Ketika Anda mempercayai seseorang hal paling berharga yang Anda miliki - data aplikasi atau layanan Anda - Anda ingin membayangkan bagaimana seseorang ini akan menangani nilai terbesar Anda.
Nama saya Vladimir Borodin, saya adalah kepala platform data Yandex.Cloud. Hari ini saya ingin memberi tahu Anda bagaimana semuanya diatur dan bekerja di dalam layanan Database Dikelola Yandex, mengapa semuanya dilakukan begitu saja dan apa keuntungannya - dari sudut pandang pengguna - dari berbagai solusi kami. Dan tentu saja, Anda pasti akan mengetahui apa yang kami rencanakan untuk diselesaikan dalam waktu dekat sehingga layanan menjadi lebih baik dan lebih nyaman bagi semua orang yang membutuhkannya.
Ayo pergi!

Managed Databases (Yandex Managed Databases) adalah salah satu layanan Yandex.Cloud paling populer. Lebih tepatnya, ini adalah seluruh kelompok layanan, yang sekarang hanya kedua setelah mesin virtual Yandex Compute Cloud dalam popularitas.
Database yang Dikelola Yandex memungkinkan untuk dengan cepat mendapatkan database yang berfungsi dan melakukan tugas-tugas seperti:
- Penskalaan - dari kemampuan dasar untuk menambah sumber daya komputasi atau ruang disk hingga peningkatan jumlah replika dan pecahan.
- Instal pembaruan, minor dan utama.
- Cadangkan dan pulihkan.
- Memberikan toleransi kesalahan.
- Pemantauan
- Menyediakan alat konfigurasi dan manajemen yang praktis.
Bagaimana layanan database dikelola diatur: tampilan atas
Layanan ini terdiri dari dua bagian utama: Control Plane dan Data Plane. Control Plane adalah, sederhananya, API manajemen basis data yang memungkinkan Anda untuk membuat, memodifikasi, atau menghapus basis data. Data Plane adalah tingkat penyimpanan data langsung.
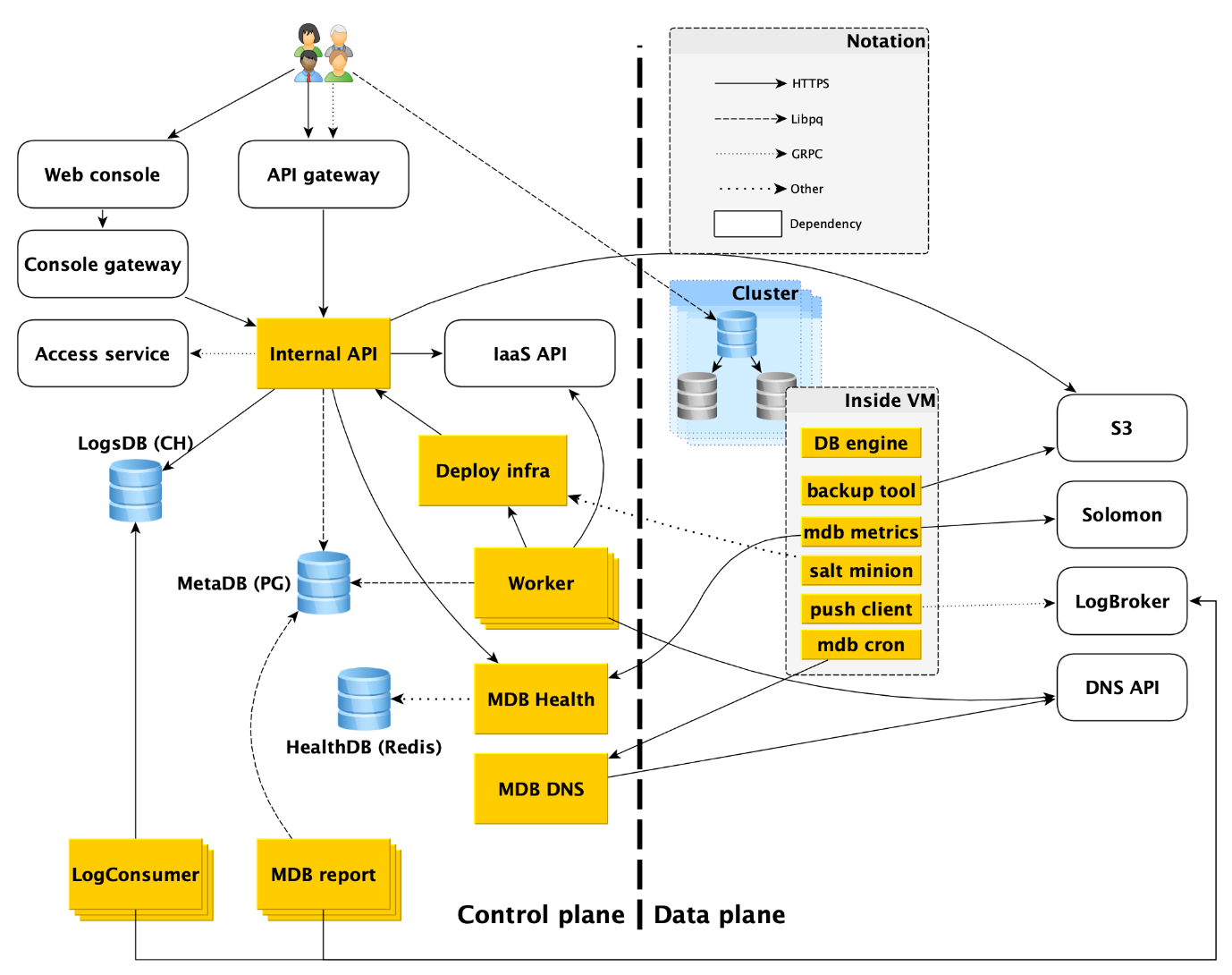
Faktanya, pengguna layanan memiliki dua titik masuk:
- Di Control Plane. Bahkan, ada banyak input - konsol Web, utilitas CLI, dan API gateway yang menyediakan API publik (gRPC dan REST). Tetapi semuanya akhirnya menuju ke apa yang kami sebut API Internal, dan oleh karena itu kami akan mempertimbangkan titik masuk yang satu ini ke dalam Control Plane. Bahkan, ini adalah titik dari mana area layanan Managed Databases (MDB) dimulai.
- Di Bidang Data. Ini adalah koneksi langsung ke database yang sedang berjalan melalui protokol akses ke DBMS. Jika itu, misalnya, PostgreSQL, maka itu akan menjadi antarmuka libpq .
Di bawah ini kami akan menjelaskan secara lebih rinci segala sesuatu yang terjadi di Data Plane, dan kami akan menganalisis masing-masing komponen Control Plane.
Pesawat data
Sebelum melihat komponen-komponen dari Pesawat Kontrol, mari kita lihat apa yang terjadi di Pesawat Data.
