Saya ingin berbagi dengan Anda pengalaman sukses pertama saya dalam memulihkan fungsionalitas penuh dari database Postgres. Saya bertemu Postgres DBMS setengah tahun yang lalu, sebelum itu saya tidak punya pengalaman administrasi database sama sekali.

Saya bekerja sebagai insinyur semi-DevOps di sebuah perusahaan IT besar. Perusahaan kami mengembangkan perangkat lunak untuk layanan yang sangat dimuat, tetapi saya bertanggung jawab atas kinerja, pemeliharaan, dan penyebaran. Mereka menetapkan tugas standar untuk saya: memperbarui aplikasi pada satu server. Aplikasi ini ditulis dalam Django, selama upgrade, migrasi dilakukan (mengubah struktur basis data), dan sebelum proses ini kami menghapus dump basis data lengkap melalui program pg_dump standar untuk berjaga-jaga.
Terjadi kesalahan tak terduga saat menghapus dump (versi Postgres 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed. pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 pg_dump: The command was: COPY public.ws_log_smevlog [...] pg_dunp: [parallel archtver] a worker process dled unexpectedly
Kesalahan
"halaman tidak sah di blok" menunjukkan masalah pada tingkat sistem file, yang sangat buruk. Di berbagai forum, mereka menyarankan membuat
FULL VACUUM dengan opsi
zero_damaged_pages untuk menyelesaikan masalah ini. Baiklah, popprobeum ...
Persiapan Pemulihan
PERHATIAN! Pastikan untuk mencadangkan Postgres sebelum upaya memulihkan database. Jika Anda memiliki mesin virtual, hentikan basis data dan ambil snapshot. Jika tidak dimungkinkan untuk mengambil snapshot, hentikan database dan salin isi direktori Postgres (termasuk file wal) ke tempat yang aman. Hal utama dalam bisnis kami bukanlah untuk memperburuk keadaan. Baca
ini .
Karena database bekerja untuk saya secara keseluruhan, saya membatasi diri pada dump database biasa, tetapi mengecualikan tabel dengan data yang rusak (opsi
-T, --exclude-table = TABLE di pg_dump).
Server bersifat fisik, tidak mungkin untuk mengambil snapshot. Cadangan dihapus, lanjutkan.
Pemeriksaan sistem file
Sebelum mencoba mengembalikan database, Anda perlu memastikan bahwa semuanya sesuai dengan sistem file itu sendiri. Dan jika terjadi kesalahan, perbaiki, karena jika tidak, Anda hanya dapat memperburuknya.
Dalam kasus saya, sistem file dengan database dipasang di
"/ srv" dan jenisnya adalah ext4.
Kami menghentikan basis data:
systemctl menghentikan postgresql@9.5-main.service dan memeriksa apakah sistem file tidak digunakan oleh siapa pun dan dapat dilepas menggunakan
perintah lsof :
lsof + D / srvSaya masih harus menghentikan database redis, karena juga menggunakan
"/ srv" . Selanjutnya, saya melepas
/ srv (umount).
Memeriksa sistem file dilakukan menggunakan utilitas
e2fsck dengan opsi -f (
Paksa memeriksa bahkan jika sistem file ditandai bersih ):
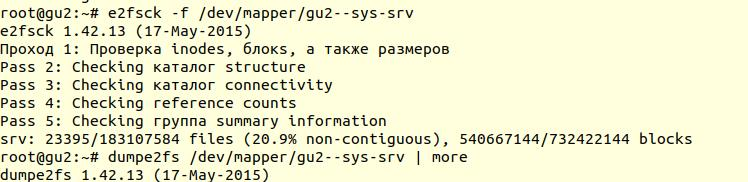
Selanjutnya, dengan menggunakan utilitas
dumpe2fs (
sudo dumpe2fs / dev / mapper / gu2 - sys-srv | grep dicentang ), Anda dapat memverifikasi bahwa pemeriksaan memang dilakukan:
 e2fsck
e2fsck mengatakan bahwa tidak ada masalah yang ditemukan pada tingkat sistem file ext4, yang berarti bahwa Anda dapat terus mencoba mengembalikan database, atau lebih tepatnya kembali ke
vakum penuh (tentu saja, Anda perlu me-mount sistem file kembali dan memulai database).
