Kami selalu ingin menulis kode dengan cepat, tetapi Anda harus membayarnya. Dalam bahasa fleksibel tingkat tinggi biasa, program dapat dikembangkan dengan cepat, tetapi berjalan lambat setelah diluncurkan. Sebagai contoh, sangat lambat untuk membaca sesuatu yang berat dengan Python murni. Bahasa seperti C bekerja lebih cepat, tetapi lebih mudah untuk membuat kesalahan, pencarian yang akan mengurangi semua peningkatan kecepatan menjadi nol.
Biasanya dilema ini diselesaikan sebagai berikut: pertama mereka menulis prototipe pada sesuatu yang fleksibel, misalnya, pada Python atau R, dan kemudian menulis ulang pada C / C ++ atau Fortran. Tetapi siklus ini terlalu lama, dapatkah Anda melakukannya tanpa itu?

Mungkin ada solusinya. Julia adalah bahasa pemrograman tingkat tinggi dan fleksibel namun cepat. Julia memiliki banyak pengiriman, kompiler pintar terintegrasi dan alat metaprogramming.
Gleb Ivashkevich (
phtRaveller ), pendiri datarythmics, yang mengembangkan sistem pembelajaran mesin untuk industri dan industri lain, mantan fisikawan, akan memberi tahu Anda lebih banyak tentang apa yang dimiliki Julia.
Gleb akan menjelaskan mengapa bahasa baru diperlukan dan mengapa terkadang Python tidak ada. Dia akan memberi tahu Anda apa yang menarik di Julia, tentang kekuatan dan kelemahannya, bandingkan dengan bahasa lain, dan tunjukkan apa yang bahasa tersebut memiliki prospek pembelajaran mesin dan komputasi secara umum.
Penafian. Tidak akan ada parsing sintaksis. Habrazhiteli mengalami pengembang, jadi tidak masuk akal untuk menunjukkan cara menulis loop, misalnya.Masalah dua bahasa
Jika Anda menulis kode dengan cepat, program berjalan lambat. Jika program bekerja dengan cepat, tulislah untuk waktu yang lama.
Python klasik termasuk dalam kategori pertama. Jika Anda menghapus NumPy, pertimbangkan sesuatu dengan Python murni perlahan. Di sisi lain, ada bahasa seperti C dan C ++. Sulit untuk menemukan keseimbangan, jadi paling sering mereka pertama kali menulis prototipe pada sesuatu yang fleksibel, dan setelah debugging algoritma, mereka menulis ulang ke bahasa lebih cepat. Ini adalah contoh
masalah yang jelas dalam dua bahasa : siklus panjang ketika Anda harus menulis dengan Python, dan menulis ulang dalam C atau dalam Cython, misalnya.
Spesialis dalam pembelajaran mesin dan Ilmu Data memiliki NumPy, Sklearn, TensorFlow. Mereka telah memecahkan masalah mereka selama bertahun-tahun tanpa satu baris dalam C, dan tampaknya masalah kedua bahasa tidak menjadi masalah mereka. Ini tidak begitu, masalah memanifestasikan dirinya
secara implisit , karena kode di NumPy atau di TensorFlow sebenarnya tidak benar-benar Python. Ini digunakan sebagai bahasa logam untuk meluncurkan apa yang ada di dalamnya. Di dalamnya persis C / Fortran (dalam kasus NumPy) atau C ++ (dalam kasus TensorFlow).
"Fitur" ini kurang terlihat, misalnya, di PyTorch, tetapi di Numpy itu terlihat jelas. Misalnya, jika siklus Python klasik
for muncul dalam perhitungan, maka ada yang salah. Dalam kode produktif, loop tidak diperlukan, Anda harus menulis ulang semuanya sehingga NumPy dapat membuat vektor dan menghitungnya dengan cepat.
Pada saat yang sama, tampaknya banyak yang NumPy cepat dan semuanya baik-baik saja dengan itu. Mari kita lihat apa yang dimiliki NumPy di bawah tenda untuk melihat ini.
