
Hanya saja, jangan kaget, tetapi pos kedua ke posting ini menghasilkan jaringan saraf, atau lebih tepatnya, algoritma sammarisasi. Dan apa itu sammarisasi?
Ini adalah salah satu
tantangan utama dan klasik
dari Natural Language Processing (NLP) . Ini terdiri dalam menciptakan algoritma yang mengambil teks sebagai input dan output versi singkatnya. Selain itu, struktur yang benar (sesuai dengan norma-norma bahasa) dipertahankan di dalamnya dan gagasan utama teks ditransmisikan dengan benar.
Algoritma seperti ini banyak digunakan di industri. Misalnya, mereka berguna untuk mesin pencari: menggunakan pengurangan teks, Anda dapat dengan mudah memahami apakah ide utama sebuah situs atau dokumen berkorelasi dengan permintaan pencarian. Mereka digunakan untuk mencari informasi yang relevan dalam aliran besar data media dan untuk menyaring informasi sampah. Pengurangan teks membantu dalam penelitian keuangan, dalam analisis kontrak hukum, anotasi makalah ilmiah dan banyak lagi. Omong-omong, algoritma sammarisasi menghasilkan semua subpos untuk posting ini.
Yang mengejutkan saya, di Habré ada sedikit artikel tentang sammarisasi, jadi saya memutuskan untuk membagikan penelitian dan hasil saya ke arah ini. Tahun ini saya berpartisipasi dalam arena pacuan kuda di konferensi
Dialog dan bereksperimen dengan generator utama untuk item berita dan puisi menggunakan jaringan saraf. Dalam posting ini, pertama-tama saya akan membahas secara singkat bagian teoritis dari sammarisasi, dan kemudian saya akan memberikan contoh dengan generasi judul, saya akan memberi tahu Anda apa kesulitan yang dimiliki model ketika mengurangi teks dan bagaimana model ini dapat ditingkatkan untuk mencapai judul yang lebih baik.
Di bawah ini adalah contoh dari item berita dan headline referensi aslinya. Model yang akan saya bicarakan akan melatih untuk menghasilkan header dengan contoh ini:

Rahasia memotong arsitektur teks seq2seq
Ada dua jenis metode pengurangan teks:
- Ekstraktif . Ini terdiri dari menemukan bagian-bagian paling informatif dari teks dan membangun dari mereka penjelasan yang benar untuk bahasa yang diberikan. Kelompok metode ini hanya menggunakan kata-kata yang ada di teks sumber.
- Abstrak Ini terdiri dari mengekstraksi tautan semantik dari teks, sambil mempertimbangkan dependensi bahasa akun. Dengan sammarisasi abstrak, kata-kata penjelasan tidak dipilih dari teks yang disingkat, tetapi dari kamus (daftar kata-kata untuk bahasa tertentu) - dengan demikian mengulangi gagasan utama.
Pendekatan kedua menyiratkan bahwa algoritma harus memperhitungkan dependensi bahasa akun, menyusun ulang dan menggeneralisasi. Dia juga ingin memiliki pengetahuan tentang dunia nyata untuk mencegah kesalahan faktual. Untuk waktu yang lama, ini dianggap sebagai tugas yang sulit, dan para peneliti tidak bisa mendapatkan solusi berkualitas tinggi - teks yang secara tata bahasa benar sambil mempertahankan ide utama. Itulah sebabnya di masa lalu, sebagian besar algoritma didasarkan pada pendekatan penggalian, karena pemilihan seluruh bagian teks dan mentransfernya ke hasilnya memungkinkan Anda untuk mempertahankan tingkat literasi yang sama dengan sumbernya.
Tapi ini sebelum booming jaringan saraf dan penetrasi ke dalam NLP. Pada tahun 2014, arsitektur
seq2seq diperkenalkan dengan mekanisme perhatian yang dapat membaca beberapa urutan teks dan menghasilkan yang lain (yang tergantung pada apa yang dipelajari oleh model untuk dihasilkan) (
artikel oleh Sutskever et al.). Pada tahun 2016, arsitektur semacam itu diterapkan langsung ke solusi masalah sammarisasi, sehingga mewujudkan pendekatan abstrak dan memperoleh hasil yang sebanding dengan apa yang dapat ditulis oleh orang yang kompeten (
artikel dari Nallapati et al., 2016;
artikel dari Rush et al., 2015; ) Bagaimana cara kerja arsitektur ini?
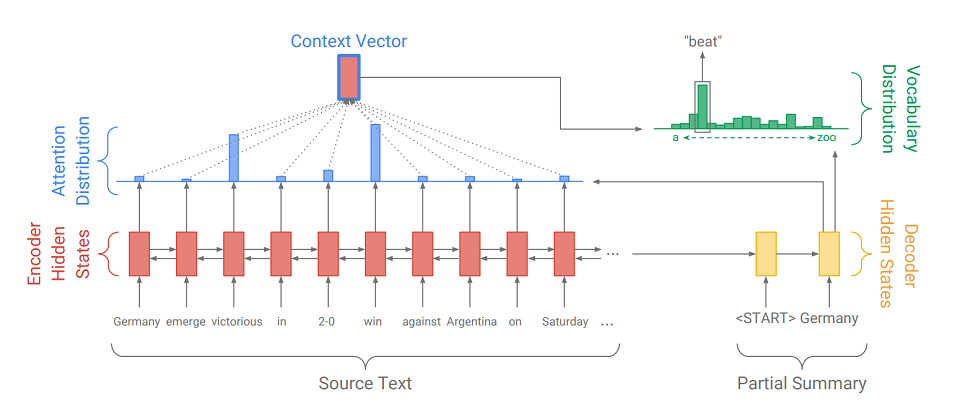
Seq2Seq terdiri dari dua bagian:
- Encoder (Encoder) - RNN dua arah, yang digunakan untuk membaca urutan input, yaitu, secara berurutan memproses elemen input secara simultan dari kiri ke kanan dan dari kanan ke kiri untuk lebih mempertimbangkan konteksnya.
- decoder (Decoder) - RNN satu arah, yang secara berurutan dan elemen-bijaksana menghasilkan urutan output.
Pertama, urutan input diterjemahkan ke dalam urutan embedding (singkatnya, embedding adalah representasi singkat dari sebuah kata sebagai vektor). Embeddings kemudian melalui jaringan rekursif encoder. Jadi, untuk setiap kata, kita mendapatkan status tersembunyi pembuat enkode (
ditunjukkan oleh segi empat merah pada diagram ), dan mereka berisi informasi tentang token itu sendiri dan konteksnya, memungkinkan kita untuk memperhitungkan koneksi bahasa antara kata-kata tersebut.
Setelah memproses input, encoder mentransfer status tersembunyi terakhirnya (yang berisi informasi terkompresi tentang seluruh teks) ke decoder, yang menerima token khusus

dan menciptakan kata pertama dari urutan output (
dalam gambar itu adalah "Jerman" ). Kemudian ia secara siklik mengambil output sebelumnya, mengumpankannya sendiri dan kembali menampilkan elemen output berikutnya (
jadi setelah "Jerman" muncul "beat", dan setelah "beat" muncul kata berikutnya, dll .). Ini diulang sampai tanda khusus dikeluarkan
. Ini berarti akhir generasi.
Untuk menampilkan elemen berikutnya, decoder, seperti halnya encoder, mengubah token input menjadi embedding, mengambil langkah dari jaringan rekursif dan menerima keadaan tersembunyi berikutnya dari decoder (
persegi panjang kuning pada diagram ). Kemudian, menggunakan lapisan yang terhubung penuh, distribusi probabilitas diperoleh untuk semua kata dari kamus model yang dikompilasi sebelumnya. Kata-kata yang paling mungkin akan disimpulkan oleh model.
Menambahkan
mekanisme perhatian membantu decoder memanfaatkan informasi input dengan lebih baik. Mekanisme pada setiap langkah generasi menentukan apa yang disebut
distribusi perhatian (
segi empat biru pada gambar adalah himpunan bobot yang sesuai dengan elemen-elemen dari urutan asli, jumlah bobot adalah 1, semua bobot> = 0 ), dan dari itu menerima jumlah tertimbang dari semua status tersembunyi dari enkoder, dengan demikian membentuk vektor konteks (
diagram menunjukkan persegi panjang merah dengan goresan biru ). Vektor ini diakhiri dengan menanamkan kata input dekoder pada tahap penghitungan keadaan laten dan dengan keadaan laten itu sendiri pada tahap penentuan kata berikutnya. Jadi pada setiap langkah output, model dapat menentukan status encoder mana yang paling penting untuk saat ini. Dengan kata lain, itu memutuskan konteks yang kata input harus paling diperhitungkan (misalnya, dalam gambar, menampilkan kata "beat", mekanisme perhatian memberikan bobot besar untuk token "menang" dan "menang", dan sisanya mendekati nol).
Karena generasi header juga merupakan salah satu tugas sammarisasi, hanya dengan output seminimal mungkin (1-12 kata), saya memutuskan untuk menerapkan
seq2seq dengan mekanisme perhatian untuk kasus kami. Kami melatih sistem semacam itu pada teks dengan judul, misalnya, tentang berita. Selain itu, disarankan pada tahap pelatihan untuk menyerahkan ke decoder bukan outputnya sendiri, tetapi kata-kata dari heading yang sebenarnya (guru memaksa), membuat hidup lebih mudah untuk dirinya sendiri dan modelnya. Sebagai fungsi kesalahan, kami menggunakan fungsi kerugian lintas-entropi standar, menunjukkan seberapa dekat distribusi probabilitas kata output dan kata dari header sebenarnya adalah:
Saat menggunakan model terlatih, kami menggunakan pencarian ray untuk menemukan urutan kata yang lebih mungkin daripada menggunakan algoritma serakah. Untuk melakukan ini, pada setiap langkah generasi, kami bukan berasal dari kata yang paling mungkin, tetapi pada saat yang sama melihat pada beam_size dari urutan kata yang paling mungkin. Ketika mereka berakhir (masing-masing berakhir
), kami memperoleh urutan yang paling mungkin.
Evolusi model
Salah satu masalah model pada seq2seq adalah ketidakmampuan untuk mengutip kata-kata yang tidak ada dalam kamus. Misalnya, model tidak memiliki kesempatan untuk menyimpulkan "obamacare" dari artikel di atas. Hal yang sama berlaku untuk:
- nama keluarga dan nama langka
- ketentuan baru
- kata dalam bahasa lain,
- pasangan kata yang berbeda dihubungkan oleh tanda hubung (sebagai "Senator Republik")
- dan desain lainnya.
Tentu saja, Anda dapat memperluas kamus, tetapi ini sangat meningkatkan jumlah parameter terlatih. Selain itu, perlu untuk menyediakan sejumlah besar dokumen di mana kata-kata langka ini ditemukan, sehingga generator belajar untuk menggunakannya secara kualitatif.
Solusi lain dan lebih elegan untuk masalah ini disajikan dalam artikel 2017 - "
Get To The Point: Summarization dengan Pointer-Generator Networks " (Abigail See et al.). Dia menambahkan mekanisme baru ke model kami -
mekanisme penunjuk, yang dapat memilih kata-kata dari teks sumber dan langsung memasukkan ke dalam urutan yang dihasilkan. Jika teks berisi OOV (
dari kosakata - kata yang tidak ada dalam kamus ), maka model, jika dianggap perlu, dapat mengisolasi OOV dan memasukkannya pada output. Sistem seperti ini disebut
" pointer-generator" (pointer-generator atau pg) dan merupakan sintesis dari dua pendekatan untuk sammarisasi. Dia sendiri dapat memutuskan pada langkah apa dia harus abstrak, dan pada langkah apa - penggalian. Bagaimana dia melakukannya, kita akan mencari tahu sekarang.
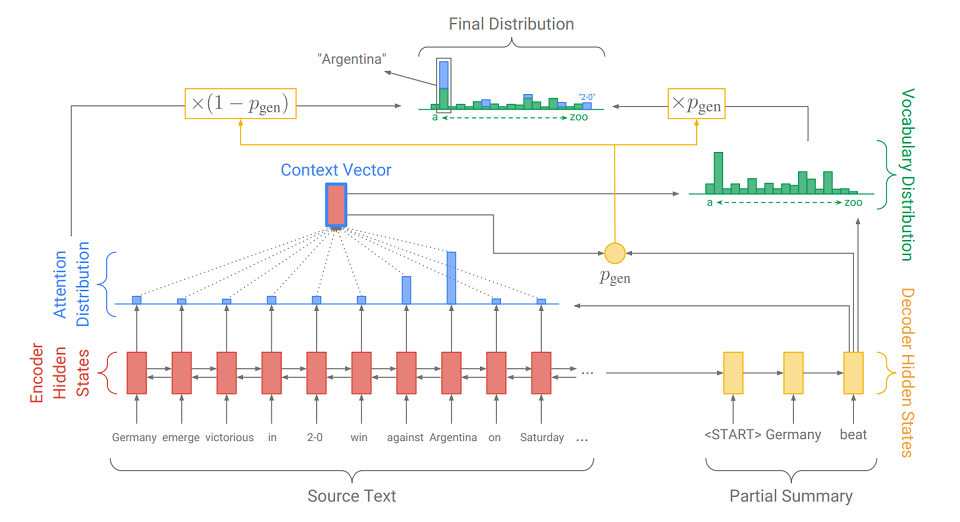
Perbedaan utama dari model seq2seq yang biasa adalah tindakan tambahan di mana p
gen dihitung - probabilitas generasi. Ini dilakukan dengan menggunakan status tersembunyi dari decoder dan vektor konteks. Arti tindakan tambahan itu sederhana. Semakin dekat p
gen ke 1, semakin besar kemungkinan bahwa model akan mengeluarkan kata dari kamusnya menggunakan generasi abstrak. Semakin dekat p
gen ke 0, semakin besar kemungkinan bahwa generator akan mengekstrak kata dari teks, dipandu oleh distribusi perhatian yang diperoleh sebelumnya. Distribusi probabilitas akhir dari hasil kata adalah jumlah dari distribusi probabilitas yang dihasilkan dari kata-kata (di mana tidak ada OOV) dikalikan dengan p
gen dan distribusi perhatian (di mana OOV, misalnya, "2-0" pada gambar) dikalikan dengan (1 - p
gen ).

Selain mekanisme penunjuk, artikel ini memperkenalkan
mekanisme peliputan , yang membantu menghindari pengulangan kata-kata. Saya juga bereksperimen dengan itu, tetapi tidak melihat peningkatan signifikan dalam kualitas judul - itu tidak benar-benar diperlukan. Kemungkinan besar, ini karena tugas spesifik: karena diperlukan untuk mengeluarkan sejumlah kecil kata-kata, generator tidak punya waktu untuk mengulang sendiri. Tetapi untuk tugas sammarisasi lainnya, misalnya, anotasi, ini bisa berguna. Jika tertarik, Anda bisa membacanya di
artikel asli.

Berbagai macam kata-kata Rusia
Cara lain untuk meningkatkan kualitas header output adalah dengan benar memproses urutan input. Selain pembuangan karakter huruf besar yang jelas, saya juga mencoba mengubah kata-kata dari teks sumber menjadi pasangan gaya dan infleksi (mis. Fondasi dan akhir). Untuk pemisahan, gunakan Porter Stemmer.
Kami menandai semua infleksi dengan simbol "+" di awal untuk membedakannya dari token lain. Kami menganggap setiap topik dan infleksi sebagai kata yang terpisah dan belajar dari mereka dengan cara yang sama seperti dalam kata-kata. Artinya, kita mendapatkan embeddings dari mereka dan memperoleh urutan (juga dipecah menjadi fondasi dan ujung) yang dapat dengan mudah diubah menjadi kata-kata.
Konversi semacam itu sangat berguna ketika bekerja dengan bahasa yang kaya secara morfologis seperti Rusia. Alih-alih menyusun kamus besar dengan berbagai macam bentuk kata Rusia, Anda dapat membatasi diri Anda pada sejumlah besar batang kata-kata ini (mereka beberapa kali lebih kecil dari jumlah bentuk kata) dan satu set akhir yang sangat kecil (saya mendapatkan banyak infleksi sebanyak 450). Dengan demikian, kami membuatnya lebih mudah bagi model untuk bekerja dengan "kekayaan" ini dan pada saat yang sama kami tidak menambah kompleksitas arsitektur dan jumlah parameter.

Saya juga mencoba menggunakan transformasi lemma + gramme. Yaitu, dari setiap kata sebelum diproses, Anda bisa mendapatkan bentuk awal dan makna tata bahasa menggunakan paket pymorphy (misalnya, "sudah"
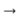
"Menjadi" dan "KATA KERJA | impf | masa lalu | sing | femn"). Jadi, saya mendapatkan sepasang urutan paralel (dalam satu - bentuk awal, yang lain - nilai-nilai tata bahasa). Untuk setiap jenis urutan, saya menyusun embeddings saya, yang kemudian saya gabungkan dan kirimkan ke saluran pipa yang dijelaskan sebelumnya. Di dalamnya, decoder tidak belajar mengeluarkan kata-kata, tetapi sebuah lemma dan tata bahasa. Tetapi sistem seperti itu tidak membawa perbaikan yang terlihat dibandingkan dengan pg pada topik. Mungkin itu adalah arsitektur yang terlalu sederhana untuk bekerja dengan nilai-nilai tata bahasa, dan layak membuat classifier terpisah untuk setiap kategori tata bahasa dalam output. Tetapi saya tidak bereksperimen dengan model yang demikian atau lebih rumit.
Saya bereksperimen dengan tambahan lain pada arsitektur asli dari pointer-generator, yang, bagaimanapun, tidak berlaku untuk preprocessing. Ini adalah peningkatan jumlah lapisan (hingga 3) dari jaringan rekursif dari encoder dan decoder. Meningkatkan kedalaman jaringan berulang dapat meningkatkan kualitas output, karena keadaan tersembunyi dari lapisan terakhir dapat berisi informasi tentang input yang jauh lebih lama daripada keadaan tersembunyi dari RNN lapisan tunggal. Ini membantu untuk memperhitungkan koneksi semantik yang diperluas kompleks antar elemen dari urutan input. Benar, ini memerlukan peningkatan yang signifikan dalam jumlah parameter model dan menyulitkan pembelajaran.

Eksperimen Header Generator
Semua percobaan saya pada generator judul dapat dibagi menjadi dua jenis: percobaan dengan artikel berita dan ayat. Saya akan memberi tahu Anda tentang mereka secara berurutan.
Eksperimen Berita
Ketika bekerja dengan berita, saya menggunakan model seperti seq2seq, pg, pg dengan batang dan infleksi - single-layer dan three-layer. Saya juga mempertimbangkan model yang bekerja dengan gram, tetapi semua yang ingin saya ceritakan tentangnya, sudah saya jelaskan di atas. Saya harus mengatakan segera bahwa semua pg yang dijelaskan dalam bagian ini menggunakan mekanisme pelapisan, walaupun pengaruhnya terhadap hasilnya diragukan (karena tanpanya tidak jauh lebih buruk).
Saya dilatih pada dataset RIA Novosti, yang disediakan oleh kantor berita Rossiya Segodnya untuk melakukan jalur pembuatan berita utama di konferensi Dialog. Dataset berisi 1.003.869 artikel berita yang diterbitkan dari Januari 2010 hingga Desember 2014.
Semua model yang dipelajari menggunakan embeddings yang sama (128), kosa kata (100k) dan status laten (256) dan dilatih untuk jumlah era yang sama. Oleh karena itu, hanya perubahan kualitatif dalam arsitektur atau preprocessing yang dapat mempengaruhi hasilnya.
Model yang disesuaikan untuk bekerja dengan teks yang sudah diproses memberikan hasil yang lebih baik daripada model yang bekerja dengan kata-kata. Pg tiga lapis yang menggunakan informasi tentang topik dan infleksi bekerja paling baik. Saat menggunakan pg apa pun, peningkatan yang diharapkan dalam kualitas header dibandingkan dengan seq2seq juga muncul, yang mengisyaratkan penggunaan pointer yang lebih disukai saat menghasilkan header. Berikut adalah contoh pengoperasian semua model:
Melihat header yang dihasilkan, kita dapat membedakan masalah berikut dari model yang diteliti:
- Model sering menggunakan bentuk kata yang tidak teratur. Model dengan batang (seperti pada contoh di atas) lebih lega dari kelemahan ini;
- Semua model, kecuali yang bekerja dengan tema, dapat menghasilkan header yang tampaknya tidak lengkap, atau desain aneh yang tidak ada dalam bahasa (seperti pada contoh di atas);
- Semua model yang dipelajari sering membingungkan orang yang dijelaskan, mengganti tanggal yang salah atau menggunakan kata-kata yang tidak cocok.


Eksperimen dengan ayat-ayat
Karena pg tiga lapis dengan tema memiliki ketidakakuratan paling sedikit dalam header yang dihasilkan, ini adalah model yang saya pilih untuk eksperimen dengan ayat. Saya mengajarinya tentang kasus ini, terdiri dari 6 juta puisi Rusia dari situs "stihi.ru". Mereka termasuk cinta (sekitar setengah dari ayat-ayat yang dikhususkan untuk topik ini), civic (sekitar seperempat), puisi urban dan lansekap. Periode penulisan: Januari 2014 - Mei 2019. Saya akan memberikan contoh judul yang dihasilkan untuk ayat:
Model itu ternyata sebagian besar mengekstraksi: hampir semua header adalah satu baris, sering diekstraksi dari bait pertama atau terakhir. Dalam kasus luar biasa, model dapat menghasilkan kata-kata yang tidak ada dalam puisi. Ini disebabkan oleh kenyataan bahwa sejumlah besar teks dalam kasus ini benar-benar memiliki salah satu baris sebagai sebuah nama.
Sebagai kesimpulan, saya akan mengatakan bahwa generator indeks, bekerja pada batang dan menggunakan decoder dan encoder single-layer, mengambil tempat kedua di jalur
kompetisi untuk menghasilkan berita utama untuk artikel berita pada konferensi dialog ilmiah pada linguistik komputer "Dialog". Penyelenggara utama konferensi ini adalah ABBYY, perusahaan ini terlibat dalam penelitian di hampir semua area modern Pengolahan Bahasa Alam.
Akhirnya, saya sarankan Anda sedikit interaktif: kirim berita di komentar, dan lihat tajuk apa yang akan dihasilkan oleh jaringan saraf untuknya.
Matvey, pengembang di NLP Group di ABBYY