
Sejarah pembelajaran mesin dimulai pada pertengahan abad terakhir. Pada saat itu, teknologi ini lebih merupakan area untuk penelitian dan eksperimen ilmiah, dan komputer yang kuat memberikan dorongan untuk aplikasi praktis ML.
Saat ini, pembelajaran mesin merupakan tren yang tidak dapat disangkal di pasar TI. Semakin banyak perusahaan dari berbagai industri menciptakan divisi ilmu data untuk menggunakan pembelajaran mesin untuk menemukan peluang baru dalam akumulasi data untuk pertumbuhan dan meningkatkan efisiensi bisnis. Namun, sementara inisiatif ini tidak memberikan pengembalian karena jatuh tempo. Menurut statistik, 8 dari 10 kasus yang dikonfirmasi tidak masuk ke operasi komersial.
Kemungkinan besar, sebagian besar dari Anda telah mendengar lelucon "cara paling efektif untuk membuat pembelajaran mesin menjadi lebih produktif adalah slide PowerPoint." Sayangnya, ini bukan lelucon. Seringkali seluruh proses terlihat seperti ini: bisnis mentransmisikan data dan kasus bisnis yang diunduh dari sistem bisnis. Data Para ilmuwan mengembangkan model pembelajaran mesin di Notebook Jupiter, menempatkan tangkapan layar grafik pada slide PowerPoint, dan mengirimkannya ke pelanggan bisnis. Apakah mungkin untuk menggunakan slide yang dihasilkan dalam membuat keputusan manajemen? Kemungkinan besar tidak, karena data perkiraan dengan cepat menjadi usang, dan situasi dalam bisnis selama waktu ini dapat berubah secara serius.
Mencoba untuk mengatasi semua hambatan dan membuat pembelajaran mesin mengalir, sebagian besar perusahaan berinvestasi dalam infrastruktur pengumpulan, penyimpanan, dan pemrosesan data dalam jumlah besar - Data Lake. Tentu saja, ini merupakan langkah penting. Tapi apa yang berubah dari perspektif bisnis? Apakah mungkin membuat keputusan berdasarkan pembelajaran mesin? Tidak, karena ada kesenjangan antara Data Lake dan bisnis. Jelas, mengapa 86% dari perusahaan yang disurvei percaya bahwa aplikasi bisnis generasi selanjutnya harus dilengkapi dengan pembelajaran mesin.
Kami di SAP memutuskan untuk menulis serangkaian artikel tentang cara mengatasi kesulitan yang ada dengan platform SAP Data Intelligence yang baru dan menempatkan alat yang sangat kuat sebagai pembelajaran mesin pada layanan bisnis. Dan, jika Anda tertarik dengan topik ini, baca terus :)
Untuk memulai, saya akan memberi tahu Anda tentang tahap pertama dan sangat penting dalam pengembangan kasus bisnis apa pun "Pencarian dan Persiapan Data". Dalam artikel-artikel berikutnya, kami akan mempertimbangkan tahapan “Pengembangan dan pelatihan model”, “Integrasi dengan SAP dan non-SAP on-premise dan sumber data cloud secara terperinci”, “Menciptakan layanan untuk menggunakan model”, “Mentransfer kasus bisnis ke produktif”, “Pemantauan dan pengoperasian kasus bisnis ”dan banyak lagi.
