Kami telah mengembangkan desain jaringan pusat data, yang memungkinkan Anda untuk menyebarkan cluster komputasi yang lebih besar dari 100 ribu server dengan bandwidth dua bagian lebih dari satu petabit per detik.
Dari laporan Dmitry Afanasyev, Anda akan belajar tentang prinsip dasar desain baru, penskalaan topologi yang muncul dengan masalah ini, solusi bagi mereka, tentang fitur perutean dan penskalaan fungsi penerusan pesawat perangkat jaringan modern di topologi "terhubung padat" dengan sejumlah besar rute ECMP . Selain itu, Dima secara singkat berbicara tentang organisasi konektivitas eksternal, tingkat fisik, sistem kabel dan cara-cara untuk lebih meningkatkan kapasitas.

- Selamat sore, semuanya! Nama saya Dmitry Afanasyev, saya seorang arsitek jaringan Yandex dan saya terutama berurusan dengan desain jaringan pusat data.

Kisah saya adalah tentang jaringan pusat data Yandex yang diperbarui. Ini sebagian besar merupakan evolusi dari desain yang kami miliki, tetapi pada saat yang sama ada beberapa elemen baru. Ini adalah presentasi ulasan, karena itu diperlukan untuk menyesuaikan banyak informasi dalam waktu singkat. Kami mulai dengan memilih topologi yang logis. Kemudian akan ada tinjauan umum bidang kontrol dan masalah dengan skalabilitas bidang data, pilihan apa yang akan terjadi pada tingkat fisik, mari kita lihat beberapa fitur perangkat. Kami juga akan menyentuh pada apa yang terjadi di pusat data dengan MPLS, tentang yang kami bicarakan beberapa waktu lalu.

Jadi, apa Yandex dalam hal beban kerja dan layanan? Yandex adalah hiperscaler yang khas. Jika Anda melihat ke arah pengguna, kami terutama memproses permintaan pengguna. Juga, berbagai layanan streaming dan output data, karena kami juga memiliki layanan penyimpanan. Jika lebih dekat ke backend, maka beban infrastruktur dan layanan muncul di sana, seperti penyimpanan objek terdistribusi, replikasi data, dan, tentu saja, antrian yang persisten. Salah satu jenis beban utama adalah MapReduce dan sejenisnya, pemrosesan streaming, pembelajaran mesin, dll.

Bagaimana infrastruktur di atas semua ini terjadi? Sekali lagi, kita adalah hiperskaler yang sangat tipikal, meskipun mungkin kita sedikit lebih dekat ke sisi spektrum di mana hiperskaler yang lebih kecil berada. Tetapi kita memiliki semua atribut. Kami menggunakan perangkat keras komoditas dan penskalaan horizontal sedapat mungkin. Kami memiliki pertumbuhan penuh pengumpulan sumber daya: kami tidak bekerja dengan mesin terpisah, rak terpisah, tetapi menggabungkannya menjadi kumpulan besar sumber daya yang dapat dipertukarkan dengan beberapa layanan tambahan yang terlibat dalam perencanaan dan alokasi, dan kami bekerja dengan semua kumpulan ini.
Jadi kita memiliki level berikutnya - klaster komputasi level sistem operasi. Sangat penting bagi kami untuk sepenuhnya mengontrol tumpukan teknologi yang kami gunakan. Kami mengontrol titik akhir (host), tumpukan jaringan dan perangkat lunak.
Kami memiliki beberapa pusat data besar di Rusia dan luar negeri. Mereka disatukan oleh tulang punggung menggunakan teknologi MPLS. Infrastruktur internal kita hampir seluruhnya berbasis IPv6, tetapi karena kita perlu menangani lalu lintas eksternal, yang sebagian besar masih disampaikan melalui IPv4, kita harus entah bagaimana mengirimkan permintaan yang datang melalui IPv4 ke server front-end, dan masih sedikit ke IPv4 eksternal. Internet - misalnya, untuk pengindeksan.
Beberapa iterasi terakhir dari desain jaringan pusat data menggunakan topologi multi-level Clos, dan hanya L3 yang digunakan di dalamnya. Kami meninggalkan L2 beberapa waktu lalu dan menghela nafas lega. Terakhir, infrastruktur kami mencakup ratusan ribu contoh komputasi (server). Ukuran cluster maksimum beberapa waktu lalu adalah sekitar 10 ribu server. Hal ini sebagian besar disebabkan oleh bagaimana sistem operasi tingkat-kluster yang sama - penjadwal, alokasi sumber daya, dll, dapat bekerja. Karena kemajuan telah terjadi di sisi perangkat lunak infrastruktur, sekarang targetnya adalah sekitar 100 ribu server dalam satu cluster komputasi, dan kami memiliki tugas - untuk dapat membangun jaringan pabrik yang memungkinkan pengumpulan sumber daya yang efisien dalam suatu klaster.

