Halo semuanya, nama saya Alexander, saya bekerja sebagai insinyur di CIAN dan saya terlibat dalam administrasi sistem dan otomatisasi proses infrastruktur. Dalam komentar ke salah satu artikel sebelumnya kami diminta untuk memberi tahu di mana kami mendapatkan 4 TB log per hari dan apa yang kami lakukan dengan mereka. Ya, kami memiliki banyak log, dan cluster infrastruktur terpisah telah dibuat untuk memprosesnya, yang memungkinkan kami untuk dengan cepat menyelesaikan masalah. Dalam artikel ini, saya akan berbicara tentang bagaimana kami mengadaptasinya sepanjang tahun untuk bekerja dengan aliran data yang terus tumbuh.
Di mana kita mulai
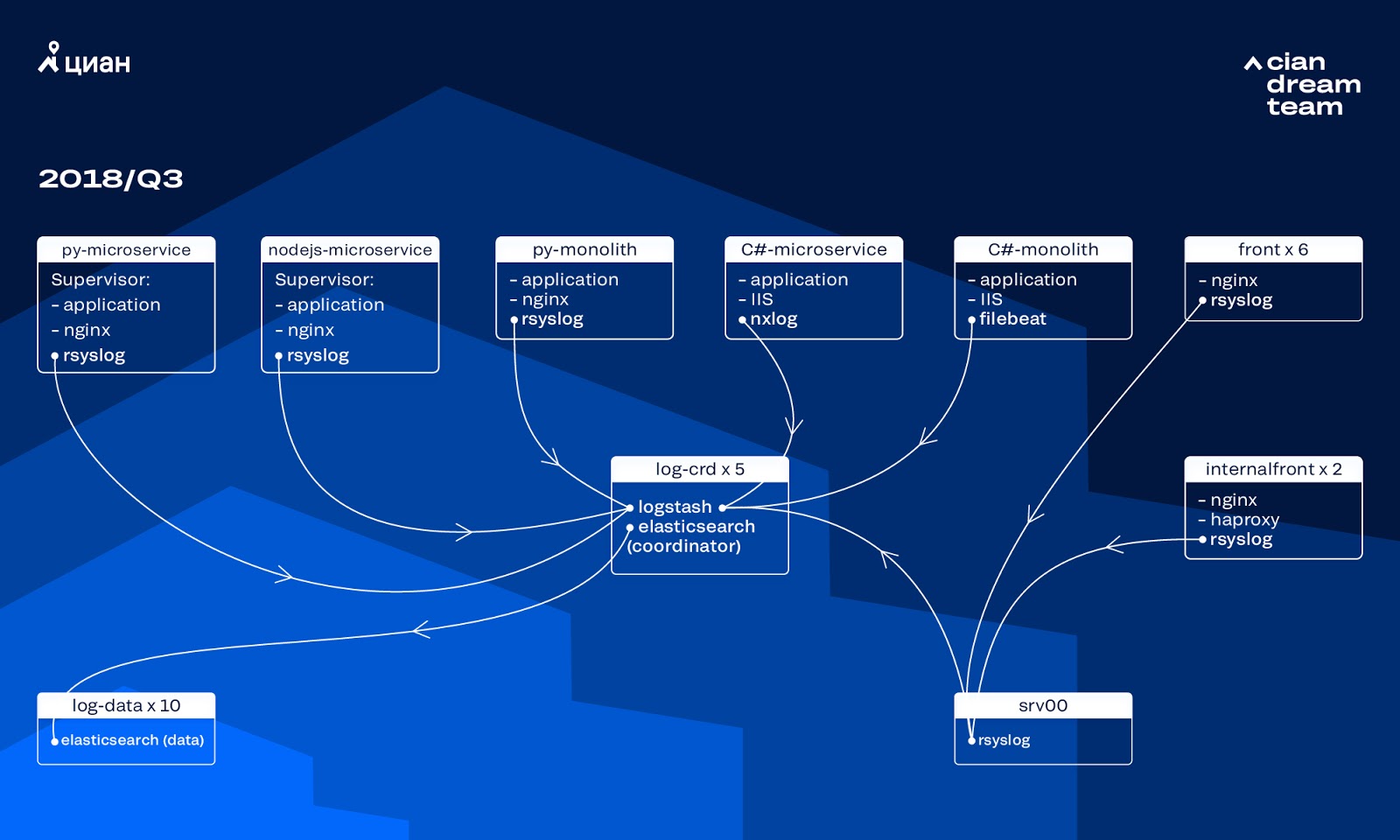
Selama beberapa tahun terakhir, beban pada cian.ru telah berkembang sangat pesat, dan pada kuartal ketiga 2018, lalu lintas sumber daya mencapai 11,2 juta pengguna unik per bulan. Pada saat itu, pada saat-saat kritis, kami kehilangan hingga 40% dari kayu bulat, karena itu kami tidak dapat dengan cepat menangani insiden dan menghabiskan banyak waktu dan upaya untuk menyelesaikannya. Kami sering tidak dapat menemukan penyebab masalah, dan kambuh setelah beberapa waktu. Itu adalah neraka yang dengannya Anda harus melakukan sesuatu.
Pada saat itu, kami menggunakan sekelompok 10 simpul data dengan ElasticSearch versi 5.5.2 dengan pengaturan indeks umum untuk menyimpan log. Ini diperkenalkan lebih dari setahun yang lalu sebagai solusi yang populer dan terjangkau: kemudian aliran log tidak begitu besar, tidak masuk akal untuk datang dengan konfigurasi non-standar.
Logstash pada port yang berbeda menyediakan pemrosesan log yang masuk pada lima koordinator ElasticSearch. Satu indeks, berapapun ukurannya, terdiri dari lima pecahan. Rotasi harian dan harian diselenggarakan, sebagai hasilnya, sekitar 100 pecahan baru muncul di cluster setiap jam. Meskipun tidak ada banyak log, cluster berhasil dan tidak ada yang memperhatikan pengaturannya.
Masalah pertumbuhan
Volume log yang dihasilkan tumbuh sangat cepat, karena dua proses saling tumpang tindih. Di satu sisi, ada lebih banyak pengguna layanan. Di sisi lain, kami mulai aktif beralih ke arsitektur microservice, menggergaji monolit lama kami menjadi C # dan Python. Beberapa lusin layanan mikro baru yang menggantikan bagian monolit menghasilkan lebih banyak log untuk cluster infrastruktur.
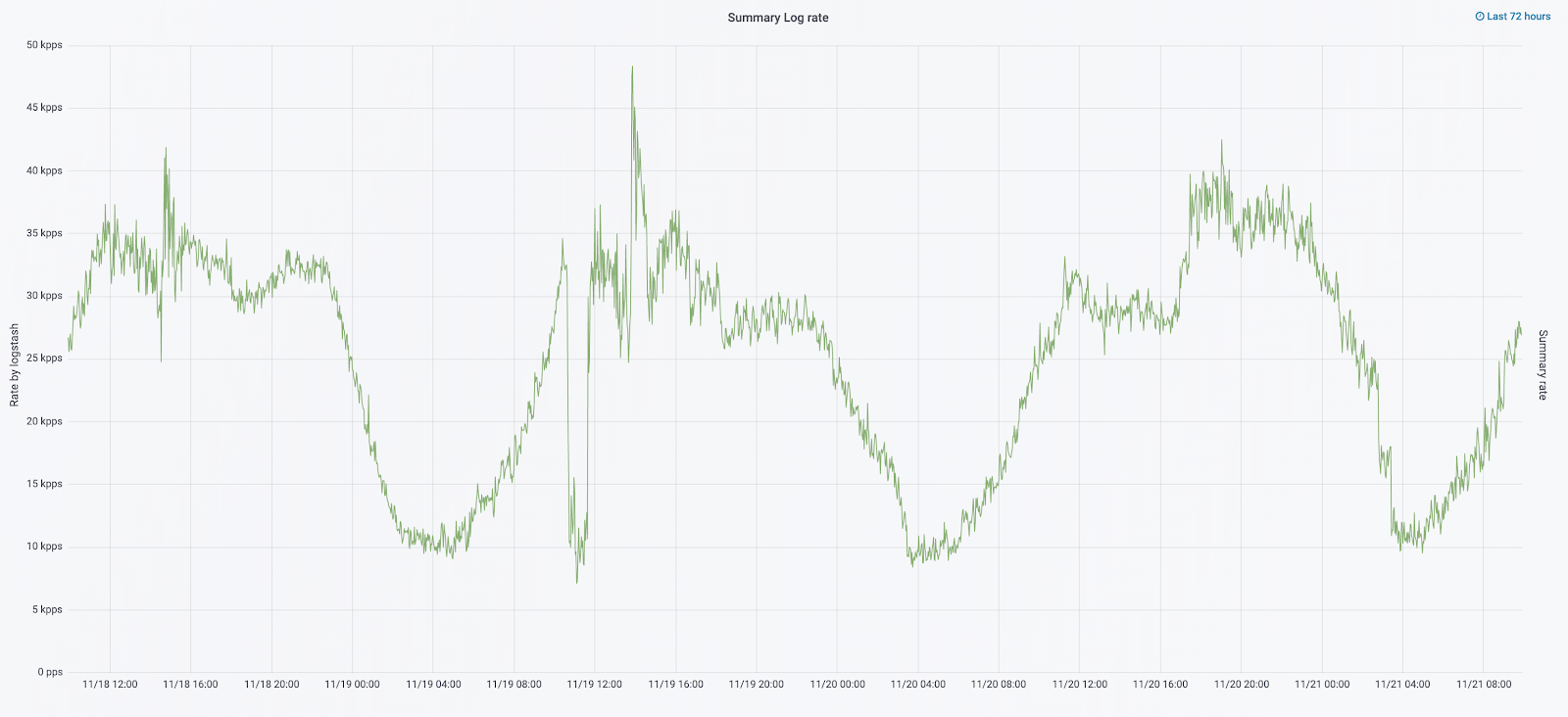
Itu scaling yang membawa kami pada fakta bahwa cluster menjadi hampir tidak terkendali. Ketika log mulai tiba dengan kecepatan 20 ribu pesan per detik, rotasi yang tidak berguna sering meningkatkan jumlah pecahan menjadi 6 ribu, dan satu simpul menyumbang lebih dari 600 pecahan.
Hal ini menyebabkan masalah dengan alokasi RAM, dan ketika sebuah node jatuh, gerakan simultan dari semua pecahan dimulai, mengalikan lalu lintas dan memuat node yang tersisa, yang membuatnya hampir mustahil untuk menulis data ke cluster. Dan selama periode ini kami dibiarkan tanpa log. Dan dengan masalah server, kami kehilangan 1/10 cluster pada prinsipnya. Sejumlah besar indeks kecil menambah kompleksitas.
Tanpa log, kami tidak memahami penyebab insiden dan cepat atau lambat dapat menginjak penggaruk yang sama lagi, tetapi dalam ideologi tim kami ini tidak dapat diterima, karena semua mekanisme kerja yang kami miliki dipertajam pada hal yang sebaliknya - tidak pernah mengulangi masalah yang sama. Untuk melakukan ini, kami membutuhkan volume penuh kayu gelondongan dan pengirimannya dalam waktu yang hampir bersamaan, karena tim insinyur tugas memantau peringatan tidak hanya dari metrik, tetapi juga dari kayu. Untuk memahami sejauh mana masalah - pada saat itu total volume kayu sekitar 2 TB per hari.
Kami menetapkan tugas - untuk sepenuhnya menghilangkan hilangnya log dan mengurangi waktu pengirimannya ke kluster ELK hingga maksimum 15 menit selama force majeure (kami mengandalkan angka ini di masa depan sebagai KPI internal).
Mekanisme rotasi baru dan simpul panas-hangat
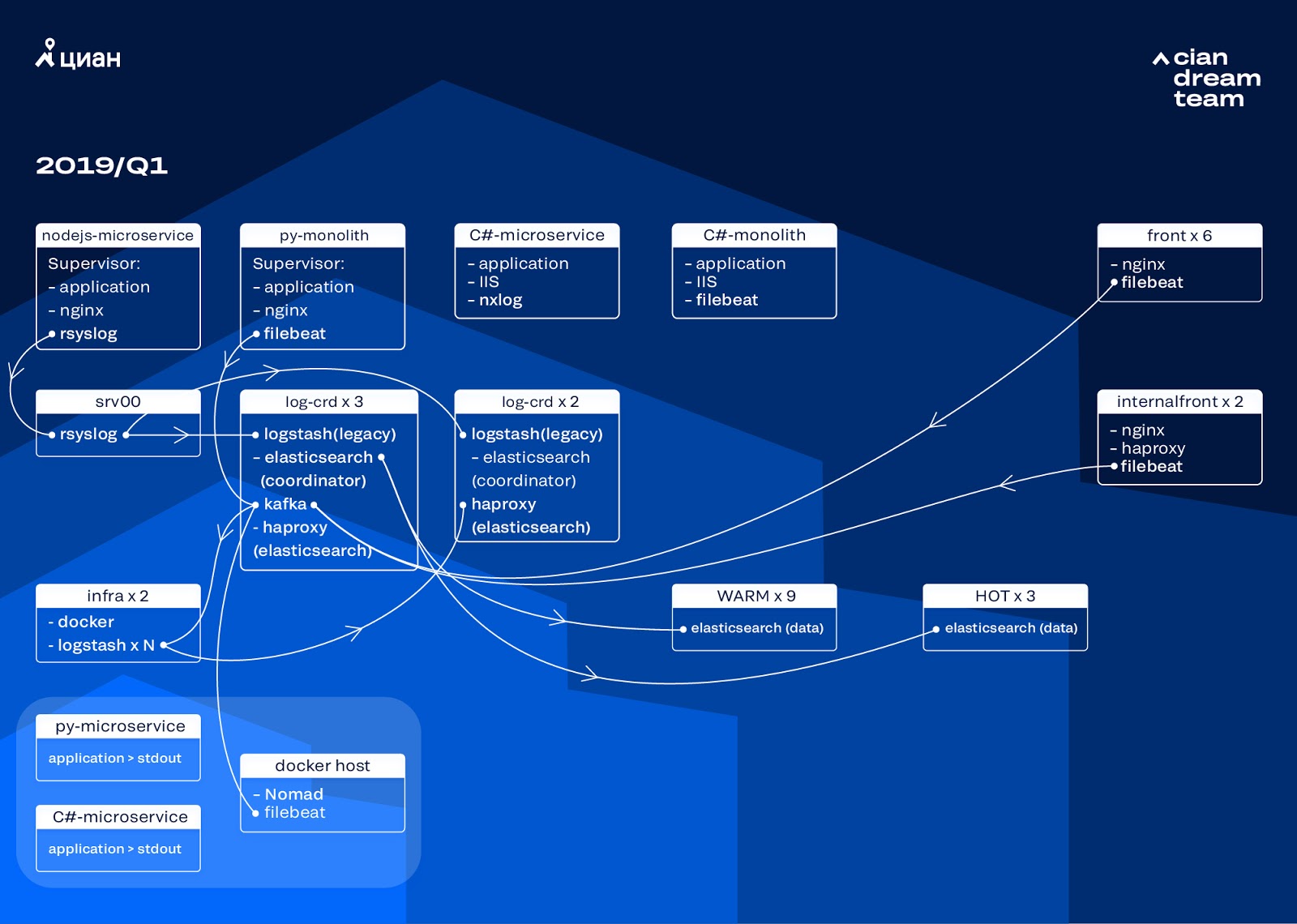
Kami memulai transformasi klaster dengan memperbarui versi ElasticSearch dari 5.5.2 ke 6.4.3. Sekali lagi, sekelompok versi 5 pergi ke kami, dan kami memutuskan untuk membayarnya dan memperbarui sepenuhnya - masih ada log. Jadi kami melakukan transisi ini hanya dalam beberapa jam.
Transformasi yang paling ambisius pada tahap ini adalah pengenalan tiga simpul dengan koordinator sebagai penyangga perantara Apache Kafka. Pialang pesan menyelamatkan kami dari kehilangan log selama masalah dengan ElasticSearch. Pada saat yang sama, kami menambahkan 2 node ke cluster dan beralih ke arsitektur panas-hangat dengan tiga node "panas" diatur dalam rak berbeda di pusat data. Kami mengarahkan log ke mereka yang tidak boleh hilang dalam hal apa pun - nginx, serta log kesalahan aplikasi. Log kecil - debug, peringatan, dll., Pergi ke node lain, dan juga, setelah 24 jam, log "penting" dipindahkan dari node "panas".
Agar tidak menambah jumlah indeks kecil, kami beralih dari rotasi waktu ke mekanisme rollover. Ada banyak informasi di forum bahwa rotasi berdasarkan ukuran indeks sangat tidak dapat diandalkan, jadi kami memutuskan untuk menggunakan rotasi dengan jumlah dokumen dalam indeks. Kami menganalisis setiap indeks dan mencatat jumlah dokumen yang setelah itu rotasi harus berfungsi. Dengan demikian, kami telah mencapai ukuran optimal dari beling - tidak lebih dari 50 GB.
Optimasi Cluster
Namun, kami tidak sepenuhnya menyingkirkan masalah. Sayangnya, indeks kecil muncul semua sama: mereka tidak mencapai volume yang ditetapkan, tidak berputar dan dihapus oleh pembersihan global indeks yang lebih tua dari tiga hari, karena kami menghapus rotasi berdasarkan tanggal. Ini menyebabkan hilangnya data karena fakta bahwa indeks dari cluster benar-benar menghilang, dan upaya untuk menulis ke indeks yang tidak ada mematahkan logika kurator yang kami gunakan untuk kontrol. Alias untuk rekaman diubah menjadi indeks dan mematahkan logika rollover, menyebabkan pertumbuhan beberapa indeks menjadi 600 GB.
Misalnya, untuk mengonfigurasi rotasi:
urator-elk-rollover.yaml --- actions: 1: action: rollover options: name: "nginx_write" conditions: max_docs: 100000000 2: action: rollover options: name: "python_error_write" conditions: max_docs: 10000000
Dengan tidak adanya alias rollover, terjadi kesalahan:
ERROR alias "nginx_write" not found. ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
Kami meninggalkan solusi untuk masalah ini untuk iterasi berikutnya dan mengambil pertanyaan lain: kami beralih untuk menarik logika Logstash, yang menangani log yang masuk (menghapus informasi yang tidak perlu dan memperkaya itu). Kami menempatkannya di buruh pelabuhan, yang kami luncurkan melalui buruh pelabuhan, dan di tempat yang sama kami menempatkan eksportir sampah, yang memberikan metrik kepada Prometheus untuk pemantauan operasional aliran log. Jadi kami memberi diri kami kesempatan untuk dengan lancar mengubah jumlah instance logstash yang bertanggung jawab untuk memproses setiap jenis log.
Sementara kami meningkatkan kluster, lalu lintas cian.ru tumbuh menjadi 12,8 juta pengguna unik per bulan. Sebagai hasilnya, ternyata konversi kami tidak mengikuti perubahan pada produksi sedikit, dan kami dihadapkan dengan fakta bahwa node "hangat" tidak dapat mengatasi beban dan memperlambat seluruh pengiriman log. Kami menerima data "panas" tanpa kegagalan, tetapi kami harus melakukan intervensi dalam pengiriman sisanya dan melakukan rollover manual untuk mendistribusikan indeks secara merata.
Pada saat yang sama, penskalaan dan mengubah pengaturan instance logstash di kluster diperumit oleh fakta bahwa itu adalah komposisi buruh pelabuhan lokal, dan semua tindakan dilakukan dengan tangan (untuk menambahkan tujuan baru, perlu untuk melewati semua server dengan tangan Anda dan melakukan pembuatan dock-up di mana-mana).
Redistribusi log
Pada bulan September tahun ini, kami masih terus melihat monolit, beban pada cluster meningkat, dan aliran log mendekati 30 ribu pesan per detik.
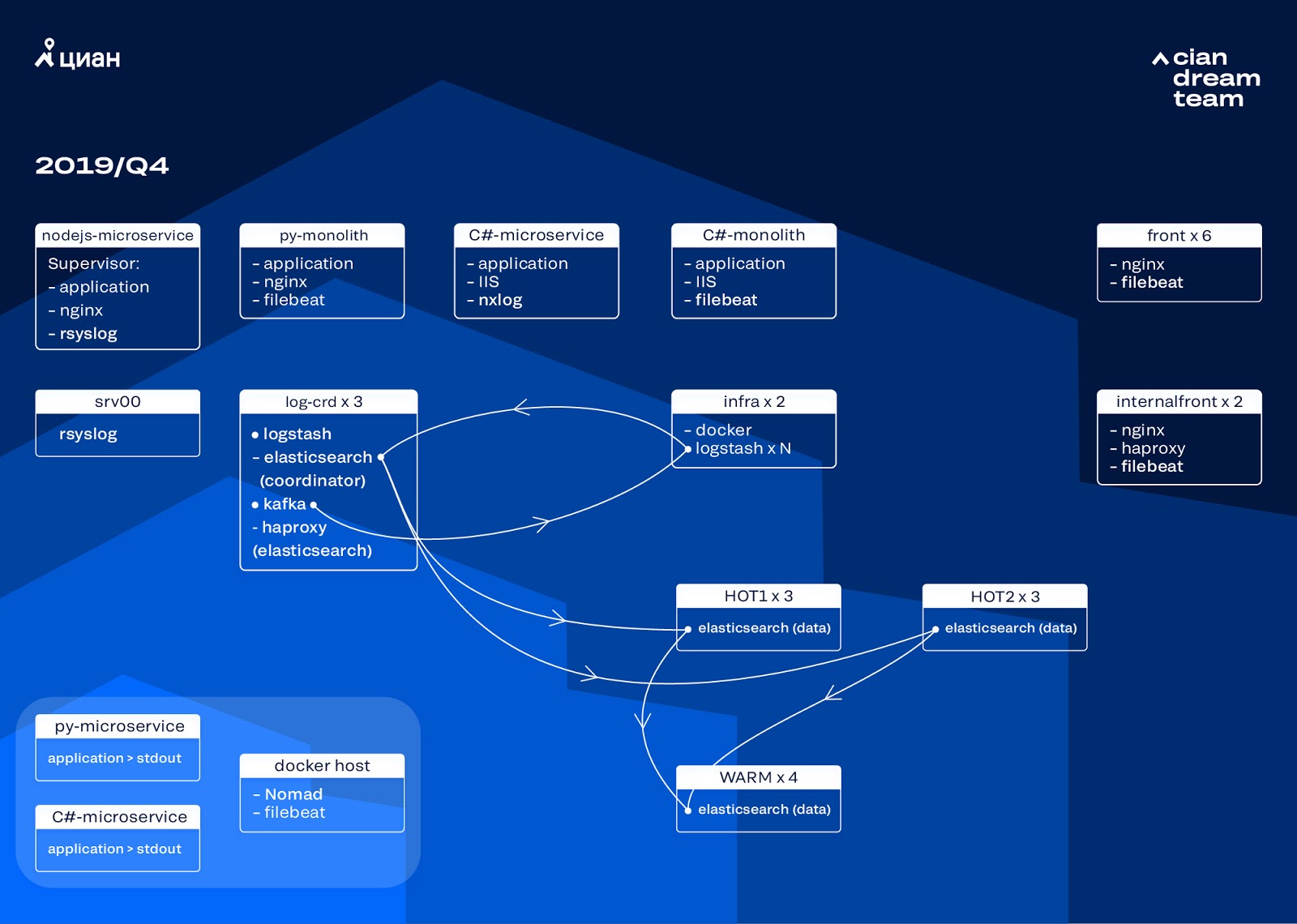
Kami memulai iterasi berikutnya dengan memperbarui setrika. Kami beralih dari lima koordinator ke tiga, mengganti node data dan memenangkan dalam hal uang dan volume penyimpanan. Untuk node, kami menggunakan dua konfigurasi:
- Untuk hot node: E3-1270 v6 / 960Gb SSD / 32 Gb x 3 x 2 (3 untuk Hot1 dan 3 untuk Hot2).
- Untuk simpul hangat: E3-1230 v6 / 4Tb SSD / 32 Gb x 4.
Pada iterasi ini, kami mengambil indeks dengan log akses layanan Microsoft, yang mengambil ruang sebanyak log nginx front-end, ke dalam kelompok kedua dari tiga node panas. Kami sekarang menyimpan data pada hot node selama 20 jam, dan kemudian mentransfernya untuk menghangatkan ke log lain.
Kami memecahkan masalah hilangnya indeks kecil dengan mengkonfigurasi ulang rotasi mereka. Indeks sekarang tetap diputar setiap 23 jam, bahkan jika hanya ada sedikit data. Ini sedikit meningkatkan jumlah pecahan (mereka menjadi sekitar 800), tetapi dari sudut pandang kinerja cluster ini dapat ditoleransi.
Akibatnya, enam node "panas" dan hanya empat "hangat" ternyata di cluster. Ini menyebabkan sedikit keterlambatan dalam permintaan dalam interval waktu yang lama, tetapi meningkatkan jumlah node di masa depan akan menyelesaikan masalah ini.
Dalam iterasi ini, masalah kurangnya penskalaan semi-otomatis juga diperbaiki. Untuk melakukan ini, kami menggunakan cluster Nomad infrastruktur - mirip dengan apa yang telah kami sebarkan untuk produksi. Sementara jumlah Logstash tidak secara otomatis berubah tergantung pada beban, tetapi kita akan sampai pada ini.
Rencana masa depan
Konfigurasi yang diimplementasikan skala dengan baik, dan sekarang kami menyimpan 13,3 TB data - semua log dalam 4 hari, yang diperlukan untuk analisis darurat peringatan. Kami mengonversi sebagian log menjadi metrik, yang kami tambahkan ke Graphite. Untuk memfasilitasi pekerjaan para insinyur, kami memiliki metrik untuk kluster infrastruktur dan skrip untuk memperbaiki masalah tipikal semi-otomatis. Setelah meningkatkan jumlah node data, yang direncanakan untuk tahun depan, kami akan beralih ke penyimpanan data dari 4 hingga 7 hari. Ini akan cukup untuk pekerjaan operasional, karena kami selalu berusaha menyelidiki insiden sesegera mungkin, dan data telemetri tersedia untuk investigasi jangka panjang.
Pada Oktober 2019, lalu lintas cian.ru naik menjadi 15,3 juta pengguna unik per bulan. Ini adalah ujian serius solusi arsitektur untuk pengiriman kayu bulat.
Sekarang kami sedang bersiap untuk meningkatkan ElasticSearch ke versi 7. Namun, untuk ini kami harus memperbarui pemetaan banyak indeks di ElasticSearch, karena mereka pindah dari versi 5.5 dan dinyatakan usang di versi 6 (di versi 7 mereka tidak ada). Dan ini berarti bahwa dalam proses pembaruan pasti akan ada force majeure yang akan meninggalkan kita tanpa log untuk sementara waktu. Dari 7 versi, kami paling menantikan Kibana dengan antarmuka yang ditingkatkan dan filter baru.
Kami mencapai tujuan utama: kami berhenti kehilangan kayu dan mengurangi waktu henti cluster infrastruktur dari 2-3 tetes per minggu menjadi beberapa jam kerja layanan per bulan. Semua pekerjaan produksi hampir tidak terlihat. Namun, sekarang kami dapat secara akurat menentukan apa yang terjadi dengan layanan kami, kami dapat dengan cepat melakukannya dalam mode tenang dan tidak khawatir bahwa log akan hilang. Secara umum, kami puas, bahagia dan sedang bersiap untuk eksploitasi baru, yang akan kita bicarakan nanti.