 Sumber
SumberHalo, Habr! Nama saya Maxim Pchelin, dan saya memimpin pengembangan BI-DWH di MyGames (divisi permainan dari Mail.ru Group). Pada artikel ini saya akan berbicara tentang bagaimana dan mengapa kami membangun penyimpanan DataLake yang berorientasi klien.
Artikel ini terdiri dari tiga bagian. Pertama, saya akan menjelaskan mengapa kami memutuskan untuk mengimplementasikan DataLake. Pada bagian kedua saya akan menjelaskan teknologi dan solusi apa yang kami gunakan sehingga penyimpanan dapat bekerja dan diisi dengan data. Dan pada bagian ketiga saya akan menjelaskan apa yang kami lakukan untuk meningkatkan kualitas layanan kami.
Apa yang membawa kami ke DataLake
Kami di
MyGames bekerja di departemen BI-DWH dan membuat layanan dari dua kategori: repositori untuk analis data dan layanan pelaporan reguler untuk pengguna bisnis (manajer, pemasar, pengembang game, dan lainnya).
Mengapa penyimpanan non-standar seperti itu?
Biasanya, BI-DWH tidak menyiratkan implementasi penyimpanan DataLake, ini tidak bisa disebut solusi khas. Dan bagaimana layanan seperti itu dibangun?
Biasanya perusahaan memiliki proyek - dalam kasus kami, ini adalah permainan. Proyek ini memiliki sistem logging yang paling sering menulis data ke database. Di atas dasar ini, etalase dibuat untuk agregat, metrik, dan entitas lain untuk analitik mendatang. Pelaporan rutin dibuat berdasarkan etalase menggunakan alat BI yang cocok, serta sistem analitik Ad-Hoc, dimulai dengan pertanyaan SQL sederhana dan tabel Excel, dan berakhir dengan Jupyter Notebook untuk DS dan ML. Seluruh sistem didukung oleh satu tim pengembangan.
Misalkan perusahaan lain lahir di sebuah perusahaan. Memiliki tim pengembangan dan infrastruktur lain di bawahnya menarik, tetapi mahal. Jadi, proyek ini perlu "dihubungkan". Ini dapat dilakukan dengan berbagai cara: di tingkat basis data, di tingkat etalase, atau setidaknya di tingkat tampilan - masalah terpecahkan.
Dan jika perusahaan memiliki proyek ketiga? “Berbagi” mungkin sudah berakhir buruk: mungkin ada masalah dengan alokasi sumber daya atau hak akses. Misalnya, salah satu proyek dilakukan oleh tim eksternal yang tidak perlu tahu apa-apa tentang dua proyek pertama. Situasi menjadi lebih berisiko.
Sekarang bayangkan bahwa tidak ada tiga proyek, tetapi lebih dari itu. Dan kebetulan inilah kasus kami.
MyGames adalah salah satu divisi terbesar dari Grup Mail.ru, kami memiliki 150 proyek dalam portofolio kami. Selain itu, mereka semua sangat berbeda: pengembangan mereka sendiri dan dibeli untuk operasi di Rusia. Mereka bekerja pada berbagai platform: PC, Xbox, Playstation, iOS dan Android. Proyek-proyek ini dikembangkan di sepuluh kantor di seluruh dunia dengan ratusan pembuat keputusan.

Untuk bisnis, ini hebat, tetapi menyulitkan tugas untuk tim BI-DWH.
Dalam permainan kami, banyak aksi pemain dicatat: ketika dia memasuki permainan, di mana dan bagaimana dia mendapatkan level, dengan siapa dan seberapa sukses dia bertarung, apa dan untuk mata uang apa yang dia beli. Kami perlu mengumpulkan semua data ini untuk setiap game.
Kami membutuhkan ini sehingga bisnis dapat menerima jawaban atas pertanyaannya tentang proyek. Apa yang terjadi minggu lalu setelah peluncuran aksi? Apa perkiraan kami untuk pendapatan atau penggunaan kapasitas server game untuk bulan berikutnya? Apa yang bisa dilakukan untuk memengaruhi ramalan ini?
Adalah penting bahwa MyGames tidak memaksakan paradigma pembangunan pada proyek. Setiap studio game mencatat data yang dianggap lebih efisien. Beberapa proyek menghasilkan log di sisi klien, beberapa di sisi server. Beberapa proyek menggunakan RDBMS untuk mengumpulkannya, sementara yang lain menggunakan alat yang sama sekali berbeda: Kafka, Elasticsearch, Hadoop, Tarantool atau Redis. Dan kita beralih ke sumber data ini untuk mengunggahnya ke repositori.
Apa yang Anda inginkan dari BI-DWH kami?
Pertama-tama, dari departemen BI-DWH mereka ingin menerima data pada semua game kami untuk menyelesaikan tugas operasional harian dan yang strategis. Mulai dari berapa banyak nyawa untuk memberikan monster yang mengerikan di akhir level, dan diakhiri dengan cara mendistribusikan sumber daya dengan baik dalam perusahaan: proyek mana yang harus memberi lebih banyak pengembang atau siapa yang harus mengalokasikan anggaran pemasaran.