Apa yang kita inginkan dari jaringan pusat data? Pertama-tama - banyak bandwidth murah dan cukup merata. Karena jaringan adalah substrat yang melaluinya kita dapat melakukan pengumpulan sumber daya. Ukuran target baru adalah sekitar 100 ribu server dalam satu cluster.
Juga, tentu saja, kami menginginkan bidang kontrol yang dapat diskalakan dan stabil, karena pada infrastruktur yang sedemikian besar, banyak sakit kepala muncul bahkan hanya dari peristiwa acak, dan kami tidak ingin bidang kontrol membuat kami sakit kepala. Pada saat yang sama, kami ingin meminimalkan keadaan di dalamnya. Semakin kecil kondisinya, semakin baik dan stabil semuanya berfungsi, lebih mudah untuk didiagnosis.
Tentu saja, kita perlu otomatisasi, karena tidak mungkin mengelola infrastruktur seperti itu secara manual, dan itu tidak mungkin beberapa waktu lalu. Kapan pun memungkinkan, kami membutuhkan dukungan operasional dan dukungan CI / CD sejauh mungkin.
Dengan ukuran pusat data dan cluster seperti itu, tugas untuk mendukung penyebaran dan perluasan tambahan tanpa gangguan layanan telah menjadi sangat akut. Jika pada cluster ukuran seribu mobil mungkin mendekati sepuluh ribu mobil, mereka masih bisa diluncurkan sebagai operasi tunggal - yaitu, kami berencana untuk memperluas infrastruktur, dan beberapa ribu mesin ditambahkan sebagai operasi tunggal, maka sebuah cluster ukuran seratus ribu mobil tidak muncul begitu saja, itu telah dibangun untuk beberapa waktu. Dan diharapkan bahwa selama ini apa yang telah dipompa keluar, infrastruktur yang digunakan, tersedia.
Dan satu persyaratan yang kami miliki dan tinggalkan: ini adalah dukungan untuk multitenancy, yaitu virtualisasi atau segmentasi jaringan. Sekarang kita tidak perlu melakukan ini di tingkat pabrik jaringan, karena segmentasi pergi ke host, dan ini membuat penskalaan sangat mudah bagi kita. Berkat IPv6 dan ruang alamat yang besar, kami tidak perlu menggunakan alamat duplikat di infrastruktur internal, semua pengalamatan sudah unik. Dan karena fakta bahwa kami mengambil penyaringan dan segmentasi jaringan ke host, kami tidak perlu membuat entitas jaringan virtual di jaringan pusat data.

Yang sangat penting adalah kita tidak perlu. Jika beberapa fungsi dapat dihapus dari jaringan, ini sangat menyederhanakan masa pakai, dan, sebagai suatu peraturan, memperluas pilihan perangkat keras dan perangkat lunak yang tersedia, dan sangat menyederhanakan diagnostik.
Jadi, apa yang tidak kita butuhkan, apa yang bisa kita tolak, tidak selalu dengan sukacita pada saat ini terjadi, tetapi dengan sangat lega, ketika proses itu selesai?
Pertama-tama, penolakan L2. Kami tidak perlu L2 baik nyata atau ditiru. Tidak digunakan sebagian besar karena kami mengendalikan tumpukan aplikasi. Aplikasi kami diskalakan secara horizontal, mereka bekerja dengan pengalamatan L3, mereka tidak benar-benar khawatir bahwa beberapa contoh tertentu mati, mereka hanya meluncurkan yang baru, itu tidak perlu meluncurkan pada alamat yang lama, karena ada tingkat penemuan layanan yang terpisah dan pemantauan mesin yang terletak di cluster . Kami tidak mengalihkan tugas ini ke jaringan. Tugas jaringan adalah untuk mengirimkan paket dari titik A ke titik B.
Juga, kami tidak memiliki situasi di mana alamat bergerak dalam jaringan, dan ini perlu dipantau. Dalam banyak desain, ini biasanya diperlukan untuk mendukung mobilitas VM. Kami tidak menggunakan mobilitas mesin virtual dalam infrastruktur internal persis Yandex besar, dan, di samping itu, kami percaya bahwa, bahkan jika ini dilakukan, ini tidak boleh terjadi dengan dukungan jaringan. Jika Anda benar-benar perlu melakukan ini, Anda harus melakukan ini di tingkat tuan rumah, dan mengarahkan alamat yang dapat bermigrasi ke overlay agar tidak menyentuh atau membuat terlalu banyak perubahan dinamis pada sistem perutean itu sendiri yang mendasari (jaringan transportasi).
Teknologi lain yang tidak kami gunakan adalah multicast. Saya bisa memberi tahu Anda secara rinci mengapa. Ini membuat hidup jauh lebih mudah, karena jika seseorang menanganinya dan menyaksikan seperti apa bidang kendali multicast - di semua instalasi kecuali yang paling sederhana, ini adalah sakit kepala yang besar. Dan terlebih lagi, sulit untuk menemukan implementasi open source yang berfungsi dengan baik, misalnya.
Akhirnya, kami merancang jaringan kami sehingga mereka tidak memiliki terlalu banyak perubahan. Kita dapat mengandalkan fakta bahwa aliran peristiwa eksternal dalam sistem routing kecil.

