
Beberapa tahun yang lalu, Kubernetes
sudah dibahas di blog resmi GitHub. Sejak itu, ia telah menjadi teknologi standar untuk menyebarkan layanan. Kubernetes sekarang mengelola sebagian besar layanan internal dan publik. Ketika kluster kami tumbuh dan persyaratan kinerja menjadi lebih ketat, kami mulai memperhatikan bahwa beberapa layanan di Kubernetes secara sporadis menampilkan penundaan yang tidak dapat dijelaskan oleh beban aplikasi itu sendiri.
Bahkan, dalam aplikasi, penundaan jaringan acak hingga 100 ms atau lebih terjadi, yang mengarah ke waktu habis atau coba lagi. Diharapkan bahwa layanan akan dapat menanggapi permintaan lebih cepat dari 100 ms. Tetapi ini tidak mungkin jika koneksi itu sendiri membutuhkan banyak waktu. Secara terpisah, kami mengamati permintaan MySQL yang sangat cepat, yang seharusnya mengambil milidetik, dan MySQL benar-benar dikelola dalam milidetik, tetapi dari sudut pandang aplikasi yang meminta, responsnya memakan waktu 100 ms atau lebih.
Segera menjadi jelas bahwa masalah hanya terjadi ketika menghubungkan ke host Kubernetes, bahkan jika panggilan itu berasal dari luar Kubernetes. Cara termudah untuk mereproduksi masalah adalah dalam tes
Vegeta , yang dijalankan dari host internal apa pun, menguji layanan Kubernetes pada port tertentu, dan secara sporadis mendaftarkan penundaan besar. Di artikel ini, kita akan melihat bagaimana kami berhasil melacak penyebab masalah ini.
Hilangkan kompleksitas yang tidak perlu dalam rantai kegagalan
Setelah mereproduksi contoh yang sama, kami ingin mempersempit fokus masalah dan menghapus lapisan kompleksitas tambahan. Awalnya, ada terlalu banyak elemen dalam aliran antara Vegeta dan polong di Kubernetes. Untuk mengidentifikasi masalah jaringan yang lebih dalam, Anda perlu mengecualikan beberapa dari mereka.
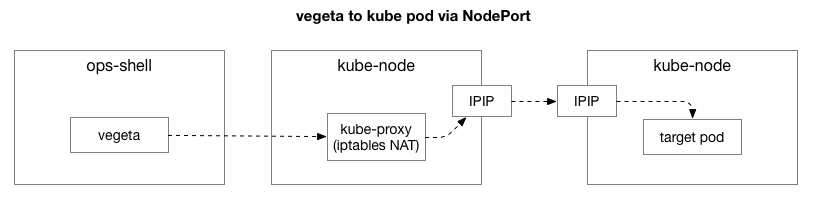
Klien (Vegeta) membuat koneksi TCP dengan node apa pun di cluster. Kubernet bertindak sebagai jaringan overlay (di atas jaringan pusat data yang ada) yang menggunakan
IPIP , yaitu, merangkum paket IP dari jaringan overlay di dalam paket IP dari pusat data. Ketika terhubung ke node pertama, terjemahan alamat jaringan
Network Address Translation (NAT) dilakukan dengan pemantauan negara untuk mengonversi alamat IP dan port host Kubernetes ke alamat IP dan port pada jaringan overlay (khususnya, pod dengan aplikasi). Untuk paket yang diterima, urutan terbalik dilakukan. Ini adalah sistem yang kompleks dengan banyak negara dan banyak elemen yang terus diperbarui dan diubah saat layanan dikerahkan dan dipindahkan.
Utilitas
tcpdump dalam tes Vegeta memberikan penundaan selama jabat tangan TCP (antara SYN dan SYN-ACK). Untuk menghapus kompleksitas yang tidak perlu ini, Anda dapat menggunakan
hping3 untuk “ping” sederhana dengan paket SYN. Periksa apakah ada keterlambatan dalam paket respons, dan kemudian atur ulang koneksi. Kami dapat memfilter data dengan memasukkan hanya paket lebih dari 100 ms, dan mendapatkan opsi yang lebih sederhana untuk mereproduksi masalah daripada tes level 7 jaringan penuh di Vegeta. Berikut adalah "ping" dari host Kubernetes menggunakan TCP SYN / SYN-ACK pada "port" host layanan (30927) dengan interval 10 ms, disaring oleh respons paling lambat:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1485 win=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1486 win=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1487 win=29200 rtt=106.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1488 win=29200 rtt=104.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5024 win=29200 rtt=109.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5231 win=29200 rtt=109.2 msSegera bisa melakukan pengamatan pertama. Nomor seri dan pengaturan waktu menunjukkan bahwa ini bukan kemacetan satu kali. Penundaan sering terakumulasi, dan akhirnya diproses.
Selanjutnya, kami ingin mengetahui komponen mana yang mungkin terlibat dalam penampilan kemacetan. Mungkin ini beberapa dari ratusan aturan iptables di NAT? Atau beberapa masalah dengan tunneling IPIP di jaringan? Salah satu cara untuk memverifikasi ini adalah memverifikasi setiap langkah sistem dengan mengecualikannya. Apa yang terjadi jika Anda menghapus logika NAT dan firewall, hanya menyisakan sebagian dari IPIP:
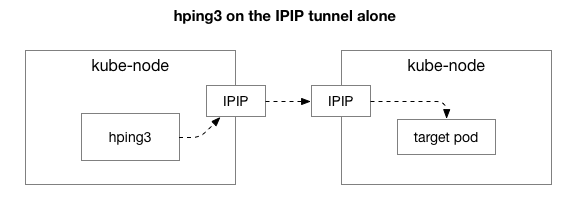
Untungnya, Linux memudahkan untuk secara langsung mengakses lapisan overlay IP jika mesin berada di jaringan yang sama:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7346 win=0 rtt=127.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7347 win=0 rtt=117.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7348 win=0 rtt=107.2 msMenilai dari hasilnya, masalahnya masih ada! Ini tidak termasuk iptables dan NAT. Jadi masalahnya ada di TCP? Mari kita lihat bagaimana ping ICMP biasa:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 msHasilnya menunjukkan bahwa masalahnya belum hilang. Mungkin ini adalah terowongan IPIP? Mari sederhanakan tesnya:
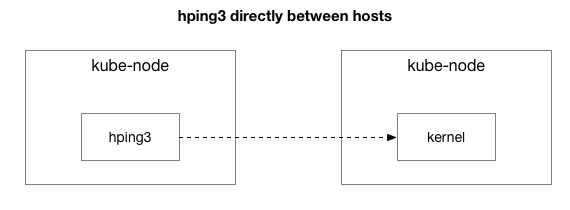
Apakah semua paket dikirim antara dua host ini?
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 msKami menyederhanakan situasinya ke dua host Kubernet yang saling mengirim paket, bahkan ping ICMP. Mereka masih melihat penundaan jika host target "buruk" (beberapa lebih buruk daripada yang lain).
Sekarang pertanyaan terakhir: mengapa penundaan hanya terjadi pada server kube-node? Dan apakah itu terjadi ketika kube-node adalah pengirim atau penerima? Untungnya, ini juga cukup mudah untuk diketahui dengan mengirim paket dari host di luar Kubernetes, tetapi dengan penerima yang "dikenal buruk" yang sama. Seperti yang Anda lihat, masalahnya belum hilang:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=312 win=0 rtt=108.5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=5903 win=0 rtt=119.4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=6227 win=0 rtt=139.9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=7929 win=0 rtt=131.2 msKemudian kami melakukan permintaan yang sama dari node-sumber sebelumnya ke host eksternal (yang tidak termasuk host asli, karena ping menyertakan komponen RX dan TX):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 msSetelah memeriksa penangkapan paket yang tertunda, kami mendapat beberapa informasi tambahan. Secara khusus, bahwa pengirim (di bawah) melihat batas waktu ini, tetapi penerima (di atas) tidak melihatnya - lihat kolom Delta (dalam detik):

Selain itu, jika Anda melihat perbedaan dalam urutan paket TCP dan ICMP (dengan nomor seri) di sisi penerima, maka paket ICMP selalu tiba dalam urutan yang sama di mana mereka dikirim, tetapi dengan waktu yang berbeda. Pada saat yang sama, paket TCP kadang-kadang bergantian, dan beberapa di antaranya macet. Secara khusus, jika kita memeriksa port dari paket SYN, maka di sisi pengirim mereka pergi dalam urutan, tetapi di sisi penerima mereka tidak.
Ada sedikit perbedaan dalam bagaimana
kartu jaringan server modern (seperti dalam data center kami) memproses paket yang berisi TCP atau ICMP. Ketika sebuah paket tiba, adapter jaringan “hashes it over the connection”, artinya, ia mencoba memutus koneksi secara bergantian dan mengirim setiap antrian ke inti prosesor yang terpisah. Untuk TCP, hash ini mencakup sumber dan tujuan alamat IP dan port. Dengan kata lain, setiap koneksi hash (berpotensi) berbeda. Untuk ICMP, hanya alamat IP yang di-hash, karena tidak ada port.
Pengamatan baru lainnya: selama periode ini kita melihat keterlambatan ICMP pada semua komunikasi antara dua host, tetapi TCP tidak. Ini memberitahu kita bahwa alasannya mungkin karena hashing dari antrian RX: hampir pasti bahwa kemacetan terjadi dalam pemrosesan paket RX, daripada dalam mengirim tanggapan.
Ini tidak termasuk pengiriman paket dari daftar kemungkinan alasan. Sekarang kita tahu bahwa masalah dengan pemrosesan paket ada di sisi penerima pada beberapa server kube-node.
Memahami Pemrosesan Paket di Kernel Linux
Untuk memahami mengapa masalah terjadi dengan penerima pada beberapa server kube-node, mari kita lihat bagaimana kernel Linux menangani paket.
Kembali ke implementasi tradisional yang paling sederhana, kartu jaringan menerima paket dan mengirimkan
interupsi ke kernel Linux, yang merupakan paket yang perlu diproses. Kernel menghentikan operasi lain, mengalihkan konteks ke interrupt handler, memproses paket, dan kemudian kembali ke tugas saat ini.

Switch konteks ini lambat: latensi mungkin tidak terlihat pada kartu jaringan 10-megabyte pada 1990-an, tetapi pada kartu 10G modern dengan throughput maksimum 15 juta paket per detik, setiap inti dari server delapan-inti kecil dapat diinterupsi jutaan kali per detik.
Agar tidak berurusan dengan penanganan interupsi terus-menerus, bertahun-tahun yang lalu Linux menambahkan
NAPI : API jaringan yang digunakan semua driver modern untuk meningkatkan kinerja pada kecepatan tinggi. Pada kecepatan rendah, kernel masih menerima interupsi dari kartu jaringan dengan cara lama. Segera setelah jumlah paket yang cukup yang melebihi ambang batas, kernel menonaktifkan interupsi dan sebagai gantinya mulai polling adapter jaringan dan mengambil paket dalam batch. Pemrosesan dilakukan dalam softirq, yaitu, dalam
konteks interupsi perangkat lunak setelah panggilan sistem dan interupsi perangkat keras ketika kernel (tidak seperti ruang pengguna) sudah berjalan.
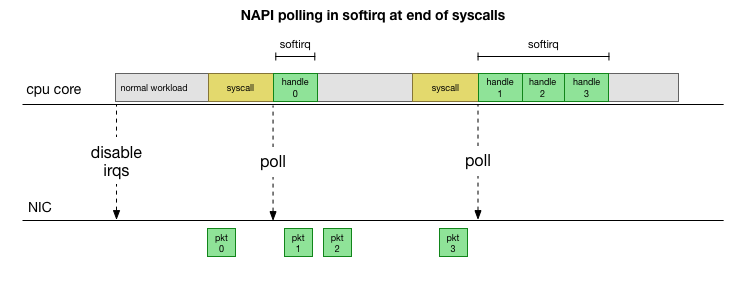
Ini jauh lebih cepat, tetapi menyebabkan masalah yang berbeda. Jika ada terlalu banyak paket, semua waktu yang diperlukan untuk memproses paket dari kartu jaringan, dan proses ruang pengguna tidak punya waktu untuk benar-benar mengosongkan antrian ini (membaca dari koneksi TCP, dll.). Pada akhirnya, antrian terisi dan kami mulai menjatuhkan paket. Mencoba menemukan keseimbangan, kernel menetapkan anggaran untuk jumlah maksimum paket yang diproses dalam konteks softirq. Setelah anggaran ini terlampaui, utas
ksoftirqd terpisah
ksoftirqd (Anda akan melihat salah satunya di
ps untuk setiap inti), yang memproses softirqs ini di luar jalur syscall / interrupt normal. Utas ini direncanakan menggunakan penjadwal proses standar yang berupaya mendistribusikan sumber daya secara adil.
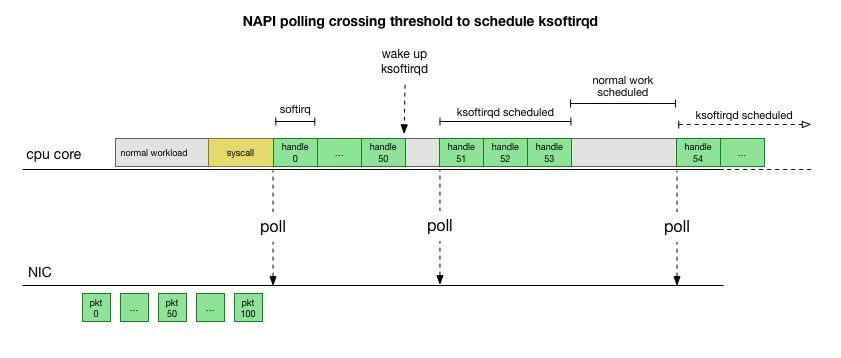
Setelah memeriksa bagaimana kernel memproses paket, Anda dapat melihat bahwa ada kemungkinan kemacetan tertentu. Jika panggilan softirq diterima lebih jarang, paket harus menunggu beberapa saat untuk diproses dalam antrian RX pada kartu jaringan. Mungkin ini karena beberapa tugas memblokir inti prosesor, atau sesuatu yang lain mencegah kernel memulai softirq.
Kami mempersempit pemrosesan ke kernel atau metode
Penundaan softirq hanyalah sebuah asumsi. Tapi itu masuk akal, dan kita tahu bahwa kita melihat sesuatu yang sangat mirip. Karena itu, langkah selanjutnya adalah mengkonfirmasi teori ini. Dan jika sudah dikonfirmasi, maka cari alasan keterlambatannya.
Kembali ke paket lambat kami:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 msSeperti dibahas sebelumnya, paket ICMP ini di-hash menjadi satu antrian NIC RX dan diproses oleh satu inti CPU. Jika kami ingin memahami cara kerja Linux, akan sangat berguna untuk mengetahui di mana (di mana inti CPU) dan bagaimana (softirq, ksoftirqd) paket ini diproses untuk melacak proses.
Sekarang saatnya menggunakan alat yang memungkinkan pemantauan real-time dari kernel Linux. Di sini kami menggunakan
bcc . Serangkaian alat ini memungkinkan Anda untuk menulis program C kecil yang mencegat fungsi sewenang-wenang di kernel dan buffer event ke dalam program Python ruang-pengguna yang dapat memprosesnya dan mengembalikan hasilnya kepada Anda. Kait untuk fungsi sewenang-wenang di kernel sangat kompleks, tetapi utilitas ini dirancang untuk keamanan maksimum dan dirancang untuk melacak dengan tepat masalah-masalah produksi yang tidak mudah direproduksi dalam lingkungan pengujian atau pengembangan.
Rencananya di sini sederhana: kita tahu bahwa kernel memproses ICMP ping ini, jadi kami mengaitkan
fungsi kernel
icmp_echo , yang menerima paket ICMP permintaan gema yang masuk dan memulai pengiriman respons ICMP respons gema. Kami dapat mengidentifikasi paket dengan menambah nomor icmp_seq, yang menunjukkan
hping3 atas.
Kode
skrip bcc terlihat rumit, tetapi tidak seseram kelihatannya. Fungsi
icmp_echo melewati
struct sk_buff *skb : ini adalah paket dengan permintaan "echo request". Kita dapat melacaknya, mengeluarkan urutan
echo.sequence (yang memetakan ke
icmp_seq dari hping3 di
), dan mengirimkannya ke ruang pengguna. Juga mudah untuk menangkap nama proses / pengenal saat ini. Di bawah ini adalah hasil yang kami lihat langsung selama pemrosesan paket oleh kernel:
NAMA PROSES PID TGID ICMP_SEQ
0 0 swapper / 11.770
0 0 swapper / 11.771
0 0 swapper / 11 772
0 0 swapper / 11 773
0 0 swapper / 11.774
20041 20086 prometheus 775
0 0 swapper / 11.776
0 0 swapper / 11.777
0 0 swapper / 11 778
4512 4542 juru bicara-laporan 779
Perlu dicatat di sini bahwa dalam konteks
softirq proses yang membuat panggilan sistem muncul sebagai "proses", meskipun sebenarnya kernel ini dengan aman memproses paket dalam konteks kernel.
Dengan alat ini kita dapat membangun koneksi proses-proses spesifik dengan paket-paket spesifik yang menunjukkan penundaan dalam
hping3 . Kami membuat
grep sederhana pada tangkapan ini untuk nilai
icmp_seq tertentu. Paket yang sesuai dengan nilai icmp_seq di atas ditandai dengan RTT mereka, yang kami amati di atas (dalam tanda kurung adalah nilai RTT yang diharapkan untuk paket yang kami filter karena nilai RTT kurang dari 50 ms):
NAMA PROSES PID TGID ICMP_SEQ ** RTT
-
10137 10436 cadvisor 1951
10137 10436 cadvisor 1952
76 76 ksoftirqd / 11 1953 ** 99ms
76 76 ksoftirqd / 11 1954 ** 89ms
76 76 ksoftirqd / 11 1955 ** 79ms
76 76 ksoftirqd / 11 1956 ** 69ms
76 76 ksoftirqd / 11 1957 ** 59ms
76 76 ksoftirqd / 11 1958 ** (49ms)
76 76 ksoftirqd / 11 1959 ** (39ms)
76 76 ksoftirqd / 11 1960 ** (29ms)
76 76 ksoftirqd / 11 1961 ** (19ms)
76 76 ksoftirqd / 11 1962 ** (9ms)
-
10137 10436 cadvisor 2068
10137 10436 cadvisor 2069
76 76 ksoftirqd / 11 2070 ** 75ms
76 76 ksoftirqd / 11 2071 ** 65ms
76 76 ksoftirqd / 11 2072 ** 55ms
76 76 ksoftirqd / 11 2073 ** (45ms)
76 76 ksoftirqd / 11 2074 ** (35ms)
76 76 ksoftirqd / 11 2075 ** (25ms)
76 76 ksoftirqd / 11 2076 ** (15ms)
76 76 ksoftirqd / 11 2077 ** (5ms)
Hasilnya memberi tahu kami beberapa hal. Pertama, konteks
ksoftirqd/11 menangani semua paket ini. Ini berarti bahwa untuk pasangan mesin khusus ini, paket ICMP di-hash pada inti 11 pada sisi penerima. Kita juga melihat bahwa di setiap kemacetan ada paket yang diproses dalam konteks panggilan sistem
cadvisor . Kemudian
ksoftirqd mengambil tugas dan memenuhi antrian yang terakumulasi: persis jumlah paket yang terakumulasi setelah
cadvisor .
Fakta bahwa
cadvisor selalu berfungsi segera sebelum ini menyiratkan keterlibatannya dalam masalah tersebut. Ironisnya, tujuan
cadvisor adalah untuk "menganalisis pemanfaatan sumber daya dan karakteristik kinerja wadah yang berjalan," daripada menyebabkan masalah kinerja ini.
Seperti halnya aspek-aspek lain dalam penanganan peti kemas, semua ini adalah alat yang sangat canggih yang dapat menyebabkan masalah kinerja dalam beberapa keadaan yang tidak terduga.
Apa yang dilakukan cadvisor yang memperlambat antrian paket?
Sekarang kita memiliki pemahaman yang cukup baik tentang bagaimana kegagalan terjadi, proses mana yang menyebabkannya, dan pada CPU mana. Kami melihat bahwa karena penguncian yang keras, kernel Linux tidak punya waktu untuk menjadwalkan
ksoftirqd . Dan kami melihat bahwa paket diproses dalam konteks
cadvisor . Adalah logis untuk mengasumsikan bahwa
cadvisor memulai syscall lambat, setelah semua paket yang terakumulasi saat ini diproses:
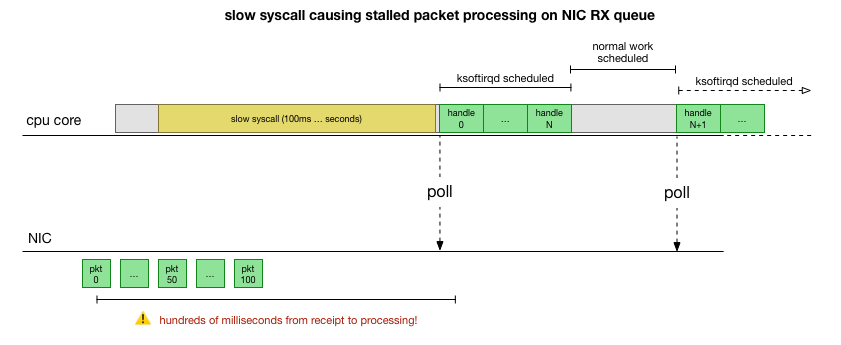
Ini adalah teori, tetapi bagaimana cara mengujinya? Apa yang dapat kita lakukan adalah melacak operasi inti CPU selama proses ini, menemukan titik di mana anggaran terlampaui oleh jumlah paket dan ksoftirqd dipanggil, dan kemudian melihat sedikit lebih awal - apa yang sebenarnya bekerja pada inti CPU tepat sebelum saat itu. Ini seperti x-ray CPU setiap beberapa milidetik. Akan terlihat seperti ini:
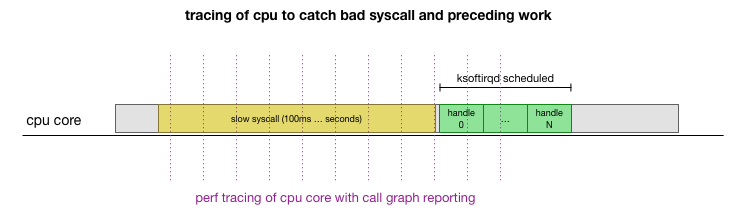
Mudahnya, semua ini bisa dilakukan dengan alat yang ada. Sebagai contoh,
catatan perf memeriksa inti CPU yang ditentukan dengan frekuensi yang ditunjukkan dan dapat menghasilkan jadwal panggilan ke sistem yang sedang berjalan, termasuk ruang pengguna dan kernel Linux. Anda dapat mengambil catatan ini dan memprosesnya menggunakan garpu kecil program
FlameGraph dari Brendan Gregg, yang mempertahankan urutan jejak tumpukan. Kita dapat menyimpan jejak tumpukan satu baris setiap 1 ms, dan kemudian memilih dan menyimpan sampel selama 100 milidetik sebelum
ksoftirqd masuk ke jejak:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100Inilah hasilnya:
( , )
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_runAda banyak hal di sini, tetapi yang utama adalah kita menemukan templat “cadvisor before ksoftirqd” yang kita lihat sebelumnya dalam pelacak ICMP. Apa artinya ini?
Setiap baris adalah jejak CPU pada titik waktu tertentu. Setiap panggilan turun tumpukan dalam garis dipisahkan oleh tanda titik koma. Di tengah baris kita melihat syscall disebut:
read(): .... ;do_syscall_64;sys_read; ... read(): .... ;do_syscall_64;sys_read; ... Dengan demikian, cadvisor menghabiskan banyak waktu pada panggilan sistem
read() , terkait dengan fungsi
mem_cgroup_* (atas tumpukan panggilan / akhir baris).
Dalam pelacakan panggilan, tidak nyaman untuk melihat apa yang sebenarnya sedang dibaca, jadi jalankan
strace dan lihat apa yang dilakukan cadvisor, dan temukan panggilan sistem lebih dari 100 ms:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0\.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880\nrss 507904\nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880\nrss 507904\nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 576 <0.154442>Seperti yang mungkin Anda harapkan, di sini kita melihat panggilan
read() lambat. Dari isi operasi baca dan konteks
mem_cgroup , dapat dilihat bahwa panggilan
read() merujuk ke file
memory.stat , yang menunjukkan penggunaan memori dan batasan cgroup (teknologi isolasi sumber daya Docker). Alat cadvisor polling file ini untuk informasi penggunaan sumber daya untuk kontainer. Mari kita periksa apakah core atau cadvisor ini melakukan sesuatu yang tidak terduga:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
real 0m0.153s
user 0m0.000s
sys 0m0.152s
theojulienne@kube-node-bad ~ $Sekarang kita dapat mereproduksi bug dan memahami bahwa kernel Linux menghadapi patologi.
Apa yang membuat membaca sangat lambat?
Pada titik ini, jauh lebih mudah untuk menemukan pesan dari pengguna lain tentang masalah serupa. Ternyata, dalam pelacak cadvisor bug ini dilaporkan sebagai
masalah penggunaan CPU yang berlebihan , hanya tidak ada yang memperhatikan bahwa penundaan itu juga tercermin secara acak dalam tumpukan jaringan. Memang, diketahui bahwa cadvisor menghabiskan lebih banyak waktu prosesor dari yang diharapkan, tetapi ini tidak terlalu penting, karena server kami memiliki banyak sumber daya prosesor, jadi kami tidak mempelajari masalah dengan cermat.
Masalahnya adalah bahwa kelompok kontrol (cgroup) memperhitungkan penggunaan memori di dalam namespace (wadah). Ketika semua proses dalam cgroup ini berakhir, Docker membebaskan grup kontrol memori. Namun, "memori" bukan hanya memori proses. Meskipun proses memori itu sendiri tidak lagi digunakan, ternyata kernel juga menetapkan konten yang di-cache, seperti dentries dan inode (direktori dan file metadata), yang di-cache dalam cgroup memori. Dari uraian masalah:
cgroups zombie: grup kontrol di mana tidak ada proses dan mereka dihapus, tetapi untuk memori yang masih dialokasikan (dalam kasus saya, dari cache dentry, tetapi juga dapat dialokasikan dari cache halaman atau tmpfs).
Memeriksa oleh kernel semua halaman dalam cache ketika cgroup dibebaskan bisa sangat lambat, jadi proses malas dipilih: tunggu sampai halaman ini diminta lagi, dan bahkan ketika memori benar-benar dibutuhkan, akhirnya bersihkan cgroup. Hingga saat ini, cgroup masih diperhitungkan saat mengumpulkan statistik.
Dalam hal kinerja, mereka mengorbankan memori untuk kinerja: mempercepat pembersihan awal karena fakta bahwa sedikit memori cache masih ada. Ini normal. Ketika kernel menggunakan bagian terakhir dari memori yang di-cache, cgroup akhirnya dihapus, jadi ini tidak bisa disebut "kebocoran". Sayangnya, implementasi spesifik
memory.stat mesin pencari dalam versi kernel ini (4.9), dikombinasikan dengan sejumlah besar memori pada server kami, mengarah pada fakta bahwa dibutuhkan jauh lebih lama untuk mengembalikan data cache terbaru dan membersihkan zombie kelompok.
Ternyata ada begitu banyak zombie grup pada beberapa node kami sehingga pembacaan dan latensi melebihi satu detik.
Sebuah solusi untuk masalah cadvisor adalah dengan segera menghapus cache gigi / inode di seluruh sistem, yang segera menghilangkan latensi baca serta latensi jaringan pada host, karena menghapus cache termasuk halaman cache cgroup zombie, dan mereka juga dibebaskan. Ini bukan solusi, tetapi mengkonfirmasi penyebab masalahnya.
Ternyata versi kernel yang lebih baru (4.19+) meningkatkan kinerja
memory.stat , jadi beralih ke kernel ini memperbaiki masalah. Pada saat yang sama, kami memiliki alat untuk mendeteksi node masalah dalam kelompok Kubernetes, dengan baik menguras mereka dan me-reboot. Kami menyisir semua cluster, menemukan node dengan penundaan yang cukup tinggi dan reboot mereka. Ini memberi kami waktu untuk memperbarui OS di seluruh server.
Untuk meringkas
Karena bug ini menghentikan pemrosesan antrian NIC RX selama ratusan milidetik, maka secara bersamaan menyebabkan penundaan besar pada koneksi pendek dan penundaan di tengah koneksi, misalnya, antara kueri MySQL dan paket respons.
, Kubernetes, . Kubernetes .