Sebagai antisipasi dimulainya utas baru pada kursus "Jaringan Saraf dengan Python" menyiapkan terjemahan artikel yang menarik untuk Anda.
Salah satu masalah utama dalam implementasi generasi baru komputer kuantum terletak pada pelanggan mereka yang paling dasar:
qubit . Qubit dapat berinteraksi dengan objek apa pun di sekitarnya yang mentransfer
energi dekat dengan
foton pengembaraan mereka sendiri (yaitu bidang elektromagnetik yang tidak diinginkan,
fonon (getaran mekanis perangkat kuantum) atau cacat kuantum (penyimpangan pada permukaan chip yang muncul selama tahap pembuatan), yang secara tak terduga dapat mengubah keadaan qubit sendiri.
Masalahnya rumit oleh banyak tugas yang menempatkan alat yang digunakan untuk mengontrol qubit. Qubit diproses dan dibaca dengan metode
klasik : sinyal analog dalam bentuk medan elektromagnetik, ditambah dengan papan fisik di mana qubit dibangun, misalnya, mikrosirkuit superkonduktor. Ketidaksempurnaan dalam elektronik kontrol (mengarah ke white noise), gangguan dari sumber radiasi eksternal dan fluktuasi dalam konverter digital-ke-analog menyebabkan kesalahan stokastik yang lebih besar yang memperburuk operasi sirkuit mikro kuantum. Masalah-masalah praktis ini mempengaruhi keakuratan perhitungan dan, dengan demikian, membatasi penerapan generasi perangkat kuantum yang akan datang.
Untuk meningkatkan daya komputasi komputer kuantum dan membuka jalan menuju komputasi kuantum skala besar, pertama-tama perlu untuk membangun model fisik yang secara akurat menggambarkan masalah eksperimental ini.
Dalam artikel
"Kontrol Kuantum Universal melalui Pembelajaran Penguatan Dalam" , yang diterbitkan dalam Nature Partner Journal (npj) Informasi Quantum (https://www.nature.com/npjqi/articles), kami memperkenalkan struktur baru kontrol kuantum yang dibuat menggunakan pembelajaran mendalam dengan penguatan di mana masalah praktis mengoptimalkan kontrol kuantum dapat diringkas dengan fungsi
kerugian tunggal. Struktur yang dipertimbangkan memberikan penurunan kesalahan rata-rata
gerbang kuantum ke dua urutan besarnya dibandingkan dengan solusi stokastik standar gradient descent dan pengurangan yang signifikan dalam waktu gerbang ke nilai optimal analog sintesis gerbang. Hasil kami membuka cakrawala baru untuk pemodelan kuantum, kimia kuantum dan tes keunggulan kuantum menggunakan perangkat kuantum dalam waktu dekat.
Inovasi paradigma kontrol kuantum ini didasarkan pada pengembangan fungsi kontrol kuantum dan metode optimisasi yang efektif berdasarkan pembelajaran mendalam dengan penguatan. Untuk mengembangkan fungsi kerugian yang komprehensif, pertama-tama kita perlu mengembangkan model fisik dari proses kontrol kuantum yang realistis di mana kita dapat secara akurat memprediksi besarnya kesalahan. Salah satu kesalahan yang paling menjengkelkan dalam mengevaluasi keakuratan komputasi kuantum adalah kebocoran: jumlah informasi kuantum yang hilang selama perhitungan. Kebocoran seperti itu biasanya terjadi ketika keadaan kuantum qubit berubah ke tingkat energi yang lebih tinggi atau lebih rendah karena emisi spontan. Karena kesalahan kebocoran, tidak hanya informasi kuantum yang berguna hilang, itu juga menurunkan "kuantum" dan pada akhirnya mengurangi kinerja komputer kuantum menjadi kinerja komputer dengan arsitektur klasik.
Praktik umum untuk memperkirakan informasi yang hilang secara akurat selama perhitungan kuantum adalah memodelkan seluruh perhitungan terlebih dahulu. Namun, ini meniadakan seluruh titik pembuatan komputer kuantum skala besar, karena keunggulan mereka adalah mereka mampu melakukan perhitungan yang mustahil untuk komputer klasik. Dengan peningkatan pemodelan fisik, fungsi kerugian umum kami memungkinkan kami untuk bersama-sama mengoptimalkan akumulasi kesalahan kebocoran, pelanggaran kondisi batas kontrol, total waktu katup, dan akurasi katup.
Dengan fungsi manajemen kerugian yang baru, langkah selanjutnya adalah menggunakan alat optimisasi yang efektif untuk menguranginya. Metode optimasi yang ada tidak cukup baik untuk mencari solusi presisi tinggi yang dapat diandalkan untuk mengendalikan fluktuasi. Sebaliknya, kami menggunakan metode yang didasarkan pada metode pembelajaran dalam kebijakan dengan penguatan (RL),
RL - area tepercaya . Karena metode ini menunjukkan kinerja yang baik dalam semua tugas pengujian, maka secara inheren resisten terhadap kebisingan sampel dan dapat mengoptimalkan masalah kontrol yang rumit dengan ratusan juta parameter kontrol. Perbedaan yang signifikan antara metode RL on-kebijakan dan metode RL off-kebijakan yang telah dipelajari sebelumnya adalah bahwa kebijakan manajemen disajikan secara independen dari manajemen kerugian. Di sisi lain, semua kebijakan RL, seperti
Q-learning , menggunakan jaringan saraf tunggal untuk mewakili jalur kontrol dan hadiah terkait, di mana lintasan kontrol menentukan sinyal kontrol yang harus dikaitkan dengan qubit pada ukuran yang berbeda, dan hadiah terkait mengukur seberapa bagus taktik tersebut. kontrol kuantum.
