 Berdasarkan penampilan saya di Highload ++ dan DataFest Minsk 2019
Berdasarkan penampilan saya di Highload ++ dan DataFest Minsk 2019Bagi banyak orang, surat hari ini adalah bagian integral dari kehidupan online. Dengan bantuannya, kami melakukan korespondensi bisnis, menyimpan semua jenis informasi penting yang berkaitan dengan keuangan, pemesanan hotel, checkout, dan banyak lagi. Pada pertengahan 2018, kami merumuskan strategi pengembangan produk surat. Apa yang seharusnya menjadi surat modern?
Mail harus
pintar , yaitu, membantu pengguna menavigasi jumlah informasi yang meningkat: filter, struktur, dan menyediakannya dengan cara yang paling nyaman. Ini harus
bermanfaat , memungkinkan langsung di kotak surat untuk menyelesaikan berbagai masalah, misalnya, membayar denda (fungsi yang, sayangnya, saya gunakan). Dan pada saat yang sama, tentu saja, surat harus memberikan perlindungan informasi dengan memotong spam dan melindungi dari peretasan, yaitu
aman .
Area-area ini menentukan sejumlah tugas utama, yang banyak di antaranya dapat diselesaikan secara efektif menggunakan pembelajaran mesin. Berikut adalah contoh fitur yang ada yang dikembangkan sebagai bagian dari strategi - satu untuk setiap arah.
- Balas Cerdas . Ada fungsi jawaban cerdas dalam surat. Jaringan saraf menganalisis teks surat itu, memahami makna dan tujuannya, dan sebagai hasilnya menawarkan tiga pilihan jawaban yang paling cocok: positif, negatif dan netral. Ini membantu menghemat waktu saat menjawab surat secara signifikan, dan juga sering merespons yang tidak standar dan menyenangkan untuk diri sendiri.
- Pengelompokan surat yang terkait dengan pesanan di toko online. Kami sering melakukan pembelian di Internet, dan, sebagai aturan, toko dapat mengirim beberapa surat untuk setiap pesanan. Misalnya, dari AliExpress, layanan terbesar, ada banyak surat untuk satu pesanan, dan kami memperkirakan bahwa dalam kasus terminal jumlahnya dapat mencapai 29. Oleh karena itu, menggunakan model Pengakuan Entitas Bernama, kami memilih nomor pesanan dan informasi lain dari teks dan grup. semua huruf dalam satu utas. Kami juga menunjukkan informasi dasar tentang pesanan dalam kotak terpisah, yang memfasilitasi pekerjaan dengan jenis huruf ini.
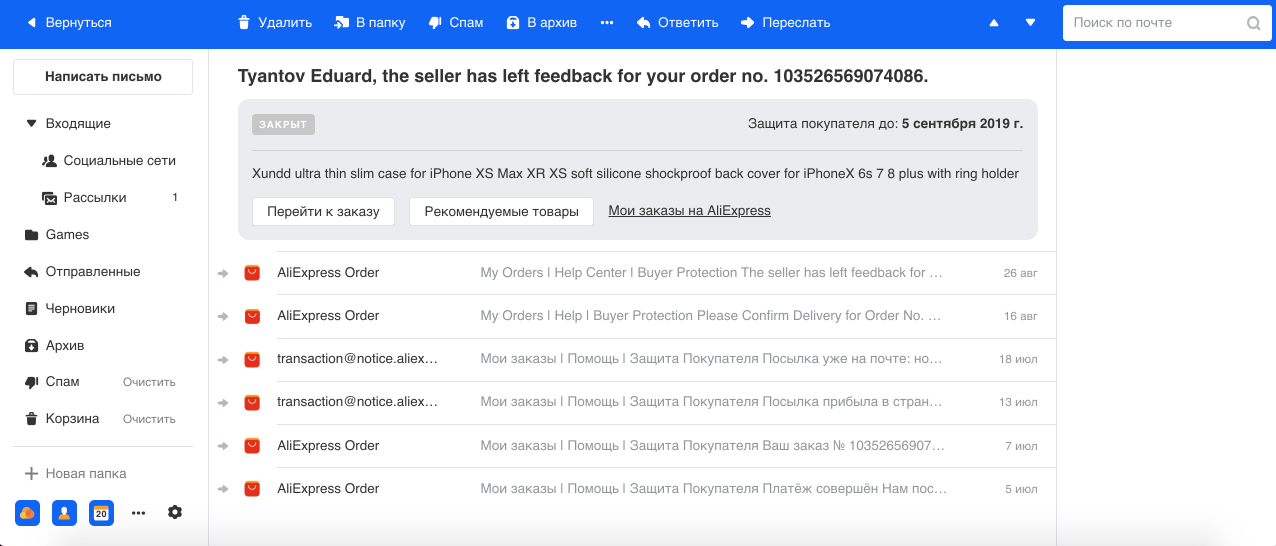
- Antiphishing . Phishing adalah jenis email penipuan yang sangat berbahaya dengan bantuan penyerang yang mencoba mendapatkan informasi keuangan (termasuk kartu bank pengguna) dan login. Surat-surat seperti itu meniru yang asli yang dikirim oleh layanan, termasuk secara visual. Oleh karena itu, dengan bantuan Computer Vision, kami mengenali logo dan gaya surat perusahaan besar (misalnya, Mail.ru, Sberbank, Alpha) dan mempertimbangkannya, bersama dengan teks dan tanda-tanda lain dalam klasifikasi spam dan phishing kami.
