Hai
Apakah Anda sering melihat komentar beracun di jejaring sosial? Mungkin tergantung pada konten yang Anda tonton. Saya mengusulkan untuk bereksperimen sedikit tentang topik ini dan mengajar jaringan saraf untuk menentukan komentar pembenci.
Jadi, tujuan global kami adalah untuk menentukan apakah komentar itu agresif, artinya, kita berurusan dengan klasifikasi biner. Kami akan menulis jaringan saraf sederhana, melatihnya pada kumpulan komentar dari jejaring sosial yang berbeda, dan kemudian kami akan membuat analisis sederhana dengan visualisasi.
Untuk pekerjaan saya akan menggunakan Google Colab. Layanan ini memungkinkan Anda untuk menjalankan Notebook Jupyter, dan memiliki akses ke GPU (NVidia Tesla K80) secara gratis, yang akan mempercepat pembelajaran. Saya akan membutuhkan backend TensorFlow, versi default di Colab 1.15.0, jadi cukup tingkatkan ke 2.0.0.
Kami mengimpor modul dan memperbarui.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
Anda dapat melihat versi saat ini seperti ini.
print(tf.__version__)
Pekerjaan persiapan selesai, kami mengimpor semua modul yang diperlukan.
import os import numpy as np
Deskripsi perpustakaan yang digunakan
- os - untuk bekerja dengan sistem file
- numpy - untuk bekerja dengan array
- panda - perpustakaan untuk menganalisis data tabular
- keras - untuk membangun model
- keras.preprocessing.Text - untuk pemrosesan teks, untuk mengirimkannya dalam bentuk numerik untuk pelatihan jaringan saraf
- sklearn.train_test_split - untuk memisahkan data uji dari pelatihan
- matplotlib - untuk memvisualisasikan proses pembelajaran
- sklearn.normalalize - untuk menormalkan data tes dan pelatihan
Parsing data dengan Kaggle
Saya memuat data langsung ke laptop Colab itu sendiri. Selanjutnya, tanpa masalah, saya sudah mengekstraksi mereka.
path = 'labeled.csv' df = pd.read_csv(path) df.head()
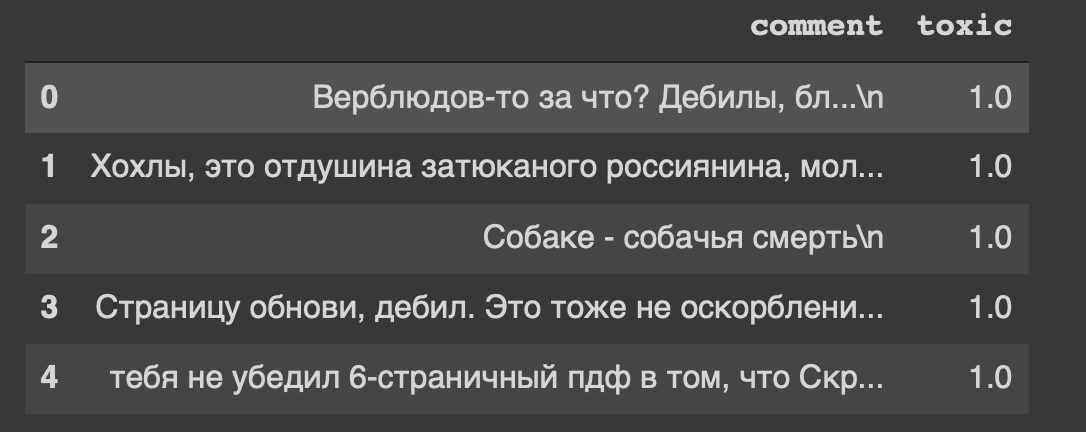
Dan ini adalah judul dari dataset kami ... Saya juga merasa tidak nyaman dari "halaman refresh, tolol."
Jadi, data kita ada dalam tabel, kita akan membaginya menjadi dua bagian: data untuk pelatihan dan untuk model uji. Tapi ini semua teks, sesuatu harus dilakukan.
