Rekan saya Rafael Grigoryan eegdude baru-baru ini menulis sebuah artikel tentang mengapa manusia membutuhkan EEG dan fenomena signifikan apa yang dapat dicatat di dalamnya. Hari ini, sebagai kelanjutan dari topik antarmuka saraf, kami menggunakan salah satu kumpulan data terbuka yang direkam pada permainan menggunakan mekanika P300 untuk memvisualisasikan sinyal EEG, melihat struktur potensi yang disebut, membangun pengklasifikasi utama, mengevaluasi kualitas yang dengannya kita dapat memprediksi keberadaan potensi yang disebut tersebut.
Biarkan saya mengingatkan Anda bahwa P300 disebut potensial (VP), respons spesifik otak yang terkait dengan pengambilan keputusan dan rangsangan yang membedakan (yang akan kita lihat di bawah). Biasanya digunakan untuk membangun BCI modern.
Untuk melakukan klasifikasi EEG, Anda dapat menelepon teman, menulis game tentang Raccoons and Demons di VR, menuliskan reaksi Anda sendiri dan menulis artikel ilmiah (saya akan membicarakan ini lain waktu), tetapi untungnya, para ilmuwan dari seluruh dunia melakukan beberapa percobaan untuk kami dan tetap hanya mengunduh data.
Analisis tentang bagaimana membangun antarmuka saraf pada P300 dengan kode langkah-demi-langkah dan visualisasi, serta tautan ke repositori dapat ditemukan di bawah kucing.
Artikel ini hanya menunjukkan poin utama dari kode, versi direproduksi penuh di notebook jupyter untuk mencari di sini
Dari sudut pandang EEG, P300 hanya ledakan pada waktu tertentu di saluran tertentu. Ada banyak cara untuk menyebutnya, misalnya, jika Anda berkonsentrasi pada satu objek, dan diaktifkan secara acak (perubahan bentuk, warna, kecerahan, atau melompat di suatu tempat). Begini cara penerapannya di zaman kuno.
Secara umum, skema ini adalah sebagai berikut: ada beberapa (biasanya dari 3 sampai 7) rangsangan dalam bidang penglihatan seseorang. Seseorang memilih salah satu dari mereka dan fokus pada itu (cara yang baik adalah dengan menghitung jumlah aktivasi), kemudian setiap objek berkedip dalam urutan acak. Mengetahui waktu aktivasi setiap stimulus, kita sekarang dapat melihat EEG berikutnya dan menentukan apakah ada puncak karakteristik di dalamnya (kita akan melihatnya dalam visualisasi di bawah). Karena orang tersebut hanya berkonsentrasi pada satu rangsangan, maka puncaknya haruslah satu. Jadi, dalam antarmuka saraf Anda ini, salah satu dari beberapa opsi dipilih (huruf untuk menulis, tindakan dalam permainan, dan Tuhan tahu apa lagi). Jika ada lebih dari tujuh opsi, Anda bisa meletakkannya di kisi dan mengurangi tugas untuk memilih baris + kolom. Ini adalah bagaimana ejaan P300 matriks klasik, ditunjukkan di atas.
Dalam kasus dataset yang dipertimbangkan saat ini, bagian visual (dan juga namanya) dipinjam dari pembagi ruang permainan yang terkenal. Itu terlihat seperti ini

Faktanya, ini adalah ejaan yang sama, hanya huruf-huruf yang diganti oleh game alien.
Video proses permainan dan laporan teknis juga disimpan.
Dengan satu atau lain cara, data yang dikumpulkan menggunakan game ini muncul di Internet dan kita dapat mengaksesnya. Data terdiri dari 16 saluran EEG dan satu saluran acara, yang menunjukkan pada saat apa target (dibuat oleh pemain) dan insentif non-target diaktifkan, dan kami akan bekerja dengannya.
Sebagian besar kumpulan data untuk BCI direkam oleh neurofisiologis, dan ini adalah orang-orang yang tidak begitu peduli dengan kompatibilitas, sehingga format data sangat beragam: dari versi file .mat berbeda ke format "standar" .gdf dan .gdf .