Pembelajaran mesin
Sedikit tentang pembelajaran mesin di surat pada umumnya. Mail adalah sistem yang sangat dimuat: di server kami, rata-rata 1,5 miliar surat per hari beralih ke 30 juta pengguna DAU. Melayani semua fungsi dan fitur yang diperlukan dari sekitar 30 sistem pembelajaran mesin.
Setiap huruf melewati seluruh konveyor klasifikasi. Pertama, kami memotong spam dan meninggalkan email yang bagus. Pengguna sering tidak memperhatikan operasi anti-spam, karena 95-99% dari spam bahkan tidak masuk ke folder yang sesuai. Pengenalan spam adalah bagian yang sangat penting dari sistem kami, dan yang paling sulit, karena di bidang anti-spam ada adaptasi yang konstan antara sistem pertahanan dan serangan, yang memberikan tantangan rekayasa berkelanjutan untuk tim kami.
Selanjutnya, kami memisahkan surat dari orang dan robot. Surat-surat dari orang-orang adalah yang paling penting, jadi bagi mereka kami menyediakan fungsi seperti Balas Cerdas. Surat-surat dari robot dibagi menjadi dua bagian: transaksional - ini adalah surat-surat penting dari layanan, misalnya, konfirmasi pembelian atau pemesanan hotel, keuangan, dan informasi - ini adalah iklan bisnis, diskon.
Kami percaya bahwa surat transaksional sama nilainya dengan korespondensi pribadi. Mereka harus siap, karena sering kali perlu mencari informasi tentang pemesanan atau memesan tiket dengan cepat, dan kami menghabiskan waktu mencari surat-surat ini. Karenanya, untuk kenyamanan, kami secara otomatis membaginya menjadi enam kategori utama: perjalanan, pemesanan, keuangan, tiket, pendaftaran, dan akhirnya, denda.
Nawala adalah grup terbesar dan mungkin kurang penting yang tidak memerlukan reaksi instan, karena tidak ada perubahan signifikan dalam kehidupan pengguna jika ia tidak membaca surat seperti itu. Di antarmuka baru kami, kami mengelompokkannya menjadi dua utas: jejaring sosial dan buletin, sehingga secara visual membersihkan kotak surat dan hanya menyisakan surat-surat penting saja.

Operasi
Sejumlah besar sistem menyebabkan banyak kesulitan dalam operasi. Setelah semua, model menurun seiring waktu, seperti perangkat lunak apa pun: tanda-tanda rusak, mesin gagal, kode bergulir. Selain itu, data terus berubah: yang baru ditambahkan, pola perilaku pengguna diubah, dll., Oleh karena itu, model tanpa dukungan yang tepat akan bekerja lebih buruk dan lebih buruk dari waktu ke waktu.
Kita tidak boleh lupa bahwa pembelajaran mesin yang lebih dalam menembus kehidupan pengguna, semakin besar dampaknya terhadap ekosistem, dan, sebagai akibatnya, semakin banyak kerugian finansial atau keuntungan yang bisa didapat pemain pasar. Oleh karena itu, di semakin banyak area, pemain beradaptasi dengan pekerjaan algoritma-ML (contoh klasik adalah iklan, pencarian, dan anti-spam yang telah disebutkan).