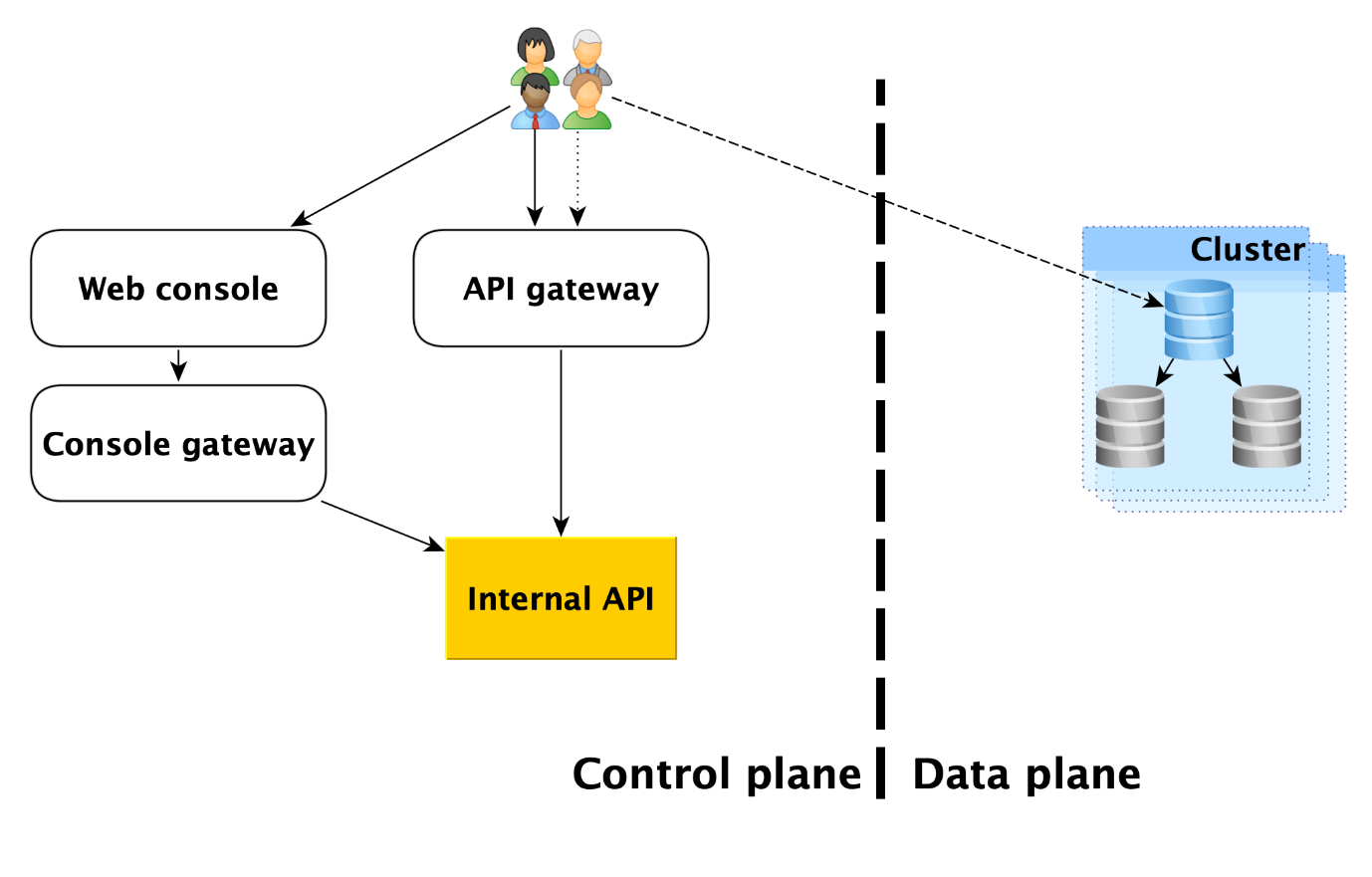
Di dalam mesin virtual
MDB menjalankan basis data di mesin virtual yang sama yang disediakan di
Yandex Compute Cloud .
Pertama-tama, mesin database, misalnya, PostgreSQL, ditempatkan di sana. Secara paralel, berbagai program tambahan dapat diluncurkan. Untuk PostgreSQL, ini akan menjadi
Odyssey , penarik koneksi database.
Juga di dalam mesin virtual, serangkaian layanan standar tertentu diluncurkan, masing-masing untuk setiap DBMS:
- Layanan untuk membuat cadangan. Untuk PostgreSQL, ini adalah alat WAL-G open source . Ini membuat cadangan dan menyimpannya di Penyimpanan Objek Yandex .
- Salt Minion adalah komponen dari sistem SaltStack untuk operasi dan manajemen konfigurasi. Informasi lebih lanjut tentang itu diberikan di bawah ini dalam deskripsi infrastruktur Deploy.
- Metrik MDB, yang bertanggung jawab untuk mentransmisikan metrik basis data ke Yandex Monitoring dan ke layanan mikro kami untuk memantau status cluster dan host MDB Health.
- Push client, yang mengirimkan log DBMS dan log tagihan ke layanan Logbroker, adalah solusi khusus untuk mengumpulkan dan mengirimkan data.
- Cron MDB - sepeda kami, yang berbeda dari cron biasa dalam kemampuan untuk melakukan tugas-tugas berkala dengan akurasi satu detik.
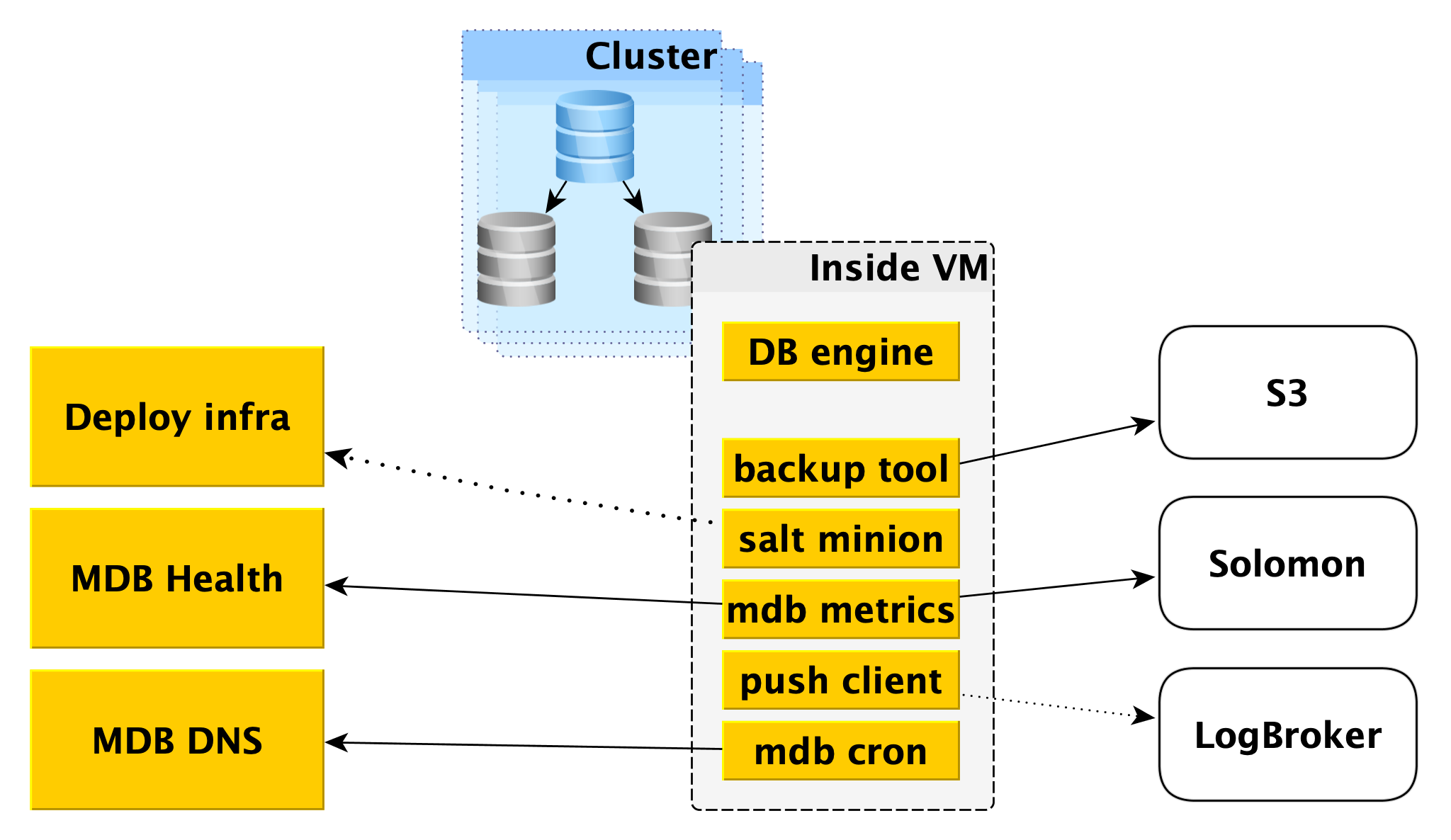
Topologi jaringan
Setiap host Data Plane memiliki dua antarmuka jaringan:
- Salah satunya menempel ke jaringan pengguna. Secara umum, diperlukan untuk memperbaiki muatan produk. Melalui itu, replikasi mengejar.