Hal terpenting yang perlu Anda ketahui tentang format ini adalah Anda tidak ingin menguraikannya atau bekerja secara langsung.
Untungnya, sekelompok penggemar dari NeuroTechX menulis pengunduh untuk beberapa set data langsung di numpy.
Bootloader ini adalah bagian dari proyek moabb yang mengklaim sebagai solusi universal untuk BCI.
Unduh dataset mentah
import moabb.datasets sampling_rate = 512 m_dataset = moabb.datasets.bi2013a( NonAdaptive=True, Adaptive=True, Training=True, Online=True, ) m_dataset.download() m_data = m_dataset.get_data()
Pada tahap ini, kami mendapat struktur RawEDF yang berisi catatan EEG. Ini adalah struktur dari paket mne , biolog biasanya menggunakannya untuk berinteraksi dengan sinyal: struktur ini memiliki metode built-in untuk menyaring, memvisualisasikan, menyimpan label, dan Anda tidak pernah tahu. Tapi kita tidak akan pergi dengan cara ini sejak itu antarmuka paket cenderung tidak stabil (versi saat ini adalah 0.19 , tetapi kami akan menggunakan 0.17 karena dataset tidak lagi dibaca oleh versi baru) dan didokumentasikan dengan buruk, melalui ini hasil kami mungkin menjadi tidak dapat diproduksi kembali.
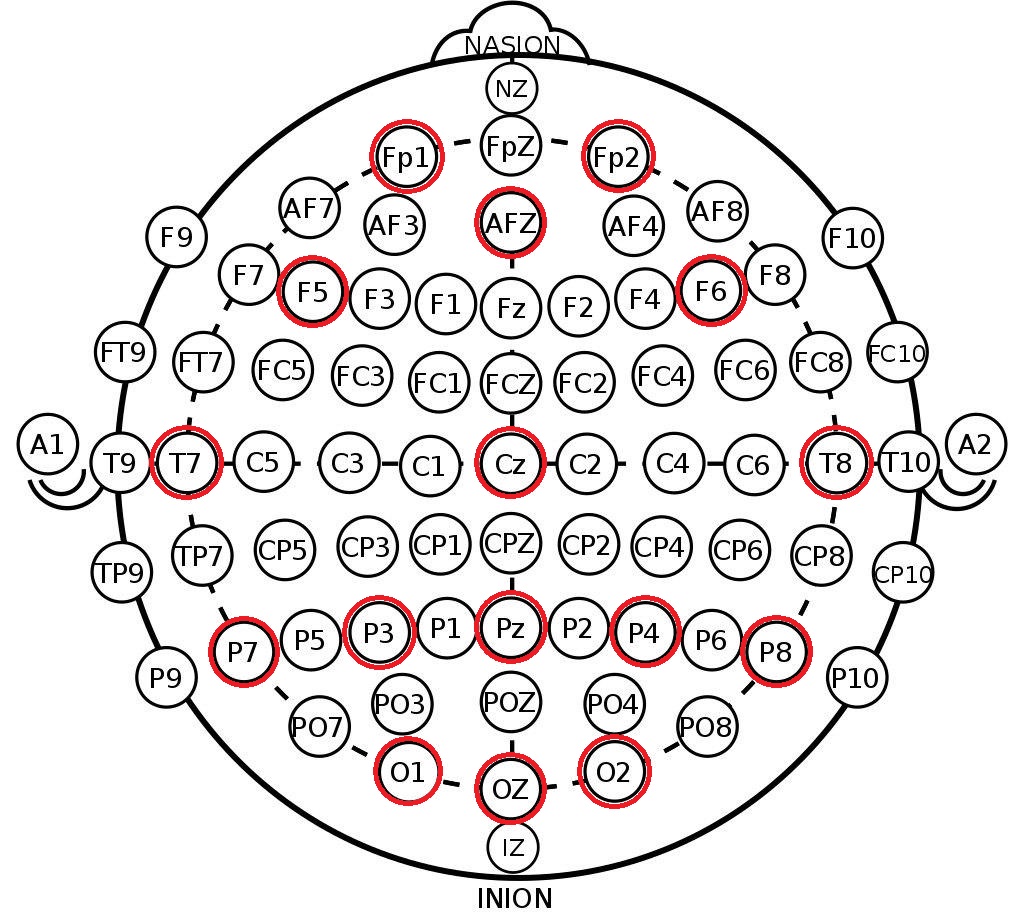
Apa yang kami ambil dari struktur yang dihasilkan adalah label saluran di sistem 10-20 . Ini adalah pengaturan elektroda internasional di kepala seseorang, dibuat agar para ilmuwan dapat mengkorelasikan zona otak dan lokasi saluran EEG. Di bawah ini adalah susunan elektroda dalam sistem 10-10 (berbeda dari 10-20 dengan dua kali kepadatan penandaan) dan saluran yang dicatat dalam dataset ini ditandai dengan warna merah.