Juga, tugas pembelajaran mesin memiliki fitur: perubahan apa pun, meskipun tidak signifikan, dalam sistem dapat menimbulkan banyak pekerjaan dengan model: bekerja dengan data, pelatihan ulang, penyebaran, yang dapat berlangsung selama berminggu-minggu atau berbulan-bulan. Oleh karena itu, semakin cepat lingkungan di mana model Anda beroperasi, semakin banyak upaya yang dibutuhkan dukungan mereka. Sebuah tim dapat membuat banyak sistem dan menikmatinya, dan kemudian menghabiskan hampir semua sumber daya untuk dukungan mereka, tanpa kemampuan untuk melakukan sesuatu yang baru. Kami pernah mengalami situasi seperti itu di tim anti-spam. Dan mereka membuat kesimpulan yang jelas bahwa pemeliharaan harus dilakukan secara otomatis.
Otomasi
Apa yang bisa otomatis? Bahkan hampir semuanya. Saya telah mengidentifikasi empat bidang yang menentukan infrastruktur pembelajaran mesin:
- pengumpulan data;
- pendidikan berkelanjutan;
- penyebaran;
- pengujian & pemantauan.
Jika lingkungan tidak stabil dan terus berubah, maka seluruh infrastruktur di sekitar model jauh lebih penting daripada model itu sendiri. Ini mungkin merupakan penggolong linier lama yang baik, tetapi jika Anda menerapkan tanda-tanda dengan benar dan membangun umpan balik yang baik dari pengguna, itu akan bekerja jauh lebih baik daripada model State-Of-The-Art dengan semua bel dan peluit.
Umpan balik
Siklus ini menggabungkan pengumpulan data, pelatihan lebih lanjut dan penyebaran - pada kenyataannya, seluruh siklus memperbarui model. Mengapa ini penting? Lihatlah jadwal pendaftaran melalui pos:

Pengembang pembelajaran mesin telah memperkenalkan model antibot yang mencegah bot dari mendaftar di pos. Grafik turun ke nilai di mana hanya pengguna nyata yang tersisa. Semuanya hebat! Tapi empat jam berlalu, botvod mengencangkan skrip mereka, dan semuanya kembali ke titik awal. Dalam implementasi ini, pengembang menghabiskan sebulan menambahkan fitur dan model pelatihan, tetapi spammer mampu beradaptasi dalam empat jam.
Agar tidak begitu menyakitkan dan tidak harus mengulang semuanya nanti, kita harus berpikir tentang bagaimana loop umpan balik akan terlihat dan apa yang akan kita lakukan jika lingkungan berubah. Mari kita mulai dengan mengumpulkan data - ini adalah bahan bakar untuk algoritma kami.
Pengumpulan data
Jelas bahwa jaringan saraf modern, semakin banyak data, semakin baik, dan mereka, pada kenyataannya, menghasilkan pengguna produk. Pengguna dapat membantu kami dengan menandai data, tetapi Anda tidak dapat menyalahgunakannya, karena pada titik tertentu pengguna akan lelah menyelesaikan model Anda dan mereka akan beralih ke produk lain.
Salah satu kesalahan yang paling umum (di sini saya membuat referensi tentang Andrew Ng) adalah bahwa orientasi ke metrik pada dataset uji terlalu kuat, dan bukan dengan umpan balik dari pengguna, yang sebenarnya merupakan ukuran utama kualitas pekerjaan, karena kami membuat produk untuk pengguna. Jika pengguna tidak memahami atau tidak menyukai karya model, maka semuanya mudah rusak.
Oleh karena itu, pengguna harus selalu dapat memberikan suara, harus memberinya alat untuk umpan balik. Jika kami berpikir bahwa surat yang terkait dengan keuangan telah tiba di dalam kotak, kami perlu menandainya "keuangan" dan menggambar tombol yang dapat diklik pengguna dan mengatakan bahwa ini bukan keuangan.
Kualitas umpan balik
Mari kita bicara tentang kualitas umpan balik pengguna. Pertama, Anda dan pengguna dapat memberikan arti berbeda dalam satu konsep. Sebagai contoh, Anda dan manajer produk berpikir bahwa "keuangan" adalah surat dari bank, dan pengguna percaya bahwa surat dari nenek saya tentang pensiun juga mengacu pada keuangan. Kedua, ada pengguna yang suka menekan tombol tanpa berpikir. Ketiga, pengguna mungkin sangat keliru dalam kesimpulannya. Contoh nyata dari praktik kami adalah pengenalan pengelompokan
spam Nigeria , jenis spam yang sangat lucu, ketika pengguna diminta untuk mengumpulkan beberapa juta dolar dari kerabat yang tiba-tiba ditemukan jauh di Afrika. Setelah memperkenalkan pengelompokan ini, kami memeriksa klik “No spam” pada surat-surat ini, dan ternyata 80% di antaranya adalah spam Nigeria yang berair, yang menunjukkan bahwa pengguna bisa sangat percaya.