- Yang kedua menempel ke salah satu jaringan terkelola kami yang digunakan host untuk mengakses Control Plane.
Ya, host dari klien yang berbeda terjebak dalam satu jaringan terkelola seperti itu, tetapi ini tidak menakutkan, karena pada antarmuka terkelola (hampir) tidak ada yang mendengarkan, koneksi jaringan keluar di Control Plane hanya dibuka darinya. Hampir tidak ada, karena ada port terbuka (misalnya, SSH), tetapi ditutup oleh firewall lokal yang hanya memungkinkan koneksi dari host tertentu. Dengan demikian, jika seorang penyerang mendapatkan akses ke mesin virtual dengan database, ia tidak dapat mencapai database orang lain.
Keamanan Pesawat Data
Karena kita berbicara tentang keamanan, harus dikatakan bahwa kita awalnya merancang layanan berdasarkan penyerang mendapatkan root pada mesin virtual cluster.
Pada akhirnya, kami melakukan banyak upaya untuk melakukan hal berikut:
- Firewall lokal dan besar;
- Enkripsi semua koneksi dan cadangan;
- Semua dengan otentikasi dan otorisasi;
- AppArmor
- IDS yang ditulis sendiri.
Sekarang perhatikan komponen Control Plane.
Kontrol pesawat
API internal
API Internal adalah titik masuk pertama ke Control Plane. Mari kita lihat bagaimana semuanya bekerja di sini.
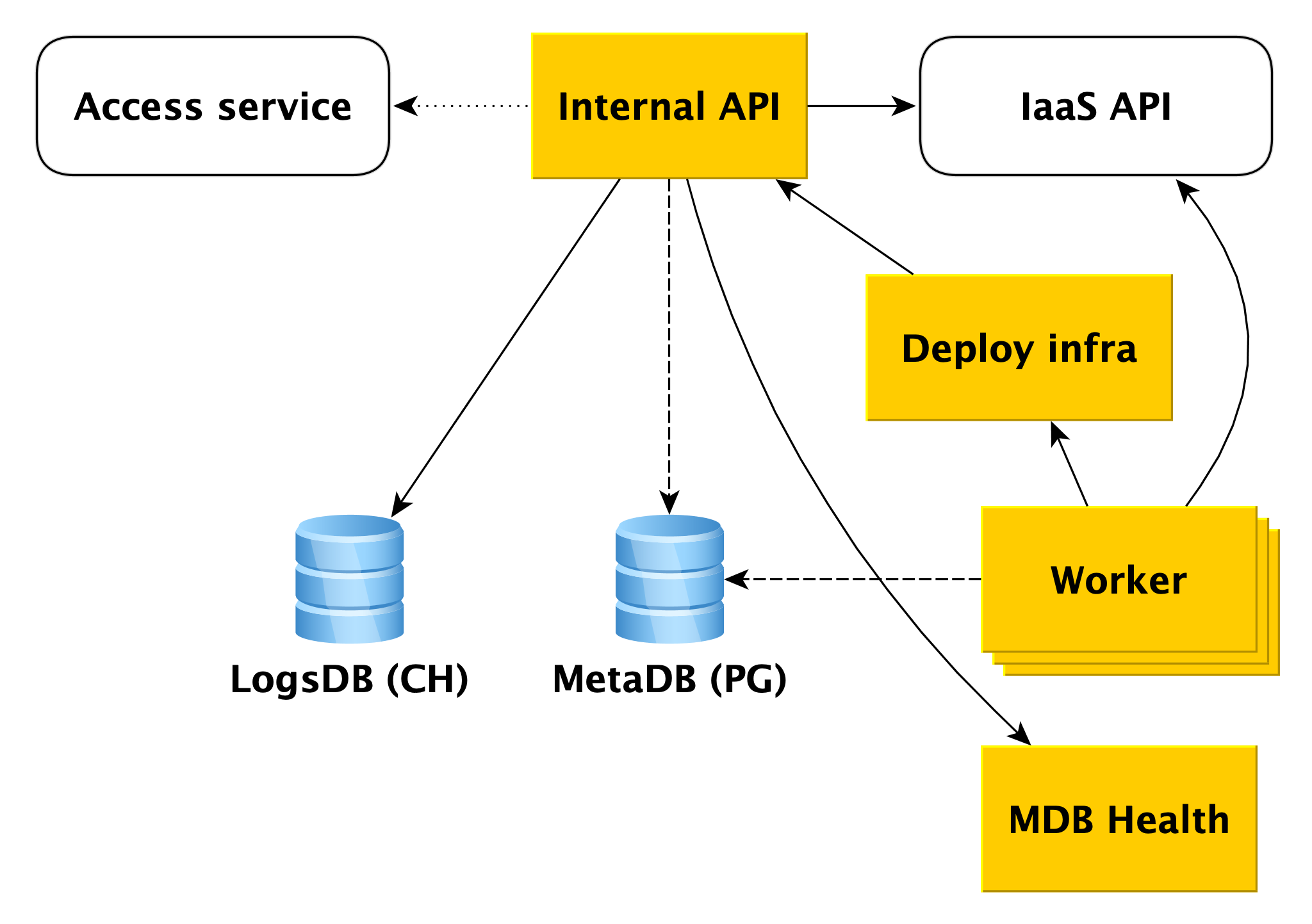
Misalkan API Internal menerima permintaan untuk membuat cluster database.
Pertama-tama, API Internal mengakses layanan Akses layanan cloud, yang bertanggung jawab untuk memeriksa otentikasi dan otorisasi pengguna. Jika pengguna lolos verifikasi, API Internal akan memeriksa validitas permintaan itu sendiri. Misalnya, permintaan untuk membuat sebuah cluster tanpa menyebutkan namanya atau dengan nama yang sudah diambil akan gagal dalam pengujian.
Dan API Internal dapat mengirim permintaan ke API layanan lain. Jika Anda ingin membuat cluster di jaringan A tertentu, dan host tertentu di subnet B tertentu, API Internal harus memastikan bahwa Anda memiliki hak untuk jaringan A dan subnet B. yang ditentukan. Pada saat yang sama, ia akan memeriksa apakah subnet B milik jaringan A Ini membutuhkan akses ke API infrastruktur.
Jika permintaan itu valid, informasi tentang cluster yang dibuat akan disimpan dalam metabase. Kami menyebutnya MetaDB, ini digunakan di PostgreSQL. MetaDB memiliki tabel dengan antrian operasi. API Internal menyimpan informasi tentang operasi dan menetapkan tugas secara transaksi. Setelah itu, informasi tentang operasi dikembalikan kepada pengguna.
Secara umum, untuk memproses sebagian besar permintaan API Internal, cukup menggunakan MetaDB dan API layanan terkait. Tetapi ada dua komponen lagi yang digunakan oleh API Internal untuk menjawab beberapa pertanyaan - LogsDB, di mana log cluster pengguna berada, dan MDB Health. Tentang masing-masing akan dijelaskan lebih detail di bawah ini.
Pekerja
Pekerja hanyalah seperangkat proses yang meminta antrian operasi di MetaDB, ambil dan jalankan.