print(m_data[1]['session_1']['run_1'])
Pertama, dari data yang diunduh untuk setiap subjek, kami mengalokasikan array EEG kontinu selama 16 detik dan semua label untuk interval ini (dalam data ini hanyalah saluran lain di mana awal peristiwa yang menarik bagi kami dicatat).
Pada tahap ini, kami mempertahankan panjang maksimum EEG kontinu agar tidak menemui efek tepi selama penyaringan lebih lanjut.
raw_dataset = [] for _, sessions in sorted(m_data.items()): eegs, markers = [], [] for item, run in sorted(sessions['session_1'].items()): data = run.get_data() eegs.append(data[:-1]) markers.append(data[-1]) raw_dataset.append((eegs, markers))
Penyaringan dan Pemisahan
Secara umum, untuk meninjau metode pra-pemrosesan dan klasifikasi EEG, saya dapat merekomendasikan ikhtisar yang sangat baik dari master antarmuka neurocomputer. Juga belum lama berselang ulasan yang lebih baru dari tes jaringan saraf dirilis.
Pra-pemrosesan minimum sinyal EEG untuk klasifikasi mencakup 3 langkah:
- penipisan
- penyaringan
- scaling
Untuk mengimplementasikan langkah-langkah ini, kami akan menggunakan sklearn lama yang baik dan paradigma transformer dan jalur pipa sehingga preprocessing kami dapat dengan mudah diperluas.
Kode transformer ditempatkan dalam file terpisah, di bawah ini kami akan menjelaskan beberapa detail.
Penipisan
Untuk beberapa alasan, dalam beberapa artikel dan contoh pemrosesan, saya bertemu dengan penurunan frekuensi sinyal dengan hanya membuang sampel dalam gaya eeg = eeg[:, ::10] . Ini sepenuhnya salah (mengapa - lihat buku apa pun tentang pemrosesan sinyal). Kami menggunakan scipy standar scipy .
Penyaringan
Di sini, kami juga mengandalkan filter scipy dengan memilih filter bandpass Butterworth 4-urutan dan menerapkannya di arah maju dan mundur ( filtfilt ) untuk mempertahankan fase. Frekuensi cutoff - dari 0,5 hingga 20 Hz, ini adalah rentang standar untuk tugas kami.
Scaling
Kami menggunakan StandardScaler per-saluran (kurangi rata-rata, bagi dengan deviasi standar), yang melihat semua sinyal dari sampel. Bahkan, kebocoran data kecil diperkenalkan pada saat ini. secara formal, scaler juga melihat data dari sampel uji, tetapi dengan volume data yang cukup besar, rerata dan deviasinya sama.
Masturbasi dilakukan saluran demi saluran sehingga dalam dataset yang sama dimungkinkan untuk mengumpulkan data dari sensor yang berbeda yang memiliki urutan besarnya dan sifat yang berbeda (misalnya, skin-galvanic reaction (RAG) )
Selain operasi di atas, dimungkinkan juga untuk membedakan artefak di EEG (berkedip, gerakan mengunyah, gerakan kepala), tetapi set data ini sudah sangat bersih, jadi mari kita biarkan sampai waktu berikutnya.
reload(transformers) decimation_factor = 10 final_rate = sampling_rate // decimation_factor epoch_duration = 0.9
Selanjutnya, kami akan menerapkan pipa preprocessing ke data kami dan memotong sinyal EEG terus menerus menjadi zaman. Kami akan menyebut periode waktu segera setelah aktivasi stimulus dengan durasi karakteristik 0,5-1 detik, dalam kasus kami durasinya adalah 900 ms, meskipun dapat dipersingkat.