Masalah apa yang muncul dan batasan apa yang harus dipertimbangkan ketika kita mengembangkan jaringan pusat data? Biaya tentu saja. Skalabilitas, ke tingkat apa kita ingin tumbuh. Kebutuhan untuk ekspansi tanpa menghentikan layanan. Ketersediaan bandwidth. Visibilitas apa yang terjadi pada jaringan, untuk sistem pemantauan, untuk tim operasional. Dukungan untuk otomasi, sekali lagi, sebanyak mungkin, karena tugas yang berbeda dapat diselesaikan di tingkat yang berbeda, termasuk pengenalan lapisan tambahan. Baik dan tidak- [jika memungkinkan] -dependensi pada vendor. Meskipun dalam periode sejarah yang berbeda, tergantung pada bagian mana yang harus dilihat, kemerdekaan ini lebih mudah atau lebih sulit untuk dicapai. Jika kita mengambil sepotong chip perangkat jaringan, maka sampai saat ini, berbicara tentang independensi dari vendor, jika kita juga menginginkan chip dengan throughput yang tinggi, itu bisa sangat sewenang-wenang.

Topologi logis apa yang akan kita gunakan untuk membangun jaringan kita? Ini akan menjadi Clos multi-level. Bahkan, saat ini tidak ada alternatif nyata. Dan topologi Clos cukup baik, bahkan jika kita membandingkannya dengan berbagai topologi canggih yang sekarang lebih di bidang minat akademik, jika kita memiliki switch dengan radix besar.
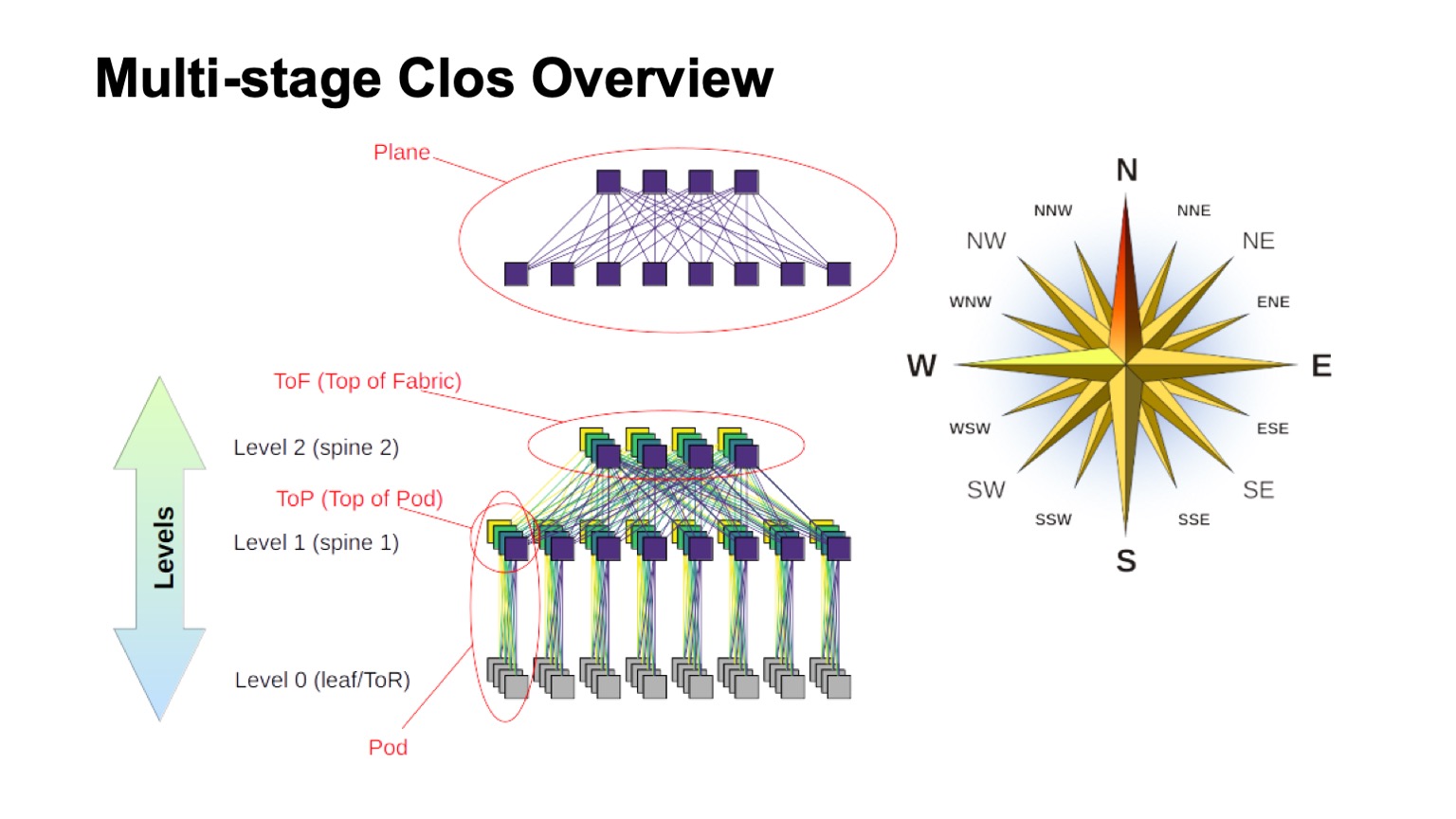