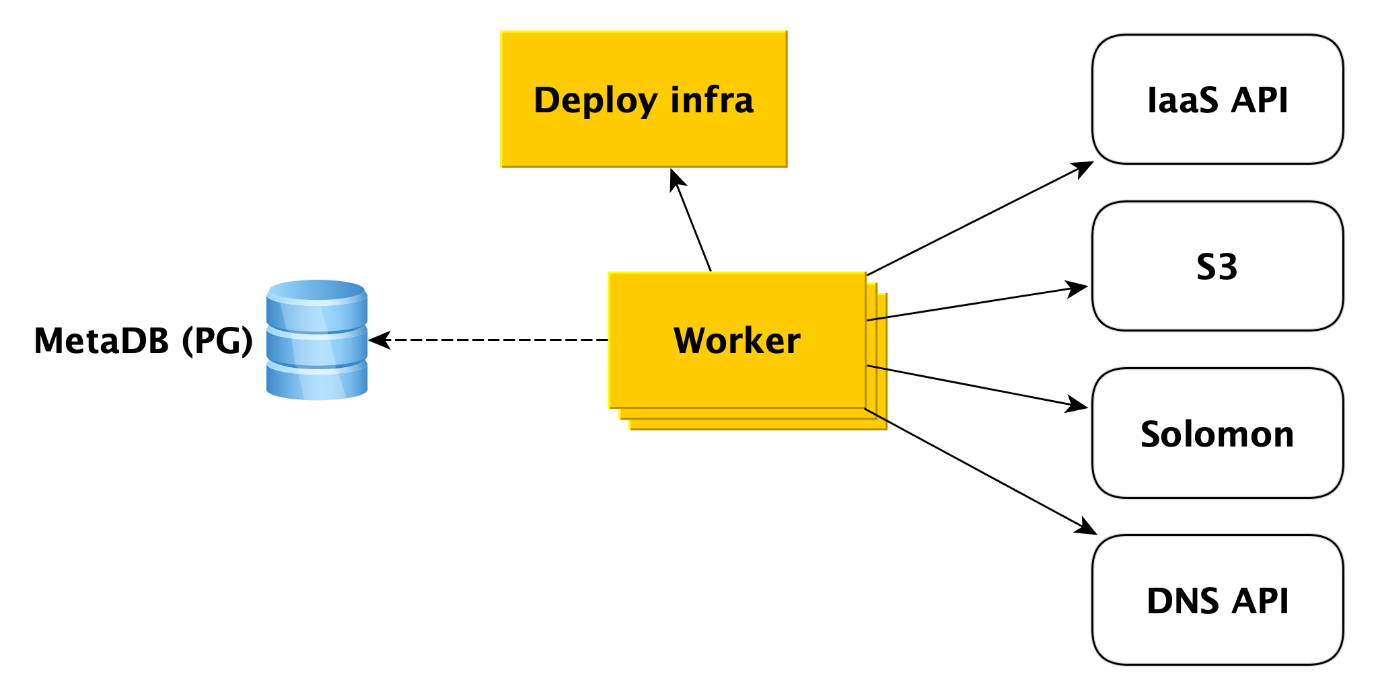
Apa sebenarnya yang dilakukan pekerja ketika sebuah cluster dibuat? Pertama dia beralih ke API infrastruktur untuk membuat mesin virtual dari gambar kita (mereka sudah memiliki semua paket yang diperlukan diinstal dan sebagian besar hal dikonfigurasi, gambar diperbarui sekali sehari). Ketika mesin virtual dibuat dan jaringan lepas landas di dalamnya, pekerja beralih ke infrastruktur Deploy (kami akan membicarakannya lebih lanjut nanti) untuk menyebarkan apa yang dibutuhkan pengguna ke mesin virtual.
Selain itu, pekerja mengakses layanan Cloud lainnya. Misalnya, untuk
Penyimpanan Objek Yandex untuk membuat ember di mana cadangan cluster akan disimpan. Ke layanan
Pemantauan Yandex , yang akan mengumpulkan dan memvisualisasikan metrik basis data. Pekerja harus membuat meta-informasi kluster di sana. Untuk API DNS, jika pengguna ingin menetapkan alamat IP publik ke host cluster.
Secara umum, pekerja bekerja dengan sangat sederhana. Ia menerima tugas dari antrian metabase dan mengakses layanan yang diinginkan. Setelah menyelesaikan setiap langkah, pekerja menyimpan informasi tentang kemajuan operasi di metabase. Jika kegagalan terjadi, tugas hanya restart dan berjalan dari tempat ia tinggalkan. Tetapi bahkan memulai kembali dari awal tidak menjadi masalah, karena hampir semua jenis tugas untuk pekerja ditulis dengan idempoten. Ini karena pekerja dapat melakukan satu atau beberapa langkah operasi, tetapi tidak ada informasi tentang ini di MetaDB.
Menyebarkan Infrastruktur
Di bagian paling bawah adalah
SaltStack , sistem manajemen konfigurasi open source yang cukup umum ditulis dengan Python. Sistem ini sangat
dapat dikembangkan , dan kami menyukainya.
Komponen utama dari garam adalah master garam, yang menyimpan informasi tentang apa yang harus diterapkan dan di mana, dan garam minion, agen yang dipasang pada setiap host, berinteraksi dengan master dan dapat langsung mengaplikasikan garam dari master garam ke host. Untuk keperluan artikel ini, kami memiliki cukup pengetahuan ini, dan Anda dapat membaca lebih banyak di
dokumentasi SaltStack .
Satu master garam tidak toleran terhadap kesalahan dan tidak skala ke ribuan pelayan, beberapa master diperlukan. Berinteraksi dengan ini langsung dari pekerja itu tidak nyaman, dan kami menulis ikatan kami pada Salt, yang kami sebut kerangka Deploy.
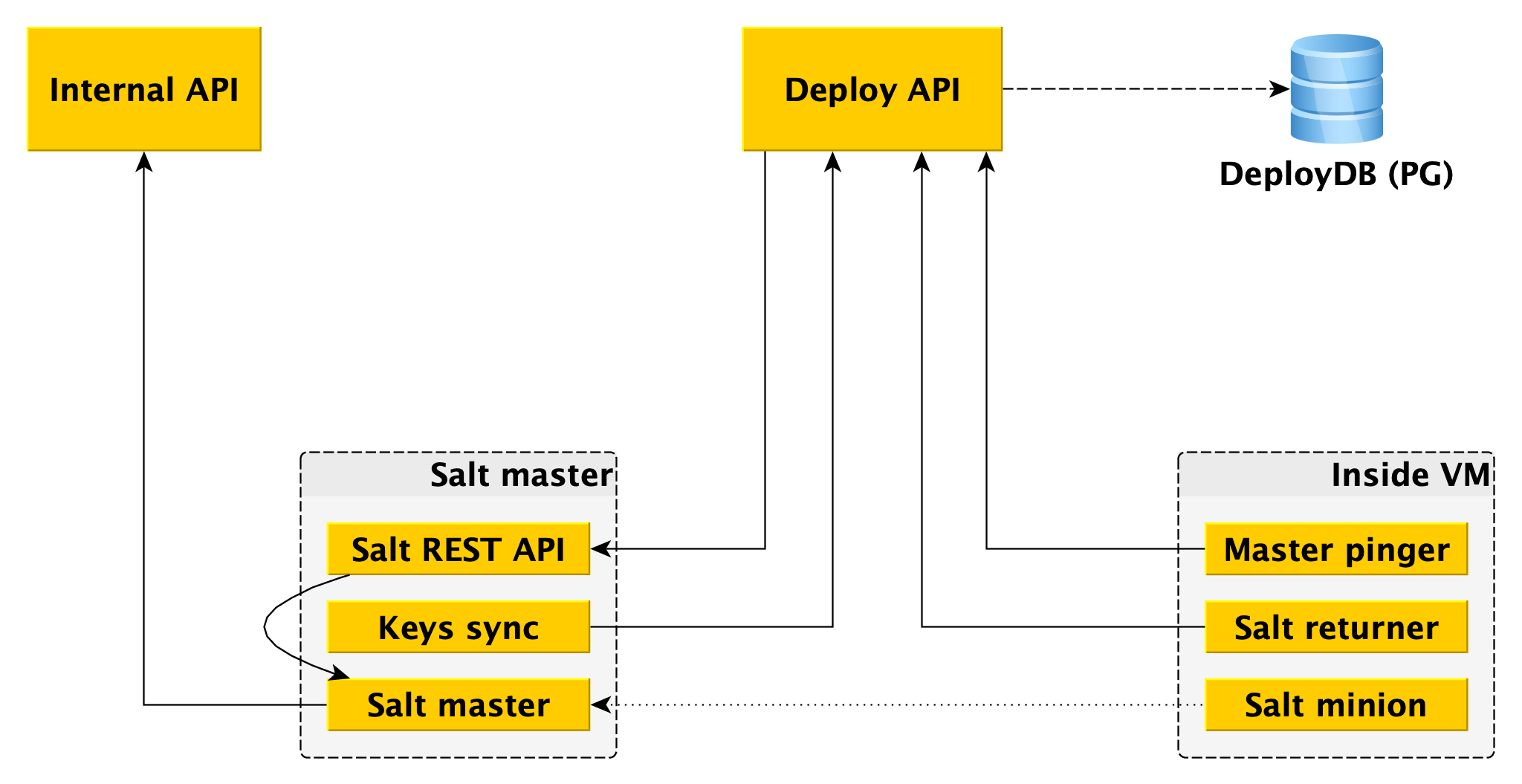
Untuk pekerja, satu-satunya titik masuk adalah Deploy API, yang mengimplementasikan metode seperti "Terapkan seluruh negara bagian atau masing-masing bagian ke antek tersebut" dan "Beri tahu status peluncuran ini dan itu". Deploy API menyimpan informasi tentang semua peluncuran dan langkah spesifiknya di DeployDB, tempat kami juga menggunakan PostgreSQL. Informasi tentang semua kaki tangan dan tuan dan tentang kepemilikan yang pertama hingga yang kedua juga disimpan di sana.
