 Diagram komputer CS-1 menunjukkan bahwa sebagian besar didedikasikan untuk menyalakan dan mendinginkan Mesin Skala Wafer "prosesor-di-pelat" raksasa (WSE). Foto: Sistem Cerebras
Diagram komputer CS-1 menunjukkan bahwa sebagian besar didedikasikan untuk menyalakan dan mendinginkan Mesin Skala Wafer "prosesor-di-pelat" raksasa (WSE). Foto: Sistem CerebrasPada Agustus 2019, Cerebras Systems dan mitra pabrikannya TSMC mengumumkan
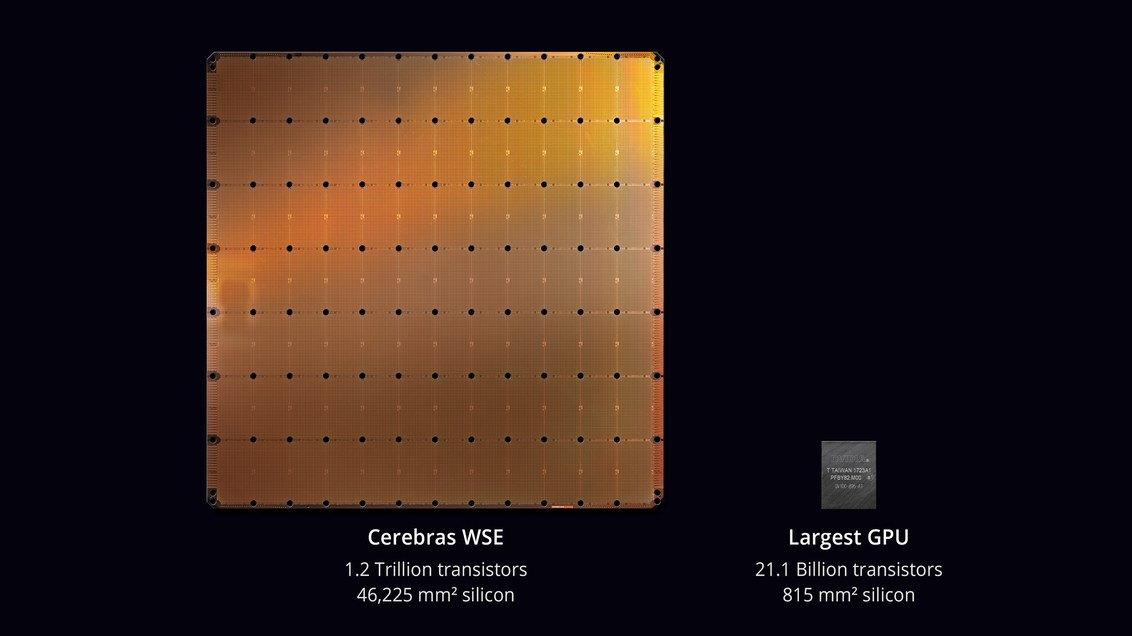
chip terbesar dalam sejarah teknologi komputer . Dengan luas 46.225 mm² dan 1,2 triliun transistor, chip Wafer Scale Engine (WSE) kira-kira 56,7 kali lebih besar dari GPU terbesar (21,1 miliar transistor, 815 mm²).
Skeptis mengatakan bahwa mengembangkan prosesor bukanlah tugas yang paling sulit. Tapi di sini bagaimana cara kerjanya di komputer sungguhan? Berapa persentase pekerjaan yang rusak? Apa daya dan pendinginan yang dibutuhkan? Berapa biaya mesin seperti itu?
Tampaknya para insinyur di Cerebras Systems dan TSMC mampu menyelesaikan masalah ini. Pada 18 November 2019, pada konferensi
Supercomputing 2019 , mereka secara resmi meluncurkan
CS-1 , "komputer tercepat di dunia untuk komputasi dalam bidang pembelajaran mesin dan kecerdasan buatan."