Bagaimana jaringan Clos yang berlapis kira-kira terstruktur dan elemen-elemen apa yang disebut di dalamnya? Pertama-tama, angin naik, untuk mencari tahu di mana utara, di mana selatan, di mana timur, di mana barat. Jaringan jenis ini biasanya dibangun oleh mereka yang memiliki traffic sangat besar barat - timur. Adapun sisa elemen, switch virtual yang dirakit dari switch yang lebih kecil ditampilkan di bagian atas. Ini adalah ide dasar untuk membangun jaringan Clos secara rekursif. Kami mengambil elemen dengan semacam radix dan menghubungkannya sehingga apa yang terjadi dapat dianggap sebagai saklar dengan radix yang lebih besar. Jika Anda membutuhkan lebih banyak lagi, prosedur ini dapat diulang.
Dalam kasus, misalnya, dengan Clos dua tingkat, ketika dimungkinkan untuk dengan jelas membedakan komponen yang vertikal dalam diagram saya, mereka biasanya disebut pesawat. Jika kita membangun Clos-dengan tiga tingkat switch tulang belakang (semua yang bukan garis batas dan bukan ToR-switch dan yang hanya digunakan untuk transit), maka pesawat akan terlihat lebih rumit, dua tingkat terlihat persis seperti itu. Blok sakelar ToR atau daun dan sakelar tulang belakang tingkat pertama terkait yang kita sebut Pod. Sakelar level 1 tulang belakang di bagian atas Pod adalah bagian atas Pod, bagian atas Pod. Sakelar yang terletak di bagian atas seluruh pabrik adalah lapisan atas pabrik, Top of fabric.

