Selama beberapa tahun terakhir, saya telah merancang dan membuat mesin yang dapat mengenali dan mengurutkan bagian-bagian LEGO. Bagian terpenting dari alat ini adalah
Unit Pengambilan, kompartemen kecil, yang hampir sepenuhnya tertutup di mana terdapat sabuk konveyor, pencahayaan, dan kamera.
Pencahayaan Anda akan melihat sedikit lebih rendah.Kamera mengambil foto bagian-bagian LEGO yang datang melalui conveyor, dan kemudian mentransfer gambar secara nirkabel ke server yang menjalankan algoritma kecerdasan buatan untuk mengenali bagian di antara ribuan elemen LEGO yang mungkin. Saya akan memberi tahu Anda lebih banyak tentang algoritma AI dalam artikel mendatang, dan artikel ini akan fokus pada pemrosesan yang dilakukan antara output mentah dari kamera video dan input ke jaringan saraf.
Masalah utama yang perlu saya pecahkan adalah mengubah aliran video dari conveyor menjadi gambar terpisah dari bagian-bagian yang dapat digunakan oleh jaringan saraf.
Tujuan akhir: untuk beralih dari video mentah (di sebelah kiri) ke satu set gambar dengan ukuran yang sama (di sebelah kanan) untuk mentransfernya ke jaringan saraf. (Dibandingkan dengan pekerjaan nyata, gif adalah sekitar setengah lambat)Ini adalah contoh yang bagus dari tugas yang di permukaan tampak sederhana, tetapi sebenarnya memiliki banyak kendala unik dan menarik, banyak di antaranya unik untuk platform visi mesin.
Mengambil bagian kanan gambar dengan cara ini sering disebut deteksi objek. Itulah tepatnya yang perlu saya lakukan: untuk mengenali keberadaan objek, lokasi dan ukurannya, sehingga Anda dapat membuat
persegi panjang pembatas untuk setiap bagian pada setiap bingkai.
Yang paling penting adalah menemukan kotak pembatas yang bagus (ditunjukkan di atas dengan warna hijau)Saya akan mempertimbangkan tiga aspek untuk menyelesaikan masalah:
- Bersiap untuk menghilangkan variabel yang tidak perlu
- Membuat proses dari operasi penglihatan mesin yang sederhana
- Mempertahankan kinerja yang memadai pada platform Raspberry Pi dengan sumber daya terbatas
Eliminasi variabel yang tidak perlu
Dalam kasus tugas-tugas seperti itu, yang terbaik adalah menghilangkan variabel sebanyak mungkin sebelum menggunakan teknik visi mesin. Sebagai contoh, saya tidak perlu khawatir tentang kondisi lingkungan, posisi kamera yang berbeda, kehilangan informasi karena tumpang tindih beberapa bagian oleh yang lain. Tentu saja, adalah mungkin (walaupun sangat sulit) untuk menyelesaikan semua variabel ini secara terprogram, tetapi untungnya bagi saya, mesin ini dibuat dari awal. Saya sendiri dapat mempersiapkan solusi yang sukses, menghilangkan semua gangguan bahkan sebelum saya mulai menulis kode.
Langkah pertama adalah dengan tegas memperbaiki posisi, sudut dan fokus kamera. Dengan ini, semuanya sederhana - dalam sistem, kamera dipasang di atas conveyor. Saya tidak perlu khawatir tentang gangguan dari bagian lain; benda yang tidak diinginkan hampir tidak memiliki peluang untuk masuk ke unit penangkapan. Sedikit lebih rumit, tetapi sangat penting untuk memastikan
kondisi pencahayaan yang konstan . Saya tidak perlu pengenal objek untuk secara keliru menafsirkan bayangan bagian yang bergerak di sepanjang pita sebagai objek fisik. Untungnya, unit tangkap sangat kecil (seluruh bidang pandang kamera lebih kecil dari sepotong roti), jadi saya memiliki lebih dari cukup kontrol atas kondisi di sekitarnya.