Salinan pertama CS-1 telah dikirim ke pelanggan. Salah satunya dipasang di Laboratorium Nasional Argonne dari Departemen Energi AS, yang mana perakitan superkomputer paling kuat di AS dari
modul Aurora pada arsitektur GPU Intel baru akan dimulai. Pelanggan lain adalah Laboratorium Nasional Livermore.
Prosesor dengan 400.000 core dirancang untuk pusat data untuk memproses komputasi di bidang pembelajaran mesin dan kecerdasan buatan. Cerebras mengklaim bahwa komputer melatih sistem AI berdasarkan pesanan yang lebih efisien daripada peralatan yang ada. Performa CS-1 setara dengan "ratusan server berbasis GPU" yang menghabiskan ratusan kilowatt. Pada saat yang sama, hanya menempati 15 unit di rak server dan mengkonsumsi sekitar 17 kW.
 Prosesor WSE. Foto: Sistem Cerebras
Prosesor WSE. Foto: Sistem CerebrasAndrew Feldman, CEO dan salah satu pendiri Cerebras Systems, mengatakan CS-1 adalah "komputer AI tercepat di dunia." Dia membandingkannya dengan kluster TPU Google dan mencatat bahwa masing-masing dari mereka "mengambil 10 rak dan mengkonsumsi lebih dari 100 kilowatt untuk menyediakan sepertiga dari kinerja instalasi CS-1 tunggal."
 Komputer CS-1. Foto: Sistem Cerebras
Komputer CS-1. Foto: Sistem CerebrasBelajar jaringan saraf besar dapat memakan waktu berminggu-minggu di komputer standar. Menginstal CS-1 dengan chip prosesor 400.000 core dan 1,2 triliun transistor melakukan tugas ini dalam hitungan menit atau bahkan detik,
tulis IEEE Spectrum. Namun, Cerebras tidak memberikan hasil tes nyata untuk menguji pernyataan kinerja tinggi seperti
tes MLPerf . Sebagai gantinya, perusahaan secara langsung menjalin kontak dengan pelanggan potensial - dan diizinkan untuk melatih model jaringan sarafnya sendiri pada CS-1.
Pendekatan ini tidak biasa, analis mengatakan: "Semua orang mengelola model mereka sendiri yang telah mereka kembangkan untuk bisnis mereka sendiri," kata
Karl Freund , seorang analis kecerdasan buatan di Moor Insights & Strategies. "Ini adalah satu-satunya hal yang penting bagi pelanggan."
Banyak perusahaan sedang mengembangkan chip khusus untuk AI, termasuk perwakilan industri tradisional seperti Intel, Qualcomm, serta berbagai startup di AS, Inggris dan Cina. Google telah mengembangkan chip khusus untuk jaringan saraf - prosesor tensor, atau TPU. Beberapa pabrikan lain mengikuti. Sistem AI beroperasi dalam mode multi-threaded, dan hambatannya adalah memindahkan data di antara chip: "Menghubungkan chip sebenarnya memperlambatnya dan membutuhkan banyak energi,"
jelas Subramanian Iyer, seorang profesor di University of California di Los Angeles yang berspesialisasi dalam mengembangkan chip untuk kecerdasan buatan. Pabrikan peralatan mengeksplorasi banyak opsi berbeda. Beberapa berusaha untuk memperluas koneksi antarproses.
Didirikan tiga tahun lalu, startup Cerebras, yang menerima lebih dari $ 200 juta dalam pembiayaan ventura, telah mengusulkan pendekatan baru. Idenya adalah untuk menyimpan semua data pada chip raksasa - dan dengan demikian mempercepat perhitungan.

Seluruh pelat sirkuit mikro dibagi menjadi 400.000 bagian yang lebih kecil (inti), mengingat beberapa di antaranya tidak akan berfungsi. Chip ini dirancang dengan kemampuan untuk rute di sekitar area yang rusak. Kernel yang dapat diprogram SLAC (Sparse Linear Algebra Cores) dioptimalkan untuk aljabar linier, yaitu untuk perhitungan dalam ruang vektor. Perusahaan juga mengembangkan teknologi “sparsity harvesting” untuk meningkatkan kinerja komputasi di bawah beban kerja yang jarang (mengandung nol), seperti pembelajaran yang mendalam. Vektor dan matriks dalam ruang vektor biasanya mengandung banyak elemen nol (dari 50% hingga 98%), sehingga pada GPU tradisional, sebagian besar perhitungan terbuang sia-sia. Sebaliknya, SLAC core pra-filter data nol.
Komunikasi antar core disediakan oleh sistem Swarm dengan throughput 100 petabit per detik. Perutean perangkat keras, latensi diukur dalam nanodetik.
Biaya komputer tidak disebut. Pakar independen percaya bahwa harga sebenarnya tergantung pada persentase pernikahan. Juga, kinerja chip dan berapa core yang beroperasi dalam sampel nyata tidak dapat dipercaya.
Perangkat lunak
Cerebras telah mengumumkan beberapa detail tentang bagian perangkat lunak dari sistem CS-1. Perangkat lunak ini memungkinkan pengguna untuk membuat model pembelajaran mesin mereka sendiri menggunakan kerangka kerja standar seperti
PyTorch dan
TensorFlow . Sistem kemudian mendistribusikan 400.000 core dan 18 gigabyte memori SRAM pada chip ke lapisan jaringan saraf sehingga semua lapisan menyelesaikan pekerjaan mereka pada waktu yang sama dengan tetangga mereka (tugas optimasi). Akibatnya, informasi diproses oleh semua lapisan tanpa penundaan. Dengan subsistem I / O Ethernet 100-Gigabit 12-port, CS-1 dapat memproses data 1,2 terabit per detik.
Konversi dari jaringan saraf sumber ke representasi yang dapat dieksekusi yang dioptimalkan (Representasi Intermediate Aljabar Linear Cerebras, CLAIR) dilakukan oleh Cerebras Graph Compiler (CGC). Kompiler mengalokasikan sumber daya komputasi dan memori untuk setiap bagian grafik, dan kemudian membandingkannya dengan array komputasi. Kemudian, jalur komunikasi dihitung sesuai dengan struktur internal pelat, unik untuk setiap jaringan.
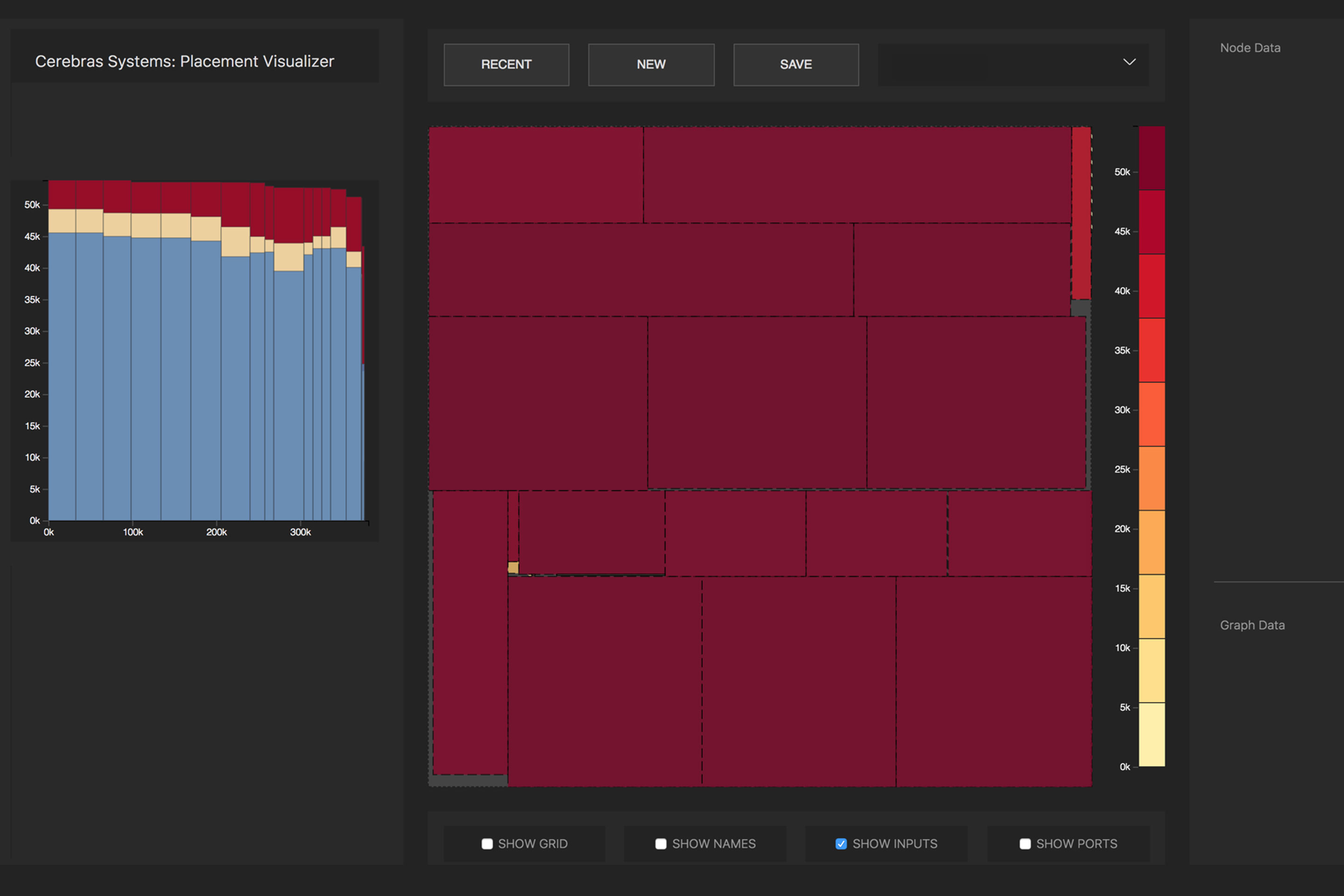 Distribusi operasi matematika dari jaringan saraf oleh inti prosesor. Foto : Cerebras