Jika server Anda fisik, pastikan untuk memeriksa status disk (via
smartctl -a / dev / XXX ) atau pengontrol RAID untuk memastikan bahwa masalahnya bukan pada tingkat perangkat keras. Dalam kasus saya, RAID ternyata "besi", jadi saya meminta administrator lokal untuk memeriksa status RAID (server beberapa ratus kilometer dari saya). Dia mengatakan bahwa tidak ada kesalahan, yang berarti bahwa kita pasti dapat memulai pemulihan.
Percobaan 1: zero_damaged_pages
Kami terhubung ke database melalui akun psql dengan hak pengguna super. Kami membutuhkan superuser, karena hanya dia yang bisa mengubah opsi
zero_damaged_pages . Dalam kasus saya, ini postgres:
psql -h 127.0.0.1 -U postgres -s [database_name]Opsi
zero_damaged_pages diperlukan untuk mengabaikan kesalahan baca (dari situs postgrespro):
Ketika judul halaman yang rusak terdeteksi, Postgres Pro biasanya melaporkan kesalahan dan membatalkan transaksi saat ini. Jika parameter zero_damaged_pages diaktifkan, sebagai gantinya, sistem mengeluarkan peringatan, membersihkan halaman yang rusak dalam memori, dan melanjutkan pemrosesan. Perilaku ini menghancurkan data, yaitu semua baris di halaman yang rusak.
Aktifkan opsi dan coba buat tabel vakum penuh:
VACUUM FULL VERBOSE
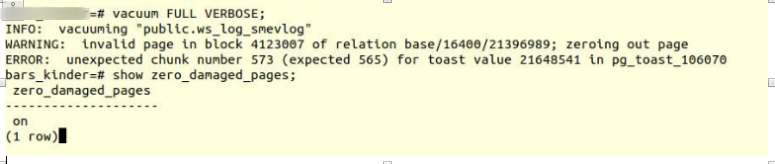
Sayangnya, kegagalan.
Kami mengalami kesalahan serupa:
INFO: vacuuming "“public.ws_log_smevlog” WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070
pg_toast - mekanisme untuk menyimpan "data panjang" di Postgres, jika tidak cocok di halaman yang sama (8kb secara default).
Percobaan 2: indeks ulang
Kiat google pertama tidak membantu. Setelah beberapa menit mencari, saya menemukan tip kedua - untuk membuat
reindex menjadi tabel yang rusak. Saya bertemu saran ini di banyak tempat, tetapi itu tidak menginspirasi kepercayaan. Buat pengindeksan ulang:
reindex table ws_log_smevlog
 Reindex
Reindex selesai tanpa masalah.
Namun, ini tidak membantu,
VACUUM FULL jatuh dengan kesalahan yang sama. Karena saya terbiasa dengan kegagalan, saya mulai mencari saran di Internet lebih jauh dan menemukan
artikel yang agak menarik.
Percobaan 3: PILIH, BATAS, OFFSET
Artikel di atas menyarankan melihat baris demi baris tabel dan menghapus data yang bermasalah. Untuk memulai, perlu untuk melihat semua baris:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; done
Dalam kasus saya, tabel tersebut berisi
1.628.991 baris! Dalam cara yang baik, perlu untuk
mempartisi data , tetapi ini adalah topik untuk diskusi terpisah. Saat itu hari Sabtu, saya menjalankan perintah ini dalam tmux dan pergi tidur:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; done
Pada pagi hari, saya memutuskan untuk memeriksa keadaan. Yang mengejutkan saya, saya menemukan bahwa dalam 2 jam hanya 2% dari data yang dipindai! Saya tidak ingin menunggu 50 hari. Kegagalan total lainnya.