Unit pengambilan, tampilan bagian dalam. Kamera berada di sepertiga atas bingkai.Salah satu solusinya adalah membuat kompartemen tertutup sepenuhnya sehingga tidak ada pencahayaan luar yang masuk. Saya mencoba pendekatan ini menggunakan strip LED sebagai sumber pencahayaan. Sayangnya, sistem ini ternyata sangat murung - hanya satu lubang kecil di kasing sudah cukup dan cahaya menembus ke dalam kompartemen, sehingga tidak mungkin untuk mengenali objek.
Pada akhirnya, solusi terbaik adalah "menyumbat" semua sumber cahaya lainnya dengan mengisi kompartemen kecil dengan cahaya yang kuat. Ternyata sumber cahaya yang bisa digunakan untuk menerangi tempat tinggal sangat murah dan mudah digunakan.
Dapatkan bayangannya!Ketika sumber diarahkan ke kompartemen kecil, itu benar-benar menyumbat semua gangguan cahaya eksternal potensial. Sistem seperti itu juga memiliki efek samping yang nyaman: karena banyaknya cahaya di kamera, Anda dapat menggunakan kecepatan rana yang sangat tinggi, mendapatkan gambar bagian yang sangat jelas bahkan ketika bergerak cepat di sepanjang conveyor.
Pengakuan Objek
Bagaimana saya bisa mengubah video yang indah ini dengan penerangan seragam ke dalam kotak pembatas yang saya butuhkan? Jika Anda bekerja dengan AI, Anda bisa menyarankan agar saya menerapkan jaringan saraf untuk pengenalan objek seperti
YOLO atau
Faster R-CNN . Jaringan saraf ini dapat dengan mudah mengatasi tugas tersebut. Sayangnya, saya mengeksekusi kode pengenalan objek pada
Raspberry pi . Bahkan komputer yang kuat akan memiliki masalah menjalankan jaringan saraf convolutional ini pada frekuensi yang saya butuhkan sekitar 90FPS. Dan Raspberry pi, yang tidak memiliki GPU yang kompatibel dengan AI, tidak dapat mengatasi versi salah satu dari algoritma AI tersebut. Saya dapat melakukan streaming video dari Pi ke komputer lain, tetapi transmisi video waktu-nyata adalah proses yang sangat murung, dan penundaan dan keterbatasan bandwidth menyebabkan masalah serius, terutama ketika Anda membutuhkan kecepatan transfer data yang tinggi.
YOLO sangat keren! Tapi saya tidak butuh semua fungsinya.Untungnya, saya bisa menghindari solusi berbasis AI yang sulit menggunakan teknik visi mesin "old-school". Teknik pertama adalah
pengurangan latar belakang , yang mencoba untuk mengisolasi semua bagian gambar yang diubah. Dalam kasus saya, satu-satunya hal yang bergerak di bidang tampilan kamera adalah detail LEGO. (Tentu saja, rekaman itu juga bergerak, tetapi karena memiliki warna yang seragam, sepertinya itu stasioner ke kamera). Pisahkan detail LEGO ini dari latar belakang, dan setengah dari masalah terpecahkan.
Agar pengurangan latar belakang berfungsi, objek latar depan harus sangat berbeda dari latar belakang. Detail LEGO memiliki berbagai warna, jadi saya harus memilih warna latar belakang dengan sangat hati-hati sehingga sejauh mungkin dari warna LEGO. Itulah mengapa kaset di bawah kamera terbuat dari kertas - tidak hanya harus sangat seragam, tetapi juga tidak dapat terdiri dari LEGO, jika tidak maka akan menjadi warna salah satu bagian yang perlu saya kenali! Saya memilih merah muda pucat, tetapi warna pastel lainnya, tidak seperti warna LEGO biasa, akan cocok.