- NumPy sedang mencoba untuk memperbaiki masalah fleksibilitas jenis Python, sehingga memiliki sistem tipe yang cukup ketat . Jika array memiliki tipe tertentu, maka tidak ada yang lain di dalamnya, jika
Float64 , tidak ada yang dapat dilakukan tentang hal itu. - Pengiriman. Bergantung pada jenis array dan operasi apa yang perlu Anda lakukan, NumPy di dalam dirinya sendiri akan memutuskan fungsi mana yang harus dihubungi untuk membuat perhitungan secepat mungkin. Perpustakaan akan mencoba membuang Python klasik keluar dari loop perhitungan.
Ternyata Numpy tidak secepat yang terlihat. Itu sebabnya ada proyek seperti
Cython atau
Numba . Yang pertama menghasilkan kode-C dari "hibrida" dari Python dan C, dan yang kedua mengkompilasi kode dalam Python dan biasanya ini lebih cepat.
Jika NumPy benar-benar secepat tampaknya bagi banyak orang, maka keberadaan Cython dan Numba tidak masuk akal.
Kami menulis ulang semua yang ada di Cython jika kami ingin cepat menemukan sesuatu yang besar dan kompleks. Salah satu kriteria untuk kualitas pembungkus dalam Cython adalah ada atau tidak adanya panggilan Python murni dalam kode yang dihasilkan.
Contoh sederhana: kami menambahkan jenis (baik) atau tidak menambahkan (buruk), dan kami mendapatkan dua kode yang sama sekali berbeda, meskipun selain jenis opsi awal tidak berbeda.

Ketika kita menghasilkan kode C, dalam kasus pertama kita mendapatkan yang berikut:
__pyx_t_4 = __pyx_v_i; __pyx_v_result = (__pyx_v_result + (*((double *) ( (__pyx_v_a.data + __pyx_t_4 * __pyx_v_a.strides[0]) ))));
Dan pada
result =0. kedua
result =0. akan berubah menjadi ini:
__pyx_t_6 = PyFloat_FromDouble((*((double *) ( (__pyx_v_a.data + __pyx_t_4 * __pyx_v_a.strides[0]) )))); if (unlikely(!__pyx_t_6)) __PYX_ERR(0, 9, __pyx_L1_error) __Pyx_GOTREF(__pyx_t_6); __pyx_t_7 = PyNumber_InPlaceAdd(__pyx_v_result, __pyx_t_6); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 9, __pyx_L1_error) __Pyx_GOTREF(__pyx_t_7); __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0; __Pyx_DECREF_SET(__pyx_v_result, __pyx_t_7); __pyx_t_7 = 0;
Ketika suatu jenis ditentukan, kode C berjalan cepat. Jika jenisnya tidak ditentukan, kita melihat Python normal, tetapi dari sisi C: panggilan Python standar, di mana karena beberapa alasan
float dibuat dari
double , tautan dihitung, dan banyak kode sampah lainnya. Kode ini lambat karena memanggil Python untuk setiap operasi.
Apakah mungkin menyelesaikan semua masalah sekaligus
Lucu ketika kita memikirkan sesuatu, kita mencoba untuk menghapus Python murni. Ada dua opsi untuk bagaimana melakukan ini.
- Menggunakan Cython atau alat lain. Ada banyak cara Anda dapat mengoptimalkan kode Cython Anda agar tidak ada panggilan Python. Tapi ini bukan kegiatan yang paling menyenangkan: tidak semuanya begitu jelas di Cython, dan hanya sedikit waktu yang dihabiskan daripada jika Anda hanya menulis semuanya dalam C. Modul yang dihasilkan dapat digunakan dalam Python, tetapi masih membutuhkan waktu yang lama, kesalahan terjadi, kode tidak selalu jelas dan tidak selalu jelas cara mengoptimalkannya.
- Menggunakan Numba, yang melakukan kompilasi JIT .
Tapi mungkin ada cara yang lebih baik, dan saya pikir ini
Julia .
