Halo, Habr! Hari ini kami ingin berbagi dengan Anda sebuah artikel oleh kepala dukungan teknis IT-GRAD Alik Fakhrutdinov, di mana kami akan berbicara tentang bagaimana kami membangun sistem pemantauan baru sebagai bagian dari kolaborasi dengan MTS PJSC. Kali ini kami menghilangkan detail teknis dan nuansa dan fokus pada kompleksitas administrasi proses. Di bawah potongan, kita akan berbicara tentang peristiwa apa yang mendorong kita untuk membangun sistem pemantauan baru (alih-alih "mengacaukan" yang lama), berbicara tentang chip pemantauan baru sebagai layanan untuk pelanggan dan kesulitan yang kita temui dalam proses.

Seperti yang Anda ketahui, konsep penyedia cloud terpadu saat ini diwakili oleh tiga merek berkolaborasi:
- #CloudMTS, dibuat oleh Pusat Inovasi MTS;
- IT-GRAD Company, penyedia IaaS berbasis cloud;
- 1 layanan keras.
Sekarang semua merek dalam konsep ini bekerja bersama dan saling melengkapi satu sama lain, mencoba untuk menutup permintaan dari berbagai segmen audiens kami. Namun, selama merger, kami menemui beberapa kesulitan, salah satunya mengarah pada pengembangan sistem pemantauan baru.
Setelah transaksi, proses pemisahan infrastruktur TI cloud IT-GRAD menjadi segmen terpisah diluncurkan. Itu adalah masa transisi yang sulit, di mana sejumlah besar peralatan dan pusat data terputus, yang tidak termasuk dalam garis besar transaksi. Routing dari jaringan internal dan eksternal telah berubah. Pada saat yang sama, tenggat waktu sangat ketat, dan pemicu dalam sistem pemantauan tidak selalu berhasil memperbarui tepat waktu. Hal ini menyebabkan banyak insiden palsu dari peralatan yang tidak ada.
Dalam proses rekonfigurasi global, para karyawan itu juga mengalami kesulitan. dukungan - mereka menghadapi aliran peringatan palsu yang sangat besar sehingga sangat sulit untuk memproses semua acara dengan benar dan tepat waktu. Itu perlu untuk mengkonfigurasi ulang sistem pemantauan, memutakhirkannya untuk tugas saat ini, dan benar-benar mengubahnya menjadi layanan baru baik untuk penggunaan internal maupun untuk pelanggan kami.
Sebagai hasilnya, diputuskan untuk membuat unit manajemen acara khusus, yang akan membentuk sistem pemantauan di IT-GRAD dan kemudian menjadi pusat tunggal untuk memantau keadaan infrastruktur penyedia cloud terintegrasi.
Sebagai hasil dari transformasi, persyaratan utama adalah:
- Sistem pemantauan harus bekerja tidak hanya pada IT-GRAD, tetapi juga menjadi layanan internal untuk Unified Cloud Provider dan layanan untuk pelanggan.
- Diperlukan solusi yang akan mengumpulkan statistik dari seluruh infrastruktur TI.
- Karena ada banyak sistem, semua peristiwa pemantauan harus bertemu dalam satu pengumpul data tunggal, di mana peristiwa dan pemicu diperiksa terhadap CMDB tunggal dan, jika perlu, pengguna secara otomatis diberitahu.
Setelah mengumpulkan dan menganalisis semua data yang tersedia pada saat itu, kami membagi implementasi proyek menjadi beberapa tahap:
- Menentukan persyaratan untuk sistem pemantauan.
- Persiapan model layanan "komponen kesehatan".
- Analisis persyaratan untuk keandalan dan toleransi kesalahan sistem pemantauan.
- Pengujian dan implementasi sistem yang konsisten.
- Organisasi pemantauan sebagai layanan bagi pelanggan.
Untuk kejelasan, kami menyajikan proses ini dalam bentuk diagram alur.

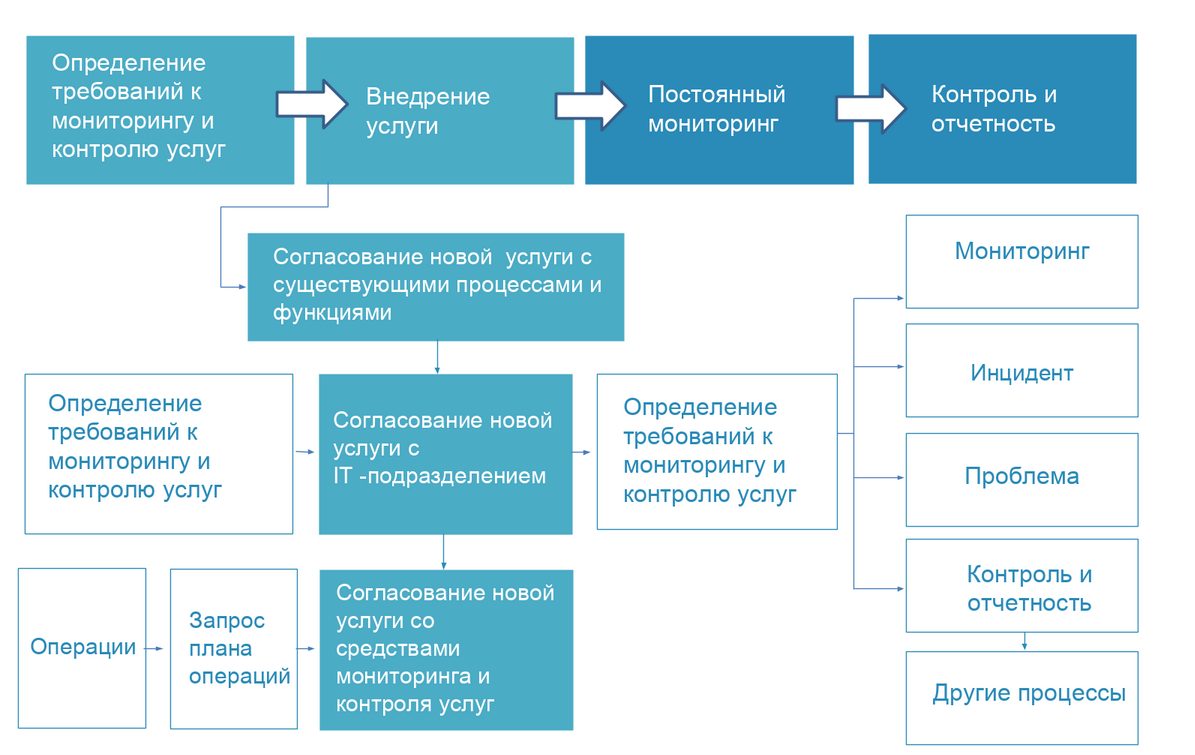
Kesulitan pertumbuhan
Tentu saja, pengenalan sistem yang begitu rumit tidak dapat berjalan dengan mulus, dan kami mengalami beberapa kesulitan.
- Poin pertama adalah pembentukan departemen baru. Ternyata menemukan spesialis yang sangat khusus yang tahu dan memiliki pengalaman praktis bekerja dengan berbagai sistem pemantauan tidak begitu sederhana. Salah satu persyaratan kami adalah pemahaman tentang pemantauan sebagai layanan, dan bukan hanya sebagai salah satu komponen infrastruktur TI.
- Tenggat waktu untuk menyelesaikan masalah.
- Infrastruktur TI yang terfragmentasi secara geografis yang perlu dibawa ke satu standar.
- Sejumlah besar sistem pemantauan yang berbeda yang perlu digabungkan menjadi satu sistem.
Pemantauan dan pelaporan dalam sistem pemantauan