Keandalan juga diharapkan dari kami. Kami bekerja di sebuah perusahaan besar dan tidak bisa hidup dengan prinsip "Kemarin kami bekerja, tapi hari ini sistemnya sudah ada, dan itu hanya akan naik dalam seminggu jika kami menemukan sesuatu."
Mereka menginginkan penghematan dari kita. Kami akan dengan senang hati menyelesaikan semua masalah dengan membeli besi atau mempekerjakan orang. Tetapi kami adalah organisasi komersial dan tidak mampu membelinya. Kami mencoba membuat keuntungan perusahaan.
Yang penting, mereka menginginkan fokus pelanggan dari kami. Klien dalam hal ini adalah konsumen kami, pelanggan: manajer, analis, dll. Kami harus beradaptasi dengan permainan kami dan bekerja sedemikian rupa sehingga nyaman bagi pelanggan untuk bekerja sama dengan kami. Sebagai contoh, dalam beberapa kasus, ketika kita membeli proyek di pasar Asia untuk operasi, bersama dengan permainan kita bisa mendapatkan pangkalan dengan nama dalam bahasa Cina. Dan dokumentasi untuk pangkalan-pangkalan ini dalam bahasa Mandarin. Kita bisa mencari pengembang ETL dengan pengetahuan bahasa Cina atau menolak untuk mengunduh data pada permainan, tetapi sebaliknya, tim dan saya mengunci diri di ruang rapat, mengambil waktu dan mulai bermain. Masuk dan keluar dari game, beli, tembak, mati. Dan kita melihat, apa dan kapan muncul di tabel ini atau itu. Kemudian kami menulis dokumentasi dan atas dasar itu kami membangun ETL.
Dalam hal ini, penting untuk merasakan ujungnya. Menggali permainan unik logging dengan DAU 50 orang, ketika Anda perlu membantu proyek dengan DAU 500.000 di dekatnya, adalah kemewahan yang tidak dapat diterima. Jadi, tentu saja, kita dapat menghabiskan banyak upaya untuk membangun solusi khusus, tetapi hanya jika bisnis benar-benar membutuhkannya.
Namun, begitu pengembang, terutama pemula, mendengar bahwa mereka harus beradaptasi dengan cara ini, mereka memiliki keinginan untuk tidak pernah melakukan itu. Setiap pengembang ingin membuat arsitektur yang ideal, tidak pernah mengubahnya dan menulis artikel tentang itu di Habr.
Tetapi apa yang terjadi jika kita berhenti menyesuaikan diri dengan permainan kita? Misalkan kita mulai meminta mereka untuk mengirim data ke satu input API? Hasilnya akan menjadi satu - semua orang akan mulai menyebar.
- Beberapa proyek akan mulai memotong solusi BI-DWH mereka, dengan preferensi dan penyair. Ini akan menyebabkan duplikasi sumber daya dan kesulitan dalam pertukaran data antar sistem.
- Proyek-proyek lain tidak akan menarik pembuatan BI-DWH mereka, tetapi mereka juga tidak ingin beradaptasi dengan proyek kami. Dan yang lain akan berhenti menggunakan data, yang bahkan lebih buruk.
- Baik dan yang paling penting, manajemen tidak akan memiliki informasi sistematis terkini tentang apa yang terjadi dalam proyek.
Bisakah kita menerapkan penyimpanan dengan cara yang sederhana?
150 proyek banyak. Untuk mengimplementasikan solusi segera untuk semuanya terlalu lama. Bisnis tidak akan menunggu satu tahun untuk hasil pertama muncul. Oleh karena itu, kami mengambil 3 proyek yang menghasilkan pendapatan maksimum, dan mengimplementasikan prototipe pertama untuk mereka. Kami ingin mengumpulkan data utama darinya dan membuat dasbor dasar dengan metrik paling populer - DAU, MAU, Pendapatan, registrasi, retensi, serta sedikit ekonomi dan prakiraan.
Kami tidak dapat menggunakan basis permainan dari proyek itu sendiri untuk ini. Pertama, ini akan membuat analisis lintas-desain lebih sulit karena kebutuhan untuk mengumpulkan data dari beberapa basis data. Kedua, permainan itu sendiri bekerja di atas database ini, yang penting agar master dan replika tidak kelebihan beban. Akhirnya, semua game pada suatu titik menghapus semua riwayat data yang tidak mereka butuhkan dalam database mereka, yang tidak dapat diterima untuk analitik.
