
Di tempat kami, sudah biasa untuk bertukar temuan menarik di tim pengembangan. Pada pertemuan berikutnya, membahas masa depan .NET dan .NET 5 khususnya, saya dan kolega saya fokus melihat platform terpadu dari gambar ini:
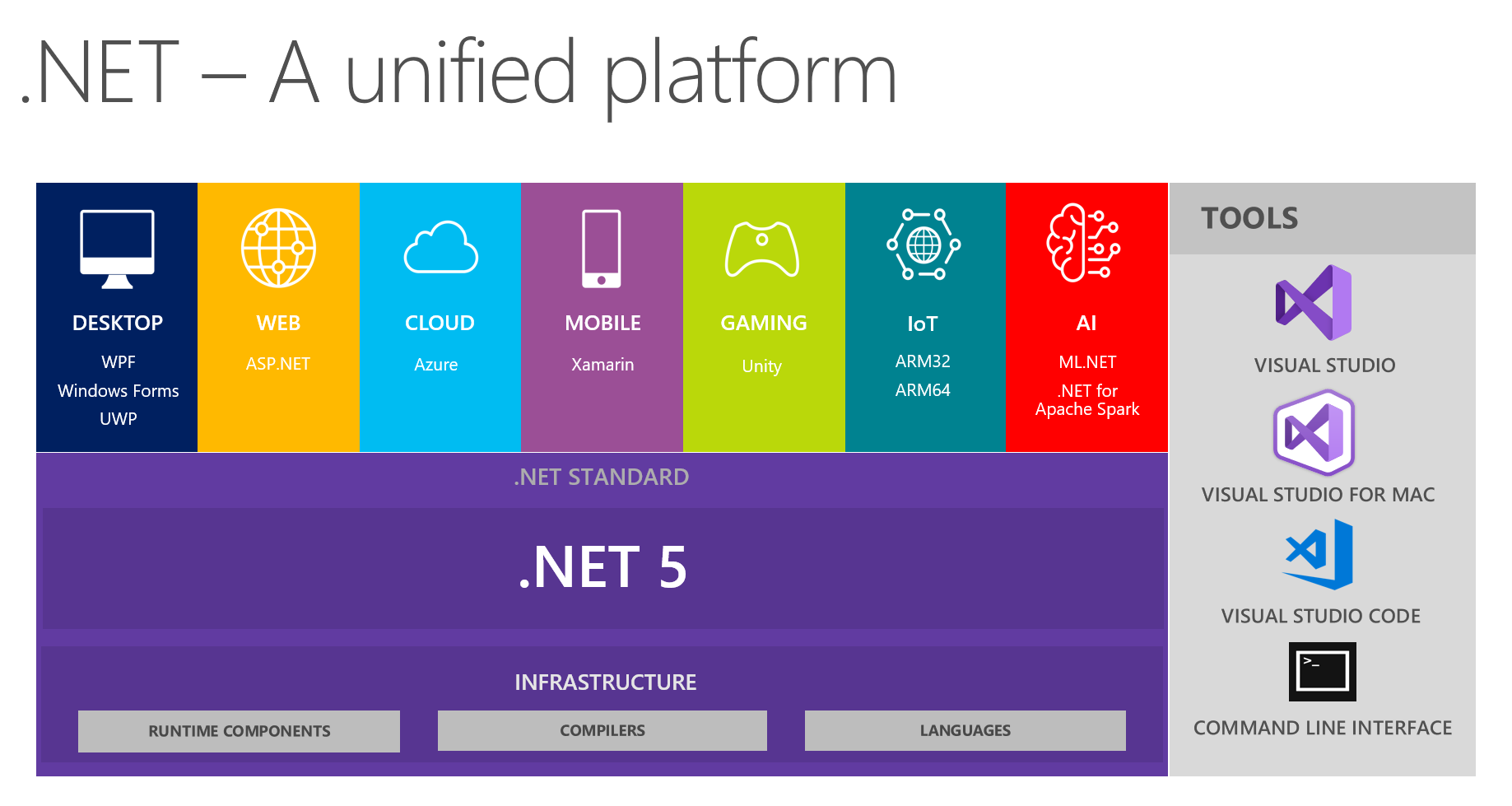
Ini menunjukkan bahwa platform menggabungkan DESKTOP, WEB, CLOUD, MOBILE, GAMING, IoT dan AI. Saya mendapat ide untuk melakukan percakapan dalam bentuk laporan kecil + pertanyaan / jawaban pada setiap topik pada pertemuan berikutnya. Orang yang bertanggung jawab untuk topik tertentu pada awalnya mempersiapkan, membaca informasi tentang inovasi utama, mencoba menerapkan sesuatu menggunakan teknologi yang dipilih, dan kemudian berbagi pemikiran dan kesan dengan kami. Akibatnya, semua orang mendapat umpan balik nyata pada alat dari sumber tepercaya secara langsung - itu sangat nyaman, mengingat bahwa mencoba dan menyerbu semua topik sendiri mungkin tidak berguna, tangan Anda tidak akan bisa menjangkau.