Sosialisme, infrastruktur TI adalah akuntansi dan kontrol. Tidak ada satu peristiwa pun, bahkan yang paling tidak penting, harus dibiarkan tanpa perhatian. Saat ini, kami telah berhasil membangun proses pelaporan dan pengendalian, termasuk:
- melaporkan dan melacak statistik pada komponen pelanggan kami;
- Melakukan analisis manajemen tentang "status operasional" infrastruktur internal kami;
- merencanakan peningkatan layanan berdasarkan pelaporan yang dikumpulkan.
CMDB tunggal yang dibuat memungkinkan kita untuk melacak status dan sejarah peristiwa baik di seluruh infrastruktur secara keseluruhan dan untuk setiap komponen secara individual.
Selain itu, kami mulai memantau status masing-masing layanan, misalnya, pencadangan, yaitu kebenaran tugas pencadangan. Jika karena alasan tertentu tugas gagal, sistem mencatat kejadian tersebut. Ini menunjukkan server cadangan, tugas itu sendiri dan mesin virtual - mengetahui ini, kita dapat dengan cepat memperbaikinya. Selain itu, dengan memantau layanan, kami dapat memberikan laporan kepada pelanggan kami.

Di bawah ini kami berikan tangkapan layar laporan Live Technologies.

Di bawah ini Anda dapat melihat laporan ringkasan tentang jumlah insiden yang dikelompokkan berdasarkan kelas unit konfigurasi (KE) dalam hal tingkat pengaruh pada infrastruktur.

Hasil Sistem Pemantauan
Sistem pemantauan yang baru sudah beroperasi secara aktif, dan kami siap untuk berbagi dengan Anda hasil pekerjaannya dan pengamatan kami sendiri.
Saat ini, kami telah berhasil memulihkan pemantauan infrastruktur IT-GRAD sepenuhnya dan menyingkirkan generasi insiden palsu. Layanan untuk pelanggan sedang diuji dan akan segera tersedia. Di masa depan, kami berencana untuk menyelesaikan integrasi infrastruktur dengan menghubungkan 1cloud dan #CloudMTS ke satu sistem pemantauan IT-GRAD.
 Sebelumnya,
Sebelumnya, ketika pemicu peringatan dipicu, insiden pada dukungan 1-line dibuat. Petugas jaga memprosesnya dan memberi tahu pelanggan melalui telepon atau e-mail.
Sekarang semuanya bekerja secara mandiri: ketika pelatuk dipicu selama 2 menit, jika perlu, klien secara otomatis diberitahu.
Kami akan sedikit memperhatikan bagaimana peringatan bekerja.

Dalam hal terjadi perubahan status komponen TI, sistem pemantauan mendaftarkan peristiwa dalam agregator data, yang memproses peristiwa melalui badan surat dan, tergantung pada tingkat kekritisan keadaan komponen yang ditentukan dalam peringatan, menghasilkan permintaan, pemberitahuan atau insiden dengan prioritas yang diinginkan. Lebih lanjut, sistem, melalui CMDB, menentukan KE milik pelanggan, dan sesuai dengan model kesehatan, ia memberi peringatan melalui email atau SMS. Selain itu, saat ini, bot telegram khusus untuk peringatan sedang menjalani tahap finalisasi dan akan segera tersedia bagi semua pelanggan kami.

Sekarang, sebagai bagian dari proses pemantauan dan pengendalian layanan, kami memantau "keadaan kesehatan" lingkungan TI yang bekerja secara real time, secara otomatis memberi tahu pengguna eksternal dan internal. Memantau status infrastruktur dan layanan TI, serta data yang dikumpulkan, memungkinkan Anda untuk mengambil tindakan proaktif sebelum terjadi kesalahan.
Seperti yang Anda lihat, proses membangun sistem pemantauan penuh dengan jebakan. Namun demikian, kami yakin bahwa sebagai hasil kerja sama para insinyur dan analis kami, kami telah memperoleh produk unggulan yang memecahkan dua masalah bisnis sekaligus: memberikan pemantauan berkualitas tinggi dan memungkinkan kami menerapkan pemantauan sebagai layanan bagi pelanggan.