Julia
Pembuat menyatakan bahwa ini adalah bahasa
cepat ,
tingkat tinggi dan
fleksibel , yang sebanding dengan Python dalam hal kemudahan menulis kode. Menurut saya, Julia seperti
bahasa scripting: Anda tidak perlu melakukan apa yang harus Anda lakukan di C, di mana semuanya sangat tingkat rendah, termasuk struktur data. Pada saat yang sama, Anda dapat bekerja di konsol biasa, seperti dengan Python dan bahasa lainnya.
Julia menggunakan
kompilasi Just-In-Time - ini adalah salah satu elemen yang memberikan kecepatan. Tapi bahasanya bagus dengan perhitungan, karena dikembangkan untuk mereka. Julia digunakan untuk tugas-tugas ilmiah dan mendapatkan kinerja yang layak.
Meskipun Julia berusaha terlihat seperti bahasa tujuan umum, Julia bagus untuk komputasi dan tidak terlalu bagus untuk layanan web. Menggunakan Julia sebagai ganti Django, misalnya, bukanlah pilihan terbaik.
Mari kita lihat fitur-fitur bahasa sebagai contoh fungsi primitif.
function f(x) α = 1 + 2x end julia> methods(f)
Empat fitur terlihat dalam kode ini.
- Praktis tidak ada batasan dalam menggunakan Unicode . Anda dapat mengambil rumus dari artikel tentang pembelajaran mendalam atau pemodelan numerik, menulis ulang dengan karakter yang sama, dan semuanya akan berfungsi - Unicode dijahit hampir di mana-mana.
- Tidak ada tanda multiplikasi. Namun, tidak selalu mungkin dilakukan tanpa itu, misalnya, dengan 2.x (angka floating-point kali x) Julia akan bersumpah.
- Tidak
return Secara umum, Anda disarankan untuk menulis return sehingga Anda dapat melihat apa yang terjadi, tetapi contohnya akan kembali α , karena tugas adalah ekspresi. - Tanpa tipe . Tampaknya jika ada kecepatan, maka di beberapa titik jenis akan muncul? Ya, mereka akan muncul, tetapi nanti.
Julia memiliki tiga fitur yang memberikan fleksibilitas dan kecepatan:
multi-dispatching, metaprogramming, dan parallelism . Kami akan berbicara tentang dua yang pertama, dan meninggalkan paralelisasi untuk studi independen untuk pengguna tingkat lanjut.
Penjadwalan berganda
Panggilan ke
methods(f) dalam contoh di atas terlihat secara tidak terduga - metode apa yang dimiliki fungsi? Kita terbiasa dengan fakta bahwa kita memiliki objek kelas, kelas memiliki metode. Tetapi di Julia semuanya terbalik: fungsi memiliki metode, karena bahasa menggunakan banyak pengiriman.
Penjadwalan berganda berarti bahwa varian fungsi tertentu yang akan dieksekusi ditentukan oleh seluruh rangkaian tipe parameter dari fungsi ini.
Saya akan menjelaskan secara singkat bagaimana ini bekerja pada contoh yang sudah akrab.
function f(x) α = 1 + 2x end function f(x::AbstractFloat) α = 1 + sin(x) end julia> methods(f)
Varian dengan fungsi yang sama untuk set tipe yang berbeda disebut metode. Ada dua dalam kode: yang pertama untuk semua angka floating-point, dan yang kedua untuk yang lainnya. Saat pertama kali memanggil fungsi, Julia akan memutuskan metode mana yang akan digunakan dan apakah akan mengompilasinya. Jika sudah dipanggil dan dikompilasi, itu akan mengambil salah satunya.
Karena di Julia semuanya tidak seperti biasanya, di sini Anda dapat menambahkan fungsi ke tipe yang ditentukan pengguna, tetapi ini tidak akan menjadi metode tipe dalam arti OOP. Ini hanya akan menjadi bidang di mana fungsi ditulis, karena
fungsi adalah objek penuh yang sama dengan yang lainnya.