Dan jangan lupa bahwa tidak hanya orang yang dapat menyodok tombol, tetapi semua jenis bot yang berpura-pura menjadi browser. Jadi umpan balik mentah tidak baik untuk belajar. Apa yang dapat dilakukan dengan informasi ini?
Kami menggunakan dua pendekatan:
- Umpan balik dari ML terkait . Sebagai contoh, kami memiliki sistem antibot online, yang, seperti yang saya sebutkan, membuat keputusan cepat berdasarkan sejumlah tanda. Dan ada sistem lambat kedua yang berfungsi ex post. Dia memiliki lebih banyak data tentang pengguna, tentang perilakunya, dll. Akibatnya, keputusan yang paling seimbang dibuat, masing-masing, ia memiliki akurasi dan kelengkapan yang lebih tinggi. Anda dapat mengarahkan perbedaan dalam pekerjaan sistem ini ke yang pertama sebagai data pelatihan. Dengan demikian, sistem yang lebih sederhana akan selalu berusaha untuk lebih dekat dengan kinerja yang lebih kompleks.
- Klasifikasi klik . Anda dapat dengan mudah mengklasifikasikan setiap klik pengguna, mengevaluasi validitas dan kemampuannya untuk digunakan. Kami melakukan ini dalam surat anti-spam menggunakan atribut pengguna, riwayatnya, atribut pengirim, teks itu sendiri dan hasil dari pengklasifikasi. Hasilnya, kami mendapatkan sistem otomatis yang memvalidasi umpan balik pengguna. Dan karena itu perlu untuk melatihnya lebih jarang, pekerjaannya dapat menjadi yang utama untuk semua sistem lainnya. Ketepatan adalah prioritas utama dalam model ini, karena melatih model tentang data yang tidak akurat penuh dengan konsekuensi.
Sementara kami membersihkan data dan melatih kembali sistem ML kami, kami tidak boleh melupakan pengguna, karena bagi kami ribuan, jutaan kesalahan pada grafik adalah statistik, dan bagi pengguna, setiap bug adalah tragedi. Selain fakta bahwa pengguna perlu hidup dengan kesalahan Anda dalam produk, dia, setelah umpan balik, mengharapkan pengecualian dari situasi yang sama di masa depan. Oleh karena itu, Anda harus selalu memberi pengguna tidak hanya kesempatan untuk memilih, tetapi juga memperbaiki perilaku sistem ML, menciptakan, misalnya, heuristik pribadi untuk setiap klik umpan balik, dalam hal surat, dimungkinkan untuk menyaring pesan tersebut dengan pengirim dan header untuk pengguna ini.
Anda juga perlu mengatur model berdasarkan beberapa laporan atau panggilan untuk mendukung dalam mode semi-otomatis atau manual, sehingga pengguna lain juga tidak mengalami masalah serupa.
Heuristik untuk Belajar
Ada dua masalah dengan heuristik dan kruk ini. Yang pertama adalah bahwa jumlah kruk yang terus bertambah sulit dipertahankan, belum lagi kualitas dan kinerja jarak jauhnya. Masalah kedua adalah bahwa kesalahan mungkin bukan frekuensi, dan beberapa klik untuk melatih ulang model tidak akan cukup. Tampaknya kedua efek yang tidak terkait ini dapat diratakan secara substansial jika pendekatan berikut diterapkan.
- Buat kruk sementara.
- Kami mengarahkan data dari itu ke model, itu diambil secara teratur, termasuk data yang diterima. Di sini, tentu saja, penting bahwa heuristik memiliki akurasi tinggi agar tidak mengurangi kualitas data dalam set pelatihan.
- Lalu kami menggantungkan pemantauan pada pengoperasian kruk, dan jika setelah beberapa saat kruk tidak lagi berfungsi dan sepenuhnya tertutup oleh model, maka Anda dapat dengan aman melepasnya. Sekarang masalah ini tidak mungkin terulang.
Jadi pasukan kruk sangat berguna. Yang utama adalah bahwa layanan mereka mendesak, tidak permanen.
Pendidikan lanjutan
Pelatihan ulang adalah proses menambahkan data baru yang diperoleh sebagai hasil umpan balik dari pengguna atau sistem lain, dan melatih model yang ada pada mereka. Mungkin ada beberapa masalah dengan pelatihan ulang:
- Model mungkin tidak mendukung pendidikan lebih lanjut, dan belajar hanya dari awal.