Dua komponen tambahan dipasang pada pemilik garam:
- Salt REST API , yang digunakan Deploy API untuk meluncurkan peluncuran. API REST pergi ke ahli garam lokal, dan dia sudah berkomunikasi dengan antek menggunakan ZeroMQ.
- Intinya adalah bahwa ia pergi ke Deploy API dan menerima kunci publik dari semua antek yang harus terhubung ke master garam ini. Tanpa kunci publik pada master, antek tidak bisa terhubung ke master.
Selain antek garam, dua komponen juga dipasang di Data Plane:
- Returner - sebuah modul (salah satu bagian yang dapat dikembangkan dalam garam), yang membawa hasil peluncuran tidak hanya ke ahli garam, tetapi juga di Deploy API. Deploy API memulai penyebaran dengan pergi ke REST API pada wizard, dan menerima hasilnya melalui kembali dari antek.
- Master pinger, yang secara berkala melakukan polling Deploy API yang mana master minions harus terhubung. Jika Deploy API mengembalikan alamat penyihir baru (misalnya, karena yang lama mati atau kelebihan beban), pinger mengkonfigurasi ulang antek tersebut.
Tempat lain di mana kami menggunakan ekstensibilitas SaltStack adalah
ext_pillar - kemampuan untuk mendapatkan
pilar dari suatu tempat di luar (beberapa informasi statis, misalnya, konfigurasi PostgreSQL, pengguna, basis data, ekstensi, dll.). Kami pergi ke API Internal dari modul kami untuk mendapatkan pengaturan cluster-spesifik, karena mereka disimpan dalam MetaDB.
Secara terpisah, perhatikan bahwa pilar juga mengandung informasi rahasia (kata sandi pengguna, sertifikat TLS, kunci GPG untuk mengenkripsi cadangan), dan oleh karena itu, pertama-tama, semua interaksi antara semua komponen dienkripsi (tidak ada dalam basis data kami mana pun) datang tanpa TLS, HTTPS di mana-mana, antek dan master juga mengenkripsi semua lalu lintas). Dan kedua, semua rahasia ini dienkripsi dalam MetaDB, dan kami menggunakan pemisahan rahasia - pada mesin API Internal ada kunci publik yang mengenkripsi semua rahasia sebelum disimpan di MetaDB, dan bagian pribadi dari itu terletak pada pemilik garam dan hanya mereka yang bisa mendapatkan buka rahasia untuk mentransfer sebagai pilar ke antek (sekali lagi melalui saluran terenkripsi).
Kesehatan MDB
Saat bekerja dengan basis data, penting untuk mengetahui statusnya. Untuk ini, kami memiliki layanan kesehatan MDB. Ia menerima informasi status host dari komponen internal MDB mesin virtual MDB dan menyimpannya dalam database sendiri (dalam hal ini, Redis). Dan ketika permintaan tentang status cluster tertentu tiba di API Internal, API Internal menggunakan data dari MetaDB dan MDB Health.
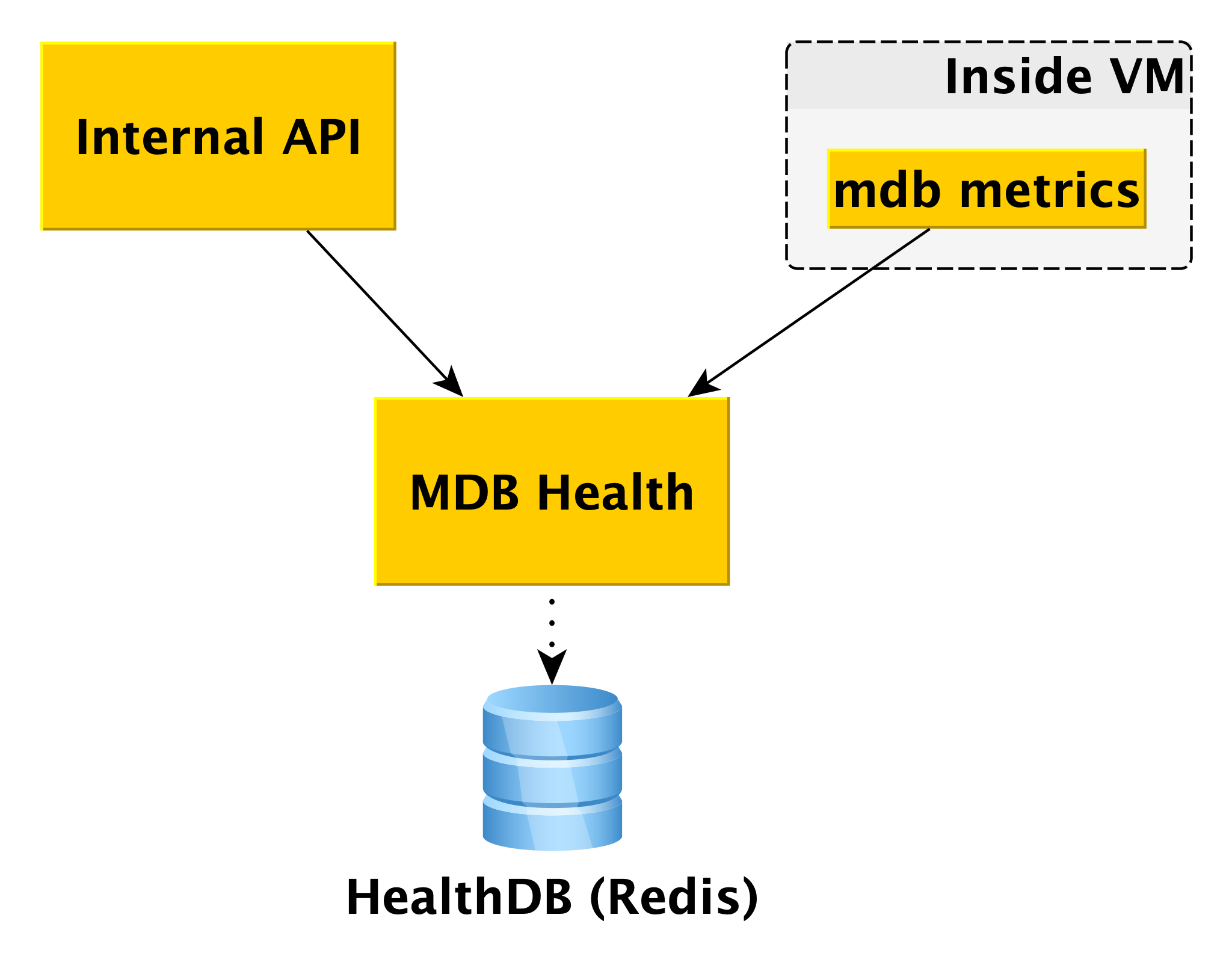
Informasi tentang semua host diproses dan disajikan dalam bentuk yang dapat dipahami dalam API. Selain keadaan host dan cluster untuk beberapa DBMS, MDB Health juga mengembalikan apakah host tertentu adalah master atau replika.