Karena saya telah secara aktif tertarik pada pembelajaran mesin sebagai hobi untuk beberapa waktu (dan kadang-kadang menggunakannya untuk tugas-tugas non-bisnis di tempat kerja), saya mendapatkan topik AI & ML.NET. Dalam proses persiapan, saya menemukan alat-alat dan bahan-bahan yang bagus, yang mengejutkan saya, saya menemukan bahwa hanya ada sedikit informasi tentang mereka di Habré. Sebelumnya di blog resmi Microsoft menulis tentang rilis ML.Net , dan Model Builder pada khususnya. Saya ingin berbagi bagaimana saya datang kepadanya dan kesan apa yang saya dapatkan dari bekerja dengannya. Artikel ini lebih banyak tentang Model Builder daripada ML dalam .NET secara keseluruhan; kami akan mencoba untuk melihat apa yang MS tawarkan kepada pengembang .NET rata-rata, tetapi dengan mata orang yang mahir dalam ML. Pada saat yang sama saya akan mencoba menjaga keseimbangan antara menceritakan kembali tutorial, benar-benar mengunyah untuk pemula dan deskripsi detail untuk spesialis ML, yang karena alasan tertentu perlu datang ke .NET.
Tubuh utama
Jadi, googling cepat tentang ML di .NET membawa saya ke halaman tutorial :
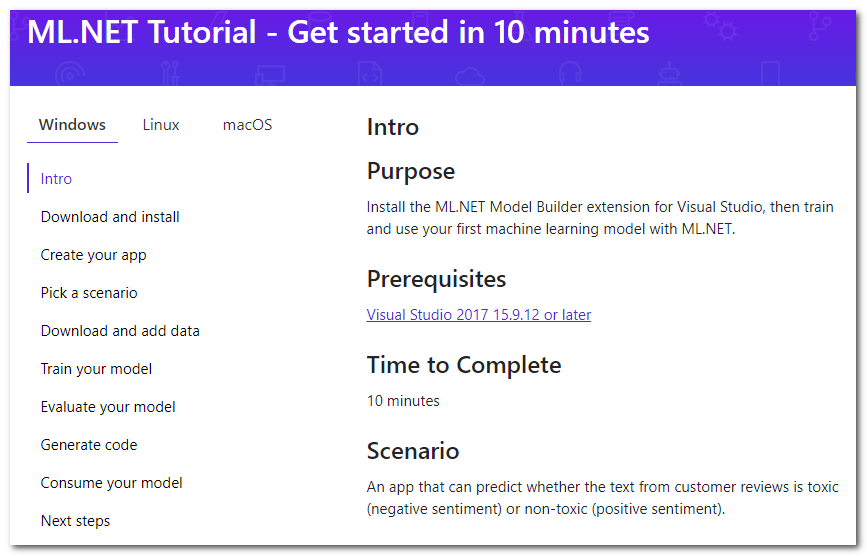
Ternyata ada ekstensi khusus untuk Visual Studio yang disebut Model Builder, yang "memungkinkan Anda menambahkan pembelajaran mesin ke proyek Anda dengan tombol mouse kanan" (terjemahan gratis). Secara singkat saya akan membahas langkah-langkah utama tutorial yang ditawarkan untuk dilakukan, saya akan menambahkan detail dan pemikiran saya.
Unduh dan pasang
Tekan tombol, unduh, instal. Studio harus memulai ulang.
Buat aplikasi Anda
Pertama, buat aplikasi C # biasa. Dalam tutorial ini diusulkan untuk membuat Core, tetapi juga sesuai dengan Framework. Dan kemudian, pada kenyataannya, ML dimulai - klik kanan pada proyek, lalu Tambah -> Pembelajaran Mesin. Jendela yang akan muncul untuk membuat model akan dianalisis, karena di dalamnya semua keajaiban terjadi.