Dalam dataset kami ada 16 saluran EEG, setelah penipisan diterapkan, frekuensi akan turun menjadi 50 Hz, sehingga satu era akan dijelaskan oleh matriks (16, 45) - 900 ms pada 50 Hz adalah 45 sampel waktu.
Tag dalam dataset ini hanya binari - mereka menandai target (disembunyikan oleh pemain, aktif, 1) dan sinyal non-target (kosong, 0).
for eegs, _ in raw_dataset: eeg_pipe.fit(eegs) dataset = [] for eegs, markers in raw_dataset: epochs = [] labels = [] filtered = eeg_pipe.transform(eegs) markups = markers_pipe.transform(markers) for signal, markup in zip(filtered, markups): epochs.extend([signal[:, start:(start + epoch_count)] for start in markup[:, 0]]) labels.extend(markup[:, 1]) dataset.append((np.array(epochs), np.array(labels)))
dataset[0][0].shape, dataset[0][1].shape
Jadi kami mendapat Pytorch Pytorch-style di mana indeks pertama menghitung orang yang berbeda. Dengan struktur ini, kami dapat melakukan validasi silang dalam data satu orang, dan menguji toleransi pengelompokan antara orang yang berbeda (yang disebut transfer learning, prediksi yang kurang kalibrasi). Data satu orang terdiri dari berbagai era dan label kelas. Jumlah era untuk setiap orang sedikit berbeda karena karakteristik rekaman.
Penelitian dan visualisasi data
Pertama, lihat salah satu sinyal kontinu sebelum mengiris zaman.
Terlepas dari kenyataan bahwa itu telah disaring, itu tidak menunjukkan aktivasi apa pun pada mata dan lebih mirip semacam kebisingan.
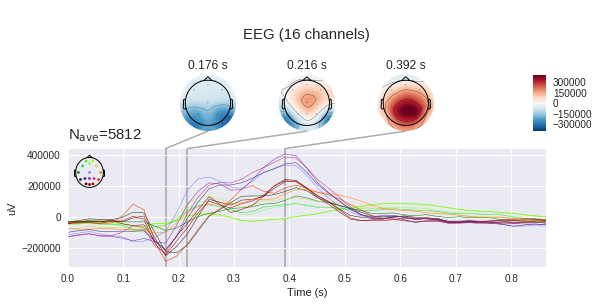
Jika kita mempertimbangkan hanya satu target zaman dari dataset kita, maka kita akan melihat peningkatan karakteristik dalam interval 400-600 ms. Ini adalah P300 potensial yang kami cari.
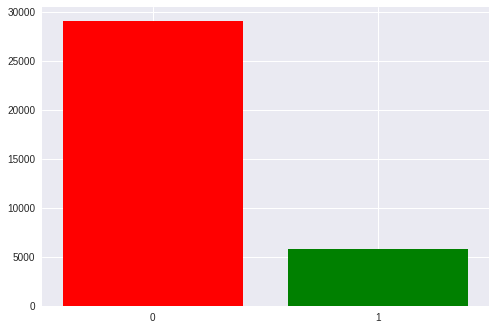
Secara total, dalam dataset kami ada sekitar 35 ribu zaman, yaitu aktivasi stimulus. Setiap orang memiliki sekitar 1300 hingga 1750 (ini disebabkan oleh fakta bahwa seseorang menembak alien lebih cepat dan seseorang lebih lambat).
Ada juga ketidakseimbangan yang terlihat di kelas: 1 sampai 5 yang mendukung rangsangan kosong. kami memiliki 6 baris dan kolom dalam matriks dan hanya salah satunya yang menjadi target. Nanti kita akan kembali ke ini ketika membahas metrik yang diperoleh.