DNS MDB
Layanan mikro DNS MDB diperlukan untuk mengelola data CNAME. Jika pengandar untuk menyambungkan ke database tidak memungkinkan mentransfer beberapa host di string koneksi, Anda dapat menyambungkan ke
CNAME khusus, yang selalu menunjukkan master saat ini di cluster. Jika master beralih, CNAME berubah.
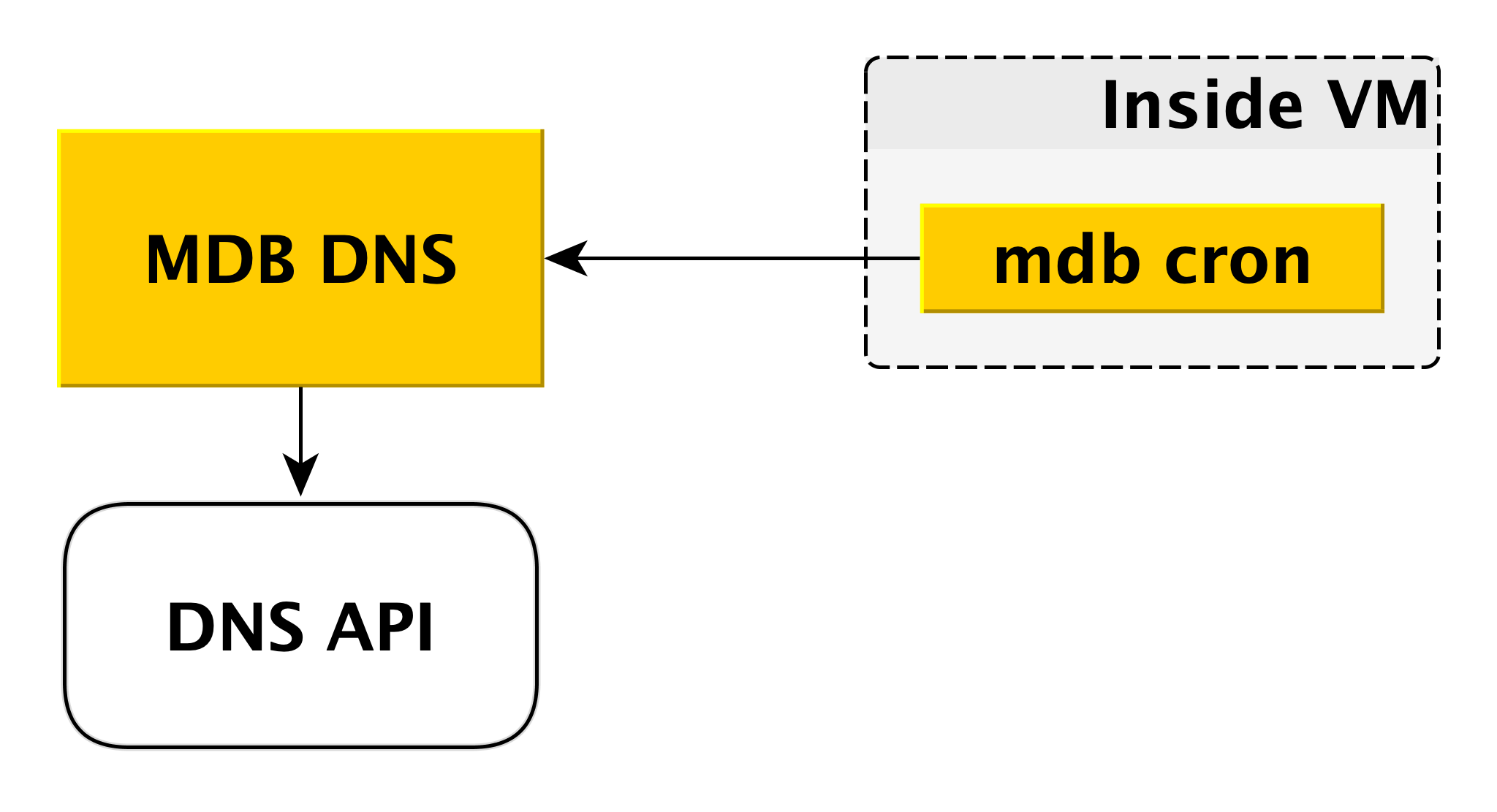
Bagaimana kabarnya? Seperti yang kami katakan di atas, di dalam mesin virtual ada cron MDB, yang secara berkala mengirimkan detak jantung dari konten berikut ke DNS MDB: "Dalam klaster ini, catatan CNAME harus menunjuk ke saya." MDB DNS menerima pesan semacam itu dari semua mesin virtual dan memutuskan apakah akan mengubah catatan CNAME. Jika perlu, itu mengubah catatan melalui API DNS.
Mengapa kami membuat layanan terpisah untuk ini? Karena DNS API hanya memiliki kontrol akses di tingkat zona. Seorang penyerang potensial, mendapatkan akses ke mesin virtual yang terpisah, dapat mengubah catatan CNAME dari pengguna lain. DNS MDB mengecualikan skenario ini karena memeriksa otorisasi.
Pengiriman dan tampilan log basis data
Ketika database pada mesin virtual menulis ke log, komponen klien push khusus membaca catatan ini dan mengirimkan baris yang baru saja muncul ke Logbroker (
mereka sudah menulis tentang itu di Habré). Interaksi klien push dengan LogBroker dibangun dengan semantik langsung: kami pasti akan mengirimkannya dan pastikan untuk sekali saja.
Kumpulan mesin yang terpisah - LogConsumers - mengambil log dari antrian LogBroker dan menyimpannya dalam database LogsDB. ClickHouse DBMS digunakan untuk database log.
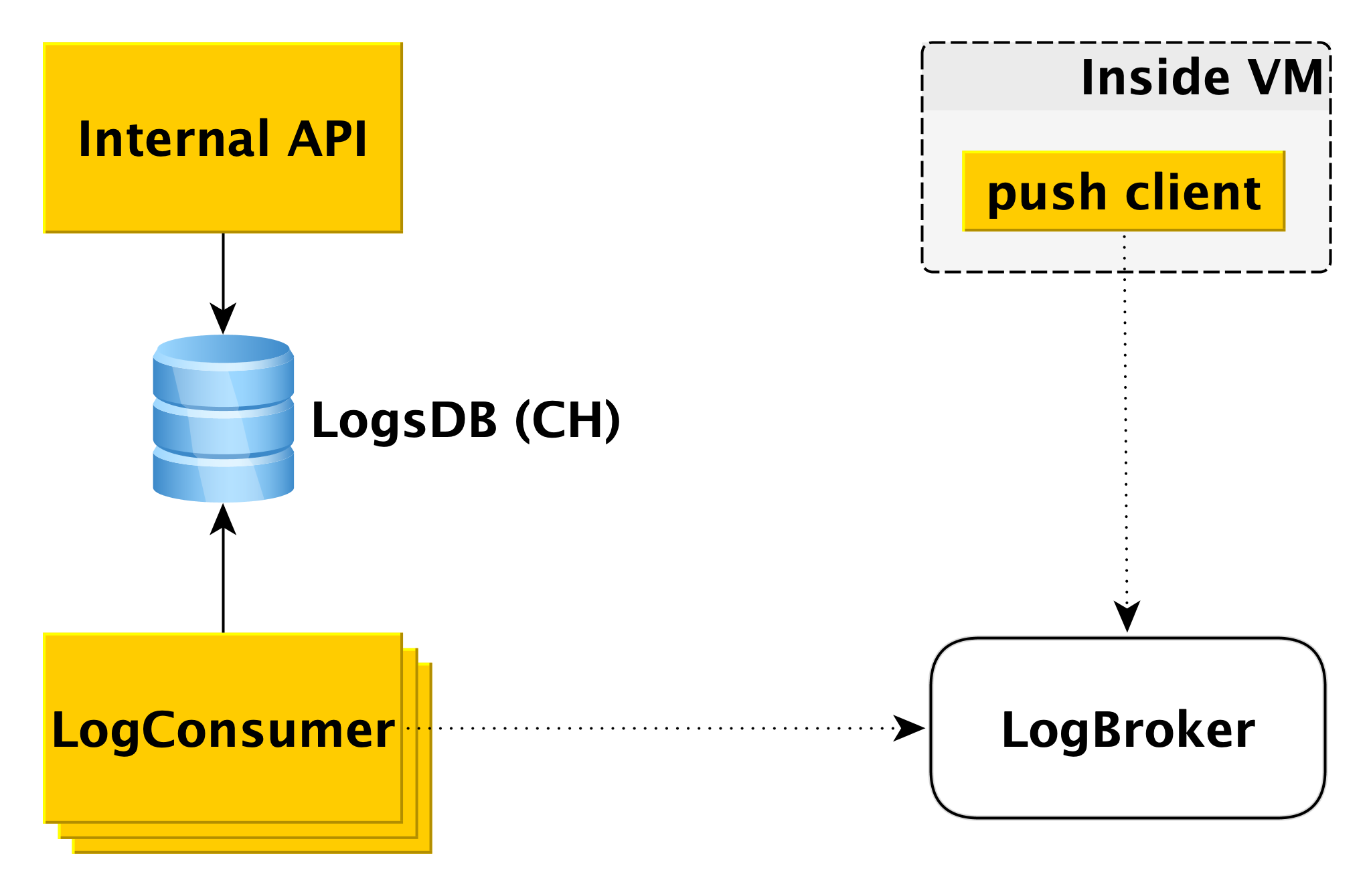
Ketika permintaan dikirim ke API Internal untuk menampilkan log untuk interval waktu tertentu untuk kluster tertentu, API Internal memeriksa otorisasi dan mengirimkan permintaan ke LogsDB. Dengan demikian, loop pengiriman log benar-benar independen dari loop tampilan log.