Pilih sebuah skenario
Pilih "skrip" aplikasi Anda. Saat ini, 5 sudah tersedia (tutorialnya agak ketinggalan jaman, ada 4 sejauh ini):
- Analisis sentimen - analisis nada suara, klasifikasi biner (klasifikasi biner), teks menentukan warna emosionalnya, positif atau negatif.
- Klasifikasi masalah - klasifikasi multi-kelas, label target untuk masalah (tiket, kesalahan, panggilan dukungan, dll.) Dapat dipilih sebagai salah satu dari tiga opsi yang saling eksklusif
- Prediksi harga - regresi, masalah regresi klasik ketika output adalah angka kontinu; Dalam contoh, ini adalah perkiraan apartemen
- Klasifikasi gambar - klasifikasi multikelas, tetapi sudah untuk gambar
- Skenario khusus - skenario Anda; Saya terpaksa bersedih karena tidak ada yang baru dalam opsi ini, hanya pada tahap selanjutnya mereka akan membiarkan saya memilih satu dari empat opsi yang dijelaskan di atas.
Perhatikan bahwa tidak ada klasifikasi multilabel ketika metode target bisa banyak pada saat yang sama (misalnya, pernyataan bisa menyinggung, rasis dan cabul pada saat yang sama, dan mungkin tidak semua ini). Untuk gambar, tidak ada opsi untuk memilih tugas segmentasi. Saya kira dengan bantuan kerangka kerja mereka pada umumnya dapat dipecahkan, namun hari ini kita fokus pada pembangun. Tampaknya penskalaan wizard untuk memperluas jumlah tugas bukanlah tugas yang sulit, jadi Anda harus mengharapkannya di masa mendatang.
Unduh dan tambahkan data
Diusulkan untuk mengunduh dataset. Dari keharusan mengunduh ke mesin Anda, kami secara otomatis menyimpulkan bahwa pelatihan akan berlangsung di mesin lokal kami. Ini memiliki dua kelebihan:
- Anda mengontrol semua data, Anda dapat memperbaiki, mengubah secara lokal, dan mengulangi percobaan.
- Anda tidak mengunggah data ke cloud, sehingga menjaga privasi. Toh, jangan unggah, ya Microsoft ? :)
dan kontra:
- Kecepatan belajar dibatasi oleh sumber daya mesin lokal Anda.
Lebih lanjut diusulkan untuk memilih dataset yang diunduh sebagai input dari tipe "File". Ada juga opsi untuk menggunakan "SQL Server" - Anda harus menentukan rincian server yang diperlukan, lalu pilih tabel. Jika saya mengerti dengan benar, skrip tertentu belum dapat ditentukan. Di bawah ini saya menulis tentang masalah yang saya miliki dengan opsi ini.
Latih model Anda
Pada langkah ini, berbagai model dilatih secara berurutan, kecepatan ditampilkan untuk masing-masing, dan pada akhirnya yang terbaik dipilih. Oh ya, saya lupa menyebutkan bahwa ini adalah AutoML - mis. algoritma dan parameter terbaik (tidak yakin, lihat di bawah) akan dipilih secara otomatis, jadi Anda tidak perlu melakukan apa pun! Diusulkan untuk membatasi waktu pelatihan maksimum hingga beberapa detik. Heuristik untuk definisi saat ini: https://github.com/dotnet/machinelearning-samples/blob/master/modelbuilder/readme.md#train . Di komputer saya, dalam 10 detik default, hanya satu model yang belajar, jadi saya harus bertaruh lebih banyak. Kami mulai, kami menunggu.
Di sini saya benar-benar ingin menambahkan bahwa nama-nama model secara pribadi tampak sedikit tidak biasa bagi saya, misalnya: AveragedPerceptronBinary, FastTreeOva, SdcaMaximumEntropyMulti. Kata "Perceptron" tidak terlalu sering digunakan akhir-akhir ini, "Ova" mungkin satu-vs-semua, dan "FastTree" Saya merasa sulit untuk mengatakan apa.
Fakta menarik lainnya adalah bahwa LightGbmMulti adalah salah satu kandidat algoritma. Jika saya memahaminya dengan benar, ini adalah LightGBM yang sama, mesin peningkat gradien yang, bersama-sama dengan CatBoost, sekarang bersaing dengan aturan XGBoost yang sendirian. Dia sedikit frustrasi dengan kecepatannya dalam kinerja saat ini - pada data saya, pelatihannya menghabiskan waktu paling banyak (sekitar 180 detik). Meskipun inputnya berupa teks, setelah memvariasikan ribuan kolom lebih banyak daripada contoh input, ini bukan kasus terbaik untuk meningkatkan dan menanamkan pohon secara umum.