Sekarang saatnya untuk melihat perbedaan antara sinyal target dan non-target
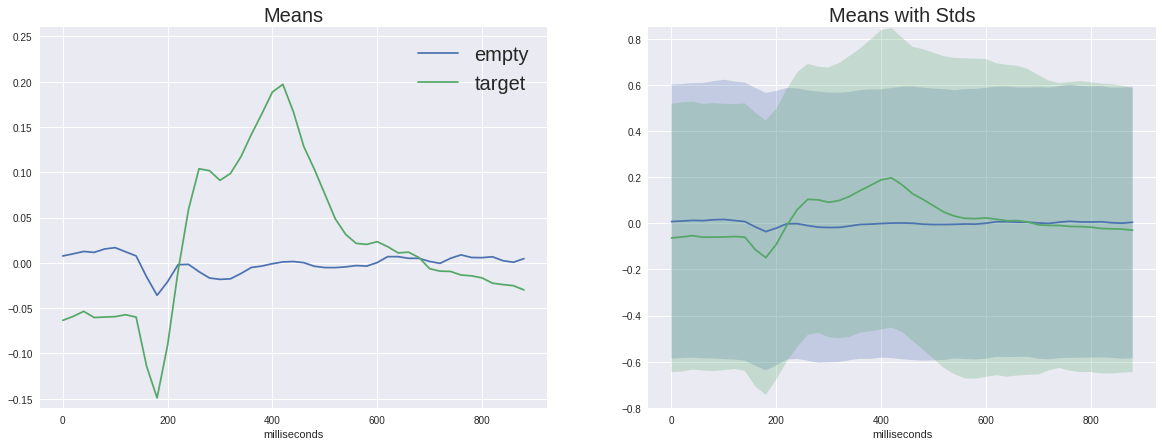
Pada grafik sebelah kiri, Anda dapat melihat bahwa sinyal rata-rata sangat bervariasi, dan keduanya memiliki respons non-spesifik di wilayah 180 ms, tetapi target satu jauh lebih banyak amplitudo, target juga memiliki punuk karakteristik dari 250 hingga 500 ms - ini adalah P300 yang terkenal kejam.
Dengan perbedaan dalam sinyal, tugas kita mungkin tampak seperti hal sepele, tetapi jika kita menambahkan standar deviasi pada setiap titik pada grafik, kita akan melihat bahwa gambarnya tidak begitu cerah - sinyalnya cukup berisik. Dan ini terlepas dari kenyataan bahwa rasio signal-to-noise untuk P300 dianggap salah satu yang tertinggi dalam neurofisiologi.
(Sebenarnya, grafik ini tidak dibangun dengan cukup jujur, karena sinyal kosong dirata-rata lebih dari lima kali lebih banyak sampel yang berbeda, sehingga penyimpangan acak lebih tersendat, tetapi seperti yang dapat kita lihat dari dispersi dengan urutan yang sama, ini tidak banyak membantu)

Juga berguna untuk melihat sinyal rata-rata dari satu orang.
Di sini komentar sebelumnya tentang rata-rata "tidak jujur" ditemukan - sinyal kosong terasa lebih amplitudo daripada dengan rata-rata atas semua. Juga, puncak P300 dalam satu orang lebih tinggi karena kurang rata-rata.
Penting untuk mencatat fitur lain dari sinyal satu orang - ia memiliki bentuk yang sedikit berbeda dari yang umum. Variabilitas interpersonal dari reaksi neurofisiologis cukup tinggi, kita masih akan melihat pengaruh faktor ini dalam pekerjaan pengklasifikasi. Namun, perbedaan intrapersonal (satu orang dalam suasana hati yang berbeda, tingkat stres, kelelahan) juga cukup besar.

Selanjutnya, kita melihat sapuan sinyal saluran per saluran. Sudut pandang di sini bertepatan dengan gambar di atas, yang menggambarkan posisi elektroda - hidung di atas, dll.
Respons masing-masing bagian kepala berbeda. Pada Fp1,2, dua puncak negatif sebelum puncak positif diucapkan. Juga, di beberapa saluran ada dua puncak positif, dan di beberapa - satu atau sesuatu transisi antara.