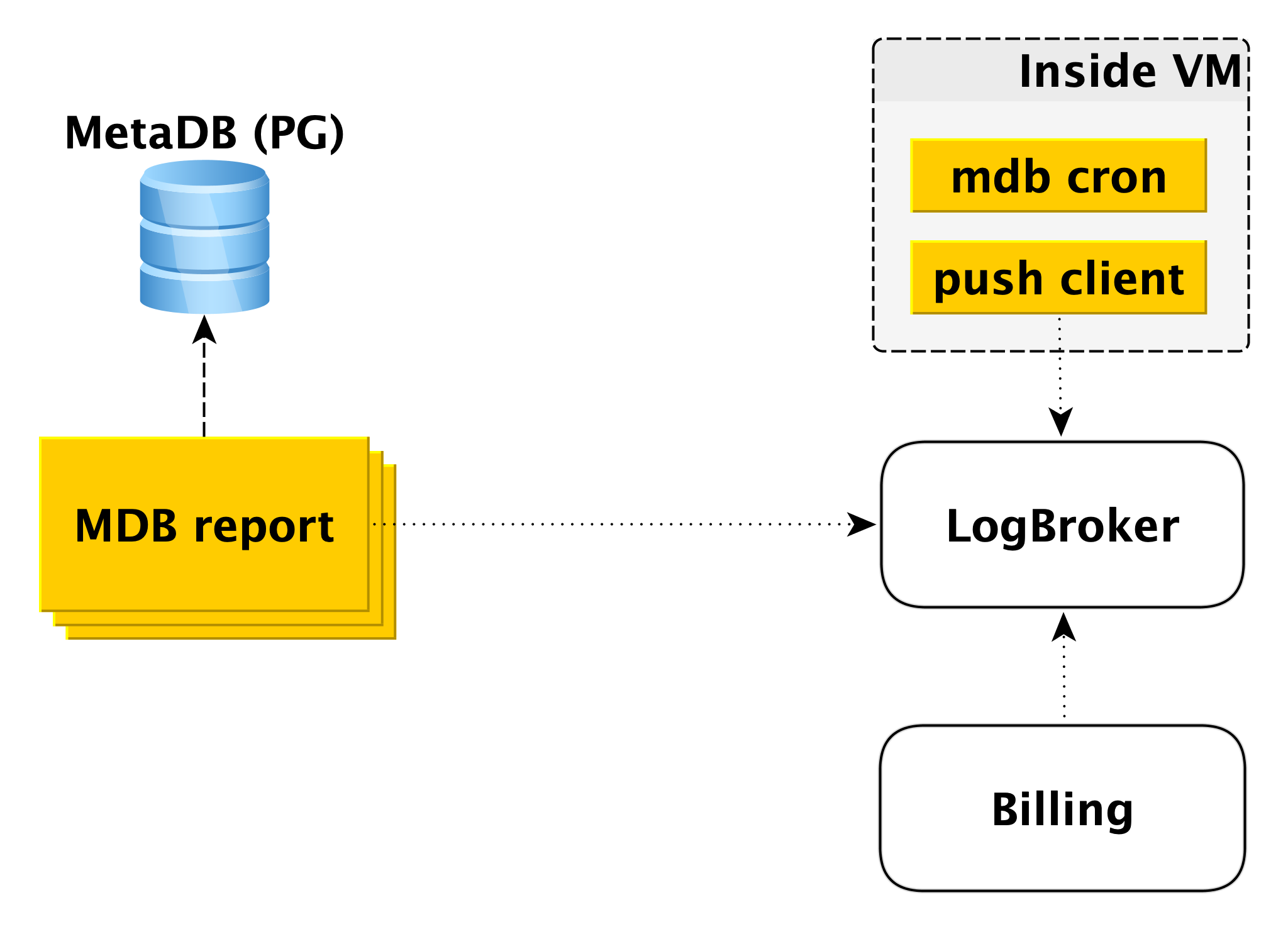
Tagihan
Skema penagihan dibuat dengan cara yang serupa. Di dalam mesin virtual, ada komponen yang memeriksa dengan periodisitas tertentu bahwa semuanya sesuai dengan database. Jika semuanya baik-baik saja, Anda dapat melakukan penagihan untuk interval waktu ini sejak saat peluncuran terakhir. Dalam hal ini, catatan dibuat di log penagihan, dan kemudian klien push mengirim catatan ke LogBroker. Data dari Logbroker ditransfer ke sistem penagihan dan perhitungan dilakukan di sana. Ini adalah skema penagihan untuk menjalankan cluster.
Jika gugus dimatikan, penggunaan sumber daya komputasi berhenti diisi, namun, ruang disk dibebankan. Dalam hal ini, penagihan dari mesin virtual tidak dimungkinkan dan sirkuit kedua terlibat - sirkuit penagihan offline. Ada kumpulan mesin yang terpisah yang menyapu daftar cluster shutdown dari MetaDB dan menulis log dalam format yang sama di Logbroker.
Penagihan offline dapat digunakan untuk penagihan dan juga termasuk cluster, tetapi kami akan menagih host, meskipun mereka berjalan, tetapi mereka tidak berfungsi. Misalnya, ketika Anda menambahkan host ke sebuah cluster, itu menyebarkan dari cadangan dan terjebak dengan replikasi. Salah menagih pengguna untuk ini, karena tuan rumah tidak aktif selama periode waktu ini.