- Tidak ada dalam buku alam tertulis bahwa melanjutkan pendidikan pasti akan meningkatkan kualitas kerja dalam produksi. Seringkali itu terjadi justru sebaliknya, yaitu hanya kemunduran yang mungkin terjadi.
- Perubahan bisa tidak dapat diprediksi. Ini adalah poin yang agak halus yang telah kami identifikasi untuk diri kami sendiri. Bahkan jika model baru dalam uji A / B menunjukkan hasil yang serupa dibandingkan dengan yang sekarang, ini tidak berarti sama sekali bahwa itu akan bekerja secara identik. Pekerjaan mereka mungkin berbeda dalam satu persen, yang dapat membawa kesalahan baru atau mengembalikan yang sudah diperbaiki. Baik kami dan pengguna sudah tahu bagaimana hidup dengan kesalahan saat ini, dan ketika sejumlah besar kesalahan baru terjadi, pengguna juga mungkin tidak mengerti apa yang terjadi, karena ia mengharapkan perilaku yang dapat diprediksi.
Oleh karena itu, hal terpenting dalam pelatihan ulang dijamin untuk memperbaiki model, atau setidaknya tidak memperburuknya.
Hal pertama yang terlintas dalam pikiran ketika kita berbicara tentang melanjutkan pendidikan adalah pendekatan Pembelajaran Aktif. Apa artinya ini? Sebagai contoh, classifier menentukan apakah surat itu terkait dengan keuangan, dan di sekitar perbatasan pengambilan keputusan, kami menambahkan pilihan contoh yang ditandai. Ini berfungsi dengan baik, misalnya, dalam periklanan, di mana ada banyak umpan balik dan Anda dapat melatih model secara online. Dan jika ada sedikit umpan balik, maka kami mendapatkan sampel yang sangat bias relatif terhadap produksi distribusi data, atas dasar yang tidak mungkin untuk mengevaluasi perilaku model selama operasi.
Sebenarnya, tujuan kami adalah untuk melestarikan pola lama, model yang sudah dikenal, dan mendapatkan yang baru. Di sini, kesinambungan itu penting. Model, yang sering kami luncurkan dengan susah payah, sudah berfungsi, sehingga kami bisa fokus pada kinerjanya.
Dalam surat, berbagai model digunakan: pohon, linier, jaringan saraf. Untuk masing-masing, kami membuat algoritma pelatihan ulang kami sendiri. Dalam proses pelatihan ulang, kami tidak hanya mendapatkan data baru, tetapi seringkali fitur baru yang akan kami perhitungkan dalam semua algoritme di bawah ini.
Model linier
Katakanlah kita memiliki regresi logistik. Kami membuat model kerugian dari komponen-komponen berikut:
- LogLoss pada data baru;
- kami mengatur bobot tanda baru (kami tidak menyentuh yang lama);
- kita belajar dari data lama untuk menjaga pola lama;
- dan, mungkin, yang paling penting: kita lampirkan Regularisasi Harmonik, yang menjamin sedikit perubahan bobot relatif terhadap model lama sesuai dengan norma.
Karena setiap komponen Kerugian memiliki koefisien, kita dapat memilih nilai optimal untuk tugas kita untuk validasi silang atau berdasarkan persyaratan produk.

Pohon
Mari kita beralih ke pohon keputusan. Kami memfilmkan algoritma pelatihan ulang pohon berikut:
- Hutan berisi 100-300 pohon bekerja di atas pohon, yang dilatih tentang kumpulan data lama.
- Pada akhirnya, kami menghapus M = 5 buah dan menambahkan 2M = 10 yang baru, dilatih pada seluruh kumpulan data, tetapi dengan bobot tinggi dari data baru, yang secara alami menjamin perubahan bertahap dalam model.
Jelas, seiring waktu, jumlah pohon meningkat secara signifikan, dan mereka harus dikurangi secara berkala agar sesuai dengan timing. Untuk melakukan ini, kami menggunakan Distilasi Pengetahuan (KD) yang ada di mana-mana. Secara singkat tentang prinsip kerjanya.
- Kami memiliki model "kompleks" saat ini. Kami memulainya pada set data pelatihan dan mendapatkan distribusi probabilitas kelas pada output.
- Selanjutnya, kami mengajarkan model siswa (model dengan pohon lebih sedikit dalam kasus ini) untuk mengulangi hasil model, menggunakan distribusi kelas sebagai variabel target.