Pemrosesan data
Hapus karakter baris baru dari teks.
def delete_new_line_symbols(text): text = text.replace('\n', ' ') return text
df['comment'] = df['comment'].apply(delete_new_line_symbols) df.head()
Komentar memiliki tipe data nyata, kita perlu menerjemahkannya menjadi integer. Selanjutnya, simpan dalam variabel terpisah.
target = np.array(df['toxic'].astype('uint8')) target[:5]
Sekarang kita akan sedikit memproses teks menggunakan kelas Tokenizer. Mari kita menulis salinannya.
tokenizer = Tokenizer(num_words=30000, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True, split=' ', char_level=False)
Cepat tentang parameter- num_words - jumlah kata tetap (paling umum)
- filter - urutan karakter yang akan dihapus
- lower - parameter boolean yang mengontrol apakah teks akan menggunakan huruf kecil
- split - simbol utama untuk memisahkan sebuah kalimat
- char_level - menunjukkan apakah satu karakter akan dianggap kata
Dan sekarang kita akan memproses teks menggunakan kelas.
tokenizer.fit_on_texts(df['comment']) matrix = tokenizer.texts_to_matrix(df['comment'], mode='count') matrix.shape
Kami mendapat 14k baris sampel dan kolom fitur 30k.

Saya membangun model dari dua lapisan: Padat dan Putus Sekolah.
def get_model(): model = Sequential() model.add(Dense(32, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer=RMSprop(lr=0.0001), loss='binary_crossentropy', metrics=['accuracy']) return model