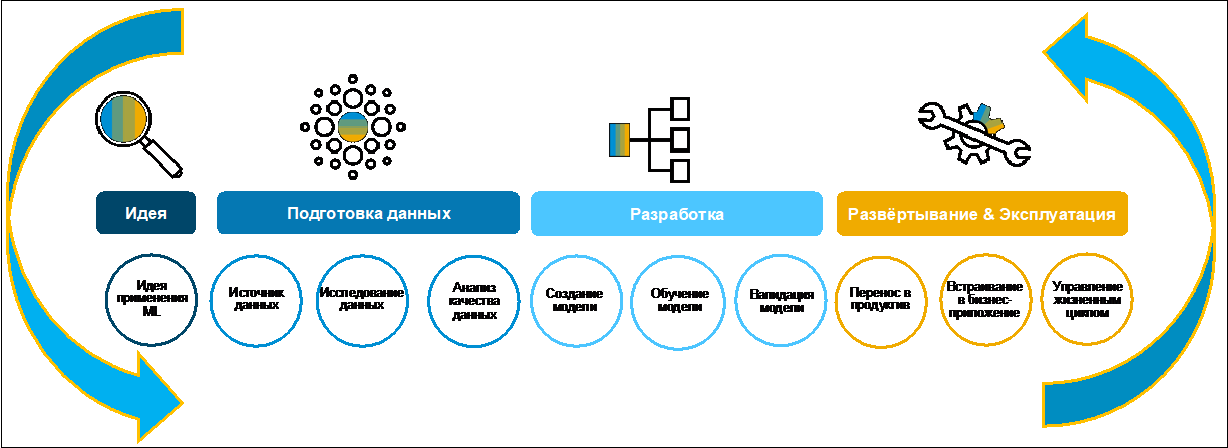
Pengembangan kasus bisnis berdasarkan pembelajaran mesin. Cari dan persiapan data.Mari kita lihat proses pembuatan case bisnis (Gambar 1).
Awalnya, sebuah ide biasanya dirumuskan oleh sebuah bisnis. Seringkali, ia melakukannya dengan sukarela, karena ia memiliki tujuan yang pasti untuk mendigitalkan fungsi-fungsi dalam transformasi digital seluruh perusahaan. Untuk mengumpulkan, mengevaluasi, dan memprioritaskan ide, Anda dapat menggunakan, misalnya, SAP Innovation Management.
 Gambar 1
Gambar 1Pada tahap pertama pencarian dan persiapan data, perlu dipahami apakah ada atau tidak sama sekali untuk pengembangan kasus bisnis, di mana mereka disimpan, dalam format apa dan kualitas apa itu. Lansekap modern yang khas mencakup banyak sistem heterogen. Data dapat diduplikasi dalam aplikasi yang berbeda. Menemukan informasi yang tepat dapat memakan banyak waktu. Untuk tujuan ini, dalam kecerdasan Data SAP, tugas ini telah sangat disederhanakan menggunakan Katalog Metadata. Mari kita lihat apa itu dan bagaimana menggunakannya.
Katalog metadataUntuk menggunakan katalog metadata, Anda harus menghubungkan sistem sumber ke Data Intelligence. Sumber data untuk Data Intelligence dapat berupa sistem di lokasi SAP ERP, BW, Pemasaran ... dan MES non-SAP, Oracle, MS SQL, DB2, Hadoop, dan banyak lainnya, serta layanan cloud Amazon, Azzure, Google SCP. Untuk terhubung ke sumber data, Anda memerlukan informasi tentang lokasi sistem dan pengguna teknis yang dibuat dalam sistem ini khusus untuk integrasi dengan SAP Data Intelligence. Gambar 2 menunjukkan contoh lanskap data yang disesuaikan di SAP Data Intelligence.
 Gambar 2
Gambar 2
Setelah dikonfigurasi dalam Katalog Metadata Data Intelijen SAP, dimungkinkan untuk melihat informasi yang disimpan pada sistem yang terhubung. Gambar 3 menunjukkan daftar file yang terletak di folder DAT263 di Hadoop yang terhubung ke SAP Data Intelligence.
 Gambar 3
Gambar 3Jika Anda menemukan data yang diperlukan untuk menerapkan kasus bisnis, mari tambahkan objek data ke Katalog menggunakan fungsi publikasikan. Saya akan menggunakan file autos_history.csv, yang berisi statistik penjualan mobil bekas. Pada Gambar 4, Anda melihat bagaimana Anda dapat mempublikasikan objek data dan metadata-nya ke Katalog untuk akses cepat di masa depan.