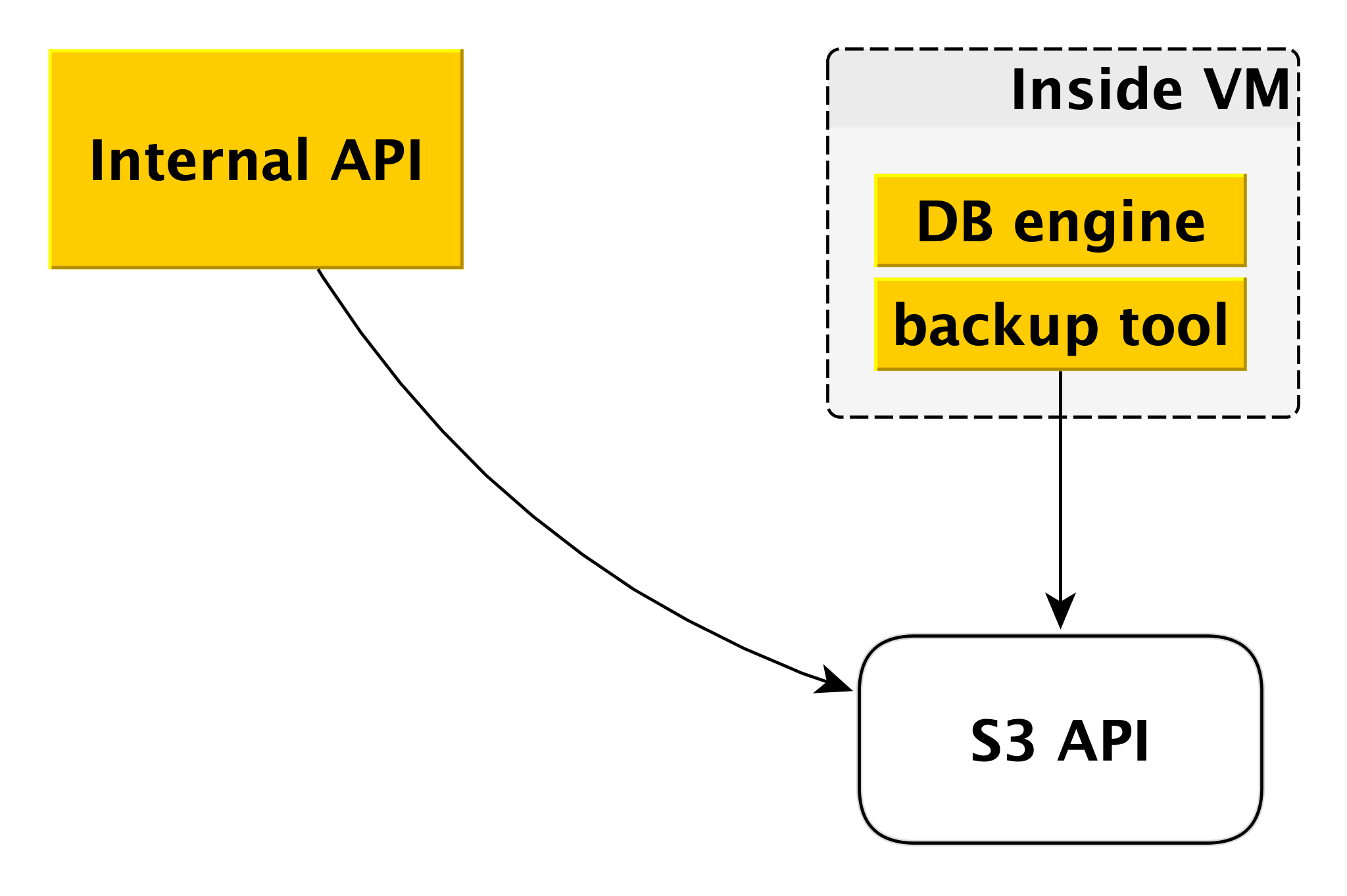
Cadangkan
Skema pencadangan mungkin sedikit berbeda untuk DBMS yang berbeda, tetapi prinsip umum selalu sama.
Setiap mesin basis data menggunakan alat cadangannya sendiri. Untuk PostgreSQL dan MySQL, ini adalah
WAL-G . Itu membuat cadangan, kompres mereka, mengenkripsi mereka dan menempatkan mereka di
Penyimpanan Objek Yandex . Pada saat yang sama, setiap cluster ditempatkan dalam ember yang terpisah (pertama, untuk isolasi, dan kedua, untuk membuatnya lebih mudah untuk menghemat ruang untuk cadangan) dan dienkripsi dengan kunci enkripsi sendiri.
Ini adalah bagaimana Control Plane dan Data Plane bekerja. Dari semua ini, layanan basis data yang dikelola Yandex.Cloud terbentuk.
Mengapa semuanya diatur dengan cara ini
Tentu saja, di tingkat global, sesuatu dapat diimplementasikan sesuai dengan skema yang lebih sederhana. Tapi kami punya alasan sendiri untuk tidak mengikuti jalan yang paling sedikit perlawanan.
Pertama-tama, kami ingin memiliki Control Plane yang sama untuk semua jenis DBMS. Tidak masalah yang mana yang Anda pilih, pada akhirnya permintaan Anda datang ke API Internal yang sama dan semua komponen di bawahnya juga umum untuk semua DBMS. Ini membuat hidup kita sedikit lebih rumit dalam hal teknologi. Di sisi lain, jauh lebih mudah untuk memperkenalkan fitur dan kemampuan baru yang memengaruhi semua DBMS. Ini dilakukan sekali, bukan enam.
Momen penting kedua bagi kami - kami ingin memastikan independensi Data Plane dari Control Plane sebanyak mungkin. Dan hari ini, bahkan jika Control Plane benar-benar tidak tersedia, semua database akan terus berfungsi. Layanan ini akan memastikan keandalan dan ketersediaannya.
Ketiga, pengembangan hampir semua layanan selalu kompromi. Dalam arti umum, secara kasar, di suatu tempat yang lebih penting adalah kecepatan rilis rilis, dan di suatu tempat keandalan tambahan. Pada saat yang sama, sekarang tidak ada yang mampu melakukan satu atau dua rilis setahun, ini jelas. Jika Anda melihat Control Plane, di sini kami fokus pada kecepatan pengembangan, pada pengenalan cepat fitur baru, meluncurkan pembaruan beberapa kali seminggu. Dan Data Plane bertanggung jawab atas keamanan database Anda, untuk toleransi kesalahan, jadi di sini adalah siklus rilis yang sangat berbeda, diukur dalam beberapa minggu. Dan fleksibilitas dalam hal pengembangan ini juga memberi kita kebebasan bersama mereka.
Contoh lain: layanan basis data yang dikelola biasanya hanya menyediakan drive jaringan kepada pengguna. Yandex.Cloud juga menawarkan drive lokal. Alasannya sederhana: kecepatan mereka jauh lebih tinggi. Dengan drive jaringan, misalnya, lebih mudah untuk menaikkan dan menurunkan mesin virtual. Lebih mudah membuat cadangan dalam bentuk snapshot penyimpanan jaringan. Tetapi banyak pengguna membutuhkan kecepatan tinggi, jadi kami membuat alat cadangan level yang lebih tinggi.
Rencana masa depan
Dan beberapa kata tentang rencana untuk meningkatkan layanan untuk jangka menengah. Ini adalah paket yang memengaruhi seluruh Yandex Managed Database secara keseluruhan, bukan DBMS individual.
Pertama-tama, kami ingin memberikan lebih banyak fleksibilitas dalam mengatur frekuensi pembuatan cadangan. Ada beberapa skenario ketika perlu bahwa pada siang hari pencadangan dilakukan sekali setiap beberapa jam, selama seminggu - sekali sehari, selama sebulan - sekali seminggu, selama tahun - sebulan sekali. Untuk melakukan ini, kami sedang mengembangkan komponen terpisah antara API Internal dan
Penyimpanan Objek Yandex .
Poin penting lainnya, penting bagi pengguna dan kami, adalah kecepatan operasi. Kami baru-baru ini membuat perubahan besar pada infrastruktur Penyebaran dan mengurangi waktu pelaksanaan hampir semua operasi menjadi beberapa detik. Tidak tercakup hanya operasi membuat cluster dan menambahkan host ke cluster. Waktu pelaksanaan operasi kedua tergantung pada jumlah data. Tetapi yang pertama kami akan mempercepat dalam waktu dekat, karena pengguna sering ingin membuat dan menghapus cluster di pipa CI / CD mereka.
Daftar kasus penting kami mencakup penambahan fungsi yang secara otomatis meningkatkan ukuran disk. Sekarang ini dilakukan secara manual, yang sangat tidak nyaman dan tidak terlalu baik.
Akhirnya, kami menawarkan kepada pengguna sejumlah besar grafik yang menunjukkan apa yang terjadi dengan basis data. Kami memberikan akses ke log. Pada saat yang sama, kami melihat bahwa data terkadang tidak mencukupi. Perlu grafis lain, irisan lain. Di sini kami juga merencanakan peningkatan.
Kisah kami tentang layanan basis data yang dikelola ternyata lama dan mungkin cukup membosankan. Lebih baik daripada kata-kata dan deskripsi, hanya latihan nyata. Karena itu, jika Anda mau, Anda dapat mengevaluasi secara independen kemampuan layanan kami: