Dalam
artikel saya sebelumnya saya berbicara tentang pengalaman menggunakan mesin
Gemini untuk mengembangkan tes visual, atau lebih tepatnya, tes regresi visual. Tes semacam itu memeriksa apakah ada sesuatu yang "bergerak" di UI setelah perubahan berikutnya dengan membandingkan tangkapan layar saat ini dengan yang sebelumnya diperbaiki. Sejak itu, banyak perubahan dalam pendekatan kami dalam menulis tes visual, termasuk mesin yang digunakan. Sekarang kita menggunakan
Hermione , tetapi dalam artikel ini saya akan memberitahu tidak hanya dan tidak begitu banyak tentang Hermione, tetapi tentang masalah yang telah terakumulasi sejak saat itu dan bagaimana menyelesaikannya, yang, antara lain, menyebabkan transisi ke mesin baru.
Pertama, meskipun tes berhasil, dan cukup berhasil, kami tidak memiliki pemahaman yang jelas tentang apa yang dicakup oleh tes dan apa yang tidak. Tentu saja ada beberapa gagasan tentang tingkat cakupan, tetapi kami tidak mengukurnya secara kuantitatif. Kedua, komposisi tes meningkat dari waktu ke waktu dan tes yang berbeda sering menguji hal yang sama, karena dalam tangkapan layar yang berbeda, beberapa bagian bertepatan dengan bagian yang sama, tetapi dalam tangkapan layar yang berbeda. Akibatnya, bahkan perubahan kecil pada CSS dapat membanjiri banyak tes sekaligus dan memerlukan pembaruan sejumlah besar standar. Ketiga, tema gelap muncul di produk kami, dan untuk menutupinya dengan beberapa pengujian, beberapa pengujian secara selektif beralih menggunakan tema gelap, yang juga tidak menambah kejelasan pada masalah dengan menentukan tingkat cakupan.
Optimalisasi kinerja
Kami mulai, anehnya, dengan kinerja yang dioptimalkan. Saya akan menjelaskan alasannya. Tes visual kami didasarkan pada
Storybook . Setiap cerita dalam buku cerita bukan komponen tunggal, tetapi seluruh "blok" (misalnya, kotak dengan daftar entitas, kartu entitas, dialog, atau bahkan aplikasi secara keseluruhan). Untuk menampilkan blok ini, Anda perlu "memompa" cerita dengan data, tidak hanya data yang ditampilkan kepada pengguna, tetapi juga keadaan komponen yang digunakan di dalam blok. Informasi ini disimpan bersama dengan kode sumber dalam bentuk file json yang berisi representasi serial dari keadaan aplikasi (redux store). Ya, data ini, secara sederhana, berlebihan, tetapi sangat menyederhanakan pembuatan tes. Untuk membuat tes baru, kita cukup membuka kartu, daftar atau dialog yang diinginkan dalam aplikasi, mengambil snapshot dari kondisi aplikasi saat ini dan membuat serialisasi ke dalam file. Lalu kami menambahkan cerita baru dan tes yang mengambil tangkapan layar dari cerita ini (semua dalam beberapa baris kode).
Pendekatan ini pasti meningkatkan ukuran bundel. Tingkat duplikasi data di dalamnya hanya "berguling". Saat menjalankan tes, mesin gemini mengeksekusi setiap test suite dalam sesi browser terpisah. Setiap sesi memuat bundel baru dan ukuran bundel dalam skema seperti itu jauh dari nilai terakhir.
Untuk mengurangi waktu uji berjalan, kami mengurangi jumlah suite uji dengan meningkatkan jumlah tes di dalamnya. Dengan demikian, satu test suite dapat mempengaruhi beberapa cerita sekaligus. Dalam skema ini, kami praktis kehilangan kemampuan untuk "menyaring" hanya area tertentu dari layar karena fakta bahwa Gemini memungkinkan Anda untuk mengatur area tangkapan layar hanya untuk test suite secara keseluruhan (meskipun API memungkinkan Anda untuk melakukan ini sebelum setiap tangkapan layar, tetapi dalam praktiknya tidak berfungsi).
Ketidakmampuan untuk membatasi area tangkapan layar dalam pengujian menyebabkan duplikasi informasi visual dalam gambar referensi. Meskipun tidak ada banyak tes, masalah ini tampaknya tidak signifikan. Ya, dan UI tidak sering berubah. Tapi ini tidak bisa berlangsung selamanya - desain ulang menjulang di cakrawala.
Ke depan, saya akan mengatakan bahwa di Hermione area tangkapan layar dapat ditetapkan untuk setiap pemotretan dan, sekilas, beralih ke mesin baru akan menyelesaikan semua masalah. Tapi kita masih harus "menghancurkan" suite tes besar. Faktanya adalah bahwa tes visual secara inheren tidak stabil (ini bisa disebabkan oleh berbagai alasan, misalnya, dengan kelambatan jaringan, menggunakan animasi, atau dengan "cuaca di Mars") dan sangat sulit untuk dilakukan tanpa coba ulang otomatis. Baik Gemini dan Hermione melakukan pengujian ulang untuk test suite secara keseluruhan, dan "lebih tebal" test suite tersebut, semakin kecil kemungkinannya untuk menyelesaikan dengan sukses selama pengujian ulang, karena pada percobaan berikutnya, tes yang sebelumnya berhasil diselesaikan dapat jatuh. Untuk suite uji tebal, kami harus menerapkan skema coba lagi alternatif yang dibangun ke dalam mesin Gemini dan benar-benar tidak ingin melakukan ini lagi ketika beralih ke mesin baru.
Oleh karena itu, untuk mempercepat pemuatan suite uji, kami membagi bundel monolitik menjadi beberapa bagian, mengalokasikan setiap snapshot dari status aplikasi menjadi “bagian” terpisah, memuat “sesuai permintaan” untuk setiap cerita secara terpisah. Kode pembuatan cerita sekarang terlihat seperti ini:
Untuk membuat cerita, komponen StoryProvider digunakan (kodenya akan diberikan di bawah). Snapshots diambil menggunakan fungsi
impor dinamis . Cerita yang berbeda berbeda satu sama lain hanya dalam gambar negara. Untuk tema gelap, ceritanya dihasilkan, menggunakan snapshot yang sama dengan cerita untuk tema terang. Dalam konteks buku cerita, kelihatannya seperti ini:
Komponen StoryProvider menerima panggilan balik untuk memuat snapshot di mana fungsi import () dipanggil. Fungsi import () bekerja secara tidak sinkron, sehingga Anda tidak dapat segera mengambil tangkapan layar setelah memuat cerita - kami berisiko menghapus kekosongan. Untuk menangkap momen akhir pengunduhan, penyedia membuat elemen DOM penanda menandakan mesin uji untuk seluruh waktu pengunduhan, yang harus ditunda dengan tangkapan layar:
Selain itu, untuk mengurangi ukuran bundel, nonaktifkan penambahan peta sumber ke bundel. Tetapi agar tidak kehilangan kemampuan untuk men-debug cerita (Anda tidak pernah tahu apa), kami melakukan ini dengan ketentuan:
.storybook / webpack.config.js Skrip build-storybook npm run mengkompilasi sebuah buku cerita statis tanpa sourcemap ke dalam folder statis-buku cerita. Ini digunakan saat melakukan tes. Dan
skrip buku cerita npm run digunakan untuk mengembangkan dan men-debug cerita uji.
Penghapusan duplikasi informasi visual
Seperti yang saya katakan di atas, Gemini memungkinkan Anda untuk mengatur pemilih area tangkapan layar untuk test suite secara keseluruhan, yang berarti bahwa untuk sepenuhnya menyelesaikan masalah duplikasi informasi visual dalam tangkapan layar, kami harus membuat suite pengujian kami sendiri untuk setiap tangkapan layar. Bahkan dengan mempertimbangkan optimalisasi memuat cerita, itu tidak terlihat terlalu optimis dalam hal kecepatan dan kami berpikir untuk mengganti mesin uji.
Sebenarnya, mengapa Hermione? Saat ini, repositori Gemini ditandai sebagai usang dan, cepat atau lambat, kami harus "pindah" ke suatu tempat. Struktur file konfigurasi Hermione identik dengan struktur file konfigurasi Gemini dan kami dapat menggunakan kembali konfigurasi ini. Plugin Gemini dan Hermione juga umum. Selain itu, kami dapat menggunakan kembali infrastruktur uji - mesin virtual dan menggunakan selenium-grid.
Tidak seperti Gemini, Hermione tidak diposisikan sebagai alat hanya untuk pengujian regresi tata letak. Kemampuan manipulasi browsernya jauh lebih luas dan hanya dibatasi oleh kemampuan
Webdriver IO . Dalam kombinasi dengan
moka, mesin ini nyaman digunakan lebih banyak untuk pengujian fungsional (mensimulasikan tindakan pengguna) daripada untuk pengujian tata letak. Untuk pengujian regresi tata letak, Hermione hanya menyediakan metode assertView (), yang membandingkan tangkapan layar laman peramban dengan referensi. Tangkapan layar dapat dibatasi pada area yang ditentukan menggunakan penyeleksi css.
Untuk kasus kami, ujian untuk setiap cerita individu akan terlihat seperti ini:
Metode waitForVisible (), terlepas dari namanya, memungkinkan Anda untuk mengharapkan tidak hanya penampilan, tetapi juga menyembunyikan elemen, jika Anda mengatur parameter kedua menjadi true. Di sini kita menggunakannya untuk menunggu elemen marker disembunyikan, menunjukkan bahwa snapshot data belum dimuat dan cerita belum siap untuk tangkapan layar.
Jika Anda mencoba menemukan metode waitForVisible () dalam dokumentasi Hermione, Anda tidak akan menemukan apa pun. Faktanya adalah bahwa metode waitForVisible ()
adalah metode API WebOver IO . Metode url (), masing-masing juga. Dalam metode url (), kami meneruskan alamat bingkai dari cerita tertentu, bukan keseluruhan buku cerita. Pertama, ini diperlukan agar daftar cerita tidak ditampilkan di jendela browser - kita tidak perlu mengujinya. Kedua, jika perlu, kita dapat memiliki akses ke elemen DOM di dalam bingkai (metode webdriverIO memungkinkan Anda untuk mengeksekusi kode JavaScript dalam konteks browser).
Untuk menyederhanakan penulisan tes, kami membuat bungkus kami lebih dari tes moka. Faktanya adalah bahwa tidak ada pengertian khusus dalam elaborasi rinci kasus uji untuk pengujian regresi. Semua kasus uji adalah sama - 'harus sama dengan etalon'. Yah, saya tidak ingin menduplikasi kode untuk menunggu pemuatan data di setiap tes. Oleh karena itu, pekerjaan yang sama untuk semua tes "monyet" didelegasikan ke fungsi pembungkus, dan tes itu sendiri ditulis secara deklaratif (well, hampir). Ini adalah teks dari fungsi ini:
buat-test-suite.js const themes = [ 'default', 'dark' ]; const rootClassName = '.explorer'; const loadingStubClassName = '.loading-stub'; const timeout = 2000; function createTestSuite(testSuite) { const { name, storyName, browsers, testCases, selector } = testSuite;
Objek yang mendeskripsikan suite tes dilewatkan ke input fungsi. Setiap rangkaian uji dibangun sesuai dengan skenario berikut: ambil tangkapan layar dari tata letak utama (misalnya, area kartu entitas atau area daftar entitas), lalu tekan tombol pemrograman yang dapat mengarah pada penampilan elemen lain (misalnya, panel sembul atau menu konteks) dan “ambil tangkapan layar »Setiap elemen tersebut secara terpisah. Jadi, kami mensimulasikan tindakan pengguna di browser, tetapi tidak dengan tujuan menguji skenario bisnis, tetapi hanya untuk "menangkap" jumlah maksimum komponen visual yang mungkin. Selain itu, duplikasi informasi visual dalam tangkapan layar minimal, karena tangkapan layar diambil "secara searah" menggunakan penyeleksi. Contoh test suite:
Penentuan cakupan
Jadi, kami menemukan kecepatan dan redundansi, masih untuk mengetahui efektivitas pengujian kami, yaitu menentukan tingkat cakupan kode dengan tes (di sini dengan kode saya maksudkan style sheet CSS).
Untuk cerita uji, kami secara empiris memilih kartu, daftar, dan elemen lain yang paling rumit untuk diisi agar dapat mencakup sebanyak mungkin gaya dengan satu tangkapan layar. Misalnya, untuk menguji kartu entitas, kartu dengan sejumlah besar jenis kontrol yang berbeda (teks, nomor, transfer, tanggal, kisi, dll.) Dipilih. Kartu untuk berbagai jenis entitas memiliki spesifiknya masing-masing, misalnya, panel dengan daftar versi dokumen dapat ditampilkan dari kartu dokumen, dan korespondensi pada tugas ini ditampilkan dalam kartu tugas. Dengan demikian, untuk setiap jenis entitas, kisahnya sendiri dan serangkaian tes khusus untuk jenis ini, dll., Dibuat. Pada akhirnya, kami memperkirakan bahwa segala sesuatu tampaknya ditutupi dengan tes, tetapi kami ingin sedikit lebih percaya diri daripada "suka".
