
Perusahaan tempat saya bekerja menulis sistem penyaringan lalu lintasnya sendiri dan melindungi bisnis dari serangan DDoS, bot, parser, dan banyak lagi. Produk ini didasarkan pada proses seperti
reverse proxying , dengan bantuan yang kami menganalisis volume besar lalu lintas secara real time dan, pada akhirnya, hanya memungkinkan permintaan pengguna yang sah, menyaring semua yang berbahaya.
Fitur utama adalah bahwa layanan kami bekerja dengan lalu lintas masuk yang tidak terbatas, sehingga sangat penting untuk menggunakan semua sumber daya workstation seefisien mungkin. Banyak pengalaman pengembangan dalam C ++ modern membantu kami dalam hal ini, termasuk standar terbaru dan seperangkat perpustakaan yang disebut Boost.
Membalikkan proxy
Mari kita kembali ke membalikkan proxy dan lihat bagaimana Anda dapat mengimplementasikannya di C ++ dan boost.asio. Pertama-tama, kita membutuhkan dua objek yang disebut sesi server dan klien. Sesi server membangun dan memelihara koneksi dengan browser, sesi klien membangun dan memelihara koneksi dengan layanan. Anda juga akan memerlukan buffer aliran yang merangkum pekerjaan dengan memori di dalamnya, di mana sesi server membaca dari soket dan dari mana sesi klien menulis ke soket. Contoh sesi server dan klien dapat ditemukan dalam dokumentasi untuk boost.asio. Cara bekerja dengan stream buffer dapat ditemukan di sana.
Setelah kami mengumpulkan prototipe proxy terbalik dari contoh, akan menjadi jelas bahwa aplikasi seperti itu mungkin tidak akan melayani lalu lintas masuk tanpa batas. Kemudian kita akan mulai menambah kompleksitas kode. Mari kita pikirkan tentang multithreading, wokers dan pool untuk konteks io, dan banyak lagi. Secara khusus, tentang optimasi prematur terkait dengan menyalin memori antara sesi server dan klien.
Jenis penyalinan seperti apa itu? Faktanya adalah bahwa saat pemfilteran, lalu lintas tidak selalu dikirimkan tidak berubah. Lihat contoh di bawah ini: di dalamnya kita menghapus satu tajuk dan menambahkan dua tajuk. Jumlah kueri pengguna di mana tindakan serupa dilakukan meningkat dengan kompleksitas logika di dalam layanan. Dalam kasus apa pun Anda dapat dengan sembarangan menyalin data dalam kasus seperti itu! Jika hanya 1% dari total permintaan yang berubah, dan 99% tetap tidak berubah, maka Anda harus mengalokasikan memori baru hanya untuk 1% ini. Ini akan membantu Anda dengan peningkatan ini :: asio :: const_buffer dan boost :: asio :: mutable_buffer, dengan bantuan yang Anda dapat mewakili beberapa blok memori terus menerus dengan satu entitas.
Permintaan pengguna:
Browser -> Proxy: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Content-Length: 5888903 > Content-Type: application/x-www-form-urlencoded > ... Proxy -> Service: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Transfer-Encoding: chunked > Content-Type: application/x-www-form-urlencoded > Expect: 100-continue > ... Service -> Proxy: < HTTP/1.1 200 OK Proxy -> Browser < HTTP/1.1 200 OK
Masalah
Sebagai hasilnya, kami mendapat aplikasi siap pakai yang dapat mengukur dengan baik dan diberkahi dengan segala macam optimasi. Dengan meluncurkannya dalam produksi, kami cukup senang untuk berapa lama itu bekerja dengan baik dan stabil.
