Berdasarkan jenis kegiatan, seseorang harus berurusan dengan situasi ketika pengembang menulis permintaan dan berpikir "
basisnya cerdas, ia dapat menangani semuanya! "
Dalam beberapa kasus (sebagian karena ketidaktahuan tentang kemampuan basis data, sebagian dari optimasi prematur), pendekatan ini mengarah pada penampilan "Frankenstein".
Pertama, saya akan memberikan contoh pertanyaan seperti itu:
Untuk mengevaluasi secara obyektif kualitas permintaan, mari kita buat beberapa kumpulan data arbitrer:
CREATE TABLE tbl AS SELECT (random() * 1000)::integer key_a , (random() * 1000)::integer key_b , (random() * 10000)::integer fld1 , (random() * 10000)::integer fld2 FROM generate_series(1, 10000); CREATE INDEX ON tbl(key_a, key_b);
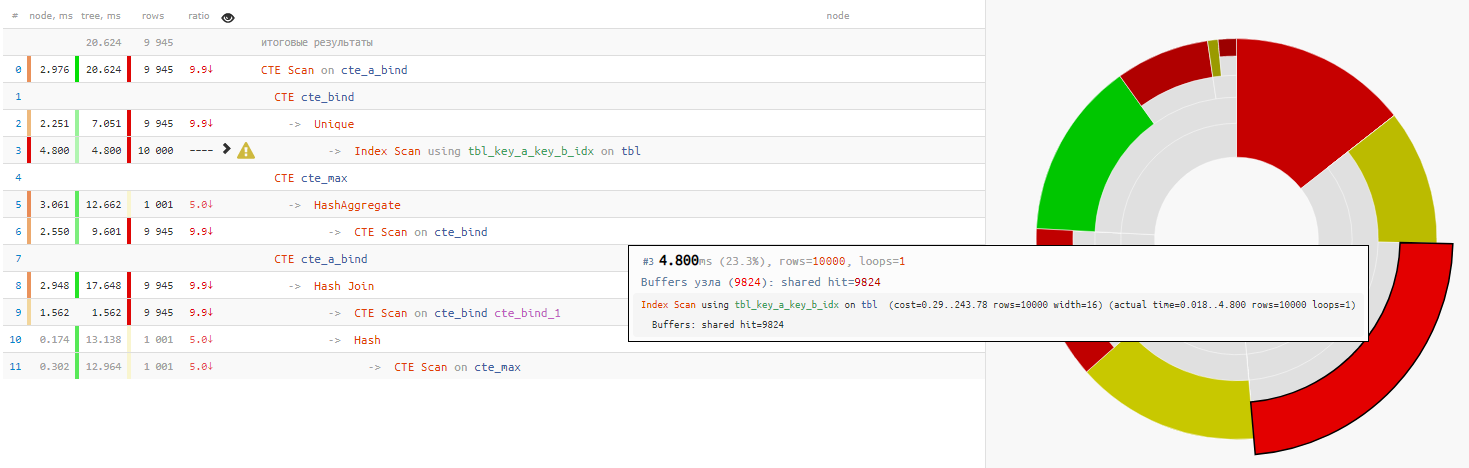
Ternyata
membaca data itu sendiri
membutuhkan kurang dari seperempat dari total waktu eksekusi permintaan:
 [lihat menjelaskan.tensor.ru]
[lihat menjelaskan.tensor.ru]Bongkar dengan tulang
Kami akan mencermati permintaan, dan kami akan bingung:
- Mengapa DENGAN RECURSIVE di sini, jika tidak ada CTE rekursif?
- Mengapa mengelompokkan nilai min / maks dalam CTE terpisah jika masih melekat pada sampel asli?
+ 25% dari waktu - Mengapa pada akhirnya menggunakan pembacaan ulang dari CTE sebelumnya melalui 'SELECT * FROM' tanpa syarat?
+ 14% dari waktu
Dalam hal ini, kami sangat beruntung bahwa Hash Join dipilih untuk koneksi, dan bukan Nested Loop, karena dengan begitu kami tidak akan mendapatkan satu pun CTE Scan pass, tetapi 10K!
sedikit tentang CTE ScanDi sini kita harus ingat bahwa CTE Scan adalah analog dari Seq Scan - yaitu, tidak ada pengindeksan, tetapi hanya pencarian lengkap, yang akan membutuhkan 10K x 0,3ms = 3000 ms untuk siklus cte_max atau 1K x 1,5 ms = 1500 ms untuk siklus cte_bind !
Sebenarnya, apa yang ingin Anda dapatkan sebagai hasilnya?
Ya, biasanya pertanyaan semacam ini yang ia kunjungi di suatu tempat pada menit ke-5 analisis permintaan "tiga lantai".Kami ingin setiap pasangan kunci unik untuk menghapus
min / maks dari grup dengan key_a .
Jadi kita akan menggunakan
fungsi jendela untuk ini:
SELECT DISTINCT ON(key_a, key_b) key_a a , key_b b , max(fld1) OVER(w) bind_fld1 , min(fld2) OVER(w) bind_fld2 FROM tbl WINDOW w AS (PARTITION BY key_a);
 [lihat menjelaskan.tensor.ru]
[lihat menjelaskan.tensor.ru]Karena membaca data di kedua versi membutuhkan waktu sekitar 4-5ms sama, seluruh waktu perolehan kami
-32% adalah
beban murni
dihapus dari CPU dasar , jika permintaan seperti itu dilakukan cukup sering.
Secara umum, Anda tidak boleh memaksa alas untuk "memakai bulat, guling persegi."