Pertanyaan klasik yang diajukan pengembang ke DBA atau pemilik bisnisnya, konsultan PostgreSQL, hampir selalu terdengar sama:
"Mengapa kueri berjalan pada basis data begitu lama?"Rangkaian alasan tradisional:
- algoritma yang tidak efisien
ketika Anda memutuskan untuk BERGABUNG dari beberapa CTE untuk beberapa puluh ribu catatan - statistik yang tidak relevan
jika sebenarnya distribusi data dalam tabel sudah sangat berbeda dari yang terakhir ANALYZE kumpulkan - "Gag" oleh sumber daya
dan sudah tidak ada cukup daya komputasi khusus dari CPU, gigabyte memori terus dipompa atau disk tidak mengikuti semua database "Wishlist" - menghalangi proses bersaing
Dan jika kunci cukup sulit untuk ditangkap dan dianalisis, maka untuk semua yang lain, kita memerlukan
rencana kueri yang dapat diperoleh dengan menggunakan
operator EXPLAIN (
lebih baik, tentu saja, segera MENJELASKAN (ANALYZE, BUFFERS) ... ) atau
modul auto_explain .
Tapi, seperti yang dikatakan dalam dokumentasi yang sama,
"Memahami rencana itu seni, dan untuk menguasainya, kau perlu pengalaman, ..."
Tapi Anda bisa melakukannya tanpanya, jika Anda menggunakan alat yang tepat!
Seperti apa tampilan rencana kueri? Sesuatu seperti ini:
Index Scan using pg_class_relname_nsp_index on pg_class (actual time=0.049..0.050 rows=1 loops=1) Index Cond: (relname = $1) Filter: (oid = $0) Buffers: shared hit=4 InitPlan 1 (returns $0,$1) -> Limit (actual time=0.019..0.020 rows=1 loops=1) Buffers: shared hit=1 -> Seq Scan on pg_class pg_class_1 (actual time=0.015..0.015 rows=1 loops=1) Filter: (relkind = 'r'::"char") Rows Removed by Filter: 5 Buffers: shared hit=1
atau seperti ini:
"Append (cost=868.60..878.95 rows=2 width=233) (actual time=0.024..0.144 rows=2 loops=1)" " Buffers: shared hit=3" " CTE cl" " -> Seq Scan on pg_class (cost=0.00..868.60 rows=9972 width=537) (actual time=0.016..0.042 rows=101 loops=1)" " Buffers: shared hit=3" " -> Limit (cost=0.00..0.10 rows=1 width=233) (actual time=0.023..0.024 rows=1 loops=1)" " Buffers: shared hit=1" " -> CTE Scan on cl (cost=0.00..997.20 rows=9972 width=233) (actual time=0.021..0.021 rows=1 loops=1)" " Buffers: shared hit=1" " -> Limit (cost=10.00..10.10 rows=1 width=233) (actual time=0.117..0.118 rows=1 loops=1)" " Buffers: shared hit=2" " -> CTE Scan on cl cl_1 (cost=0.00..997.20 rows=9972 width=233) (actual time=0.001..0.104 rows=101 loops=1)" " Buffers: shared hit=2" "Planning Time: 0.634 ms" "Execution Time: 0.248 ms"
Tetapi untuk membaca rencana dengan teks "dari lembaran" sangat sulit dan dicintai:
- node menampilkan jumlah sumber daya subtree
yaitu, untuk memahami berapa banyak waktu yang diperlukan untuk mengeksekusi node tertentu, atau tepatnya berapa banyak pembacaan dari tabel ini mengangkat data dari disk - Anda perlu entah bagaimana mengurangi satu dari yang lain - waktu simpul harus dikalikan dengan loop
ya, pengurangan bukan operasi yang paling sulit yang perlu dilakukan "dalam pikiran" - setelah semua, runtime ditunjukkan rata-rata lebih dari satu eksekusi node, dan mungkin ada ratusan dari mereka - baik, dan semua ini bersama-sama membuat sulit untuk menjawab pertanyaan utama - jadi siapa "rantai terlemah" ?
Ketika kami mencoba menjelaskan semua ini kepada beberapa ratus pengembang kami, kami menyadari bahwa dari luar terlihat seperti ini:

Dan itu berarti kita membutuhkan ...
Instrumen
Di dalamnya, kami mencoba mengumpulkan semua mekanik utama yang membantu sesuai dengan rencana dan meminta untuk memahami "siapa yang harus disalahkan dan apa yang harus dilakukan." Nah, bagikan beberapa pengalaman Anda dengan komunitas.
Temui dan gunakan -
jelaskan.tensor.ruRencana yang jelas
Apakah mudah untuk memahami rencana ketika terlihat seperti ini?
Seq Scan on pg_class (actual time=0.009..1.304 rows=6609 loops=1) Buffers: shared hit=263 Planning Time: 0.108 ms Execution Time: 1.800 ms
Tidak juga.
Tapi seperti ini,
dalam bentuk singkat , ketika indikator utama dipisahkan - sudah jauh lebih jelas:
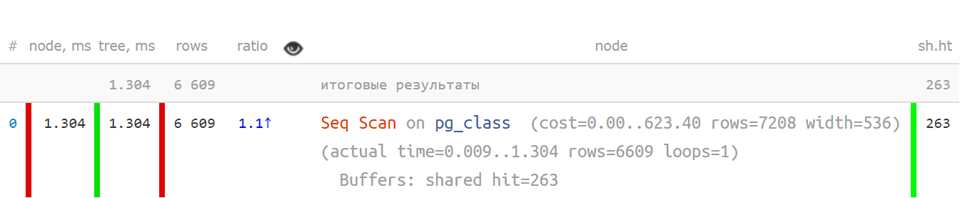
Tetapi jika rencana itu lebih rumit,
distribusi waktu piechart oleh node akan datang untuk
menyelamatkan :
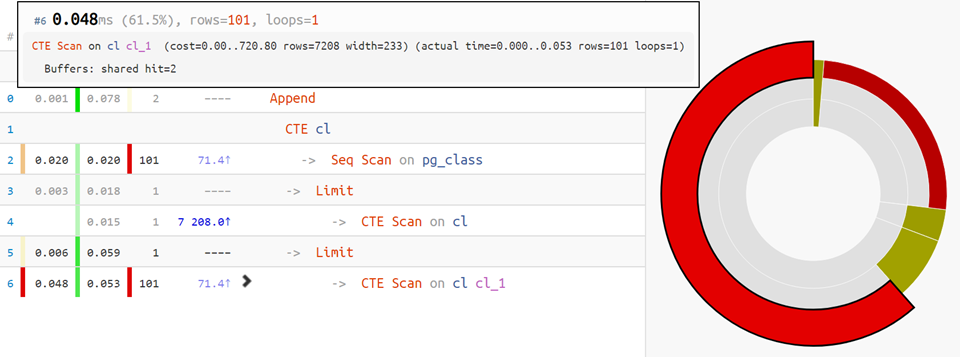
Nah, untuk opsi yang paling sulit,
diagram eksekusi bergegas untuk membantu:
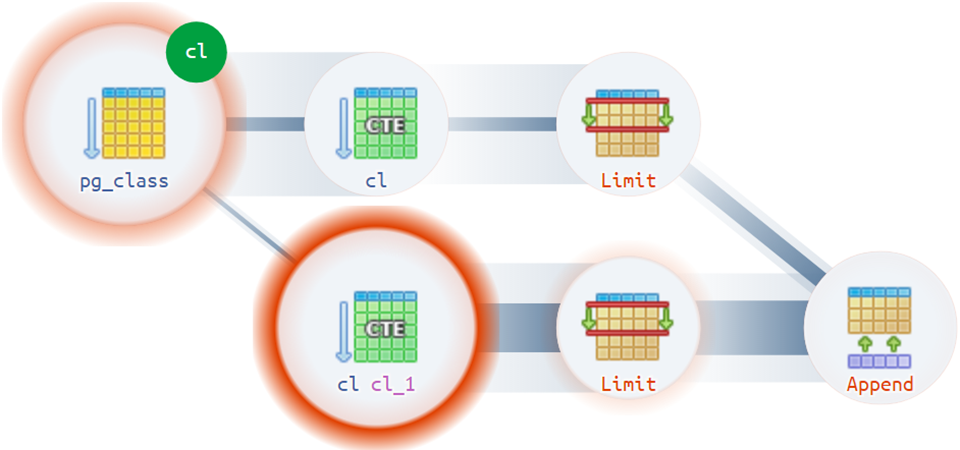
Misalnya, ada beberapa situasi yang tidak sepele ketika sebuah rencana dapat memiliki lebih dari satu root aktual:
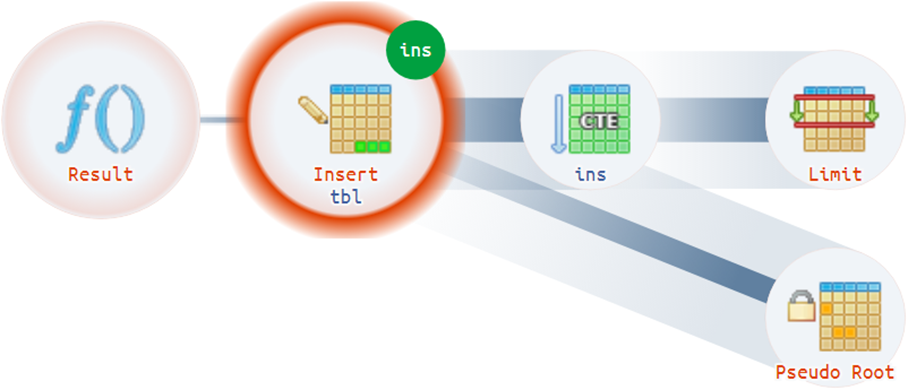
Tip Struktural
Nah, dan jika seluruh struktur rencana dan titik-titik sakitnya sudah ditata dan terlihat - mengapa tidak menyoroti mereka dengan pengembang dan menjelaskannya dengan "bahasa Rusia"?

Kami telah mengumpulkan beberapa lusin template rekomendasi tersebut.
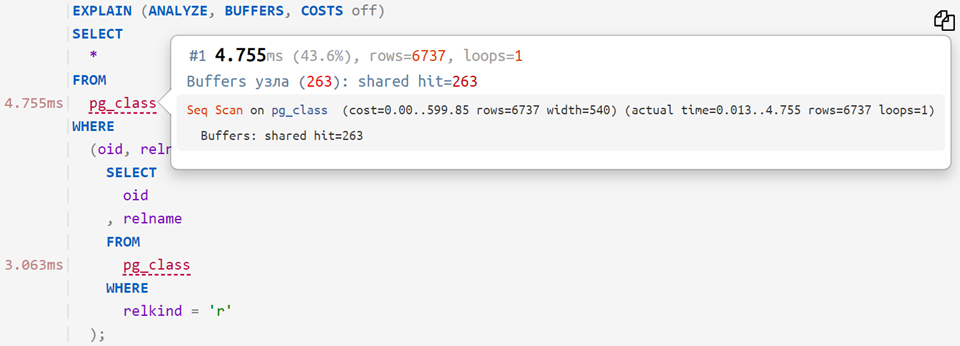
Profiler permintaan
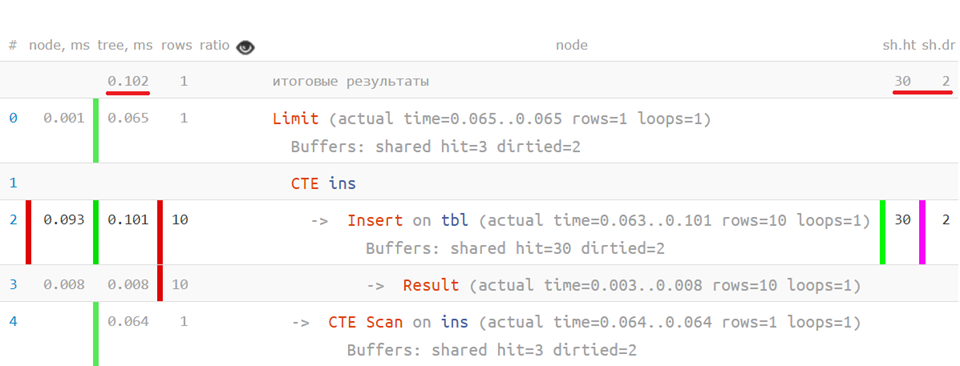
Sekarang, jika Anda menempatkan kueri asli pada paket yang dianalisis, Anda dapat melihat berapa banyak waktu yang dibutuhkan untuk masing-masing operator - seperti ini:
... atau bahkan lebih:

Substitusi parameter dalam permintaan
Jika Anda "melampirkan" tidak hanya permintaan pada paket, tetapi juga parameternya dari baris DETAIL log, Anda dapat menyalinnya di salah satu opsi:
- dengan substitusi nilai dalam permintaan
untuk eksekusi langsung pada basisnya dan pembuatan profil lebih lanjut
SELECT 'const', 'param'::text;
- dengan substitusi nilai melalui PREPARE / EXECUTE
untuk mengemulasi pekerjaan scheduler ketika bagian parametrik dapat diabaikan - misalnya, ketika bekerja pada tabel dipartisi
DEALLOCATE ALL; PREPARE q(text) AS SELECT 'const', $1::text; EXECUTE q('param'::text);
Arsip Rencana
Masukkan, analisis, bagikan dengan kolega! Paket tersebut akan tetap ada di arsip, dan Anda dapat kembali lagi nanti:
menjelaskan.tensor.ru/archiveTetapi jika Anda tidak ingin orang lain melihat rencana Anda, jangan lupa untuk mencentang kotak "jangan terbitkan dalam arsip".
Dalam artikel-artikel berikut saya akan berbicara tentang kesulitan dan solusi yang muncul dalam analisis rencana.