Kami menormalkan matriks dan membagi data menjadi dua bagian, sesuai kesepakatan (pelatihan dan tes).
X = normalize(matrix) y = target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) X_train.shape, y_train.shape
Pelatihan model
model = get_model() history = model.fit(X_train, y_train, epochs=150, batch_size=500, validation_data=(X_test, y_test)) history
Saya akan menunjukkan proses pembelajaran pada iterasi terakhir.

Visualisasi proses pembelajaran
history = history.history fig = plt.figure(figsize=(20, 10)) ax1 = fig.add_subplot(221) ax2 = fig.add_subplot(223) x = range(150) ax1.plot(x, history['acc'], 'b-', label='Accuracy') ax1.plot(x, history['val_acc'], 'r-', label='Validation accuracy') ax1.legend(loc='lower right') ax2.plot(x, history['loss'], 'b-', label='Losses') ax2.plot(x, history['val_loss'], 'r-', label='Validation losses') ax2.legend(loc='upper right')
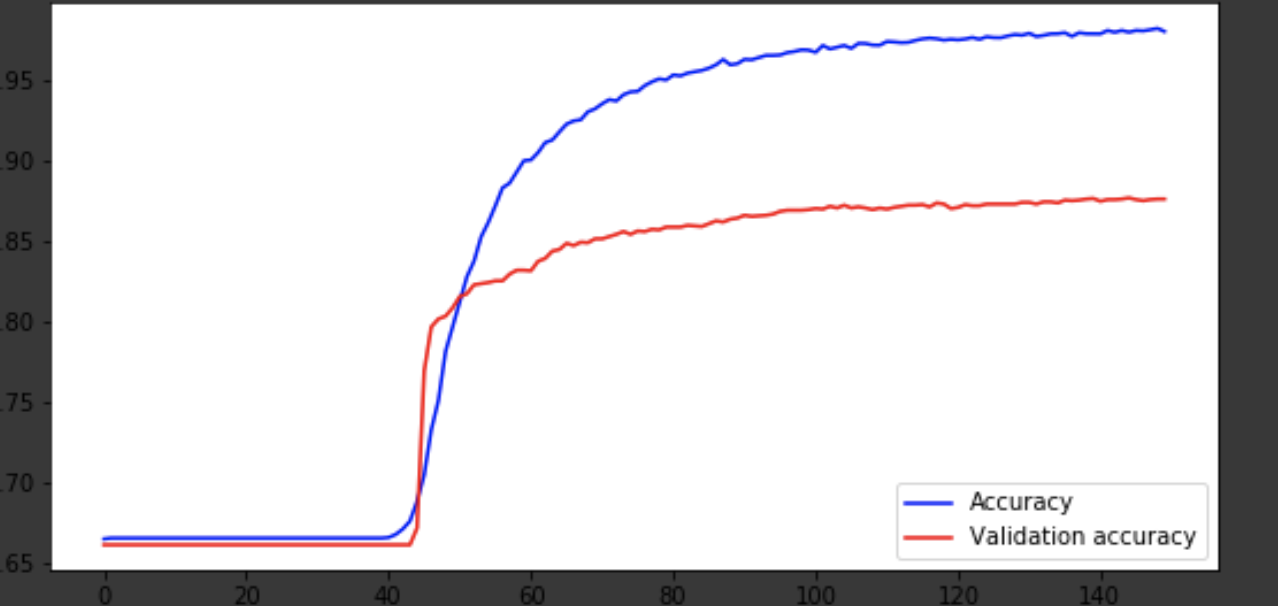
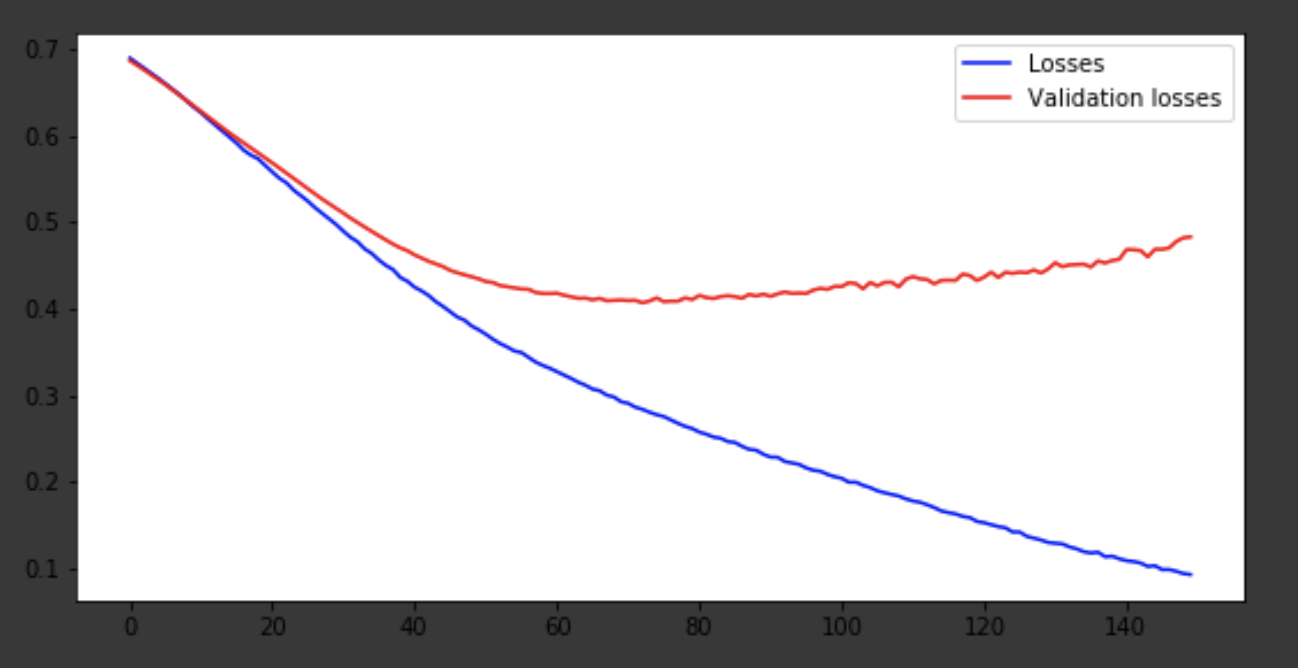
Kesimpulan
Model keluar sekitar era ke-75, dan kemudian berperilaku buruk. Keakuratan 0,85 tidak mengecewakan. Anda bisa bersenang-senang dengan jumlah layer, hyperparameter dan mencoba meningkatkan hasilnya. Itu selalu menarik dan merupakan bagian dari pekerjaan. Tuliskan pemikiran Anda dalam komentar, kami akan melihat berapa banyak topi yang akan didapat artikel ini.