Tentu saja, muncul pertanyaan: Clos-networks telah dibangun untuk beberapa waktu, ide itu sendiri umumnya berasal dari zaman telepon klasik, TDM-networks. Mungkin sesuatu yang lebih baik muncul, mungkin Anda bisa melakukan sesuatu yang lebih baik entah bagaimana? Ya dan tidak Secara teoritis, ya, dalam praktiknya, dalam waktu dekat, pasti tidak. Karena ada sejumlah topologi yang menarik, beberapa di antaranya bahkan digunakan dalam produksi, misalnya, Capung digunakan dalam aplikasi HPC; Ada juga topologi menarik seperti Xpander, FatClique, Jellyfish. Jika Anda melihat laporan di konferensi seperti SIGCOMM atau NSDI belakangan ini, Anda dapat menemukan sejumlah besar makalah tentang topologi alternatif yang memiliki sifat lebih baik (satu atau yang lain) daripada Clos.
Tetapi semua topologi ini memiliki satu sifat menarik. Ini mencegah implementasi mereka dalam jaringan pusat data, yang kami coba untuk membangun berdasarkan perangkat keras komoditas dan yang memakan biaya uang yang masuk akal. Dalam semua topologi alternatif ini, sebagian besar band, sayangnya, tidak dapat diakses melalui jalur terpendek. Karena itu, kami segera kehilangan kemampuan untuk menggunakan pesawat kontrol tradisional.
Secara teoritis, solusi untuk masalah tersebut diketahui. Ini, misalnya, modifikasi keadaan tautan menggunakan jalur terpendek k, tetapi, sekali lagi, tidak ada protokol yang akan diimplementasikan dalam produksi dan tersedia secara besar-besaran pada peralatan.
Selain itu, karena sebagian besar kapasitas tidak dapat diakses melalui jalur terpendek, kita perlu memodifikasi tidak hanya bidang kontrol sehingga memilih semua jalur ini (dan, omong-omong, ini adalah keadaan yang jauh lebih besar di bidang kontrol). Kami masih perlu memodifikasi bidang penerusan, dan sebagai aturan, setidaknya dua fitur tambahan diperlukan. Ini adalah kesempatan untuk membuat semua keputusan tentang paket penerusan satu kali, misalnya, pada host. Ini sebenarnya sumber routing, kadang-kadang dalam literatur tentang jaringan interkoneksi itu disebut keputusan penerusan semua-sekaligus. Dan routing adaptif sudah merupakan fungsi yang kita butuhkan pada elemen jaringan, yang bermuara, misalnya, dengan fakta bahwa kita memilih hop berikutnya berdasarkan informasi tentang beban paling sedikit pada antrian. Sebagai contoh, opsi lain dimungkinkan.
Dengan demikian, arahnya menarik, tetapi, sayangnya, kami tidak dapat menerapkannya sekarang.

Oke, memilih topologi logis dari Clos. Bagaimana kita mengukurnya? Mari kita lihat cara kerjanya dan apa yang bisa dilakukan.

Di jaringan Clos ada dua parameter utama yang entah bagaimana kita dapat bervariasi dan mendapatkan hasil tertentu: elemen radix dan jumlah level dalam jaringan. Saya secara skematis menggambarkan bagaimana satu dan yang lain memengaruhi ukuran. Idealnya, kami menggabungkan keduanya.
Dapat dilihat bahwa total lebar jaringan Clos adalah produk dari semua level switch tulang belakang radix selatan, berapa banyak link yang kita miliki, bagaimana cabangnya. Ini adalah bagaimana kami skala ukuran jaringan.
Adapun kapasitas, terutama pada switch ToR, ada dua opsi penskalaan. Entah kita bisa, sambil mempertahankan topologi umum, menggunakan tautan yang lebih cepat, atau kita dapat menambahkan lebih banyak pesawat.
Jika Anda melihat versi detail dari jaringan Clos (di sudut kanan bawah) dan kembali ke gambar ini dengan jaringan Clos di bawah ...
... maka ini adalah topologi yang persis sama, tetapi pada slide ini runtuh lebih kompak dan pesawat-pesawat pabrik ditumpangkan satu sama lain. Itu satu dan sama.

Seperti apa penskalaan jaringan Clos dalam angka? Di sini saya punya data berapa lebar maksimum yang bisa didapat jaringan, berapa rak maksimum, sakelar ToR atau sakelar daun, jika mereka tidak ada di rak, kita bisa dapatkan tergantung pada radix sakelar apa yang kita gunakan untuk duri level dan berapa level yang kita gunakan.
Ini menunjukkan berapa banyak rak yang bisa kita miliki, berapa banyak server dan berapa banyak semua ini dapat dikonsumsi pada tingkat 20 kW per rak. Sedikit lebih awal, saya menyebutkan bahwa kami menargetkan ukuran cluster sekitar 100 ribu server.
Dapat dilihat bahwa dalam keseluruhan konstruksi ini dua setengah opsi menarik. Ada opsi dengan dua lapisan duri dan switch 64-port, yang agak pendek. Kemudian, opsi yang cocok untuk switch tulang belakang 128-port (dengan 128 radix) dengan dua level, atau switch dengan 32 radix dengan tiga level. Dan dalam semua kasus di mana ada lebih banyak radix dan lebih banyak level, Anda dapat membuat jaringan yang sangat besar, tetapi jika Anda melihat konsumsi yang diharapkan, sebagai aturan, ada gigawatt. Anda dapat meletakkan kabelnya, tetapi kami tidak mungkin mendapatkan begitu banyak listrik di satu lokasi. Jika Anda melihat statistik, data publik tentang pusat data - sangat sedikit pusat data yang dapat ditemukan dengan perkiraan kapasitas lebih dari 150 MW. Terlebih lagi - sebagai aturan, kampus pusat data, beberapa pusat data besar terletak cukup dekat satu sama lain.
Ada parameter penting lainnya. Jika Anda melihat kolom kiri, bandwidth yang dapat digunakan ditunjukkan di sana. Sangat mudah untuk memperhatikan bahwa dalam jaringan Clos, sebagian besar port dihabiskan untuk menghubungkan switch satu sama lain. Bandwidth yang dapat digunakan adalah apa yang dapat Anda berikan, ke server. Secara alami, saya berbicara tentang port bersyarat dan tentang strip. Sebagai aturan, tautan dalam jaringan lebih cepat dari tautan ke server, tetapi per unit band, sejauh yang kami bisa berikan ke peralatan server kami, masih ada beberapa band lagi di dalam jaringan itu sendiri. Dan semakin banyak level yang kita lakukan, semakin besar biaya unit untuk menyediakan strip ini ke luar.
Apalagi band tambahan ini tidak persis sama. Meskipun bentangnya pendek, kita dapat menggunakan sesuatu seperti DAC (kabel tembaga langsung, yaitu kabel twinax), atau optik multimode, yang harganya bahkan lebih mahal. Segera setelah kami beralih ke rentang yang lebih otentik - sebagai aturan, ini adalah mode optik tunggal, dan biaya pita tambahan ini meningkat secara nyata.
Dan lagi, kembali ke slide sebelumnya, jika kita membuat jaringan Clos tanpa berlangganan kembali, maka mudah untuk melihat diagram, melihat bagaimana jaringan dibangun - menambahkan setiap level switch tulang belakang, kita ulangi seluruh strip yang ada di bawah. Plus level - ditambah seluruh pita yang sama, jumlah port yang sama pada sakelar seperti pada level sebelumnya, jumlah transceiver yang sama. Oleh karena itu, jumlah level switch tulang belakang sangat diinginkan untuk diminimalkan.
Berdasarkan gambar ini, jelas bahwa kami benar-benar ingin membangun sesuatu seperti switch dengan 128 radix.

Di sini, pada prinsipnya, semuanya sama seperti yang saya katakan sebelumnya, slide ini lebih mungkin untuk dipertimbangkan nanti.

, ? , - . , . , . , . , , , , . ( ), control plane , , , , . , , .
, , , SerDes- — - . forwarding . , , , , , Clos-, . .
, , . , , , , , , , , , .

— , . , , . , , , - , . , , , , .
, , , . -, , . , , 128 , .
, , , data plane. . , , . , , , . , , , , 128 , . . . .
, - , . ( ), , — ToR- leaf-, . - , , , , - . , , , - .

, , .