Tapi saya tidak menyerah. Saya bertanya-tanya mengapa pemindaian begitu lama. Dari dokumentasi (lagi di postgrespro) saya menemukan:
OFFSET menunjukkan untuk melewati jumlah baris yang ditentukan sebelum mulai menghasilkan garis.
Jika kedua OFFSET dan LIMIT ditentukan, sistem pertama-tama akan melompati garis OFFSET dan kemudian mulai menghitung garis untuk membatasi LIMIT.
Saat menggunakan LIMIT, juga penting untuk menggunakan klausa ORDER BY sehingga garis hasil dikembalikan dalam urutan tertentu. Jika tidak, himpunan bagian string yang tidak dapat diprediksi akan dikembalikan.
Jelas, perintah di atas salah: pertama, tidak ada
perintah , hasilnya bisa salah. Kedua, Postgres pertama harus memindai dan melewati garis OFFSET, dan dengan peningkatan
OFFSET, kinerja akan semakin berkurang.
Percobaan 4: hapus dump dalam bentuk teks
Selanjutnya, sebuah ide yang tampaknya cemerlang muncul di benak saya: untuk menghapus dump dalam bentuk teks dan menganalisis baris yang terakhir direkam.
Tapi pertama-tama,
mari kita lihat
struktur tabel
ws_log_smevlog :

Dalam kasus kami, kami memiliki kolom
"id" , yang berisi pengidentifikasi unik (penghitung) untuk baris. Rencananya adalah ini:
- Kami mulai menghapus dump dalam bentuk teks (dalam bentuk perintah sql)
- Pada titik waktu tertentu, dump akan terganggu karena kesalahan, tetapi file teks akan tetap disimpan di disk
- Kami melihat di akhir file teks, dengan demikian kami menemukan pengidentifikasi (id) dari baris terakhir yang berhasil ditembak
Saya mulai menghapus dump dalam bentuk teks:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dump
Tempat pembuangan sampah, seperti yang diharapkan, terputus dengan kesalahan yang sama:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
Selanjutnya, melalui
ekor, saya melihat ujung dump (
tail -5 ./my_dump.dump ) dan menemukan bahwa dump terputus pada baris dengan id
186 525 . "Jadi, masalahnya ada di baris dengan id 186 526, rusak, dan perlu dihapus!" Saya pikir. Tetapi dengan membuat permintaan ke database:
"
Pilih * dari ws_log_smevlog di mana id = 186529 " ternyata semuanya baik-baik saja dengan baris ini ... Baris dengan indeks 186 530 - 186 540 juga bekerja tanpa masalah. “Ide cemerlang” lain gagal. Kemudian, saya mengerti mengapa ini terjadi: ketika menghapus / mengubah data dari tabel, mereka tidak dihapus secara fisik, tetapi ditandai sebagai "tupel mati", kemudian
autovacuum datang dan menandai garis-garis ini sebagai dihapus dan memungkinkan penggunaan garis-garis ini lagi. Untuk memahami, jika data dalam tabel diubah dan autovacuum dihidupkan, maka mereka tidak disimpan secara berurutan.
Percobaan 5: PILIH, DARI, DI MANA id =
Kegagalan membuat kita lebih kuat. Anda tidak boleh menyerah, Anda harus pergi sampai akhir dan percaya pada diri sendiri dan kemampuan Anda. Oleh karena itu, saya memutuskan untuk mencoba satu opsi lagi: cukup lihat semua entri dalam database satu per satu. Mengetahui struktur tabel saya (lihat di atas), kami memiliki bidang id yang unik (kunci utama). Dalam tabel, kami memiliki 1.628.991 baris dan
id berjalan berurutan, yang berarti bahwa kami dapat mengulanginya satu per satu:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Jika seseorang tidak mengerti, perintahnya berfungsi sebagai berikut: ia memindai baris demi baris tabel dan mengirimkan stdout ke
/ dev / null , tetapi jika perintah SELECT gagal, teks kesalahan ditampilkan (stderr dikirim ke konsol) dan baris yang mengandung kesalahan adalah output (terima kasih kepada ||, yang berarti bahwa pilih memiliki masalah (kode pengembalian perintah bukan 0)).