Evaluasi model Anda
Sebenarnya, penilaian terhadap hasil model. Pada langkah ini, Anda dapat melihat metrik target apa yang telah dicapai, serta mengarahkan model secara langsung. Tentang metrik sendiri dapat dibaca di sini: MS dan sklearn .
Saya terutama tertarik pada pertanyaan - apa yang diuji? Pencarian di halaman bantuan yang sama memberikan jawaban - partisi ini sangat konservatif, 80% hingga 20%. Saya tidak menemukan kemampuan untuk mengkonfigurasi ini di UI. Dalam praktiknya, saya ingin mengontrol ini, karena ketika benar-benar ada banyak data, partisi bisa mencapai 99% dan 1% (menurut Andrew Ng, saya sendiri tidak bekerja dengan data seperti itu). Ini juga akan berguna untuk dapat mengatur pengambilan sampel data benih acak, karena pengulangan selama konstruksi dan pemilihan model terbaik sulit ditaksir terlalu tinggi. Tampaknya menambahkan opsi-opsi ini tidak sulit, untuk mempertahankan transparansi dan kesederhanaan, Anda dapat menyembunyikannya di belakang beberapa kotak centang opsi tambahan.
Dalam proses membangun model, tablet dengan indikator kecepatan ditampilkan pada konsol, kode generasi yang dapat ditemukan di proyek-proyek dari langkah berikutnya. Kita dapat menyimpulkan bahwa kode yang dihasilkan benar-benar berfungsi, dan output jujurnya adalah output, bukan palsu.
Pengamatan yang menarik - saat menulis artikel, saya sekali lagi berjalan langkah-langkah pembangun, menggunakan dataset komentar yang diusulkan dari Wikipedia. Namun sebagai tugas saya memilih "Custom", lalu klasifikasi multiclass sebagai target (walaupun hanya ada dua kelas). Hasilnya, kecepatan berubah menjadi sekitar 10% lebih buruk (sekitar 73% berbanding 83%) daripada kecepatan tangkapan layar dengan klasifikasi biner. Bagi saya ini agak aneh, karena sistem bisa menebak bahwa hanya ada dua kelas. Pada prinsipnya, pengklasifikasi tipe satu-vs-semua (ala satu terhadap semua, ketika masalah klasifikasi multiklass direduksi menjadi solusi sekuensial dari masalah N-biner untuk masing-masing kelas N) juga harus menunjukkan kecepatan biner yang serupa dalam situasi ini.
Buat kode
Pada langkah ini, dua proyek akan dihasilkan dan ditambahkan ke solusi. Salah satu dari mereka memiliki contoh lengkap tentang penggunaan model, dan yang lainnya harus dilihat hanya jika detail implementasi menarik.
Bagi saya sendiri, saya menemukan bahwa seluruh proses pembelajaran secara ringkas dibentuk menjadi sebuah saluran pipa (halo ke saluran pipa dari sk-learn):
// Data process configuration with pipeline data transformations var processPipeline = mlContext.Transforms.Conversion.MapValueToKey("Sentiment", "Sentiment") .Append(mlContext.Transforms.Text.FeaturizeText("SentimentText_tf", "SentimentText")) .Append(mlContext.Transforms.CopyColumns("Features", "SentimentText_tf")) .Append(mlContext.Transforms.NormalizeMinMax("Features", "Features")) .AppendCacheCheckpoint(mlContext);
(sedikit menyentuh format kode agar pas dengan baik)
Ingat, saya berbicara tentang parameter? Saya tidak melihat parameter khusus, semua nilai default. Ngomong-ngomong, dengan menggunakan label SentimentText_tf pada output dari FeaturizeText kita dapat menyimpulkan bahwa ini adalah frekuensi istilah (dokumentasi mengatakan bahwa ini adalah n-gram dan char-gram teks; Saya ingin tahu apakah ada IDF, frekuensi dokumen terbalik).
Konsumsilah model Anda
Sebenarnya, contoh penggunaan. Saya hanya dapat mencatat bahwa Prediksi dilakukan secara elemen.
