Sejak publikasi terakhir di dunia bahasa Julia, banyak hal menarik terjadi:
Pada saat yang sama, ada peningkatan minat yang nyata dari pengembang, yang dinyatakan dengan pembandingan yang melimpah:
Kami hanya bersukacita pada alat baru dan nyaman dan terus mempelajarinya. Malam ini akan dikhususkan untuk analisis teks, pencarian makna tersembunyi dalam pidato presiden dan generasi teks dalam semangat Shakespeare dan seorang programmer Julia, dan untuk hidangan penutup, kami memberi makan jaringan rekursif 40.000 pai.
Baru-baru ini di sini di Habré ulasan paket untuk Julia dilakukan memungkinkan untuk melakukan penelitian di bidang NLP - Julia NLP. Kami memproses teks . Jadi mari kita langsung ke bisnis dan mulai dengan paket TextAnalysis .
TeksAnalisys
Biarkan beberapa teks diberikan, yang kami wakili sebagai dokumen string:
using TextAnalysis str = """ Ich mag die Sonne, die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher. Ich mag den kalten Mond, wenn der Vollmond rund, Und ich mag dich mit einem Knebel in dem Mund. """; sd = StringDocument(str)
StringDocument{String}("Ich mag die ... dem Mund.\n", TextAnalysis.DocumentMetadata(Languages.Default(), "Untitled Document", "Unknown Author", "Unknown Time"))
Untuk pekerjaan mudah dengan sejumlah besar dokumen, dimungkinkan untuk mengubah bidang, misalnya, judul, dan juga, untuk menyederhanakan pemrosesan, kami dapat menghapus tanda baca dan huruf kapital:
title!(sd, "Knebel") prepare!(sd, strip_punctuation) remove_case!(sd) text(sd)
"ich mag die sonne die palmen und das meer \nich mag den himmel schauen den wolken hinterher \nich mag den kalten mond wenn der vollmond rund \nund ich mag dich mit einem knebel in dem mund \n"
yang memungkinkan Anda membuat n-gram yang tidak berantakan untuk kata-kata:
dict1 = ngrams(sd) Dict{String,Int64} with 26 entries: "dem" => 1 "himmel" => 1 "knebel" => 1 "der" => 1 "schauen" => 1 "mund" => 1 "rund" => 1 "in" => 1 "mond" => 1 "dich" => 1 "einem" => 1 "ich" => 4 "hinterher" => 1 "wolken" => 1 "den" => 3 "das" => 1 "palmen" => 1 "kalten" => 1 "mag" => 4 "sonne" => 1 "vollmond" => 1 "die" => 2 "mit" => 1 "meer" => 1 "wenn" => 1 "und" => 2
Jelas bahwa tanda baca dan kata-kata dengan huruf kapital akan menjadi unit terpisah dalam kamus, yang akan mengganggu penilaian kualitatif tentang frekuensi kemunculan istilah-istilah tertentu dari teks kami, oleh karena itu kami menyingkirkannya. Untuk n-gram, mudah untuk menemukan banyak aplikasi menarik, misalnya, mereka dapat digunakan untuk mengaburkan pencarian dalam teks , tetapi karena kita hanya turis, kita akan bertahan dengan contoh mainan, yaitu generasi teks menggunakan rantai Markov
Procházení modelového grafu
Rantai Markov adalah model diskrit dari proses Markov yang terdiri dari perubahan sistem yang hanya memperhitungkan kondisi sebelumnya (model). Secara kiasan, seseorang dapat menganggap konstruksi ini sebagai otomat seluler yang probabilistik. N-gram cukup hidup berdampingan dengan konsep ini: setiap kata dari leksikon dikaitkan dengan setiap koneksi lain dengan ketebalan berbeda, yang ditentukan oleh frekuensi kemunculan pasangan kata (gram) tertentu dalam teks.

Rantai Markov untuk string "ABABD"
Implementasi dari algoritma itu sendiri sudah merupakan kegiatan yang hebat untuk malam itu, tetapi Julia sudah memiliki paket Markovify yang luar biasa , yang dibuat hanya untuk keperluan ini. Dengan hati-hati menelusuri manual dalam bahasa Ceko , kami melanjutkan ke eksekusi bahasa kami.
Memecah teks menjadi token (mis. Kata-kata)
using Markovify, Markovify.Tokenizer tokens = tokenize(str, on = words) 2-element Array{Array{String,1},1}: ["Ich", "mag", "die", "Sonne,", "die", "Palmen", "und", "das", "Meer,", "Ich", "mag", "den", "Himmel", "schauen,", "den", "Wolken", "hinterher."] ["Ich", "mag", "den", "kalten", "Mond,", "wenn", "der", "Vollmond", "rund,", "Und", "ich", "mag", "dich", "mit", "einem", "Knebel", "in", "dem", "Mund."]
Kami membuat model orde pertama (hanya tetangga terdekat yang diperhitungkan):
mdl = Model(tokens; order=1) Model{String}(1, Dict(["dich"] => Dict("mit" => 1),["den"] => Dict("Himmel" => 1,"kalten" => 1,"Wolken" => 1),["in"] => Dict("dem" => 1),["Palmen"] => Dict("und" => 1),["wenn"] => Dict("der" => 1),["rund,"] => Dict("Und" => 1),[:begin] => Dict("Ich" => 2),["Vollmond"] => Dict("rund," => 1),["die"] => Dict("Sonne," => 1,"Palmen" => 1),["kalten"] => Dict("Mond," => 1)…))
Kemudian kami melanjutkan untuk mengimplementasikan fungsi frase pembangkit berdasarkan model yang disediakan. Faktanya, dibutuhkan model, solusi, dan jumlah frasa yang ingin Anda dapatkan:
Kode function gensentences(model, fun, n) sentences = []
Pengembang paket menyediakan dua fungsi bypass: walk and walk2 (yang kedua bekerja lebih lama, tetapi memberikan desain yang lebih unik), dan Anda selalu dapat menentukan pilihan Anda. Mari kita coba:
gensentences(mdl, walk, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher." "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund." gensentences(mdl, walk2, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag dich mit einem Knebel in dem Mund." "Ich mag den Himmel schauen, den kalten Mond, wenn der Vollmond rund, Und ich mag den Wolken hinterher." "Ich mag die Sonne, die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund."
Tentu saja, godaan itu bagus untuk dicoba pada teks-teks Rusia, terutama pada ayat-ayat putih. Untuk bahasa Rusia, karena kerumitannya, sebagian besar frasa tidak dapat dibaca. Plus, seperti yang telah disebutkan , karakter khusus memerlukan perhatian khusus, oleh karena itu kami menyimpan dokumen dari mana teks yang dikodekan dalam UTF-8 dikumpulkan, atau kami menggunakan alat tambahan .
Atas saran saudara perempuannya, setelah membersihkan beberapa buku Oster dari karakter khusus dan pemisah apa pun dan menetapkan urutan kedua untuk n-gram, saya mendapatkan seperangkat unit frasa berikut:
", !" ". , : !" ", , , , ?" " !" ". , !" ". , ?" " , !" " ?" " , , ?" " ?" ", . ?"
Dia meyakinkan bahwa itu dengan teknik sedemikian rupa sehingga pikiran dibangun di otak perempuan ... ahem, dan siapa aku untuk berdebat ...
Analisis itu
Dalam direktori paket TextAnalysis Anda dapat menemukan contoh-contoh data tekstual, salah satunya adalah kumpulan pidato oleh presiden Amerika sebelum Kongres

Kode using TextAnalysis, Clustering, Plots
29-element Array{String,1}: "Bush_1989.txt" "Bush_1990.txt" "Bush_1991.txt" "Bush_1992.txt" "Bush_2001.txt" "Bush_2002.txt" "Bush_2003.txt" "Bush_2004.txt" "Bush_2005.txt" "Bush_2006.txt" "Bush_2007.txt" "Bush_2008.txt" "Clinton_1993.txt" ⋮ "Clinton_1998.txt" "Clinton_1999.txt" "Clinton_2000.txt" "Obama_2009.txt" "Obama_2010.txt" "Obama_2011.txt" "Obama_2012.txt" "Obama_2013.txt" "Obama_2014.txt" "Obama_2015.txt" "Obama_2016.txt" "Trump_2017.txt"
Setelah membaca file-file ini dan membentuk korps darinya, serta membersihkannya dari tanda baca, kami akan meninjau kosakata umum semua pidato:
Kode crps = DirectoryCorpus(pth) standardize!(crps, StringDocument) crps = Corpus(crps[1:29]);
remove_case!(crps) prepare!(crps, strip_punctuation) update_lexicon!(crps) update_inverse_index!(crps) lexicon(crps)
Dict{String,Int64} with 9078 entries: "enriching" => 1 "ferret" => 1 "offend" => 1 "enjoy" => 4 "limousines" => 1 "shouldn" => 21 "fight" => 85 "everywhere" => 17 "vigilance" => 4 "helping" => 62 "whose" => 22 "'" => 725 "manufacture" => 3 "sleepless" => 2 "favor" => 6 "incoherent" => 1 "parenting" => 2 "wrongful" => 1 "poised" => 3 "henry" => 3 "borders" => 30 "worship" => 3 "star" => 10 "strand" => 1 "rejoin" => 3 ⋮ => ⋮
Mungkin menarik untuk melihat dokumen mana yang berisi kata-kata tertentu, misalnya, lihat bagaimana kita menangani janji:
crps["promise"]' 1×24 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 1 2 3 4 6 7 9 10 11 12 15 … 21 22 23 24 25 26 27 28 29 crps["reached"]' 1×7 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 12 14 15 17 19 20 22
atau dengan frekuensi ganti:
lexical_frequency(crps, "i"), lexical_frequency(crps, "you") (0.010942182388035081, 0.005905479339070189)
Jadi mungkin ilmuwan dan jurnalis pemerkosaan dan ada sikap menyimpang terhadap data yang dipelajari.
Matriks
Semantik distribusi sesungguhnya dimulai ketika teks, gram, dan token berubah menjadi vektor dan matriks .
Matriks dokumen istilah ( DTM ) adalah matriks yang memiliki ukuran dimana - jumlah dokumen dalam kasus ini, dan - ukuran kamus corpus yaitu jumlah kata (unik) yang ditemukan di korpus kami. Pada baris ke-1, kolom ke-10 dari matriks adalah angka - berapa kali dalam teks ke-1 kata ke- j ditemukan.
Kode dtm1 = DocumentTermMatrix(crps)
D = dtm(dtm1, :dense) 29×9078 Array{Int64,2}: 0 0 1 4 0 0 0 0 0 0 0 0 0 … 1 0 0 16 0 0 0 0 0 0 0 1 4 0 0 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 3 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 5 8 0 0 0 0 0 0 0 0 0 0 0 0 10 38 0 0 0 0 0 3 0 0 0 0 0 0 0 0 5 0 … 0 0 0 22 0 0 0 0 0 0 0 12 4 2 0 0 0 0 0 1 3 0 0 0 0 41 0 0 0 0 0 0 0 1 1 2 1 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 44 0 0 0 0 0 0 0 2 1 1 0 0 0 0 0 0 2 0 0 0 67 0 0 14 1 1 31 2 0 8 2 1 1 0 0 0 0 0 4 0 … 0 0 0 50 0 0 0 0 0 2 0 3 3 0 2 0 0 0 0 0 2 1 0 0 0 11 0 0 0 0 0 0 0 8 3 6 3 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 1 11 5 3 3 0 0 0 1 0 1 0 1 0 0 44 0 0 0 0 0 0 0 11 5 4 5 0 0 0 0 0 1 0 1 0 0 48 0 0 0 0 0 0 0 18 6 8 4 0 0 0 0 0 0 1 1 0 0 80 0 0 0 0 0 0 0 1 2 0 0 0 0 0 0 0 0 0 … 0 0 0 26 0 0 0 0 0 1 0 4 5 5 1 0 0 0 0 0 1 0 0 0 45 0 0 0 0 0 1 1 0 8 2 1 3 0 0 0 0 0 2 0 0 0 47 0 0 170 11 11 1 0 0 7 1 1 1 0 0 0 0 0 0 0 0 0 3 2 0 208 2 2 0 1 0 5 2 0 1 1 0 0 0 0 1 0 0 0 41 0 0 122 7 7 1 0 0 4 3 4 1 0 0 0 0 0 0 0 … 0 0 62 0 0 173 11 11 7 2 0 6 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 3 0 3 0 0 0 0 0 0 0 0 0 0 0 35 0 0 0 0 0 1 0 2 2 0 2 0 0 0 0 0 1 0 0 0 0 30 0 0 0 0 0
Di sini unit asli adalah persyaratan
m.terms[3450:3465] 16-element Array{String,1}: "franklin" "frankly" "frankness" "fraud" "frayed" "fraying" "fre" "freak" "freddie" "free" "freed" "freedom" "freedoms" "freely" "freer" "frees"
Tunggu sebentar ...
crps["freak"] 1-element Array{Int64,1}: 25 files[25] "Obama_2013.txt"
Penting untuk membaca lebih detail ...
Anda juga dapat mengekstrak semua jenis data menarik dari matriks istilah. Ucapkan frekuensi kemunculan kata-kata tertentu dalam dokumen
w1, w2 = dtm1.column_indices["freedom"], dtm1.column_indices["terror"] (3452, 8101)
D[:, w1] |> bar
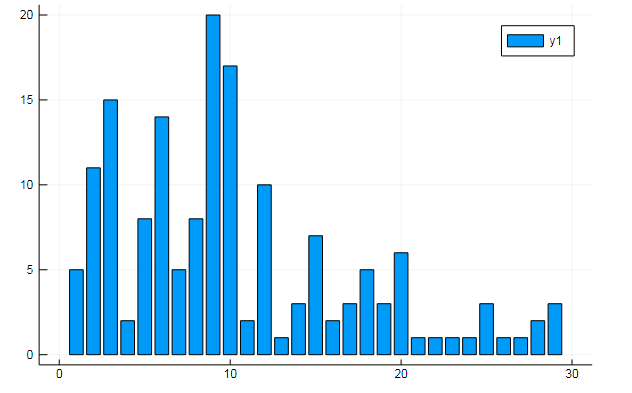
D[:, w1] |> bar
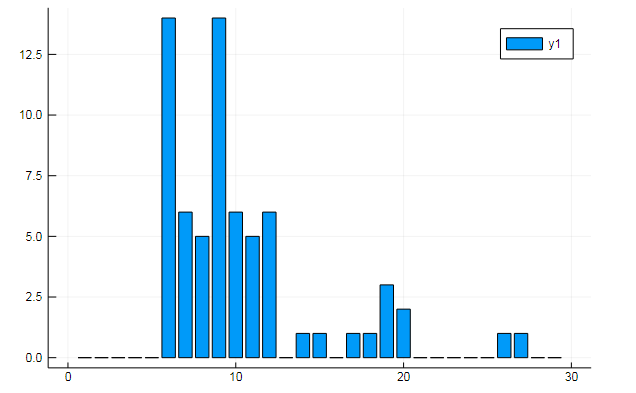
atau kesamaan dokumen pada beberapa topik tersembunyi:
k = 3

Grafik menunjukkan bagaimana masing-masing dari tiga topik diungkapkan dalam pidato
atau mengelompokkan kata berdasarkan topik, atau, misalnya, kesamaan kosakata dan preferensi topik tertentu dalam dokumen yang berbeda
T = tf_idf(D) cl = kmeans(T, 5)
s1 = scatter(T[10, 1:10:end], assign, yaxis = "Bush 2006") s2 = scatter(T[29, 1:10:end], assign, yaxis = "Obama 2016") s3 = scatter(T[30, 1:10:end], assign, yaxis = "Trump 2017") plot(s1, s2, s3, layout = (3,1), legend=false )
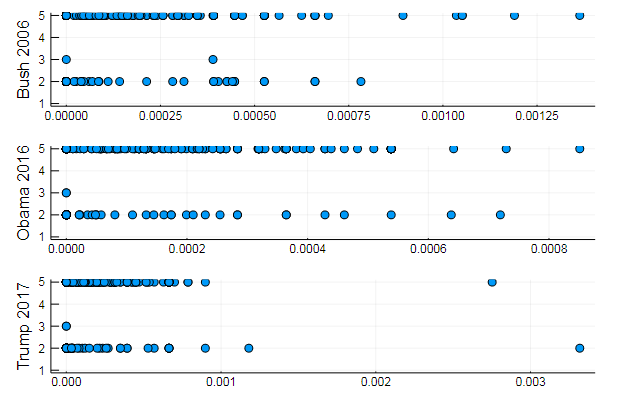
Hasil yang cukup alami, penampilan dari jenis yang sama. Sebenarnya, NLP adalah ilmu yang cukup menarik, dan Anda dapat mengekstraksi banyak informasi berguna dari data yang disiapkan dengan benar: Anda dapat menemukan banyak contoh tentang sumber ini ( Pengakuan penulis dalam komentar , penggunaan LDA , dll.)
Nah, agar tidak melangkah terlalu jauh, kami akan menghasilkan frase untuk presiden yang ideal:
Kode function loadfiles(filenames) return ( open(filename) do file text = read(file, String)
7-element Array{Any,1}: "I want harmony and fathers, sons and we mark the jobkilling TransPacific Partnership." "I am asking all across our partners must be one very happy, indeed." "At the health insurance and terrorismrelated offenses since my Inauguration, and the future and pay their jobs, their community." "Millions lifted from this Nation, and Jessica Davis." "It will expand choice, increase access, lower the Director of our aspirations, not working." "We will defend our freedom." "The challenges we will celebrate the audience tonight, has come for a record."
Memori jangka pendek
Nah, bagaimana bisa tanpa jaringan saraf! Mereka mengumpulkan kemenangan di bidang ini dengan kecepatan yang meningkat, dan lingkungan bahasa Julia berkontribusi dalam hal ini dalam segala hal. Bagi yang penasaran, Anda dapat menyarankan paket Knet , yang, tidak seperti Flux yang kami kaji sebelumnya , tidak bekerja dengan arsitektur jaringan saraf sebagai konstruktor dari modul, tetapi sebagian besar bekerja dengan iterator dan aliran. Ini bisa menjadi minat akademis dan berkontribusi pada pemahaman yang lebih dalam tentang proses pembelajaran, dan juga memberikan komputasi kinerja tinggi. Dengan mengklik tautan yang disediakan di atas, Anda akan menemukan panduan, contoh, dan bahan untuk belajar sendiri (misalnya, itu menunjukkan cara membuat generator teks Shakespeare atau kode juliac pada jaringan berulang). Namun, beberapa fungsi dari paket Knet hanya diimplementasikan untuk GPU, jadi untuk sekarang, mari kita terus menjalankan Flux.
Salah satu contoh khas dari pengoperasian jaringan perulangan sering kali adalah model yang diberi makan soneta Shakespeare secara simbolis:
QUEN: Chiet? The buswievest by his seld me not report. Good eurronish too in me will lide upon the name; Nor pain eat, comes, like my nature is night. GRUMIO: What for the Patrople: While Antony ere the madable sut killing! I think, bull call. I have what is that from the mock of France: Then, let me? CAMILLE: Who! we break be what you known, shade well? PRINCE HOTHEM: If I kiss my go reas, if he will leave; which my king myself. BENEDICH: The aunest hathing rouman can as? Come, my arms and haste. This weal the humens? Come sifen, shall as some best smine? You would hain to all make on, That that herself: whom will you come, lords and lafe to overwark the could king to me, My shall it foul thou art not from her. A time he must seep ablies in the genely sunsition. BEATIAR: When hitherdin: so like it be vannen-brother; straight Edwolk, Wholimus'd you ainly. DUVERT: And do, still ene holy break the what, govy. Servant: I fearesed, Anto joy? Is it do this sweet lord Caesar: The dece
Jika Anda menyipitkan mata dan tidak tahu bahasa Inggris, maka permainan itu tampaknya cukup nyata .

Lebih mudah dipahami dalam bahasa Rusia
Tetapi jauh lebih menarik untuk mencoba yang hebat dan kuat, dan meskipun sangat sulit secara leksikal, Anda dapat menggunakan literatur yang lebih primitif sebagai data, yaitu, yang lebih baru-baru ini dikenal sebagai arus modern puisi modern - sajak-pian.
Pengumpulan data
Pai dan bubuk - quatrains berirama, sering tanpa sajak, diketik dalam huruf kecil dan tanpa tanda baca.
Pilihan jatuh di situs poetory.ru di mana admin kawan hior . Kurangnya respons terhadap permintaan data adalah alasan untuk mulai mempelajari penguraian situs. Sekilas tentang tutorial HTML memberi Anda pemahaman mendasar tentang desain halaman web. Berikutnya, kami menemukan cara bahasa Julia untuk bekerja di bidang-bidang tersebut:
- HTTP.jl - HTTP client dan fungsionalitas server untuk Julia
- Gumbo.jl - parsing html-layout dan tidak hanya
- Cascadia.jl - Paket Pelengkap untuk Gumbo

Kemudian kami mengimplementasikan skrip yang mengubah halaman puisi dan menyimpan pai menjadi dokumen teks:
Kode using HTTP, Gumbo, Cascadia function grabit(npages) str = "" for i = 1:npages url = "https://poetory.ru/por/rating/$i"
Secara lebih rinci, itu dibongkar di notebook Jupiter . Mari kita kumpulkan pai dan bubuk mesiu dalam satu baris:
str = read("pies.txt", String) * read("poroh.txt", String); length(str)
Dan lihat alfabet yang digunakan:
prod(sort([unique(str)..., '_']) )

Periksa data yang diunduh sebelum memulai proses.
Ay-ah-ah, sungguh memalukan! Beberapa pengguna melanggar aturan (kadang-kadang orang hanya mengekspresikan diri mereka sendiri dengan membuat suara dalam data ini). Jadi kita akan membersihkan kotak simbol dari sampah
str = lowercase(str)
Seperti yang disarankan oleh rssdev10, kode dimodifikasi menggunakan ekspresi reguler
Punya set karakter yang lebih dapat diterima. Pengungkapan terbesar hari ini adalah bahwa, dari sudut pandang kode mesin, setidaknya ada tiga ruang yang berbeda - sulit bagi pemburu data untuk hidup.

Sekarang Anda dapat menghubungkan Flux dengan penyajian data selanjutnya dalam bentuk vektor onehot:
Flux ikut berperan using Flux using Flux: onehot, chunk, batchseq, throttle, crossentropy using StatsBase: wsample using Base.Iterators: partition texta = collect(str) println(length(texta))
Kami mengatur model dari beberapa lapisan LSTM, perceptron dan softmax yang terhubung penuh, serta hal-hal kecil sehari-hari, dan untuk fungsi kerugian dan pengoptimal:
Kode m = Chain( LSTM(N, 256), LSTM(256, 128), Dense(128, N), softmax)
Model ini siap untuk pelatihan, jadi dengan menjalankan baris di bawah ini, Anda dapat menjalankan bisnis Anda sendiri, biaya yang dipilih sesuai dengan kekuatan komputer Anda. Dalam kasus saya, ini adalah dua kuliah tentang filsafat yang, untuk beberapa hal, disampaikan kepada kami larut malam ...
@time Flux.train!(loss, params(m), zip(Xs, Ys), opt, cb = throttle(evalcb, 30))
Setelah mengumpulkan generator sampel, Anda dapat mulai menuai manfaat dari kerja Anda.
generator barmaglot function sample(m, alphabet, len)
Kekecewaan sedikit karena harapan yang agak tinggi. Meskipun jaringan hanya memiliki urutan karakter pada input dan hanya dapat beroperasi dengan frekuensi pertemuan mereka satu demi satu, itu benar-benar menangkap struktur kumpulan data, memilih beberapa kemiripan kata-kata, dan dalam beberapa kasus bahkan menunjukkan kemampuan untuk mempertahankan ritme. Mungkin, identifikasi afinitas semantik akan membantu dalam meningkatkan.

Bobot jaringan yang terlatih dapat disimpan ke disk, lalu dibaca dengan mudah
weights = Tracker.data.(params(model)); using BSON: @save
Dengan prosa juga, hanya psychedelia cyber abstrak yang keluar. Ada upaya untuk meningkatkan kualitas lebar dan kedalaman jaringan, serta keanekaragaman dan kelimpahan data. Untuk korps teks yang diberikan, terima kasih khusus kepada popularizer terbesar dari bahasa Rusia

! . ? , , , , , , , , . , , , , . , . ? , , , , , ,
Tetapi jika Anda melatih jaringan saraf pada kode sumber bahasa Julia, maka itu ternyata cukup keren:
Menambah kemungkinan metaprogramming , kita mendapatkan program yang menulis dan mengeksekusi, bahkan mungkin kode kita sendiri! Ya, atau itu akan menjadi berkah bagi perancang film tentang peretas .
Secara umum, permulaan telah dibuat, dan kemudian sudah seperti yang ditunjukkan fantasi. Pertama, Anda harus mendapatkan peralatan berkualitas tinggi sehingga perhitungan panjang tidak menghambat keinginan untuk bereksperimen. Kedua, kita perlu mempelajari metode dan heuristik lebih mendalam, yang akan memungkinkan kita untuk merancang model yang lebih baik dan lebih dioptimalkan. Pada sumber daya ini, cukup untuk menemukan segala sesuatu yang berkaitan dengan Pemrosesan Bahasa Alami, setelah itu sangat mungkin untuk mengajarkan jaringan saraf Anda cara menghasilkan puisi atau pergi ke hackathon untuk analisis teks .
Tentang ini, biarkan aku pergi. Data untuk pelatihan di cloud , daftar di github , api di mata, telur di bebek, dan selamat malam semuanya!