Distribusi operasi matematika dari jaringan saraf oleh inti prosesor. Foto : CerebrasKarena ukuran besar WSE, semua lapisan dalam jaringan saraf secara bersamaan terletak di atasnya dan bekerja secara paralel. Pendekatan ini unik untuk WSE - tidak ada perangkat lain yang memiliki memori internal yang cukup untuk memuat semua lapisan pada satu chip sekaligus, kata Cerebras. Arsitektur seperti itu dengan penempatan seluruh jaringan saraf pada sebuah chip memberikan keuntungan besar karena throughputnya yang tinggi dan latensi yang rendah.
Perangkat lunak ini dapat melakukan tugas pengoptimalan untuk banyak komputer, memungkinkan sekelompok komputer untuk bertindak sebagai satu mesin besar. Sekelompok komputer 32 CS-1 menunjukkan peningkatan kinerja sekitar 32 kali lipat, yang menunjukkan skalabilitas yang sangat baik. Feldman mengatakan ini berbeda dari cluster berbasis GPU: “Hari ini, ketika Anda membuat sekelompok GPU, itu tidak berperilaku seperti satu mesin besar. Anda mendapatkan banyak mobil kecil. "
Siaran pers mengatakan bahwa Laboratorium Nasional Argonne telah bekerja dengan Cerebras selama dua tahun: "Dengan menggunakan CS-1, kami secara dramatis meningkatkan kecepatan pelatihan jaringan saraf, yang memungkinkan kami untuk meningkatkan produktivitas penelitian kami dan mencapai kesuksesan yang signifikan."
Salah satu beban pertama untuk CS-1 adalah
simulasi jaringan saraf dari tabrakan lubang hitam dan gelombang gravitasi, yang dibuat sebagai hasil dari tabrakan ini. Versi sebelumnya dari tugas ini bekerja pada 1024 dari 4392 node superkomputer
Theta .