Bagian satu, ditambah.
Cotans, hai.
Saya Sasha dan saya menikmati neuron.
Atas permintaan para pekerja, saya akhirnya mengumpulkan pikiran saya dan memutuskan untuk mendapatkan serangkaian instruksi pendek dan hampir selangkah demi selangkah.
Petunjuk tentang cara melatih dan menggunakan jaringan saraf Anda dari awal, sekaligus berteman dengan bot telegram.
Instruksi untuk boneka seperti saya.
Hari ini kita akan memilih arsitektur jaringan saraf kita, mengujinya, dan mengumpulkan set data pelatihan pertama kita.
Pilihan arsitektur
Setelah peluncuran bot
selfie2anime yang relatif sukses (menggunakan model
UGATIT yang sudah jadi), saya ingin melakukan hal yang sama, tetapi milik saya. Misalnya, model yang mengubah foto Anda menjadi komik.
Berikut adalah beberapa contoh dari
photo2comicsbot saya, dan kami akan melakukan hal serupa.



Karena model
UGATIT terlalu berat untuk kartu video saya, saya menarik perhatian pada analogi yang lebih tua, tetapi kurang rakus -
CycleGANDalam implementasi ini, ada beberapa model arsitektur dan tampilan visual yang nyaman dari proses pembelajaran di browser.
CycleGAN, seperti
arsitektur untuk mentransfer gaya melintasi satu gambar, tidak memerlukan gambar berpasangan untuk pelatihan. Ini penting, karena kalau tidak kita harus mengubah semua foto diri kita menjadi komik untuk membuat set pelatihan.
Tugas yang akan kami tetapkan untuk algoritma kami terdiri dari dua bagian.
Pada output, kita harus mendapatkan gambaran bahwa:
a) mirip dengan buku komik
b) mirip dengan gambar aslinya
Poin "a" dapat diimplementasikan menggunakan GAN biasa, di mana Kritikus yang terlatih akan bertanggung jawab untuk "menyerupai komik".
Lebih lanjut tentang GAN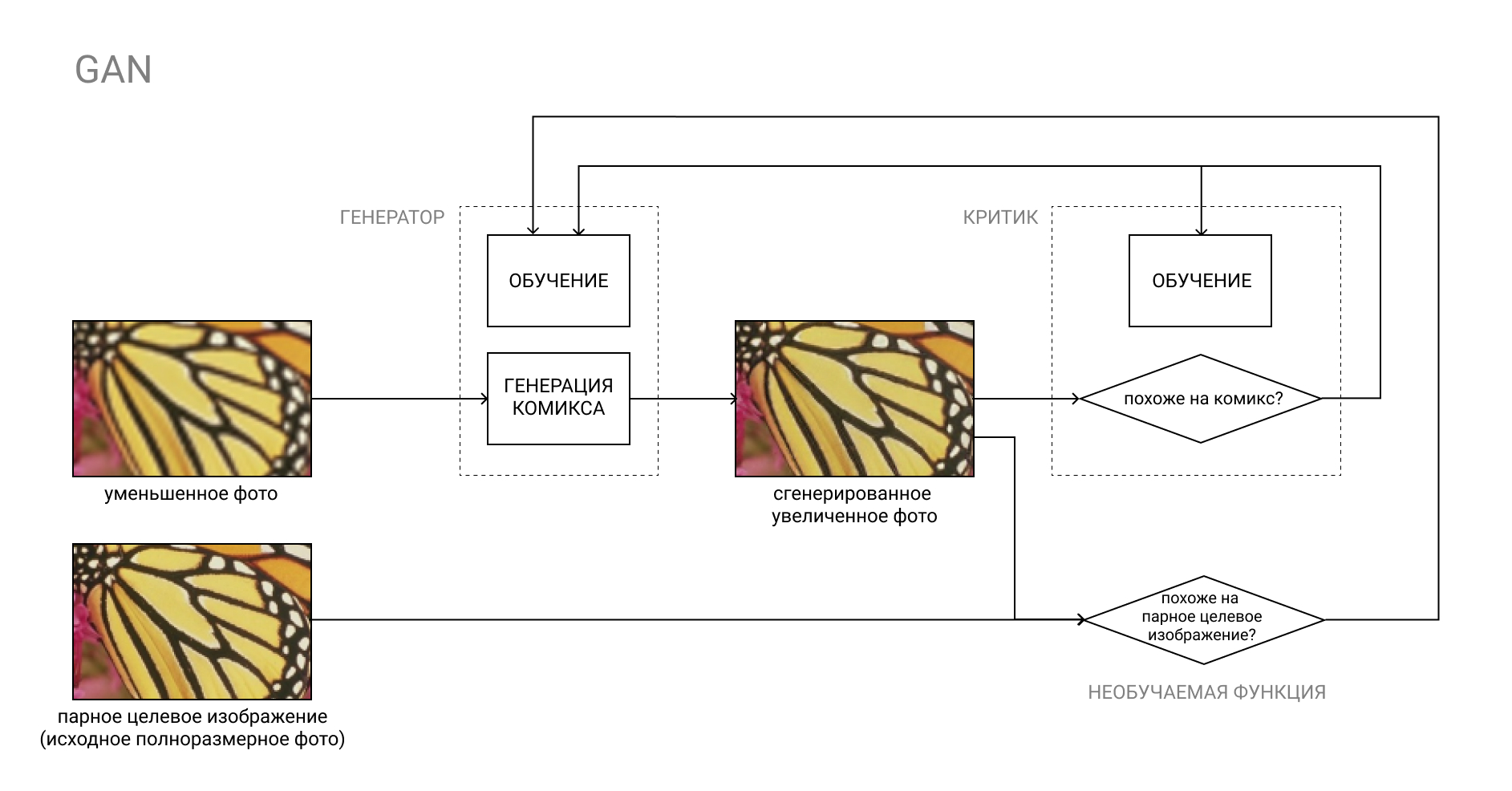
GAN, atau Generative Adversarial Network, adalah sepasang dari dua jaringan saraf: Generator dan Critic.
Generator mengubah input, misalnya, dari foto ke buku komik, dan kritikus membandingkan hasil "palsu" yang dihasilkan dengan buku komik nyata. Tugas Generator adalah untuk menipu Critic, dan sebaliknya.
Dalam proses pembelajaran, Generator belajar untuk membuat komik yang semakin mirip dengan komik asli, dan Critic belajar untuk lebih membedakan mereka.
Bagian kedua agak lebih rumit. Jika kita memasangkan foto, di mana akan ada foto di set "A", dan di set "B" itu, tapi digambar ulang menjadi komik (yaitu, apa yang ingin kita dapatkan dari model), kita bisa hanya untuk membandingkan hasil yang dihasilkan oleh Generator dengan gambar yang dipasangkan dari set "B" dari set pelatihan kami.
Dalam kasus kami, set "A" dan "B" sama sekali tidak terhubung satu sama lain. Di set "A" - foto acak, di set "B" - komik acak.
Tidak ada gunanya membandingkan komik palsu dengan beberapa komik acak dari set "B", karena ini setidaknya akan menduplikasi fungsi Kritikus, belum lagi hasil yang tidak terduga.
Di sinilah arsitektur CycleGAN datang untuk menyelamatkan.
Singkatnya, ini adalah pasangan GAN, yang pertama mengubah gambar dari kategori "A" (misalnya, foto) ke kategori "B" (misalnya, buku komik), dan yang kedua kembali, dari kategori "B" ke kategori "A".
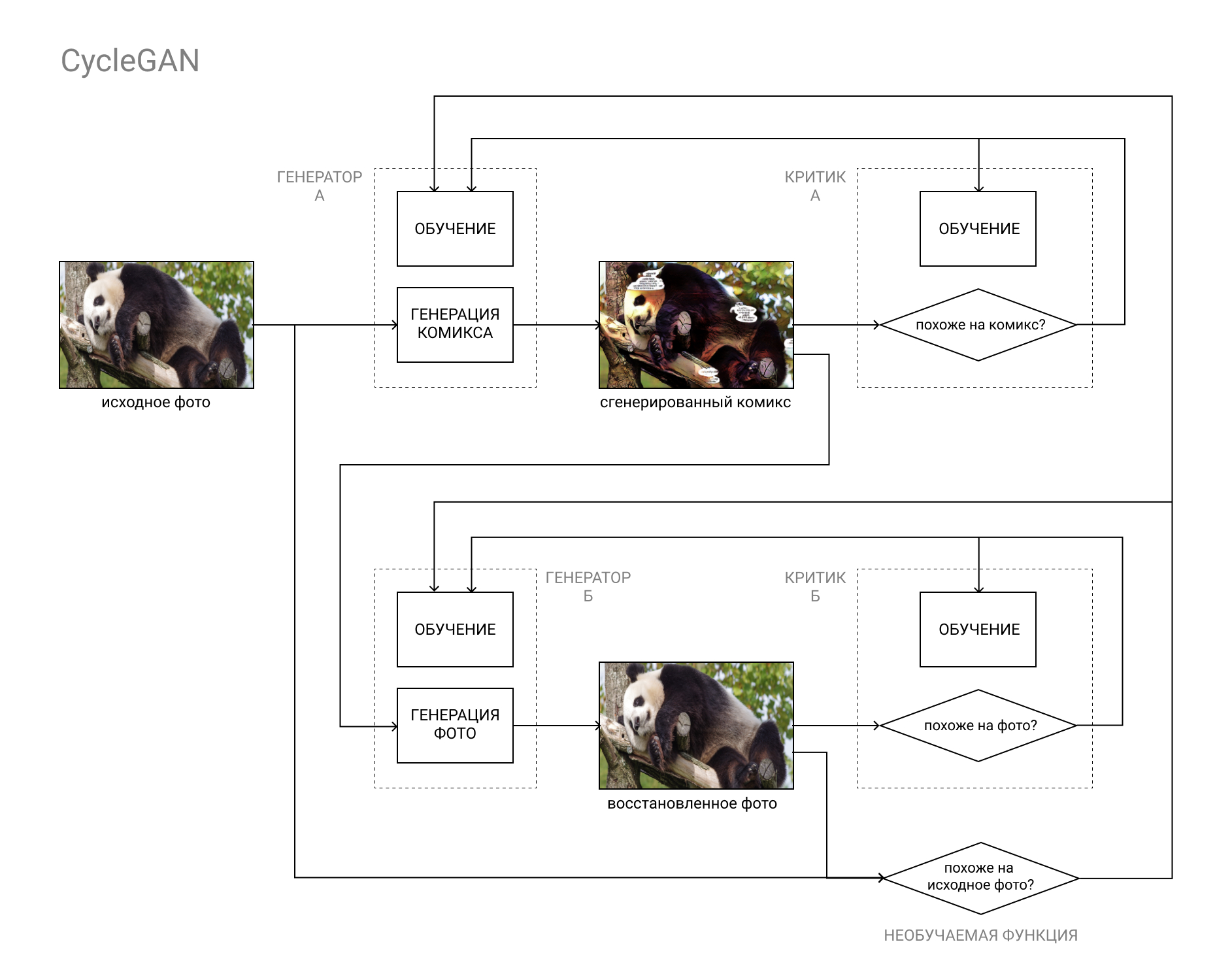
Model dilatih baik berdasarkan perbandingan foto asli dengan yang dipulihkan (sebagai hasil dari siklus "A" - "B" - "A", "foto-komik-foto), dan data para kritikus, seperti dalam GAN biasa.
Hal ini memungkinkan untuk menyelesaikan kedua bagian dari tugas kami: membuat buku komik yang tidak dapat dibedakan dari komik lain, dan pada saat yang sama menyerupai foto aslinya.
Instalasi model dan verifikasi
Untuk mengimplementasikan rencana licik kami, kami membutuhkan:
- Kartu grafis yang mendukung CUDA dengan RAM 8GB
- OS Linux
- Miniconda / Anaconda dengan Python 3.5+
Kartu video dengan kurang dari 8GB RAM juga dapat bekerja jika Anda menyulap dengan pengaturan. Ini juga akan bekerja pada Windows, tetapi lebih lambat, saya memiliki perbedaan setidaknya 1,5-2 kali.
Jika Anda tidak memiliki GPU dengan dukungan CUDA, atau Anda terlalu malas untuk mengatur semuanya, Anda selalu dapat menggunakan Google Colab. Jika ada cukup banyak orang yang ingin, saya akan mengisi tutorial dan cara mendongkrak semua yang berikut di Google cloud.Miniconda bisa dibawa ke siniPetunjuk pemasanganSetelah memasang Anaconda / Miniconda (selanjutnya disebut sebagai conda), buat lingkungan baru untuk percobaan kami dan aktifkan:
(Pengguna Windows harus memulai Anaconda Prompt terlebih dahulu dari menu Mulai)conda create --name cyclegan conda activate cyclegan
Sekarang semua paket akan diinstal di lingkungan aktif tanpa mempengaruhi sisa lingkungan. Ini nyaman jika Anda memerlukan kombinasi versi tertentu dari berbagai paket, misalnya, jika Anda menggunakan kode lama orang lain dan Anda perlu menginstal paket usang tanpa merusak kehidupan dan lingkungan kerja utama Anda.
Selanjutnya, cukup ikuti instruksi README.MD dari distribusi:
Simpan distribusi CycleGAN:
(atau cukup unduh arsip dari GitHub) git clone https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix cd pytorch-CycleGAN-and-pix2pix
Instal paket yang diperlukan:
conda install numpy pyyaml mkl mkl-include setuptools cmake cffi typing conda install pytorch torchvision -c pytorch conda install visdom dominate -c conda-forge
Unduh dataset yang sudah selesai dan model yang sesuai:
bash ./datasets/download_cyclegan_dataset.sh horse2zebra bash ./scripts/download_cyclegan_model.sh horse2zebra
Perhatikan foto apa saja yang ada dalam dataset yang diunduh.
Jika Anda membuka file skrip dari paragraf sebelumnya, Anda dapat melihat bahwa ada set data dan model yang sudah jadi untuk mereka.
Terakhir, uji model pada dataset yang diunduh:
python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra_pretrained --model test --no_dropout
Hasilnya akan disimpan di folder / results / horse2zebra_pretrained /
Membuat set pelatihan
Langkah yang sama pentingnya setelah memilih arsitektur model masa depan (dan mencari implementasi yang sudah selesai pada github) adalah mengkompilasi dataset, atau set data, yang akan kami latih dan uji model kami.
Hampir semuanya tergantung pada data apa yang kita gunakan. Sebagai contoh, UGATIT untuk bot selfie2anime dilatih tentang selfie wanita dan wajah wanita dari anime. Oleh karena itu, dengan foto-foto pria, dia berperilaku setidaknya lucu, menggantikan pria berjanggut brutal dengan gadis kecil dengan kerah tinggi. Dalam foto itu, hambamu yang rendah hati setelah dia mengetahui bahwa dia sedang menonton anime.

Seperti yang sudah Anda pahami, ada baiknya memilih foto / komik yang ingin Anda gunakan pada input dan dapatkan pada output. Apakah Anda berencana memproses selfie - tambahkan selfie dan close-up wajah dari komik, foto bangunan - tambahkan foto bangunan dan halaman dari komik dengan bangunan.
Sebagai contoh foto, saya menggunakan
DIV2K dan
Urban100 , dibumbui dengan foto bintang Google untuk meningkatkan keragaman.
Saya mengambil komik dari Marvel universe, seluruh halaman, membuang iklan dan pengumuman di mana gambarnya tidak terlihat seperti buku komik. Saya tidak bisa melampirkan tautan karena alasan yang jelas, tetapi atas permintaan Marvel Comics Anda dapat dengan mudah menemukan opsi yang dipindai di situs favorit Anda dengan komik, jika Anda tahu apa yang saya maksud.
Penting untuk memperhatikan gambar, itu berbeda dalam seri yang berbeda, dan skema warna.

Saya memiliki banyak deadpool dan spiderman, sehingga kulit menjadi sangat merah.
Daftar dataset publik lain yang tidak lengkap dapat ditemukan di
sini .
Struktur folder dalam dataset kami adalah sebagai berikut:
selfie2comics
├── trainA
├── melatih B
├── testA
└── testB
trainA - foto kami (sekitar 1000 pcs)
testA - beberapa foto untuk tes model (30pcs akan cukup)
trainB - komik kami (sekitar 1000 pcs.)
testB - komik untuk tes (30pcs.)
Dianjurkan untuk menempatkan dataset pada SSD, jika memungkinkan.
Itu saja untuk hari ini, dalam edisi berikutnya kita akan mulai melatih model dan mendapatkan hasil pertama!
Pastikan untuk menulis jika ada yang salah dengan Anda, ini akan membantu meningkatkan kepemimpinan dan mengurangi penderitaan pembaca berikutnya.
Jika Anda sudah mencoba untuk melatih modelnya, silakan bagikan hasilnya di komentar. Sampai ketemu lagi!
⇨ Bagian selanjutnya