Karena itu, satu-satunya pilihan adalah mengumpulkan semua yang Anda butuhkan untuk analisis di satu tempat. Pada titik ini, setiap basis data relasional atau repositori teks biasa cocok untuk kita. Kami akan mengacaukan BI dan membangun dasbor. Ada banyak opsi untuk kombinasi solusi tersebut:

Tapi kami mengerti bahwa nanti kami harus mencakup semua 150 pertandingan lainnya. Mungkin beberapa basis data relasional cluster dapat menangani jumlah data yang dihasilkan. Tetapi sumber tidak hanya terletak di sistem yang sama sekali berbeda, tetapi juga memiliki struktur data yang sangat berbeda. Kami bertemu dengan struktur relasional, Data Vault, dan lainnya. Ini tidak akan berhasil untuk menempatkan semua ini dalam satu database tanpa trik yang rumit dan melelahkan.
Semua ini membuat kami mengerti bahwa kami perlu membangun DataLake.
Implementasi DataLake
Pertama-tama, penyimpanan DataLake cocok untuk kondisi kami, karena memungkinkan kami untuk menyimpan data yang tidak terstruktur. DataLake dapat menjadi titik masuk tunggal untuk semua sumber yang beragam, dari tabel dari RDBMS ke JSON, yang kami kirimkan dari Kafka atau Mongo. Akibatnya, DataLake dapat menjadi dasar untuk analitik desain-silang yang diimplementasikan berdasarkan antarmuka untuk berbagai konsumen: SQL, Python, R, Spark dan sebagainya.
Beralih ke Hadoop
Untuk DataLake, kami memilih solusi yang jelas - Hadoop. Secara khusus, perakitannya dari Cloudera. Hadoop memungkinkan Anda untuk bekerja dengan data yang tidak terstruktur dan mudah diskalakan dengan menambahkan node data. Selain itu, produk ini telah dipelajari dengan baik, sehingga jawaban atas pertanyaan apa pun dapat ditemukan di Stackoverflow, dan tidak menghabiskan sumber daya untuk R&D.
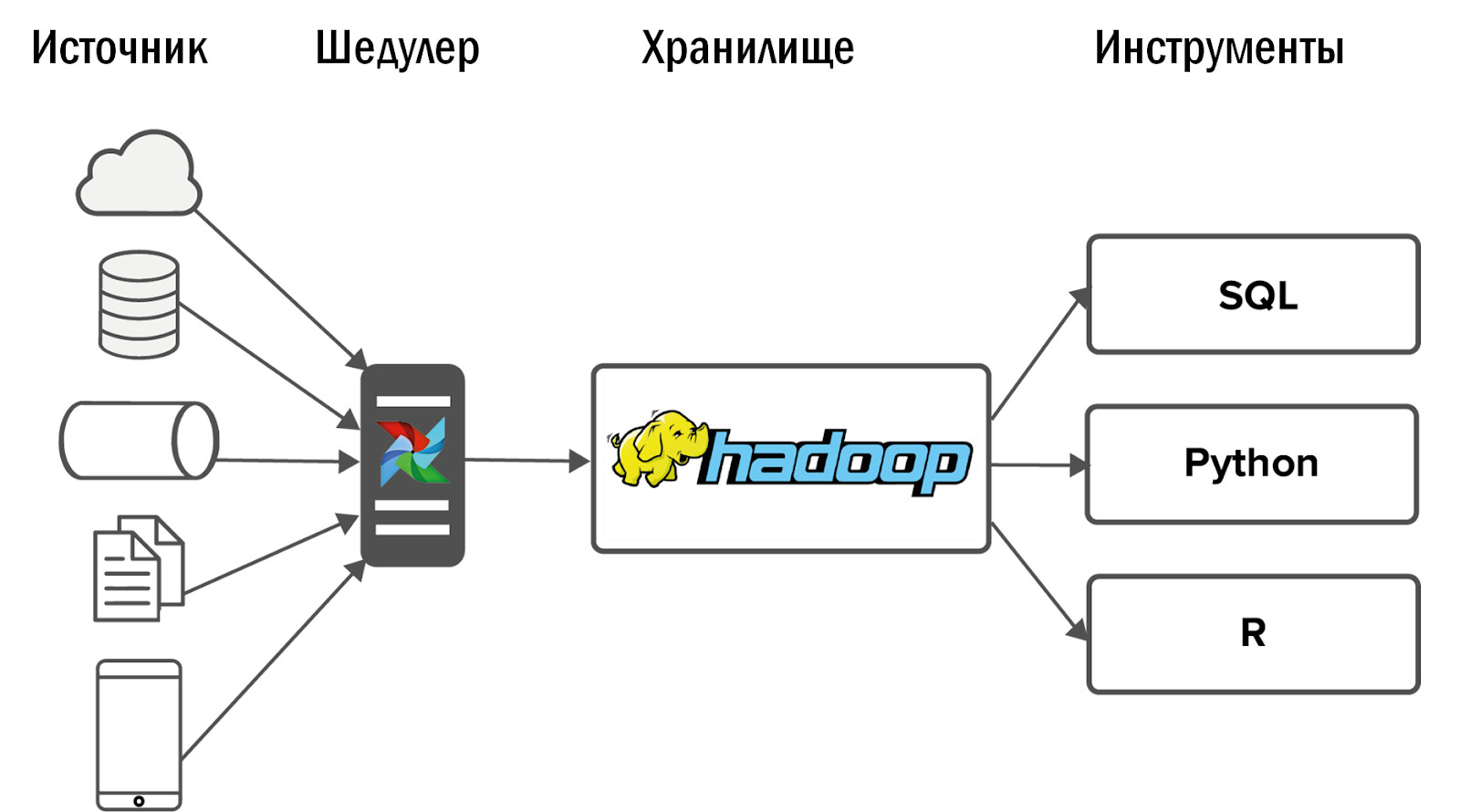
Setelah menerapkan Hadoop, kami mendapatkan diagram berikut dari penyimpanan terpadu pertama kami:

Data dikumpulkan ke Hadoop dari sejumlah kecil sumber, dan kemudian beberapa antarmuka diadu di dalamnya: alat dan layanan BI untuk analitik Ad-Hoc.