Untuk mengetahui apa yang sebenarnya akan dipicu, ada makro khusus. Mereka mulai dengan
@ . Dalam contoh ini, makro yang memungkinkan
@which mengetahui metode mana yang dipanggil untuk kasus tertentu.

Dalam kasus pertama, Julia memutuskan bahwa karena 2 adalah bilangan bulat, itu tidak cocok dengan
AbstractFloat , dan disebut opsi pertama. Dalam kasus kedua, dia memutuskan bahwa itu adalah
Float dan sudah menyerukan versi khusus. Kira-kira ini akan berfungsi jika Anda menambahkan metode lain untuk beberapa jenis tertentu.
LLVM dan JIT
Julia menggunakan kerangka kerja LLVM untuk dikompilasi. Perpustakaan kompilasi JIT datang dalam paket bahasa. Pertama kali fungsi dipanggil, Julia melihat apakah fungsi tersebut telah digunakan dengan set tipe ini, dan mengkompilasinya jika perlu. Peluncuran pertama akan memakan waktu, dan kemudian semuanya akan bekerja dengan cepat.
Fungsi akan dikompilasi pada saat panggilan pertama untuk set parameter ini.
Fitur Kompiler
- Kompiler ini cukup masuk akal karena LLVM adalah produk yang bagus.
- Kebanyakan pengembang tingkat lanjut dapat melihat proses kompilasi dan melihat apa yang dihasilkannya.
- Kompilasi Julia dan Numba serupa . Di Numba, Anda juga membuat dekorator JIT, tetapi di Numba Anda tidak bisa "masuk" begitu banyak dan memutuskan apa yang harus dioptimalkan atau diubah.
Untuk mengilustrasikan pekerjaan kompiler, saya akan memberikan contoh fungsi sederhana:
function f(x) α = 1 + 3x end julia> @code_llvm f(2) define i64 @julia_f_35897(i64) { top: %1 = mul i64 %0, 3 %2 = add i64 %1, 1 ret i64 %2 }
Makro
@code_llvm memungkinkan Anda melihat hasil pembuatan.
LLVM IR ini adalah
representasi perantara , semacam assembler.
Dalam kode, argumen fungsi dikalikan dengan 3, 1 ditambahkan ke hasilnya, hasilnya dikembalikan. Segalanya semudah mungkin. Jika Anda mendefinisikan fungsi sedikit berbeda, misalnya, ganti 3 dengan 2, maka semuanya akan berubah.
function f(x) α = 1 + 2x end julia> @code_llvm f(2) define i64 @julia_f_35894(i64) { top: %1 = shl i64 %0, 1 %2 = or i64 %1, 1 ret i64 %2 }
Tampaknya, apa bedanya: 2, 3, 10? Tetapi Julia dan LLVM melihat bahwa ketika Anda memanggil fungsi untuk integer, Anda bisa melakukan sedikit lebih pintar. Mengalikan dengan dua bilangan bulat adalah pergeseran kiri dengan satu bit - lebih cepat dari produk. Tapi, tentu saja, ini hanya berfungsi untuk bilangan bulat, itu tidak akan berhasil menggeser
Float kiri sebanyak 1 bit dan mendapatkan hasil dari mengalikan dengan 2.
Jenis khusus
Jenis khusus di Julia secepat jenis bawaan. Penjadwalan multipel dilakukan pada mereka, dan itu akan secepat untuk tipe bawaan. Dalam hal ini, mekanisme pengiriman banyak tertanam dalam bahasa.
Adalah logis untuk mengharapkan bahwa variabel tidak memiliki tipe, hanya nilai yang memilikinya. Variabel tanpa tipe hanyalah marker, label pada beberapa wadah.
Sistem tipe bersifat hierarkis. Kita tidak dapat membuat turunan dari tipe beton, tipe abstrak hanya dapat memilikinya. Namun, tipe abstrak tidak bisa dipakai. Nuansa ini tidak akan menarik bagi semua orang.