On-policy RL terkenal karena kemampuannya untuk menggunakan fitur-fitur non-lokal di jalur kontrol, yang menjadi kritis ketika lanskap kontrol multi-dimensi dan dikemas dengan sejumlah besar solusi non-global, seperti yang sering terjadi dengan sistem kuantum.
Kami menyandikan jalur kontrol ke jaringan saraf tiga lapis, yang sepenuhnya terhubung - kebijakan NN, dan fungsi kontrol hilang ke dalam jaringan saraf kedua - nilai NN, yang mencerminkan penghargaan masa depan yang didiskon. Solusi kontrol yang andal diperoleh dengan agen pembelajaran penguatan yang melatih kedua jaringan saraf dalam lingkungan stokastik yang mensimulasikan kontrol kebisingan realistis. Kami menawarkan solusi untuk mengendalikan satu set gerbang kuantum dua-qubit yang diparameterisasi secara terus-menerus, yang sangat penting dalam aplikasi untuk kimia kuantum, tetapi terlalu mahal untuk diterapkan menggunakan gerbang universal universal standar.
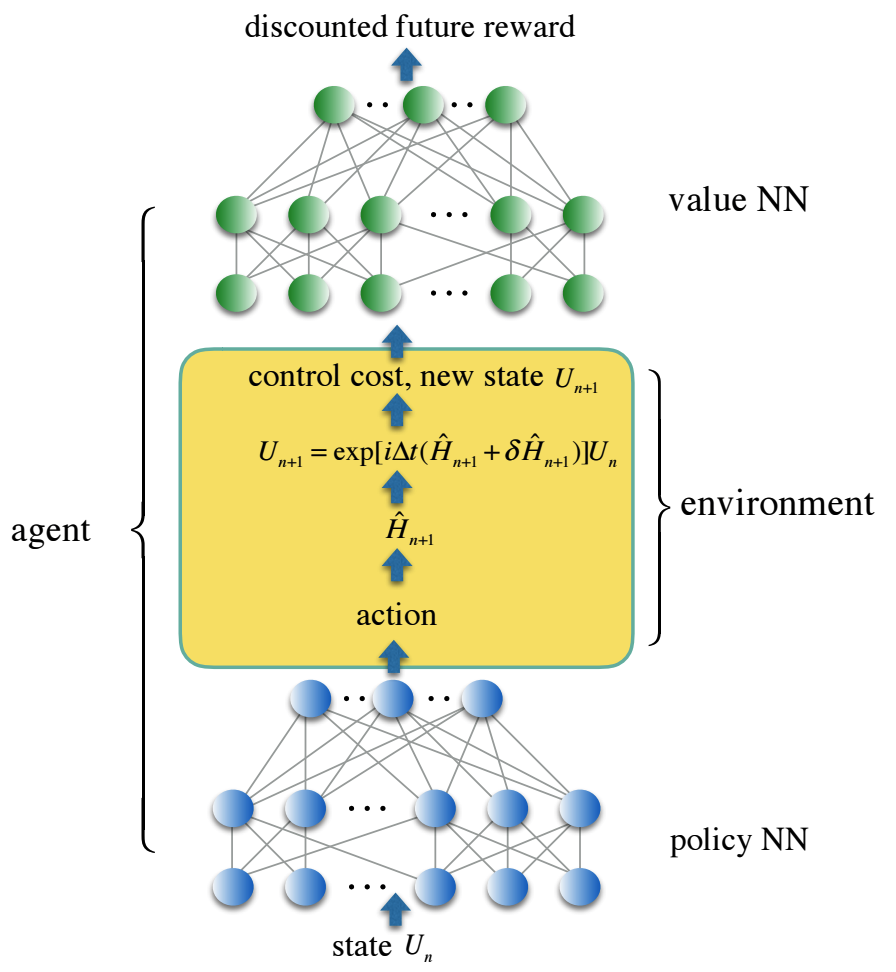
Dalam kerangka struktur baru ini, simulasi numerik kami menunjukkan penurunan seratus kali lipat dalam kesalahan gerbang kuantum dan pengurangan waktu gerbang untuk keluarga simulasi gerbang kuantum yang diparameterisasi secara terus menerus dengan rata-rata satu urutan besarnya dibandingkan dengan pendekatan tradisional menggunakan serangkaian gerbang universal.
Pekerjaan ini menekankan pentingnya menggunakan metode pembelajaran mesin baru dan algoritma kuantum terbaru yang menggunakan fleksibilitas dan kekuatan pemrosesan tambahan dari rangkaian kontrol kuantum universal. Untuk sepenuhnya mengintegrasikan pembelajaran mesin dan meningkatkan kemampuan komputasi, perlu untuk melakukan eksperimen tambahan, mirip dengan apa yang diberikan dalam pekerjaan ini.