Peristiwa lebih lanjut berkembang secara tak terduga: Hadoop kami mulai dengan sempurna, dan konsumen yang datanya mengalir ke toko meninggalkan sistem analisis lama dan mulai menggunakan produk baru setiap hari untuk pekerjaan mereka.
Tetapi muncul masalah: semakin banyak Anda lakukan, semakin banyak yang mereka inginkan dari Anda. Dengan sangat cepat, proyek-proyek yang sudah terintegrasi ke Hadoop mulai meminta lebih banyak data. Dan proyek-proyek yang belum ditambahkan, mulai memintanya. Persyaratan stabilitas mulai tumbuh dengan tajam.
Pada saat yang sama, tidak masuk akal untuk hanya meningkatkan tim secara linear. Jika dua pengembang DWH mengatasi dua proyek, maka untuk empat proyek kami tidak dapat mempekerjakan dua pengembang lagi. Karena itu, pertama-tama kami pergi ke arah yang lain.
Proses pendirian
Dengan sumber daya terbatas, solusi termurah adalah menyesuaikan proses. Selain itu, di perusahaan besar tidak mungkin untuk hanya datang dengan arsitektur penyimpanan dan mengimplementasikannya. Harus bernegosiasi dengan sejumlah besar orang.
- Pertama-tama, dengan perwakilan bisnis yang mengalokasikan sumber daya untuk analitik. Anda harus membuktikan bahwa Anda hanya perlu mengimplementasikan tugas-tugas dari pelanggan Anda yang akan menguntungkan bisnis.
- Anda juga perlu bernegosiasi dengan analis sehingga mereka memberi Anda sesuatu sebagai imbalan atas layanan yang Anda berikan kepada mereka - analisis sistem, analisis bisnis, pengujian. Sebagai contoh, kami memberikan analisis sistem sumber data kami kepada analis. Tentu saja, mereka tidak bahagia, tetapi jika tidak maka tidak akan ada orang yang melakukannya.
- Last but not least, Anda harus bernegosiasi dengan pengembang game: pasang SLA dan setujui struktur data. Jika bidang terus-menerus menghilang, muncul dan berganti nama, maka tidak peduli ukuran tim, Anda akan selalu merindukan tangan Anda.
- Anda juga perlu bernegosiasi dengan tim Anda sendiri: mencari kompromi antara solusi ideal yang ingin dibuat semua pengembang, dan solusi standar yang tidak begitu menarik, tetapi yang dapat dipaku dengan murah dan cepat.
- Penting untuk menyetujui dengan administrator tentang pemantauan infrastruktur. Meskipun, segera setelah Anda memiliki sumber daya tambahan, lebih baik untuk menyewa spesialis DevOps Anda sendiri dalam tim penyimpanan.
Pada titik ini, saya bisa menyelesaikan artikel jika versi repositori seperti itu akan memenuhi semua tujuan yang ditetapkan untuk itu. Tapi ini tidak benar. Mengapa
Sebelum Hadoop, kami dapat menyediakan data dan statistik untuk lima proyek. Dengan implementasi Hadoop dan tanpa peningkatan tim, kami dapat mencakup 10 proyek. Setelah menetapkan proses, tim kami telah melayani 15 proyek. Ini keren, tapi kami punya 150 proyek. Kami butuh sesuatu yang baru.
Implementasi aliran udara
Awalnya, kami mengumpulkan data dari sumber menggunakan Cron. Dua proyek normal. 10 - sakit, tapi ok. Namun, sekarang sekitar 12 ribu proses dimuat setiap hari untuk memuat dari 150 proyek ke DataLake. Cron tidak lagi cocok. Untuk melakukan ini, kita memerlukan alat yang ampuh untuk mengelola aliran unduhan data.
Kami memilih Pengelola Tugas Aliran Udara sumber terbuka. Ia lahir di usus Airbnb, setelah itu ia dipindahkan ke Apache. Ini adalah alat untuk ETL berbasis kode. Artinya, Anda menulis skrip dengan Python, dan itu dikonversi ke DAG (grafik asiklik langsung). DAG sangat bagus untuk menjaga dependensi antar tugas - Anda tidak dapat membangun etalase menggunakan data yang belum dimuat.