Seperti yang dijelaskan oleh penulis bahasa ketika mereka mengembangkan Julia, mereka ingin mendapatkan hasilnya, dan jika ada sesuatu yang sulit dilakukan, mereka menolaknya. Sistem tipe hierarkis seperti itu lebih mudah untuk dikembangkan. Ini bukan masalah katastropik, tetapi jika Anda tidak memalingkan kepala terlebih dahulu, itu akan merepotkan.
Jenis dapat diparameterisasi , yang agak mirip C / C ++. Sebagai contoh, kita mungkin memiliki struktur di mana ada bidang, tetapi jenis bidang ini tidak ditentukan - ini adalah parameter. Kami menentukan jenis tertentu di instantiation.
Dalam kebanyakan kasus, jenis dapat dilewati . Biasanya mereka diperlukan ketika tipe membantu kompiler untuk menebak cara terbaik untuk mengkompilasi. Dalam hal ini, jenisnya lebih baik untuk ditentukan. Anda juga perlu menentukan jenis jika Anda ingin mencapai kinerja yang lebih baik.
Mari kita lihat apa yang mungkin dan apa yang tidak bisa dipakai.

Tipe pertama
AbstractPoint tidak dapat dipakaikan. Sebagai contoh, ini hanyalah induk dari semua orang yang dapat kita tentukan dalam metode. Baris kedua mengatakan bahwa
PlanarPoint{T} adalah turunan dari titik abstrak ini. Di bawah bidang dimulai - di sini Anda dapat melihat parameterisasi. Anda dapat meletakkan
float ,
int atau jenis lainnya di sini.
Jenis pertama tidak dapat dipakai, dan untuk semua yang lain tidak mungkin untuk membuat keturunan. Selain itu, secara default mereka tidak
berubah . Agar dapat mengubah bidang, ini harus ditentukan secara eksplisit.
Ketika semuanya sudah siap, Anda dapat melanjutkan, misalnya, menghitung jarak untuk berbagai jenis titik. Dalam contoh tersebut, titik pertama pada pesawat adalah
PlanarPoint , lalu pada bola dan pada silinder. Bergantung pada dua titik yang kita hitung jaraknya, kita perlu menggunakan metode yang berbeda. Secara umum, fungsinya akan terlihat seperti ini:
function describe(p::AbstractPoint) println("Point instance: $p") end
Untuk
Float64 ,
Float32 ,
Float16 akan menjadi:
function distance(pf::PlanarPoint{T}, ps::PlanarPoint{T}) where T<:AbstractFloat sqrt((pf.x-ps.x)^2 + (pf.y-ps.y)^2) end
Dan untuk bilangan bulat, metode perhitungan jarak akan terlihat seperti ini:
function distance(pf::PlanarPoint{T}, ps::PlanarPoint{T}) where T<:Integer abs(pf.x-ps.x) + abs(pf.y-ps.y) end
Untuk poin dari setiap jenis, metode yang berbeda akan dipanggil.
