
Menurut analis, pasar untuk pusat data di tahun-tahun mendatang akan tumbuh sebesar 38% per tahun dan akan tumbuh menjadi $ 35 miliar selama lima tahun, dan niche yang paling intensif sumber daya (dalam hal intensitas komputasi) adalah pembelajaran mendalam, jaringan saraf dan tugas AI.
Tentu saja, Intel tidak akan acuh tak acuh untuk menonton bagaimana Nvidia (dan AMD, pada tingkat yang lebih rendah) dengan GPU-nya menangkap pasar ini, termasuk sektor yang tumbuh paling cepat. Pekan lalu, raksasa industri mikroelektronik membuat beberapa pengumuman profil tinggi sekaligus:
Modul Komputer Aurora
Pada CPU ini, GPU dan oneAPI mereka akan menyusun modul komputasi Aurora untuk superkomputer eponymous dengan tingkat kinerja 1 exaflops (10 ^ 18 operasi per detik). Diasumsikan bahwa mesin ini akan dipasang di Laboratorium Nasional Argonne dari Departemen Energi AS.

Setiap modul komputasi memiliki dua prosesor Sapphire Rapids dan enam GPU yang terhubung melalui bus CXL.

Menurut
perkiraan AnandTech , dalam sistem 200 rak, seperti yang disebutkan, jika Anda mengurangi cadangan untuk jaringan dan drive, sekitar 2400 dua unit node Aurora akan cocok. Itu adalah total sekitar 5.000 prosesor Sapphire Rapids dan 15.000 Ponte Vecchio. Jika kita membagi kinerja yang dinyatakan dari 1 exaflops dengan jumlah GPU, maka sekitar 66,6 teraflops per GPU keluar. Selanjutnya, dengan asumsi kinerja CPU 14 teraflops, kami masih mendapatkan sekitar 50 teraflops, yaitu, ini adalah peningkatan lima kali lipat dalam kinerja GPU di pusat data pada tahun 2021.
Tentu saja, rencana tidak terbatas pada superkomputer untuk Departemen Energi. Intel mengumumkan bahwa Lenovo dan Atos sudah bersiap untuk merilis platform server berbasis pada Xeon CPU, X
e GPU dan oneAPI. Dengan demikian, modul komputasi Aurora dalam beberapa bentuk akan menemukan aplikasi di pusat data lainnya.
Superkomputer harus diluncurkan pada 2021. Pada saat yang sama, 7-nanometer X
e GPU akan muncul di pasar.
Menurut Intel, sekarang solusi tradisional kinerja tinggi (HPC) menyatu dengan AI, pindah ke beban kerja yang menggunakan pembelajaran mendalam. HPC, AI, dan analitik adalah tiga beban kerja utama yang mendorong permintaan akan sumber daya komputasi: “Beragam kebutuhan komputasi seperti itu mendorong komputasi heterogen.
Kata Rajeeb Hazra, wakil presiden dan manajer umum Intel Enterprise and Government. - Solusi universal tidak lagi cocok di sini. Di era konvergensi ini, Anda harus melihat arsitektur yang disesuaikan dengan kebutuhan berbeda dari berbagai jenis beban kerja.
GPU untuk pusat data

Ponte Vecchio adalah GPU pertama pada arsitektur X
e baru. Arsitektur itu sendiri akan menjadi dasar untuk GPU di berbagai segmen:
- komputasi kinerja tinggi;
- pembelajaran yang mendalam;
- Komputasi awan
- grafik;
- transcoding media;
- workstation
- komputer game;
- PC desktop biasa;
- perangkat seluler dan ultramobile.

