
Pada forum RAIF 2019, yang diadakan di Skolkovo sebagai bagian dari Inovasi Terbuka, saya berbicara tentang bagaimana pengenalan model pembelajaran mesin sedang dilaksanakan. Sehubungan dengan karakteristik profesi, saya menghabiskan beberapa hari setiap minggu dalam produksi, memperkenalkan model pembelajaran mesin, dan sisa waktu mengembangkan model-model ini. Posting ini adalah rekaman dari laporan di mana saya mencoba merangkum pengalaman saya.
Kami mulai dengan menggambarkan proses dalam pukulan besar, secara bertahap masuk ke detail setiap tahap.
Apakah kita mengandalkan optimalisasi produksi berdasarkan hasil survei lengkap (idealnya), atau hanya mengumpulkan ide, "optimasi tambal sulam", hasilnya entah bagaimana
pembentukan daftar inisiatif . Penting untuk memahami area produksi mana yang akan kami optimalkan. Proses ini biasanya memakan waktu sekitar dua bulan.
Kemudian kita melanjutkan ke tahap
uji coba , akan memakan waktu tiga hingga empat bulan - kita harus membangun model dasar dan memahami apakah pembelajaran mesin berlaku untuknya, dan apa manfaatnya bagi bisnis.
Tahap berikutnya, yang jauh lebih lama, tidak ada banyak pembelajaran mesin tentang itu -
implementasi adalah ketika Anda perlu mengintegrasikan, membangun sistem saat ini dan mulai mendapatkan keuntungan yang kami prediksi di tahap kedua. Implementasi biasanya berlangsung dari enam bulan hingga sembilan bulan.
Tahap
kontrol menyelesaikan proses. Adalah satu hal untuk membuat model dan pertunjukan, dan satu lagi untuk mempertahankan model untuk beberapa waktu. Produksi berubah, peralatan mesin diganti. Dalam kondisi ini, model harus terus "berputar" dan mencari peluang baru untuk optimasi.
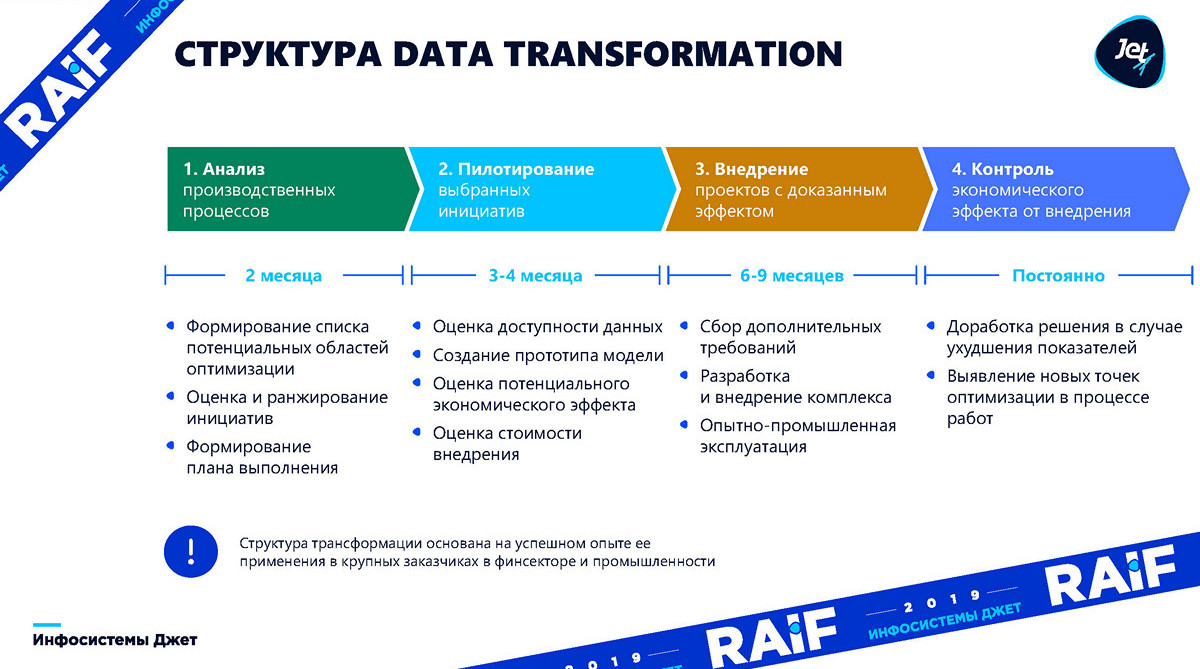
Sekarang dalam urutan yang lebih detail:
Mencari hipotesis
Dari mana datangnya hipotesis? Siapa yang akan mencalonkannya?