- Penting untuk dicatat di sini bahwa kami tidak menggunakan markup kumpulan data dengan cara apa pun, dan oleh karena itu kami dapat menggunakan data sewenang-wenang. Tentu saja, kami menggunakan sampel data dari aliran pertempuran sebagai sampel pelatihan untuk model siswa. Dengan demikian, set pelatihan memungkinkan kami untuk memastikan keakuratan model, dan aliran sampel memastikan kinerja yang sama pada distribusi produksi, mengimbangi bias dari sampel pelatihan.
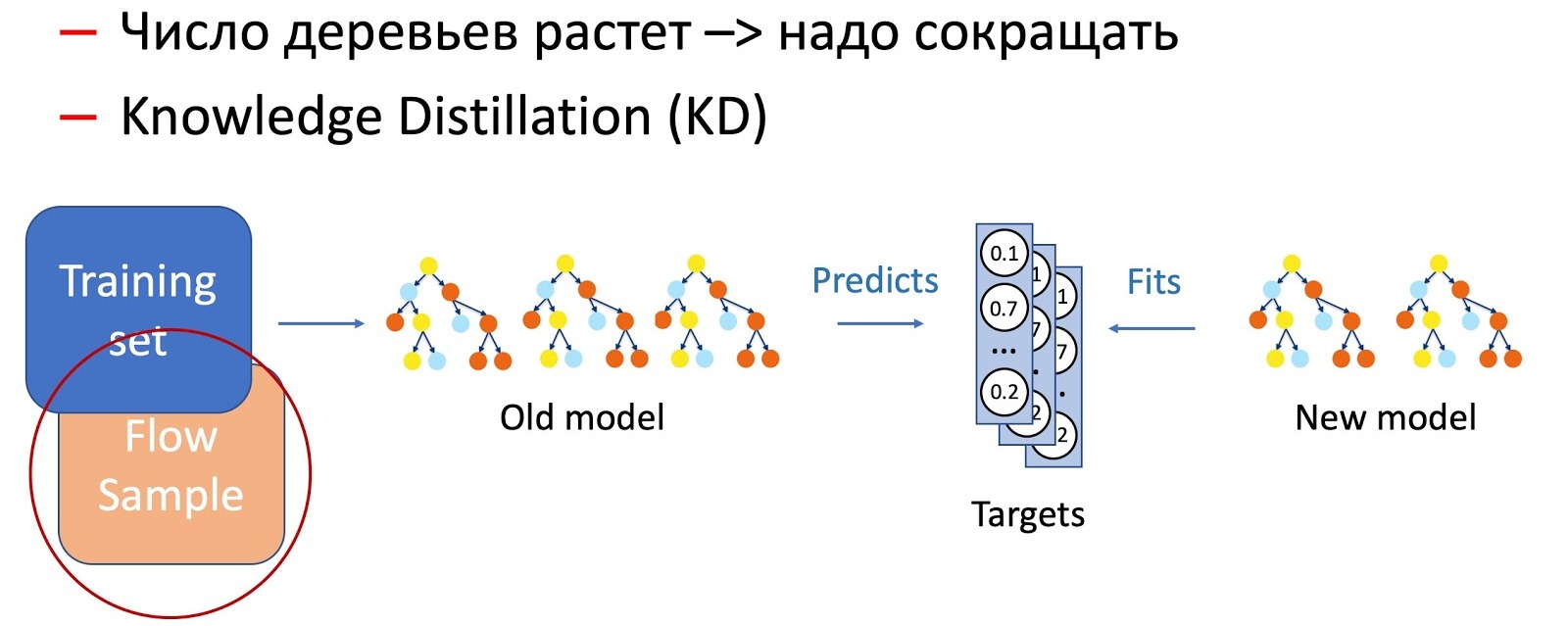
Kombinasi kedua teknik ini (menambah pohon dan mengurangi jumlah mereka secara berkala dengan menggunakan Distilasi Pengetahuan) memastikan pengenalan pola-pola baru dan kelanjutan yang lengkap.
Dengan bantuan KD, kami juga melakukan pembedaan operasi dengan karakteristik model, misalnya, penghapusan karakteristik dan bekerja pada lintasan. Dalam kasus kami, kami memiliki sejumlah fitur statistik penting (oleh pengirim, hash teks, URL, dll.), Yang disimpan dalam database yang memiliki properti untuk ditolak. Model ini, tentu saja, tidak siap untuk perkembangan acara seperti itu, karena tidak ada situasi kegagalan dalam set pelatihan. Dalam kasus seperti itu, kami menggabungkan teknik KD dan augmentasi: ketika melatih untuk sebagian data, kami menghapus atau nol tanda-tanda yang diperlukan, dan kami mengambil label (output dari model saat ini) sebagai yang awal, model siswa mengajarkan kami untuk mengulangi distribusi ini.