? . , , , : leaf-, 1, 2. , — twinax, multimode, single mode. , , , , , .
. , , multimode , , , 100- . , , , single mode , , single mode, - CWDM, single mode (PSM) , , , .
: , 100 425 . SFP28 , QSFP28 100 . multimode .
- , - , - - . , . , - Pods twinax- ( ).
, , , CWDM. .
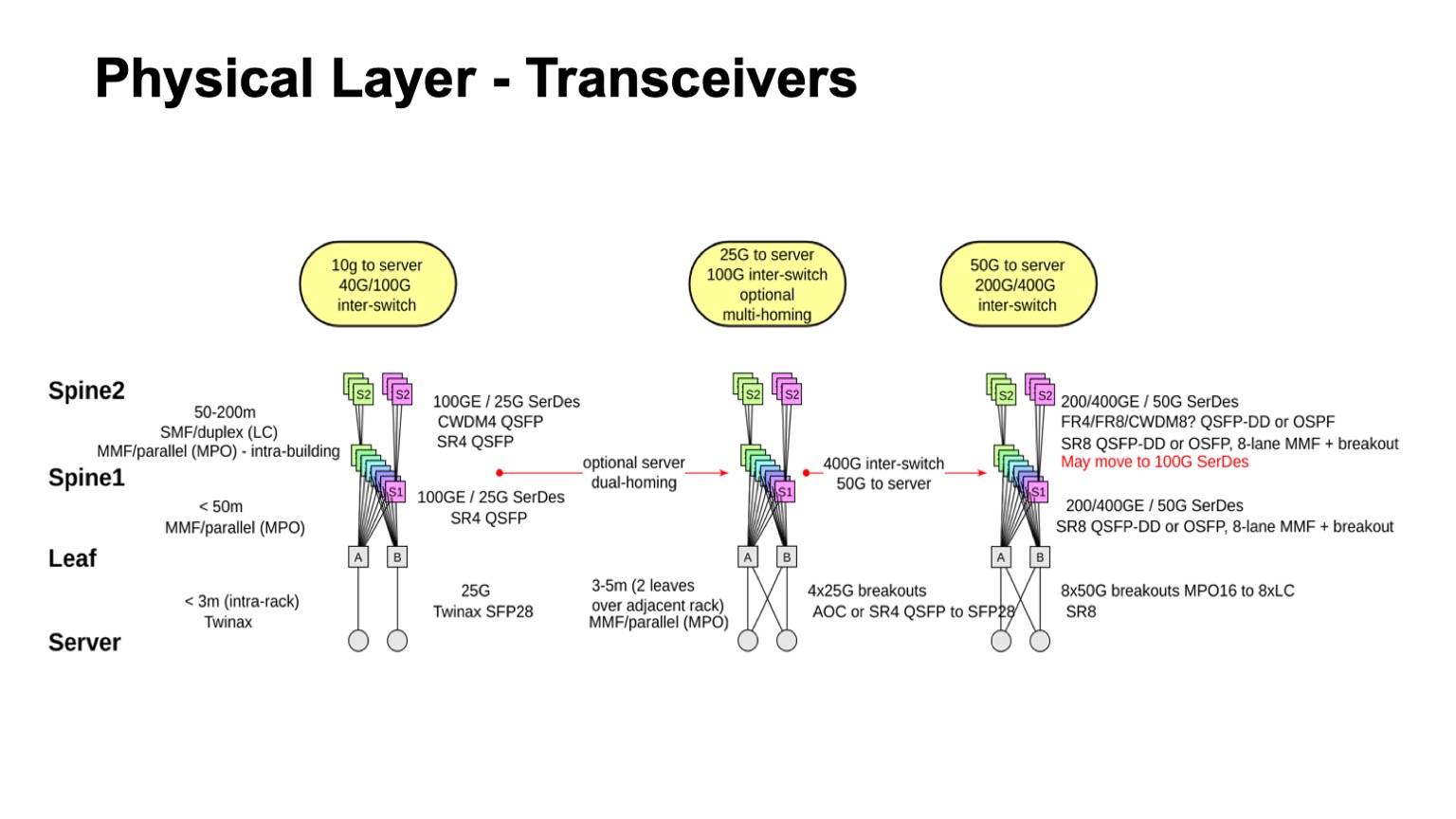
, , . , , 50- SerDes . , , 400G, 50G SerDes- , 100 Gbps per lane. , 50 100- SerDes 100 Gbps per lane, . , 50G SerDes , , , 100G SerDes . - , , .
. , 400- 200- 50G SerDes. , , , , , , . 128. , , , , .
, , . , , , , , 100- , .

