Di hampir semua permainan komputer modern, kehadiran mesin fisik adalah prasyarat. Bendera dan kelinci berkibar ditiup angin, dihujani bola - semua ini membutuhkan eksekusi yang tepat. Dan, tentu saja, bahkan jika tidak semua pahlawan mengenakan jas hujan ... tetapi mereka yang mengenakannya benar-benar membutuhkan simulasi kain pengibar yang memadai.

Namun demikian, pemodelan fisik penuh dari interaksi seperti itu sering menjadi tidak mungkin, karena urutannya lebih lambat dari yang diperlukan untuk permainan waktu nyata. Artikel ini menawarkan metode pemodelan baru yang dapat mempercepat simulasi fisik, membuatnya 300-5000 kali lebih cepat. Tujuannya adalah untuk mencoba mengajarkan jaringan saraf untuk mensimulasikan kekuatan fisik.
Kemajuan dalam pengembangan mesin fisik ditentukan oleh kekuatan komputasi yang berkembang dari peralatan teknis dan pengembangan metode pemodelan yang cepat dan stabil. Metode tersebut termasuk, misalnya, pemodelan dengan memotong ruang menjadi subruang dan pendekatan berbasis data - yaitu, berdasarkan data. Yang pertama hanya bekerja dalam subruang yang dikurangi atau dikompresi, di mana hanya beberapa bentuk deformasi yang diperhitungkan. Untuk proyek besar, ini dapat menyebabkan peningkatan yang signifikan dalam persyaratan teknis. Pendekatan berbasis data menggunakan memori sistem dan data pra-komputasi yang tersimpan di dalamnya, yang mengurangi persyaratan ini.
Di sini kita melihat pendekatan yang menggabungkan kedua metode: dengan cara ini, ini dimaksudkan untuk memanfaatkan kekuatan keduanya. Metode seperti itu dapat diinterpretasikan dalam dua cara: baik sebagai metode pemodelan subruang parameterisasi oleh jaringan saraf, atau sebagai metode DD berdasarkan pemodelan subruang untuk membangun media simulasi terkompresi.
Esensinya adalah ini: pertama kami mengumpulkan data simulasi presisi tinggi menggunakan
Maya nCloth , dan kemudian kami menghitung subruang linier menggunakan
metode komponen utama (PCA) . Pada langkah berikutnya, kami menggunakan pembelajaran mesin berdasarkan model jaringan saraf klasik dan metodologi baru kami, setelah itu kami memperkenalkan model terlatih ke dalam algoritma interaktif dengan beberapa optimasi, seperti algoritma dekompresi yang efisien oleh GPU dan metode untuk mendekati normals vertex.
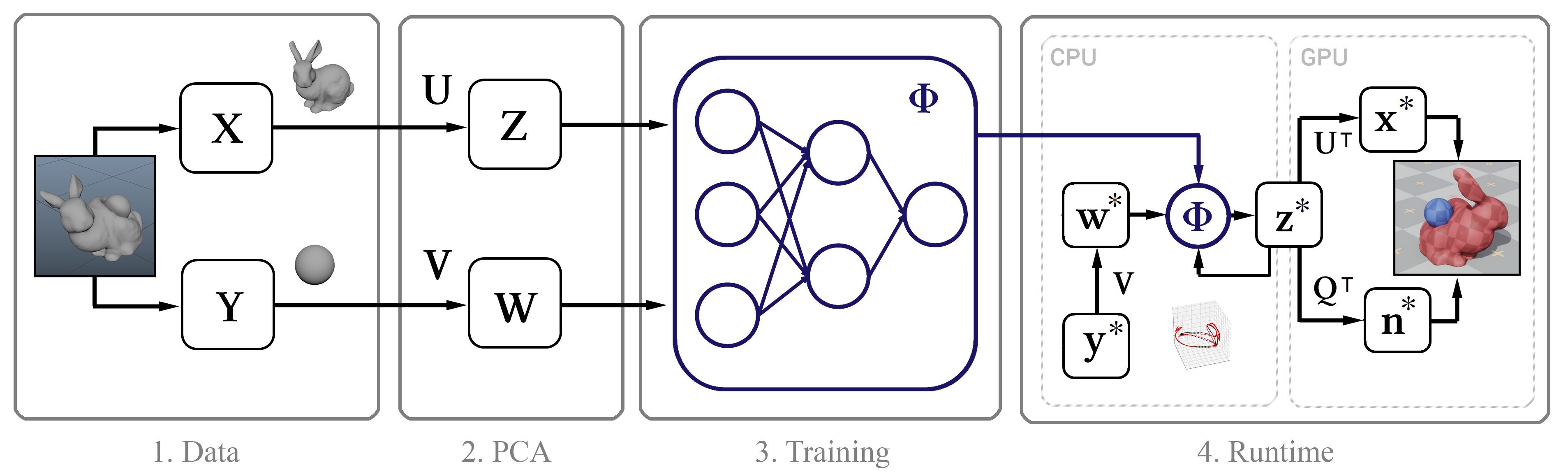 Gambar 1. Diagram struktural dari metode ini
Gambar 1. Diagram struktural dari metode iniData pelatihan
Secara umum, satu-satunya input untuk metode ini adalah stempel waktu mentah dari posisi frame-by-frame dari simpul objek. Selanjutnya, kami menggambarkan proses pengumpulan data tersebut.
Kami melakukan simulasi dalam Maya nCloth, menangkap data pada kecepatan 60 frame per detik, dengan 5 atau 20 subteps dan 10 atau 25 membatasi iterasi, tergantung pada stabilitas simulasi. Untuk kain, gunakan model T-shirt dengan sedikit peningkatan berat bahan dan ketahanannya terhadap peregangan, dan untuk benda yang cacat, karet keras dengan pengurangan gesekan. Kami melakukan tumbukan eksternal dengan bertabrakan segitiga geometri eksternal, tumbukan sendiri - simpul dengan simpul untuk kain dan segitiga dengan segitiga untuk karet. Dalam semua kasus, kami menggunakan ketebalan tumbukan yang agak besar - sekitar 5 cm - untuk memastikan stabilitas model dan mencegah terjepit dan robeknya kain.
Tabel 1. Parameter dari objek yang dimodelkan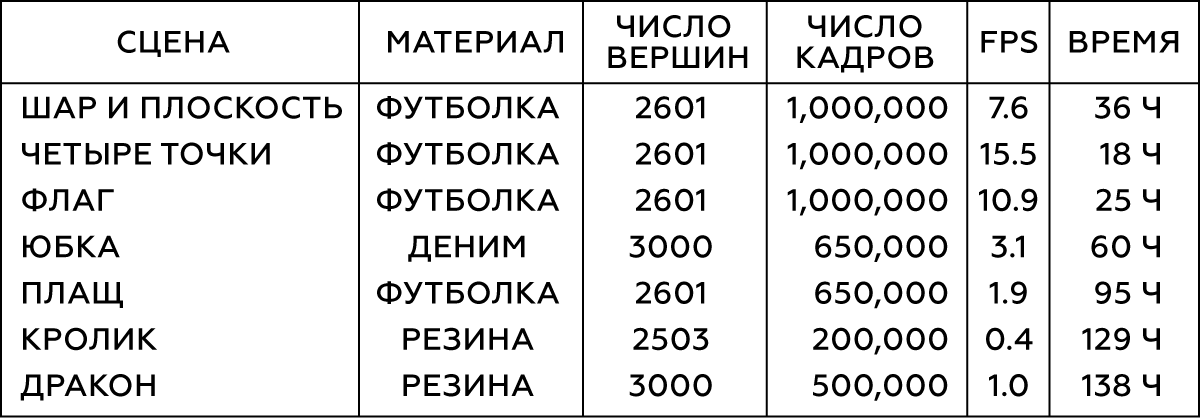
Untuk berbagai jenis interaksi objek sederhana (misalnya, bola), kami akan menghasilkan gerakan mereka secara acak dengan memotong koordinat acak pada waktu acak. Untuk mensimulasikan interaksi jaringan dengan karakter, kami menggunakan basis data penangkapan gerak 6,5 × 10
5 frame, yang merupakan satu animasi besar. Setelah menyelesaikan simulasi, kami memverifikasi hasilnya dan mengecualikan frame dengan perilaku yang tidak stabil atau buruk. Untuk adegan dengan rok, kami melepas tangan karakter, karena mereka sering bersinggungan dengan geometri jala kaki dan sekarang tidak signifikan.
 Gambar 2. Dua adegan pertama dari tabel
Gambar 2. Dua adegan pertama dari tabelBiasanya kita membutuhkan 10
5 -10
6 frame data pelatihan. Dalam pengalaman kami, dalam kebanyakan kasus 10
5 frame sudah cukup untuk pengujian, sedangkan hasil terbaik dicapai dengan 10
6 frame.
Pelatihan
Selanjutnya, kita akan berbicara tentang proses pembelajaran mesin: tentang parameterisasi dalam jaringan saraf kita, tentang arsitektur jaringan dan langsung tentang teknik itu sendiri.
Parameterisasi
Untuk mendapatkan kumpulan data pelatihan, kami mengumpulkan koordinat simpul di setiap frame
t menjadi satu vektor
xt , dan kemudian menggabungkan vektor frame-by-frame ini ke dalam satu matriks besar X. Matriks ini menjelaskan keadaan objek yang dimodelkan. Selain itu, kita harus memiliki gagasan tentang keadaan objek eksternal di setiap bingkai. Untuk objek sederhana (seperti bola), Anda dapat menggunakan koordinat tiga dimensi mereka, sedangkan keadaan model kompleks (karakter) dijelaskan oleh posisi setiap sambungan relatif ke titik referensi: dalam kasus rok, pendukung seperti itu akan menjadi sendi pinggul, dalam kasus jubah - leher. Untuk objek dengan sistem referensi bergerak, posisi Bumi relatif terhadapnya harus diperhitungkan: maka sistem kami akan mengetahui arah gravitasi, serta kecepatan linier, akselerasi, kecepatan rotasi, dan percepatan rotasi. Untuk bendera, kita akan memperhitungkan kecepatan dan arah angin. Akibatnya, untuk setiap objek kita mendapatkan satu vektor besar yang menggambarkan keadaan objek eksternal, dan semua vektor ini juga digabungkan ke dalam matriks Y.
Sekarang kita menerapkan PCA ke matriks X dan Y, dan menggunakan matriks transformasi yang dihasilkan Z dan W untuk membangun gambar ruang bagian. Jika prosedur PCA membutuhkan terlalu banyak memori, sampel pertama data kami.
Kompresi PCA mau tidak mau mengakibatkan hilangnya detail, terutama untuk objek dengan banyak kondisi potensial, seperti lipatan tipis kain. Namun, jika subruang terdiri dari 256 vektor basis, ini biasanya membantu menyimpan sebagian besar detail. Di bawah ini adalah animasi dari fisika standar jubah dan model dengan 256, 128 dan 64 vektor basis, masing-masing.
 Gambar 3. Perbandingan model kontrol (standar) dengan model yang diperoleh dengan metode kami di ruang dengan basis dimensi yang berbeda
Gambar 3. Perbandingan model kontrol (standar) dengan model yang diperoleh dengan metode kami di ruang dengan basis dimensi yang berbedaSumber dan Model yang Diperluas
Itu perlu untuk mengembangkan model yang dapat memprediksi keadaan vektor model dalam bingkai masa depan. Dan karena objek yang dimodelkan biasanya ditandai oleh inersia dengan kecenderungan ke keadaan rata-rata tertentu (setelah prosedur PCA objek mengambil keadaan seperti itu pada nilai nol), model awal yang baik akan menjadi ekspresi yang diwakili oleh garis 9 dari algoritma pada Gambar 4. Di sini α dan β adalah parameter model, ⊙ adalah produk yang meledak. Nilai-nilai parameter ini akan diperoleh dari sumber data dengan menyelesaikan
persamaan kuadrat linear terkecil secara individual untuk α dan β:
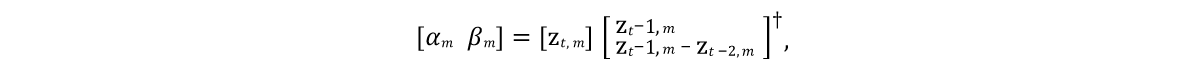
Di sini † adalah
transformasi pseudoinverse dari matriks .
Karena prediksi seperti itu hanya perkiraan yang sangat kasar dan tidak memperhitungkan pengaruh objek eksternal, jelas, itu tidak akan dapat secara akurat memodelkan data pelatihan. Oleh karena itu, kami melatih ne jaringan syaraf perkiraan efek residual dari model sesuai dengan garis 11 algoritma. Di sini kita parameterisasi
jaringan saraf distribusi langsung standar dengan 10 lapisan, untuk setiap lapisan (kecuali output) menggunakan fungsi aktivasi
ReLU . Tidak termasuk lapisan input dan output, kami menetapkan jumlah unit tersembunyi pada setiap lapisan yang tersisa sama dengan satu setengah ukuran data PCA, yang menyebabkan kompromi yang baik antara ruang yang ditempati pada hard drive dan kinerja.
 Gambar 4. Algoritma pembelajaran jaringan saraf
Gambar 4. Algoritma pembelajaran jaringan sarafPelatihan jaringan saraf
Cara standar untuk melatih jaringan saraf adalah dengan beralih pada seluruh kumpulan data dan melatih jaringan untuk membuat prediksi untuk setiap frame. Tentu saja, pendekatan seperti itu akan menyebabkan kesalahan belajar yang rendah, tetapi umpan balik dalam prediksi seperti itu akan menyebabkan perilaku hasilnya tidak stabil. Oleh karena itu, untuk memastikan prediksi jangka panjang yang stabil, algoritma kami menggunakan
metode propagasi kesalahan kembali selama prosedur integrasi.
Secara umum, ini bekerja seperti ini: dari jendela kecil data pelatihan
z dan
w, kami mengambil dua frame pertama
z 0 dan
z 1 dan menambahkan sedikit noise
r 0 ,
r 1 kepada mereka untuk sedikit mengganggu jalur pembelajaran. Kemudian, untuk memprediksi frame berikutnya, kami menjalankan algoritme beberapa kali, kembali ke hasil prediksi sebelumnya pada setiap langkah waktu baru. Segera setelah kami mendapatkan prediksi seluruh lintasan, kami menghitung kesalahan koordinat rata-rata, dan kemudian meneruskannya ke pengoptimal AmsGrad menggunakan turunan otomatis yang dihitung menggunakan TensorFlow.
Kami akan mengulangi algoritma ini pada sampel mini 16 frame, menggunakan jendela tumpang tindih 32 frame, untuk 100 era atau sampai pelatihan bertemu. Kami menggunakan tingkat pembelajaran 0,0001, koefisien atenuasi dari tingkat pembelajaran 0,999, dan standar deviasi kebisingan yang dihitung dari tiga komponen pertama ruang PCA. Pelatihan semacam ini memakan waktu 10 hingga 48 jam, tergantung pada kerumitan instalasi dan ukuran data PCA.
 Gambar 5. Perbandingan visual rok referensi dan rok yang dipelajari jaringan saraf kami
Gambar 5. Perbandingan visual rok referensi dan rok yang dipelajari jaringan saraf kamiImplementasi sistem
Kami akan menjelaskan secara rinci implementasi metode kami dalam lingkungan interaktif, termasuk mengevaluasi jaringan saraf, menghitung normals ke permukaan objek untuk rendering, dan bagaimana kami menangani persimpangan yang terlihat.
Aplikasi rendering
Kami merender model yang dihasilkan dalam aplikasi 3D interaktif sederhana yang ditulis dalam C ++ dan DirectX: kami sekali lagi menerapkan preproses dan operasi jaringan saraf dalam kode C ++ single-threaded dan memuat bobot jaringan biner yang diperoleh selama prosedur pelatihan kami. Kemudian kami menerapkan beberapa optimasi sederhana untuk estimasi jaringan, khususnya, penggunaan kembali buffer memori dan data matriks-vektor yang jarang, yang menjadi mungkin karena adanya nol unit tersembunyi yang diperoleh berkat fungsi aktivasi ReLU.
Dekompresi GPU
Kirim data status z yang dikompresi ke GPU dan dekompres untuk render lebih lanjut. Untuk tujuan ini, kami menggunakan shader komputasi sederhana, yang untuk setiap titik objek menghitung titik produk dari vektor z dan tiga baris pertama dari matriks U
T yang sesuai dengan koordinat titik ini, setelah itu kami menambahkan nilai rata-rata
x µ . Pendekatan ini memiliki dua keunggulan dibandingkan
metode dekompresi
naif . Pertama, paralelisme GPU secara signifikan mempercepat perhitungan vektor model negara, yang dapat memakan waktu hingga 1 ms. Kedua, mengurangi waktu transfer data antara pusat dan GPU dengan urutan besarnya, yang sangat penting untuk platform di mana transfer seluruh keadaan seluruh objek terlalu lambat.
Prediksi Vertex Normal
Selama rendering, tidak cukup hanya memiliki akses ke koordinat titik - informasi tentang deformasi normalnya juga diperlukan. Biasanya, dalam mesin fisik, hilangkan perhitungan ini, atau lakukan perhitungan ulang frame-by-frame yang naif terhadap normals dengan redistribusi selanjutnya ke simpul-simpul yang bertetangga. Ini mungkin berubah menjadi tidak efisien, karena implementasi dasar dari prosesor sentral, selain biaya dekompresi dan transfer data, memerlukan 150 μs untuk prosedur seperti itu. Dan meskipun perhitungan ini dapat dilakukan pada GPU, ternyata lebih sulit untuk diterapkan karena kebutuhan untuk operasi paralel.
Sebagai gantinya, kami melakukan regresi linier dari kondisi ruang bagian ke vektor kondisi penuh normal pada shader GPU. Mengetahui nilai-nilai normals dari simpul di setiap frame, kami menghitung matriks Q, yang paling mewakili representasi dari subruang pada normals dari simpul.
Karena prediksi normals dalam metode kami tidak pernah ditampilkan sebelumnya, tidak ada jaminan bahwa pendekatan ini akan akurat, tetapi dalam praktiknya terbukti sangat baik, seperti yang dapat dilihat dari gambar di bawah ini.
 Gambar 6. Perbandingan model yang dihitung dengan metode kami dan referensi (kebenaran dasar), serta perbedaan di antara mereka
Gambar 6. Perbandingan model yang dihitung dengan metode kami dan referensi (kebenaran dasar), serta perbedaan di antara merekaPertarungan titik-temu
Jaringan saraf kami belajar untuk melakukan tabrakan secara efisien, namun, karena ketidakakuratan dalam prediksi dan kesalahan yang disebabkan oleh kompresi subruang, persimpangan dapat terjadi antara objek eksternal dan yang disimulasikan. Selain itu, karena kami menunda perhitungan keadaan penuh adegan hingga permulaan rendering, tidak ada cara untuk secara efektif menyelesaikan masalah ini sebelumnya. Oleh karena itu, untuk mempertahankan kinerja tinggi, menghilangkan persimpangan ini diperlukan selama rendering.
Kami menemukan solusi sederhana dan efektif untuk ini, terdiri dari fakta bahwa perpotongan simpul diproyeksikan ke permukaan primitif dari mana kita membentuk karakter. Proyeksi ini mudah dilakukan pada GPU menggunakan shader komputasi yang sama yang mendekompresi fabric dan menghitung shading normal.
Jadi, pertama-tama, kita akan menyusun karakter dari objek proxy yang terhubung dengan simpul dengan jari-jari awal dan akhir yang berbeda, setelah itu kita akan mentransfer informasi tentang koordinat dan jari-jari objek ini ke shader komputasi. Sekali lagi, periksa koordinat masing-masing simpul untuk persimpangan dengan objek proxy yang sesuai dan, jika ya, proyeksikan simpul ini ke permukaan objek proxy. Jadi kami hanya memperbaiki posisi vertex, tanpa menyentuh yang normal itu sendiri, agar tidak merusak shading.
Pendekatan ini akan menghapus persimpangan kecil objek yang terlihat, asalkan kesalahan perpindahan verteks tidak begitu besar sehingga proyeksi berada di sisi berlawanan dari objek proxy yang sesuai.
 Gambar 7. Model karakter terdiri dari objek proxy dan hasil menghilangkan persimpangan terlihat menggunakan metode kami: sebelum dan sesudah
Gambar 7. Model karakter terdiri dari objek proxy dan hasil menghilangkan persimpangan terlihat menggunakan metode kami: sebelum dan sesudahAnalisis Hasil
Jadi, adegan pengujian kami meliputi:
, .
- 16 , 120 240 .
 8. 16 . Party time!
8. 16 . Party time!, , , , .
, PCA. , , , .
 9. , , –
9. , , –Eksekusi
― , . , . 300-5000 , . ,
- (HRPD) ,
(LSTM) (GRU) .
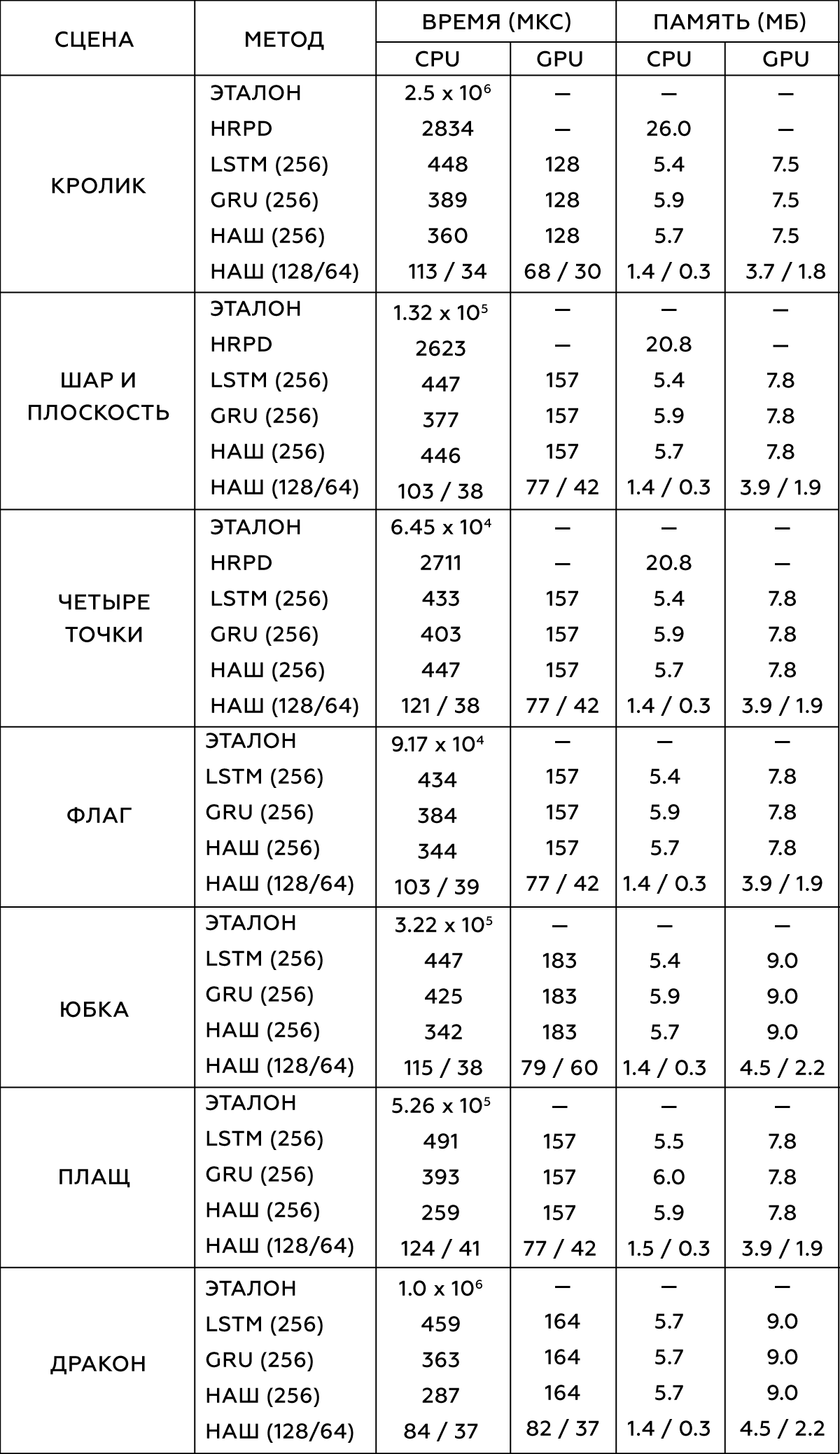
, . Intel Xeon E5-1650 3.5 GHz GeForce GTX 1080 Titan.
2.
, , . , .
data-driven , . , , , , , . , , ― , .
, , , .
, . data-driven , ― , . , , , . , , , .
, . .
, , , . , , ― , . -, , , - . .
, , , , . , , , , ― , , . .
.
 10. vs : choose your fighter
10. vs : choose your fighter