Saluran yang berbeda memiliki kepentingan yang berbeda untuk menentukan keberadaan P300, dapat diperkirakan menggunakan metode yang berbeda - menghitung informasi timbal balik (mutual information) atau metode add-delete (alias stepwise regression). Penerapan metode ini akan kita hadapi di lain waktu.
Perlu diingat bahwa kita mengukur perbedaan potensial antara elektroda dengan elektroda, yang berarti bahwa kita dapat membuat peta tegangan untuk seluruh head pada titik-titik waktu menggunakan perubahan tegangan pada titik-titik individual. Jelas bahwa jika ada 16 elektroda, keakuratan kartu seperti itu meninggalkan banyak yang diinginkan, tetapi beberapa pemahaman harus dibentuk. ( mne secara default mengharapkan untuk melihat microvolts, tetapi kami telah menerapkan penskalaan, sehingga nilai absolutnya tidak benar)

Klasifikasi
Akhirnya, saatnya menerapkan metode pembelajaran mesin pada sampel kami.
Beberapa yang dasar dipilih sebagai pengklasifikasi - log. regresi, metode vektor dukungan (SVM), dan beberapa metode menggunakan analisis korelasi dari paket pyriemann (rincian masing-masing metode dapat ditemukan dalam dokumentasi), perlu dicatat bahwa metode ini dikembangkan secara khusus untuk aplikasi EEG dan dengan bantuan mereka beberapa kompetisi dimenangkan pada kaggle.
clfs = { 'LR': ( make_pipeline(Vectorizer(), LogisticRegression()), {'logisticregression__C': np.exp(np.linspace(-4, 4, 9))}, ), 'LDA': ( make_pipeline(Vectorizer(), LDA(shrinkage='auto', solver='eigen')), {}, ), 'SVM': ( make_pipeline(Vectorizer(), SVC()), {'svc__C': np.exp(np.linspace(-4, 4, 9))}, ), 'CSP LDA': ( make_pipeline(CSP(), LDA(shrinkage='auto', solver='eigen')), {'csp__n_components': (6, 9, 13), 'csp__cov_est': ('concat', 'epoch')}, ), 'Xdawn LDA': ( make_pipeline(Xdawn(2, classes=[1]), Vectorizer(), LDA(shrinkage='auto', solver='eigen')), {}, ), 'ERPCov TS LR': ( make_pipeline(ERPCovariances(estimator='oas'), TangentSpace(), LogisticRegression()), {'erpcovariances__estimator': ('lwf', 'oas')}, ), 'ERPCov MDM': ( make_pipeline(ERPCovariances(), MDM()), {'erpcovariances__estimator': ('lwf', 'oas')}, ), }

Skema antarmuka saraf yang paling umum adalah "kalibrasi + kerja" yaitu Pertama, perlu bahwa seseorang berkonsentrasi pada rangsangan yang ditunjukkan sebelumnya untuk beberapa waktu, dan hanya setelah itu kita memprediksi pilihannya. Pendekatan ini jelas memiliki kerugian dari tahap awal yang membosankan.
Untuk menilai kinerja metode kami dalam mode ini, kami akan melakukan validasi silang dalam era satu orang.
Metrik akurasi dalam kasus ini tidak relevan karena ketidakseimbangan dataset (baseline adalah 5/6 ~ 83% di sini), jadi saya lebih suka melihat ketepatan-recall-f1 tiga.
Untuk meninjau seluruh dataset, kami rata-rata hasil validasi silang tersebut di semua orang. Secara umum, kinerja model terbaik cukup tinggi dibandingkan dengan apa yang kami miliki di Neiry dalam kondisi "lapangan" sebuah taman hiburan (saya ingat bahwa dataset ini direkam di laboratorium).
Dalam dataset ini hanya ada label biner untuk data. Secara umum, kita perlu memecahkan masalah multikelas dalam memilih salah satu rangsangan (omong-omong, itu seimbang karena setiap stimulus diaktifkan jumlah yang sama kali). Untuk mengatasinya, jumlah aktivasi setiap stimulus biasanya ditetapkan (misalnya, masing-masing 6 stimuli dari 5 aktivasi) dan semua stimuli diaktifkan secara acak (30 kali), 30 zaman diperoleh dan probabilitas aktivasi ditambahkan untuk ditargetkan, setelah itu stimulus yang telah mencapai maksimum jumlahnya diakui sebagai target. Kami akan mendemonstrasikan implementasi pendekatan ini pada posting mendatang pada dataset yang sesuai.

Skema kedua disebut transfer learning - yaitu, transfer classifier antara orang-orang. Faktanya adalah bahwa ketika kita melakukan kalibrasi, kita benar-benar berlatih kembali ke bentuk puncak dari satu orang, sehingga kita dapat memperkirakannya dengan baik dalam tes berikutnya. Dengan tidak adanya kalibrasi, classifier pra-terlatih harus dapat mengisolasi konsep P300 tanpa mengetahui terlebih dahulu bentuk gelombang orang tertentu.
Kami akan melakukan dua percobaan - kami akan melatih penggolong pada satu orang, dan kami akan memprediksi lima, dan kemudian kami akan meningkatkan sampel pelatihan menjadi 10 orang dan membandingkan hasilnya untuk memastikan bahwa model mampu meningkatkan kemampuan generalisasi mereka
Pelatihan untuk 1 orang

Pelatihan untuk 10 orang
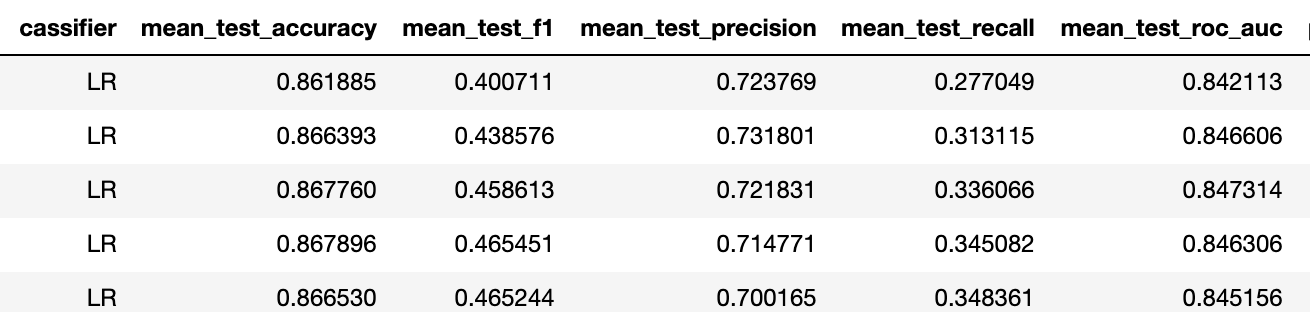
Jadi f1 naik dari 0,23 menjadi 0,4 untuk pengklasifikasi yang lebih baik (dalam kedua kasus itu adalah regresi log dengan regularisasi yang sama).
Ini berarti bahwa kemampuan prediksi telah meningkat dari "tidak" menjadi "dapat diterima." Berdasarkan pengalaman kami, dengan metrik tugas biner seperti itu, 5 aktivasi setiap stimulus cukup untuk mencapai keakuratan masalah multiclass sekitar 75%.
Pada akhirnya, saya ingin mencatat bahwa metode di atas cukup primitif, yang dapat dilihat, misalnya, dengan tingkat tinggi regularisasi regresi log - saluran dalam data berkorelasi sangat kuat dan ada beberapa pendekatan untuk menyelesaikan fakta ini.
Kesimpulan
Hari ini, kami menjadi lebih akrab dengan potensi yang ditimbulkan P300 dan membangun saluran pipa sederhana untuk antarmuka saraf. Saya merekomendasikan mereka yang tertarik untuk membuka laptop sendiri (terletak di repositori ) dan bereksperimen dengan opsi visualisasi dan pengklasifikasi.
Memiliki pemahaman dasar tentang metode bekerja dengan sinyal EEG, kami akan dapat lebih jauh memeriksa topik ini - untuk menerapkan metode preprocessing canggih, serta jaringan saraf, untuk memecahkan masalah membangun antarmuka saraf. Dilanjutkan ...