Pustaka OpenCV yang luar biasa telah memiliki beberapa algoritma untuk pengurangan latar belakang. MOG2 Background Subtractor adalah yang paling kompleks di antara mereka, dan pada saat yang sama bekerja sangat cepat bahkan pada raspberry pi. Namun, memberi bingkai video langsung ke MOG2 tidak berfungsi dengan baik. Sosok abu-abu terang dan putih terlalu dekat dengan kecerahan latar belakang pucat dan hilang di atasnya. Saya perlu menemukan cara untuk lebih jelas memisahkan pita dari bagian-bagian di atasnya, memesan subtrakter latar belakang untuk melihat lebih dekat pada
warna , dan bukan pada
kecerahan . Untuk melakukan ini, cukup bagi saya untuk meningkatkan saturasi gambar sebelum mentransfernya ke subtrakter latar belakang. Hasilnya telah meningkat secara signifikan.
Setelah mengurangi latar belakang, saya perlu menggunakan operasi morfologis untuk menghilangkan kebisingan sebanyak mungkin. Untuk menemukan kontur area putih, Anda dapat menggunakan fungsi findContours () dari pustaka OpenCV. Dengan menerapkan berbagai heuristik untuk membelokkan loop yang mengandung kebisingan, Anda dapat dengan mudah mengkonversi loop ini ke kotak pembatas yang telah ditentukan.
Performa
Jaringan saraf adalah makhluk yang rakus. Untuk hasil terbaik dalam klasifikasi, ia membutuhkan gambar dengan resolusi maksimum dan dalam jumlah sebanyak mungkin. Ini berarti bahwa saya perlu memotret mereka pada frame rate yang sangat tinggi, dengan tetap menjaga kualitas dan resolusi gambar. Saya harus memeras maksimum yang dimungkinkan dari kamera dan GPU Raspberry PI.
Dokumentasi yang sangat terperinci
untuk picamera mengatakan bahwa chip kamera V2 dapat menghasilkan gambar berukuran 1280x720 piksel dengan frekuensi maksimum 90 bingkai per detik. Ini adalah jumlah data yang luar biasa, dan meskipun kamera dapat menghasilkannya, ini tidak berarti bahwa komputer dapat mengatasinya. Jika saya memproses gambar RGB 24-bit mentah, saya harus mentransfer data pada kecepatan sekitar 237 MB / s, yang terlalu banyak untuk GPU buruk dari komputer Pi dan SDRAM. Bahkan ketika menggunakan kompresi akselerasi GPU dalam format JPEG, 90fps tidak dapat dicapai.
Raspberry Pi mampu menampilkan gambar YUV mentah dan tanpa filter. Meskipun lebih sulit untuk bekerja dibandingkan dengan dengan RGB, YUV sebenarnya memiliki banyak properti yang nyaman. Yang paling penting dari mereka adalah bahwa ia hanya menyimpan 12 bit per piksel (untuk RGB itu 24 bit).
Setiap empat byte Y memiliki satu byte U dan satu byte V, yaitu 1,5 byte per piksel.Ini berarti bahwa dibandingkan dengan frame RGB, saya dapat memproses frame YUV
dua kali lebih banyak , dan ini tidak termasuk waktu tambahan yang dihemat GPU saat mengkonversi ke gambar RGB.
Namun, pendekatan ini memberlakukan batasan unik pada proses pemrosesan. Sebagian besar operasi dengan bingkai video berukuran penuh akan mengkonsumsi sumber daya memori dan CPU yang sangat besar. Dalam batas waktu saya yang ketat, bahkan tidak mungkin untuk memecahkan kode bingkai YUV layar penuh.
Untungnya, saya tidak perlu memproses seluruh bingkai! Untuk pengenalan objek, persegi panjang pembatas tidak harus akurat, perkiraan akurasi sudah cukup, sehingga seluruh proses mengenali objek dapat dilakukan dengan bingkai yang jauh lebih kecil. Operasi zoom out tidak diperlukan untuk memperhitungkan semua piksel bingkai berukuran penuh, sehingga bingkai dapat dikurangi dengan sangat cepat dan tanpa biaya. Kemudian skala persegi pembatas yang dihasilkan meningkat lagi dan digunakan untuk memotong objek dari bingkai YUV berukuran penuh. Berkat ini, saya tidak perlu men-decode atau memproses seluruh frame beresolusi tinggi.