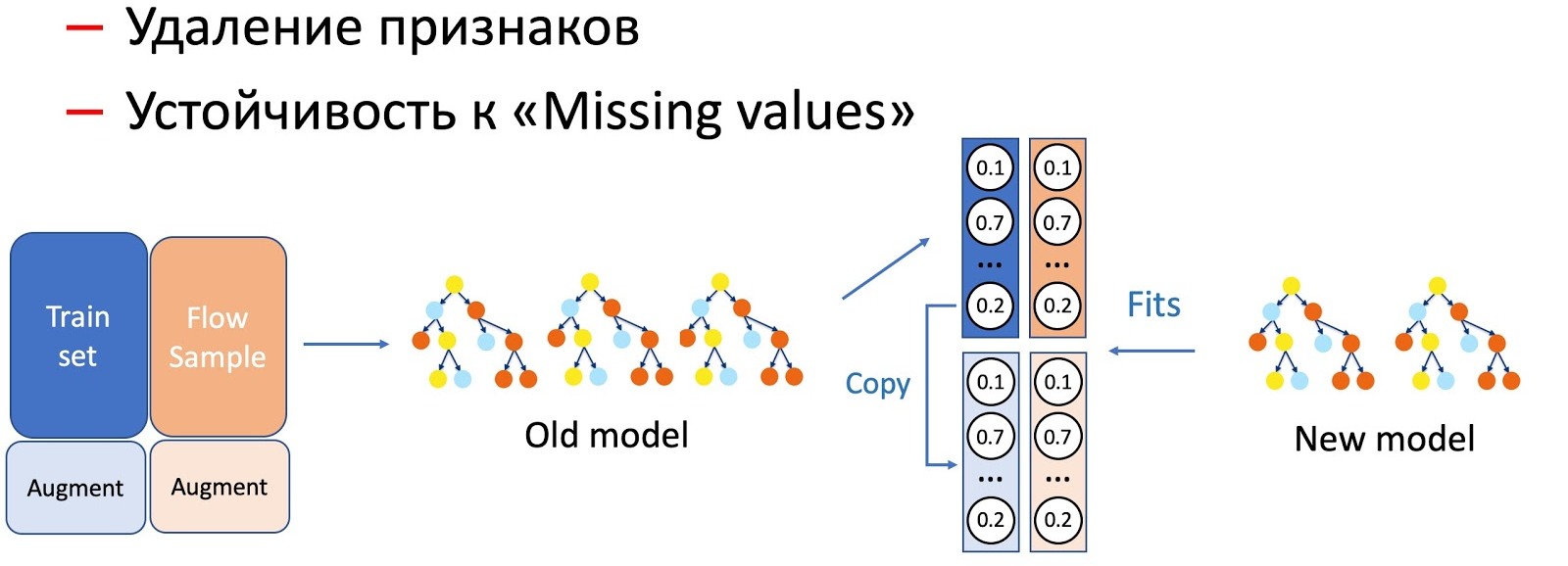
Kami perhatikan bahwa semakin serius manipulasi model terjadi, semakin besar persentase aliran sampel yang dibutuhkan.
Untuk menghapus fitur, operasi paling sederhana, hanya sebagian kecil dari aliran diperlukan, karena hanya beberapa fitur yang berubah, dan model saat ini dipelajari pada set yang sama - perbedaannya minimal. Untuk menyederhanakan model (mengurangi jumlah pohon beberapa kali), sudah diperlukan 50 hingga 50. Dan menghilangkan fitur statistik penting yang secara serius mempengaruhi kinerja model bahkan membutuhkan lebih banyak aliran untuk meratakan pekerjaan model baru, yang tahan terhadap kelalaian, pada semua jenis huruf.
Teks cepat
Mari kita beralih ke FastText. Biarkan saya mengingatkan Anda bahwa representasi (Embedding) dari suatu kata terdiri dari jumlah embedding dari kata itu sendiri dan semua hurufnya N-gram, biasanya trigram. Karena trigram bisa sangat banyak, Bucket Hashing digunakan, yaitu, konversi seluruh ruang menjadi hashmap tetap tertentu. Akibatnya, matriks bobot diperoleh dengan dimensi lapisan dalam dengan jumlah kata + ember.