Airflow memiliki penangan kesalahan yang hebat. Jika suatu proses macet atau ada masalah dengan jaringan, operator mengirim ulang proses berapa kali Anda tentukan. Jika ada banyak kegagalan, misalnya, tabel di sumber telah berubah, maka pesan pemberitahuan tiba.
Airflow memiliki UI yang hebat: ini menampilkan dengan mudah proses mana yang sedang berjalan, mana yang telah berhasil diselesaikan atau dengan kesalahan. Jika tugas mengalami kesalahan, Anda dapat memulai kembali dari antarmuka dan mengontrol proses melalui pemantauan tanpa masuk ke dalam kode.
Aliran Udara yang Dapat Disesuaikan, dibangun di atas operator - ini adalah plugin untuk bekerja dengan sumber tertentu. Beberapa operator keluar dari kotak, banyak yang menulis komunitas Airflow. Jika mau, Anda dapat membuat operator sendiri, antarmuka untuk ini sangat sederhana.
Bagaimana kita menggunakan aliran udara?
Sebagai contoh, kita perlu memuat tabel dari PostgreSQL ke Hadoop. Tugas
sql_sensor_battle_log memeriksa untuk melihat apakah sumber memiliki data yang kami butuhkan untuk kemarin. Jika demikian, tugas
load_stg_data_from_battle_log data dari PG dan menambahkannya ke Hadoop. Akhirnya,
load_oda_data_from_battle_log melakukan pemrosesan awal: katakanlah, mengubah dari Unix Time ke waktu yang dapat dibaca manusia.
Dalam rantai tugas seperti itu, data diambil dari satu entitas dalam satu sumber:

Jadi - dari semua entitas yang kita butuhkan dari satu sumber:
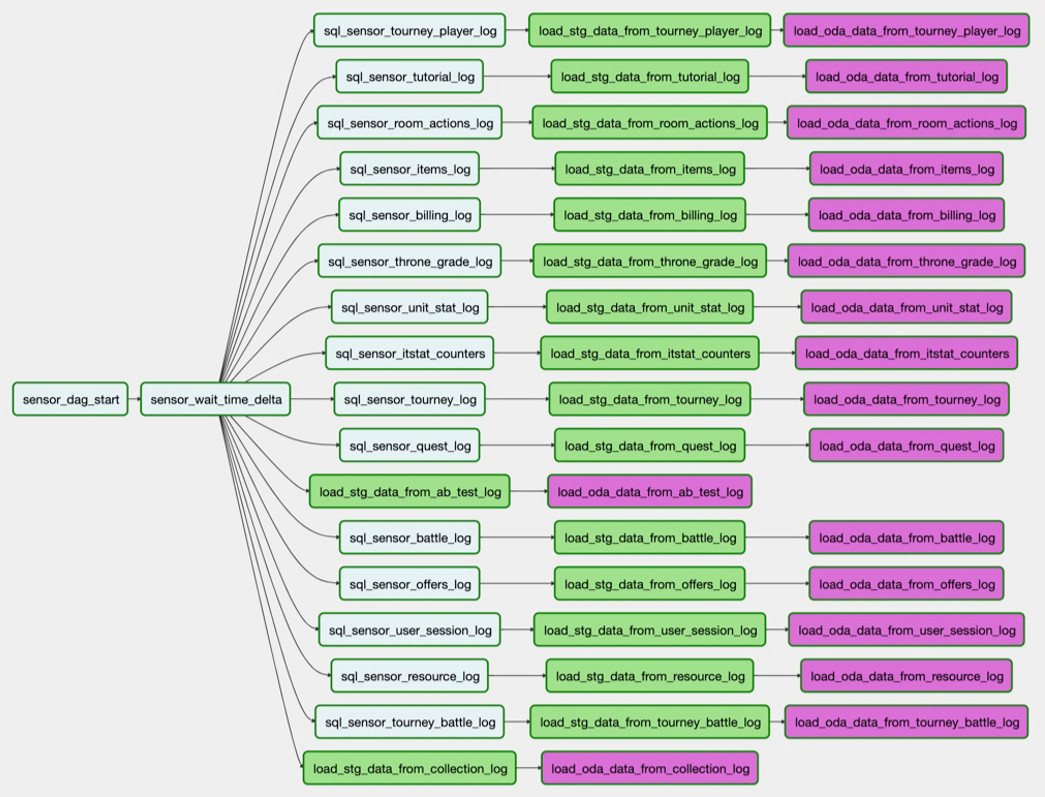
Kumpulan unduhan ini adalah DAG. Dan saat ini kami memiliki 250 DAG untuk memuat data mentah, memproses, mengubah dan membuat etalase di dalamnya.