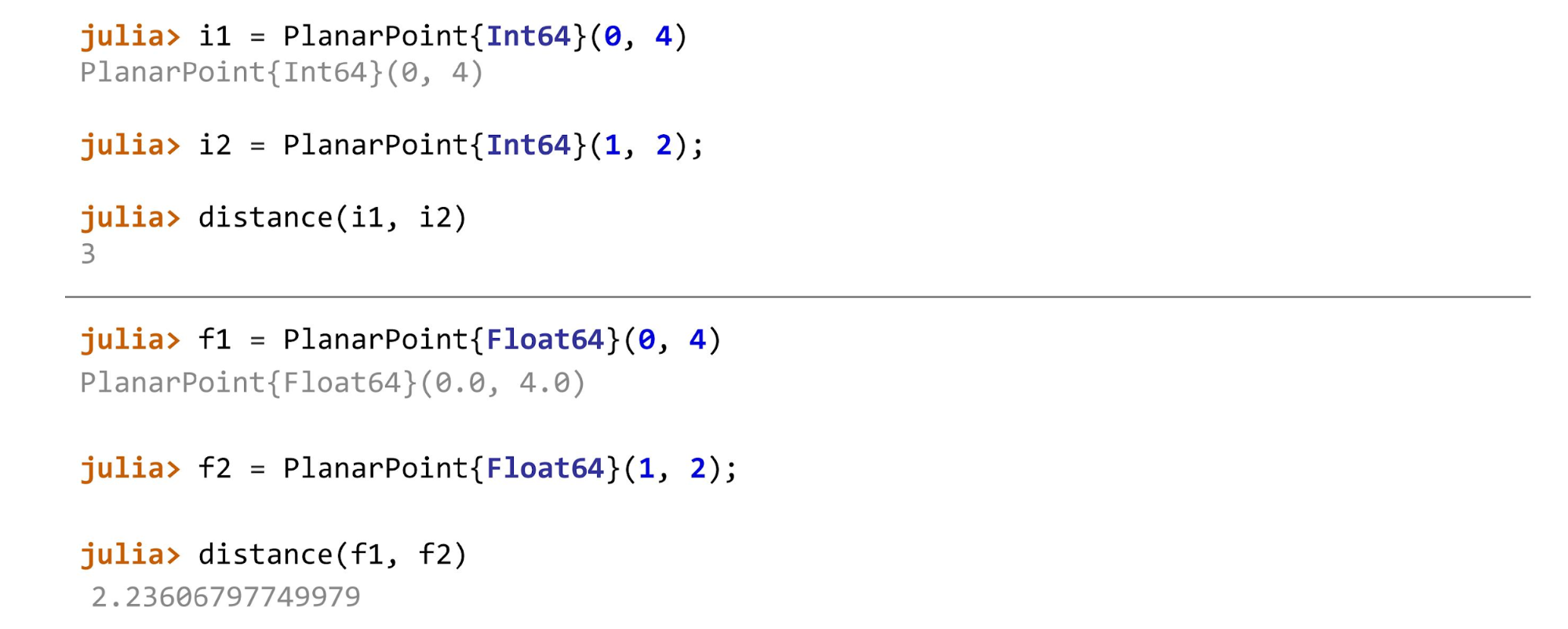
Jika Anda curang dan, misalnya, menerapkan
distance(f1, i2) , Julia akan bersumpah: “Saya tidak tahu metode ini! Anda bertanya kepada saya metode semacam itu, dan mengatakan bahwa keduanya memiliki tipe yang sama. Anda tidak memberi tahu saya cara menghitung ini ketika satu parameter
float dan yang lainnya adalah
int . "
Kecepatan
Anda mungkin sudah senang: “Ada kompilasi JIT: menulis itu mudah, itu akan bekerja dengan cepat. Buang Python dan mulai menulis dalam Julia! "
Tapi tidak sesederhana itu. Tidak semua fitur di Julia akan cepat. Itu tergantung pada dua faktor.
- Dari pengembang . Tidak ada bahasa di mana fungsi apa pun akan cepat. Pengembang yang tidak berpengalaman bahkan akan menulis kode dalam C yang akan bekerja jauh lebih lambat daripada kode Python dari pengembang yang berpengalaman. Bahasa apa pun memiliki trik dan nuansa tersendiri yang bergantung pada kinerja. Kompiler, apakah itu statis biasa atau JIT, tidak dapat memberikan semua opsi yang mungkin dan mengoptimalkan semuanya.
- Dari stabilitas jenis . Dalam versi yang lebih cepat, fungsi yang stabil berdasarkan jenis akan dikompilasi.
Ketik stabilitas
Apa itu stabilitas tipe? Ketika kompiler tidak dapat dengan cukup andal menebak apa yang terjadi dengan tipe-tipe itu, ia harus menghasilkan banyak kode wrapper sehingga segala sesuatu yang masuk ke input bekerja.
Contoh sederhana untuk memahami stabilitas tipe.