Biasanya umum untuk pergi ke departemen TI untuk hipotesis, tetapi orang-orang yang dapat mengkonfigurasi sistem bekerja di sana, tahu tentang integrasi dan tidak tahu apa-apa tentang pembelajaran mesin. Selain itu, mereka tidak begitu menyadari produksi. Mereka tidak memiliki kompetensi untuk memahami dalam praktik bagaimana pembelajaran mesin bekerja.
Percobaan nomor dua adalah menuju ke hipotesis produksi. Memang, spesialis yang dekat dengan produksi mengetahui fitur teknis dari proses, tetapi ... tidak tahu pembelajaran mesin. Karena itu, mereka tidak dapat mengatakan di mana itu berlaku dan di mana tidak.
Dalam hal ini, dari mana datangnya hipotesis? Untuk melakukan ini, mereka datang dengan posisi khusus - Kepala Digital Transformation Officer. Ini adalah orang yang terlibat dalam transformasi digital. Atau Chief Date Officer - seseorang yang mengetahui data dan bagaimana itu bisa diterapkan. Jika kedua orang ini tidak ada di perusahaan, maka hipotesis harus berasal dari manajemen puncak. Yaitu, spesialis yang sepenuhnya memahami bisnis dan bergerak dalam teknologi modern.
Jika perusahaan tidak memiliki Chief Digital Transformation Officer, atau Chief Date Officer, dan manajemen puncak tidak dapat melahirkan hipotesis, maka ... pesaing akan datang untuk menyelamatkan. Jika mereka telah mengimplementasikan sesuatu, ini tidak dapat diambil dari mereka. Tetapi, perusahaan integrator yang terhubung dengan proyek dapat mengetahui apa dan bagaimana dapat dioptimalkan.

Bagaimana cara memilih ide?
Empat faktor penting di sini:
- Omset proses untuk dioptimalkan.
- Penyimpangan yang signifikan dalam proses. Ada metodologi enam-sigma, yang menunjukkan bahwa semua proses harus menyimpang tidak lebih dari enam standar deviasi dari hasil mereka. Jika Anda memiliki lebih banyak penyimpangan ini, maka Anda perlu menguraikannya, dan pembelajaran mesin akan membantu.
- Ketersediaan dan ketersediaan data. Jika, misalnya, Anda menerima data dari sensor pada pengoperasian peralatan setelah 12 bulan, maka Anda tidak akan menerapkan pembelajaran mesin.
- Kompleksitas penerapan digitalisasi dalam proses. Biaya memperkenalkan model Anda, dibandingkan dengan biaya yang dapat dihematnya.
Apa datanya?
Struktur data adalah:
Terstruktur: beberapa tabel, bacaan - semuanya sederhana. Ketika kita ingin menggunakan data dari jejaring sosial, atau set foto, kita harus berurusan dengan data yang tidak terstruktur. Adalah perlu untuk meletakkan bahwa data seperti itu juga harus terstruktur, berubah menjadi angka-angka yang dapat dipahami oleh pembelajaran mesin. Jenis data ketiga adalah berulir. Jika kita bekerja dengan data yang berubah setiap milidetik, kita harus segera berpikir tentang load balancing: dapatkah sistem kita menahan kecepatan penerimaannya?