— , . , . leaf- — , . , , — .
, , , -. , , - -, . . , , , . - -, -, , , , . : . - , « », Clos-, . , , .
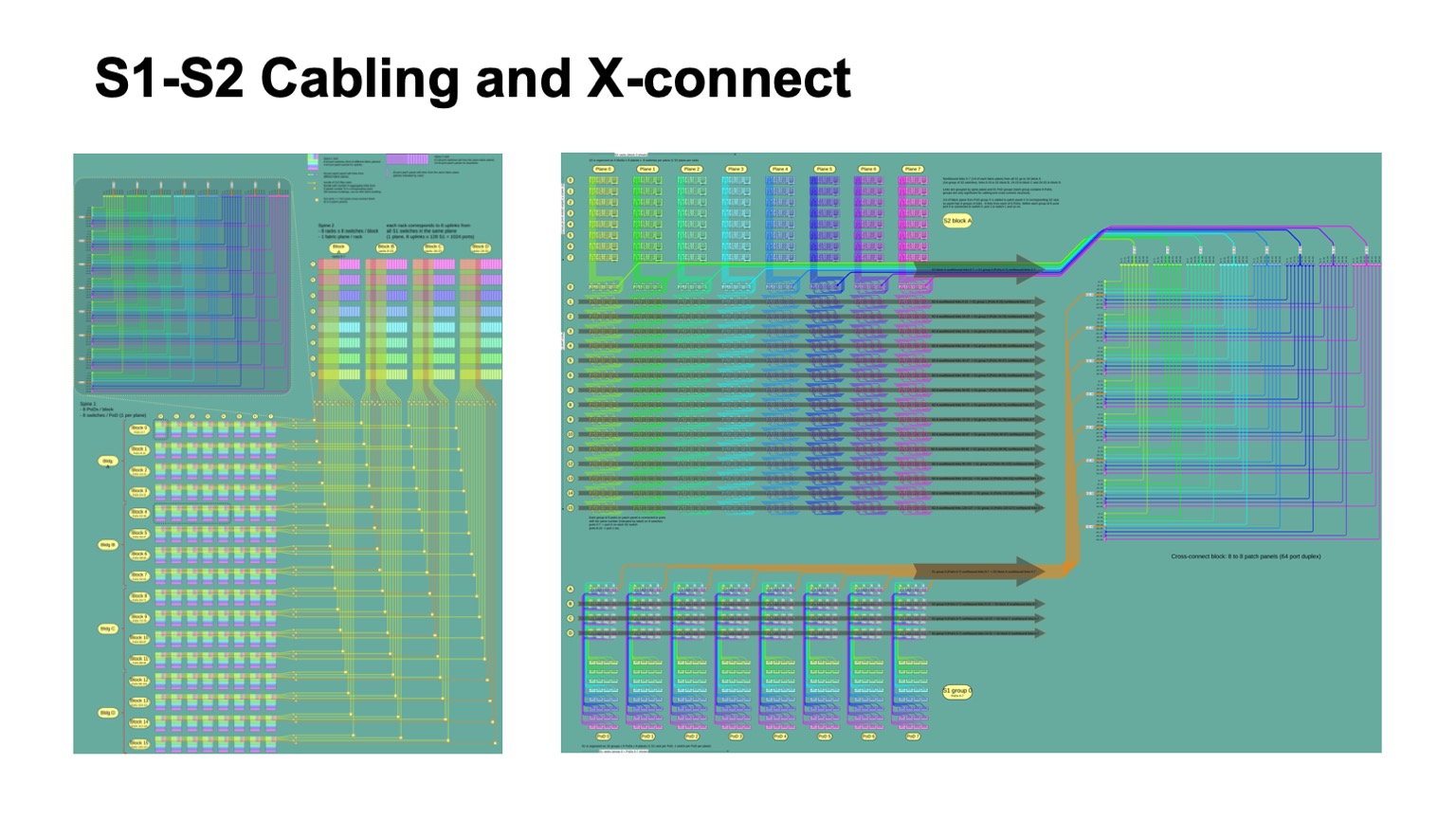
. - , , , , -2-.
. , - 512 512 , , , -2. Pods -1, -, -2.

Ini tampilannya. -2 () -. , . -, . , , .

: , . control plane-? , - , link state , , , , . , — , link state . , , , , fanout, control plane . link state .
— BGP. , RFC 7938 BGP -. : , , , path hunting. , , , valley free. , , , . , , . . .
, , BGP. eBGP, link local, : ToR, -1- Pod, Top of Fabric. , BGP , .

, , , , control plane. L3 , , . — , , , multi-path, multi-path , , , . , , , , , . , multi-path, ToR-.

, , — . , , , , BGP, . , corner cases , BGP .
RIFT, .

— , data plane , . : ECMP , Next Hop.
, , Clos- , , , , , . , ECMP, single path-. . , Clos- , Top of fabric, , . , , . , ECMP state.
data plane ? LPM (longest prefix match), , 100 . Next Hop , , 2-4 . , Next Hops ( adjacencies), - 16 64. . : MPLS -? , .

. , . white boxes MPLS. MPLS, , , , ECMP. Dan inilah alasannya.

ECMP- IP. Next Hops ( adjacencies, -). , -, Next Hop. IP , , Next Hops.

MPLS , . Next Hops . , , .
, 4000 ToR-, — 64 ECMP, -1 -2. , , ECMP-, ToR , Next Hops.

, Segment Routing . Next Hops. wild card: . , .
, - . ? Clos- . , Top of fabric. . , , Top of fabric, , , . , , , , .
— . , Clos- , , , ToR, Top of fabric , . Pod, Edge Pod, .
. , , Facebook. Fabric Aggregator HGRID. -, -. , . , touch points, . , , -. , - , , . , , . overlays, .

? — CI/CD-. , , , . , , . , , .
, . . — .
. , RIFT. congestion control , , , , RDMA .
, , , , overhead. — HPC Cray Slingshot, commodity Ethernet, . overhead .

, , . — . — . - scale out — . , . . Terima kasih