Spesialis pembelajaran mesin akan mengatakan bahwa ini adalah aktivasi relu yang normal: jika x> 0, kembalikan seperti apa adanya, jika tidak kembalikan nol. Satu masalah adalah nol setelah bilangan bulat tanda tanya. Ini berarti bahwa jika kita memanggil fungsi ini untuk angka titik-mengambang, maka dalam satu kasus, angka titik-mengambang akan dikembalikan, dan dalam kasus lain, bilangan bulat.
Kompiler tidak dapat menebak jenis hasil hanya dengan jenis argumen fungsi. Dia juga perlu tahu artinya. Karena itu, ia menghasilkan banyak kode.
Selanjutnya, kita membuat array 100 per 100 angka acak dari 0 ke 1, menggesernya 0,5 untuk mendistribusikan angka positif dan negatif secara merata, dan mengukur hasilnya. Ada dua poin menarik: titik dan fungsinya. Titik setelah
rand(100,100) berarti "berlaku untuk setiap elemen." Jika Anda memiliki semacam koleksi dan fungsi skalar, Anda mengakhiri itu, dan Julia akan melakukan sisanya. Kita dapat mengasumsikan bahwa ini sama efektifnya dengan loop normal dalam bahasa yang dikompilasi normal. Tidak perlu menulis - semuanya akan dilakukan untuk Anda.
Tidak ada masalah di titik -
masalahnya ada di dalam fungsi itu sendiri . Perkiraan waktu eksekusi dari opsi semacam itu pada komputer yang layak untuk matriks semacam itu adalah mikrodetik. Tetapi dalam kenyataannya - milidetik, yang terlalu banyak untuk matriks sekecil itu.
Ubah hanya satu baris.

Fungsi
zero(x) dijalankan menghasilkan nol dengan tipe yang sama dengan argumen
(x) . Ini berarti bahwa tidak peduli berapa nilai
x , tipe hasil akan selalu diketahui oleh tipe
x itu sendiri.
Ketika kita melihat hanya pada tipe argumen dan sudah tahu tipe hasil, ini adalah fungsi yang tipe stabil.
Jika kita perlu melihat makna argumen, ini bukan fungsi yang stabil.
Ketika kompiler dapat mengoptimalkan kode, perbedaan waktu eksekusi diperoleh oleh dua urutan besarnya. Dalam contoh kedua, hanya dialokasikan tepat untuk array baru, beberapa byte lebih banyak dan tidak lebih. Opsi ini jauh lebih efektif daripada yang sebelumnya.
Ini adalah hal utama yang harus diperhatikan ketika kita menulis kode dalam Julia. Jika Anda menulis seperti di Python, maka itu akan berfungsi seperti di Python. Jika Anda melakukan operasi yang sama pada NumPy, maka nol dengan atau tanpa titik tidak memainkan peran. Tetapi di Julia, ini bisa sangat merusak kinerja.
Untungnya, ada metode untuk mengetahui apakah ada masalah. Ini adalah makro
@code_warntype , yang memungkinkan Anda untuk mengetahui apakah kompiler dapat menebak di mana jenis berada dan mengoptimalkan jika semuanya baik-baik saja.

Pada opsi pertama (kiri), kompiler tidak yakin akan jenisnya dan menampilkannya dengan warna merah. Dalam kasus kedua, akan selalu ada
Float64 untuk argumen seperti itu, sehingga Anda dapat menghasilkan kode yang jauh lebih pendek.
Ini belum LLVM, tetapi kode Julia berlabel,
return 0 atau
return 0.0 memberikan perbedaan kinerja dua urutan besarnya.
Metaprogramming
Metaprogramming adalah ketika kita membuat program dalam suatu program dan menjalankannya saat bepergian.
Ini adalah metode yang ampuh yang memungkinkan Anda melakukan banyak hal menarik yang berbeda. Contoh klasik adalah Django ORM, yang membuat bidang menggunakan metaclasses.
Banyak orang mengetahui penafian dari
Tim Peters , penulis Zen of Python:
“Metaclasses adalah keajaiban yang lebih dalam yang tidak perlu dikhawatirkan oleh 99% pengguna. Jika Anda bertanya-tanya apakah metaclasses diperlukan dalam Python, Anda tidak membutuhkannya. Jika Anda membutuhkannya, maka Anda tahu persis mengapa dan bagaimana menggunakannya. ”
Dengan metaprogramming, situasinya mirip, tetapi di Julia dijahit lebih dalam, ini adalah fitur penting dari seluruh bahasa. Kode Julia adalah struktur data yang sama dengan yang lain, Anda dapat memanipulasi, menggabungkan, membuat ekspresi, dan semua ini akan berhasil.
julia> x = 4; julia> typeof(:(x+1)) Expr julia> expr = :(x+1) :(x + 1) julia> expr.head :call julia> expr.args 3-element Array{Any,1}: :+ :x 1
Makro adalah salah satu alat pemrograman di Julia : kami memberi mereka sesuatu, mereka melihat, menambahkan yang tepat, menghapus yang tidak perlu, dan memberikan hasilnya. Dalam semua contoh sebelumnya, kami meneruskan panggilan ke fungsi, dan makro di dalamnya mem-parsing panggilan. Semua ini terjadi pada tingkat bekerja dengan pohon sintaksis.
Anda dapat menguraikan ekspresi yang sangat sederhana: jika itu, misalnya,
(x+1) , maka ini adalah panggilan ke fungsi
+ (penambahan bukan operator, seperti dalam banyak bahasa lain, tetapi fungsi) dan dua argumen: satu karakter (titik dua berarti bahwa itu adalah karakter ), dan yang kedua hanya sebuah konstanta.
Contoh makro sederhana lainnya:
macro named(name, expr) println("Starting $name") return quote $(esc(expr)) end end julia> @named "some process" x=5; Starting some process julia> x 5
Menggunakan makro, misalnya, indikator kemajuan atau filter untuk bingkai data dibuat - ini adalah mekanisme umum di Julia.
Macro tidak dieksekusi pada saat panggilan, tetapi ketika menguraikan kode.
Ini adalah fitur makro utama di Julia. - , . , , .
,
Julia — . .
- Julia . .
- , . , , C .
- Julia JIT- . , , , , .
- — . .
- ( ). , . , , .
- Julia — .
Ekosistem
, , Julia . , , data science , , , Python. , Python Pandas, , , , Julia .
Julia , Python 2008 . Python, , Julia. , . , Julia.
( ) Python Julia
. Julia: , , .…
. .
- DataFrames.jl .
- JuliaDB , .
- Query.jl . Pandas — - , ..
Plotting .
Matplotlib , Julia. :
VegaLite.jl ,
Plots.jl , ,
Gadfly.jl .
.
TensorFlow , Flux.jl. Flux , , , Keras TensorFlow, . .
Scikit-learn . , , sklearn, , .
XGBoost . , Julia .
?
Jupyter . IDE — Juno, Visual Studio, .
. GPU/TPU . CUDAnative.jl Julia . Julia-, - , . , , , , .
: C, Fortran, Python .
, .
Packaging : Julia: , , ..
, , . , , . ,
PyTorch , TensorFlow, , .
, , , . Julia, , , . ,
,
Zygote.jl . Flux.jl.
julia> using Zygote julia> φ(x) = x*sin(x) julia> Zygote.gradient(φ, π/2.) (1.0,) julia> model = Chain(Dense(768, 128, relu), Dense(128, 10), softmax) julia> loss(x, y) = crossentropy(model(x), y) + sum(norm, params(model)) julia> optimizer = ADAM(0.001) julia> Flux.train!(loss, params(model), data, optimizer) julia> model = Chain(x -> sqrt(x), x->x-1)
φ , , , .
Zygote «source-to-source»: , , .
differentiable programming — — backpropagation , .
Julia : «source-to-source» , . , .
Julia ?
, — . .
- , , , — .
, , .
Julia , .
- , , . Julia «» .
- , API, , .
Moscow Python Conf++ , 27 , Python Julia. , , telegram- MoscowPython.