Yah, itu saja, sebenarnya - kami memeriksa semua langkah pembangun dan mencatat poin-poin penting. Tetapi artikel ini akan menjadi tidak lengkap tanpa tes pada data sendiri, karena siapa pun yang pernah mengalami ML dan AutoML tahu betul bahwa mesin apa pun baik pada tugas standar, tes sintetik dan kumpulan data dari Internet. Oleh karena itu, diputuskan untuk memeriksa pembangun pada tugas mereka; selanjutnya selalu berfungsi dengan teks atau teks + fitur kategorikal.
Bukan kebetulan bahwa saya memiliki dataset dengan beberapa kesalahan / masalah / cacat terdaftar pada salah satu proyek. Ini memiliki 2949 baris, 8 kelas target tidak seimbang, 4mb.
ML.NET (memuat, konversi, algoritma dari daftar di bawah; butuh 219 detik)
| Top 2 models explored | -------------------------------------------------------------------------------- | Trainer MicroAccuracy MacroAccuracy Duration #Iteration| |1 SdcaMaximumEntropyMulti 0,7475 0,5426 176,7 1| |2 AveragedPerceptronOva 0,7128 0,4492 42,4 2| --------------------------------------------------------------------------------
(rongga menyengat di piring agar pas di Markdown)
Versi Python saya (memuat, membersihkan , mengonversi, lalu LinearSVC; butuh 41 detik):
Classsification report: precision recall f1-score support Class 1 0.71 0.61 0.66 33 Class 2 0.50 0.60 0.55 5 Class 3 0.65 0.58 0.61 59 Class 4 0.75 0.60 0.67 5 Class 5 0.78 0.86 0.81 77 Class 6 0.75 0.46 0.57 13 Class 7 0.82 0.90 0.86 227 Class 8 0.86 0.79 0.82 169 accuracy 0.80 588 macro avg 0.73 0.67 0.69 588 weighted avg 0.80 0.80 0.80 588
0,80 vs 0,747 Mikro dan 0,73 vs 0,542 Makro (mungkin ada beberapa ketidakakuratan dalam definisi Makro, jika menarik, saya akan memberi tahu Anda dalam komentar).
Saya terkejut, hanya 5% perbedaannya. Pada beberapa dataset lain, perbedaannya bahkan lebih kecil, dan kadang-kadang tidak sama sekali. Ketika menganalisis besarnya perbedaan, ada baiknya memperhitungkan fakta bahwa jumlah sampel dalam dataset kecil, dan kadang-kadang, setelah unggahan berikutnya (ada sesuatu yang dihapus, ada yang ditambahkan), saya mengamati pergerakan kecepatan 2-5 persen.
Saat saya bereksperimen sendiri, tidak ada masalah menggunakan pembangun. Namun, selama presentasi, rekan-rekan masih bertemu beberapa tiang tembok:
- Kami mencoba memuat salah satu dataset secara jujur dari tabel ke dalam database, tetapi menemukan pesan kesalahan yang tidak informatif. Saya memiliki gambaran kasar tentang jenis data teks rencana apa yang ada, dan segera menemukan bahwa masalahnya bisa sejalan. Yah, saya mengunduh dataset menggunakan pandas.read_csv , membersihkannya dari \ n \ r \ t, menyimpannya di tsv, dan melanjutkan.
- Selama pelatihan model selanjutnya, mereka menerima pengecualian yang melaporkan bahwa ukuran matriks ~ 220.000 per 1000 tidak dapat dengan nyaman masuk dalam memori, sehingga pelatihan dihentikan. Pada saat yang sama, model juga tidak dihasilkan. Apa yang harus dilakukan selanjutnya tidak jelas, kami keluar dari situasi dengan mengganti batas waktu belajar "dengan mata" - sehingga algoritma yang jatuh tidak punya waktu untuk mulai bekerja.
Omong-omong, dari paragraf kedua kita dapat menyimpulkan bahwa jumlah kata dan n-gram selama vektorisasi tidak benar-benar dibatasi oleh batas atas, dan "n" mungkin sama dengan dua. Saya dapat mengatakan dari pengalaman saya sendiri bahwa 200k jelas terlalu banyak. Biasanya itu terbatas pada kejadian yang paling sering, atau diterapkan pada berbagai jenis algoritma reduksi dimensi, misalnya, SVD atau PCA.
Kesimpulan
Pembangun menawarkan pilihan beberapa skenario di mana saya tidak menemukan tempat-tempat kritis yang membutuhkan perendaman di ML. Dari sudut pandang ini, sangat cocok sebagai alat "memulai" atau memecahkan masalah sederhana yang khas di sini dan sekarang. Kasus penggunaan yang sebenarnya sepenuhnya terserah pada imajinasi Anda. Anda dapat memilih opsi yang ditawarkan oleh MS:
- untuk memecahkan masalah penilaian sentimen (analisis sentimen), misalnya, dalam komentar pada produk di situs
- mengklasifikasikan tiket berdasarkan kategori atau tim (klasifikasi masalah)
- terus mengejek tiket, tetapi dengan bantuan prediksi harga - perkirakan biaya waktu
Dan Anda dapat menambahkan sesuatu sendiri, misalnya, untuk mengotomatiskan tugas mendistribusikan kesalahan / insiden yang masuk di antara pengembang, menguranginya menjadi tugas klasifikasi menurut teks (label target adalah ID / Nama keluarga pengembang). Atau Anda dapat menyenangkan operator workstation internal yang mengisi bidang dalam kartu dengan seperangkat nilai tetap (daftar drop-down) untuk bidang lain atau deskripsi teks. Untuk melakukan ini, Anda hanya perlu menyiapkan pilihan dalam csv (bahkan beberapa ratus baris sudah cukup untuk percobaan), ajarkan model langsung dari UI Visual Studio dan terapkan dalam proyek Anda dengan menyalin kode dari contoh yang dihasilkan. Saya mengarah pada fakta bahwa ML.NET menurut saya cukup cocok untuk menyelesaikan tugas-tugas praktis, pragmatis, duniawi yang tidak memerlukan keterampilan khusus dan menghabiskan waktu dengan sia-sia. Selain itu, dapat diterapkan dalam proyek paling biasa, yang tidak mengklaim sebagai inovatif. Setiap pengembang .NET yang siap untuk menguasai perpustakaan baru dapat menjadi penulis model seperti itu.
Saya memiliki latar belakang ML sedikit lebih dari rata-rata. Pengembang NET, jadi saya memutuskan untuk diri saya sendiri: untuk gambar, mungkin tidak, untuk kasus-kasus yang kompleks, tetapi untuk tugas-tugas tabel sederhana, pasti ya. Saat ini, lebih mudah bagi saya untuk melakukan tugas ML pada tumpukan teknologi Python / numpy / pandas / sk-learn / keras / pytorch yang lebih akrab, namun saya akan melakukan kasus tipikal untuk kemudian menanamkan dalam aplikasi .NET menggunakan ML.NET .
Ngomong-ngomong, senang bahwa kerangka teks berfungsi sempurna tanpa gerakan yang tidak perlu dan perlunya penyetelan oleh pengguna. Secara umum, ini tidak mengejutkan, karena dalam praktiknya, pada sejumlah kecil data, TfIDF lama yang baik dengan pengklasifikasi seperti SVC / NaiveBayes / LR bekerja dengan sangat baik. Ini dibahas pada DataFest musim panas dalam laporan dari iPavlov - pada beberapa test suite word2vec, GloVe, ELMo (semacam) dan BERT dibandingkan dengan TfIdf. Pada tes tersebut, dimungkinkan untuk mencapai keunggulan beberapa persen hanya dalam satu kasus dari 7-10 kasus, meskipun jumlah sumber daya yang dihabiskan untuk pelatihan sama sekali tidak sebanding.
PS Mempopulerkan ML di kalangan massa kini sedang tren, bahkan mengambil " alat Google untuk membuat AI, yang bahkan bisa digunakan oleh anak sekolah ." Semuanya lucu dan intuitif bagi pengguna, tetapi apa yang sebenarnya terjadi di balik layar di awan tidak jelas. Dalam hal ini, untuk pengembang .NET, ML.NET dengan pembuat model terlihat seperti opsi yang lebih menarik.
Presentasi PSS berjalan dengan keras, rekan kerja termotivasi untuk mencoba :)
Umpan balik
Omong-omong, salah satu buletin dengan tajuk "ML.NET Model Builder" mengatakan:
Berikan Tanggapan Anda
Jika Anda mengalami masalah, merasa ada sesuatu yang hilang, atau sangat menyukai sesuatu tentang ML.NET Model Builder, beri tahu kami dengan membuat masalah dalam repo GitHub kami.
Model Builder masih dalam Pratinjau, dan umpan balik Anda sangat penting dalam mengarahkan arah yang kami ambil dengan alat ini!
Artikel ini dapat dianggap sebagai umpan balik!
Referensi
Di ML.NET
Untuk artikel yang lebih lama dengan panduan