Selama pendidikan lebih lanjut, tanda-tanda baru muncul: kata-kata dan trigram. Dalam standar pasca pelatihan dari Facebook, tidak ada yang signifikan terjadi. Hanya beban lama dengan cross-entropy pada data baru yang dilatih ulang. , , , , . FastText. ( ), - , .

CNN
. CNN , , , . , , . Triplet Loss (
).
Triplet Loss
Triplet Loss. , . , , .

, , . , . , .
- . (Finetuning): , . , — . , v1 v2. .

, , . , , CNN Fast Text . , ( , , ). . , .

. CNN Fast Text , — . Knowledge Distillation.
, . , , .
Sebarkan
, .
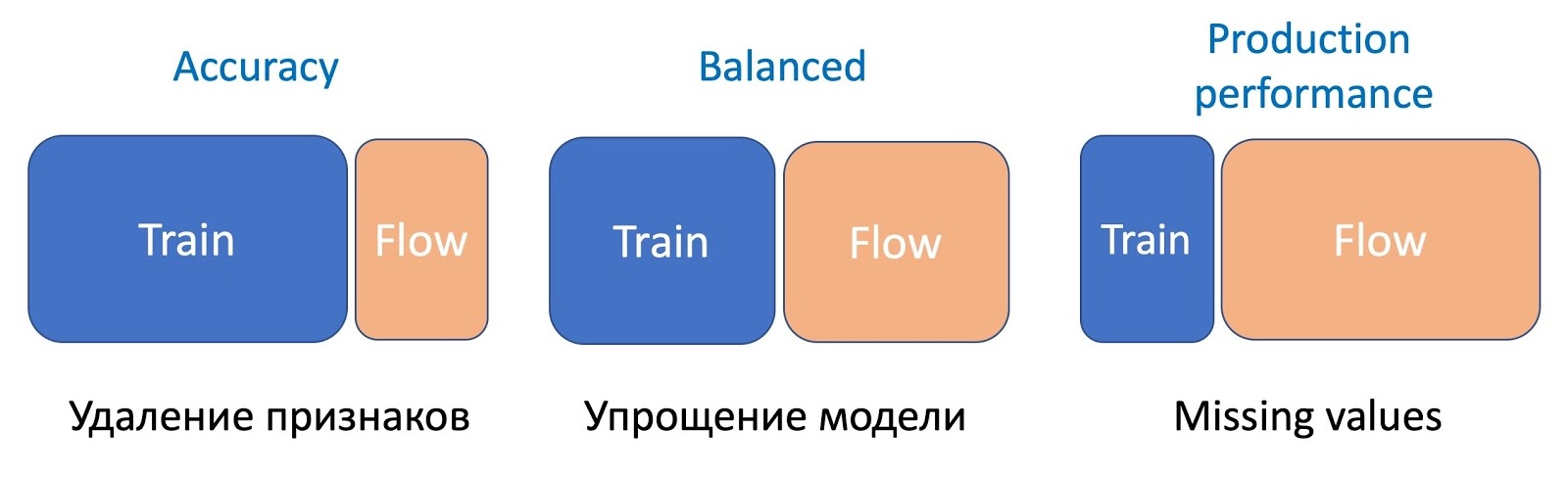
/B-
, , , , - . , , , A/B-. . 5 %, 30 %, 50 % 100 % , . - , , , . 50 % , , .
A/B- . , A/B- ( 6 24 ), . , /B- ( ), A/B- . , , .
, A/B-. , Precision, Recall , . , , (Complexity) . , -, , , A/B-.

A/B-.
&
, , , , , . , — , .
, — . , . , — - , .
, . ( ). - . , , «» . , , . .

. , , . KL- A/B- , .
, . , NER- -, , . !
Ringkasan
.
- . : , . , — , ML-. , , , .
- . — , -. , .
- Sebarkan . Metrik otomatis sangat mengurangi waktu yang diperlukan untuk menerapkan model. Memantau statistik dan distribusi pengambilan keputusan, jumlah jatuh dari pengguna adalah wajib untuk Anda tidur nyenyak dan hari libur yang produktif.
Yah, saya harap apa yang Anda baca akan membantu Anda meningkatkan sistem ML Anda lebih cepat, mempercepat peluncuran pasar mereka dan membuatnya lebih andal, mengurangi jumlah tekanan dari pekerjaan.