Untuk mengevaluasi cakupan di Chrome DevTools, ada alat dengan nama Cakupan yang sangat cocok untuk kasus ini:
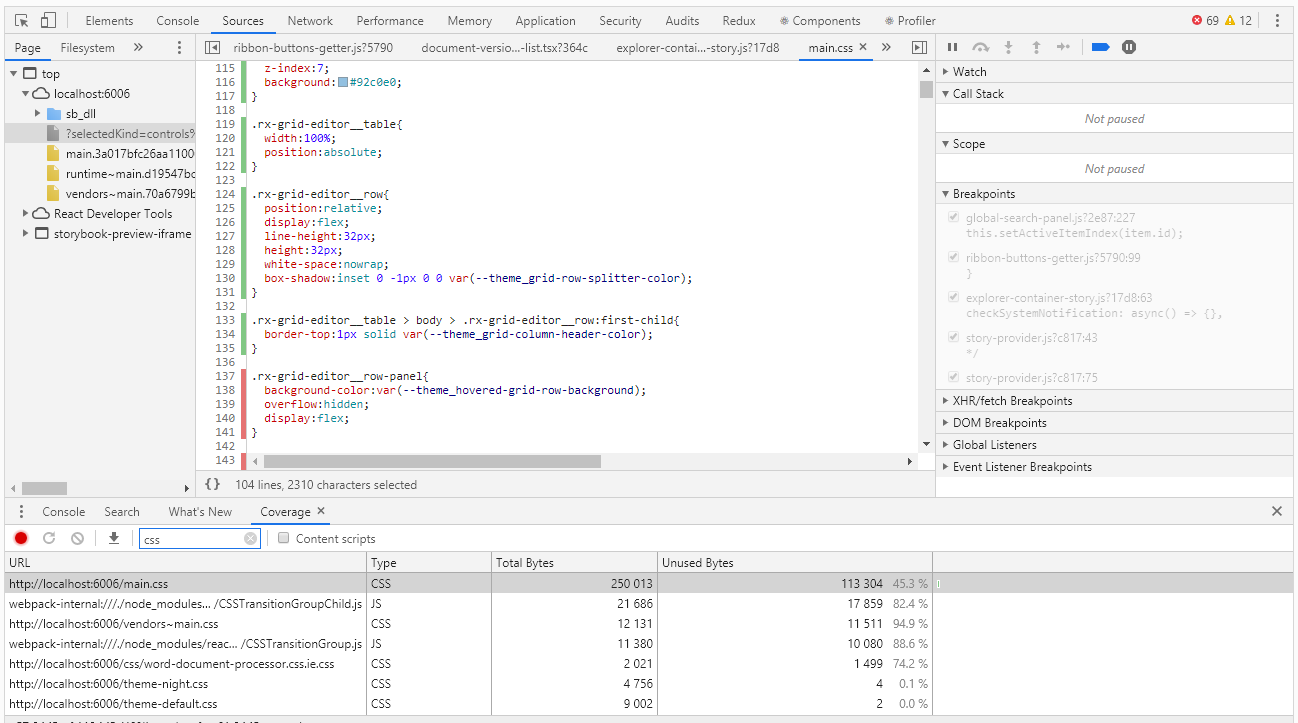
Cakupan memungkinkan Anda untuk menentukan gaya atau kode js mana yang digunakan saat bekerja dengan halaman browser. Laporan tentang penggunaan garis hijau menunjukkan kode yang digunakan, merah - tidak digunakan. Dan semuanya akan baik-baik saja jika kita memiliki aplikasi tingkat "halo, dunia", tetapi apa yang harus dilakukan ketika kita memiliki ribuan baris kode? Pengembang cakupan memahami hal ini dengan baik dan menyediakan kemampuan untuk mengekspor laporan ke file yang sudah dapat dikerjakan secara terprogram.
Saya harus mengatakan segera bahwa sejauh ini kami belum menemukan cara untuk mengumpulkan tingkat cakupan secara otomatis. Secara teoritis, ini dapat dilakukan dengan menggunakan browser kepala tanpa kepala, tetapi pupeteer tidak bekerja di bawah kendali selenium, yang berarti bahwa kita tidak akan dapat menggunakan kembali kode pengujian kami. Jadi untuk sekarang, mari kita lewati topik yang sangat menarik ini dan bekerja dengan pena.
Setelah menjalankan tes dalam mode manual, kami mendapatkan laporan cakupan, yang merupakan file json. Dalam laporan untuk setiap css, js, ts, dll. file menunjukkan teksnya (dalam satu baris) dan interval kode yang digunakan dalam teks ini (dalam bentuk indeks karakter dari baris ini). Di bawah ini adalah bagian dari laporan:
coverage.json [ { "url": "http://localhost:6006/theme-default.css", "ranges": [ { "start": 0, "end": 8127 } ], "text": "... --theme_primary-accent: #5b9bd5;\r\n --theme_primary-light: #ffffff;\r\n --theme_primary: #f4f4f4;\r\n ..." }, { "url": "http://localhost:6006/main.css", "ranges": [ { "start": 0, "end": 610 }, { "start": 728, "end": 754 } ] "text": "... \r\n line-height:1;\r\n}\r\n\r\nol, ul{\r\n list-style:none;\r\n}\r\n\r\nblockquote, q..." ]
Pada pandangan pertama, tidak ada yang sulit dalam menemukan penyeleksi css yang tidak digunakan. Tetapi apa yang harus dilakukan dengan informasi ini? Memang, dalam analisis akhir, kita perlu menemukan penyeleksi tidak spesifik, tetapi komponen yang kita lupa untuk menutup dengan tes. Gaya satu komponen dapat diatur oleh lebih dari selusin penyeleksi. Akibatnya, berdasarkan hasil analisis laporan, kami mendapatkan ratusan penyeleksi yang tidak digunakan, dan jika Anda berurusan dengan masing-masing dari mereka, Anda dapat menghabiskan banyak waktu.
Di sini, ekspresi reguler membantu kami. Tentu saja, mereka hanya akan berfungsi jika konvensi penamaan untuk kelas css terpenuhi (dalam kode kami, kelas css dinamai sesuai dengan metodologi BEM - block_name_name_name_ame_modifier). Menggunakan ekspresi reguler, kami menghitung nilai unik dari nama blok, yang tidak lagi sulit untuk dikaitkan dengan komponen. Tentu saja, kami juga tertarik pada elemen dan pengubah, tetapi tidak di tempat pertama, pertama kita perlu berurusan dengan "ikan" yang lebih besar. Di bawah ini adalah skrip untuk memproses laporan Cakupan
coverage.js const modules = require('./coverage.json').filter(e => e.url.endsWith('.css')); function processRange(module, rangeStart, rangeEnd, isUsed) { const rules = module.text.slice(rangeStart, rangeEnd); if (rules) { const regex = /^\.([^\d{:,)_ ]+-?)+/gm; const classNames = rules.match(regex); classNames && classNames.forEach(name => selectors[name] = selectors[name] || isUsed); } } let previousEnd, selectors = {}; modules.forEach(module => { previousEnd = 0; for (const range of module.ranges) { processRange(module, previousEnd, range.start, false); processRange(module, range.start, range.end, true); previousEnd = range.end; } processRange(module, previousEnd, module.length, false); }); console.log('className;isUsed'); Object.keys(selectors).sort().forEach(s => { console.log(`${s};${selectors[s]}`); });
Kami menjalankan skrip dengan terlebih dahulu meletakkan file coverage.json yang diekspor dari Chrome DevTools dan menulis knalpot ke file .csv:
node coverage.js> coverage.csvAnda dapat membuka file ini menggunakan excel dan menganalisis data, termasuk menentukan persentase cakupan kode dengan tes.

Alih-alih resume
Menggunakan buku cerita sebagai dasar untuk tes visual telah sepenuhnya dibenarkan sendiri - kami memiliki tingkat cakupan kode css yang cukup dengan tes dengan jumlah cerita yang relatif kecil dan biaya minimal untuk membuat yang baru.
Transisi ke mesin baru memungkinkan kami untuk menghilangkan duplikasi informasi visual dalam tangkapan layar, yang sangat menyederhanakan dukungan tes yang ada.
Tingkat cakupan kode css diukur dan, dari waktu ke waktu, dipantau. Tentu saja ada pertanyaan besar - bagaimana tidak melupakan perlunya kendali ini dan bagaimana tidak ketinggalan sesuatu dalam proses mengumpulkan informasi tentang liputan. Idealnya, saya ingin mengukur tingkat cakupan secara otomatis pada setiap uji coba, sehingga ketika ambang yang ditentukan tercapai, tes akan jatuh dengan kesalahan. Kami akan mengerjakan ini, jika ada berita, saya pasti akan memberi tahu Anda.