 Gambar 4
Gambar 4Anda dapat menyesuaikan struktur direktori, tingkat hierarki sesuai dengan persyaratan kasus bisnis Anda. Misalnya, dalam folder Habr_demo saya, semua metadata tentang objek yang saya butuhkan untuk artikel ini akan dikumpulkan.
Katalog Metadata yang dihasilkan adalah akses cepat ke data kasus bisnis. Saya akan melakukan pembuatan profil dan analisis kualitas mereka pada objek folder saya di Katalog Metadata Data Intelijen SAP. Layar awal katalog metadata ditunjukkan pada Gambar. 5.
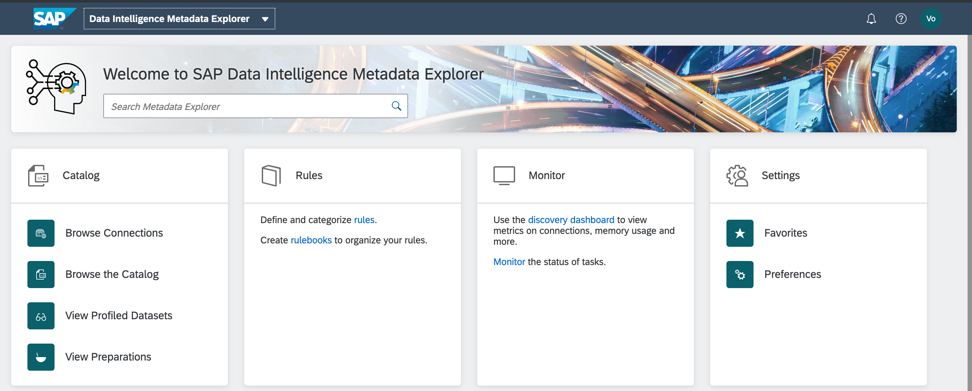 Gambar 5
Gambar 5Dan di sini adalah objek data yang saya terbitkan di folder Habr_demo (Gbr. 6)
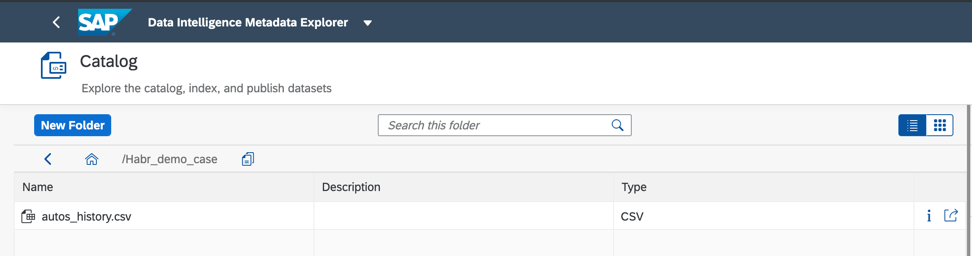 Gambar 6
Gambar 6Selain itu, untuk meningkatkan dan mempercepat pencarian, kami dapat menetapkan tag atau label dalam katalog objek data, seperti yang ditunjukkan pada Gambar. 7.
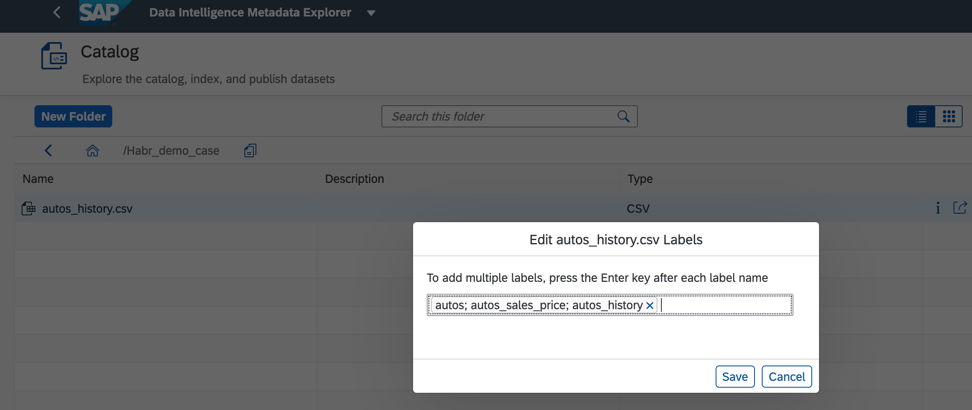 Gambar 7
Gambar 7Katalog metadata memungkinkan Anda untuk mencari objek berdasarkan nama, bidang, dan labelnya. Objek data tunggal mungkin memiliki beberapa label. Ini nyaman jika beberapa pengembang bekerja dengannya, semua orang dapat menetapkan label pada case bisnis mereka, dan dengan cepat menemukan semua yang Anda butuhkan darinya. Selain itu, tag dapat menyoroti data pribadi dan rahasia, akses yang harus dibatasi secara ketat.
Dalam kumpulan data yang dipertimbangkan, pencarian berdasarkan label dan nama bidang memberikan hasil cepat (Gbr. 8). Setuju, ini sangat nyaman!
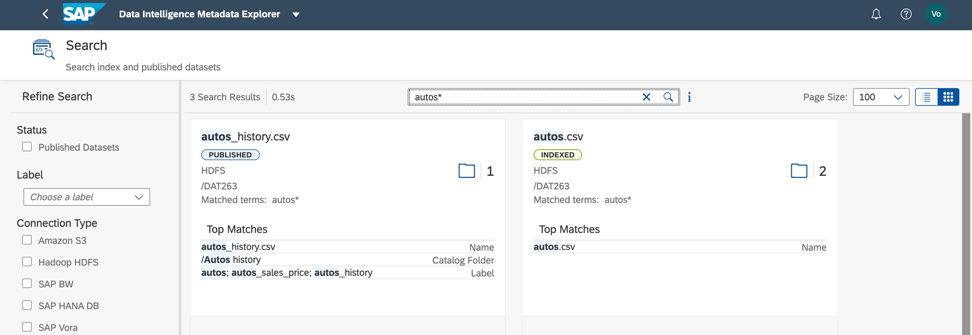 Gambar 8
Gambar 8Selanjutnya, kita perlu memahami bagaimana file kita diisi. Untuk melakukan ini, kita dapat membuat profil data. Kami juga memulai proses dari katalog metadata dan menu konteks untuk objek data (Gbr. 9).
 Gambar 9
Gambar 9Selama pembuatan profil, katalog metadata akan membaca isi file, menganalisis strukturnya dan mengisi. Hasilnya dapat ditemukan di Lembar Fakta (Gbr. 10).
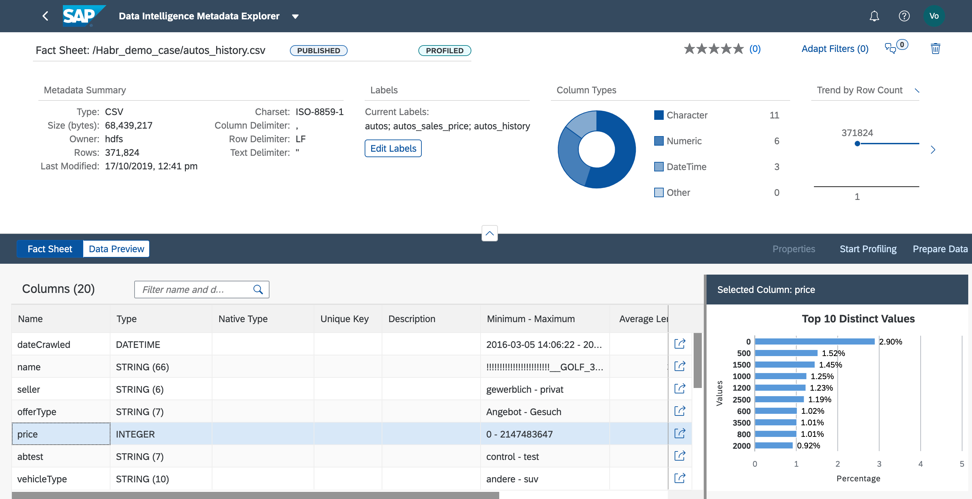 Gambar 10
Gambar 10
Dalam Lembar Fakta kita melihat struktur file dan informasi tentang mengisi kolom.
