Hai Habr!
Kredit Rumah adalah sistem besar dan sangat dinamis, yang terkadang sulit untuk dilacak. Untuk membantu karyawan mengikuti semua berita dan perubahan serta mengikuti perkembangan di mana-mana, kami secara aktif memperkenalkan algoritma pembelajaran mesin. Di Bank kami, obrolan bot sudah menjadi bagian dari pekerjaan operator, ulasan pelanggan dianalisis tidak hanya oleh para ahli, tetapi juga oleh algoritma cerdas untuk memproses bahasa alami.
Hari ini saya akan memberi tahu Anda bagaimana kami membantu spesialis operasi layanan perbankan menyingkirkan kebutuhan untuk terus melihat dasbor sistem pemantauan, yaitu, mereka meminta pembelajaran mesin untuk membantu. Itu yang kita dapat.

Bagaimana cara kerja pemantauan manual?
Tempat kerja tipikal dari spesialis operasi terlihat seperti pada gambar di atas, dan ia menghabiskan sebagian besar waktunya melihat dashboard. Setiap aktivitas mencurigakan dalam sistem, misalnya, ketika jaringan jatuh atau NullPointerException telah turun hujan, akan segera menarik perhatian - penyelidikan akan segera dimulai.
Manusia bukan mesin. Dia bisa terganggu, pergi makan malam, menjawab telepon. Dan ketika jumlah grafik melebihi seratus, menjadi sulit untuk mengikat mereka semua bersama dan sampai ke dasar esensi.
Masalah lain adalah bahwa ada keluarga kesalahan yang terjadi terus-menerus, tetapi tidak secara serius mempengaruhi perilaku sistem. Sebagai contoh, microservice pihak ketiga jatuh dan dashboard terguncang, tetapi kenyataannya sistem ini keluar dari bahaya. Sepintas, tidak selalu jelas bagaimana perilaku abnormal itu penting, dan apa yang ada di baliknya. Untuk menetapkan alasan secara rinci, Anda harus pergi ke server dan mempelajari log secara menyeluruh. Operasi semacam itu harus dilakukan puluhan kali sehari. Mari kita setidaknya sebagian mempercayakan dia ke mobil.
Pembelajaran mesin sebagai asisten yang cerdas
Ada tiga sumber utama data: Zabbix, ElasticSearch, dan sistem pemantauan metrik bisnis internal. Kami menggunakan Zabbix untuk memantau perangkat keras, jaringan, dan ketersediaan berbagai titik masuk ke dalam sistem. Menggunakan ElasticSearch, parsing dan ekstrak log pesan. Berbagai kesalahan, eksekusi, dan kueri digunakan sebagai metrik. Akan tetapi, analis bisnis memantau kinerja pengguna: jumlah transfer, penjualan, dan aktivitas bisnis lainnya. Data dikumpulkan pada frekuensi sekali per menit dan ditambahkan ke database. Nah, data dikumpulkan, saatnya untuk menulis sekelompok jika untuk belajar mesin dalam pertempuran.
Kami merumuskan masalah sebagai berikut: memiliki metrik sistem pada input, kami akan mengklasifikasikan status akhir sistem: reguler atau abnormal. Dalam pengaturan ini, masalahnya cocok dengan paradigma belajar dengan seorang guru. Ini berarti bahwa seluruh dataset pelatihan kami harus diberi label. Dengan kata lain, setiap menit operasi sistem harus memiliki label 0 (perilaku normal) atau -1 (perilaku tidak normal).
Dalam hidup, ternyata tidak semuanya semerah yang kita inginkan. Sebagai aturan, tidak semua insiden dicatat di JIRA, banyak yang tersisa di pos dan tidak melampauinya, dan kadang-kadang batas waktu anomali kabur atau tidak akurat. Ternyata membangun dataset berkualitas tinggi di bidang data historis bukanlah tugas sepele.
Sementara data baru baru saja mulai ditata, mari kita coba memeras manfaat dari apa yang sudah kita miliki. Untuk kasus di mana data tidak memiliki markup, metode pembelajaran tanpa guru digunakan. Kami akan melanjutkan dari fakta bahwa sebagian besar waktu sistem bekerja dengan benar, tetapi kadang-kadang peristiwa yang tidak terduga terjadi: bug (di mana tanpa mereka), pangkalan jatuh, atau, misalnya, excavator Petr menabrak kabel pusat data. Oleh karena itu, kami mengurangi tugas kami untuk mencari anomali, yaitu, mencari perilaku sistem baru (Deteksi Baru).
Untuk melakukan ini, gunakan algoritma Hutan Terisolasi. Itu sudah diterapkan di perpustakaan sklearn. Kami akan menggunakan metrik dari sistem pemantauan sebagai fitur.
clf = IsolationForest(behaviour='new', max_samples=100, random_state=rng, contamination='auto')
Kami akan melatih Hutan Terisolasi pada data historis, dan kami akan menggunakan data baru yang sudah kami tandai untuk menilai kualitas. Dengan demikian, tetap memilih model hyperparameters dan ukuran dataset untuk pelatihan.
Sekarang data status, yang dikumpulkan setiap menit, dimasukkan ke model yang terlatih dan mendapatkan label 0 atau -1.
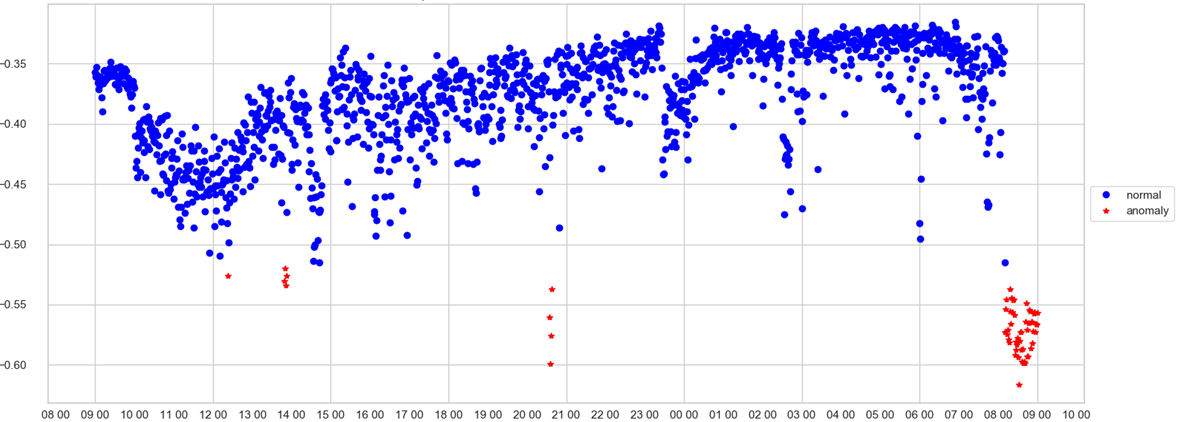
Operator hanya dapat melacak satu jadwal. Pada sumbu X - waktu, pada skor Y - anomali, yaitu, seberapa kuat model menganggap keadaan sistem pada menit ini tidak normal. Jika nilai kecepatan telah melewati trashhold (yang model pilih sendiri), titik berwarna merah dan anomali dicatat.
Sekarang kita belajar bahwa sistem beroperasi dalam mode yang tidak biasa atau bahwa situasi darurat terjadi hampir secara waktu nyata. Ini sangat bagus, tetapi bagaimana dengan operator pada saat menerima sinyal tentang anomali? Dasbor apa yang harus dilihat? Mari kita coba membuka "kotak hitam" model kita dan memahami bagaimana itu membuat keputusan.
Menafsirkan model menggunakan LIME
Ada beberapa pendekatan berbeda tentang cara membuka kotak hitam model yang terlatih dan memahami apa yang ada dalam pikiran mesin. Dengan regresi logistik atau pohon keputusan, semuanya jelas, tidak sulit untuk memahami atas dasar keputusan itu dibuat. Dengan Hutan Terisolasi, segalanya menjadi lebih rumit. Pertama, ada kecelakaan di dalam algoritma, dan kedua, itu adalah algoritma pembelajaran tanpa guru.
Kandidat pertama adalah perpustakaan LIME, yang menggunakan model agnostik pendekatan, yang membantu untuk menafsirkan model apa pun, hal utama adalah bahwa output model memiliki distribusi probabilistik di antara kelas-kelas. Oke, tentu saja, hasilnya bukan probabilitas, tetapi segera, tetapi mari kita coba menormalkannya dalam kisaran dari 0 hingga 1 dan memperlakukannya sebagai probabilitas. Dengan demikian, kami dapat memberikan format input yang kompatibel dengan LIME.
Cara LIME menafsirkan hasil itu mengecewakan. Pertama, sebagai interpretasi, ada beberapa tanda paling penting pada output, dan, dalam kebanyakan kasus, hanya satu dari mereka yang benar-benar mencerminkan esensi keputusan, sisanya menambahkan suara. Kelemahan kedua adalah bahwa interpretasinya tidak stabil dan sering menghasilkan daftar tanda yang berbeda dari lari ke lari. Untuk mendapatkan hasil yang lebih stabil, Anda harus menjalankan interpretasi beberapa kali dan hasilnya rata-rata. Saya tidak benar-benar ingin melakukan ini.
SHAP - jembatan dari orang ke mobil
Setelah itu, mata kami tertuju pada perpustakaan lain untuk interpretasi model - SHAP. Ide di balik perpustakaan berasal dari teori permainan. Perpustakaan juga memiliki visualisasi yang indah. Setelah melihat contoh-contohnya, kami menyadari dengan frustrasi bahwa SHAP tidak dapat menafsirkan Hutan Terisolasi, dan kami benar-benar ingin! Namun, di sisi lain, SHAP dengan percaya diri dapat membedah XGBoost. Kami berpikir, bagaimana jika kami diajari untuk melakukan XGBoost hal yang sama yang dapat dilakukan oleh Hutan Terisolasi? Untuk melakukan ini, kami mengambil seluruh dataset kami dan menandainya dengan Hutan Terisolasi. Selain itu, sebagai target mereka tidak mengambil kelas, tetapi skor, yang ditugaskan ke Hutan Terisolasi. Kami akan memprediksi dengan semua metrik kecepatan yang akan diberikan Hutan Terisolasi, tetapi hanya dengan XGBoot! Tidak lebih cepat dikatakan daripada dilakukan. Kami akan menjalankan dataset yang ditandai melalui XGBoost. Dan sekarang, sekarang dia tahu bagaimana memprediksi kecepatan dengan cara yang sama seperti Hutan Terisolasi. Hore, sekarang kita bisa menggunakan SHAP!
Langkah pertama adalah membuat objek TreeExplainer, melewati model itu sendiri sebagai parameter. Selanjutnya, nilai shap dihitung, yang memungkinkan kami untuk memberikan penjelasan tentang bagaimana model membuat keputusan ini atau itu.
explainer = shap.TreeExplainer(model) shap_values = explainer.shap_values(X)
SHAP memungkinkan Anda untuk menafsirkan model sebagai keseluruhan dan hasil untuk contoh-contoh spesifik. Misalnya, Anda bisa mendapatkan penjelasan untuk contoh tertentu menggunakan metode force_plot (), yang menerima nilai input dan nilai-nilai contoh itu sendiri.
shap.force_plot(explainer.expected_value,shap_values[0,:], X.iloc[0,:])
Ternyata grafik berikut, yang menampilkan fitur mana dari model dan seberapa besar mempengaruhi keputusan.

Kami membantu bisnis
Sekarang, mengetahui metrik mana yang memberikan kontribusi signifikan terhadap tingkat kelainan keseluruhan, menjadi mungkin untuk menentukan pada tingkat apa masalah muncul, dan yang paling penting apakah itu berdampak pada pengguna akhir sistem.

Setiap kali anomali terdeteksi, daftar metrik yang memiliki dampak terbesar pada keputusan diperoleh. Jika daftar menyertakan metrik yang secara langsung melacak indikator yang terkait dengan bisnis, ini disebutkan dalam peringatan dengan cara khusus, sehingga secara otomatis meningkatkan prioritas anomali.
Ini hanya langkah pertama tetapi penting dalam memperkuat dan mengotomatisasi sistem pemantauan menggunakan pembelajaran mesin, yang secara signifikan dapat meningkatkan kecepatan mengidentifikasi penyebab dan pengaruh perilaku sistem yang abnormal.
Referensi:scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.htmlgithub.com/marcotcr/limegithub.com/slundberg/shap