Skema penyimpanan terpadu yang diperbarui adalah sebagai berikut:
- Setelah pengenalan Airflow, kami mampu meningkatkan jumlah sumber yang tajam - hingga 400 buah. Sumber data adalah internal (dari game kami) dan eksternal: sistem statistik yang dibeli, API heterogen. Airflow-lah yang memungkinkan kita untuk mengeksekusi dan mengendalikan 12 ribu proses setiap hari yang memproses data dari 150 game kita.
- Secara lebih rinci tentang Aliran Udara kami, Dean Safina menulis dalam artikelnya ( https://habr.com/ru/company/mailru/blog/344398/ ). Dan juga bergabung dengan komunitas Airflow di Telegram ( https://t.me/ruairflow ). Banyak pertanyaan tentang Aliran Udara dapat diselesaikan dengan bantuan dokumentasi, tetapi kadang-kadang lebih banyak permintaan khusus muncul: bagaimana saya bisa mengemas Aliran Udara ke buruh pelabuhan, mengapa tidak bekerja pada hari ketiga dan semua itu. Ini bisa dijawab di komunitas ini.
Apa yang harus diperbaiki di DataLake
Pada titik ini, pengembang DWH yakin bahwa semuanya sudah siap dan sekarang Anda bisa tenang. Sayangnya atau untungnya, masih ada sesuatu untuk diperketat di DataLake.
Kualitas data
Dengan sejumlah besar tabel di DataLake, kualitas data adalah yang pertama kali menderita. Misalnya, ambil tabel dengan pembayaran. Berisi user_id, jumlah, tanggal dan waktu pembayaran:
Sekitar 10 ribu pembayaran terjadi setiap hari:

Setelah di meja untuk hari itu datang hanya 28 entri. Ya, dan user_id semuanya kosong:
Jika sesuatu tiba-tiba pecah di sumber kami, maka, berkat Airflow, kami akan segera mengetahuinya. Tetapi jika secara formal ada data, dan bahkan dalam format yang tepat, maka kita tidak segera belajar tentang gangguan dan sudah dari data konsumen. Tidak realistis untuk memeriksa 5000 meja kami dengan tangan kami sendiri.
Untuk mencegah hal ini, kami telah mengembangkan sistem kontrol kualitas data (DQ) kami sendiri. Setiap hari ia memonitor unduhan kunci ke repositori kami: ia melacak perubahan mendadak dalam jumlah baris, mencari bidang kosong, dan memeriksa duplikasi data. Sistem ini juga menerapkan pemeriksaan khusus dari analis. Berdasarkan ini, dia mengirim pemberitahuan ke surat tentang apa yang salah dan di mana. Analis pergi ke proyek dan mencari tahu mengapa, misalnya, ada terlalu sedikit data, menghilangkan alasan, dan kami memuat ulang data.
Prioritaskan unduhan
Dengan meningkatnya jumlah tugas untuk memuat data ke DataLake, konflik prioritas dengan cepat muncul. Situasi yang biasa: beberapa proyek yang tidak terlalu penting mengambil semua sumber daya dengan unduhannya di malam hari, dan tabel yang diperlukan untuk menghitung metrik untuk manajemen puncak tidak punya waktu untuk memuat pada awal hari kerja. Kami menangani ini dalam beberapa cara.
- Memantau unduhan kunci. Airflow memiliki sistem SLA sendiri, yang memungkinkan Anda untuk menentukan apakah semua kunci tepat waktu. Jika beberapa data tidak dimuat, maka kami akan mengetahuinya beberapa jam lebih awal dari pengguna dan punya waktu untuk memperbaikinya.
- Pengaturan prioritas. Untuk melakukan ini, kami menggunakan antrian Aliran Udara dan sistem prioritas. Hal ini memungkinkan kami untuk menentukan urutan pemuatan DAG dan jumlah proses paralel di dalamnya. Tidak masuk akal untuk mengunggah log yang dianalisis sebulan sekali, sebelum mengunduh data untuk metrik manajemen puncak.
Memantau durasi batch malam
Kami memiliki penyimpanan batch. Pada malam hari, kami sedang dalam proses membangunnya, dan penting bagi kami untuk memastikan bahwa ada cukup malam untuk memproses batch harian. Jika tidak, selama jam kerja, analis tidak akan memiliki sumber daya penyimpanan yang cukup untuk bekerja. Kami secara teratur menyelesaikan masalah ini dengan beberapa cara:
- Membalikkan penskalaan. Kami tidak mengirimkan semua data, tetapi hanya apa yang dibutuhkan analis. Kami memantau semua tabel yang dimuat, dan jika salah satunya tidak digunakan selama enam bulan, maka kami mematikan pemuatannya.
- Pembangunan kapasitas. Jika kami memahami bahwa kami dibatasi oleh kemampuan jaringan, jumlah core atau kapasitas disk, maka kami menambahkan node data ke Hadoop.
- Optimalisasi Aliran Udara Pekerja. Kami melakukan semuanya sehingga setiap bagian dari sistem kami digunakan secara maksimal pada setiap saat waktu konstruksi penyimpanan.