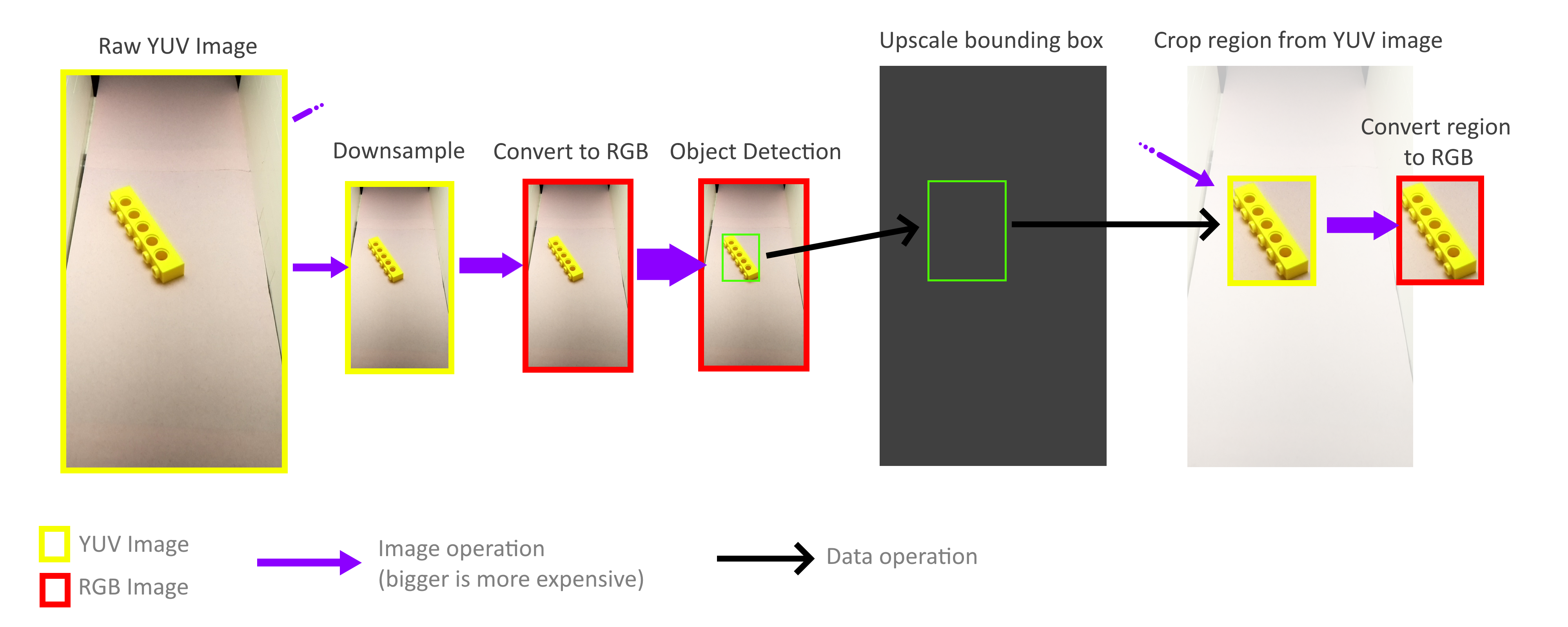
Untungnya, berkat metode penyimpanan format YUV ini (lihat di atas), sangat mudah untuk menerapkan operasi pemangkasan dan pembesaran yang bekerja langsung dengan format YUV. Selain itu, seluruh proses dapat diparalelkan dengan empat inti Pi tanpa masalah. Namun, saya menemukan bahwa tidak semua core digunakan untuk potensi penuh mereka, dan ini memberitahu kita bahwa bandwidth memori masih menjadi hambatan. Namun demikian, saya berhasil mencapai 70-80FPS dalam praktek. Analisis yang lebih dalam tentang penggunaan memori dapat membantu mempercepat segalanya.
Jika Anda ingin tahu lebih banyak tentang proyek ini, maka baca artikel saya sebelumnya,
"Bagaimana Saya Membuat Lebih Dari 100 Ribu Gambar LEGO Berlabel untuk Belajar .
"Video pengoperasian seluruh mesin sortir: