
Merancang analitik streaming dan sistem pemrosesan data streaming memiliki nuansa tersendiri, masalah tersendiri, dan tumpukan teknologinya sendiri. Kami membicarakan hal ini dalam
pelajaran terbuka berikutnya, yang diadakan menjelang peluncuran kursus
Insinyur Data .
Di webinar dibahas:
- saat pemrosesan streaming diperlukan;
- elemen apa yang ada di SPOD, alat apa yang bisa kita gunakan untuk mengimplementasikan elemen-elemen ini;
- cara membangun sistem analisis clickstream Anda sendiri.
Dosen -
Yegor Mateshuk , Insinyur Data Senior di MaximaTelecom.
Kapan streaming diperlukan? Streaming vs Gelombang
Pertama-tama, kita perlu mencari tahu kapan kita perlu streaming, dan kapan pemrosesan batch. Mari kita jelaskan kekuatan dan kelemahan pendekatan ini.
Jadi, kerugian dari pemrosesan batch:- data dikirimkan dengan penundaan. Karena kita memiliki periode perhitungan tertentu, maka untuk periode ini kita selalu ketinggalan waktu nyata. Dan semakin banyak iterasi, semakin kita tertinggal. Dengan demikian, kami mendapat penundaan waktu, yang dalam beberapa kasus sangat penting;
- beban puncak pada besi dibuat. Jika kami menghitung banyak dalam mode batch, pada akhir periode (hari, minggu, bulan) kami memiliki beban puncak, karena Anda perlu menghitung banyak hal. Apa yang menyebabkan ini? Pertama, kita mulai bersandar pada batasan, yang, seperti yang Anda tahu, tidak terbatas. Akibatnya, sistem berjalan secara berkala hingga batas, yang sering mengakibatkan kegagalan. Kedua, karena semua pekerjaan ini dimulai pada saat yang sama, mereka bersaing dan dihitung cukup lambat, yaitu, Anda tidak dapat mengandalkan hasil yang cepat.
Tetapi pemrosesan batch memiliki kelebihan:- efisiensi tinggi. Kami tidak akan masuk lebih dalam, karena efisiensi terkait dengan kompresi, dan dengan kerangka kerja, dan dengan penggunaan format kolom, dll. Faktanya adalah bahwa pemrosesan batch, jika Anda mengambil jumlah catatan yang diproses per unit waktu, akan lebih efisien;
- kemudahan pengembangan dan dukungan. Anda dapat memproses bagian mana pun dari data dengan menguji dan menghitung ulang seperlunya.
Keuntungan pemrosesan data streaming (streaming):- menghasilkan waktu nyata. Kami tidak menunggu akhir periode: segera setelah data (bahkan jumlah yang sangat kecil) datang kepada kami, kami dapat segera memprosesnya dan meneruskannya. Artinya, hasilnya, menurut definisi, berjuang untuk waktu nyata;
- beban seragam pada besi. Jelas bahwa ada siklus harian, dll., Namun, bebannya masih didistribusikan sepanjang hari dan ternyata lebih seragam dan dapat diprediksi.
Kerugian utama dari pemrosesan streaming:- kompleksitas pengembangan dan dukungan. Pertama, menguji, mengelola, dan mengambil data sedikit lebih sulit jika dibandingkan dengan batch. Kesulitan kedua (sebenarnya, ini adalah masalah paling mendasar) dikaitkan dengan rollback. Jika pekerjaan tidak berhasil, dan ada kegagalan, sangat sulit untuk menangkap momen di mana semuanya rusak. Dan memecahkan masalah akan membutuhkan lebih banyak upaya dan sumber daya daripada pemrosesan batch.
Jadi, jika Anda berpikir tentang
apakah Anda perlu streaming , jawablah pertanyaan berikut untuk diri sendiri:
- Apakah Anda benar-benar membutuhkan waktu nyata?
- Apakah ada banyak sumber streaming?
- Apakah kehilangan satu catatan penting?
Mari kita lihat
dua contoh :
Contoh 1. Analisis stok untuk ritel:- tampilan barang tidak berubah secara real time;
- data paling sering dikirim dalam mode batch;
- kehilangan informasi sangat penting.
Dalam contoh ini, lebih baik menggunakan batch.
Contoh 2. Analisis untuk portal web:- kecepatan analitik menentukan waktu respons terhadap suatu masalah;
- data datang secara real time;
- Kehilangan sejumlah kecil informasi aktivitas pengguna dapat diterima.
Bayangkan analitik mencerminkan bagaimana perasaan pengunjung ke portal web menggunakan produk Anda. Misalnya, Anda meluncurkan rilis baru dan Anda perlu memahami dalam 10-30 menit apakah semuanya beres, jika ada fitur kustom yang rusak. Katakanlah teks dari tombol "Pesan" hilang - analitik akan memungkinkan Anda untuk dengan cepat merespons penurunan tajam dalam jumlah pesanan, dan Anda akan segera memahami bahwa Anda harus mundur.
Jadi, dalam contoh kedua, lebih baik menggunakan stream.
Elemen SPOD
Insinyur pemrosesan data menangkap, memindahkan, mengirim, mengonversi, dan menyimpan data ini (ya, penyimpanan data juga merupakan proses yang aktif!).
Oleh karena itu, untuk membangun sistem pemrosesan data streaming (SPOD), kita perlu elemen-elemen berikut:
- pemuat data (sarana pengiriman data ke penyimpanan);
- bus pertukaran data (tidak selalu diperlukan, tetapi tidak ada cara untuk mengalirkannya, karena Anda membutuhkan sistem yang melaluinya Anda akan bertukar data secara langsung);
- penyimpanan data (seperti tanpa itu);
- Mesin ETL (diperlukan untuk melakukan berbagai penyaringan, penyortiran dan operasi lainnya);
- BI (untuk menampilkan hasil);
- orchestrator (menghubungkan seluruh proses bersama-sama, mengatur pemrosesan data multi-tahap).
Dalam kasus kami, kami akan mempertimbangkan situasi paling sederhana dan hanya fokus pada tiga elemen pertama.
Alat Pemroses Streaming Data
Kami memiliki beberapa "kandidat" untuk peran
pemuat data :
- Apache flume
- Apache nifi
- Streamset
Apache flume
Yang pertama akan kita bicarakan adalah
Apache Flume , alat untuk mengangkut data antara berbagai sumber dan repositori.

Pro:
- hampir di mana-mana
- lama digunakan
- cukup fleksibel dan dapat diperluas
Cons:
- konfigurasi tidak nyaman
- sulit dipantau
Adapun konfigurasinya, tampilannya seperti ini:

Di atas, kami membuat satu saluran sederhana yang berada di port, mengambil data dari sana dan hanya mencatatnya. Pada prinsipnya, untuk menggambarkan satu proses, ini masih normal, tetapi ketika Anda memiliki lusinan proses seperti itu, file konfigurasi berubah menjadi neraka. Seseorang menambahkan beberapa konfigurator visual, tetapi mengapa repot-repot jika ada alat yang membuatnya keluar dari kotak? Misalnya, NiFi dan StreamSets yang sama.
Apache nifi
Bahkan, ia melakukan peran yang sama dengan Flume, tetapi dengan antarmuka visual, yang merupakan nilai tambah besar, terutama ketika ada banyak proses.
Beberapa fakta tentang NiFi
- awalnya dikembangkan di NSA;
- Hortonworks sekarang didukung dan dikembangkan;
- bagian dari HDF dari Hortonworks;
- memiliki versi khusus MiNiFi untuk mengumpulkan data dari perangkat.
Sistemnya terlihat seperti ini:
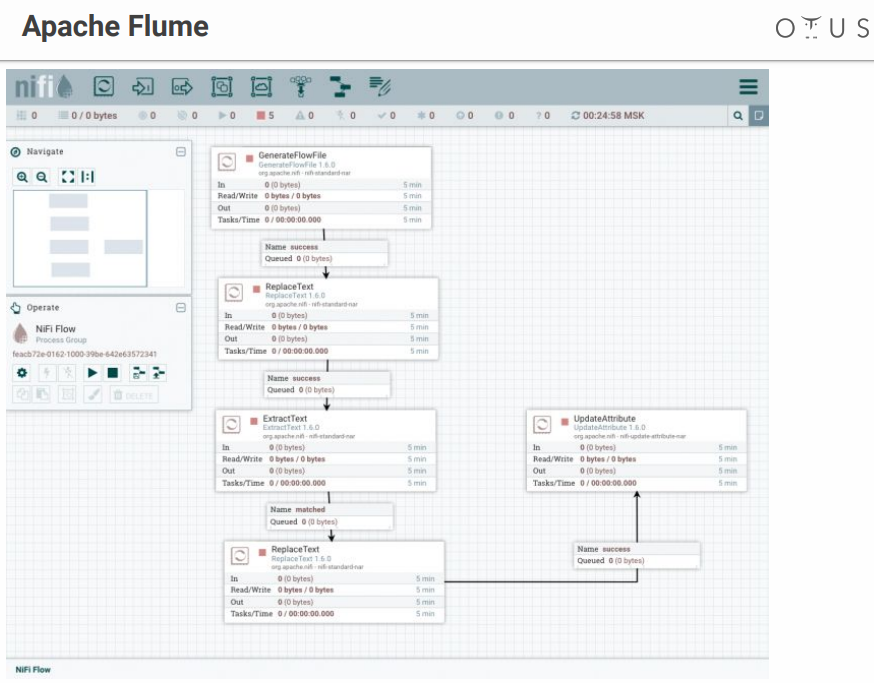
Kami memiliki bidang kreativitas dan tahapan pemrosesan data yang kami lemparkan ke sana. Ada banyak konektor untuk semua sistem yang memungkinkan, dll.
Streamset
Ini juga merupakan sistem kontrol aliran data dengan antarmuka visual. Ini dikembangkan oleh orang-orang dari Cloudera, mudah diinstal sebagai Parcel di CDH, ia memiliki versi khusus dari SDC Edge untuk mengumpulkan data dari perangkat.
Terdiri dari dua komponen:
- SDC - sistem yang melakukan pemrosesan data langsung (gratis);
- StreamSets Control Hub - pusat kontrol untuk beberapa SDC dengan fitur tambahan untuk pengembangan paylines (berbayar).
Itu terlihat seperti ini:

Momen tidak menyenangkan - StreamSets memiliki bagian gratis dan berbayar.
Bus data
Sekarang mari kita cari tahu di mana kita akan mengunggah data ini. Pelamar:
Apache Kafka adalah pilihan terbaik, tetapi jika Anda memiliki RabbitMQ atau NATS di perusahaan Anda, dan Anda perlu menambahkan sedikit analitik, maka menggunakan Kafka dari awal tidak akan sangat menguntungkan.
Dalam semua kasus lain, Kafka adalah pilihan yang bagus. Bahkan, ini adalah broker pesan dengan penskalaan horizontal dan bandwidth besar. Ini sangat terintegrasi ke dalam seluruh ekosistem alat untuk bekerja dengan data dan dapat menahan beban berat. Ini memiliki antarmuka universal dan merupakan sistem sirkulasi pemrosesan data kami.
Di dalam, Kafka dibagi menjadi Topik - aliran data terpisah dari pesan dengan skema yang sama atau, setidaknya, dengan tujuan yang sama.
Untuk membahas nuansa berikutnya, Anda harus ingat bahwa sumber data mungkin sedikit berbeda. Format data sangat penting:

Format serialisasi data Apache Avro patut disebutkan secara khusus. Sistem menggunakan JSON untuk menentukan struktur data (skema) yang diserialisasi ke dalam
format biner yang ringkas . Oleh karena itu, kami menyimpan sejumlah besar data, dan serialisasi / deserialisasi lebih murah.
Semuanya tampak baik-baik saja, tetapi keberadaan file terpisah dengan sirkuit menimbulkan masalah, karena kita perlu bertukar file antara sistem yang berbeda. Tampaknya itu sederhana, tetapi ketika Anda bekerja di departemen yang berbeda, orang-orang di ujung sana dapat mengubah sesuatu dan tenang, dan semuanya akan rusak untuk Anda.
Agar tidak mentransfer semua file ini ke flash drive, floppy disk dan lukisan gua, ada layanan khusus - Schema registry. Ini adalah layanan untuk menyinkronkan skema-avro antara layanan yang menulis dan membaca dari Kafka.

Dalam hal Kafka, produsen adalah orang yang menulis, konsumen adalah orang yang mengkonsumsi (membaca) data.
Gudang data
Penantang (pada kenyataannya, ada banyak opsi lagi, tetapi hanya mengambil beberapa):
- HDFS + Sarang
- Kudu + Impala
- Clickhouse
Sebelum memilih repositori, ingat
idempotensi apa
itu . Wikipedia mengatakan bahwa idempotensi (idem Latin - yang sama + potens - mampu) - properti dari suatu objek atau operasi ketika menerapkan operasi ke objek lagi, memberikan hasil yang sama seperti yang pertama. Dalam kasus kami, proses pemrosesan streaming harus dibangun sehingga saat mengisi ulang sumber data, hasilnya tetap benar.
Cara mencapai ini dalam sistem streaming:
- mengidentifikasi id unik (dapat berupa gabungan)
- gunakan id ini untuk mendeduplikasi data
Penyimpanan HDFS + Hive
tidak memberikan idempotensi untuk streaming rekaman "out of the box", jadi kami memiliki:
Kudu adalah repositori yang cocok untuk kueri analitik, tetapi dengan Kunci Utama, untuk deduplikasi.
Impala adalah antarmuka SQL ke repositori ini (dan beberapa lainnya).
Adapun ClickHouse, ini adalah database analitik dari Yandex. Tujuan utamanya adalah analitik pada tabel yang diisi dengan aliran besar data mentah. Dari kelebihan - ada mesin ReplacingMergeTree untuk deduplikasi kunci (deduplikasi dirancang untuk menghemat ruang dan dapat meninggalkan duplikat dalam beberapa kasus, Anda perlu mempertimbangkan
nuansa ).
Tetap menambahkan beberapa kata tentang
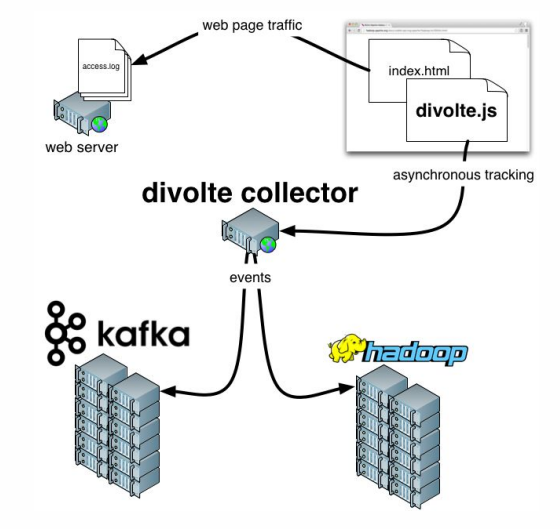
Divolte . Jika Anda ingat, kami berbicara tentang fakta bahwa beberapa data perlu ditangkap. Jika Anda perlu mengatur analisis untuk portal dengan cepat dan mudah, maka Divolte adalah layanan yang sangat baik untuk menangkap acara pengguna di halaman web melalui JavaScript.
Contoh praktis
Apa yang kita coba lakukan?
Mari kita coba membangun saluran untuk mengumpulkan data Clickstream secara real time.
Clickstream adalah jejak virtual yang ditinggalkan pengguna saat berada di situs Anda. Kami akan mengambil data menggunakan Divolte, dan menulisnya di Kafka.

Anda perlu Docker untuk bekerja, ditambah Anda harus mengkloning
repositori berikut . Segala sesuatu yang terjadi akan diluncurkan dalam wadah. Untuk secara konsisten menjalankan banyak wadah sekaligus,
docker-compose.yml akan digunakan. Selain itu, ada
Dockerfile yang mengkompilasi StreamSet kami dengan dependensi tertentu.
Ada juga tiga folder:
- data clickhouse akan ditulis ke clickhouse-data
- persis ayah yang sama ( sdc-data ) yang akan kita miliki untuk StreamSets, di mana sistem dapat menyimpan konfigurasi
- folder ketiga ( contoh ) termasuk file permintaan dan file konfigurasi pipa untuk StreamSets

Untuk memulai, masukkan perintah berikut:
docker-compose up
Dan kami menikmati betapa lambat tapi pasti wadah mulai. Setelah memulai, kita bisa pergi ke alamat
http: // localhost: 18630 / dan segera sentuh Divolte:

Jadi, kami memiliki Divolte, yang telah menerima beberapa acara dan merekamnya di Kafka. Mari kita coba menghitungnya menggunakan StreamSets:
http: // localhost: 18630 / (kata sandi / login - admin / admin).

Agar tidak menderita, lebih baik
mengimpor Pipeline , menamainya, misalnya,
clickstream_pipeline . Dan dari folder contoh kita mengimpor
clickstream.json . Jika semuanya baik-baik saja,
kita akan melihat gambar berikut :

Jadi, kami membuat koneksi ke Kafka, mendaftarkan Kafka mana yang kami butuhkan, mendaftarkan topik mana yang menarik minat kami, kemudian memilih bidang yang menarik minat kami, kemudian menguras Kafka, mendaftarkan Kafka mana dan topik mana. Perbedaannya adalah bahwa dalam satu kasus, format Data adalah Avro, dan yang kedua hanya JSON.
Mari kita lanjutkan. Kami dapat, misalnya,
membuat pratinjau yang menangkap catatan tertentu secara real time dari Kafka. Lalu kami menuliskan semuanya.
Setelah diluncurkan, kita akan melihat bahwa aliran acara terbang ke Kafka, dan ini terjadi secara real time:

Sekarang Anda dapat membuat repositori untuk data ini di ClickHouse. Untuk bekerja dengan ClickHouse, Anda dapat menggunakan klien asli yang sederhana dengan menjalankan perintah berikut:
docker run -it --rm --network divolte-ss-ch_default yandex/clickhouse-client --host clickhouse
Harap perhatikan bahwa baris ini menunjukkan jaringan yang ingin Anda sambungkan. Dan tergantung pada bagaimana Anda memberi nama folder dengan repositori, nama jaringan Anda mungkin berbeda. Secara umum, perintahnya adalah sebagai berikut:
docker run -it --rm --network {your_network_name} yandex/clickhouse-client --host clickhouse
Daftar jaringan dapat dilihat dengan perintah:
docker network ls
Tidak ada yang tersisa:
1.
Pertama, "tandatangani" ClickHouse kami ke Kafka , "jelaskan kepadanya" format data apa yang kami butuhkan di sana:
CREATE TABLE IF NOT EXISTS clickstream_topic ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = Kafka SETTINGS kafka_broker_list = 'kafka:9092', kafka_topic_list = 'clickstream', kafka_group_name = 'clickhouse', kafka_format = 'JSONEachRow';
2.
Sekarang kita akan membuat tabel nyata di mana kita akan meletakkan data akhir:
CREATE TABLE clickstream ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = ReplacingMergeTree() ORDER BY (timestamp, pageViewId);
3.
Dan kemudian kami akan memberikan hubungan antara dua tabel ini :
CREATE MATERIALIZED VIEW clickstream_consumer TO clickstream AS SELECT * FROM clickstream_topic;
4.
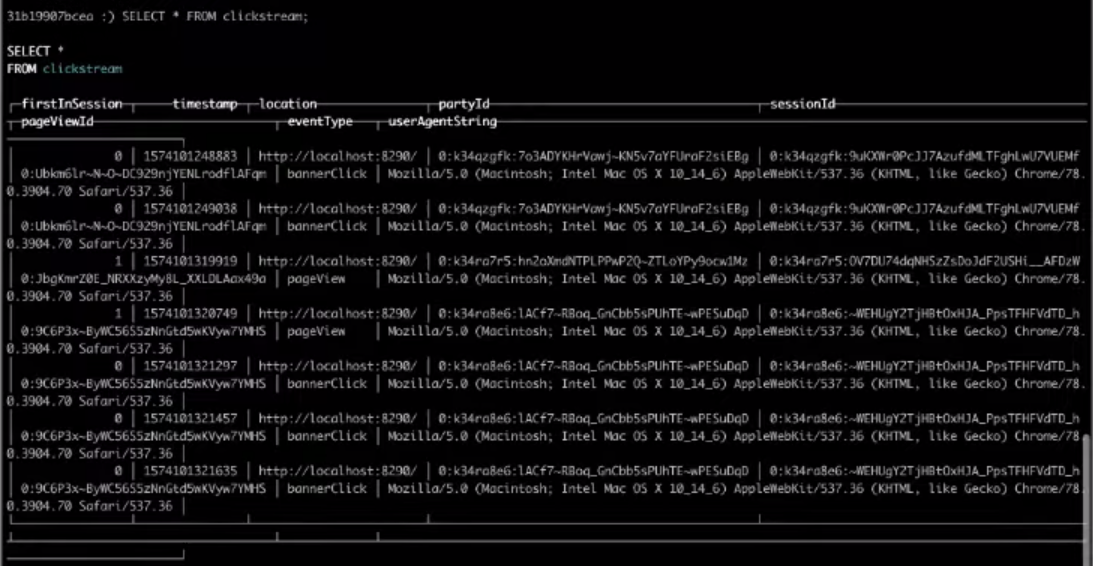
Dan sekarang kita akan memilih bidang yang diperlukan :
SELECT * FROM clickstream;
Akibatnya, pilihan dari tabel target akan memberi kita hasil yang kita butuhkan.
Itu saja, itu Clickstream paling sederhana yang bisa Anda buat. Jika Anda ingin menyelesaikan sendiri langkah-langkah di atas,
tonton seluruh
video .