Hai
Kebetulan Anda menonton film, dan di kepala Anda hanya ada satu pertanyaan - "Apakah saya mendapatkan clickbait lagi?" Kami akan menyelesaikan masalah ini dan kami hanya akan menonton film yang sesuai. Saya sarankan untuk sedikit bereksperimen dengan data dan menulis jaringan saraf sederhana untuk mengevaluasi film.
Eksperimen kami didasarkan pada teknologi analisis sentimen untuk menentukan suasana hati audiens terhadap suatu produk. Sebagai data kami mengambil dataset ulasan pengguna pada film IMDb. Lingkungan pengembangan Google Colab akan memungkinkan Anda untuk dengan cepat melatih jaringan saraf Anda berkat akses gratis ke GPU (NVidia Tesla K80).
Saya menggunakan perpustakaan Keras, dengan bantuan yang saya akan membangun model universal untuk memecahkan masalah pembelajaran mesin yang sama. Saya akan membutuhkan backend TensorFlow, versi default di Colab 1.15.0, jadi cukup tingkatkan ke 2.0.0.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
Selanjutnya, kami mengimpor semua modul yang diperlukan untuk preprocessing data dan pembangunan model. Pada artikel sebelumnya, penekanannya adalah pada perpustakaan, Anda dapat melihat di sana.
%matplotlib inline import matplotlib import matplotlib.pyplot as plt
import numpy as np from keras.utils import to_categorical from keras import models from keras import layers from keras.datasets import imdb
Parsing Data IMDb
Dataset IMDb terdiri dari 50.000 ulasan film dari pengguna yang ditandai positif (1) dan negatif (0).
- Ulasan sudah diproses sebelumnya, dan masing-masing disandikan dengan urutan indeks kata dalam bentuk bilangan bulat
- Kata-kata dalam ulasan diindeks berdasarkan frekuensi totalnya dalam dataset. Misalnya, bilangan bulat "2" mengkodekan kata yang paling sering digunakan kedua
- 50.000 ulasan dibagi menjadi dua set: 25.000 untuk pelatihan dan 25.000 untuk pengujian.
Unduh dataset yang dibangun ke Keras. Karena data dibagi menjadi pelatihan dan tes dalam rasio 50-50, saya akan menggabungkannya sehingga nanti saya bisa membaginya dengan 80-20.
from keras.datasets import imdb (training_data, training_targets), (testing_data, testing_targets) = imdb.load_data(num_words=10000) data = np.concatenate((training_data, testing_data), axis=0) targets = np.concatenate((training_targets, testing_targets), axis=0)
Eksplorasi data
Mari kita lihat apa yang sedang kita kerjakan.
print("Categories:", np.unique(targets)) print("Number of unique words:", len(np.unique(np.hstack(data))))

length = [len(i) for i in data] print("Average Review length:", np.mean(length)) print("Standard Deviation:", round(np.std(length)))

Anda dapat melihat bahwa semua data termasuk dalam dua kategori: 0 atau 1, yang mewakili mood peninjauan. Seluruh dataset berisi 9998 kata unik, ukuran ulasan rata-rata adalah 234 kata dengan standar deviasi 173.
Mari kita lihat review pertama dari dataset ini, yang ditandai sebagai positif.
print("Label:", targets[0]) print(data[0])

index = imdb.get_word_index() reverse_index = dict([(value, key) for (key, value) in index.items()]) decoded = " ".join( [reverse_index.get(i - 3, "#") for i in data[0]] ) print(decoded)

Persiapan data
Saatnya menyiapkan data. Kita perlu membuat vektor setiap survei dan mengisinya dengan nol sehingga vektor tersebut berisi persis 10.000 angka. Ini berarti bahwa setiap ulasan yang lebih pendek dari 10.000 kata diisi dengan nol. Saya melakukan ini karena ikhtisar terbesar hampir sama ukurannya, dan setiap elemen input dari jaringan saraf kita harus memiliki ukuran yang sama. Anda juga perlu mengubah variabel menjadi tipe float.
def vectorize(sequences, dimension = 10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1 return results data = vectorize(data) targets = np.array(targets).astype("float32")
Selanjutnya, saya membagi dataset menjadi data pelatihan dan tes sesuai kesepakatan 4: 1.
test_x = data[:10000] test_y = targets[:10000] train_x = data[10000:] train_y = targets[10000:]
Buat dan latih model
Masalahnya kecil, tetap hanya untuk menulis model dan melatihnya. Mulailah dengan memilih jenis. Dua jenis model tersedia dalam Keras: berurutan dan dengan API fungsional. Maka Anda perlu menambahkan lapisan input, tersembunyi dan keluaran.
Untuk mencegah pelatihan ulang, kita akan menggunakan "dropout" di antara mereka. Pada setiap lapisan kita menggunakan fungsi "padat" untuk sepenuhnya menghubungkan lapisan satu sama lain. Di lapisan tersembunyi kita akan menggunakan fungsi aktivasi "relu", ini hampir selalu mengarah ke hasil yang memuaskan. Pada layer output kami menggunakan fungsi sigmoid yang merenormalkan kembali nilai dalam kisaran dari 0 hingga 1.
Saya menggunakan pengoptimal adam, itu akan mengubah bobot selama pelatihan.
Kami menggunakan cross-entropy biner sebagai fungsi kerugian, dan akurasi sebagai metrik ukuran.
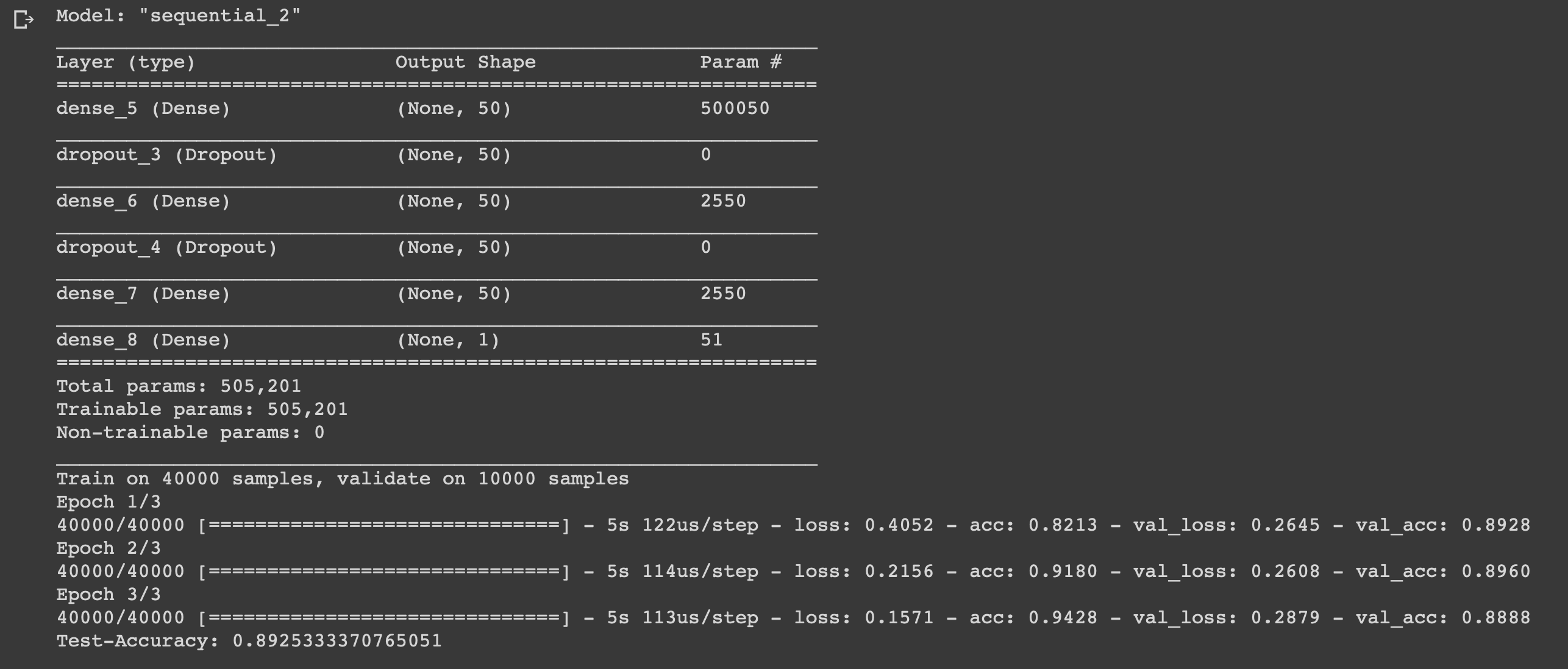
Sekarang Anda dapat melatih model kami. Kami akan melakukan ini dengan ukuran batch 500 dan hanya tiga era, karena terungkap bahwa model mulai melatih kembali jika dilatih lebih lama.
model = models.Sequential()
Kesimpulan
Kami telah membuat jaringan saraf enam lapis sederhana yang dapat menghitung mood pembuat film dengan akurasi 0,89. Tentu saja, untuk menonton film keren sama sekali tidak perlu untuk menulis jaringan saraf, tetapi ini hanyalah contoh lain dari bagaimana Anda dapat menggunakan data, manfaatkan dari itu, karena Anda memerlukannya untuk itu. Jaringan saraf bersifat universal karena kesederhanaan strukturnya, mengubah beberapa parameter, Anda dapat menyesuaikannya untuk tugas yang sama sekali berbeda.
Jangan ragu untuk menuliskan ide Anda di komentar.