Ari Rauch, wakil presiden arsitektur, grafis, dan perangkat lunak Intel, mengatakan satu arsitektur GPU akan memberi pengembang "kerangka kerja bersama," tetapi sebagai bagian dari arsitektur ini, perusahaan sedang mengembangkan "banyak mikroarsitektur yang memberikan kinerja paling efisien untuk masing-masingnya." beban kerja ini. "
Ponte Vecchio GPU didasarkan pada mikroarsitektur X
e khusus untuk HPC dan AI, dan fitur mikroarsitektur termasuk mesin matriks paralel yang fleksibel dengan matriks vektor, throughput tinggi perhitungan floating point penghitungan ganda (FP64) dan throughput cache dan memori yang sangat tinggi. Untuk format INT8, Bfloat16 dan FP32 akan ada Matrix Engine terpisah untuk pemrosesan paralel matriks (mungkin analog dari TensorCore), dan untuk FP64 akselerasi akan mencapai 40 kali untuk setiap unit komputasi.
"Beban kerja ini membutuhkan kinerja komputasi yang tinggi, jadi kami fokus pada penambahan sejumlah besar modul vektor dan matriks dan komputasi paralel yang disesuaikan dan dioptimalkan untuk beban kerja ini," kata Rauch.
Ponte Vecchio akan menjadi GPU pertama dari generasi baru. Ini mengimplementasikan beberapa teknologi baru yang telah dikembangkan Intel dalam beberapa tahun terakhir:
- proses produksi 7 nm;
- tata letak berlapis dari sirkuit terintegrasi Foveros 3D;
- EMIB (Embedded Multi-Die Interconnect Bridge) untuk menghubungkan beberapa kristal pada satu media;
- X e Link pada standar interkoneksi CXL baru (berdasarkan PCI Express 5.0) - akses ke GPU melalui ruang memori tunggal.

 Layered Foveros 3D Integrated Circuits dari Intel 2018 Presentation
Layered Foveros 3D Integrated Circuits dari Intel 2018 PresentationSpesifikasi teknis chip belum diumumkan. Mereka mengatakan bahwa dalam GPU ini akan ada ribuan Unit Eksekutif yang terhubung melalui XEMF (XE Memory Fabric) dengan memori dan cache.

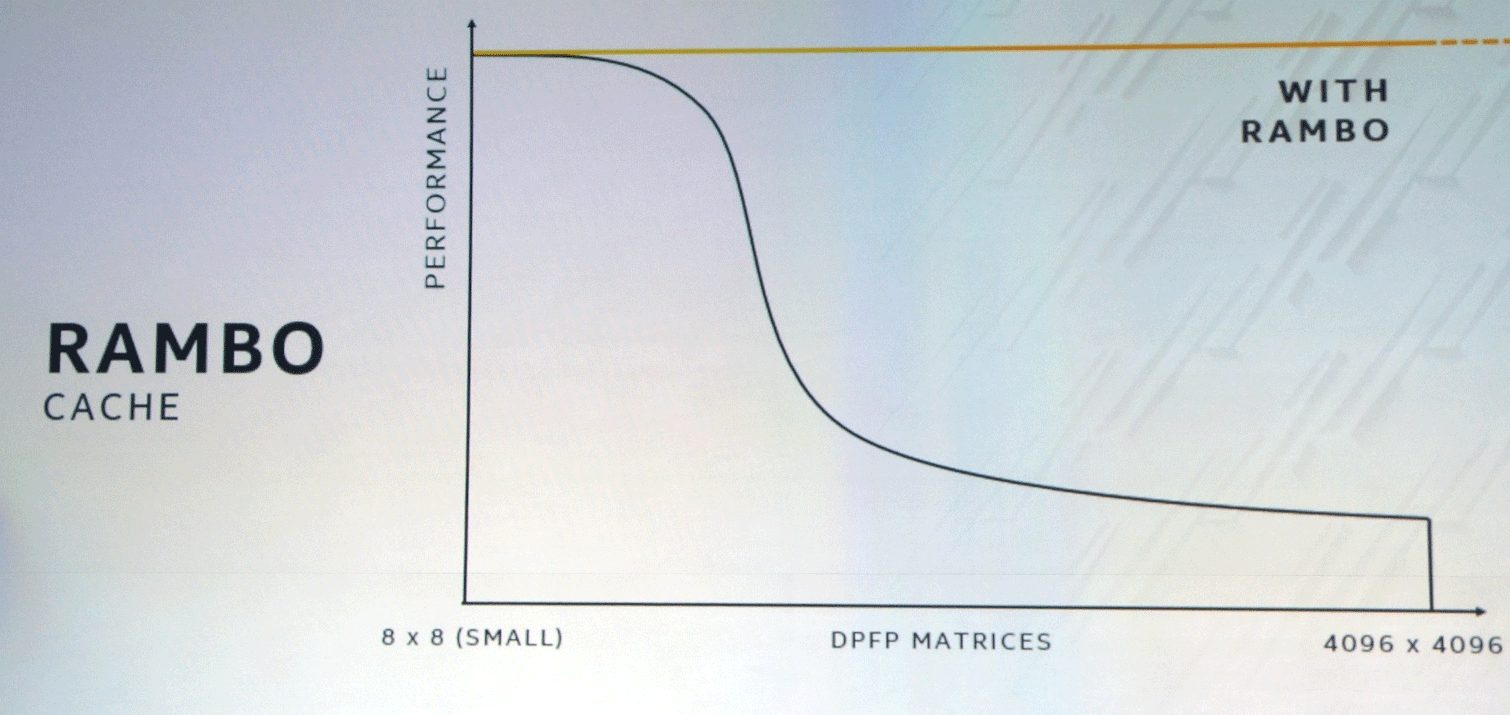
Bus XEMF bekerja dengan cache Rambo Cache ultra-cepat khusus untuk menghilangkan hambatan akses memori. Cache ini terhubung ke unit komputasi melalui Foveros, dan EMIB akan digunakan untuk menghubungkan memori HBM.
Kombinasi pendekatan SIMT dan SIMD khusus untuk GPU dan CPU, masing-masing, dan instruksi vektor panjang variabel akan memberikan peningkatan kinerja yang signifikan dalam beberapa kelas tugas.