- Refactoring dari proses yang tidak optimal. Misalnya, kami mempertimbangkan ekonomi permainan baru, dan kami membutuhkan waktu 5 menit. Tetapi setelah satu tahun, data tumbuh, dan permintaan yang sama diproses selama 2 jam. Pada titik tertentu, kita harus menyesuaikan kembali dengan perhitungan ulang bertahap, meskipun pada awalnya ini mungkin tampak seperti komplikasi yang tidak perlu.
Kontrol Sumberdaya
Penting tidak hanya memiliki waktu untuk menyelesaikan persiapan repositori di awal hari kerja, tetapi juga untuk memantau ketersediaan sumber dayanya setelah itu. Dengan ini, kesulitan mungkin timbul seiring waktu. Pertama-tama, alasannya adalah bahwa analis menulis kueri yang tidak optimal. Sekali lagi, para analis itu sendiri menjadi semakin banyak. Hal paling sederhana dalam hal ini: meningkatkan kapasitas perangkat keras. Namun, permintaan yang tidak optimal masih akan mengambil semua sumber daya yang tersedia. Artinya, cepat atau lambat Anda akan mulai menghabiskan uang untuk besi tanpa manfaat yang signifikan. Oleh karena itu, kami menggunakan beberapa pendekatan lain.
- Kutipan: kami menyerahkan kepada pengguna setidaknya sedikit sumber daya. Ya, permintaan akan dieksekusi perlahan, tetapi setidaknya mereka akan melakukannya.
- Pemantauan sumber daya yang dikonsumsi: berapa banyak inti yang digunakan oleh permintaan pengguna, yang lupa untuk menggunakan partisi di Hadoop dan mengambil semua RAM, dll ... Selain itu, pemantauan ini dapat dilihat oleh para analis sendiri, dan ketika sesuatu tidak bekerja untuk mereka, mereka sendiri menemukan pelakunya dan berurusan dengan dia. Jika kami memiliki beberapa proyek, kami akan melacak sendiri konsumsi sumber daya. Tetapi dengan begitu banyak, kami harus menyewa tim pemantau yang terpisah dan terus berkembang. Dan dalam jangka panjang, ini tidak masuk akal.
- Pelatihan pengguna sukarela-wajib. Tugas analis bukanlah menulis kueri berkualitas ke repositori Anda. Tugas mereka adalah menjawab pertanyaan bisnis. Dan selain diri kita sendiri - tim repositori - tidak ada yang peduli dengan kualitas permintaan analis. Oleh karena itu, kami membuat FAQ dan presentasi, mengadakan kuliah untuk analis kami, menjelaskan bagaimana kami dapat bekerja dengan DataLake kami, dan bagaimana tidak.
Faktanya, menghabiskan waktu untuk menyediakan data jauh lebih penting daripada mengisinya. Jika ada data dalam penyimpanan, tetapi tidak tersedia, maka dari sudut pandang bisnis itu masih ada, dan upaya Anda untuk mengunduh telah dikeluarkan.
Fleksibilitas arsitektur
Penting untuk tidak melupakan fleksibilitas dari DataLake yang dibangun dan jangan takut untuk mengubah arsitektur ketika mengubah faktor input: data apa yang perlu diunggah ke penyimpanan, siapa yang menggunakannya dan bagaimana. Kami tidak percaya bahwa arsitektur kami akan selalu tetap tidak berubah.
Misalnya, kami meluncurkan game seluler baru. Dia menulis JSON ke Nginx dari klien, Nginx melempar data ke Kafka, kami menguraikannya menggunakan Spark dan memasukkannya ke Hadoop. Semuanya berfungsi, tugas ditutup.
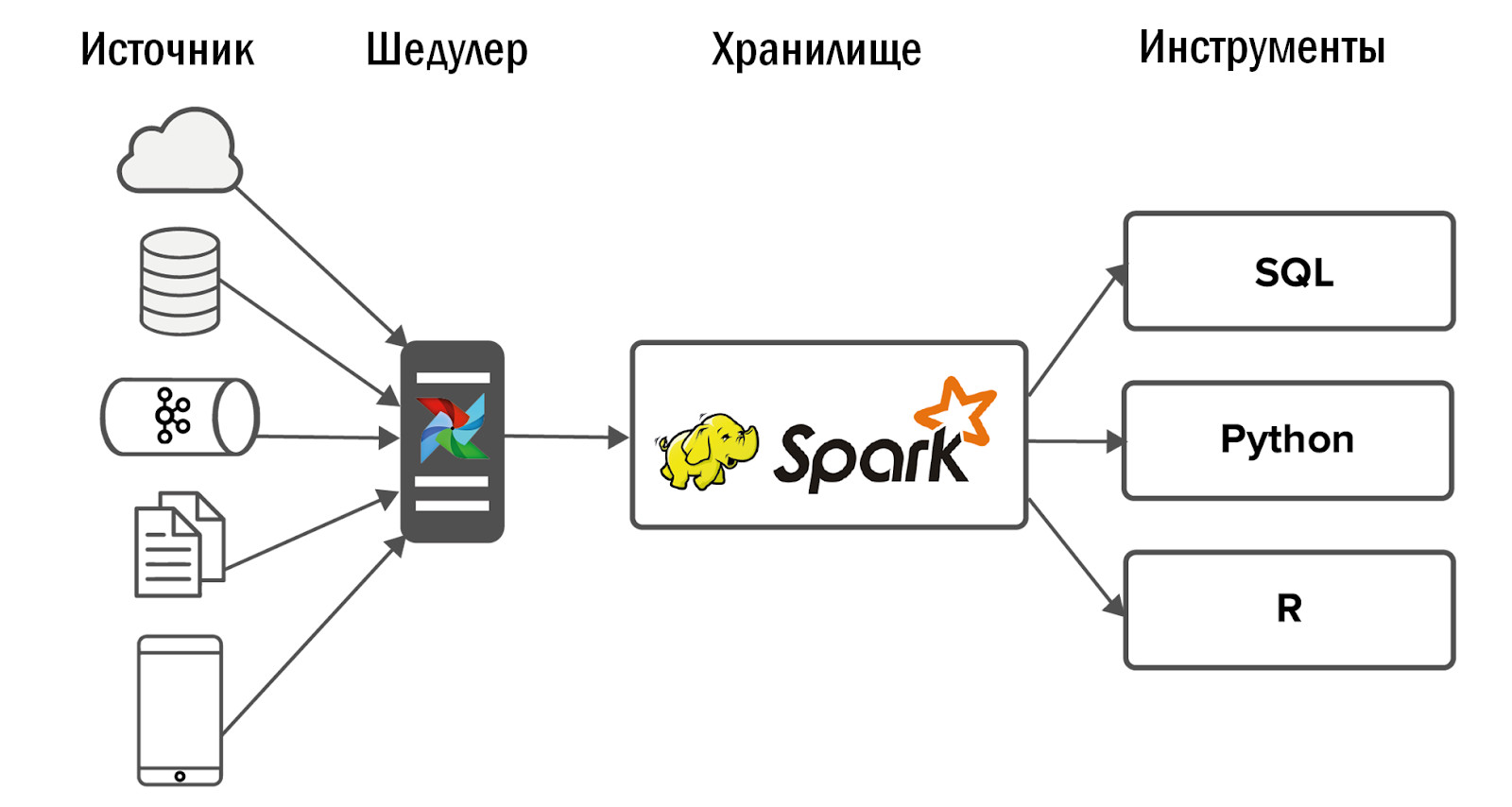
Beberapa bulan berlalu, dan dalam penyimpanan semua proses batch malam mulai berjalan lebih lama. Kami mulai mencari tahu apa masalahnya: ternyata game itu "menembak", 50 kali lebih banyak data dihasilkan dan Spark tidak dapat mengatasi analisis JSON, menyeret setengah dari sumber daya penyimpanan. Awalnya, semua data dikirim ke satu topik Kafka, dan Spark mengurutkannya menjadi entitas yang berbeda. Kami meminta pengembang game untuk berbagi data tentang klien dengan entitas yang berbeda dan menuangkannya ke dalam topik Kafka yang terpisah. Itu menjadi lebih mudah, tetapi tidak lama. Kemudian kami memutuskan untuk beralih dari analisis JSON setiap hari menjadi setiap jam. Namun, fasilitas penyimpanan mulai dibangun tidak hanya pada malam hari, tetapi sekitar jam, yang tidak diinginkan bagi kami. Setelah upaya tersebut, untuk mengatasi masalah ini, kami meninggalkan Spark dan menerapkan ClickHouse.

Ini memiliki mesin parsing JSON hebat yang secara instan menguraikan data ke dalam tabel. Kami pertama kali mengirim informasi dari Kafka ke ClickHouse, dan dari sana kami mengambilnya di Hadoop. Ini sepenuhnya menyelesaikan masalah kami.
Tentu saja, kami mencoba untuk tidak membiakkan sistem kebun binatang di penyimpanan DataLake kami, tetapi kami mencoba untuk memilih teknologi yang paling cocok untuk tugas tertentu.
Apakah itu sepadan?
Apakah layak untuk menggunakan Hadoop, sistem kontrol kualitas, berurusan dengan Airflow, dan membangun proses bisnis? Tentu saja itu layak:
- Bisnis memiliki informasi terkini tentang semua proyek, yang tersedia dalam layanan tunggal.
- Pengguna sistem kami, mulai dari perancang game hingga manajer, berhenti membuat keputusan hanya berdasarkan intuisi dan beralih ke pendekatan Berbasis Data.
- Kami memberi analis alat untuk membuat ilmu roket mereka sendiri. Sekarang mereka menjawab pertanyaan bisnis yang kompleks, membangun model peramalan, sistem rekomendasi, meningkatkan permainan. Sebenarnya, untuk ini kami bekerja di BI-DWH.