Saya beruntung, saya membuat indeks di bidang
id :

Ini berarti bahwa menemukan garis dengan id yang diinginkan tidak perlu banyak waktu. Secara teori, itu harus bekerja. Nah, jalankan perintah di
tmux dan pergi tidur.
Pada pagi hari, saya menemukan bahwa sekitar 90.000 catatan telah ditonton, yang hanya lebih dari 5%. Hasil luar biasa bila dibandingkan dengan metode sebelumnya (2%)! Tapi saya tidak mau menunggu 20 hari ...
Percobaan 6: PILIH, DARI, DI MANA id> = dan id <
Server yang sangat baik dialokasikan untuk pelanggan di bawah basis data: prosesor ganda
Intel Xeon E5-2697 v2 , di lokasi kami ada sebanyak 48 utas! Server memuat rata-rata, kami dapat mengambil sekitar 20 utas tanpa masalah. RAM-nya juga cukup: sebanyak 384 gigabyte!
Karena itu, perintah perlu diparalelkan:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Di sini dimungkinkan untuk menulis skrip yang indah dan elegan, tetapi saya memilih cara tercepat untuk memparalelkan: memecah secara manual kisaran 0-1628991 ke dalam interval 100.000 catatan dan menjalankan 16 perintah formulir secara terpisah:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Tapi itu belum semuanya. Secara teori, menghubungkan ke database juga membutuhkan waktu dan sumber daya sistem. Menghubungkan 1.628.991 tidak terlalu masuk akal, setuju. Karena itu, mari kita ekstrak 1000 baris dalam satu koneksi, bukan satu. Akibatnya, tim berubah menjadi ini:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Buka 16 jendela di sesi tmux dan jalankan perintah:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Sehari kemudian, saya mendapat hasil pertama! Yaitu (nilai XXX dan ZZZ belum dipertahankan):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070 146000
Ini berarti bahwa kami memiliki tiga baris yang mengandung kesalahan. id dari catatan masalah pertama dan kedua adalah antara 829.000 dan 830.000, id yang ketiga adalah antara 146.000 dan 147.000. Selanjutnya, kita hanya harus menemukan nilai id yang tepat dari catatan masalah. Untuk melakukan ini, lihat rentang kami dengan catatan masalah di langkah 1 dan identifikasi id:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
Selamat berakhir
Kami menemukan jalur yang bermasalah. Kami masuk ke database melalui psql dan mencoba untuk menghapusnya:
my_database=# delete from ws_log_smevlog where id=829417; DELETE 1 my_database=# delete from ws_log_smevlog where id=829449; DELETE 1 my_database=# delete from ws_log_smevlog where id=146911; DELETE 1
Yang mengejutkan saya, entri itu dihapus tanpa masalah, bahkan tanpa opsi
zero_damaged_pages .
Kemudian saya terhubung ke database, membuat
VACUUM FULL (saya pikir itu tidak perlu dilakukan), dan akhirnya berhasil menghapus cadangan menggunakan
pg_dump . Tumpukan ini membintangi tanpa kesalahan! Masalahnya dipecahkan dengan cara yang sangat bodoh. Tidak ada batas kegembiraan, setelah begitu banyak kegagalan kami berhasil menemukan solusi!
Ucapan Terima Kasih dan Kesimpulan
Ini adalah pengalaman pertama saya dalam memulihkan database Postgres nyata. Saya akan mengingat pengalaman ini untuk waktu yang lama.
Dan akhirnya, saya ingin mengucapkan terima kasih kepada PostgresPro untuk dokumentasi yang diterjemahkan ke dalam bahasa Rusia dan untuk
kursus online gratis yang telah banyak membantu selama analisis masalah.