Banyak yang berharap Intel bersaing dengan Nvidia dan AMD di pasar untuk pusat data dan AI. Ini bukan hanya tentang persaingan harga, tetapi juga munculnya platform teknologi alternatif, yang akan memacu kemajuan teknologi secara keseluruhan.
OneAPI: puncak abstraksi untuk besi heterogen
Selain pengumuman peralatan baru, Intel telah merilis versi beta dari antarmuka perangkat lunak terpadu oneAPI. Mereka dirancang untuk memfasilitasi pekerjaan pengembang yang, untuk mengoptimalkan program mereka secara maksimal, secara tradisional harus beralih di antara berbagai bahasa pemrograman dan perpustakaan menggunakan middleware dan kerangka kerja.
Secara default, ini diterima di industri bahwa pada level rendah, kode yang berbeda perlu disiapkan untuk setiap arsitektur. Sebagai contoh, TensorFlow awalnya sepenuhnya dioptimalkan pada saat rilis untuk GPU satu vendor (untuk Nvidia CUDA).
"OneAPI sedang mencoba menyelesaikan masalah ini dengan menawarkan antarmuka tingkat rendah yang umum untuk perangkat keras yang heterogen dengan kinerja tanpa kompromi," kata Bill Savage, wakil presiden divisi arsitektur, grafis dan perangkat lunak Intel. "Sehingga pengembang dapat menulis program langsung pada perangkat keras melalui bahasa dan perpustakaan yang umum digunakan untuk arsitektur dan vendor yang berbeda, serta memastikan bahwa middleware dan kerangka kerja bekerja pada oneAPI dan sepenuhnya dioptimalkan untuk pengembang yang berada di atas abstraksi ini."
Intel memuji oneAPI sebagai "standar terbuka untuk dukungan komunitas dan industri," yang akan memungkinkan "menggunakan kembali kode lintas arsitektur dan perangkat keras dari produsen yang berbeda."
Spesifikasi oneAPI akan mencakup bahasa pemrograman DPC ++ lintas-arsitektur standar berdasarkan C ++ dan SYCL, serta "API yang kuat untuk mempercepat fungsi-fungsi utama spesifik domain".
Selain kompiler DPC ++ dan pustaka API, alat khusus akan dirilis, termasuk VTune Inspector Advisor, debugger, dan "alat kompatibilitas" untuk porting kode CUDA (Nvidia) ke DPC ++.
Untuk merangsang transisi ke oneAPI, Intel meluncurkan kotak pasir di
DevCloud untuk mengembangkan dan menguji program pada sejumlah CPU, GPU, dan FPGA. Bekerja dengan kotak pasir tidak memerlukan instalasi perangkat keras atau perangkat lunak apa pun.
Sementara itu, pendapatan Nvidia untuk kuartal ini
naik menjadi $ 3 miliar , sementara di pasar pusat data, pertumbuhan selama tiga bulan adalah 11% ($ 726 juta). Penjualan prosesor V100 dan T4 memecahkan semua rekor. Intel masih melihatnya dari luar, tetapi kami sudah tahu apa jawabannya. Yang paling menarik baru saja dimulai.