Menurut asal, data dibagi menjadi:
Otomatis - sensor menghasilkan semacam angka, kami percaya atau tidak. Tapi mereka hampir sama. Dimasukkan secara manual - di sini Anda perlu memahami bahwa mungkin ada kesalahan terkait faktor manusia. Dan modelnya harus tahan terhadap ini. Data eksternal - mungkin kita akan tertarik pada nilai tukar jika implementasinya terkait dengan transaksi keuangan, atau prakiraan cuaca jika kita memperkirakan pertukaran panas suhu. Hanya data statis yang dapat digunakan kembali.

Masalah data
- Kelengkapan - saat ketika beberapa data / bulan dapat dilewati.
- Kesalahan perubahan - jika, misalnya, sensor Anda memiliki kesalahan 5 milidetik, maka model dengan akurasi dua milidetik - Anda tidak akan dapat, karena data input mulai berbeda.
- Aksesibilitas online - jika Anda ingin membuat perkiraan "sekarang", data harus siap.
- Waktu penyimpanan - jika Anda ingin menggunakan tren tahunan, dan Anda perlu memperkirakan permintaan, dan data disimpan hanya selama enam bulan - Anda tidak akan membuat model.
Bekerja dengan data
Dengarkan profesional, tetapi hanya percaya data. Anda perlu pergi ke bengkel, berbicara dengan para profesional, pergi ke pabrik, berbicara dengan operator, memahami bisnis mereka. Tapi percayalah hanya data. Ada banyak contoh ketika operator mengatakan bahwa ini tidak mungkin - kami tunjukkan data - ternyata ini benar-benar terjadi. Contoh yang menarik: setelah model menunjukkan bahwa hari dalam seminggu memengaruhi produksi. Pada hari Senin - satu koefisien, pada hari Jumat - yang lain.
Efeknya hanya dapat dipahami dalam pertempuran - prototyping cepat sangat penting. Yang paling penting adalah dengan cepat melihat bagaimana model bekerja dalam kehidupan sehari-hari. Dalam presentasi dan pada laptop lokal, proyek mungkin terlihat sangat berbeda dari apa yang sebenarnya: sebagai aturan, sebenarnya masalah yang sama sekali berbeda menjadi prioritas.
Hanya model yang ditafsirkan yang memiliki peluang untuk ditingkatkan. Anda selalu perlu memahami dengan jelas mengapa model memutuskan dengan cara ini dan bukan sebaliknya.
Bekerja dengan metrik
Pada kenyataannya, ketergantungan pada ketepatan laba dapat berupa apa saja. Sampai kita memahami bagaimana keakuratan ini mempengaruhi efek, pertanyaan tentang keakuratan sama sekali tidak berarti. Anda selalu perlu menerjemahkan ke dalam laba. Grafik di bawah ini menunjukkan bahwa keuntungan dapat bervariasi tergantung pada keakuratan model. Bagan pertama menggambarkan betapa sulitnya untuk menentukan di muka tepat pada titik mana akurasi model cukup untuk pertumbuhan laba:
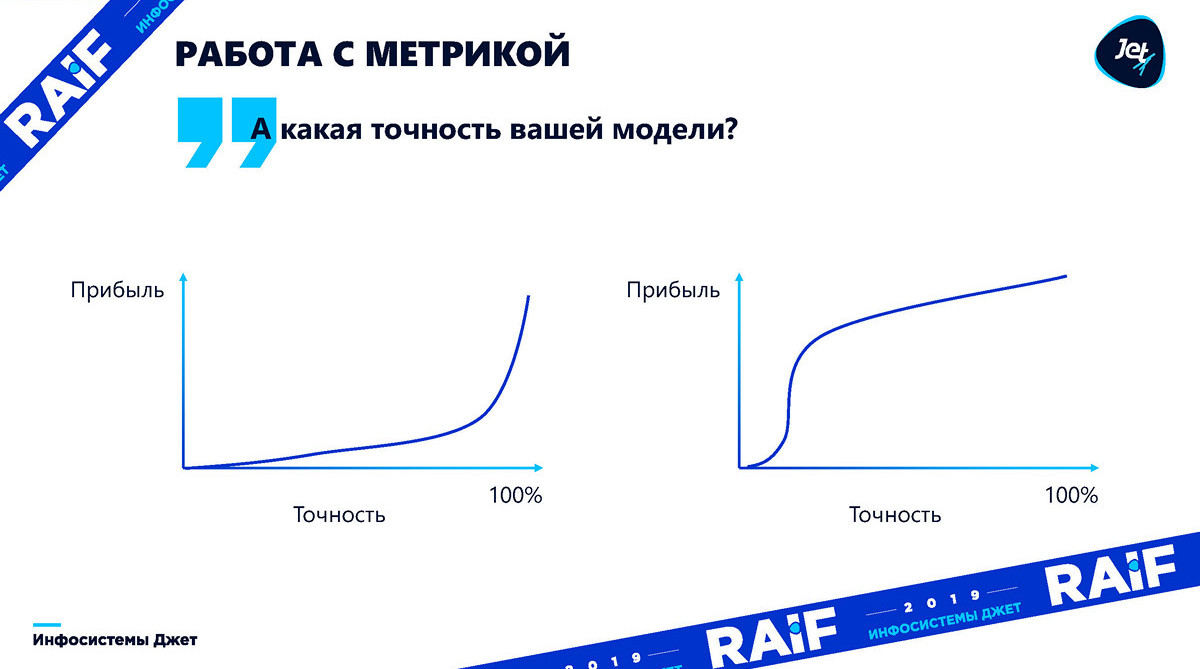
Selain itu, untuk beberapa kasus dengan akurasi model yang tidak memadai, itu hanya akan membawa kerugian:

Poin-poin penting tentang integrasi:
- Integrasi membutuhkan lebih banyak waktu daripada pengembangan model.
- Ide baru. Terkadang ternyata proyek tersebut menguntungkan di tempat yang tidak diharapkan.
- Pelatihan Orang beradaptasi lebih cepat daripada besi.
Poin lain yang sering dilupakan para pakar data adalah tujuan memperkenalkan model: perkiraan atau rekomendasi. Biasanya rekomendasi didasarkan pada model prediktif, tetapi dalam kasus ini model prediktif harus dibangun terutama, karena cukup sulit untuk menemukan kotak hitam minimum dengan efek tiba-tiba yang tidak menyenangkan. Jika kita berbicara tentang metrik kinerja, maka tergantung pada tujuan implementasi:
- Keluarkan perkiraan, - evaluasi hasil penerapan pengetahuan;
- Berikan rekomendasi - evaluasi perbandingan dengan proses yang lama.
Nuansa penting dari fase implementasi:
Implementasi / Pelatihan
- Literasi statistik - implementasi jauh lebih berhasil ketika karyawan lokal mulai beroperasi dengan ketentuan statistik yang benar.
- Motivasi berbagai unit struktural - setiap orang harus memahami mengapa ini terjadi, dan tidak takut pada perubahan.
- Perubahan organisasi - setidaknya satu karyawan akan melihat hasil model, yang berarti mereka akan mengubah pendekatan mereka terhadap proses. Sering kali ternyata orang tidak siap untuk ini.
Dukungan
Jangan lupa bahwa kondisinya berubah dan model harus terus "berputar" dan mencari peluang baru untuk optimasi. Berikut ini penting:
- Strategi manajemen model dan reaksi terhadap ramalan adalah sedikit promosi diri: kami di Jet Infosystems hanya banyak memikirkan hal ini dan mengembangkan sistem JET GALATEA kami sendiri.
- Faktor manusia - masalah utama model sering dikaitkan dengan penggunaannya, atau intervensi manusia, yang tidak dapat diramalkan model.
- Analisis rutin kerja dengan para profesional dari lapangan - tidak mungkin semuanya akan dikurangi menjadi satu angka, yang akan menunjukkan apa yang perlu ditingkatkan, akan perlu untuk menganalisis setiap ramalan atau rekomendasi yang meragukan. Bersiaplah untuk mempelajari profesi lain untuk berbicara dalam bahasa yang sama dengan teknologi dan operator perangkat di tempat kerja.

Diposting oleh Nikolay Knyazev, Kepala Kelompok Pembelajaran Mesin, Jet Infosystems