Saat mengekstraksi informasi, tugas sering muncul untuk menemukan fragmen teks seperti itu. Dalam konteks pencarian, kueri dapat dihasilkan oleh pengguna (misalnya, teks yang dimasukkan pengguna di mesin pencari) atau oleh sistem itu sendiri. Seringkali kita perlu mencocokkan permintaan yang masuk dengan permintaan yang sudah diindeks. Pada artikel ini kita akan melihat bagaimana Anda dapat membangun sistem yang memecahkan masalah ini sehubungan dengan miliaran permintaan tanpa menghabiskan banyak uang pada infrastruktur server.
Pertama, kami mendefinisikan masalah secara formal:
Diberikan seperangkat pertanyaan tetap permintaan masuk dan integer . Perlu menemukan subset pertanyaan seperti itu R = \ kiri \ {q0, q1, ..., qk \ right \} \ subset Q untuk setiap permintaan lebih seperti dari permintaan lainnya di .
Misalnya, dengan rangkaian kueri ini
:
{tesla cybertruck, beginner bicycle gear, eggplant dishes, tesla new car, how expensive is cybertruck, vegetarian food, shimano 105 vs ultegra, building a carbon bike, zucchini recipes}
dan
Anda dapat mengharapkan hasil ini:
Harap perhatikan bahwa kami belum menetapkan kriteria
kesamaan . Dalam konteks ini, ini bisa berarti hampir apa saja, tetapi biasanya bermuara pada beberapa bentuk kesamaan berdasarkan kata kunci atau vektor. Menggunakan kesamaan berdasarkan kata kunci, kita dapat menemukan dua pertanyaan yang serupa jika mengandung cukup banyak kata-kata umum. Misalnya, pertanyaan "membuka restoran di munich" dan "restoran terbaik munich" serupa karena berisi kata-kata "restoran" dan "munich". Dan pertanyaan "restoran munich terbaik" dan "tempat makan di munich" sudah kurang mirip, karena mereka hanya memiliki satu kata umum. Namun, seseorang yang mencari restoran di Munich akan lebih baik jika pasangan permintaan kedua ternyata serupa. Dan dalam hal ini kami akan membantu perbandingan berdasarkan vektor.
Representasi vektor kata
Representasi vektor kata adalah teknik pembelajaran mesin yang digunakan dalam pemrosesan bahasa alami untuk mengubah teks atau kata menjadi vektor. Memindahkan tugas ke dalam ruang vektor, kita dapat menggunakan operasi matematika dengan vektor - menjumlahkan dan menghitung jarak. Untuk membuat tautan antara kata-kata yang mirip, Anda dapat menggunakan metode pengelompokan vektor tradisional.
Arti dari operasi ini dalam ruang kata aslinya mungkin tidak jelas, tetapi keuntungannya adalah bahwa sekarang kita memiliki akses ke berbagai alat matematika. Jika Anda tertarik pada detail tentang vektor kata dan aplikasinya, baca tentang
word2vec dan
GloVe .
Kami memiliki cara untuk menghasilkan vektor dari kata-kata, sekarang kami akan mengumpulkannya menjadi vektor teks (vektor dokumen atau ekspresi). Cara termudah untuk melakukan ini adalah dengan menambahkan (atau rata-rata) vektor semua kata dalam teks.
 Gambar 1: Vektor Kueri.
Gambar 1: Vektor Kueri.Sekarang Anda dapat menentukan kesamaan dua potongan teks (atau kueri) dengan merepresentasikannya dalam ruang vektor dan menghitung jarak antara vektor. Biasanya, jarak sudut digunakan untuk ini.
Akibatnya, representasi vektor kata memungkinkan pencocokan teks dari jenis yang berbeda, yang melengkapi pencocokan berbasis kata kunci. Anda dapat menjelajahi kesamaan semantik dari permintaan (misalnya, "restoran munich terbaik" dan "tempat makan di munich"), seperti yang tidak dapat kami lakukan sebelumnya.
Perkiraan Pencarian Tetangga Terdekat
Sekarang kita dapat memperbaiki masalah pencocokan kueri asli kami:
Diberi set vektor permintaan yang tetap vektor yang masuk dan integer . Anda perlu menemukan subset vektor seperti itu R = \ kiri \ {q0, q1, ..., qk \ right \} \ subset Q sehingga jarak sudut dari untuk setiap vektor lebih pendek dari jarak ke vektor lain di .
Ini disebut tugas menemukan tetangga terdekat. Ada
sejumlah algoritma untuk solusi cepatnya di ruang dimensi rendah. Tetapi ketika bekerja dengan representasi vektor dari kata-kata, kami biasanya beroperasi dengan vektor dimensi tinggi (100-1000 dimensi). Dan di sini metode yang disebutkan tidak lagi berfungsi.
Tidak ada cara yang cocok untuk dengan cepat menentukan tetangga terdekat dalam ruang dimensi tinggi. Oleh karena itu, kami menyederhanakan masalah dengan mengizinkan penggunaan hasil perkiraan: alih-alih selalu mengembalikan vektor terdekat, kami akan puas hanya dengan beberapa tetangga terdekat atau
sampai batas tertentu . Ini disebut perkiraan pencarian tugas tetangga terdekat dan merupakan area penelitian aktif.
Dunia kecil hirarkis
Grafik Hierarchical Navigable Small-World (
HNSW ) adalah salah satu algoritma tercepat untuk perkiraan pencarian tetangga terdekat. Indeks pencarian di HNSW adalah struktur multi-level di mana setiap level adalah grafik kedekatan. Setiap simpul grafik sesuai dengan salah satu vektor kueri.
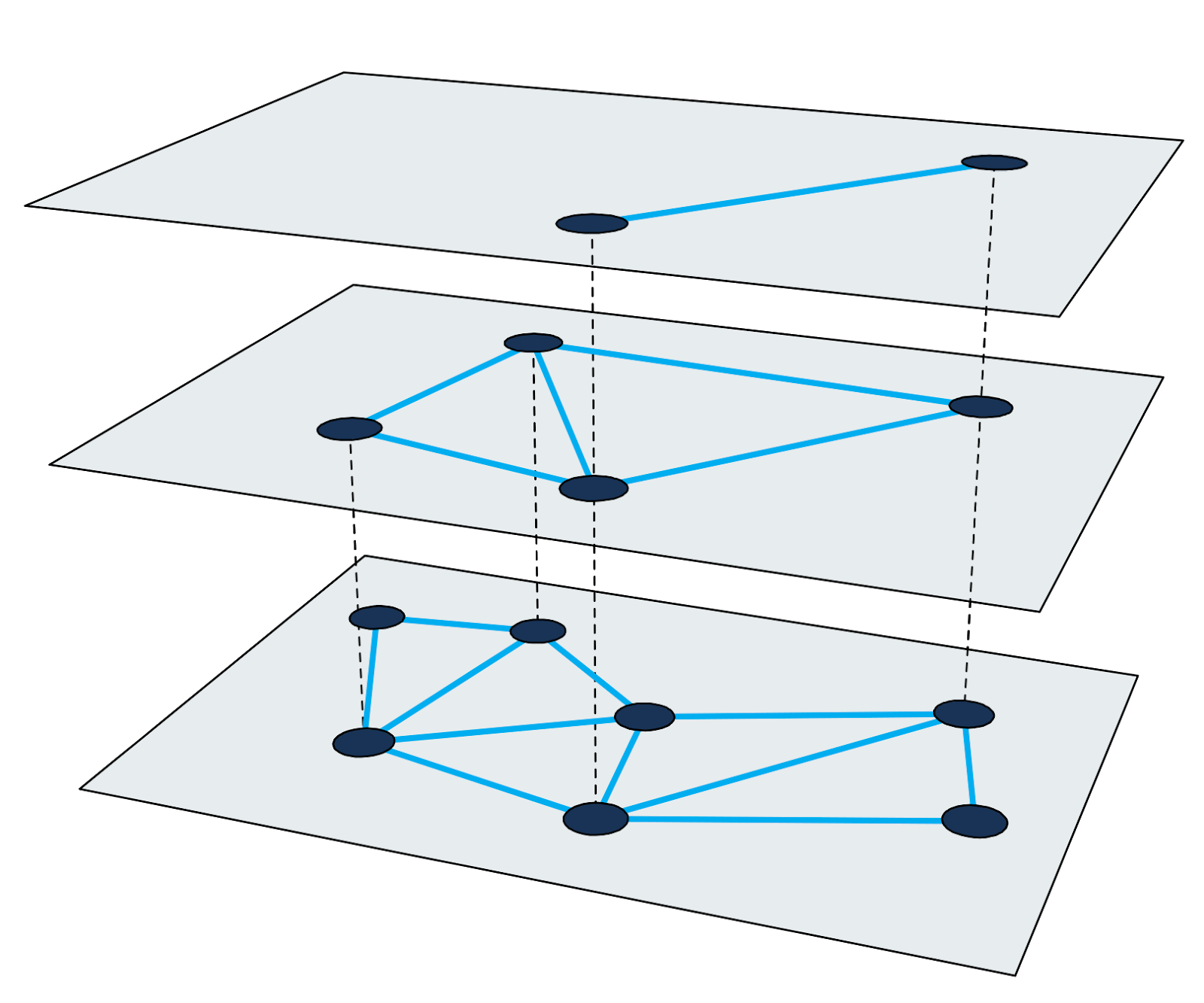 Gambar 2: Grafik kedekatan bertingkat.
Gambar 2: Grafik kedekatan bertingkat.Menemukan tetangga terdekat di HNSW menggunakan metode pembesaran. Ini dimulai pada simpul input dari level tertinggi dan secara rekursif melakukan traversal grafik serakah di setiap level hingga mencapai minimum lokal di bagian bawah.
Rincian tentang algoritma dan teknik pencarian dijelaskan dengan baik dalam karya ilmiah. Penting untuk diingat bahwa setiap siklus pencarian untuk tetangga terdekat terdiri dari melintasi node grafik dengan menghitung jarak antara vektor. Kami akan melihat langkah-langkah di bawah ini untuk menggunakan metode ini untuk membuat indeks skala besar.
Kesulitan mengindeks miliaran kueri
Misalkan kita perlu mengindeks 4 miliar vektor kueri 200-dimensi, dengan masing-masing dimensi diwakili oleh angka floating point empat byte (4 miliar cukup untuk membuat tugas menarik, tetapi Anda masih dapat menyimpan ID node dalam angka empat-byte reguler) . Perhitungan kasar memberitahu kita bahwa ukuran vektor saja akan sekitar 3 TB. Karena sebagian besar pustaka yang ada menggunakan kapasitas RAM untuk perkiraan pencarian tetangga terdekat, kami akan memerlukan server yang sangat besar untuk mendorong setidaknya vektor ke dalam RAM. Harap perhatikan bahwa ini tidak memperhitungkan indeks pencarian tambahan, yang diperlukan untuk sebagian besar metode.
Dalam seluruh sejarah pengembangan mesin pencari kami, kami telah menggunakan beberapa pendekatan berbeda untuk menyelesaikan masalah ini. Mari kita pertimbangkan beberapa di antaranya.
Subset data
Pendekatan pertama dan paling sederhana, yang tidak memungkinkan kami untuk sepenuhnya menyelesaikan masalah, adalah membatasi jumlah vektor dalam indeks. Mengambil sepersepuluh dari data, kami membuat indeks yang membutuhkan - kejutan - 10% dari memori. Namun, kualitas pencarian telah memburuk, karena sekarang kami telah beroperasi dengan kueri yang lebih sedikit.
Kuantisasi
Di sini kami menggunakan semua data, tetapi menguranginya menggunakan
kuantisasi (kami menggunakan teknik kuantisasi yang berbeda, misalnya, kuantisasi produk, tetapi tidak dapat mencapai kualitas kerja yang diinginkan dengan jumlah data ini). Dengan menyelesaikan beberapa kesalahan, kami dapat mengganti semua angka empat byte dalam vektor asli dengan versi byte tunggal yang dikuantisasi. Jumlah RAM untuk vektor menurun hingga 75%. Namun, kami masih membutuhkan memori 750 GB (belum termasuk ukuran indeks itu sendiri), dan ini masih merupakan server yang sangat besar.
Memecahkan masalah memori dengan Granne
Pendekatan yang dijelaskan memiliki kelebihan, tetapi membutuhkan banyak sumber daya dan memberikan kualitas pencarian yang buruk. Meskipun
ada perpustakaan yang merespons dalam waktu kurang dari 1 ms, kami dapat mengorbankan kecepatan dengan imbalan persyaratan perangkat keras yang lebih rendah.
Granne (perkiraan tetangga terdekat terdekat berbasis grafik) adalah perpustakaan HNSW yang dikembangkan dan digunakan oleh Cliqz untuk mencari pertanyaan semacam itu. Ini memiliki kode sumber terbuka, tetapi perpustakaan masih dalam pengembangan aktif. Versi yang ditingkatkan akan dipublikasikan di
crates.io pada tahun 2020. Itu ditulis dalam karat dengan sisipan Python, dirancang untuk menangani miliaran vektor menggunakan daya saing. Dari sudut pandang vektor kueri, menarik bahwa Granne memiliki mode khusus yang membutuhkan memori jauh lebih sedikit dibandingkan dengan perpustakaan lain.
Representasi ringkas dari vektor kueri
Mengurangi ukuran vektor kueri akan memberi kita banyak manfaat. Untuk melakukan ini, mari kembali dan pertimbangkan untuk membuat vektor. Karena kueri terdiri dari kata-kata, dan vektor kueri adalah jumlah vektor kata, kita dapat secara eksplisit menolak menyimpan vektor-vektor kueri dan menghitungnya seperlunya.
Anda bisa menyimpan kueri dalam bentuk kumpulan kata dan menggunakan tabel pencarian untuk menemukan vektor yang sesuai. Namun, kami menghindari pengalihan dengan menyimpan setiap kueri sebagai daftar ID integer yang sesuai dengan vektor kata dalam kueri. Misalnya, simpan kueri "restoran terbaik munich" sebagai
dimana
- ini adalah ID vektor dari kata "terbaik", dll. Misalkan kita memiliki kurang dari 16 juta vektor kata (lebih dari ini akan menelan biaya 1 byte per kata), maka Anda dapat menggunakan 3 byte untuk mewakili semua kata ID. Artinya, alih-alih menyimpan 800 byte (atau 200 byte dalam kasus vektor terkuantisasi), kami hanya akan menyimpan 12 byte untuk permintaan ini (Ini tidak sepenuhnya benar. Karena permintaan terdiri dari jumlah kata yang berbeda, kami juga perlu menyimpan daftar offset dalam indeks kata. Untuk ini akan membutuhkan 5 byte per permintaan).
Adapun kata vektor, kita semua membutuhkannya. Namun, jumlah kata jauh lebih kecil dari jumlah kueri yang dapat dibuat dengan menggabungkan kata-kata ini. Dan itu berarti ukuran kata tidak terlalu penting. Jika Anda menyimpan vektor kata sebagai versi titik apung empat byte dalam larik sederhana
, maka kita membutuhkan kurang dari 1 GB untuk setiap juta kata. Volume ini dapat dengan mudah masuk dalam RAM. Sekarang vektor kueri terlihat seperti ini:
{v _ {{i_ {best}}} + {v _ {{i_ {restaurant}}} + {v _ {{i_ {of}}} + {v _ {{i_ {munich}}}} .
Ukuran akhir pengiriman kueri tergantung pada jumlah total kata dalam kueri. Untuk 4 miliar kueri, ini sekitar 80 GB (termasuk vektor kata). Dengan kata lain, dibandingkan dengan vektor kata asli, ukurannya menurun sebesar 97%, dan dibandingkan dengan vektor terkuantisasi - sebesar 90%.
Dan satu hal lagi. Untuk satu pencarian, kita perlu mengunjungi sekitar 200-300 node grafik. Setiap node memiliki 20-30 tetangga. Jadi, kita perlu menghitung jarak dari vektor kueri input ke 4000-9000 vektor dalam indeks. Dan terlebih lagi, kita perlu menghasilkan vektor. Berapa lama untuk membuat vektor kueri dengan cepat?
Ternyata dengan prosesor yang cukup baru masalah ini dapat diselesaikan dalam beberapa milidetik. Permintaan yang dulu berjalan dalam 1 ms sekarang berjalan dalam sekitar 5 ms. Tapi kemudian kami mengurangi jumlah memori untuk vektor sebesar 90%. Kami dengan senang hati menerima kompromi seperti itu.
Tampilan dalam memori vektor dan indeks
Di atas, kami memecahkan masalah mengurangi jumlah memori untuk vektor. Tetapi setelah kami memecahkan masalah ini, struktur indeks itu sendiri menjadi faktor pembatas. Sekarang Anda perlu mengurangi ukurannya.
Di Granne, struktur grafik secara kompak disimpan dalam bentuk daftar adjacency dengan jumlah variabel tetangga untuk setiap node. Artinya, ingatan hampir tidak terbuang pada metadata. Ukuran struktur indeks sangat tergantung pada parameter desain dan properti grafik. Namun demikian, untuk mendapatkan gambaran tentang ukuran indeks, cukup untuk mengatakan bahwa kita dapat membangun indeks untuk 4 miliar vektor dengan ukuran total sekitar 240 GB. Ini mungkin dapat diterima untuk penggunaan dalam memori pada server besar, tetapi dapat dilakukan dengan lebih baik.
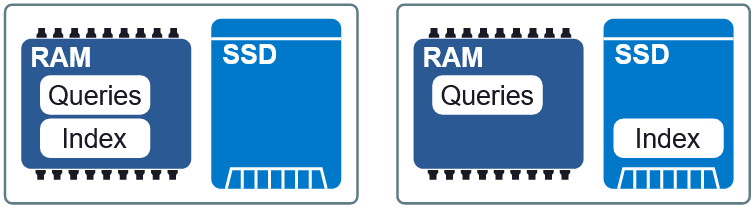 Gambar 3: Dua tata letak yang berbeda dalam RAM dan SSD.
Gambar 3: Dua tata letak yang berbeda dalam RAM dan SSD.Properti penting dari Granne adalah kemampuan untuk
menampilkan indeks dan permintaan vektor
dalam memori . Ini memungkinkan kita untuk memuat indeks dan berbagi memori dengan berbagai proses. File indeks dan kueri dibagi menjadi file tampilan terpisah dalam memori dan dapat digunakan dalam tata letak yang berbeda dalam RAM dan pada SSD. Jika persyaratan untuk penundaan sedikit lebih rendah, kemudian menempatkan indeks pada SSD, meminta RAM, kami mempertahankan kecepatan yang dapat diterima tanpa konsumsi memori yang berlebihan. Di akhir artikel kita akan melihat bagaimana kompromi ini terlihat.
Meningkatkan lokalitas data
Dalam konfigurasi kami saat ini, ketika indeks pada SSD, setiap permintaan memerlukan hingga 200-300 bacaan dari disk. Anda dapat mencoba meningkatkan lokalitas data dengan mengatur elemen-elemen yang vektornya sangat dekat sehingga node HNSW mereka terletak di indeks juga tidak jauh dari satu sama lain. Lokalitas data meningkatkan kinerja, karena operasi baca tunggal (biasanya diekstraksi dari 4 KB) lebih cenderung mengandung node lain yang diperlukan untuk melintasi grafik. Dan ini, pada gilirannya, mengurangi jumlah pengambilan data per satu pencarian.
 Gambar 4: Lokalitas data mengurangi pencarian informasi.
Gambar 4: Lokalitas data mengurangi pencarian informasi.Perlu dicatat bahwa penataan ulang elemen tidak mempengaruhi hasil pencarian, ini adalah cara untuk mempercepatnya. Artinya, urutannya bisa apa saja, tetapi tidak setiap opsi akan mempercepat pencarian. Sangat sulit untuk menemukan urutan yang optimal. Namun, heuristik yang berhasil kami gunakan adalah untuk mengurutkan kueri berdasarkan kata paling
penting dalam setiap kueri.
Kesimpulan
Kami menggunakan Granne untuk membuat dan memelihara indeks bernilai miliaran dolar dengan vektor kueri untuk mencari kueri serupa dengan konsumsi memori yang relatif rendah. Tabel di bawah ini menunjukkan persyaratan untuk berbagai metode. Jadilah skeptis tentang nilai absolut dari keterlambatan selama pencarian, karena mereka sangat bergantung pada apa yang dianggap sebagai respons yang dapat diterima. Namun, informasi ini menjelaskan kinerja relatif dari metode tersebut.
* Mengalokasikan indeks memori yang lebih besar dari jumlah yang diperlukan menyebabkan caching beberapa node (sering dikunjungi), yang mengurangi keterlambatan dalam pencarian. Tidak ada cache internal yang digunakan untuk ini, hanya alat OS internal (kernel Linux).Perlu dicatat bahwa beberapa optimasi yang disebutkan dalam artikel tidak dapat digunakan untuk menyelesaikan masalah umum menemukan tetangga terdekat dengan vektor yang tidak dapat dikomposasikan. Namun, mereka berlaku dalam situasi di mana elemen dapat dihasilkan dari bagian yang lebih sedikit (seperti halnya dengan kata-kata dan pertanyaan). Jika tidak, Anda masih dapat menggunakan Granne dengan vektor sumber, hanya membutuhkan lebih banyak memori, seperti perpustakaan lainnya.