1. Dalam file yang dipilih, sebagai akibat dari pembuatan profil, kami mengungkapkan: bidang penjual memiliki satu nilai I di semua baris. Ini berarti bahwa kita dapat menghapus bidang ini dari kumpulan data agar tidak menggunakan pembelajaran mesin saat membangun model, karena itu tidak akan mempengaruhi hasil perkiraan (Gbr. 11).
 Gambar 11.2.
Gambar 11.2. Menganalisis kolom harga, kami memahami bahwa hampir 3% dari data yang kami miliki berisi harga nol. Untuk menggunakan file ini dalam kasus bisnis kami, kami harus mengisi harga dengan nilai aktual atau rata-rata untuk produk ini, atau kami harus menghapus garis dengan harga nol dari file (Gbr. 12).
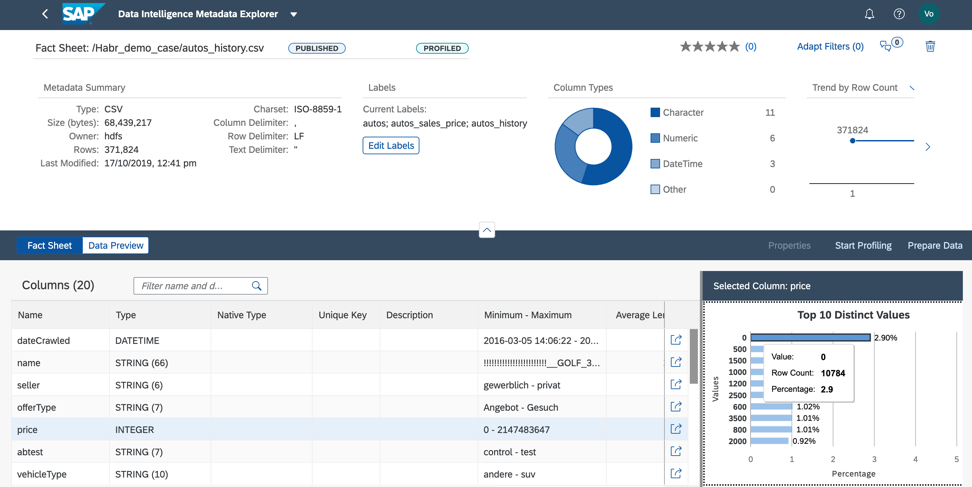 Gambar 12.
Gambar 12.Kita dapat melakukan preprocessing data dengan dua cara: di Katalog Metadata atau langsung di Notebook Jupiter. Pilihan alat tergantung pada siapa yang bertanggung jawab atas preprocessing data untuk kasus bisnis. Jika seorang analis, maka saya sarankan menggunakan antarmuka persiapan data visual, yang tersedia di Katalog Metadata. Jika seorang ilmuwan data terlibat dalam persiapan data, maka pilihan pasti harus mendukung Notebook Jupiter, yang juga diintegrasikan ke dalam Data Intelligence.
3. Nilai bidang model terdistribusi dengan baik, yang akan memungkinkan kita untuk melatih model secara kualitatif, seperti pada Gambar 13.
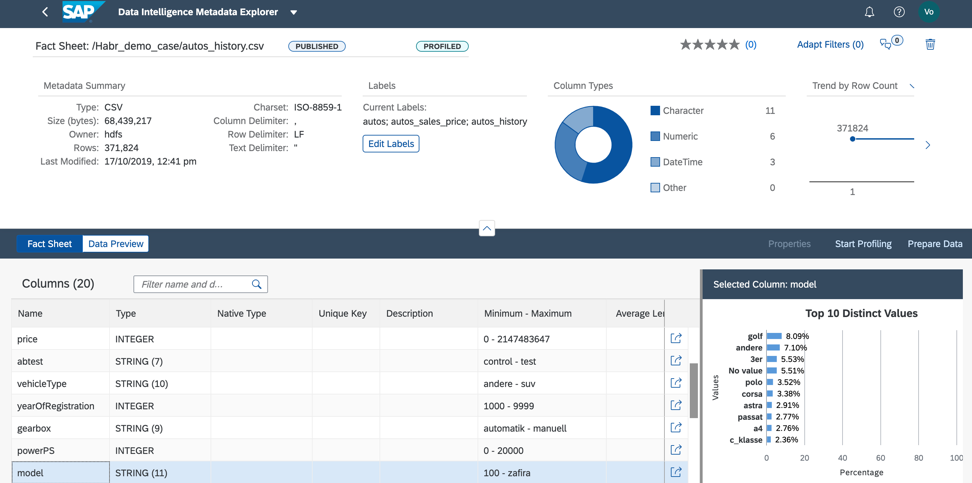 Gambar 13.
Gambar 13.
Sekarang kita memahami objek data apa yang diperlukan untuk mengimplementasikan kasus bisnis, objek data apa yang diisi, preprocessing apa yang harus kita lakukan untuk menggunakan data ini untuk mengimplementasikan, melatih, dan menguji model. Tetapi sebelum Anda mulai preprocessing, Anda perlu memeriksa kualitas data. Untuk melakukan ini, aturan bisnis tersedia di Katalog Metadata. Saya segera mencatat bahwa saat ini fungsi aturan bisnis memiliki sejumlah batasan serius. Oleh karena itu, saya merekomendasikan pemrosesan data yang lebih atau kurang rumit di Notebook Jupiter, yang diintegrasikan ke dalam SAP Data Intelligence.
Jadi, mari kita kembali ke kumpulan data kami dan memverifikasi kepatuhan dengan ambang batas minimum dan maksimum di bidang harga, sehingga kami dapat memperkirakan secara kasar apakah data memiliki anomali atau nilai yang salah. Seperti yang sudah Anda pahami, aturan bisnis juga dikonfigurasi dalam Katalog Metadata, seperti pada Gambar. 14a, c. Hubungan aturan dan data dikonfigurasikan dalam buku aturan (Rulebook). Ini memungkinkan Anda untuk menggunakan aturan yang sama untuk memverifikasi data yang berbeda.
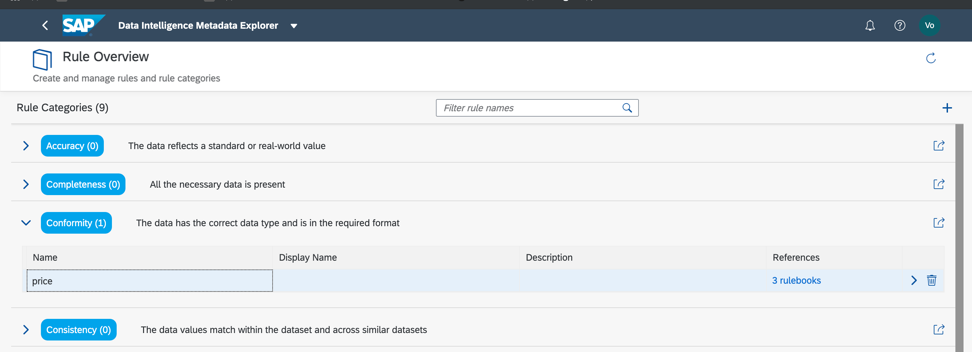 Gambar 14 a.
Gambar 14 a.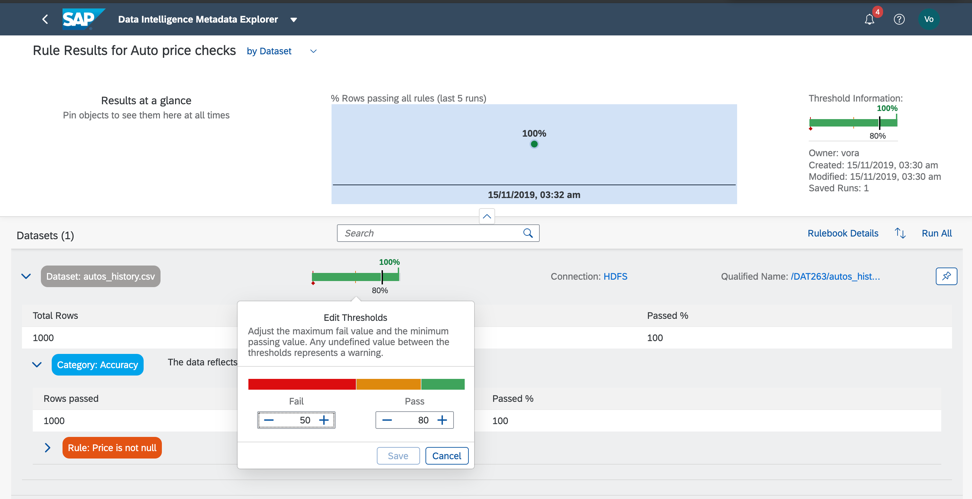 Gambar 14 c.
Gambar 14 c.Jadi, seperti yang kita lihat, data kita 100% benar.
Tetapi ini tidak selalu terjadi. Data dapat dianggap benar jika 75% dari catatan memenuhi persyaratan yang ditentukan dalam aturan.
Dimungkinkan untuk meningkatkan kualitas data, dan yang terutama, ini dilakukan dalam sistem akuntansi. Untuk melakukan ini, perusahaan mengatur proses manajemen data. Alasan lain yang mungkin adalah kriteria kualitas data yang salah didefinisikan.
Ringkasnya, saya ingin mengatakan tentang kelebihan dan kekurangan dari Katalog Metadata.
Menurut saya, ini memiliki 3 keunggulan utama:
- Sederhanakan akses data.
- Mempercepat pengambilan data.
- Antarmuka yang nyaman dan intuitif, yang dirancang tidak hanya untuk para profesional di bidang IT atau Data Sains, tetapi juga untuk bisnis yang terlibat dalam implementasi dan dukungan lebih lanjut dari kasus bisnis.
Dan, tentu saja, tentang kekurangannya. Mereka jelas. Saat ini, fungsionalitas Katalog Metadata di SAP Data Intelligence berada pada tingkat dasar. Mungkin cukup untuk mulai menggunakan, tetapi fungsionalitasnya tidak sepenuhnya mencakup semua persyaratan untuk solusi manajemen data.
Dan ini adalah konsekuensi dari kebaruan dan kompleksitas SAP Data Intelligence. SAP menginvestasikan banyak sumber daya untuk meningkatkan solusi ini. Dan ini menginspirasi keyakinan bahwa dalam waktu dekat Katalog Metadata akan berubah menjadi alat yang kuat untuk manajemen data. Akan ada peluang untuk membuat aturan bisnis yang rumit tanpa pemrograman. Juga dimungkinkan untuk mengintegrasikan SAP Information Steward dan SAP Data Hub untuk tujuan cakupan fungsional dari topik manajemen data.
Pada artikel berikutnya, kita akan berbicara tentang fase “Pengembangan dan pelatihan model dalam SAP Data Intelligence”. Semua yang paling menarik di depan!
Diposting oleh Elena Ganchenko, Pakar SAP CIS