Ketakutan operasi buffer membawa ...
Dengan menggunakan kueri kecil sebagai contoh, pertimbangkan beberapa pendekatan universal untuk mengoptimalkan kueri pada PostgreSQL. Apakah menggunakannya atau tidak, itu terserah Anda, tetapi ada baiknya Anda mengetahuinya.
Dalam beberapa versi PG masa depan, situasinya mungkin berubah dengan "kebijaksanaan" penjadwal, tetapi untuk 9.4 / 9.6 kelihatannya hampir sama, seperti contoh di sini.
Saya akan menerima permintaan yang sangat nyata:
SELECT TRUE FROM "" d INNER JOIN "" doc_ex USING("@") INNER JOIN "" t_doc ON t_doc."@" = d."" WHERE (d."3" = 19091 or d."" = 19091) AND d."$" IS NULL AND d."" IS NOT TRUE AND doc_ex.""[1] IS TRUE AND t_doc."" = '' LIMIT 1;
tentang nama-nama tabel dan bidangNama "Rusia" bidang dan tabel dapat diperlakukan berbeda, tetapi ini adalah masalah selera. Karena
kami tidak memiliki pengembang asing
di "Tensor" , dan PostgreSQL memungkinkan kami untuk memberi nama bahkan dengan hieroglif, jika mereka
terlampir dalam tanda kutip , kami lebih suka memberi nama objek secara jelas, jelas, sehingga tidak ada kesalahpahaman.
Mari kita lihat rencana yang dihasilkan:
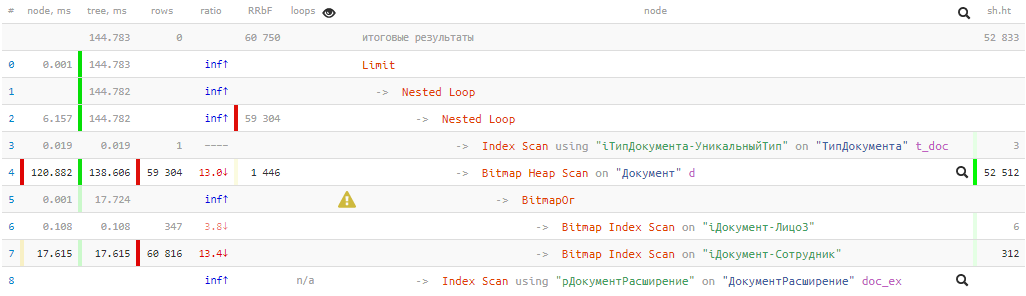 [lihat menjelaskan.tensor.ru]144ms dan hampir 53K buffer
[lihat menjelaskan.tensor.ru]144ms dan hampir 53K buffer - yaitu, lebih dari 400MB data! Dan kami beruntung jika semuanya ada dalam cache pada saat permintaan kami, jika tidak maka akan beberapa kali lebih lama ketika dikurangkan dari disk.
Algoritma itu paling penting!
Untuk mengoptimalkan permintaan apa pun, Anda harus terlebih dahulu memahami apa yang harus dilakukan.
Untuk saat ini, kami meninggalkan pengembangan struktur basis data di luar ruang lingkup artikel ini dan sepakat bahwa kami dapat secara relatif “murah”
menulis ulang kueri dan / atau memasukkan ke dalam basis data
indeks apa pun yang kami butuhkan.
Jadi permintaannya adalah:
- memeriksa keberadaan setidaknya beberapa dokumen
- dalam kondisi yang kita butuhkan dan jenis tertentu
- di mana penulis atau pelaksana adalah karyawan yang kita butuhkan
GABUNG + BATAS 1
Cukup sering, lebih mudah bagi pengembang untuk menulis kueri di mana, pada awalnya, sejumlah besar tabel digabungkan, dan kemudian dari seluruh rangkaian ini hanya ada satu catatan. Tetapi lebih mudah bagi pengembang - tidak berarti lebih efisien untuk database.
Dalam kasus kami, hanya ada 3 tabel - dan apa efeknya ...
Untuk memulai, mari singkirkan koneksi ke tabel "TypeDocument", dan pada saat yang sama beri tahu database bahwa
tipe record kita unik (kita tahu ini, tetapi scheduler tidak tahu):
WITH T AS ( SELECT "@" FROM "" WHERE "" = '' LIMIT 1 ) ... WHERE d."" = (TABLE T) ...
Ya, jika tabel / CTE terdiri dari satu bidang catatan tunggal, maka dalam PG Anda dapat menulis demikian, alih-alih
d."" = (SELECT "@" FROM T LIMIT 1)
Komputasi malas dalam kueri PostgreSQL
BitmapOr vs UNION
Dalam beberapa kasus, Bitmap Heap Scan akan menghabiskan banyak uang bagi kita - misalnya, dalam situasi kita, ketika catatan yang cukup jatuh dalam kondisi yang diperlukan. Kami mendapatkannya karena
kondisi OR, yang berubah menjadi operasi
BitmapOr dalam paket.
Mari kita kembali ke tugas semula - Anda perlu menemukan catatan yang cocok dengan
salah satu ketentuan - yaitu, tidak perlu mencari semua catatan 59K untuk kedua kondisi. Ada cara untuk menyelesaikan satu kondisi, dan
pergi ke kondisi kedua hanya ketika tidak ada yang ditemukan pada kondisi pertama . Desain ini akan membantu kami:
( SELECT ... LIMIT 1 ) UNION ALL ( SELECT ... LIMIT 1 ) LIMIT 1
"Eksternal" LIMIT 1 memastikan bahwa pencarian berakhir ketika catatan pertama ditemukan. Dan jika sudah di blok pertama, yang kedua tidak akan
dieksekusi (
tidak pernah dieksekusi dalam rencana).
"Bersembunyi di bawah KASUS" kondisi sulit
Ada saat yang sangat tidak nyaman dalam permintaan awal - memeriksa status menggunakan tabel yang ditautkan "Ekstensi Dokumen". Terlepas dari kebenaran kondisi yang tersisa dalam ekspresi (misalnya,
d. "Dihapus" TIDAK BENAR ), koneksi ini selalu dilakukan dan "bernilai sumber daya". Kurang lebih dari mereka akan dihabiskan - tergantung pada ukuran tabel ini.
Tetapi Anda dapat memodifikasi permintaan sehingga pencarian untuk catatan terkait hanya terjadi ketika benar-benar diperlukan:
SELECT ... FROM "" d WHERE ... AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END
Karena kami
tidak memerlukan bidang apa pun untuk hasil dari tabel tertaut, kami dapat mengubah GABUNGAN menjadi kondisi untuk subquery.
Kami meninggalkan bidang yang diindeks “di luar kurung” KASUS, kami menambahkan kondisi sederhana dari catatan ke blok KETIKA - dan sekarang kueri “berat” dijalankan hanya ketika beralih ke KEMUDIAN.
Nama belakang saya adalah "Total"
Kami mengumpulkan kueri yang dihasilkan dengan semua mekanisme yang dijelaskan di atas:
WITH T AS ( SELECT "@" FROM "" WHERE "" = '' ) ( SELECT TRUE FROM "" d WHERE ("3", "") = (19091, (TABLE T)) AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END LIMIT 1 ) UNION ALL ( SELECT TRUE FROM "" d WHERE ("", "") = ((TABLE T), 19091) AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END LIMIT 1 ) LIMIT 1;
Kustomisasi Indeks [Bawah]
Mata yang terlatih memperhatikan bahwa kondisi yang diindeks dalam subunit UNION sedikit berbeda - ini karena kami telah memiliki indeks yang sesuai pada tabel. Dan jika mereka tidak ada di sana, maka layak untuk dibuat:
Dokumen (Person3, Jenis Dokumen) dan
Dokumen (Jenis Dokumen, Karyawan) .
tentang urutan bidang dalam kondisi ROWDari sudut pandang perencana, tentu saja, Anda dapat menulis keduanya (A, B) = (constA, constB) , dan (B, A) = (constB, constA) . Tetapi ketika menulis dalam urutan bidang dalam indeks , permintaan seperti itu lebih mudah untuk di-debug nanti.
Apa rencananya?
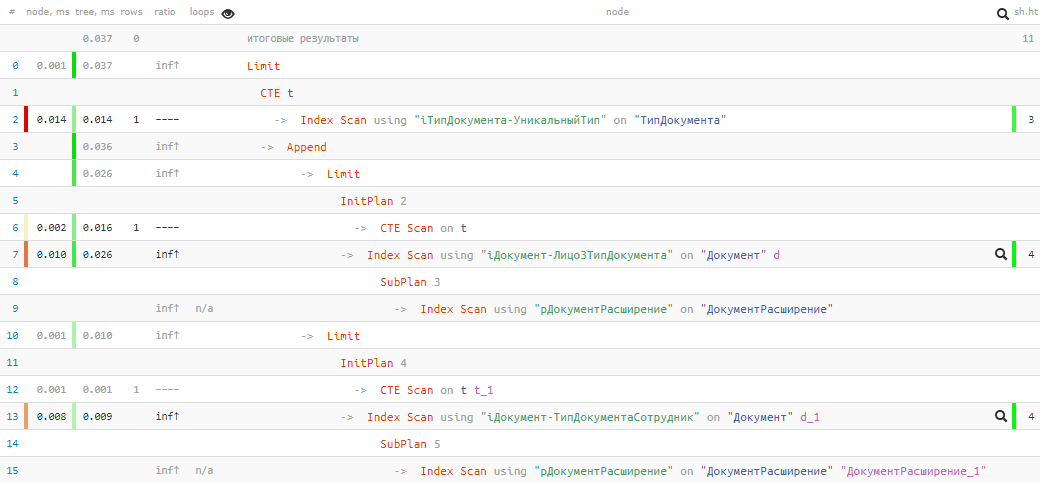 [lihat menjelaskan.tensor.ru]
[lihat menjelaskan.tensor.ru]Sayangnya, kami tidak beruntung, dan tidak ada yang ditemukan di blok UNION pertama, jadi yang kedua tetap pergi ke eksekusi. Namun demikian - hanya
0,037 ms dan 11 buffer !
Kami mempercepat permintaan dan mengurangi "pemompaan" data dalam memori
beberapa ribu kali , menggunakan metode yang cukup sederhana - hasil yang baik dengan copy-paste kecil. :)