Seiring waktu, kami mulai memiliki lebih banyak pelanggan, dengan munculnya lalu lintas yang juga tumbuh. Di beberapa titik, kami dihadapkan dengan masalah kurangnya kinerja saat memukul mundur serangan besar. Setelah menganalisis layanan menggunakan utilitas
perf , kami perhatikan bahwa semua operasi dengan heap under load ada di atas. Kemudian kami menciptakan kembali situasi yang serupa di sirkuit uji menggunakan
yandex-tank dan kartrid yang dihasilkan berdasarkan lalu lintas nyata. Mengaitkan layanan melalui
amplifier, kami melihat gambar berikut ...
Cuplikan layar penguat (woslab):
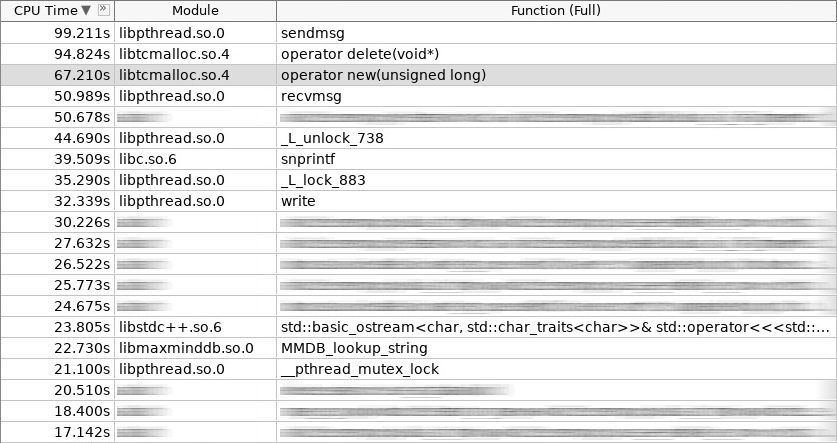
Dalam tangkapan layar, operator baru bekerja 67 detik, dan operator menghapus lebih banyak lagi - 97 detik.
Situasi ini membuat kami sedih. Bagaimana cara mengurangi waktu tinggal aplikasi di operator baru dan operator hapus? Adalah logis bahwa ini dapat dilakukan dengan meninggalkan alokasi konstan dari objek yang sering dibuat dan dihapus di heap. Kami menetapkan tiga pendekatan. Dua di antaranya adalah standar:
kumpulan objek dan
alokasi tumpukan . Sesi klien yang diatur dalam kumpulan pada tahap permulaan aplikasi ditempatkan dengan baik pada pendekatan pertama. Pendekatan kedua digunakan di mana-mana di mana permintaan pengguna diproses dari awal hingga berakhir di tumpukan yang sama, dengan kata lain, dalam penangan konteks io yang sama. Kami tidak akan membahas hal ini secara lebih rinci. Sebaiknya kita bicara tentang pendekatan ketiga, sebagai pendekatan yang paling kompleks dan menarik. Ini disebut
alokasi slab atau distribusi slab.
Gagasan distribusi slab bukanlah hal baru. Itu diciptakan dan diimplementasikan di Solaris, kemudian dimigrasi ke kernel Linux, dan terdiri dari fakta bahwa objek yang sering digunakan dari jenis yang sama lebih mudah untuk disimpan di kolam. Kami hanya mengambil objek dari kolam ketika kami membutuhkannya, dan setelah menyelesaikan pekerjaan kami mengembalikannya. Tidak ada panggilan ke operator baru dan operator hapus! Apalagi minimal inisialisasi. Dalam inti slab, distribusi digunakan untuk semaphores, deskriptor file, proses, dan utas. Dalam kasus kami, ini jatuh dengan sempurna di sesi server dan klien, serta semua yang ada di dalamnya.
Bagan (distribusi slab):

Selain fakta bahwa pengalokasi slab ada di kernel, implementasinya juga ada di ruang pengguna. Ada beberapa dari mereka, dan mereka yang aktif berkembang umumnya sedikit. Kami menetap di perpustakaan bernama
libsmall , yang merupakan bagian dari
tarantool . Ia memiliki semua yang Anda butuhkan.
- kecil :: pengalokasi
- small :: slab_cache (utas lokal)
- small :: slab
- small :: arena
- kecil :: kuota
Struktur slab :: kecil adalah kumpulan dengan tipe objek tertentu. Struktur small :: slab_cache adalah cache yang berisi berbagai daftar kumpulan dengan tipe objek tertentu. Struktur small :: dialokasikan adalah kode yang memilih cache yang diperlukan, mencari kumpulan yang sesuai di dalamnya, di mana objek yang diminta didistribusikan. Apa yang kecil :: arena dan objek kecil :: kuota lakukan akan menjadi jelas dari contoh di bawah ini.
Bungkus
Pustaka libsmall ditulis dalam C, bukan C ++, jadi kami harus mengembangkan beberapa pembungkus untuk integrasi transparan ke pustaka C ++ standar.
- variti :: slab_allocator
- variti :: slab
- variti :: thread_local_slab
- variti :: slab_allocate_share
Kelas variti :: slab_allocator mengimplementasikan persyaratan minimum yang ditetapkan oleh standar saat menulis pengalokasi sendiri. Di dalam kelas-kelas slar variti ::, semua pekerjaan dengan libsmall library dienkapsulasi. Mengapa variti :: thread_local_slab diperlukan? Faktanya adalah bahwa cache slab distribusi adalah objek lokal thread. Ini berarti bahwa setiap utas memiliki set cache yang berbeda. Ini dilakukan untuk mengurangi hingga nol jumlah operasi yang diblokir saat mendistribusikan objek baru. Oleh karena itu, dalam memori setiap utas, kami menempatkan instance kami dari kelas variti :: slab, dan aksesnya diatur menggunakan pembungkus variti :: thread_local_slab. Saya akan memberi tahu Anda tentang fungsi template variti :: slab_allocate_share nanti.
Di dalam kelas variti :: slab_allocator, semuanya cukup sederhana. Dia memiliki kemampuan untuk mengubah dari satu tipe ke tipe lainnya, misalnya, dari void ke char. Menariknya, Anda dapat memperhatikan prevalensi nullptr dengan pengecualian std :: bad_alloc dalam kasus ketika memori habis dari slab distribusi. Sisanya meneruskan panggilan di dalam pembungkus variti :: thread_local_slab.
Cuplikan (slab_allocator.hpp):
template <typename T> class slab_allocator { public: using value_type = T; using pointer = value_type*; using const_pointer = const value_type*; using reference = value_type&; using const_reference = const value_type&; template <typename U> struct rebind { using other = slab_allocator<U>; }; slab_allocator() {} template <typename U> slab_allocator(const slab_allocator<U>& other) {} T* allocate(size_t n, const void* = nullptr) { auto p = static_cast<T*>(thread_local_slab::allocate(sizeof(T) * n)); if (!p && n) throw std::bad_alloc(); return p; } void deallocate(T* p, size_t n) { thread_local_slab::deallocate(p, sizeof(T) * n); } }; template <> class slab_allocator<void> { public: using value_type = void; using pointer = void*; using const_pointer = const void*; template <typename U> struct rebind { typedef slab_allocator<U> other; }; };
Mari kita lihat bagaimana konstruktor dan destruktor variti :: slab diimplementasikan. Dalam konstruktor, kami mengalokasikan total memori tidak lebih dari 1 GiB untuk semua objek. Ukuran setiap kolam dalam wadah kami tidak melebihi 1 MiB. Objek minimum yang dapat kita distribusikan adalah ukuran 2 byte (pada kenyataannya, libsmall akan meningkatkannya ke minimum yang diperlukan - 8 byte). Objek yang tersisa yang tersedia melalui distribusi slab kami adalah kelipatan dari dua (ditetapkan oleh konstanta 2.f). Total, Anda dapat mendistribusikan objek dengan ukuran 8, 16, 32, dll. Jika objek yang diminta berukuran 24 byte, maka overhead akan muncul dari memori. Distribusi akan mengembalikan objek ini kepada Anda, tetapi akan ditempatkan di kumpulan yang sesuai dengan objek berukuran 32 byte. 8 byte yang tersisa akan menganggur.
Cuplikan (slab.hpp):
inline void* phys_to_virt_p(void* p) { return reinterpret_cast<char*>(p) + sizeof(std::thread::id); } inline size_t phys_to_virt_n(size_t n) { return n - sizeof(std::thread::id); } inline void* virt_to_phys_p(void* p) { return reinterpret_cast<char*>(p) - sizeof(std::thread::id); } inline size_t virt_to_phys_n(size_t n) { return n + sizeof(std::thread::id); } inline std::thread::id& phys_thread_id(void* p) { return *reinterpret_cast<std::thread::id*>(p); } class slab : public noncopyable { public: slab() { small::quota_init(& quota_, 1024 * 1024 * 1024); small::slab_arena_create(&arena_, & quota_, 0, 1024 * 1024, MAP_PRIVATE); small::slab_cache_create(&cache_, &arena_); small::allocator_create(&allocator_, &cache_, 2, 2.f); } ~slab() { small::allocator_destroy(&allocator_); small::slab_cache_destroy(&cache_); small::slab_arena_destroy(&arena_); } void* allocate(size_t n) { auto phys_n = virt_to_phys_n(n); auto phys_p = small::malloc(&allocator_, phys_n); if (!phys_p) return nullptr; phys_thread_id(phys_p) = std::this_thread::get_id(); return phys_to_virt_p(phys_p); } void deallocate(const void* p, size_t n) { auto phys_p = virt_to_phys_p(const_cast<void*>(p)); auto phys_n = virt_to_phys_n(n); assert(phys_thread_id(phys_p) == std::this_thread::get_id()); small::free(&allocator_, phys_p, phys_n); } private: small::quota quota_; small::slab_arena arena_; small::slab_cache cache_; small::allocator allocator_; };
Semua pembatasan ini berlaku untuk turunan khusus dari kelas variti :: slab. Karena setiap utas memiliki sendiri (pikirkan utas lokal), batas total pada proses tidak akan menjadi 1 GiB, tetapi akan berbanding lurus dengan jumlah utas yang menggunakan distribusi pelat.
Bagan (std :: utas :: id):
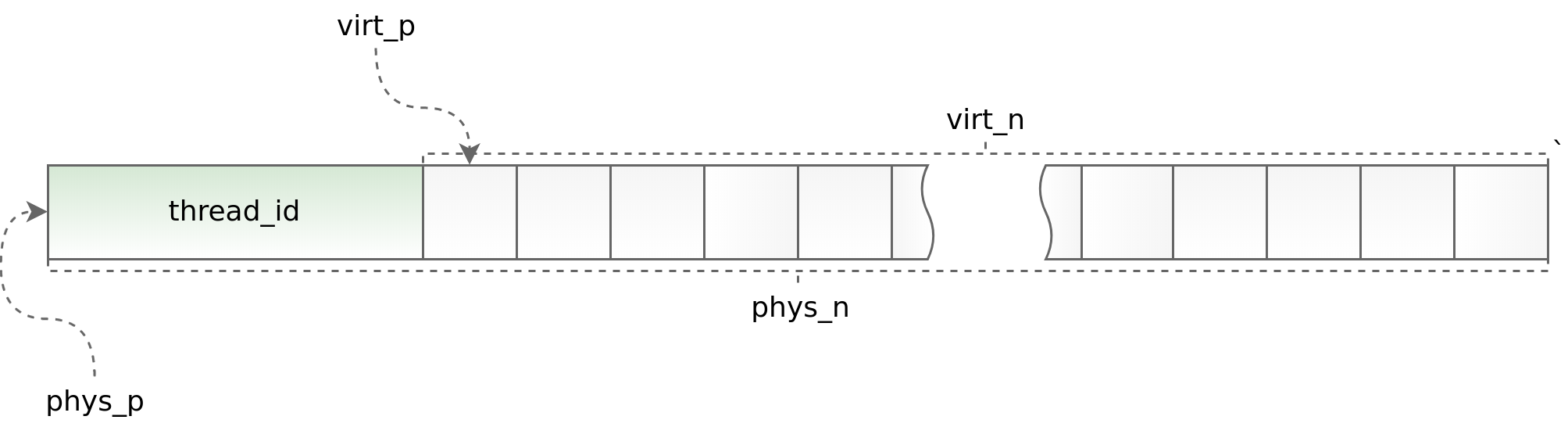
Di satu sisi, menggunakan thread lokal memungkinkan Anda untuk mempercepat pekerjaan distribusi slab dalam aplikasi multi-threaded, di sisi lain, itu memberlakukan batasan serius pada arsitektur aplikasi asinkron. Anda harus meminta dan mengembalikan objek dalam aliran yang sama. Melakukan ini sebagai bagian dari boost.asio terkadang sangat bermasalah. Untuk melacak situasi yang keliru jelas, pada awal setiap objek kita menempatkan pengidentifikasi aliran di mana metode alokasi dipanggil. Identifier ini kemudian diverifikasi dalam metode deallocate. Helpers Phys_to_virt_p dan virt_to_phys_p membantu dalam hal ini.
Cuplikan (thread_local_slab.hpp):
class thread_local_slab : public noncopyable { public: static void initialize(); static void finalize(); static void* allocate(size_t n); static void deallocate(const void* p, size_t n); };
Cuplikan (thread_local_slab.cpp):
static thread_local slab* slab_; void thread_local_slab::initialize() { slab_ = new slab(slab_cfg_); } void thread_local_slab::finalize() { delete slab_; } void* thread_local_slab::malloc(size_t n) { return slab_->malloc(n); } void thread_local_slab::free(const void* p, size_t n) { slab_->free(p, n); }
Ketika kontrol atas aliran hilang (saat mentransfer objek antara konteks io yang berbeda), penunjuk pintar memungkinkan pelepasan objek yang benar. Semua yang dia lakukan adalah mendistribusikan objek, mengingat konteks io-nya, dan kemudian membungkusnya di std :: shared_ptr dengan pembagi kustom, yang tidak segera mengembalikan objek ke distribusi, tetapi apakah itu dalam konteks io yang disimpan sebelumnya. Ini bekerja dengan baik ketika setiap konteks io berjalan pada satu utas. Kalau tidak, sayangnya, pendekatan ini tidak berlaku.
Cuplikan (slab_helper.hpp):
template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator](T* p) { p->~T(); allocator.deallocate(p); }); return ptr; }; template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, boost::asio::io_service* io, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator, io](T* p) { io->post([allocator, p]() { p->~T(); allocator.deallocate(p); }); }); return ptr; };
Solusi
Setelah pekerjaan pembungkusan libsmall selesai, pertama-tama kami memindahkan pengalokasi chun di dalam buffer aliran ke slab. Ini cukup mudah dilakukan. Setelah menerima hasil positif, kami melanjutkan dan menerapkan pengalokasi slab terlebih dahulu ke buffer aliran itu sendiri, dan kemudian ke semua objek di dalam sesi server dan klien.
- variti :: chunk
- variti :: streambuf
- variti :: server_session
- variti :: client_session
Pada saat yang sama, perlu untuk memecahkan masalah tambahan, yaitu: mentransfer objek sederhana, objek komposit, dan koleksi ke pengalokasi slab. Dan jika tidak ada kesulitan serius dengan dua kelas objek pertama (objek komposit direduksi menjadi yang sederhana), maka ketika menerjemahkan koleksi kami mengalami kesulitan serius.
- std :: daftar
- std :: deque
- std :: vektor
- std :: string
- std :: map
- std :: unordered_map
Salah satu batasan utama ketika bekerja dengan distribusi slab adalah bahwa jumlah objek dari tipe yang berbeda tidak boleh terlalu besar (semakin kecil, semakin baik). Dalam konteks ini, beberapa koleksi mungkin jatuh pada konsep pengalokasi slab, sementara beberapa mungkin tidak.
Untuk std :: list slab, pengalokasi berfungsi dengan baik. Koleksi ini diimplementasikan secara internal menggunakan daftar tertaut, yang masing-masing elemen memiliki ukuran tetap. Jadi, dengan penambahan data baru ke daftar std :: dalam distribusi slab, jenis objek baru tidak muncul. Kondisi yang ditunjukkan di atas puas! Std :: map diatur dengan cara yang sama. Satu-satunya perbedaan adalah bahwa di dalamnya bukan daftar yang ditautkan, tetapi sebuah pohon.
Dalam kasus std :: deque, banyak hal lebih rumit. Koleksi ini diimplementasikan melalui blok memori yang berdekatan yang berisi pointer ke chunks. Sementara potongan cukup akurat, std :: deque berperilaku sama dengan daftar std ::, tetapi ketika mereka berakhir, blok memori yang sama ini didistribusikan kembali. Dari sudut pandang pengalokasi slab, setiap redistribusi memori adalah objek dengan tipe baru. Jumlah objek yang ditambahkan ke koleksi secara langsung tergantung pada pengguna dan dapat tumbuh tanpa terkendali. Situasi ini tidak dapat diterima, jadi kami sebelumnya membatasi ukuran std :: deque di mana dimungkinkan, atau std :: list yang disukai.
Jika kita mengambil std :: vector dan std :: string, maka mereka masih lebih rumit. Implementasi koleksi ini agak mirip dengan std :: deque, kecuali bahwa blok memori kontinyu tumbuh secara signifikan lebih cepat. Kami mengganti std :: vector dan std :: string dengan std :: deque, dan dalam kasus terburuk dengan std :: list. Ya, kami kehilangan fungsionalitas dan bahkan di suatu tempat dalam kinerja, tetapi ini memengaruhi gambaran akhir jauh lebih sedikit daripada optimisasi untuk segala sesuatu yang dikandung.
Kami melakukan hal yang persis sama dengan std :: unordered_map, meninggalkannya demi variti yang ditulis sendiri :: flat_map diimplementasikan melalui std :: deque. Pada saat yang sama, kami cukup meng-cache kunci yang sering digunakan dalam variabel yang terpisah, misalnya, seperti yang dilakukan dengan header permintaan http di nginx.
Kesimpulan
Setelah menyelesaikan transfer penuh dari server dan sesi klien ke pengalokasi slab, kami mengurangi waktu yang dihabiskan untuk bekerja dengan sekelompok lebih dari satu setengah kali.
Cuplikan layar penguat (coldslab):
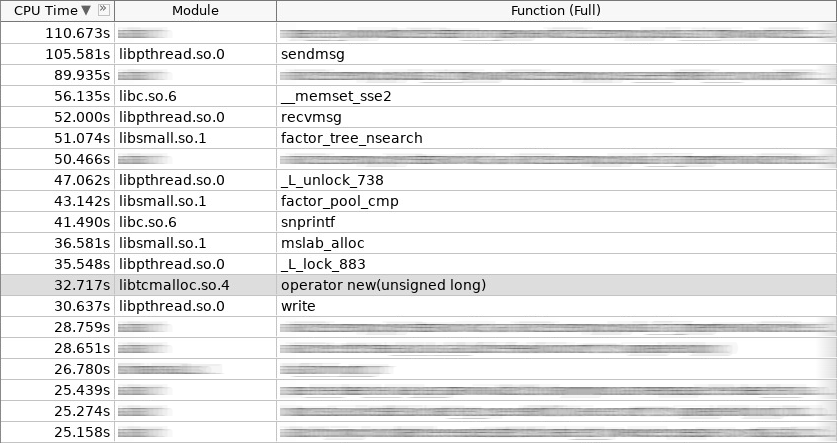
Dalam tangkapan layar, operator baru bekerja 32 detik, dan operator menghapus - 24 detik. Pada saat ini, fungsi-fungsi lain untuk bekerja dengan heap ditambahkan: smalloc - 21 detik, mslab_alloc - 37 detik, smfree - 8 detik, mslab_free - 21 detik. Total, 143 detik versus 161 detik.
Tetapi pengukuran ini dilakukan segera setelah memulai layanan tanpa menginisialisasi cache dalam distribusi slab. Setelah penembakan berulang dari tank-yandex, gambar keseluruhan membaik.
Cuplikan layar penguat (hotslab):
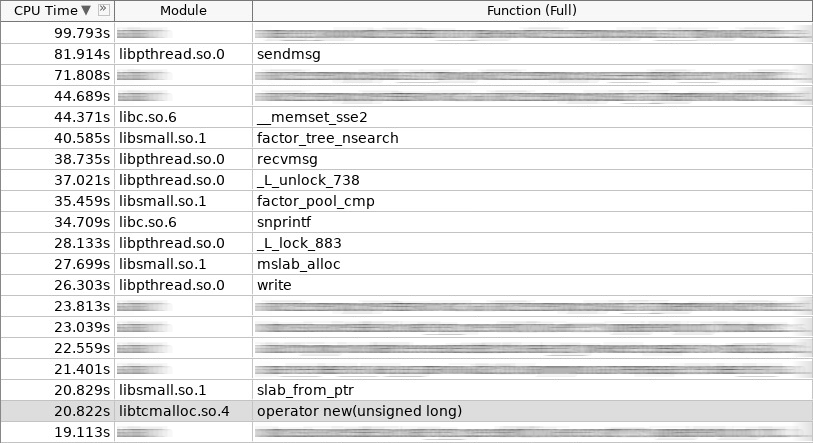
Dalam tangkapan layar, operator baru bekerja 20 detik, smalloc - 16 detik, mslab_alloc - 27 detik, operator hapus - 16 detik, smfree - 7 detik, mslab_free - 17 detik. Total 103 detik melawan 161 detik.
Meja pengukuran:
woslab coldslab hotslab operator new 67s 32s 20s smalloc - 21s 16s mslab_alloc - 37s 27s operator delete 94s 24s 16s smfree - 8s 7s mslab_free - 21s 17s summary 161s 143s 103s
Dalam kehidupan nyata, hasilnya harus lebih baik, karena pengalokasi slab tidak hanya memecahkan masalah alokasi memori yang lama dan membebaskan, tetapi juga mengurangi fragmentasi. Tanpa slab, seiring waktu, pengoperasian operator baru dan operator hapus hanya akan melambat. Dengan slab - itu akan selalu tetap pada level yang sama.
Seperti yang dapat kita lihat, pengalokasi slab berhasil memecahkan masalah alokasi memori objek yang sering digunakan. Perhatikan mereka jika masalah seringnya membuat dan memindahkan objek relevan untuk Anda. Tetapi jangan lupa tentang batasan yang mereka berikan pada arsitektur aplikasi Anda! Tidak semua objek kompleks dapat dengan mudah ditempatkan dalam distribusi slab. Terkadang Anda harus menyerah banyak! Nah, semakin kompleks arsitektur aplikasi Anda, semakin sering Anda harus berhati-hati mengembalikan objek ke cache yang benar dalam hal multithreading. Ini bisa sederhana ketika Anda segera mengerjakan arsitektur aplikasi, dengan mempertimbangkan penggunaan pengalokasi slab, tetapi pasti akan menyebabkan kesulitan ketika Anda memutuskan untuk mengintegrasikannya pada tahap akhir.
Aplikasi
Lihat kode sumber di
sini !